在开发检索增强生成(Retrieval-Augmented Generation, RAG)应用的过程中,处理文档的分块(Chunking)无疑是最为复杂的任务之一。分块究竟是什么?它指的是将信息切割并整理成易于处理或富有意义小组的行为,这些小组随后可以被送入我们的语言模型中进行处理。虽然这个概念乍听之下似乎简单直白,但实际上,其执行的细节才是成功的关键。根据文本的具体特征,你可能需要在将文本输入到语言模型之前,采取不同的策略来进行分块。在本文中,我们将探讨不同分块策略对同一数据集的影响。
在RAG应用的领域内,开发者们经常面临的一个挑战是如何有效地将长篇文档输入到大型语言模型(Large Language Models, LLMs)中。随着像GPT-4这样的LLMs技术的不断演进,它们生成高质量、与上下文紧密相关的回答的能力,越来越依赖于输入数据的质量和结构。因此,将信息分割并组织成易于管理的段落变得至关重要。
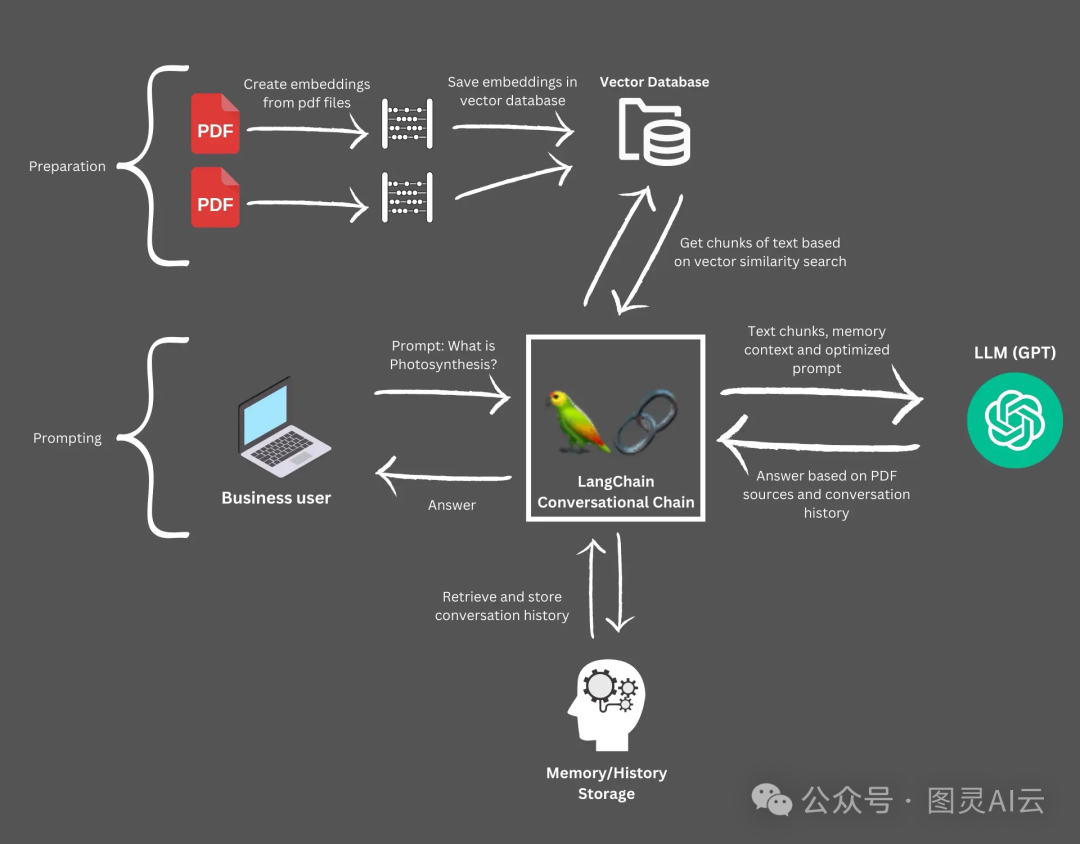
文本分割不单纯是一个技术性的步骤;它是一个战略性的过程,直接关系到LLM驱动应用的性能和可靠性。如果分割不当,大型文档可能会使LLMs不堪重负,导致输出结果不准确、不完整或与预期无关。开发者们常常在寻找一个最佳的分块策略上费尽心思,这个策略需要在文本段的大小和连贯性之间找到平衡点,确保每个分块既保留了足够的上下文以保持其有用性,同时又足够简洁,以便模型能够高效地处理。
LangChain是一个用于大型语言模型(LLM)的编排框架。它提供了一些内置的工具,用于文本的分割和文档的加载。本文的重点是最小化LLMs的使用,而主要关注于设置分块参数。在概念层面上,我们将会编写一个函数,该函数接受参数以加载文档并进行分块处理。此函数会打印出检索到的分块。为了进行实验,我们通过这个函数运行了多种分块参数,尤其是对块的大小进行了深入的探索。
LangChain代码导入和设置
在本小节中,我们将重点关注代码的导入和初步设置环节。您可能会立刻注意到,下方的代码示例中包含了大量的导入语句。其中,os和dotenv这两个模块的使用较为频繁,但我不会对它们进行详细解释。简而言之,它们主要用于处理环境变量。接下来,我们将通过Python和pymilvus客户端,逐步深入了解LangChain中的文本分割功能。
在代码的顶部,您会看到我们有三个用于文档获取的导入。首先是NotionDirectoryLoader,它负责加载包含Markdown或Notion格式文档的目录。紧随其后的是Markdown标题分割器和递归字符文本分割器。这些工具分别根据文档中的标题(标题分割器)或一系列预定义的字符断点(递归分割器)来分割Markdown文档中的文本内容。
随后,我们引入了检索器相关的模块。Milvus作为我们的向量数据库,OpenAIEmbeddings作为我们的嵌入模型,而OpenAI则是我们的LLM。SelfQueryRetriever是LangChain提供的原生检索器,它使得向量数据库能够执行“自我查询”操作。
我们从LangChain导入的最后一个模块是AttributeInfo,它负责向自查询检索器传递带有信息的属性。最后,我想简单讨论一下pymilvus的导入。这些导入严格来说是为了实用目的;即使不使用它们,我们也可以在LangChain中操作向量数据库。我使用这些导入主要是为了在最后清理数据库。
在我们着手编写函数之前,我们会加载环境变量并声明一些常量。headers_to_split_on变量极为重要——它列出了所有我们期望在Markdown文档中识别并分割的标题。而path变量则简单地指示LangChain在何处查找Notion文档。
import os
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from pymilvus import connections, utility
from dotenv import load_dotenv
load_dotenv()
my_test_uri = os.getenv("YOUR_CLUSTER_01_URI")
