消息队列的优点
① 实现系统解耦 ② 实现异步调用 ③ 流量削峰
消息队列的缺点
① 系统可用性降低 ② 提升系统的复杂度 ③ 数据一致性问题
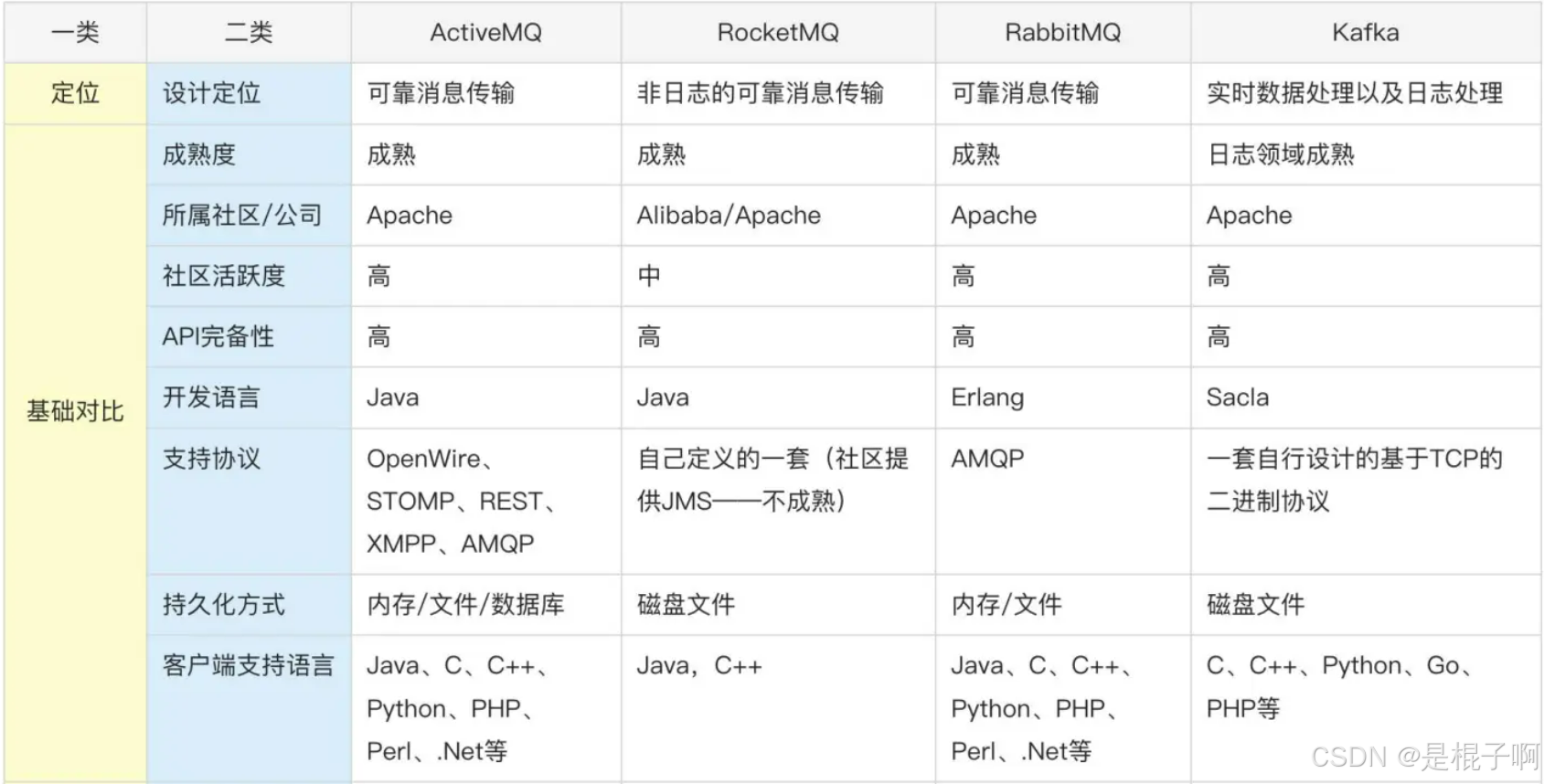
各个消息队列组件简介
Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的日志提交系统(a distributed commit log)。Kafka高性能、可扩展性高、可持久化,数据分区,可复制和可容错.
