Redis
主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
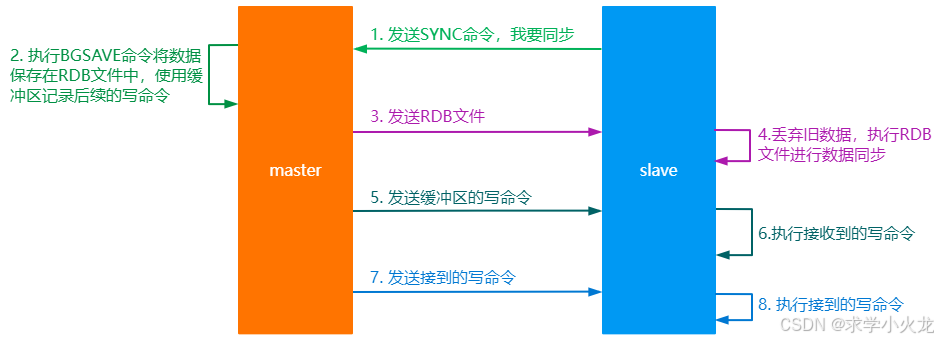
主从复制原理:
从节点发送SYNC命令到主节点,主节点开启一个缓存池,同时执行BGSAVE命令将自己的数据存储到RDB文件中,主节点创建和发送RDB文件给从节点的过程中如果有新的写操作数据则将数据存储在缓存池中,当发送文件完毕后利用缓存池中的数据进行更新。
从节点拿到新的数据后丢弃旧数据,利用得到的文件进行数据同步,同时主节点会将缓存池中的数据发给从节点,从节点进行数据更新。
主节点每执行一个写命令就会向从节点发送相同的写命令,从节点接收并执行收到的写命令。
主从复制的优缺点:
优点:
1.读写分离,从节点可以为客户端提供只读的服务,而写服务仍然由主节点完成,这样就分担了主节点收到请求的压力。
2.从节点也可以作为其他节点的主节点,分担请求压力。
3.在主从复制的过程中由于利用了缓存池,因此是非阻塞的,不会影响请求的处理。
缺点:
1.容错率较低,如果主机或者从机宕机,就会导致部分请求无法处理。
2.扩容较难。
主从复制搭建:
这里采用伪集群(在一台电脑上实现集群)
注意:集群搭建不能将Redis存放在C盘,因为C盘创建文件需要权限。如果已经安装在C盘,那么只需要将整个Redis文件拷贝至其他盘即可。
-
编辑redis.windows.conf文件,将其中的bind 121.199.174.183 修改为 bind 本机IP地址。例如:10.7.183.61
如果是每个redis服务器都是独立的文件夹,那么appendfilename属性可以不用设置。
bind 10.7.183.61 #这个是本机IP # appendfilename "appendonly6379.aof" -
拷贝redis文件夹三份,放到另外的一个文件夹内,作为三个从节点文件。
-
修改每一个从节点文件中的redis.windows.conf 文件,修改内容如下:
port 6380 slaveof 10.7.183.61 6379 masterauth 123456 #如果master有设置密码,必须添加到这里。没有设置,可以不用配置这项port 6381 slaveof 10.7.183.61 6379 masterauth 123456 #如果master有设置密码,必须添加到这里。没有设置,可以不用配置这项port 6382 slaveof 10.7.183.61 6379 masterauth 123456 #如果master有设置密码,必须添加到这里。没有设置,可以不用配置这项除此之外,还需要都把ip地址改为本机地址
bind 10.7.183.61 -
在三个文件夹中分别启动Redis,主从复制搭建完成
redis-server.exe redis.windows.conf
Jedis 连接 Redis 主从复制集群
redis.clients.jedis.exceptions.JedisDataException: NOAUTH Authentication required.
