扩散模型(公式推导)
本文很大程度上参考了Diffusion Model 扩散模型-[通俗易懂+代码讲解](一) - 知乎 (zhihu.com)以及https://blog.csdn.net/m0_63642362/article/details/127586200,https://segmentfault.com/a/1190000043744225
三篇文章都写得非常好
本文相当于作者自己的一个学习笔记。在一些步骤上进行了补充,但由于博主刚开始学习,还是存在一些不理解的地方。
模型训练
1. 前向扩散过程(Forward Diffusion Process)→图片中添加噪声;
2. 反向扩散过程(Reverse Diffusion Process)→去除图片中的噪声
前向扩散过程:不断往其中添加高斯噪声
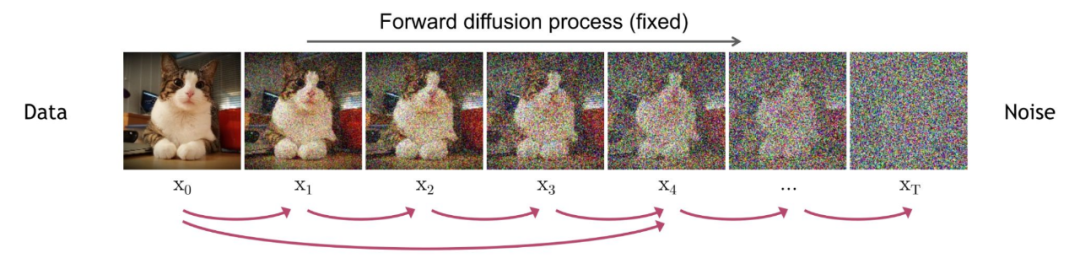
反向扩散过程:将噪声逐渐还原为原始图片
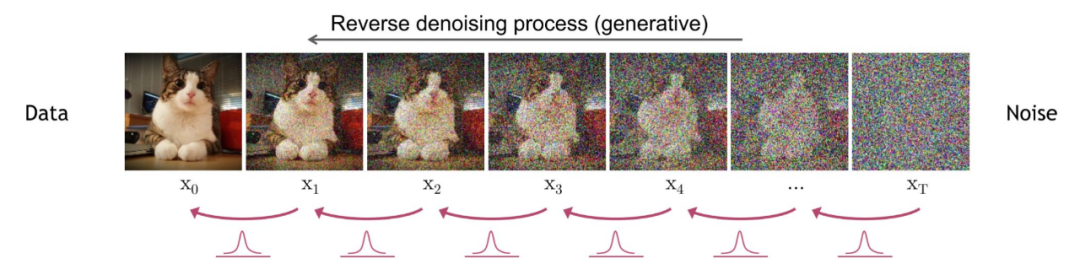
一些前置知识:
给定两个服从正态分布的独立随机变量 X ∼ N ( μ X , σ X 2 ) , Y ∼ N ( μ Y , σ Y 2 ) X \sim N(\mu_X, \sigma_X^2), Y \sim N(\mu_Y, \sigma_Y^2) X∼N(μX,σX2),Y∼N(μY,σY2),这两个分布的加和 Z = X + Y Z = X + Y Z=X+Y,同样服从正态分布 Z ∼ N ( μ X + μ Y , σ X 2 + σ Y 2 ) Z \sim N(\mu_X + \mu_Y, \sigma_X^2 + \sigma_Y^2) Z∼N(μX+μY,σX2+σY2)。这意味着两个独立正态分布随机变量的和是正态的,其平均值是两个平均值的和,其方差是两个方差的和。
前向扩散过程推导
定义前向传播过程:给定一组从真实数据分布中采样的数据 x 0 ∼ q ( x ) x_0∼q(x) x0∼q(x),即原始数据,分 T(注意,此处的 T 在训练过程中是一个可变参数)步来一步步对该样本叠加高斯噪声,最终的得到一系列经噪声叠加后的样本 x 1 , x 2 , … , x T x_1,x_2,…,x_T x1,x2,…,xT,其中,步数 T 的大小受 β t β_t βt 约束( β t ∈ ( 0 , 1 ) } t = 1 T {\beta_t \in (0, 1) \}_{t=1}^T } βt∈(0,1)}t=1T)。
(目的:使得数据分布逐渐趋于一个一致的简单分布(通常是标准正态分布)。这个过程可以表示为一个马尔科夫链,其中每一步的状态 x t x_t xt 都依赖于前一步的状态 x t − 1 x_{t-1} xt−1。)
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI) q表示已知 x t − 1 x_{t-1} xt−1时 x t x_t xt的概率分布,它是一个多元高斯分布。
参数分别为(当前状态,均值,协方差矩阵)。
我们想要表达从初始状态 x 0 x_0 x0 开始,到时刻 T T T 的所有状态 x 1 , x 2 , … , x T x_1, x_2, \dots, x_T x1,x2,…,xT 的联合分布 q ( x 1 : T ∣ x 0 ) q(x_{1:T} \mid x_0) q(x1:T∣x0)。
已知全概率公式形式为:
P ( A ) = ∑ i P ( A ∣ B i ) P ( B i ) P(A) = \sum_{i} P(A \mid B_i) P(B_i) P(A)=∑iP(A∣Bi)P(Bi)
同时我们有
P ( A , B ) = P ( A ∣ B ) P ( B ) P(A, B) = P(A \mid B) P(B) P(A,B)=P(A∣B)P(B)(AB联合分布概率,可以理解为同时发生的概率)
对于多个事件 X 1 , X 2 , … , X n X_1, X_2, \dots, X_n X1,X2,…,Xn,联合概率分布可以写成条件概率的乘积:
P ( X 1 , X 2 , … , X n ) = P ( X 1 ) P ( X 2 ∣ X 1 ) P ( X 3 ∣ X 1 , X 2 ) ⋯ P ( X n ∣ X 1 , X 2 , … , X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) P(X_2 \mid X_1) P(X_3 \mid X_1, X_2) \cdots P(X_n \mid X_1, X_2, \dots, X_{n-1}) P(X1,X2,…,Xn)=P(X1)P(X2∣X1)P(X3∣X1,X2)⋯P(Xn∣X1,X2,…,Xn−1)
根据链式法则,对于随机变量序列 X 0 , X 1 , … , X T X_0, X_1, \dots, X_T X0,X1,…,XT,我们有:
q ( x 0 , x 1 , … , x T ) = q ( x 0 ) q ( x 1 ∣ x 0 ) q ( x 2 ∣ x 0 , x 1 ) ⋯ q ( x T ∣ x 0 , x 1 , … , x T − 1 ) q(x_0, x_1, \dots, x_T) = q(x_0) q(x_1 \mid x_0) q(x_2 \mid x_0, x_1) \cdots q(x_T \mid x_0, x_1, \dots, x_{T-1}) q(x0,x1,…,xT)=q(x0)q(x1∣x0)q(x2∣x0,x1)⋯q(xT∣x0,x1,…,xT−1)
在扩散模型中,我们假设每个状态 x t x_t xt 只依赖于前一个状态 x t − 1 x_{t-1} xt−1 (马尔科夫性质),即:
q ( x t ∣ x 0 , x 1 , … , x t − 1 ) = q ( x t ∣ x t − 1 ) q(x_t \mid x_0, x_1, \dots, x_{t-1}) = q(x_t \mid x_{t-1}) q(xt∣x0,x1,…,xt−1)=q(xt∣xt−1)
因此,联合概率分布可以简化为:
