文章目录
第一章:shell入门基础
1.1 为什么学习和使用Shell编程
对于一个合格的系统管理员来说,学习和掌握Shell编程是非常重要的。通过编程,可以在很大程度上简化日常的维护工作,使得管理员从简单的重复劳动中解脱出来。
Shell程序的特点:
- 1、简单易学
- 2、解释性语言,不需要编译即可执行
注意:编译程序的效率高于解释性语言。
1.2 什么Shell
在学习Shell编程之前,必须弄清楚什么是Shell。为了能够使读者在学习具体的Shell编程之前对Shell有个基本的了解,本节将对Shell进行概括性的介绍,包括Shell的起源、功能和分类。
1.2.1 shell起源
- 1964年,美国AT&T公司的贝尔实验室、麻省理工学院及美国通用电气公司共同参与开始研发一套可以安装在大型主机上的多用户、多任务的操作系统,该操作系统的名称为Multics。
- 1970年,丹尼斯•里奇和汤普逊启动了另外一个新的多用户、多任务的操作系统的项目,他们把这个项目称之为UNICS。
- 1973年,使用C语言重写编写了Unix。通过这次编写,使得Unix得以移植到其他的小型机上面。
- 1979年,第一个重要的标准UNIX Shell在Unix的第7版中推出,并以作者史蒂夫•伯恩(Stephen Bourne)的名字命名,叫做Bourne Shell,简称为sh。
- 20世纪70年代末,C Shell作为2BSD UNIX的一部分发布,简称csh。
- 之后又出现了许多其他的Shell程序,主要包括Tenex C Shell(tcsh)、Korn Shell(ksh)以及GNU Bourne-Again shell(bash)。
1.2.2 什么是shell
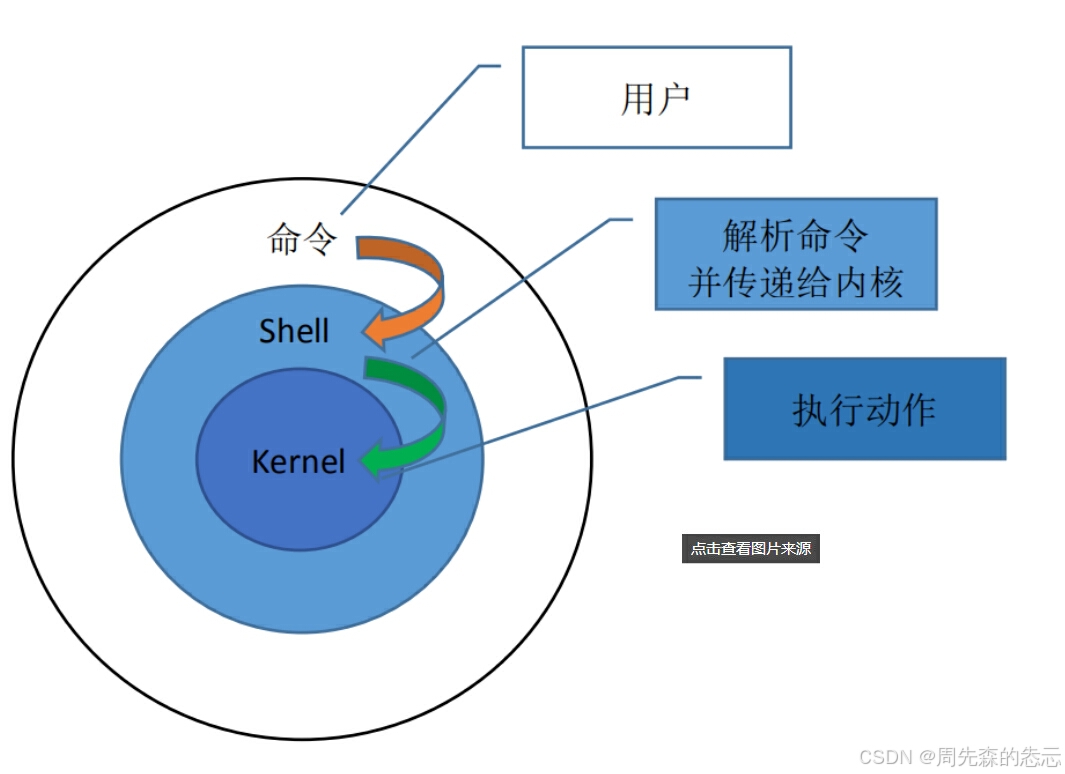
Shell又称命令解释器,它能识别用户输入的各种命令,并传递给操作系统。它的作用类似于Windows操作系统中的命令行,但是,Shell的功能远比命令行强大的多。在UNIX或者localhost中,Shell既是用户交互的界面,也是控制系统的脚本语言。
1.3 shell的分类
-
Bourne Shell:标识为sh,该Shell由Steve Bourne在贝尔实验室时编写。在许多Unix系统中,该Shell是root用户的默认的Shell。
-
Bourne-Again Shell:标识为bash,该Shell由Brian Fox在1987年编写,是绝大多数localhost发行版的默认的Shell。
-
Korn Shell:标识为ksh,该Shell由贝尔实验室的David Korn在二十世纪八十年代早期编写。它完全向上兼容 Bourne Shell 并包含了C Shell 的很多特性。
-
C Shell:标识为csh,该Shell由Bill Joy在BSD系统上开发。由于其语法类似于C语言,因此称为C Shell。
如何查看当前系统支持的shell?
[root@localhost ~]# cat /etc/shells [root@HAHA ~]# cat /etc/shells /bin/sh /bin/bash /usr/bin/sh /usr/bbash
如何查看当前系统默认shell?
[root@localhost ~]# echo $SHELL
/bin/baSh
1.4 程序设计语言shell特性
Shell不仅仅是充当用户与UNIX或者localhost交互界面的角色,还可以作为一种程序设计语言来使用。通过Shell编程,可以实现许多非常实用的功能,提高系统管理的自动化水平。本节将介绍作为程序设计语言的Shell的一些特性。
shell脚本
问**:如何区分python脚本和shell脚本?**
区分Python脚本和Shell脚本主要基于以下几个方面:
1. 文件扩展名
虽然这不是一个硬性规定,但文件扩展名通常可以给我们一个初步的提示。
Python脚本:通常以.py作为文件扩展名。
Shell脚本:通常以.sh(表示shell)或.bash(如果特定于Bash shell)作为文件扩展名,尽管有时也可能没有扩展名或者使用.cmd(在Windows的命令提示符环境中,但这不是典型的Unix/Linux shell脚本)。
2. shebang行(Shebang Line)
在脚本的第一行,通常会有一个指示脚本应该由哪个解释器执行的指令,这被称为shebang(在某些上下文中,特别是Python社区中,这个词可能被误用或不太常见,但在这里我们用它来指代这种行)。
Python脚本:#!/usr/bin/env python3 或 #!/usr/bin/python3(指向Python解释器的路径)。
Shell脚本:#!/bin/bash、#!/bin/sh 或 #!/usr/bin/env bash(指向shell解释器的路径)。
3. 语法和命令
Python和Shell脚本使用完全不同的语法和命令集。
Python脚本:使用Python语法,包括缩进、变量赋值(不使用$)、函数定义(使用def)、条件语句(使用if、elif、else)、循环(使用for、while)等。
Shell脚本:使用shell语法,包括变量赋值(使用=且变量名前通常不加$,但在引用变量值时需要使用$)、函数定义(使用function关键字或不带关键字的简单定义)、条件语句(使用if、then、elif、else、fi)、循环(使用for、while、until、select等)。
4. 执行方式
虽然两者都可以通过命令行执行,但执行它们的解释器是不同的。
Python脚本:需要Python解释器来执行,通常通过python script.py或python3 script.py命令来运行。
Shell脚本:需要shell解释器(如Bash)来执行,通常通过赋予执行权限后直接运行(./script.sh)或作为解释器的参数来运行(bash script.sh)。
5. 功能和用途
Python和Shell脚本在功能和用途上也有所不同。
Python脚本:通常用于编写更复杂的应用程序,包括Web开发、数据分析、机器学习等。Python提供了丰富的标准库和第三方库,使得开发过程更加高效。
Shell脚本:通常用于自动化系统管理和维护任务,如文件操作、进程管理、系统监控等。Shell脚本在Unix/Linux环境中非常常见,因为它们能够直接调用系统命令和工具。
