一、实验目的
1.掌握基于决策树和随机森林构建鸢尾花种类预测模型的步骤
2.理解决策树算法的原理
3.理解决策树算法的主要参数(剪枝参数)
4.掌握集成算法的使用
5.掌握树模型可视化方法
二、代码及结果
0.加载查看数据集
# sklearn库中已有鸢尾花数据集,可以直接调用
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import display
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import export_graphviz
import graphviz # 安装见 http://t.csdnimg.cn/slBMD
iris = load_iris() # 准备数据集
features = iris.data # 获取特征集
labels = iris.target # 获取目标集
# 将鸢尾花特征与数据添加在一起
iris_dataset = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_dataset['label'] = iris.target
print(iris_dataset.head())
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=0) # 数据拆分
print(X_train.shape, X_test.shape) # 查看拆分结果
1.根据notebook提示实验,sklearn中与决策树分类有关的函数是DecisionTreeClassifier函数,本次实验主要使用DecisionTreeClassifier,集成学习由RandomForestRegressor函数指定若干棵决策树。使用这两种函数默认参数补全代码。
代码:
'''
sklearn中与决策树有关的函数有DecisionTreeRegressor和DecisionTreeClassifier,前者是决策树回归函数后者是决策树分类函数,参数略有不同,
DecisionTreeRegressor中特征选择标准criterion可以选择squared_error代表均方差,absolute_error代表和均值之差的绝对值之和。一般来说默认参数
squared_error更精确。
本实验采用DecisionTreeClassifier,参数criterion可以选择gini代表基尼系数即CART算法,值越小代表分类的纯度越高;entropy代表
信息增益。为了提高精度,可以使用几十棵决策树集成为随机森林RandomForestRegressor。
1、DecisionTreeClassifier;2、RandomForestRegressor
分别使用不同的决策树类别进行实验。
'''
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor
DTC = DecisionTreeClassifier().fit(X_train,y_train)
RFR = RandomForestRegressor().fit(X_train,y_train)
print('---------------\t默认参数决策树分类\t---------------')
# 评估模型(分类模型输出准确率,回归模型输出R2_score)
print('test_score---------:', DTC.score(X_test, y_test))
# 预测测试集中的鸢尾花种类
y_pred_DTC = DTC.predict(X_test)
n = 10 # 显示前n个样本的预测类别
print('预测种类:', np.round(y_pred_DTC[:n])) # np.round()-四舍五入取整
print('实际种类:', y_test[:n])
print('---------------\t默认参数随机森林\t---------------')
# 评估模型(分类模型输出准确率,回归模型输出R2_score)
print('test_score:', RFR.score(X_test, y_test))
# 预测测试集中的鸢尾花种类
y_pred_RFR = RFR.predict(X_test)
n = 10 # 显示前n个样本的预测类别