q ( x 0 , x 1 , … , x T ) = q ( x 0 ) q ( x 1 ∣ x 0 ) q ( x 2 ∣ x 1 ) ⋯ q ( x T ∣ x t − 1 ) q(x_0, x_1, \dots, x_T) = q(x_0) q(x_1 \mid x_0) q(x_2 \mid x_1) \cdots q(x_T \mid x_{t-1}) q(x0,x1,…,xT)=q(x0)q(x1∣x0)q(x2∣x1)⋯q(xT∣xt−1)
在给定初始状态 x 0 x_0 x0 的情况下,所有中间状态的条件联合分布为:
q ( x 1 : T ∣ x 0 ) = q ( x 1 ∣ x 0 ) q ( x 2 ∣ x 1 ) ⋯ q ( x T ∣ x t − 1 ) = ∏ t = 1 T q ( x t ∣ x t − 1 ) q(x_{1:T} \mid x_0) = q(x_1 \mid x_0) q(x_2 \mid x_1) \cdots q(x_T \mid x_{t-1}) = \prod_{t=1}^{T} q(x_t \mid x_{t-1}) q(x1:T∣x0)=q(x1∣x0)q(x2∣x1)⋯q(xT∣xt−1)=∏t=1Tq(xt∣xt−1)
其间,原始数据 x 0 x_0 x0 在前向扩散的 t t t步数的迭代,逐渐失去其独特鲜明的特征,最终当 T → ∞ T \rightarrow \infty T→∞, x T x_T xT 等价于一个符合各向同性的高斯分布噪声,如图所示。
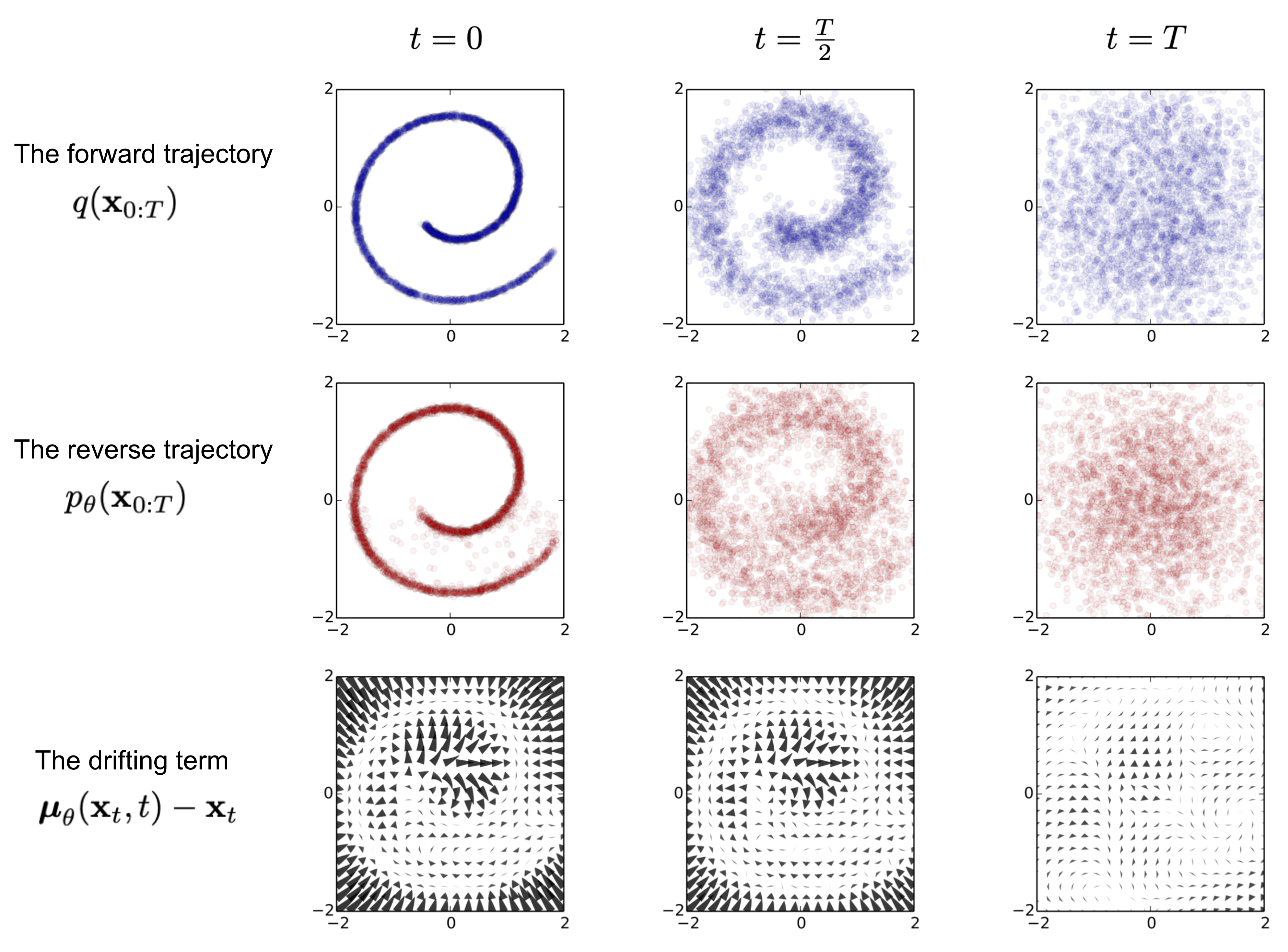
往右边就是前向扩散,往左边就是逆向扩散
高斯噪声(Gaussian noise),也叫做白噪声 :概率密度函数遵循高斯分布(也称为正态分布)
在任意时间步 t t t 的 x t x_t xt 进行采样。这里定义 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 且 α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod_{i=1}^{t} \alpha_i αˉt=∏i=1tαi,给定高斯噪声: ϵ t − 1 , ϵ t − 2 , ⋯ ∼ N ( 0 , I ) \epsilon_{t-1}, \epsilon_{t-2}, \dots \sim N(0, I) ϵt−1,ϵt−2,⋯∼N(0,I)。
x t = α t x t − 1 + 1 − α t ϵ t − 1 x_t = \sqrt{\alpha_t} x_{t-1} + \sqrt{1 - \alpha_t} \epsilon_{t-1} xt=αtxt−1+1−αtϵt−1 (这里开始,相当于每一步加一点噪声)
= α t α t − 1 x t − 2 + α t − α t α t − 1 ϵ t − 2 + 1 − α t ϵ t − 1 = \sqrt{\alpha_t \alpha_{t-1}} x_{t-2} + \sqrt{\alpha_t - \alpha_t \alpha_{t-1}} \epsilon_{t-2} + \sqrt{1 - \alpha_t} \epsilon_{t-1} =αtαt−1xt−2+αt−αtαt−1ϵt−2+1−αtϵt−1
1 − α t ϵ t − 1 \sqrt{1 - \alpha_t} \epsilon_{t-1} 1−αtϵt−1 和 α t − α t α t − 1 ϵ t − 2 \sqrt{\alpha_t - \alpha_t \alpha_{t-1}} \epsilon_{t-2} αt−αtαt−1ϵt−2 分别表示 ϵ t − 1 ∼ N ( 0 , σ 1 2 I ) \epsilon_{t-1} \sim N(0, \sigma_1^2 I) ϵt−1∼N(0,σ12I) 和 ϵ t − 2 ∼ N ( 0 , σ 2 2 I ) \epsilon_{t-2} \sim N(0, \sigma_2^2 I) ϵt−2∼N(0,σ22I) ,方差变为原分布的 ( 1 − α t ) (1 - \alpha_t) (1−αt) 与 ( α t − α t α t − 1 ) (\alpha_t - \alpha_t \alpha_{t-1}) (αt−αtαt−1) 倍,
新的分布加和得到 ϵ t − 2 ∼ N ( 0 , ( σ 1 2 + σ 2 2 ) I ) \epsilon_{t-2} \sim N(0, (\sigma_1^2 + \sigma_2^2)I) ϵt−2∼N(0,(σ12+σ22)I),该分布方差为 ( α t − α t α t − 1 ) + 1 − α t = 1 − α t α t − 1 (\alpha_t - \alpha_t \alpha_{t-1}) + 1 - \alpha_t = 1 - \alpha_t \alpha_{t-1} (αt−αtαt−1)+1−αt=1−αtαt−1 的倍数。
x
t
=
α
t
α
t
−
1
x
t
−
2
+
1
−
α
t
α
t
−
1
ϵ
ˉ
t
−
2
x_t = \sqrt{\alpha_t \alpha_{t-1}} x_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\epsilon}_{t-2}
xt=αtαt−1xt−2+1−αtαt−1ϵˉt−2
=
⋯
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
= \dots = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon
=⋯=αˉtx0+1−αˉtϵ 其中,
ϵ
ˉ
t
−
2
\bar{\epsilon}_{t-2}
ϵˉt−2 为合并两个高斯分布
ϵ
t
−
1
\epsilon_{t-1}
ϵt−1 和
ϵ
t
−
2
\epsilon_{t-2}
ϵt−2 后的分布表示。
由此推导出的公式记为 x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon xt=αˉtx0+1−αˉtϵ (由原始公式推导出来)
这样就可以得到在已知