综上所述,通过文件扩展名、shebang行、语法和命令、执行方式以及功能和用途等方面的比较,我们可以区分Python脚本和Shell脚本。
如果有一系列经常需要使用的命令,把它存储在一个文件里,shell可以读取这个文件并顺序执行其中的命令,这样的文件就叫shell脚本。shell脚本按行解释。
(1)顺序执行:逐条执行(自上而下循环执行)
(2)选择执行:代码有一个分支:条件满足时才会执行
两个以上分支:只执行其中一个满足条件的分支
(3)循环执行:代码片断(循环体)要执行0,1或多个来回
shell脚本语言是实现linux/Unix系统管理及自动化运维所必备的重要工具,linux/unix系统的底层及基础应用软件的核心大多都涉及shell脚本的内容。
[root@localhost ~]# vim a.sh # 创建并编译脚本
[root@localhost ~]# cat a.sh
ls
[root@localhost ~]# bash a.sh # 运行脚本
anaconda-ks.cfg Desktop Downloads Pictures Templates
a.sh Documents Music Public Videos
1.4.1编程语言和脚本语言区别
1,定义与特性
- 编程语言:
- 定义:编程语言是人与计算机之间通信的桥梁,用于编写能够指挥计算机完成特定任务的程序。
- 特性:通常具有严格的语法规则和结构,需要编译器将源代码转换为机器码才能执行。
- 脚本语言:
- 定义:脚本语言是一种介于标记语言和编程语言之间的语言,通常用于自动化任务和控制应用程序。
- 特性:语法相对简单,易于学习和使用。脚本语言通常是解释执行的,即不需要编译过程,由解释器逐行解释执行。
2,执行方式与编译过程
- 编程语言:
- 执行方式:需要先通过编译器将源代码转换为机器码,然后计算机才能执行。
- 编译过程:是一个需要花费时间的过程,但一旦源代码被编译成机器码,程序的运行速度将非常快。
- 脚本语言:
- 执行方式:通常是解释执行的,即代码在运行时由解释器逐行解释并执行。
- 编译过程:不需要预编译过程,因此具有很好的灵活性和可移植性
- 执行方式:通常是解释执行的,即代码在运行时由解释器逐行解释并执行。
3,运行环境与应用场景
- 编程语言:
- 运行环境:通常构建的是可独立运行的软件,这些软件在执行时与操作系统的交互较少。
- 应用场景:常用于开发大型和复杂的系统,如操作系统、数据库和游戏引擎等。
- 脚本语言:
- 运行环境:通常只需解释器的支持就可以运行,因此易于在不同的操作系统之间移植。
- 应用场景:广泛用于网站开发、小型工具编写、数据分析、自动化脚本编写等领域。
4,学习难易程度与入门门槛
- 编程语言:
- 学习难易程度:相对较复杂,需要更多的学习和理解才能熟练掌握。
- 入门门槛:较高,需要掌握更多的语法规则和编程概念。
- 脚本语言:
- 学习难易程度:相对简单,通常具有直观和易于理解的语法。
- 入门门槛:较低,适合初学者快速上手并实现一些小型任务和项目。
5,性能与优化
- 编程语言:
- 性能:由于编译器能够优化代码,因此通常具有较高的性能。
- 优化:编译器在编译过程中可以进行深入的优化,提高程序的运行效率。
- 脚本语言:
- 性能:由于每次执行时都需要解释器逐行解释执行,因此通常性能较低。
- 优化:虽然解释器也可以进行一些优化,但通常无法与编译器相比。
脚本语言:
如:shell、PHP、Python、JavaScript、Perl、Ruby 等
编程(译)语言:
如:java、c、c++ 等
比较
1.脚本语言不需要编译器因而省去了编译的过程减少了开发的时间,而编程语言需要编译所以时间更长一点
2.脚本语言是一种动态语言,也就是说可以实时的更改代码,而不需要将程序停止下来,这是一种高级特性。而Java等编程语言是静态的语言,一旦编译完成并且运行就不能更改代码,除非将程序停止下来。
3.脚本语言非常容易学习,但是不够全面缺乏系统性而且语法较为散漫。而高级编程语言虽然相对难学,但是规则强可以编程出简洁美观的代码,并且可读性也相对较强。
4.一般来说脚本语言通用性较差,但是可以通过专门的应用来调整。
5.随着技术的发展,其实脚本语言变得越来越强,和编程语言的界限也比较模糊,比如Python,可以将它视为编程语言了,因为它很强大。
shell脚本与php/perl/python语言的区别和优势?
shell脚本的优势在于处理操作系统系统底层的业务(linux系统内部应用的都是shell脚本来完成)因为有大量的linux系统命令为他做支撑。2000多个个命令都是shell脚本编程的有力支撑,特别是grep、awk、sed等。例如:一键安装软件、优化监控报警脚本,常规的业务应用,shell开发更简单快捷,符合韵味的简单、易用高效原则。
PHP、python优势在于开发运维工具以及web界面的管理工具,web业务的开发等。处理一键软件安装、优化、报警脚本。常规业务的应用等php/python也是能够做到的。但是开发效率和shell比差很多,代码量多更复杂。
1.5 如何学好shell
学好shell编程基础知识:
- 熟练使用vi(vim)编辑器 注释:3,6 s/^/# /
- 熟练掌握Linux基本命令
- 熟练掌握文本三剑客工具(grep、sed、awk)
- 熟悉常用服务器部署、优化、日志及排错
如何学好shell编程:
1、掌握Shell脚本基本语法
2、形成自己的脚本开发风格
3、从简单做起,简单判断,简单循环
4、多模仿,多参考资料练习,多思考
5、学会分析问题,逐渐形成编程思维
6、编程变量名字要规范,采用驼峰语法表示
7、不要拿来主义,特别是新手
1.6 Shell脚本的基本元素
对于一个基本的Shell程序来说,应该拥有以下基本元素: .sh /script/user.sh
第1行的 “#!/bin/bash” 。(注:脚本用什么来解释 she-Bang 魔数)
注释:说明某些代码的功能。
可执行语句:实现程序的功能。
Shell脚本中的注释和风格
通过在代码中增加注释可以提高程序的可读性。 传统的Shell只支持单行注释,其表示方法是一个井号“#”,从该符号开始一直到行尾都属于注释的内容。
例如:
#comment1 # 单行注释
#comment2
#comment3
...
// # 单行注释
/* # 单行注释
....
*/
如何实现多行注释?