出现这个错误表示没有设置jedis连接的密码
public static void main(String[] args) {
Jedis master = new Jedis("10.7.183.61", 6379);
master.auth("123456");
Jedis slave1 = new Jedis("10.7.183.61", 6380);
slave1.auth("123456");
// Jedis slave2 = new Jedis("10.7.183.61", 6381);
// slave2.auth("123456");
// Jedis slave3 = new Jedis("10.7.183.61", 6382);
// slave3.auth("123456");
slave1.slaveof("10.7.183.61", 6379);
// slave2.slaveof("10.7.183.61", 6379);
// slave3.slaveof("10.7.183.61", 6379);
master.set("name", "张三");
System.out.println(slave1.get("name"));
// System.out.println(slave2.get("name"));
// System.out.println(slave3.get("name"));
}
}
哨兵模式
在主从复制中如果存在节点宕机则会丢失请求,对此产生了哨兵模式,即增加了哨兵节点用于监听主从节点,如果发现主节点挂掉则安排从节点顶上。
哨兵模式一般需要一个主节点,三个从节点和三个哨兵节点,即一主三从三哨兵。
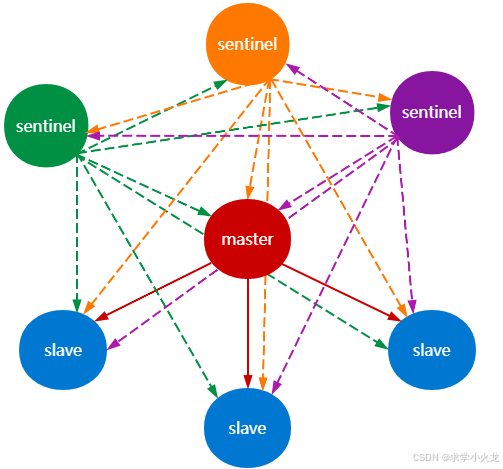
哨兵的工作方式:
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为**主观下线(**SDOWN)
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值,一般为超过半数)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
- 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
- 若有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线,监视该服务的所有sentinel(哨兵)将进行协商,并选出一个领头的sentinel(哨兵),然后对Master 主服务器进行故障转移操作:
- 从所有Slave从服务器里面挑选一个Slave从服务器,将其转成主服务器,领头Sentinel(哨兵)向被选出从服务器(新主)发送SLAVEOF no one命令,以每秒一次的频率向被升级的从服务器发送INFO命令,观察回复的角色信息,直到Slave从服务器变成Master主服务器。
- 之前下线的Master主服务器下的所有Slave从服务器改为复制新的Master主服务器
- 将之前下线的Master主服务器改为新的Master主服务器下的Slave从服务器
哨兵模式的优缺点:
优点:
1.哨兵模式基于主从模式,因此具有主从模式的优点。
2.实现了主从的切换,解决了主节点宕机问题,实现了高可用。
缺点:
仍然难以扩容。
哨兵模式的搭建:
bind 10.7.183.61 #本机ip
port 6404
# Sentinel去监视一个名为master的主redis实例,
# 这个主实例的IP地址为本机地址10.7.183.61,端口号为6379,
# 而将这个主实例判断为失效至少需要2个Sentinel进程的同意,只要同意Sentinel的数量不达标,自动failover就不会执行
sentinel monitor master 10.7.183.61 6379 2
# down-after-milliseconds指定了Sentinel认为Redis实例已经失效所需的毫秒数。
# 当实例超过该时间没有返回PING,或者直接返回错误,那么Sentinel将这个实例标记为主观下线。
# 只有一个Sentinel进程将实例标记为主观下线并不一定会引起实例的自动故障迁移:只有在足够数量的Sentinel都将一
# 个实例标记为主观下线之后,实例才会被标记为客观下线。这时自动故障迁移才会执行
sentinel down-after-milliseconds master 5000