x
0
x_0
x0的情况下,
x
t
x_t
xt的概率分布为:
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
ˉ
t
x
0
,
(
1
−
α
ˉ
t
)
I
)
q(x_t \mid x_0) = N(x_t; \sqrt{\bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t)I)
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
(这个是由于噪声的均值为0,协方差为
I
I
I)
逆向扩散过程(Reverse diffusion process)
扩散过程是将数据噪音化,反向过程就是一个去噪的过程。逆向扩散过程中,我们将以高斯噪声 x T ∼ N ( 0 , I ) x_T \sim N(0, I) xT∼N(0,I) 作为输入,从 q ( x t − 1 ∣ x t ) q(x_{t-1} \mid x_t) q(xt−1∣xt) 中采样,推断并重构出真实样本。
训练出一个模型来对这些噪声的条件概率进行预测:
将前向传播每步生成的真实噪声记录下来作为标签,在模型做逆向扩散时,即可对前向扩散中所产生的高斯噪声进行预测,并一步一步推断,以还原最初始的样本数据。
而在去除 x t − 1 x_{t-1} xt−1 所加的高斯噪声的后验估计分布为:
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , ∑ θ ( x t , t ) ) p_\theta (x_{t-1} \mid x_t) = N(x_{t-1}; \mu_\theta(x_t, t), \sum_{\theta} (x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),∑θ(xt,t)) 这里面的参数代表神经网络估计的值
虽然分布 q ( x t − 1 ∣ x t ) q(x_{t-1} \mid x_t) q(xt−1∣xt) 是无法直接计算得到的,但是加上条件 x 0 x_0 x0 的后验分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1} \mid x_t, x_0) q(xt−1∣xt,x0) 即可通过计算处理而得。
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
~
(
x
t
,
x
0
)
,
β
~
t
I
)
q(x_{t-1} \mid x_t, x_0) = q(x_{t-1} \mid x_t) = N(x_{t-1}; \tilde{\mu}(x_t, x_0), \tilde{\beta}_t I)
q(xt−1∣xt,x0)=q(xt−1∣xt)=N(xt−1;μ~(xt,x0),β~tI)
(最左边的式子表示在已知
x
t
x_t
xt和已知
x
0
x_0
x0的情况下
x
t
−
1
的概率
x_{t-1}的概率
xt−1的概率,别搞错了)
公式推导
-
联合概率可以通过条件概率表示为:
q ( x t − 1 , x t ∣ x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q(x_{t-1}, x_t \mid x_0) = q(x_t \mid x_{t-1}, x_0) q(x_{t-1} \mid x_0) q(xt−1,xt∣x0)=q(xt∣xt−1,x0)q(xt−1∣x0) -
同时,也可以表示为:
q ( x t − 1 , x t ∣ x 0 ) = q ( x t − 1 ∣ x t , x 0 ) q ( x t ∣ x 0 ) q(x_{t-1}, x_t \mid x_0) = q(x_{t-1} \mid x_t, x_0) q(x_t \mid x_0) q(xt−1,xt∣x0)=q(xt−1∣xt,x0)q(xt∣x0)
联立两个式子,可以得到
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
q(x_{t-1} \mid x_t, x_0) = \frac{q(x_t \mid x_{t-1}, x_0) q(x_{t-1} \mid x_0)}{q(x_t \mid x_0)}
q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)
这时候右边三个式子都是已知的了
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t \mid x_0) = N(x_t; \sqrt{\bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t)I) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I) *已知1
q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β t x t − 1 , β t I ) q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI) *已知2
那么
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q
(
x
t
∣
x
0
)
q(x_{t-1} \mid x_t, x_0) = \frac{q(x_t \mid x_{t-1}, x_0) q(x_{t-1} \mid x_0)}{q(x_t \mid x_0)}
q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)