用户还可以通过其他的一些变通的方法来实现多行注释,其中,最简单的方法就是使用冒号“:”配合here document,语法如下:
:<<BLOCK
....注释内容
BLOCK
1.7 Shell脚本编写规范
(1)开头指定脚本解释器 #!/bin/sh或#!/bin/bash 其他行#表示注释 名称见名知义 backup_mysql.sh,以sh结尾
(2)开头加版本版权等信息
Date:创建日期
Author:作者
Mail:联系方式
Function:功能
Version:版本
(3)脚本中尽量不用中文注释
别吝啬添加注释,必要的注释方便自己别人理解脚本逻辑和功能;
尽量用英文注释,防止本机或切换系统环境后中文乱码的困扰;
单行注释,可以放在代码行的尾部或代码行的上部;
多行注释,用于注解复杂的功能说明,可以放在程序体中,也可以放在代码块的开始部分,代码修改 时,对修改的内容
(4)多使用内部命令
内部命令可以在性能方面为你节省很多,从而减少系统卡顿。
[root@HAHA ~]# echo $[3+4]
7
[root@HAHA ~]# expr 3 + 5
8
[root@HAHA ~]# time echo $[4+4]
8
real 0m0.000s
user 0m0.000s
sys 0m0.000s
[root@HAHA ~]# time expr 4 + 4
8
real 0m0.002s
user 0m0.000s
sys 0m0.002s
(5)没有必要使用cat命令 vim % co $ grep root /etc/passwd cat /etc/passwd | grep root
eg:cat /etc/passwd | grep guru
使用以下方式即可
eg:grep guru /etc/passwd
(6)代码缩进
代码缩进示 (shell没有强制要求,建议缩进提交代码的可阅读性,更有层次感。python严格缩进标识代码块)
#!/bin/bash
i=1
while [ $i -le 10 ]
do
if [ $i -le 9 ]
then
username=user0$i
else
username=user$i
fi
! id $username &>/dev/null && {
useradd $username
echo $username | passwd --stdin $username &>/dev/null
}
let i++
done
(7)仔细阅读出错信息 有时候我们修改了某个错误并再次运行后,系统依旧会报错。然后我们再次修改,但系统再次报错。这可能会持续很长时间。但实际上,旧的错误可能已经被纠正,只是由于出现了其它一些新错误才导致系统再次报错
(8)脚本以.sh为扩展名
例如:script-name.sh
如何快速生成脚本开头的版本版权注释信息
[root@ scripts]# cat ~/.vimrc
autocmd BufNewFile *.py,*.cc,*.sh,*.java exec ":call SetTitle()"
func SetTitle()
if expand("%:e") == 'sh'
call setline(1,"#!/bin/bash")
call setline(2,"##############################################################")
call setline(3, "# File Name: ".expand("%"))
call setline(4, "# Version: V1.0")
call setline(5, "# Author: xx")
call setline(6, "# Email: [email protected]")
call setline(7, "# Organization: http://www.xx.com/xx/")
call setline(8, "# Created Time : ".strftime("%F %T"))
call setline(9, "# Description:")
call setline(10,"##############################################################")
call setline(11, "")
endif
endfunc
案例:
# 标准注释符
[root@localhost ~]# mkdir /day01/
[root@localhost ~]# vim a.sh
[root@localhost ~]# cat a.sh
#!/bin/bash
# # 单行注释
:<<EOF # 多行注释
sdef
eef
sf
EOF
ls
cat /etc/shells
echo #SHELL
[root@localhost ~]# bash a.sh
anaconda-ks.cfg Desktop Downloads Pictures Templates
a.sh Documents Music Public Videos
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
编写脚本全过程:
1,项目路径
2,创建脚本文件(vim *.sh)
she-bang #! 指定命令解释器
# 注释(:<<EOF 多行内容 EOF(不推荐))
代码(缩进,尽量使用内置命令,用最少命令执行解决)
编辑脚本设置:
[root@localhost /]# vim /etc/vimrc # 所有用户设置
[root@localhost /]# vim ~/.vimrc # 当前用户设置
[root@localhost /]# vim a.sh
echo $?
cat /etc/passwd &> /dev/null
cat aaa
cdd /
mkdir /test/haha
[root@localhost /]# bash -n a.sh # 仅检测shell语法检测,并不会执行脚本信息
1.8 shell脚本执行
方法一:当前目录下./a.sh 文件需要执行权限
方法二:绝对路径 /test/a.sh 文件需要执行权限
方法三:用sh 或bash来执行 bash a.sh 文件不要执行权限 —建议使用方法
方法四:用source a.sh 或 . a.sh 执行会开启子shell 文件不要执行权限 (一般不用 vim /etc/init.d/network )
区别:
1、方法三:可以在脚本中不指定解释器,脚本可以没有执行权限
2、方法一和方法二脚本需要有执行权限,./script_name.sh 或/path/script_name.sh bash a.sh
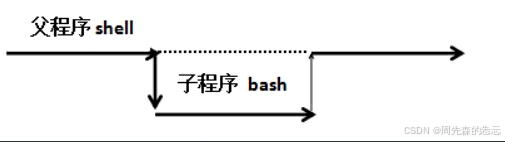
3、方法四:当前shell执行,方法1-3开启子shell
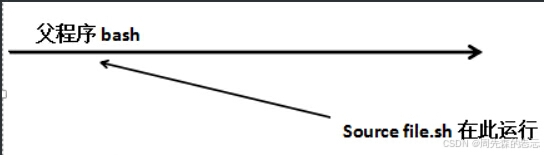
## 测试:
[root@localhost ~]# cd /day01/
[root@localhost day01]# vim test.sh # 创建脚本
[root@localhost day01]# cat test.sh
echo 'helloword!'
[root@localhost day01]# ll test.sh
-rw-r--r--. 1 root root 317 Nov 9 11:12 test.sh
[root@localhost day01]# chmod a+x test.sh # 给文件添加执行权限(仅用于方法一、二)
[root@localhost day01]# ll
total 4
-rwxr-xr-x. 1 root root 317 Nov 9 11:12 test.sh
# 方法一:相对路径执行文件
[root@localhost day01]# ./test.sh
helloword!
# 方法二:绝对路径执行文件
[root@localhost day01]# /day01/test.sh
helloword!
# 方法三:通过解释器执行文件
[root@localhost day01]# bash test.sh
helloword!
# 方法四:通过source执行文件
[root@localhost day01]# source test.sh
helloword!
## 一般推荐使用前三种方法执行文件
##注意:方法一和方法二都需要文件的执行权限,方法三和方法四都不需要文件的执行权限
案例1:
[root@localhost day01]# vim test1.sh
[root@localhost day01]# cat test1.sh
#!/bin/bash
##############################################################
# File Name: test1.sh
# Version: V1.0
# Author: xx
# Email: [email protected]
# Organization: http://www.xx.com/xx/
# Created Time : 2024-11-09 11:21:31
# Description:
##############################################################
exit # 添加退出指令
[root@localhost day01]# bash test1.sh
自定义脚本
写脚本:show_info.sh
输出: 当前系统时间是:xxxx
输出: 当前用户: $USER
vim tab键的缩进为4个空格
"add by school1024.com`
set ts=4
set softtabstop=4
set shiftwidth=4
set expandtab
set autoindent
ts是tabstop的缩写,设TAB宽度为4个空格。
softtabstop 表示在编辑模式的时候按退格键的时候退回缩进的长度,当使用 expandtab 时特别有用。
shiftwidth 表示每一级缩进的长度,一般设置成跟 softtabstop 一样。 expandtab表示缩进用空格来表示,noexpandtab 则是用制表符表示一个缩进。 autoindent自动缩进
脚本检测
bash -n 脚本语法检测,不执行脚本文件
一、命令功能
bash -n 命令用于对 Bash 脚本进行语法检查,而不实际执行脚本中的任何命令。它帮助用户在脚本执行前发现潜在的语法错误,从而避免脚本运行时出现意外的问题。
二、命令格式
bash
bash -n script.sh
其中,script.sh 是要检查的 Bash 脚本文件的文件名。用户需要将 script.sh 替换为实际的脚本文件名。
三、命令执行过程
当执行 bash -n script.sh 命令时,Bash shell 会按照以下步骤进行操作:
读取脚本文件:Bash shell 会读取指定的脚本文件内容。
语法检查:Bash shell 会对脚本中的语法进行逐行检查,包括命令、变量、控制结构(如循环、条件语句)等是否正确。
输出结果:如果脚本中存在语法错误,Bash shell 会输出错误信息,并指出错误所在的行数和具体错误信息。如果脚本中没有语法错误,则不会有任何输出。
四、命令返回值
成功:如果脚本语法正确,bash -n 命令会返回 0(表示成功)。
失败:如果脚本中存在语法错误,bash -n 命令会返回非 0 值(表示失败),并输出错误信息。
五、使用场景
bash -n 命令在以下场景中非常有用:
脚本开发阶段:在编写 Bash 脚本时,可以使用 bash -n 命令对脚本进行语法检查,确保脚本在语法层面没有问题。
脚本调试阶段:在调试 Bash 脚本时,可以先使用 bash -n 命令检查语法错误,然后再使用其他调试工具(如 bash -x 命令)跟踪脚本的执行流程。
脚本部署前验证:在将 Bash 脚本部署到生产环境之前,可以使用 bash -n 命令对脚本进行最后的语法检查,确保脚本在生产环境中能够正常运行。
六、注意事项
bash -n 命令只检查脚本的语法,而不执行脚本中的任何命令。因此,它无法发现脚本中的逻辑错误或运行时错误。
在使用 bash -n 命令时,请确保脚本文件具有可执行权限(虽然不是必需的,但通常是一个好习惯)。可以使用 chmod +x script.sh 命令为脚本文件添加可执行权限。
bash -x 跟踪脚本执行
bash -x 命令在 Bash shell 环境中用于调试脚本,通过显示脚本中每个命令的执行过程及其结果,帮助用户跟踪脚本的执行流程并诊断问题。以下是对该命令的详细解释:
一、命令功能
bash -x 命令会在执行 Bash 脚本时,将脚本中的每条命令及其参数、变量替换后的值以及命令的执行结果(如果有的话)输出到标准错误(stderr)。这有助于用户了解脚本的执行过程,发现潜在的错误或问题。
二、命令格式
bash
bash -x script.sh
或者,如果脚本已经具有可执行权限,并且希望在脚本的 shebang 行中指定调试模式,可以这样做:
bash
#!/bin/bash -x
# 脚本内容
在这种情况下,当脚本被执行时,它会自动以调试模式运行。
三、命令执行过程
当执行 bash -x script.sh 命令时,Bash shell 会按照以下步骤进行操作:
读取脚本文件:Bash shell 会读取指定的脚本文件内容。
预处理:在执行每条命令之前,Bash shell 会对命令进行预处理,包括变量替换、命令替换、算术扩展等。
输出调试信息:将预处理后的命令(包括参数和变量替换后的值)输出到标准错误。
执行命令:执行预处理后的命令。
输出结果:如果命令有输出,则将其输出到标准输出(stdout)或标准错误(stderr),具体取决于命令本身。
四、调试信息的格式
调试信息的格式通常如下:
+ command arg1 arg2 ...