# parallel-syncs指定了在执行故障转移时,最多可以有多少个从Redis实例在同步新的主实例,
# 在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长
sentinel parallel-syncs master 1
# 如果在failover-timeout该时间(ms)内未能完成故障迁移(failover)操作,则认为该failover失败
sentinel failover-timeout master 15000
sentinel auth-pass master 123456
注意:注意:哨兵设置密码后,创建连接池的时候需要指定哨兵的密码。如果没有设置,那么创建连接池的时候可以不需要使用密码。但是spring-boot对redis不支持哨兵设置密码。
注意bug:哨兵的文件夹名字中不能有“-”,应该为“_”,否则会出错。
启动顺序:Master->Slave->Sentinel
Jedis 连接 Redis 哨兵
@Test
public void redisSentinelTest(){
Set<String> sentinels = new HashSet<>();
//只需要配置哨兵的服务器信息即可
sentinels.add(new HostAndPort("10.7.183.61", 6404).toString());
sentinels.add(new HostAndPort("10.7.183.61", 6405).toString());
sentinels.add(new HostAndPort("10.7.183.61", 6406).toString());
JedisSentinelPool pool = new JedisSentinelPool("master", sentinels, "123456");
Jedis jedis = pool.getResource();
jedis.select(1);
String result = jedis.set("success", "OK");
System.out.println(result);
jedis.close();
pool.close();
}
Redis集群-Redis Cluster
集群介绍
为了解决哨兵模式难以扩容的问题,出现了Redis Cluster,假设一个master节点的内存只有4G,那slave节点所能存储的数据最多也是4G,虽然可以增加slave节点来增加读的并发能力,但是由于写操作只能通过master节点实现,所以写和存储能力无法进行扩展,这就是难以扩容的原因。
Redis从3.0开始支持集群功能,所谓集群就是功能不同的多个部分组合到一起完成总的功能。所以Redis集群使用多组主从节点,每一组主从节点负责的数据不同,这样所能写和存储的数据量就是多组主节点的总和。(官方要求至少要三主三从)
Redis集群采用的是无中心节点的方式,也就是多组主从节点之间是平级关系,没有中心的一组,由于Redis拥有16个库,每个库中拥有1024个slot(槽位)用于存储数据,因此总共有16384(16*1024)个槽位,Redis集群将这些槽位分布到多组主从节点的主节点中,每个主节点只负责自己分到的槽位的请求处理(读+写),而从节点则负责在主节点宕机的时候顶上去,这样就实现了高可用的同时还能解决大量数据的问题。
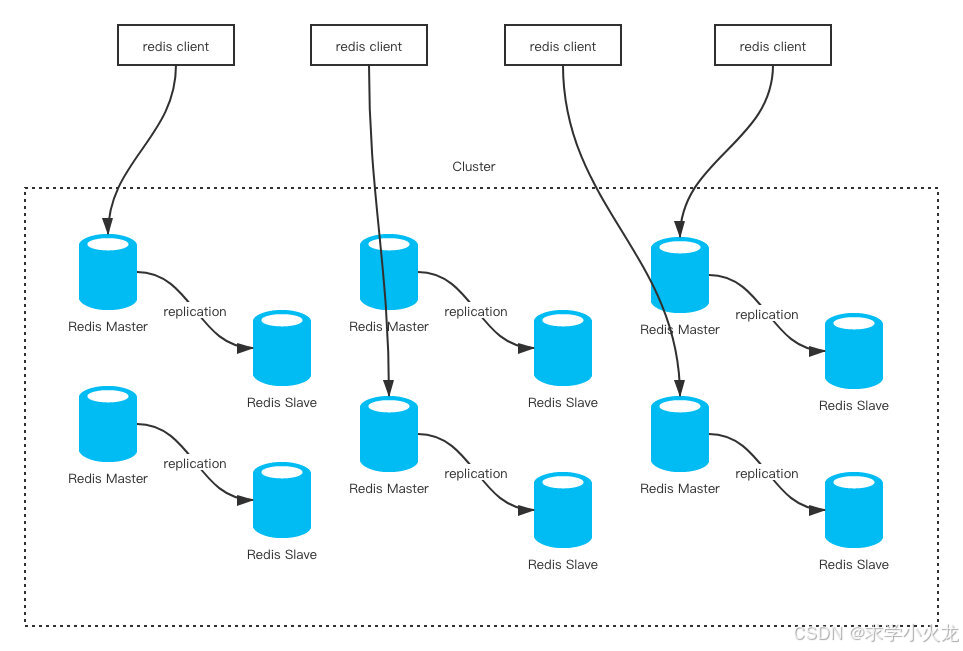
具体来说,当接受到一个请求时,会对请求的键利用“CRC16(key) % 16384”的算法
计算出这个请求的数据应该由哪一个节点分管,客户端在访问时只需要访问一个节点,这个节点计算出数据的slot后如果是自己分管则执行请求,如果不是则返回MOVED错误并告诉客户端应该访问哪一个节点。
数据迁移
之前提到主从复制和哨兵模式存储的最大容量只取决于主从节点中容量最小的一个节点,所以难以在线扩容。而Cluster集群由于最大容量是多个主节点的容量之和,所以在线扩容无非就是增加一组主从节点。那么增加了主从节点后Redis是如何分配数据的呢?