优点:
① 客户端语言丰富:支持Java、.Net、PHP、Ruby、Python、Go等多种语言;
② 高性能:单机写入TPS约在100万条/秒(消息大小10个字节);
③ 提供完全分布式架构,有replica机制,拥有较高的可用性和可靠性,理论上支持消息无限积;
④ 消费者采用Pull方式获取消息。消息有序,通过控制能够保证所有消息被消费且仅被消费一次;
⑤ 在日志领域比较成熟,被多家公司和多个开源项目使用。有管理界面Kafka-Manager;
缺点:
① Kafka单机超过64个队列/分区时,Load时会发生明显的飙高现象。队列越多,负载越高,发送消息响应时间变长;
② 使用短轮询方式,实时性取决于轮询间隔时间;
③ 消费失败不支持重试;
④ 社区更新较慢。
RocketMQ出自阿里的开源产品,用Java语言实现,在设计时参考了Kafka,并做出了自己的一些改进,消息可靠性上比Kafka更好。RocketMQ在阿里内部被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
优点
① 单机支持1万以上持久化队列;
② RocketMQ的所有消息都是持久化的,先写入系统PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,而访问时,直接从内存读取。
③ 模型简单,接口易用;
④ 性能非常好,可以允许大量堆积消息在Broker中;
⑤ 支持多种消费模式,包括集群消费、广播消费等;
⑥ 各个环节分布式扩展设计,支持主从和高可用;开发度较活跃,版本更新很快。
缺点
① 没有Web管理界面,提供了一个CLI (命令行界面) 管理工具带来查询、管理和诊断各种问题
② 支持的客户端语言不多,目前是Java及C++,其中C++还不成熟;
③ RocketMQ社区关注度及成熟度也不及Kafka;
④ 没有在MQ核心里实现JMS等接口;
RabbitMQ于2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。它提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性机制、投递确认、发布者证实和高可用性机制;灵活的路由,消息在到达队列前是通过交换机进行路由的。RabbitMQ为典型的路由逻辑提供了多种内置交换机类型。
优点
① 由于Erlang语言的特性,消息队列性能较好,支持高并发;
② 健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
③ 有消息确认机制和持久化机制,可靠性高;
④ 高度可定制的路由;
⑤ 管理界面较丰富,在互联网公司也有较大规模的应用,社区活跃度高。
缺点
① 实现了代理架构,意味着消息在发送到客户端之前可以在中央节点上排队。此特性使得
RabbitMQ易于使用和部署,但是使得其运行速度较慢,因为中央节点增加了延迟,消息封装后
也比较大;需要学习比较复杂的接口和协议,学习和维护成本较高。
② 尽管结合Erlang语言本身的并发优势,性能较好,却不利于做二次开发和维护;
ActiveMQ是由Apache出品,ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的JMSProvider实现。它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能。
优点
① 可以用JDBC:可以将数据持久化到数据库。虽然使用JDBC会降低ActiveMQ的性能,但是数据库一直都是开发人员最熟悉的存储介质;
② 支持JMS规范:支持JMS规范提供的统一接口;
③ 支持自动重连和错误重试机制;
④ 有安全机制:支持基于shiro,jaas等多种安全配置机制,可以对Queue/Topic进行认证和授权;
⑤ 监控完善:拥有完善的监控,包括WebConsole,JMX,Shell命令行,Jolokia的RESTful API;
⑥ 界面友善:提供的WebConsole可以满足大部分情况,还有很多第三方的组件可以使用;
缺点
① 社区活跃度不及RabbitMQ高;
② 根据其他用户反馈,会出莫名其妙的问题,会丢失消息;
③ 目前重心放到activemq6.0产品Apollo,对5.x的维护较少;
④ 不适合用于上千个队列的应用场景;

常见面试题
1. 如何防止消息丢失?
针对发送方: 将ack设置为1或者-1/all可以防止消息丢失,如果要做到99.9999%,ack要设置为-1/all,并把min.insync.replicas配置成分区备份数
针对接收方: 把自动提交修改为手动提交(enable-auto-commit)。
(-1/all: 表示kafka ISR列表中所有的副本同步数据成功,才返回消息给客户端,这是最强的数据保证。min.insync.replicas 这个配置是用来设置同步副本个数的下限的, 并不是只有 min.insync.replicas 个副本同步成功就返回ack。而是,只要acks=all就意味着ISR列表里面的副本必须都要同步成功。
0: 表示producer不需要等待任何broker确认收到消息的ACK回复,就可以继续
发送下一条消息。性能最高,但是最容易丢失消息
1: 表示至少等待leader已经成功将数据写入本地日志,但是不需要等待所有
follower都写入成功,就可以继续发送下一条消息)
2. 如何防止消息的重复消费?
一条消息被消费者消费多次,如果为了不消费到重复的消息,我们需要在消费端增加幂等性处理,例如:
① 通过mysql插入业务id作为主键,因为主键具有唯一性,所以一次只能插入一条业务数据。
② 使用redis或zk的分布式锁,实现对业务数据的幂等操作。
3. 如何做到顺序消费?