其中,+ 表示这是一条调试信息,command 是要执行的命令,arg1 arg2 ... 是命令的参数。如果命令中包含了变量替换或命令替换,则这些部分会被替换为相应的值。
五、使用场景
bash -x 命令在以下场景中非常有用:
脚本调试:当脚本的行为不符合预期时,可以使用 bash -x 命令来跟踪脚本的执行流程,找出问题所在。
脚本学习:对于初学者来说,使用 bash -x 命令可以帮助他们更好地理解脚本的执行过程,学习 Bash 脚本的编写技巧。
脚本优化:在优化脚本性能时,可以使用 bash -x 命令来观察脚本的执行过程,找出可以优化的部分。
六、注意事项
bash -x 命令会输出大量的调试信息,因此在使用时需要注意筛选和过滤这些信息,以便更快地定位问题。
如果脚本中包含敏感信息(如密码、密钥等),则在使用 bash -x 命令时需要谨慎,因为这些信息可能会被输出到调试信息中。
在某些情况下,bash -x 命令可能会因为输出过多的信息而导致脚本执行变慢。如果遇到这种情况,可以尝试减少脚本中的输出或使用其他调试方法。
shellcheck 脚本文件检测脚本 …
1.9 shell特性
1、echo linux打印命令
选项:-n 取消输出后行末的换行符号
-e 支持反斜线控制的字符转换
| 控制字符 | 作 用 |
|---|---|
| \ | 输出\本身 ! |
| \a | 输出警告音 |
| \b | 退格键,也就是向左删除键 |
| \c | 取消输出行末的换行符。和“-n”选项一致 |
| \e | Esc键向右删除键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 字符替换 |
| \t | 制表符,也就是Tab键 |
| \v | 垂直制表符 |
| \0nnn | 按照八进制 ASCII 码表输出字符。其中 0 为数字 0,nnn 是三位八进制数 eg:141 这个八制数在 ASCII 码中代表小写的"a",其他的以此类推echo -e “\0141\t\0142” |
| \xhh | 按照十六进制 ASCLL 码表输出字符。其中 hh 是两位十六进制数 [root@localhost ~]# echo -e “\x61\t\x62\t\x63\n\x64\t\x65\t\x66” a b c d e f #如果按照十六进制ASCII码同样可以输出 |
练习:
[root@localhost ~]# echo -e "helloword\a"
helloword
[root@localhost ~]# echo -e "hell\bword"
helword
[root@localhost ~]# echo -e "helloword\c"
helloword[root@localhost ~]# ^C
[root@localhost ~]# echo -e "hello\eword"
helloord
[root@localhost ~]# echo -e "hello\tword"
hello word
[root@localhost ~]# echo -e "hello\fword"
hello
word
[root@localhost ~]# echo -e "hello\vword"
hello
word
[root@localhost ~]# echo -e "\e[35;42m helloword! \e[0m"
helloword!
[root@localhost ~]# echo -e "\e[5;35;42m helloword! \e[0m"
helloword! # 这里的字符颜色在闪烁
[root@localhost ~]# echo -e "\e[1;31m abed \e[0m"
echo -e "\033[1;31;42m abcd \033[0m"
这条命令会把 abcd 按照红色输出。
解释一下这个命令:\e[字体控制选项;字体背景颜色;文字颜色m 字符串 \e[0m 代表颜色输出结束
文字颜色:30m=黑色,31m=红色,32m=绿色,33m=黄色,34m=蓝色,35m=洋红,36m=青色,37m=白色。
字体背景色:40m=黑色,41m=红色,42m=绿色,43m=黄色,44m=蓝色,45m=洋红,46m=青色,47m=白色。
字体控制选项:1表示高亮,4表示下划线,5颜色闪烁
[root@localhost ~]# df -h # 查看文件系统的使用情况
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 866M 0 866M 0% /dev/shm
tmpfs 347M 7.2M 340M 3% /run
/dev/mapper/rhel-root 17G 4.2G 13G 26% /
/dev/nvme0n1p2 960M 292M 669M 31% /boot
/dev/nvme0n1p1 599M 7.0M 592M 2% /boot/efi
tmpfs 174M 88K 174M 1% /run/user/0
/dev/sr0 113M 113M 0 100% /run/media/root/CDROM
/dev/sr1 9.9G 9.9G 0 100% /run/media/root/RHEL-9-3-0-BaseOS-x86_64
[root@localhost ~]# useradd # 等同于adduser,只能管理员添加,且只能一个一个用户添加
[root@localhost ~]# #userdel -r # 删除用户
[root@localhost ~]# usermod -n # 修改用户信息
2、printf
printf 命令模仿 C 程序库(library)里的 printf() 程序。
printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。
printf 使用引用文本或空格分隔的参数,外面可以在 printf 中使用格式化字符串,还可以制定字符串的宽度、左右对齐方式等。默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf 命令的语法:
printf format-string [arguments...]