∝ e − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) \propto e^{-\frac{1}{2} \left( \frac{(x_t - \sqrt{\alpha_t} x_{t-1})^2}{\beta_t} + \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}} x_0)^2}{1 - \bar{\alpha}_{t-1}} - \frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{1 - \bar{\alpha}_t} \right)} ∝e−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2)
= e − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x t − 1 x 0 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) = e^{-\frac{1}{2} \left( \frac{x_t^2 - 2 \sqrt{\alpha_t} x_t x_{t-1} + \alpha_t x_{t-1}^2}{\beta_t} + \frac{x_{t-1}^2 - 2 \sqrt{\bar{\alpha}_{t-1}} x_{t-1} x_0 + \bar{\alpha}_{t-1} x_0^2}{1 - \bar{\alpha}_{t-1}} - \frac{(x_t - \sqrt{\bar{\alpha}_t} x_0)^2}{1 - \bar{\alpha}_t} \right)} =e−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1xt−1x0+αˉt−1x02−1−αˉt(xt−αˉtx0)2)
= e − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) = e^{-\frac{1}{2} \left( \left( \frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}} \right) x_{t-1}^2 - \left( \frac{2 \sqrt{\alpha_t}}{\beta_t} x_t + \frac{2 \sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} x_0 \right) x_{t-1} + C(x_t, x_0) \right)} =e−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0))
这是一个类似高斯分布的式子,观察高斯分布形式:
e
−
1
2
(
(
x
t
−
1
−
μ
)
2
σ
2
)
e^{-\frac{1}{2} \left( \frac{(x_{t-1} - \mu)^2}{\sigma^2} \right)}
e−21(σ2(xt−1−μ)2)。
配方之后可以得到:
( α t β t + 1 1 − α ˉ t − 1 ) ( x t − 1 2 − 2 ( α t x t β t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) x t − 1 + ( α t x t β t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) 2 ) \left( \frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}} \right) \left( x_{t-1}^2 - 2 \left( \frac{\sqrt{\alpha_t} x_t}{\beta_t} + \frac{\sqrt{\bar{\alpha}_{t-1}} x_0}{1 - \bar{\alpha}_{t-1}} \right) x_{t-1} + \left( \frac{\sqrt{\alpha_t} x_t}{\beta_t} + \frac{\sqrt{\bar{\alpha}_{t-1}} x_0}{1 - \bar{\alpha}_{t-1}} \right)^2 \right) (βtαt+1−αˉt−11)(xt−12−2(βtαtxt+1−αˉt−1αˉt−1x0)xt−1+(βtαtxt+1−αˉt−1αˉt−1x0)2)
那么均值和方差就可以表示为:
方差:
β ~ t = 1 ( α t β t + 1 1 − α ˉ t − 1 ) = 1 ( α t ( 1 − α ˉ t − 1 ) + β t β t ( 1 − α ˉ t − 1 ) ) = 1 ( 1 − β t − α ˉ t − 1 + β t β t ( 1 − α ˉ t − 1 ) ) = 1 − α ˉ t − 1 1 − α ˉ t β t \tilde{\beta}_t = \frac{1}{\left( \frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}} \right)} = \frac{1}{\left( \frac{\alpha_t (1 - \bar{\alpha}_{t-1}) + \beta_t}{\beta_t (1 - \bar{\alpha}_{t-1})} \right)} = \frac{1}{\left( \frac{1 - \beta_t - \bar{\alpha}_{t-1} + \beta_t}{\beta_t (1 - \bar{\alpha}_{t-1})} \right)} = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t β~t=(βtαt+1−αˉt−11)1=(βt(1−αˉt−1)αt(1−αˉt−1)+βt)1=(βt(1−αˉt−1)1−βt−αˉt−1+βt)1=1−αˉt1−αˉt−1βt
方差的所有参数都是已知的, α t \alpha_t αt, β t \beta_t βt都是已知的,随t不断变化的可以设置的参数。
均值:
μ
~
t
(
x
t
,
x
0
)
=
(
α
t
β
t
x
t
+
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