Redis并不是重新分配,因为在线扩容就代表不能影响其他节点,如果重新分配那么所有节点的槽位可能都要改动,而最好的情况是尽可能少地改变槽位,所以Redis数据迁移的思想为每一个主节点将自己负责的一部分槽位迁移给新的主节点,所以扩容后会出现槽位分配不是连续的情况,但是只要能够涵盖所有的槽位,是不是连续并不重要。
如果在分配的过程中有请求要访问即将转移的槽位信息怎么办? - 节点会返回ASK错误:如果访问的时候节点还没有迁移则直接执行,如果已经迁移则会返回ASK错误,这个错误会附上迁移目的节点信息,客户端向目的节点发送ASKING命令以执行之前的请求命令。
Redis Cluster搭建(windows)
-
复制Redis文件夹,创建新的六个文件夹作为集群的三组主从节点。
-
对于每一个文件夹修改其redis.windows.conf文件:
bind 10.7.183.61 #本机ip
daemonize yes
port 6410 #分别对每个机器的端口号进行设置
cluster-enabled yes #启动集群模式
cluster-config-file nodes-6410.conf #集群节点信息文件,这里 6410 和port对应上
cluster-node-timeout 5000
protected-mode no #关闭保护模式
#如果要设置密码需要增加如下配置:
requirepass 123456 #设置redis访问密码
masterauth 123456 #设置集群节点间访问密码,跟上面一致
- 启动每个节点redis服务
redis-server.exe redis.windows.conf
- 执行创建集群命令
#代表为每个创建的主服务器节点创建一个从服务器节点 -a表示访问密码 设置了密码需要使用-a --cluster-replicas 1表示一个主节点有一个从节点
redis-cli -a 123456 --cluster create --cluster-replicas 1 10.7.183.61:6410 10.7.183.61:6411 10.7.183.61:6412 10.7.183.61:6413 10.7.183.61:6414 10.7.183.61:6415
# 未设置密码
redis-cli --cluster create --cluster-replicas 1 10.7.183.61:6410 10.7.183.61:6411 10.7.183.61:6412 10.7.183.61:6413 10.7.183.61:6414 10.7.183.61:6415
启动后可以看到每一个主节点所负责的槽位信息。
Jedis操作Redis Cluster
public static void main(String[] args) throws IOException {
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("10.7.183.61",6410));
nodes.add(new HostAndPort("10.7.183.61",6411));
nodes.add(new HostAndPort("10.7.183.61",6412));
nodes.add(new HostAndPort("10.7.183.61",6413));
nodes.add(new HostAndPort("10.7.183.61",6414));
nodes.add(new HostAndPort("10.7.183.61",6415));
JedisCluster cluster = new JedisCluster(nodes, 5, 0, 3, "123456", new GenericObjectPoolConfig());
cluster.set("class","java");
String res = cluster.get("class");
System.out.println(res);
int slot = JedisClusterCRC16.getCRC16("class");//查看这个key存放在哪个slot
System.out.println(slot);
System.out.println(slot%16384);
cluster.close();
//去对应的节点查看是否有数据
Jedis jedis = new Jedis("10.7.183.61", 6411);
jedis.auth("123456");
System.out.println(jedis.get("class"));
}
RedisTemplate模板类
在Java中与Redis进行交互通信有两种工具,一种就是之前使用的Jedis,一种是Lettuce。
Jedis中的命令简单直接,和Redis客户端中的命令一致,易上手。但是Jedis是线程不安全的,往往需要使用连接池,且不支持异步和响应式编程模型,不支持高并发的环境。
所以一般使用Lettuce的较多,Lettuce线程安全无需使用连接池,而且支持异步和响应式编程。要使用Lettuce又一般在springboot项目下采用spring框架提供的模板类RedisTemplate,这是Spring Data Redis 提供的一个用于简化和Redis交互的模板类。
依赖:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
</parent>
<!--springboot提供的与redis整合包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jdk8</artifactId>
</dependency>
<!--支持redis存储的时候将jdk8提供的新的时间类存储进去-->
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
要使用Cluster集群,需要在application.yml中进行配置:
spring:
redis:
cluster:
nodes:
- 10.7.183.61:6410
- 10.7.183.61:6411
- 10.7.183.61:6412
- 10.7.183.61:6413
- 10.7.183.61:6414
- 10.7.183.61:6415
password: 123456
配置类:
spring data 提供的整合包在使用的时候,核心类都是XxxTemplate,这里整合的redis核心类就是RedisTemplate.