my_test_token = os.getenv("YOUR_CLUSTER_01_TOKEN")
headers_to_split_on = [
("##", "Section"),
]
path='./notion_docs'
在本文中,构建实验函数是最为关键的一环。正如之前所述,该函数接收一系列参数,这些参数用于文档的摄取和实验过程。具体来说,我们需要指定文档的存储路径、用于分割文档的标题(splitters)、块的大小、块大小的最大重叠部分,以及一个指示是否在实验结束后通过删除集合来进行清理的选项。默认情况下,集合删除选项是开启的。
我们尽可能减少集合的创建和删除,以避免不必要的开销。
首先,我们使用Notion目录加载器从指定路径加载文档。请注意,我们仅提取第一个网页的HTML内容(实际上只有一个页面)。
随后,我们获取分割器。这里我们先利用Markdown分割器来根据之前传递的标题进行分割。之后,我们采用递归分割方法,根据块大小和重叠部分对文档进行进一步的分割。
这就是我们进行的所有分割工作。分割完成后,我们为分割结果指定一个集合名称,并利用默认的环境变量、OpenAI嵌入模型、分割结果和集合名称初始化一个LangChain Milvus实例。此外,我们还通过AttributeInfo对象创建了一个元数据字段列表,以便告知自查询检索器我们拥有“节(Section)”这一属性。
在完成所有这些设置后,我们获取LLM,并将其传递给一个Python自查询检索器。之后,当我们提出与文档相关的问题时,检索器便开始发挥其魔力。我已经设置了系统,使其能够在测试过程中告诉我们当前正在测试的分块策略。最后,如果需要,我们可以删除集合。
def test_langchain_chunking(docs_path, splitters, chunk_size, chunk_overlap, drop_collection=True):
path = docs_path
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file = docs[0].page_content
# 根据页面中的节标题创建分组
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=splitters)
md_header_splits = markdown_splitter.split_text(md_file)
# 定义文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits = text_splitter.split_documents(md_header_splits)
test_collection_name = f"EngineeringNotionDoc_{chunk_size}_{chunk_overlap}"
vectordb = Milvus.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings(),
connection_args={"uri": my_test_uri,
"token": my_test_token},
collection_name=test_collection_name)
metadata_fields_info = [
AttributeInfo(
name="Section",
description="Part of the document that the text comes from",
type="string or list[string]"
),
]
document_content_description = "Major sections of the document"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
res = retriever.get_relevant_documents("What makes a distinguished engineer?")