print('预测种类:', np.round(y_pred_RFR[:n]))
print('实际种类:', y_test[:n])
运行结果:

2.根据实验提示对不同函数的参数进行调参,即指定是使用哪种决策树算法。使用criterion=“entropy”(信息熵)、criterion=”gini”(CART算法),同时修改max_depth的值分选择2和5进行实验。以及使用20棵和50棵决策树的随机森林进行实验。并按照实验要求打印6种实验结果。
代码:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor
criterions = ["entropy","gini"]
splitters = ["best","random"]
max_depths = [2,5]
for c in criterions:
for s in splitters:
for d in max_depths:
DTC = DecisionTreeClassifier(criterion = c ,splitter = s, max_depth = d).fit(X_train,y_train)
print(f'---------------\t{c}-{s}-{d}决策树分类\t---------------')
# 评估模型(分类模型输出准确率,回归模型输出R2_score)
print('test_score:', DTC.score(X_test, y_test))
# 预测测试集中的鸢尾花种类
y_pred_DTC = DTC.predict(X_test)
n = 10 # 显示前n个样本的预测类别
print('预测种类:', np.round(y_pred_DTC[:n]))
print('实际种类:', y_test[:n])
n_estimator = [20,50]
for n in n_estimator:
RFR = RandomFor--------------------------------------------------------------estRegressor(n_estimators = n).fit(X_train,y_train)
print(f'---------------\tn_estimators = {n} 随机森林\t---------------')
# 评估模型(分类模型输出准确率,回归模型输出R2_score)
print('test_score:', RFR.score(X_test, y_test))
# 预测测试集中的鸢尾花种类
y_pred_RFR = RFR.predict(X_test)
n = 10 # 显示前n个样本的预测类别
print('预测种类:', np.round(y_pred_RFR[:n]))
print('实际种类:', y_test[:n])
运行结果:


- 使用标准化后的数据进行模型的训练,比较模型的性能。
代码:
from sklearn.preprocessing import StandardScaler
#标准化数据
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train)
X_test_scaler = scaler.transform(X_test)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor
criterions = ["entropy","gini"]
splitters = ["best","random"]
max_depths = [2,5]
for c in criterions:
for s in splitters:
for d in max_depths:
DTC = DecisionTreeClassifier(criterion = c ,splitter = s, max_depth = d).fit(X_train_scaler,y_train)
print(f'---------------\t{c}-{s}-{d}决策树分类\t---------------')
# 评估模型(分类模型输出准确率,回归模型输出R2_score)
print('test_score:', DTC.score(X_test_scaler, y_test))