(
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
)
=
(
α
t
β
t
x
t
+
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
1
(
α
t
β
t
+
1
1
−
α
ˉ
t
−
1
)
=
(
α
t
β
t
x
t
+
α
ˉ
t
−
1
1
−
α
ˉ
t
−
1
x
0
)
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
\tilde{\mu}_t (x_t, x_0) = \frac{\left( \frac{\sqrt{\alpha_t}}{\beta_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} x_0 \right)}{\left( \frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}} \right)} =\left( \frac{\sqrt{\alpha_t}}{\beta_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} x_0 \right) \frac{1}{\left( \frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}} \right)} = \left( \frac{\sqrt{\alpha_t}}{\beta_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} x_0 \right) \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \beta_t
μ~t(xt,x0)=(βtαt+1−αˉt−11)(βtαtxt+1−αˉt−1αˉt−1x0)=(βtαtxt+1−αˉt−1αˉt−1x0)(βtαt+1−αˉt−11)1=(βtαtxt+1−αˉt−1αˉt−1x0)1−αˉt1−αˉt−1βt
= ( α t ( 1 − α ˉ t − 1 ) β t ( 1 − α ˉ t ) x t + α ˉ t − 1 β t ( 1 − α ˉ t − 1 ) ( 1 − α ˉ t ) x 0 ) = α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 β t x 0 β t ( 1 − α ˉ t ) = \left( \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1})}{\beta_t (1 - \bar{\alpha}_t)} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{(1 - \bar{\alpha}_{t-1}) (1 - \bar{\alpha}_t)} x_0 \right) = \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1}) x_t + \sqrt{\bar{\alpha}_{t-1}} \beta_t x_0}{\beta_t (1 - \bar{\alpha}_t)} =(βt(1−αˉt)αt(1−αˉt−1)xt+(1−αˉt−1)(1−αˉt)αˉt−1βtx0)=βt(1−αˉt)αt(1−αˉt−1)xt+αˉt−1βtx0
= α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 β t x 0 1 − α ˉ t = \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1}) x_t + \sqrt{\bar{\alpha}_{t-1}} \beta_t x_0}{1 - \bar{\alpha}_t} =1−αˉtαt(1−αˉt−1)xt+αˉt−1βtx0
= α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 β t x 0 1 − α ˉ t = \sqrt{\alpha_t (1 - \bar{\alpha}_{t-1}) x_t + \sqrt{\bar{\alpha}_{t-1}} \beta_t x_0}{1 - \bar{\alpha}_t} =αt(1−αˉt−1)xt+αˉt−1βtx01−αˉt
由于
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon
xt=αˉtx0+1−αˉtϵ,
x
0
=
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
ϵ
)
x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}} (x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon)
x0=αˉt1(xt−1−αˉtϵ)
那么:
μ
~
t
=
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
+
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
1
α
ˉ
t
(
x
t
−
1
−
α
ˉ
t
ϵ
)
\tilde{\mu}_t = \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}} (x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon)
μ~t=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵ)