配置的内容为设置连接工厂,设置序列化和反序列化。其中序列化和反序列化又需要设置对象映射器。
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory factory){
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);//设置RedisTemplate使用的连接工厂
ObjectMapper mapper = new ObjectMapper();//对象映射器,因为要把对象转换为JSON格式
mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL,JsonTypeInfo.As.PROPERTY);
//对象映射器配置哪些属性可见:PropertyAccessor.ALL表示所有的属性都可以转换成JSON格式
//Visibility.ANY表示类中定义的属性使用任何访问修饰符都可以
mapper.setVisibility(PropertyAccessor.ALL,JsonAutoDetect.Visibility.ANY);
mapper.registerModule(new JavaTimeModule());
//支持JDK8相关处理
mapper.registerModule(new Jdk8Module());
//支持存储地理位置
mapper.registerModule(new GeoModule());
GenericJackson2JsonRedisSerializer valueSerializer = new GenericJackson2JsonRedisSerializer(mapper);
StringRedisSerializer keySerializer = new StringRedisSerializer();
template.setKeySerializer(keySerializer);
template.setValueSerializer(valueSerializer);
template.setHashKeySerializer(keySerializer);
template.setHashValueSerializer(valueSerializer);
return template;
}
RedisTemplate操作:
操作:
@Test
public void setTest(){
//RedisTemplate支持对Redis中的所有数据类型的操作,但是需要根据提供的方法来获取对应类型的数据
ValueOperations<String, Object> valueOperations = redisTemplate.opsForValue();
HashOperations<String, Object, Object> hashOperations = redisTemplate.opsForHash();
ListOperations<String, Object> listOperations = redisTemplate.opsForList();
SetOperations<String, Object> setOperations = redisTemplate.opsForSet();
ZSetOperations<String, Object> zSetOperations = redisTemplate.opsForZSet();
valueOperations.set("spring-boot-data-redis", Arrays.asList(1,2,3,4,5,6));
Object o = valueOperations.get("spring-boot-data-redis");
System.out.println(o);
}
由上可知,RedisTemplate支持值类型为Object。
由于RedisTemplate类的方法在操作和Redis命令不一样,比较繁琐,所以在操作之前建议设置一个类用来包装命令,将命令简化为和Redis命令一致的方法
package com.qf.redis;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ZSetOperations;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@Component //这个注解的作用就是为当前类创建一个实例放入IOC容器
public class RedisService {
@Autowired
private RedisTemplate<String,Object> redisTemplate;
public void set(String key, Object value){
redisTemplate.opsForValue().set(key, value);
}
public void set(String key, Object value, long expire, TimeUnit unit){
redisTemplate.opsForValue().set(key, value, expire, unit);
}
public void setNx(String key, Object value, long expire, TimeUnit unit){
redisTemplate.opsForValue().setIfAbsent(key, value, expire, unit);
}
public Object get(String key){
return redisTemplate.opsForValue().get(key);
}
public void hset(String key, String field, Object value){
redisTemplate.opsForHash().put(key, field, value);
}
public void hmset(String key, Map<String, Object> fieldValues){
redisTemplate.opsForHash().putAll(key, fieldValues);
}
public Object hget(String key, String field){
return redisTemplate.opsForHash().get(key, field);
}
public Map<Object, Object> hgetAll(String key){
return redisTemplate.opsForHash().entries(key);
}