参数说明:
- format-string: 为格式控制字符串%10s %c %d %f
- arguments: 为参数列表。
实例
$ echo "Hello, Shell"
Hello, Shell
$ printf "Hello, Shell**\n**"
Hello, Shell
$
用一个脚本来体现 printf 的强大功能:
实例
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876
执行脚本,输出结果如下所示:
姓名 性别 体重kg
郭靖 男 66.12
杨过 男 48.65
郭芙 女 47.99
%s %c %d %f 都是格式替代符,%s 输出一个字符串,%d 整型输出,%c 输出一个字符,%f 输出实数,以小数形式输出。
%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中 .2 指保留2位小数,4是总长度啊
实例
printf "%d %s\n" 1 "abc"
# 单引号与双引号效果一样*
printf '%d %s\n' 1 "abc"
# 没有引号也可以输出
printf %s abcdef
# 格式只指定了一个参数,但多出的参数仍然会按照该格式输出,format-string 被重用
printf %s abc def
printf "%s\n" abc def
printf "%s %s %s\n" a b c d e f g h i j
# 如果没有 arguments,那么 %s 用NULL代替,%d 用 0 代替*
printf "%s and %d \n"
执行脚本,输出结果如下所示:
1 abc
1 abc
abcdefabcdefabc
def
a b c
d e f
g h i
j
and 0
**3、命令执行顺序 **
; --命令的顺序执行 date; ls -l /etc/passwd
&&与 --前面命令执行不成功,后面的命令不执行 id haha && userdel -r haha
||或--如果前面命令成功,后面就不执行,如果前面不成功后面就执行
! 非
案例:
[root@localhost ~]# useradd tom && id tom # 先创建tom用户,让然后查看tom用户的id值
uid=1001(tom) gid=1001(tom) groups=1001(tom)
[root@localhost ~]# id zhangsan || useradd zhangsan
id: ‘zhangsan’: no such user
[root@localhost ~]# id zhangsan
uid=1002(zhangsan) gid=1002(zhangsan) groups=1002(zhangsan)
4、通配符(文件名通用匹配),正则符(文件内容,标准输出结果)
通配符是系统命令使用,一般用来匹配文件名或者什么的用在系统命令中。而正则表达式是操作字符串,以行尾单位来匹配字符串使用的。
? 匹配一个任意字符
`*` 匹配 0 个或任意多个任意字符,也就是可以匹配任何内容
[a1b2] 匹配中括号中任意一个字符。
[a-z] 匹配中括号中任意一个字符, '-'代表一个范围。
[^a-z] 逻辑非,表示匹配不是中括号内的一个字符。
[a-z] [0-9] [a-zA-Z] [^0-9a-zA-Z]
{1,2,3,4}
mkdir {1,2,3,4}
. 匹配当前目录
.. 匹配上一级目录
## 验证:
[root@localhost ~]# ll a?
ls: cannot access 'a?': No such file or directory
[root@localhost ~]# ll a?sh
-rw-r--r--. 1 root root 70 Nov 9 10:10 a.sh
[root@localhost ~]# ll a*
-rw-------. 1 root root 832 Oct 12 18:32 anaconda-ks.cfg
-rw-r--r--. 1 root root 70 Nov 9 10:10 a.sh
[root@localhost ~]# ll a[a-z]*
-rw-------. 1 root root 832 Oct 12 18:32 anaconda-ks.cfg
[root@localhost ~]# touch a1bc
[root@localhost ~]# touch a2bc
[root@localhost ~]# ll a[a-z]*
-rw-------. 1 root root 832 Oct 12 18:32 anaconda-ks.cfg
[root@localhost ~]# ll a[^a-z]*
-rw-r--r--. 1 root root 0 Nov 9 14:54 a1bc
-rw-r--r--. 1 root root 0 Nov 9 14:54 a2bc
-rw-r--r--. 1 root root 70 Nov 9 10:10 a.sh
**[[:class:]]:**匹配一个属于指定字符类中的字符,[:class:]表示一种字符类,比如数字、大小写字母等。
常用字符类:
[:alnum:] :匹配任意一个字母或者数字 ,传统UNIX写法: a-zA-Z0-9
[:alpha:] :匹配任意一个字母,传统UNIX写法: a-zA-Z [:alpha:]
[:digit:] :匹配任意一个数字,传统UNIX写法: 0-9
[:lower:] : 匹配任意一个小写字母,传统UNIX写法: a-z
[:upper:] : 匹配任意一个大写字母,传统UNIX写法:A-Z
[:space:] :空白字符
[:punct:] : 标点符号
注意事项:在使用专属字符集的时候,字符集之外还需要用 [ ] 来包含住,否则专用字符集不会生效,例
如 [[:space:]]
[root@HAHA ~]# grep '[[:upper:]]' a
AAA
BBB
CCC
通配符常用语法:
1、匹配任意长度的任意字符,就是说“什么都可以”。
[root@localhost ~]# ll *
2、?:与任何单个字符匹配。
[root@localhost ~]# ll a?
3、[ ]:与?相似,可以匹配一个括号内的字符,也可以用“-”进行范围指定。
[0-9]
[a-z]
[A-Z]
[0-9a-zA-Z]
ll /etc[0-9] #将列出 /etc 中以数字开头的所有文件。
ls /tmp/[A-Za-z] #将列出/tmp中以大写字母或小写字母开头的所有文件。
4、[!]:括号内的“!”代表非的意思,即不与括弧中的字符匹配。
rm myfile[!9] #删除除了myfile9之外的名为myfile加一个字符的所有文件
5、{}生成序列
touch file{1..9}.txt
#当前路径生成file1.txt~file9.txt。{a..f}代表a-f,不连续的使用,分 隔,比如f{1,3,5}.txt
6、使用{}备份
cp file1.txt{,.bak} #将fiel1.txt复制一份叫file1.txt.bak
cp file{2,22}.txt #复制file2.txt为file22.txt
[root@localhost ~]# cp /etc/passwd{,.bak}
[root@localhost ~]# ll /etc/passwd*
-rw-r--r--. 1 root root 2184 Nov 9 14:40 /etc/passwd
-rw-r--r--. 1 root root 2137 Nov 9 14:37 /etc/passwd-
-rw-r--r--. 1 root root 2184 Nov 9 15:09 /etc/passwd.bak
示例:
1、列出/etc/目录中不是以字母a到n开头的,并且以.conf结尾的文件
[root@localhost ~]# ls /etc/[!a-n]*.conf
2、列出/etc/目录中以字母a到n开头的,并且以.conf结尾的文件
[root@localhost ~]# ls /etc/[a-n]*.conf
3、列出/bin/下以 c或k开头的文件名
[root@localhost ~]# ls /bin/[ck]*
1、创建用户haha且用户的密码同用户名,而且要求,添加密码完成后不显示passwd命令的执行结果信息;
[root@localhost ~]# useradd haha && echo "haha" | passwd --stdin haha > /dev/null # > :重定向符;/dev/null是空设备文件,文件进入即被清理
2、每个用户添加完成后,都要显示用户某某已经成功添加;
[root@localhost ~]# useradd user1 && echo "user1已经成功添加"
# 如果用户存在,就显示用户已存在;否则,就添加此用户;
[root@localhost ~]# (id user1 &>/dev/null && echo "user已存在") || useradd user1
# 如果用户不存在,就添加;否则,显示其已经存在;
[root@localhost ~]# !id user1 &>/dev/null && (useradd user1;echo user1 |passwd --stdin user1) || echo "用户已存在"
[root@localhost ~]# !id user1 &>/dev/null && (useradd user1 && echo user1 |passwd --stdin user1) || echo "用户已存在"
[root@localhost ~]# ! id user1 && useradd user1 || echo "user1 exists."