= α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t 1 α ˉ t ( x t − 1 − α ˉ t ϵ ) = \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}} (x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon) =1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−1−αˉtϵ)
= 1 α ˉ t ( x t − 1 − α t 1 − α ˉ t ϵ ) = \frac{1}{\sqrt{\bar{\alpha}_t}} \left( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon \right) \quad =αˉt1(xt−1−αˉt1−αtϵ)
这个 x t x_t xt会受到不同 x 0 x_0 x0影响,每次不是确定的。
优化目标
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , ∑ θ ( x t , t ) ) p_\theta (x_{t-1} \mid x_t) = N(x_{t-1}; \mu_\theta(x_t, t), \sum_{\theta} (x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),∑θ(xt,t)) 这里面的参数代表神经网络估计的值
现在,我们要预测的就是这里的 μ θ ( x t , t ) \mu_\theta(x_t, t) μθ(xt,t)
我们先看整体损失函数:
− log ( P θ ( X 0 ) ) -\log (P_\theta (X_0)) −log(Pθ(X0)),希望神经网络的参数 θ \theta θ 可以使得生成 X 0 X_0 X0 的概率越来越大越好。
前置知识 Kullback-Leibler散度(相对熵):用于衡量两个概率分布之间的差异。具体来说,它衡量的是当一个分布𝑞被另一个分布p 近似时,所损失的信息。
也就是说,当使用分布
p
θ
p_\theta
pθ来近似分布𝑞时,会丢失多少信息。数学表达式为:
D
K
L
(
q
∥
p
)
=
∑
x
q
(
x
)
log
q
(
x
)
p
(
x
)
D_{KL}(q \parallel p) = \sum_x q(x) \log \frac{q(x)}{p(x)}
DKL(q∥p)=∑xq(x)logp(x)q(x)
由于损失函数无法直接计算,我们选择:
−
log
p
θ
(
x
0
)
≤
−
log
p
θ
(
x
0
)
+
D
K
L
(
q
(
x
1
:
T
∣
x
0
)
∥
p
θ
(
x
1
:
T
∣
x
0
)
)
- \log p_\theta (x_0) \leq - \log p_\theta (x_0) + D_{KL}(q(x_{1:T} \mid x_0) \parallel p_\theta (x_{1:T} \mid x_0))
−logpθ(x0)≤−logpθ(x0)+DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))
= D K L ( q ( x 1 : T ∣ x 0 ) ∥ p θ ( x 1 : T ∣ x 0 ) ) = E x 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 1 : T ∣ x 0 ) ] =D_{KL}(q(x_{1:T} \mid x_0) \parallel p_\theta (x_{1:T} \mid x_0)) = \mathbb{E}_{x_{1:T} \sim q(x_{1:T} \mid x_0)} \left[ \log \frac{q(x_{1:T} \mid x_0)}{p_\theta (x_{1:T} \mid x_0)} \right] =DKL(q(x1:T∣x0)∥pθ(x1:T∣x0))=Ex1:T∼q(x1:T∣x0)[logpθ(x1:T∣x0)q(x1:T∣x0)]
由于 p θ ( x 0 : T ) p θ ( x 0 ) ← p θ ( x 0 , x 1 : T ) p θ ( x 0 ) ← p θ ( x 0 ∣ x 1 : T ) p θ ( x 1 : T ) p θ ( x 0 ) \frac{p_\theta (x_{0:T})}{p_\theta (x_0)} \leftarrow \frac{p_\theta (x_0, x_{1:T})}{p_\theta (x_0)} \leftarrow \frac{p_\theta (x_0 \mid x_{1:T}) p_\theta (x_{1:T})}{p_\theta (x_0)} pθ(x0)pθ(x0:T)←pθ(x0)pθ(x0,x1:T)←pθ(x0)pθ(x0∣x1:T)pθ(x1:T)
则 = − log p θ ( x 0 ) + E x 1 : T ∼ q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) / p θ ( x 0 ) ] = -\log p_\theta (x_0) + \mathbb{E}_{x_{1:T} \sim q(x_{1:T} \mid x_0)} \left[ \log \frac{q(x_{1:T} \mid x_0)}{p_\theta (x_{0:T}) / p_\theta (x_0)} \right] =−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]
= − log p θ ( x 0 ) + E q [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] + log p θ ( x 0 ) = -\log p_\theta (x_0) + \mathbb{E}_q \left[ \log \frac{q(x_{1:T} \mid x_0)}{p_\theta (x_{0:T})} \right] + \log p_\theta (x_0) =−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)]+logpθ(x0)