print(f"""Responses from chunking strategy:
{chunk_size}, {chunk_overlap}""")
for doc in res:
print(doc)
# 这只是初步的清理工作,未来可以进一步优化
# 需要考虑多种实际应用场景
if drop_collection:
connections.connect(uri=my_test_uri, token=my_test_token)
utility.drop_collection(test_collection_name)
LangChain测试和结果
现在,让我们进入最让人心潮澎湃的环节——展示测试结果。
以下简洁的代码片段展示了我们如何通过循环执行我们的函数来进行实验。我设计了五个实验,本文中测试了分块策略的长度从32到512,以2的幂次递增,重叠部分从4到64,同样以2的幂次递增。在测试过程中,我们遍历元组列表并调用之前编写的函数。
chunking_tests = [(32, 4), (64, 8), (128, 16), (256, 32), (512, 64)]
for test in chunking_tests:
test_langchain_chunking(path, headers_to_split_on, test[0], test[1])
这是整个输出的概览。接下来,让我们深入探讨个别的输出结果。请记住,我们选择的示例问题是:“What makes a distinguished engineer?”
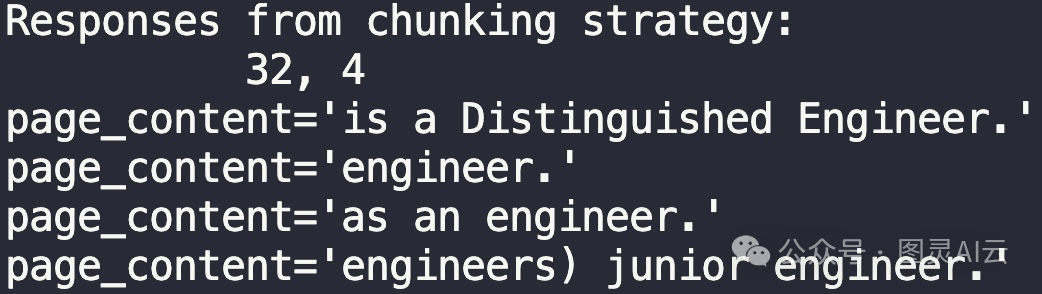
从这个结果中,我们可以看出32的长度太短了。这个长度下的句子几乎没有用处。
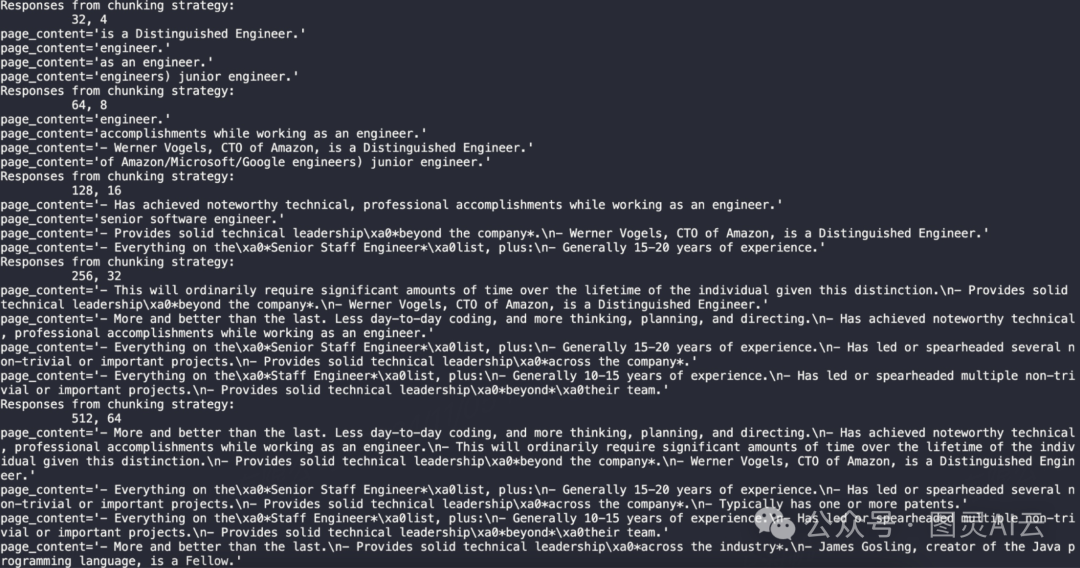
64和8的组合一开始也没有好到哪里去。但至少它给出了一个杰出工程师的例子——Werner Vogels, CTO of Amazon。