针对发送方: 在发送时将ack配置为非0,确保消息至少同步到leader之后再返回ack继续发送。但是,只能保证分区内部的消息是顺序的,而无法保证一个Topic下的多个分区总的消息是有序的。
针对接收方: 消息发送到一个分区中,只配置一个消费组的消费者来接收消息,那么这个Consumer所接收到的消息就是有顺序的了,不过这也就牺牲掉了性能。
4. 如何解决消息积压的问题?
消息积压会导致很多问题,比如:磁盘被打满、Producer发送消息导致kafka性能过慢,然后就有可能发生服务雪崩。解决的方案如下所示:
① 在一个消费者中启动多个线程,加快消费的速度, 提升单个Consumer的处理能力。
② 增加Consumer的数量从而提高整体消费能力。
③ 设定某个时间内,如果消息仍没有被消费,那么Consumer收到消息后,直接废弃掉,不执行下面的业务逻辑。
5. 如何实现延迟队列?
场景:订单创建成功后如果超过30分钟没有付款,则需要取消订单。
① 创建一个表示“订单30分钟未支付”的Topic,如:order_not_paid_30min,
表示延迟30分钟的消息队列。
② Producer发送消息的时候,消息内容要带上订单生成的时间create_time。
③ Consumer消费Topic中的消息,如果发现now减去create_time不足30分钟,
则不去消费;记录当前的offset,不去消费当前以及之后的消息。
④ 通过记录的offset去获取消息,如果发现消息已经超过30分钟且订单状态
是“未支付”,那么则将订单状态设置为“取消”,然后获取下一个offset的
消息。
6. Kafka如何做到单机上百万的高吞吐量呢 ?
写入数据:主要是依靠页面缓存技术 + 磁盘顺序写实现的。
读取数据:主要依靠零拷贝技术实现的。
非零拷贝:数据从生产者到消费者会经历两次数据拷贝,一次是从OS Cache里拷 贝到Kafka进程的缓存里,接着又从Kafka进程的缓存里拷贝回OS的Socket缓存里。中间会发生了好几次上下文切换,所以这种方式来读取数据是比较消耗性能的。
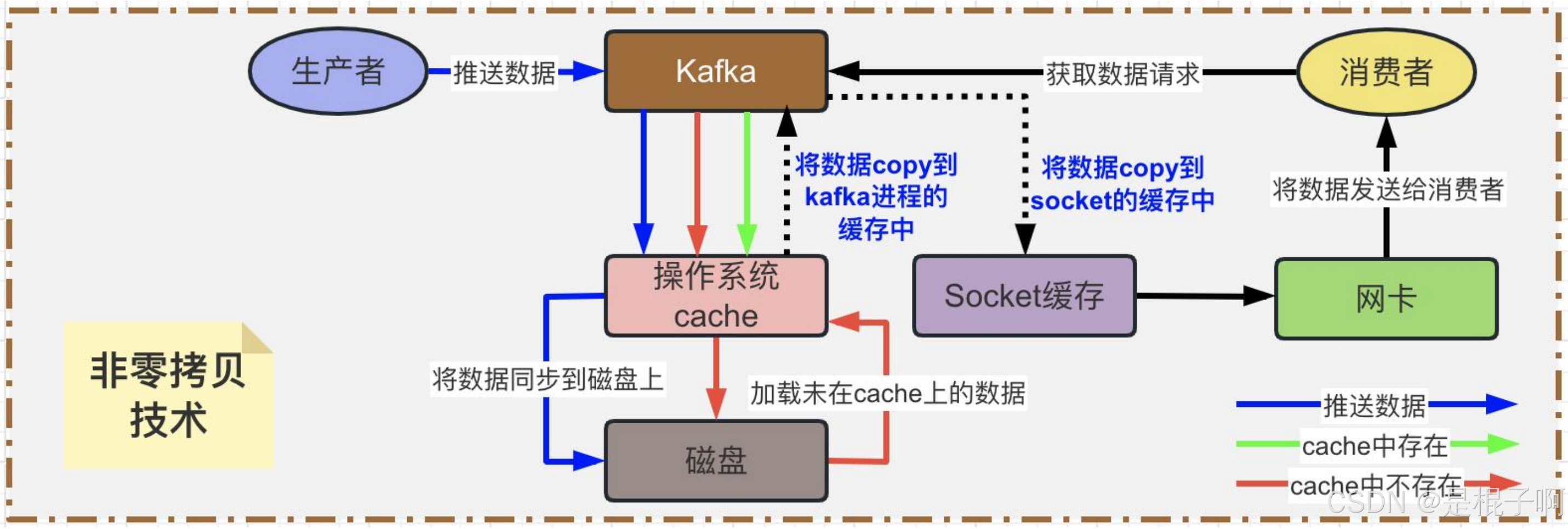
零拷贝:通过 OS的sendfile技术直接让OS Cache中的数据发送到网卡后传输给下游的消费者,中间跳过了两次拷贝数据的步骤.