# 如果用户不存在,添加并且给密码;否则,显示其已经存在;
id user
useradd user
echo mima | passwd --stdin user
echo "用户已存在"
[root@localhost ~]# (id user && echo "用户已存在") || (useradd user && echo mima | passwd --stdin user)
[root@localhost ~]# (!id user && useradd user && echo 123 | passwd --stdin user) || echo "用户已存在"
练习,写一个脚本,完成以下要求:
1、添加1个用户user1;但要先判断用户是否存在,不存在而后再添加;
2、最后显示当前系统上共有多少个用户;
文本文件命令:
创建:
vim(gedit----图形化界面)
touch
nano
查看:
cat
tac
more
less
tail
head
(grep):只是基于关键字显示
删除:
rm -i
修改:
vim
vim:
vim 是一个非常强大的文本编辑器,在 Linux 和类 Unix 系统中广泛使用。vim 命令本身以及它的启动参数提供了许多功能来定制编辑器的行为和外观。以下是一些常用的 vim 启动参数及其含义:
-v 或 --vi-compatible:
使 vim 的行为更接近传统的 vi 编辑器。
-e 或 --ex-mode:
启动 vim 的 Ex 模式,这是一个命令行模式,类似于 ex 编辑器。
-R 或 --readonly:
以只读模式打开文件。
-r 或 --recover:
尝试恢复崩溃的文件。
-b 或 --binary:
以二进制模式打开文件,而不是文本模式。
-M 或 --nomagic:
在搜索时关闭魔法模式(magic mode),使正则表达式匹配更加直观。
--noplugin:
启动时不加载任何插件。
--clean:
使用一个干净的、默认的配置文件启动 vim,不加载用户的 .vimrc 文件或插件。
-u <filename> 或 --userrc=<filename>:
使用指定的初始化文件而不是默认的 .vimrc。
-U <none> 或 --nouserrc:
不加载用户的初始化文件(.vimrc)。
-i <filename> 或 --initfile=<filename>:
使用指定的初始化脚本文件。
-n 或 --no-swapfile:
不生成交换文件(swapfile)。
-w 或 --write:
写入文件并退出,主要用于从脚本中调用。
-q 或 --quiet:
安静模式,不显示启动信息。
-c <command> 或 --cmd=<command>:
在启动 vim 后执行指定的 Vim 命令。
-s <scriptin> 或 --source=<scriptin>:
从指定的脚本文件中读取并执行 Vim 命令。
-V 或 --verbose=<n>:
设置详细模式,n 是详细级别,n 越大输出越详细。
-d <file_list> 或 --diff <file_list>:
以差异模式启动 vim,用于比较多个文件的内容。
-f 或 --foreground:
在前台运行 vim,而不是在后台。
-g 或 --geometry=<rows>x<cols>:
设置 vim 窗口的初始大小。
-o[N] 或 --onehalf[N]:
水平分割窗口,打开 N 个文件(如果未指定 N,则默认打开两个文件)。
-O[N] 或 --two 或 --vertical[N]:
垂直分割窗口,打开 N 个文件(如果未指定 N,则默认打开两个文件)。
+[cmd] 或 --cmd=<cmd>:
在启动 vim 后,将光标定位到指定的位置或执行指定的命令。
--servername=<name>:
为客户端/服务器模式指定服务器名称。
touch:
-a:
只更改文件的访问时间(access time),而不更改修改时间(modification time)。
-c 或 --no-create:
如果指定的文件不存在,则不创建新文件。这个选项通常用于确保只更新已存在文件的时间戳,而不创建新文件。
-d 或 --date=STRING:
使用指定的字符串(STRING)来设置文件的时间戳,而不是使用当前时间。STRING的格式可以参考date命令的输出格式,例如"2023-12-31 23:59:59"。
-f:
这是一个“无用参数”(no-op),通常用于兼容其他系统或脚本中的旧语法。
-h 或 --no-dereference:
如果操作的是符号链接(symlink),则只更改符号链接本身的时间戳,而不更改链接指向的源文件的时间戳。
-m:
只更改文件的修改时间(modification time),而不更改访问时间(access time)。
-r 或 --reference=FILE:
使用指定文件(FILE)的时间戳来更新目标文件的时间戳。这允许用户将一个文件的时间戳复制到另一个文件上。
-t:
使用指定的时间戳格式来设置文件的时间戳。格式通常为[[CC]YY]MMDDhhmm[.ss],其中CC是世纪(可选),YY是年份的后两位,MM是月份,DD是日期,hh是小时,mm是分钟,ss是秒(可选)。
--time=WORD:
修改特定的时间戳。WORD可以是access、atime或use(等同于-a),表示访问时间;也可以是modify或mtime(等同于-m),表示修改时间。
--help:
显示touch命令的帮助信息,包括所有可用的选项和参数。
--version:
显示touch命令的版本信息。
使用touch命令时,可以通过组合这些选项来定制其行为。例如,使用touch -a filename可以只更新文件的访问时间,而不更改修改时间;使用touch -d "2023-12-31 23:59:59" filename可以将文件的时间戳设置为指定的日期和时间。
rm:
rm -i
rm命令是Linux系统中用于删除文件或目录的常用命令,其相关参数及含义如下:
-f, --force
强制删除文件或目录,不会提示用户确认,即使文件或目录是只读的,也会尝试删除。
使用此参数时,如果文件或目录不存在,rm命令也不会显示错误信息。
-i, --interactive
交互模式,在每次删除文件或目录前都会询问用户确认。
这有助于防止误删除重要文件或目录。
-r, -R, --recursive
递归删除目录及其下的所有文件和子目录。
如果要删除一个非空目录及其所有内容,必须使用此参数。
-d, --directory
直接删除空目录,而不需要递归。
如果目录不为空,使用此参数会报错。
-v, --verbose
显示详细输出,列出正在删除的文件或目录的详细信息。
这有助于用户了解rm命令的执行过程。
--no-preserve-root
在使用-r或-R参数时,通常rm命令会拒绝删除根目录/。
使用此参数可以覆盖这一保护机制,但极其危险,因为删除根目录及其内容将导致系统无法正常工作。
注意:此参数通常不推荐使用,除非用户非常确定要删除整个系统。
--help
显示rm命令的帮助信息,包括所有可用参数和选项的说明。
--version
显示rm命令的版本信息。
使用rm命令时,请务必小心谨慎,尤其是在使用-r、-f等参数时,因为这些操作可能导致数据永久丢失且无法恢复。在执行删除操作之前,建议用户先使用ls命令确认要删除的文件或目录,以避免意外删除重要数据。
此外,对于一些重要的文件或目录,建议用户在进行删除操作之前先进行备份,以防止数据丢失带来的不便和损失。
目录文件
创建:
mkdir
查看:
cd
ll
-d 目录名
删除:
rm -r
rm -f
文本内容处理命令
grep:
grep -options "模式匹配" 文件名
在Linux系统中,grep命令是一种强大的文本搜索工具,它使用正则表达式搜索文本,并把匹配的行打印出来。以下是grep命令的一些常用参数及其含义:
-a 或 --text
将二进制文件视为文本文件进行搜索。
-c 或 --count
仅显示匹配行的计数,而不是显示匹配的行。
-i 或 --ignore-case
忽略大小写进行搜索。
-l 或 --files-with-matches
仅显示包含匹配模式的文件名,而不是显示匹配的行。
-n 或 --line-number
显示匹配行的行号。
-v 或 --invert-match
显示不匹配指定模式的行,即反转匹配。
-r 或 --recursive
递归搜索指定目录及其子目录中的文件。
-w 或 --word-regexp
仅匹配整个单词,而不是部分匹配。
-E 或 --extended-regexp
使用扩展正则表达式进行匹配。
-m <num> 或 --max-count=<num>
仅显示指定数量的匹配行。
-o 或 --only-matching
仅显示匹配的部分,而不是整行。
-A <num>
显示匹配行之后的指定行数。
-B <num>
显示匹配行之前的指定行数。
-C <num>
显示匹配行之前和之后的指定行数。
-q 或 --quiet
静默模式,不输出任何结果,通常用于脚本中判断是否存在匹配。
-e exp
指定字符串作为查找文件内容的样式,可以多次使用以查找多个模式。
-f file