当分块长度增加到128时,我们开始看到更完整的句子。减少了“engineer”类型的词汇和回应。这个结果还不错,成功提取了关于Werner Vogel的部分和“Has achieved noteworthy technical, professional accomplishments while working as an engineer.”。最后一条信息实际上来自首席工程师部分。
然而,这里的一个缺点是我们已经看到了特殊字符如\xa0和\n的出现。这告诉我们,可能在分块长度上做得太过了,这些字符的出现可能是由于过度分割导致的格式错误。

经过深入分析,我们得出结论,当前的分块长度显然过于冗长。这种长度不仅捕获了我们所需的信息,还意外地包含了“Fellow”、“Principal Engineer”和“Senior Staff Engineer”等其他类别的内容。值得注意的是,尽管第一条结果确实源自于杰出工程师的分类,并且涵盖了该分类下的三个关键点。
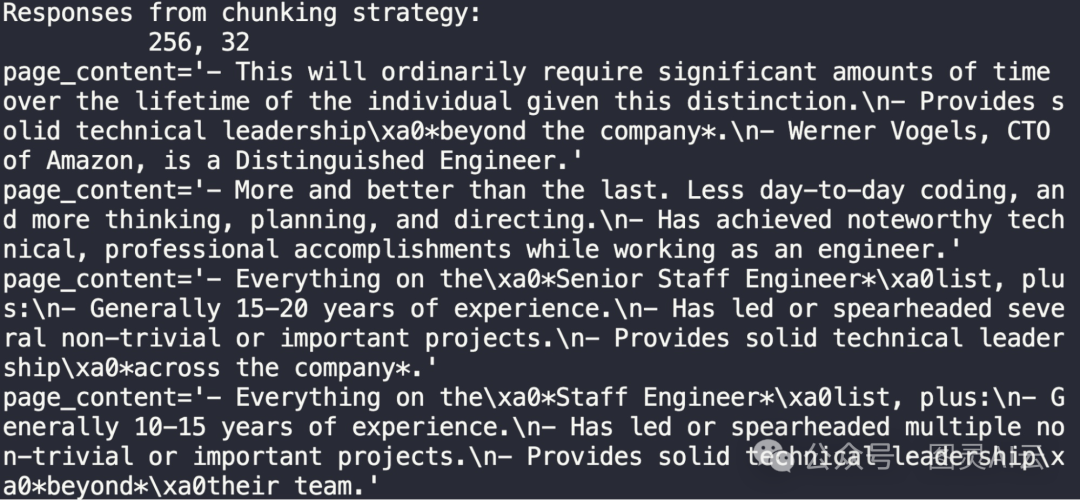
我们已确定,256的分块长度过长。然而,有趣的是,512长度的第一个结果实际上包含了整个杰出工程师的章节。这引出了一个关键问题——我们是更倾向于获取单独的“lines”或“notes”,还是希望一次性获取整个章节?这个问题的答案取决于具体的应用场景。

令人振奋的是,我们通过五种不同的文本分割策略,以参数化的方式展示了块大小和块重叠策略的重要性。在这篇使用LangChain进行分块的Python实操中,我们从五个简单的分块策略中学到了一个重要的教训:在获取单独片段与整个部分之间做出选择,这完全取决于块的大小。我们发现,128的长度在获取关于杰出工程师的单独“lines”或“notes”方面表现出色,而512的长度则能够完整地返回整个章节。然而,256的长度并不理想。
这三个数据点向我们揭示了文本分割器的一些特性。这不仅仅是关于找到理想的块大小的挑战,也表明在确定块大小时,需要考虑我们希望从回应中获得的具体内容。
更多关于langchain文章,请查看《需要全面学习LangChain?您看这篇就够了》