public boolean hexists(String key, String field){
return redisTemplate.opsForHash().hasKey(key, field);
}
public void hdelete(String key, String... fields){
redisTemplate.opsForHash().delete(key, fields);
}
public void lpush(String key, Object value){
redisTemplate.opsForList().leftPush(key, value);
}
public void rpush(String key, Object value){
redisTemplate.opsForList().rightPush(key, value);
}
public Object lpop(String key){
return redisTemplate.opsForList().leftPop(key);
}
public Object rpop(String key){
return redisTemplate.opsForList().rightPop(key);
}
public List<Object> range(String key, long start, long end){
return redisTemplate.opsForList().range(key, start, end);
}
public void sadd(String key, Object... values){
redisTemplate.opsForSet().add(key, values);
}
public boolean sIsMember(String key, Object value){
return Boolean.TRUE.equals(redisTemplate.opsForSet().isMember(key, value));
}
public Set<Object> sinter(String key, String... otherKeys){
return redisTemplate.opsForSet().intersect(key, Arrays.asList(otherKeys));
}
public Set<Object> sunion(String key, String... otherKeys){
return redisTemplate.opsForSet().union(key, Arrays.asList(otherKeys));
}
public Set<Object> sdiff(String key, String... otherKeys){
return redisTemplate.opsForSet().difference(key, Arrays.asList(otherKeys));
}
public void zadd(String key, Object value, double score){
redisTemplate.opsForZSet().add(key, value, score);
}
public void zrem(String key, Object... values){
redisTemplate.opsForZSet().remove(key, values);
}
public Long zcard(String key){
return redisTemplate.opsForZSet().zCard(key);
}
public Set<Object> zrange(String key, long start, long end){
return redisTemplate.opsForZSet().range(key, start, end);
}
public Set<Object> zRevRange(String key, long start, long end){
return redisTemplate.opsForZSet().reverseRange(key, start, end);
}
public Set<Object> zRangeByScore(String key, double min, double max){
return redisTemplate.opsForZSet().rangeByScore(key, min, max);
}
public Set<Object> zRevRangeByScore(String key, double min, double max){
return redisTemplate.opsForZSet().reverseRangeByScore(key, min, max);
}
public Set<ZSetOperations.TypedTuple<Object>> zRangeByScoreWithScore(String key, double min, double max){
return redisTemplate.opsForZSet().rangeByScoreWithScores(key, min, max);
}
public Set<ZSetOperations.TypedTuple<Object>> zRevRangeByScoreWithScore(String key, double min, double max){
return redisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, min, max);
}
}
简化后的操作:
@Test
public void redisServiceTest(){
redisService.hset("actor","name","周星星");
redisService.hset("actor","age","24");
Map<Object, Object> actor = redisService.hgetAll("actor");
System.out.println(actor);
}
RedisTemplate扫描操作:
全局键扫描方式一:
RedisSerializer<String> keySerializer = (RedisSerializer<String>) redisTemplate.getKeySerializer();
List<String> results = redisTemplate.execute(new RedisCallback<List<String>>() {
@Override