指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
这些参数可以组合使用,以满足不同的搜索需求。例如,grep -i -n "pattern" file将忽略大小写地在file文件中搜索pattern,并显示匹配行的行号。
请注意,在使用grep命令时,如果文件很大或目录结构复杂,某些参数(如-r)可能会导致搜索过程非常耗时。因此,在选择参数时,应根据实际需求进行权衡。
cut:
在Linux系统中,cut命令是一个用于从文本文件中提取特定列或字符的实用工具。以下是cut命令的一些常用参数及其含义:
-b, --bytes=LIST
以字节为单位进行分割,并提取指定范围内的字节。例如,cut -b 1-3 file会提取文件file中每行的前三个字节。
-c, --characters=LIST
以字符为单位进行分割,并提取指定范围内的字符。与-b选项不同,-c会考虑多字节字符的完整性。例如,cut -c 1-3 file会提取文件file中每行的前三个字符。
-d, --delimiter=DELIM
指定字段的分隔符。默认情况下,cut命令使用制表符(TAB)作为字段分隔符。通过-d选项,可以指定其他字符作为分隔符。例如,cut -d ':' -f 1 /etc/passwd会以冒号(:)为分隔符,提取/etc/passwd文件中每行的第一个字段(通常是用户名)。
-f, --fields=LIST
提取指定范围内的字段。字段是通过-d选项指定的分隔符来确定的。例如,cut -d ':' -f 1,3 /etc/passwd会提取/etc/passwd文件中每行的第一个和第三个字段。
-n
与-b选项一起使用时,不分割多字节字符。这有助于确保在提取字节时不会破坏多字节字符的完整性。
--complement
补足被选择的字节、字符或字段。即,提取除了指定范围之外的所有内容。例如,cut -c 1-3 --complement file会提取文件file中每行除了前三个字符之外的所有字符。
--out-delimiter=STRING
指定输出内容的字段分隔符。例如,cut -d ':' -f 1,2 --out-delimiter=',' /etc/passwd会以逗号(,)为分隔符输出/etc/passwd文件中每行的第一个和第二个字段。
--help
显示cut命令的帮助信息,包括所有可用参数和选项的说明。
--version
显示cut命令的版本信息。
请注意,在使用cut命令时,应根据实际需求选择合适的参数和选项。例如,当处理包含多字节字符的文本时,应谨慎使用-b选项,以避免破坏字符的完整性。相反,-c选项更适合处理这种情况,因为它会考虑多字节字符的完整性。同时,通过组合使用不同的参数和选项,可以实现更复杂的文本提取和处理任务。
sort:
在Linux系统中,sort命令是一个用于对文本文件内容进行排序的实用工具。以下是sort命令的一些常用参数及其含义:
-b, --ignore-leading-blanks
忽略每行前面开始的空格字符。这对于处理包含前导空格的行特别有用,可以确保排序时这些空格不会影响行的顺序。
-c, --check
检查文件是否已经按照顺序排序。如果文件未排序,sort会提示从哪一行开始乱序。这对于验证文件的排序状态很有用。
-C, --check=quiet, --no-check
类似于-c选项,但不会在终端输出任何诊断信息。可以通过检查命令的退出状态码来判断文件是否已排序(未排序时退出状态码为1)。
-d, --dictionary-order
只考虑英文字母、数字及空格字符,忽略其他字符。这会使排序更符合字典顺序。
-f, --fold-case
排序时,将小写字母视为大写字母,即忽略大小写差异进行排序。
-h, --human-numeric-sort
使用易读性数字(例如2K、1G)进行排序。这对于处理包含大数字的文件(如文件大小、内存使用量等)特别有用。
-i, --ignore-nonprinting
除了ASCII字符040至176(八进制0-177,包括空格、换行等常见字符)之外,忽略其他无法打印的字符。
-k, --key=POS1[,POS2]
按照指定字段(或字符位置范围)进行排序。可以指定起始和结束位置,以逗号分隔。这对于处理包含多个字段的文件特别有用。
-m, --merge
将几个已经排序好的文件进行合并,不重新排序。这有助于在合并多个有序文件时保持它们的顺序。
-M, --month-sort
将前面3个字母依照月份的缩写进行排序(如Jan、Feb、Mar等)。
-n, --numeric-sort
按照数值大小进行排序。这对于处理包含数字的文件特别有用,可以确保数字按大小顺序排列。
-o, --output=FILE
将排序后的结果输出到指定文件,而不是默认的标准输出(终端)。
-r, --reverse
以相反的顺序进行排序(降序)。默认情况下,sort命令按升序排序。
-t, --field-separator=SEP
指定字段分隔符。默认情况下,sort命令使用空白字符(空格或制表符)作为字段分隔符。通过-t选项,可以指定其他字符作为分隔符。
-u, --unique
去除重复行,只保留唯一行。这对于处理包含重复行的文件特别有用。
--version
显示sort命令的版本信息。
--help
显示sort命令的帮助信息,包括所有可用参数和选项的说明。
请注意,在使用sort命令时,应根据实际需求选择合适的参数和选项。通过组合使用不同的参数和选项,可以实现更复杂的排序任务。同时,对于包含特殊字符或格式的文件,可能需要使用额外的参数或选项来确保正确的排序结果。
uniq:
在Linux系统中,uniq命令用于处理文本文件,特别是用于识别并去除(或者操作)相邻且重复的行。以下是uniq命令的一些常用参数及其含义:
-c, --count:
在每行前加上该行在文件中出现的次数。这个选项对于统计重复行的数量非常有用。
-d, --repeated:
仅显示重复出现的行。这个选项会过滤掉文件中不重复的行,只保留重复的行。
-D:
打印所有重复行,而不仅仅是第一次出现的行。与-d选项相比,-D会显示所有重复的行,而不仅仅是其中一行。
--all-repeated[=METHOD]:
类似-D,但可以接受空行分隔的重复行组,并可以选择如何输出这些组(none, prepend, separate)。这个选项提供了更灵活的重复行输出方式。
-f N, --skip-fields=N:
跳过比较前N个字段(由制表符或空格分隔)。这个选项允许在比较行时忽略前N个字段,只考虑后面的字段。
-s N, --skip-chars=N:
跳过比较前N个字符。与-f选项类似,但-s选项是基于字符而不是字段来跳过比较的部分。
--group[=METHOD]:
输出时,在不同重复组之间插入空行,允许指定插入位置(separate, prepend, append, both)。这个选项有助于在视觉上区分不同的重复行组。
-i, --ignore-case:
忽略大小写差异。在比较行时,不区分大小写字母。
-u, --unique:
显示唯一的、不重复的行。这个选项会过滤掉文件中重复的行,只保留唯一的行。
--version:
显示uniq命令的版本信息。
--help:
显示uniq命令的帮助信息,包括所有可用参数和选项的说明。
需要注意的是,uniq命令处理的是相邻的重复行。因此,在实际应用中,通常需要先对数据进行排序(例如使用sort命令),确保可能重复的行相邻,然后再使用uniq进行去重或计数等操作。
wc:
在Linux系统中,wc(word count)命令是一个用于统计文件中的行数、单词数和字节数(或字符数)的实用工具。以下是wc命令的一些常用参数及其含义:
-c, --bytes:
统计文件中的字节总数。这个选项会输出文件中所有字符的字节数,不考虑字符的编码。
-m, --chars:
统计文件中的字符总数。这个选项会输出文件中所有字符的数量,包括多字节字符(如UTF-8编码的汉字)。在某些系统上,-m和-c选项可能给出相同的结果,但在处理多字节字符时,-m通常更准确。
-l, --lines:
统计文件中的行数。这个选项会输出文件中包含的行数,每行以换行符(\n)分隔。
-w, --words:
统计文件中的单词数。wc命令将任何由空白字符(空格、制表符、换行符等)分隔的字符串视为一个单词。这个选项会输出文件中单词的总数。
-L, --max-line-length:
显示文件中最长一行的长度(以字符数计)。这个选项会输出文件中最长行的字符数,对于处理包含长行的文件特别有用。
--help:
显示wc命令的帮助信息,包括所有可用参数和选项的说明。这个选项对于不熟悉wc命令的用户非常有用,可以帮助他们快速了解命令的用法和功能。
文件名:
指定要统计的文件名。wc命令可以接受一个或多个文件名作为输入,并分别输出每个文件的统计信息。如果没有指定文件名,wc命令会从标准输入(stdin)读取数据。
需要注意的是,wc命令在处理包含多字节字符(如UTF-8编码的文本)的文件时,-m和-c选项可能会给出不同的结果。因为-m统计的是字符数(可能包括多字节字符),而-c统计的是字节数。