=
E
q
[
log
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
]
= \mathbb{E}_q \left[ \log \frac{q(x_{1:T} \mid x_0)}{p_\theta (x_{0:T})} \right]
=Eq[logpθ(x0:T)q(x1:T∣x0)]
(由于最右边是一个常数值,对它取期望的操作相当于它本身)
(接下来的推导又会用到:
q
(
x
t
−
1
,
x
t
∣
x
0
)
=
q
(
x
t
∣
x
t
−
1
,
x
0
)
q
(
x
t
−
1
∣
x
0
)
q(x_{t-1}, x_t \mid x_0) = q(x_t \mid x_{t-1}, x_0) q(x_{t-1} \mid x_0)
q(xt−1,xt∣x0)=q(xt∣xt−1,x0)q(xt−1∣x0)
q
(
x
t
−
1
,
x
t
∣
x
0
)
=
q
(
x
t
−
1
∣
x
t
,
x
0
)
q
(
x
t
∣
x
0
)
q(x_{t-1}, x_t \mid x_0) = q(x_{t-1} \mid x_t, x_0) q(x_t \mid x_0)
q(xt−1,xt∣x0)=q(xt−1∣xt,x0)q(xt∣x0))
E q [ log ( ∏ t = 1 T q ( x t ∣ x t − 1 ) p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) ) ] E_q \left[ \log \left( \frac{\prod_{t=1}^{T} q(x_t | x_{t-1})}{p_\theta (x_T) \prod_{t=1}^{T} p_\theta (x_{t-1} | x_t)} \right) \right] Eq[log(pθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1))]
= E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E_q \left[ -\log p_\theta (x_T) + \sum_{t=2}^{T} \log \frac{q(x_t | x_{t-1})}{p_\theta (x_{t-1} | x_t)} + \log \frac{q(x_1 | x_0)}{p_\theta (x_0 | x_1)} \right] =Eq[−logpθ(xT)+∑t=2Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]
= E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E_q \left[ -\log p_\theta (x_T) + \sum_{t=2}^{T} \log \frac{q(x_t | x_{t-1})}{p_\theta (x_{t-1} | x_t)} + \log \frac{q(x_1 | x_0)}{p_\theta (x_0 | x_1)} \right] =Eq[−logpθ(xT)+∑t=2Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]
= E q [ − log p θ ( x T ) + ∑ t = 2 T log ( q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x t − 1 ∣ x 0 ) p θ ( x t − 1 ∣ x t ) ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E_q \left[ -\log p_\theta (x_T) + \sum_{t=2}^{T} \log \left( \frac{q(x_t | x_{t-1}) q(x_{t-1} | x_0)}{q(x_{t-1} | x_0) p_\theta (x_{t-1} | x_t)} \right) + \log \frac{q(x_1 | x_0)}{p_\theta (x_0 | x_1)} \right] =Eq[−logpθ(xT)+∑t=2Tlog(q(xt−1∣x0)pθ(xt−1∣xt)q(xt∣xt−1)q(xt−1∣x0))+logpθ(x0∣x1)q(x1∣x0)]
$ =E_q \left[ -\log p_\theta (x_T) + \sum_{t=2}^{T} \log \frac{q(x_t | x_{t-1})}{p_\theta (x_{t-1} | x_t)} + \sum_{t=2}^{T} \log \frac{q(x_{t-1} | x_0)}{q(x_{t-1} | x_0)} + \log \frac{q(x_1 | x_0)}{p_\theta (x_0 | x_1)} \right]$
= E q [ − log p θ ( x T ) + ∑ t = 2 T log q ( x t ∣ x t − 1 ) p θ ( x t − 1 ∣ x t ) + log q ( x T ∣ x 0 ) q ( x 1 ∣ x 0 ) + log q ( x 1 ∣ x 0 ) p θ ( x 0 ∣ x 1 ) ] = E_q \left[ -\log p_\theta (x_T) + \sum_{t=2}^{T} \log \frac{q(x_t | x_{t-1})}{p_\theta (x_{t-1} | x_t)} + \log \frac{q(x_T | x_0)}{q(x_1 | x_0)} + \log \frac{q(x_1 | x_0)}{p_\theta (x_0 | x_1)} \right] =Eq[−logpθ(xT)+∑t=2Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]