public List<String> doInRedis(RedisConnection redisConnection) throws DataAccessException {
List<String> keys = new ArrayList<>();
ScanOptions options = new ScanOptions.ScanOptionsBuilder().count(5).match("*a*").build();//扫描含有a的数据,每次扫描5条左右的数据
Cursor<byte[]> cursor = redisConnection.scan(options);
while (cursor.hasNext()){
byte[] next = cursor.next();
keys.add(keySerializer.deserialize(next));
}
try {
cursor.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
return keys;
}
});
全局键扫描方式二:
/**
* 全局扫描
*/
@Test
public void scanKeys() {
List<String> keys = new ArrayList<>();
RedisConnection redisConnection = redisTemplate.getConnectionFactory().getConnection();
Cursor<byte[]> cursor = redisConnection.scan(ScanOptions.scanOptions().match("*a*").count(1000).build());
while (cursor.hasNext()) {
keys.add(new String(cursor.next()));
}
System.out.println(keys);
}
hash扫描(键+值):
/**
* hash键扫描
*/
@Test
public void hScanTest() {
//这里必须使用RedisTemplate来存储数据,如果直接在Redis客户端中存储而利用RedisTemplate扫描就会出错
//因为RedisTemplate存储字符串时会将数据转换为JSON格式,扫描必须扫描JSON格式数据
redisService.hset("hash","abc","american");
Cursor<Map.Entry<Object, Object>> cursor = redisTemplate.opsForHash().scan("hash", ScanOptions.scanOptions().match("*").count(10).build());
while (cursor.hasNext()) {
Map.Entry<Object, Object> next = cursor.next();
System.out.println(next.getKey() + ":" + next.getValue());
}
}
分布式锁
redis使用场景最多的是作为缓存,即在客户端和mysql数据库中作为缓存层,这样当客户端发送请求的时候会先在Redis中查询,如果没有数据再向mysql发送请求,这样就分担了mysql的压力。
缓存击穿
由于数据在Redis中是以缓存的形式存储,所以存储的键都应该有一个过期时间,当过期时间到后就会消失,避免了无休止地增加数据。因此当一个键承担着高并发的请求时,如果这个键的过期时间到了,Redis中删除了这个键,那么大量的并发的请求就会涌入Mysql数据库,造成mysql的高负担,这就是缓存击穿。
解决方案:
由于缓存击穿是由于大量的请求涌入mysql数据库,所以可以给这些请求加上一个互斥锁,只允许一个线程去完成请求任务,而其他的线程则等待。
缓存雪崩
和缓存击穿类似,当大量的key同时到达过期时间时,缓存中失去了这些key,所以大量请求又涌入了mysql数据库。
解决方案:
避免大量的key同时到达过期时间,可以给key加一个随机数,随机数的时间单位需要精确到至少毫秒以上,这样就可以解决同时过期的问题。
缓存穿透
缓存穿透和缓存击穿与缓存雪崩不一样,缓存穿透一般是由于恶意的攻击。具体来说,缓存穿透是指大量的请求查询数据库中不存在的数据而引起的,因为mysql中不存在数据,因而Redis缓存中也不会留下数据,所以就会一直穿过缓存查询到mysql,造成大量的负担。
解决方案:
有两种解决方案:
一种是即使没有从mysql中查询到数据,也在Redis缓存中添加key,值设为null或者空字符串,这样再次查询时就不会通过。
Redistemplate扫描
第二种是使用布隆过滤器,布隆过滤器原理类似于hashmap。在hashmap中当key的hash值相同时将会把数据存储在hashmap的一个位置的hash桶中。布隆过滤器也是这样,如果key相同则会放在一个区域的一个子区域里,当请求的key属于的区域存在值时说明mysql数据库中有数据则放行,当请求key属于的区域的子区域没有值时说明mysql数据库中没有数据则不放行。
对于其中的缓存击穿的情况需要加上互斥锁,但是syncronize和lock都只能锁住单节点内的请求,不能锁住其他节点的,在分布式的情况下无法完成请求互斥的效果,所以需要使用分布式锁。
分布式锁
分布式锁的实现有两种方案,一种是zookeeper实现的分布式锁,一种是Redis实现的分布式锁,这里只介绍Redis的分布式锁。
Redis分布式锁实现思想就是不在节点中设置锁,因为只能锁住JVM,而改为在Redis中利用key来设置,这样即使分布式服务器有多个,但是key在Redis中只有一个,达到互斥的效果。
其实现原理为在Redis中添加一个具有过期时间的key,如果添加成功则说明成功获取分布式锁;如果添加失败则说明key还没有过期,正在被其他节点使用,然后在一段时间内不断重复地尝试获取锁。拿到锁后执行相关业务,业务执行完成后删除这个key,即释放锁。
从Redis分布式锁的实现原理中可以发现两个问题:
如果在一个节点拿到锁的时候,由于自身业务执行时间过长,导致业务还没执行完毕,锁的过期时间就到了怎么办?
Redis提供了Redisson来解决,Redisson中有一个功能为 watch dog(看门狗),看门狗会查看被锁住的节点,如果节点的业务还没执行完毕但是过期时间却到了一定程度(一般定义为所剩时间为总过期时间的1/3),那么将会对该节点执行续约,即延迟过期时间。
看门狗的实现原理是使用计时器延迟调度任务实现的,主要用的是Timer和TimerTask。
如果持有锁的节点在业务逻辑执行过程中崩溃,锁没有被删除。 那么当另外一个节点拿到这个锁的时候,还没执行完业务,但是之前的节点恢复了,将锁进行删除怎么办?
由于节点拿到的是之前的锁,看门狗一直按照之前节点设置的过期时间进行锁的续约怎么办?