此外,wc命令还可以与其他命令结合使用,通过管道(pipe)传递数据。例如,可以使用cat命令输出文件内容,然后通过管道传递给wc命令进行统计。或者,可以使用find命令查找特定类型的文件,并通过-exec选项执行wc命令对找到的文件进行统计。
tr:
在Linux系统中,tr(translate or delete characters)命令是一个用于字符转换或删除的实用工具。以下是tr命令的一些常用参数及其含义:
-c, --complement:
使用字符集1的补集。这个选项会选取不在字符集1中的所有字符,并对其进行后续操作(如替换或删除)。
-d, --delete:
删除字符集1中的字符。这个选项会删除输入中所有属于字符集1的字符,不进行替换。
-s, --squeeze-repeats:
压缩连续的重复字符。这个选项会将输入中连续的重复字符压缩为单个字符。
-t, --truncate-set1-to-length-of-set2:
将字符集1截断到与字符集2相同的长度。这个选项在替换字符时非常有用,可以确保字符集1和字符集2在长度上对齐,从而实现更精确的文本转换。
需要注意的是,tr命令主要用于处理单个字符的替换、删除和压缩操作,它不能用于替换字符串。在使用tr命令时,通常需要指定两个字符集:字符集1(要转换或删除的字符集合)和字符集2(替换或保留的字符集合)。字符集可以使用单字符、字符范围或列表来表示。
此外,tr命令还可以与其他命令结合使用,通过管道(pipe)传递数据。例如,可以使用cat命令输出文件内容,然后通过管道传递给tr命令进行字符转换或删除操作。
df:
df(disk free)命令在Linux系统中用于显示磁盘空间的使用情况。通过不同的参数,你可以定制df命令的输出。以下是一些常见的df命令参数及其含义:
-a 或 --all:
显示所有文件系统的磁盘使用情况,包括伪文件系统如/proc、/sys等。
-h 或 --human-readable:
以人类可读的格式显示大小,例如使用KB、MB、GB等单位。
-i:
显示inode的使用情况,而不是块的使用情况。Inode是文件系统中用于存储文件元数据的结构。
-k:
以1KB为单位显示磁盘使用情况,这是默认行为,但使用-k可以明确指定。
-m:
以1MB为单位显示磁盘使用情况。
-g:
以1GB为单位显示磁盘使用情况。
-T 或 --type=TYPE:
显示特定类型的文件系统的磁盘使用情况。例如,你可以使用df -T ext4来显示所有ext4文件系统的使用情况。
-t 或 --type=TYPE:
仅显示特定类型的文件系统的磁盘使用情况,与-T不同,-t会过滤掉其他类型的文件系统。
--total:
在最后添加一行,显示所有文件系统的总计使用情况。
-B:
设置块大小。例如,df -BG会以GB为单位显示磁盘使用情况。
-l:
仅显示本地文件系统的磁盘使用情况,忽略网络文件系统(如NFS)。
--sync:
调用sync命令强制将所有缓冲的数据写入磁盘,然后显示磁盘使用情况。这在需要确保数据最新时很有用。
--no-sync:
不调用sync命令,这是默认行为。
--portability:
使用POSIX兼容的输出格式。
--file=:
仅显示指定文件的文件系统使用情况。
--output=[TYPE[,TYPE]...]:
指定要显示的列。例如,df --output=source,fstype,itotal,iused,iavail,ipcent,size,used,avail,pcent,target会显示特定的列。
例子:
df -h:以人类可读的格式显示磁盘使用情况。
df -i:显示inode的使用情况。
df -T:显示文件系统类型及其使用情况。
df --total:显示所有文件系统的总计使用情况。
更多关于linux的命令:Linux 命令大全_w3cschool
linux命令中关于磁盘分区的相关命令及其参数:
在Linux系统中,关于磁盘分区的相关命令及其参数具有多种功能和用途。以下是一些常用的磁盘分区命令及其参数的解释:
fdisk 命令
fdisk 是最常用的磁盘分区命令之一,用于创建、删除、查看磁盘分区等操作。
fdisk -l:列出系统中所有的磁盘和分区信息。
fdisk /dev/sdX:打开指定的磁盘(例如 /dev/sda)进行分区操作。
n:创建一个新分区。
d:删除一个分区。
p:打印分区表。
w:保存并退出分区表。
parted 命令
parted 是一个功能更强大的磁盘分区工具,常用于创建和管理GPT分区表,支持更多文件系统类型。
parted -l:列出系统中所有的磁盘和分区信息。
parted /dev/sdX:打开指定的磁盘进行分区操作。
mklabel gpt:创建GPT分区表。
mkpart primary <文件系统类型> <起始位置> <结束位置>:创建一个主分区或逻辑分区。
resizepart <分区号> <新的结束位置>:调整分区大小。
rm <分区号>:删除一个分区。
print:打印分区信息。
quit:退出parted工具。
gdisk 命令
gdisk 是专门用于GPT分区表的命令行工具,与parted类似。
gdisk -l /dev/sdX:显示指定磁盘的分区表信息。
gdisk /dev/sdX:打开指定的磁盘进行分区操作。
n:创建一个新分区。
d:删除一个分区。
p:打印分区表。
w:保存并退出分区表。
mkfs 命令
mkfs 命令用于格式化磁盘分区,将分区设置为指定的文件系统格式。
mkfs.ext4 /dev/sdX1:格式化指定的磁盘分区为ext4文件系统。
mkfs.xfs /dev/sdX1:格式化指定的磁盘分区为xfs文件系统。
mkfs.ntfs /dev/sdX1:格式化指定的磁盘分区为ntfs文件系统。
mkfs.vfat /dev/sdX1:格式化指定的磁盘分区为vfat文件系统。
cfdisk 命令
cfdisk 是一个基于ncurses的磁盘分区工具,提供了更易于使用和交互的界面。
cfdisk /dev/sdX:进入cfdisk交互界面,使用箭头键选择需要分区的磁盘,然后按照提示创建、删除或修改分区。
sfdisk 命令
sfdisk 命令用于备份和还原磁盘分区表。
sfdisk -l:列出所有的磁盘分区表。
sfdisk -d /dev/sdX > backup.txt:将指定磁盘的分区表备份到文件。
sfdisk /dev/sdX < backup.txt:将备份文件中的分区表恢复到指定磁盘。
其他相关命令
lsblk:用于列出系统中的所有块设备和磁盘分区。
mount:用于将分区挂载到Linux文件系统中。例如,mount /dev/sdX /mnt 将指定分区挂载到指定挂载点。
umount:用于卸载已挂载的分区。例如,umount /mnt 卸载指定挂载点。
df:用于查看文件系统的磁盘使用情况。
在使用这些命令时,需要以root权限运行,并且小心操作以避免数据丢失。建议在执行分区操作之前备份重要数据。
判断文件是否是shell脚本文件:
在 Linux 中,判断一个文件是否是 Shell 脚本文件通常涉及以下几个步骤:
检查文件扩展名:
虽然这不是一个可靠的方法,因为文件扩展名可以被更改或省略,但常见的 Shell 脚本文件通常以 .sh 结尾。你可以使用 ls 命令查看文件列表,并检查文件名的后缀。
sh
ls -l
如果文件名类似于 script.sh,那么它可能是一个 Shell 脚本。
检查文件内容:
更可靠的方法是检查文件的第一行是否包含 Shebang(#!),它指定了用于解释该脚本的 Shell。你可以使用 head、cat、less 或 more 命令来查看文件的前几行。
sh
head -n 1 script.sh
或者
sh
cat -n script.sh | head -n 1
如果输出类似于 #!/bin/bash 或 #!/usr/bin/env bash,那么该文件很可能是一个 Bash Shell 脚本。
检查文件权限:
虽然文件权限本身并不直接表明文件是 Shell 脚本,但可执行权限(x)的存在可能意味着该文件被设计为可执行脚本。你可以使用 ls -l 命令查看文件权限。
sh
ls -l script.sh
如果输出中的文件权限部分包含 x(例如 -rwxr-xr-x),则该文件具有可执行权限,可能是脚本或其他可执行文件。
尝试执行文件:
如果你怀疑一个文件是 Shell 脚本,并且想要验证它是否可以成功执行,你可以尝试运行它(当然,前提是你信任该文件的内容,并且它来自一个可信的来源)。
sh
./script.sh
或者,如果你不确定文件是否包含正确的 Shebang,你可以使用特定的 Shell 解释器来执行它:
sh
bash script.sh
如果文件是有效的 Shell 脚本,它应该会按预期运行。
使用 file 命令:
file 命令可以检测文件类型,但它可能无法准确识别所有 Shell 脚本,特别是如果脚本没有 Shebang 或扩展名。然而,它仍然是一个有用的工具,可以提供关于文件内容的线索。
sh
file script.sh
输出可能会是 ASCII text 或 Bourne-Again shell script text executable(对于 Bash 脚本)等。
综上所述,最可靠的方法是结合文件扩展名、Shebang、文件内容和执行结果来判断一个文件是否是 Shell 脚本文件。