= E q [ log q ( x T ∣ x 0 ) p θ ( x T ) + ∑ t = 2 T log q ( x t − 1 ∣ x 0 ) p θ ( x t − 1 ∣ x t ) − log p θ ( x 0 ∣ x 1 ) ] = E_q \left[ \log \frac{q(x_T | x_0)}{p_\theta (x_T)} + \sum_{t=2}^{T} \log \frac{q(x_{t-1} | x_0)}{p_\theta (x_{t-1} | x_t)} - \log p_\theta (x_0 | x_1) \right] =Eq[logpθ(xT)q(xT∣x0)+∑t=2Tlogpθ(xt−1∣xt)q(xt−1∣x0)−logpθ(x0∣x1)]
= E q [ D K L ( q ( x T ∣ x 0 ) ∥ p θ ( x T ) ) + ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) − log p θ ( x 0 ∣ x 1 ) ] =E_q \left[ D_{KL}(q(x_T | x_0) \parallel p_\theta (x_T)) + \sum_{t=2}^{T} D_{KL}(q(x_{t-1} | x_t, x_0) \parallel p_\theta (x_{t-1} | x_t)) - \log p_\theta (x_0 | x_1) \right] =Eq[DKL(q(xT∣x0)∥pθ(xT))+∑t=2TDKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−logpθ(x0∣x1)]
这时候第一项没有可以学习的参数,就是一个正向过程,同时 x T x_T xT已知
最后一项不要了
根据上文,我们现在有:
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
q
(
x
t
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
~
(
x
t
,
x
0
)
,
β
~
t
I
)
q(x_{t-1} \mid x_t, x_0) = q(x_{t-1} \mid x_t) = N(x_{t-1}; \tilde{\mu}(x_t, x_0), \tilde{\beta}_t I)
q(xt−1∣xt,x0)=q(xt−1∣xt)=N(xt−1;μ~(xt,x0),β~tI)
p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , ∑ θ ( x t , t ) ) p_\theta (x_{t-1} \mid x_t) = N(x_{t-1}; \mu_\theta(x_t, t), \sum_{\theta} (x_t, t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),∑θ(xt,t))
真实值
μ
~
t
=
1
α
ˉ
t
(
x
t
−
1
−
α
t
1
−
α
ˉ
t
ϵ
)
\tilde{\mu}_t= \frac{1}{\sqrt{\bar{\alpha}_t}} \left( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon \right) \quad
μ~t=αˉt1(xt−1−αˉt1−αtϵ)
参数化表示预测值
μ
θ
(
x
t
,
t
)
=
1
α
t
(
x
t
−
1
−
α
t
1
−
α
ˉ
t
ϵ
θ
(
x
t
,
t
)
)
\mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta (x_t, t) \right)
μθ(xt,t)=αt1(xt−1−αˉt1−αtϵθ(xt,t))
用了一种均方误差表示法来计算误差:
L t = 1 2 σ t 2 ∥ μ ~ t ( x t , x 0 ) − μ θ ( x t , t ) ∥ 2 L_t = \frac{1}{2\sigma_t^2} \| \tilde{\mu}_t (x_t, x_0) - \mu_\theta (x_t, t) \|^2 Lt=2σt21∥μ~t(xt,x0)−μθ(xt,t)∥2
↓ 将 μ 的表达式代入 \downarrow \text{将} \mu 的表达式代入 ↓将μ的表达式代入
= 1 2 σ t 2 ∥ 1 α t ( x t − β t 1 − α ˉ t ϵ ) − 1 α t ( x t − β t 1 − α ˉ t ϵ θ ( x t , t ) ) ∥ 2 = \frac{1}{2\sigma_t^2} \| \frac{1}{\sqrt{\alpha_t}} (x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon) - \frac{1}{\sqrt{\alpha_t}} (x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta (x_t, t)) \|^2 =2σt21∥αt1(xt−1−αˉtβtϵ)−αt1(xt−1−αˉtβtϵθ(xt,t))∥2
= β t 2 2 σ t 2 α t ( 1 − α ˉ t ) ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 = \frac{\beta_t^2}{2\sigma_t^2 \alpha_t (1 - \bar{\alpha}_t)} \| \epsilon - \epsilon_\theta (x_t, t) \|^2 =2σt2αt(1−αˉt)βt2∥ϵ−ϵθ(xt,t)∥2
如果把前面的系数全部丢掉的话,模型的效果更好。最终,我们就能得到一个非常简单的优化目标:
= ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 = \| \epsilon - \epsilon_\theta (x_t, t) \|^2 =∥ϵ−ϵθ(xt,t)∥2