锁的删除(释放)分为两种,一种是由于过期时间到了,Redis中自动把key删除了,一种是手动进行删除,一般是由于业务执行完了,所以手动将锁释放。
1.键手动删除的问题,可以在加锁(设置键)的时候设置其值为当前线程的ID(保证唯一),在删除的时候先检查这个ID是否是当前线程的ID,如果是则说明这个锁是由当前线程获取的,那么就可以进行删除释放,如果不是就说明不是当前线程获取的锁,就不进行删除操作。
2.键自动删除的问题,即下一个节点由于获取的是上一个节点的锁,因此看门狗可能会延长上一个节点的锁的时间,这样就会扰乱锁的逻辑,所以不仅在加锁的时候给锁的值设置唯一标识,看门狗也需要唯一标识,如果当前ID为锁的ID才延长续约。
Redis分布式锁的实现(手写实现Redis分布式锁)
思路:
参数:用户指定锁的键,获取锁的等待时间(一个节点如果在这个时间内没有成功获取锁则放弃获取,不执行请求),锁的过期时间,过期时间单位,业务执行方法。
当获取锁的时间没有结束时不断尝试获取锁,锁的实现为通过lua脚本设置不存在的键值及其过期时间,其中键的值必须唯一,所以利用当前线程的id作为值,如果成功获取锁则继续加上看门狗,即通过timer类和timertask类中利用lua脚本实现判断锁的键值是否是当前线程id,如果是则延长过期时间。并设置看门狗的实现延长时间和执行的时间间隔。
然后是业务的执行,执行完毕后再次利用lua脚本设置锁的释放,即判断id+删除键。
如果没有获取锁则每隔一段获取锁的等待时间就再次尝试获取。
lua脚本:
锁的操作需要满足原子性,如果在锁的操作过程中节点挂掉,则这个锁就可能变成死锁,所以需要让锁操作实现要么成功要么回滚,这就需要利用lua脚本来实现。
lua脚本中的判断语法: if…then … else …end
-
lua脚本对redis的支持语法:redis.call(), 比如redis.call(‘set’, ‘username’, ‘zhansgan’)
-
lua脚本对于redis中使用的参数有规定:对于key使用的参数要使用KEYS[位置],对于value使用的参数要
//使用ARGV[位置],比如 redis.call(‘SET’, KEYS[1], ARGV[1])
自定义业务:
业务执行为自定义接口,由用户自己重写,这样实现业务直接调用方法即可
public interface WorkBusiness {
void work();
}
手写Redis分布式锁
/**
* 手写实现分布式锁
* @param lockKey 锁的键
* @param waitTime 等待锁的时间
* @param expireTime 锁的过期时间
* @param unit 过期时间单位
* @param work 自定义业务执行
*/
public void tryLock(String lockKey, long waitTime, long expireTime, TimeUnit unit, WorkBusiness work){
long currentTime = System.currentTimeMillis();
long endTime = currentTime + waitTime;
long expireMillis = unit.toMillis(expireTime);
while (System.currentTimeMillis()<=endTime){
//设置的获取锁时间没有过期时不断地尝试获取锁
String luaScript = "if redis.call('exists' KEYS[1]) ==0 then redis.call('set' KEYS[1] ARGV[1] 'px' ARGV[2]);return 1; else return 0; end";
RedisScript<Integer> script = new DefaultRedisScript<>(luaScript,Integer.class);
long lockValue = Thread.currentThread().getId();
Integer result = redisTemplate.execute(script, Collections.singletonList(lockKey), Arrays.asList(lockValue, expireMillis));
if(result!=null && result==1){
//成功拿到锁
//设置看门狗
Timer timer = new Timer();
TimerTask task = new TimerTask() {
@Override
public void run() {
//如果当前键和当前线程id匹配则启用续约
String luaScript = "if redis.call('get' KEYS[1]) == ARGV[1] then return redis.call('pexpire' KEYS[1] ARGV[2]) else return 0; end";
DefaultRedisScript<Integer> script = new DefaultRedisScript<>(luaScript, Integer.class);
Integer result = redisTemplate.execute(script, Collections.singletonList(lockKey), Arrays.asList(lockValue, expireTime));
if(result!=null && result==1){
//看门狗设置成功
System.out.println("续约成功");
}
}
};
long period = 2 * expireMillis/3;
timer.schedule(task,period,period);//两个period分别代表延迟执行时间和执行时间间隔
work.work();//执行业务
//释放锁
luaScript = "if redis.call('get' KEYS[1]) == ARGV[1] then return redis.call('del' KEYS[1]) else return 0; end";
script= new DefaultRedisScript<>(luaScript, Integer.class);
Integer delSesult = redisTemplate.execute(script, Collections.singletonList(lockKey), Collections.singletonList(lockValue));
if(delSesult!=null && delSesult==1){
System.out.println("释放锁成功");
}
break;
}
}
try {
Thread.sleep(100);//获取锁间隔
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}