# 预测测试集中的鸢尾花种类
y_pred_DTC = DTC.predict(X_test_scaler)
n = 10 # 显示前n个样本的预测类别
print('预测种类:', np.round(y_pred_DTC[:n]))
print('实际种类:', y_test[:n])
n_estimator = [20,50]
for n in n_estimator:
RFR = RandomForestRegressor(n_estimators = n).fit(X_train_scaler,y_train)
print(f'---------------\tn_estimators = {n} 随机森林\t---------------')
# 评估模型(分类模型输出准确率,回归模型输出R2_score)
print('test_score:', RFR.score(X_test_scaler, y_test))
# 预测测试集中的鸢尾花种类
y_pred_RFR = RFR.predict(X_test_scaler)
n = 10 # 显示前n个样本的预测类别
print('预测种类:', np.round(y_pred_RFR[:n]))
print('实际种类:', y_test[:n])
运行结果:

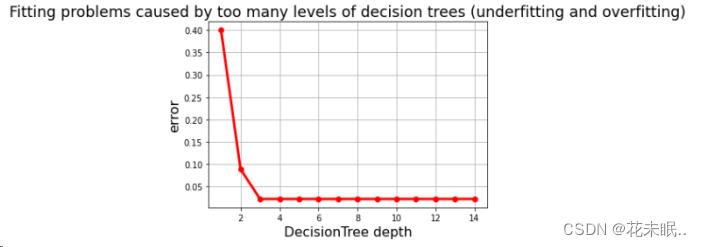
- 画图查看决策树深度和错误率之间的关系,观察是否存在过拟合现象:
代码:
depths = np.arange(1, 15)
err_list = []
for d in depths:
clf = DecisionTreeClassifier(criterion='entropy', max_depth=d)
clf.fit(X_train, y_train)
## 计算的是在训练集上的模型预测能力
score = clf.score(X_test, y_test)
err = 1 - score
err_list.append(err)
## 画图
plt.figure(facecolor='w')
plt.plot(depths, err_list, 'ro-', lw=3)
plt.xlabel(u'DecisionTree depth', fontsize=16)
plt.ylabel(u'error', fontsize=16)
plt.grid(True)
plt.title(u'Fitting problems caused by too many levels of decision trees (underfitting and overfitting)', fontsize=18)
plt.show()
运行结果:
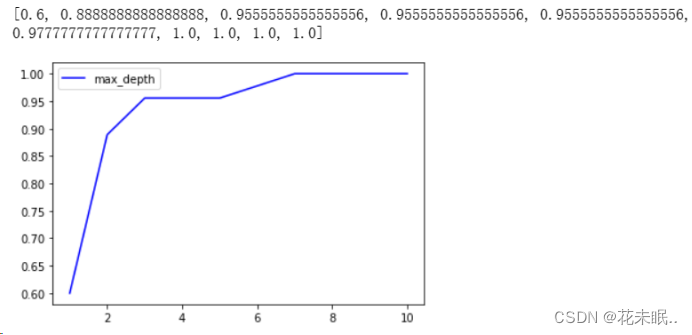
5.尝试不同的剪枝参数训练模型,对结果进行比较,画出准确率随深度的变化图:
(剪枝参数:max_depth:限制树的最多分层,适用于高维低量样本,分一层需要的样本就多一倍,一般从3开始试。与这个参数类似的还有:
min_samples_leaf: 一个节点分支后的子节点上至少包含多少的训练样本数量。
min_samples_split :一个节点上至少包含多少训练样本数量。)
代码:
test = []
for i in range(10):#0-9的循环
clf_test = DecisionTreeClassifier(
max_depth = i + 1
,criterion='gini'
,random_state=30
,splitter='random'
)
clf_test = clf_test.fit(X_train,y_train)
score_test = clf_test.score(X_test,y_test)
test.append(score_test)
print(test)
plt.plot(range(1,11),test,c='blue',label='max_depth')
plt.legend()#添加图例
plt.show()
运行结果:
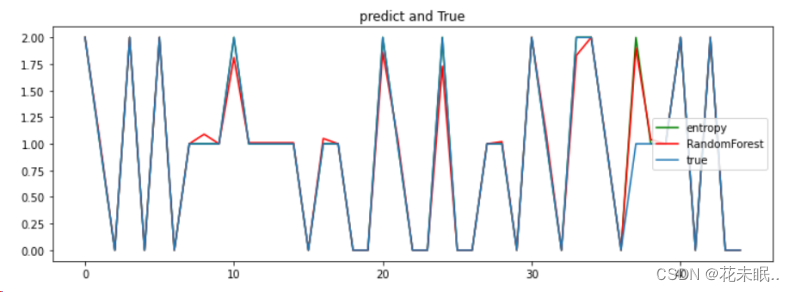
6.打印预测值和真实值之间的图像(一张图即可)。
代码:
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestRegressor
DTC = DecisionTreeClassifier(criterion = 'entropy').fit(X_train,y_train)
RFR = RandomForestRegressor().fit(X_train,y_train)
# 预测测试集中的鸢尾花种类
y_pred_DTC = DTC.predict(X_test)
# 预测测试集中的鸢尾花种类
y_pred_RFR = RFR.predict(X_test)
# 可视化预测曲线
plt.figure(figsize=(12, 4)) # 图像尺寸
plt.title('predict and True') # 标题
n = 45 # 图中显示样本的数量
plt.plot(np.arange(n), y_pred_DTC[:n], "g", label='entropy') # 预测值
plt.plot(np.arange(n), y_pred_RFR[:n], "r", label='RandomForest') # 预测值
plt.plot(np.arange(n), y_test[:n], label='true') # 实际值
plt.legend() # 显示图例
plt.show()
运行结果:
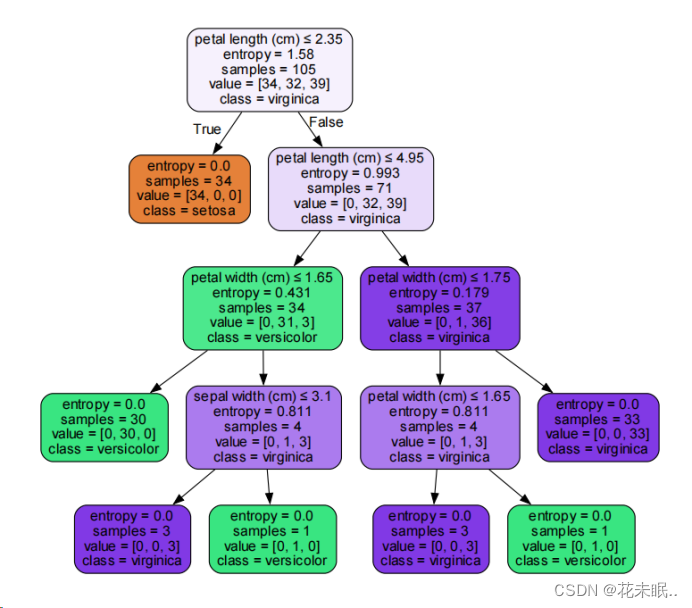
7.使用graphviz进行决策树的可视化(gini和entropy各一张)
代码:
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import graphviz
from sklearn.ensemble import RandomForestRegressor
# 创建gini系数、entropy两种分类模型
criterions = ["entropy","gini"]
for c in criterions:
DTC = DecisionTreeClassifier(criterion = c).fit(X_train,y_train)
dot_data = export_graphviz(DTC, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
# 生成 Source.gv.pdf 文件,并打开
pdf_file_path = f"{c}.gv.pdf"
graph.render(pdf_file_path, view=True,engine='dot')
运行结果:
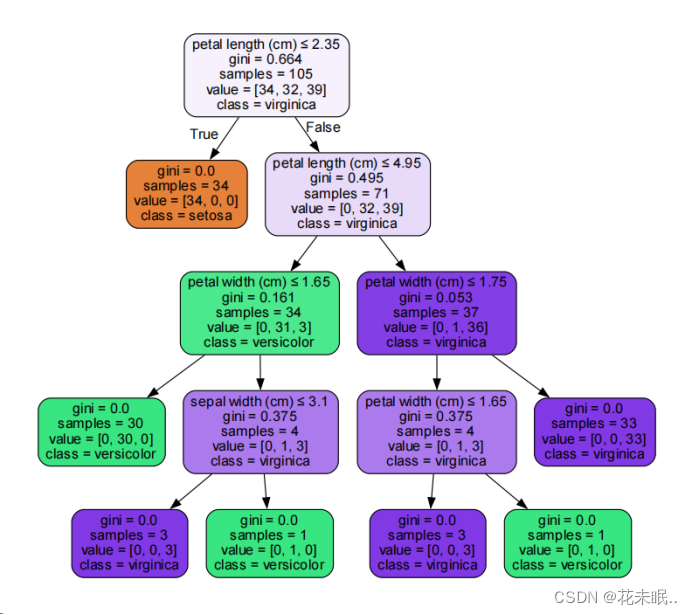
三、结果分析
1.默认参数下的模型效果比较:
决策树分类器默认参数下测试准确率约为 97.78%,而随机森林默认参数下测试准确率约为 96.67%。
预测结果显示前10个样本的种类,大部分预测值与实际值相符,但随机森林的预测结果包含浮点数。
2.不同参数组合下的模型效果比较:
通过不同的决策树参数(criterion、splitter、max_depth)和随机森林的n_estimators进行实验,发现不同参数组合下模型的测试准确率有所变化。
以信息熵(entropy)和基尼指数(gini)为划分标准,以及不同的剪枝深度和随机性分裂方式,测试准确率差异较大。
随机森林在不同树的数量下的测试准确率也有所不同,但整体表现较为稳定。
3.使用标准化数据进行训练:
对比标准化前后,模型的测试准确率略有不同。标准化后的数据可能对某些参数配置具有更好的表现,但对于其他参数可能无明显影响。
4.决策树深度和错误率关系:
通过绘制决策树深度与测试误差之间的关系图,可以看出随着决策树深度增加,模型测试误差的变化情况。这有助于观察模型是否存在过拟合或欠拟合问题。
四、实验总结
通过这些实验,可以更深入地理解决策树算法的原理,包括信息熵、基尼指数等划分标准。掌握决策树剪枝参数的调整方式,以及不同参数对模型性能的影响。
了解集成算法如随机森林的基本原理和参数配置方式,同时学会调整参数以提高模型性能,并掌握一些常用的模型评估和可视化方法。
提高模型准确率的可能方法:
1.网格搜索(Grid Search)方法:通过系统地遍历参数组合,找到最佳参数以提高模型性能。
2.数据预处理:标准化、归一化等数据预处理方法可能对模型性能产生影响。
3.特征选择:选择最重要的特征以避免噪声和不相关特征对模型性能的负面影响。