背景
客户流失率问题是电信运营商面临的一项重要的业务。根据测算,招揽新的客户比保留住既有客户花费大得多(通常5-20倍的差距)。因此,如何保留住现在的客户对运营商而言是一项非常有意义的事情。
数据字段
- State:州名
- Account Length:账户长度
- Area Code:区号
- Phone:电话号码
- ‘Int'l Plan:国际漫游需求与否
- VMail Plan:参与活动
- VMail Message:语音邮箱
- Day Mins:白天通话分钟数
- Day Calls:白天打电话个数
- Day Charge:白天收费情况
- Eve Mins:晚间通话分钟数
- Eve Calls:晚间打电话个数
- Eve Charge:晚间收费情况
- Night Mins:夜间通话分钟数
- Night Calls:夜间打电话个数
- Night Charge:夜间收费情况
- Intl Mins:国际通话分钟数
- Intl Calls:国际打电话个数
- Intl Charge:国际收费
- CustServ Calls:客服电话数量
- Churn:流失与否
1、数据清洗与格式转换
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore') #忽视
churn_df = pd.read_csv('churn.csv')
col_names = churn_df.columns.tolist() #所有的列展示出来
print("Column names:")
print(col_names)
churn_df.info() # 是否有缺失值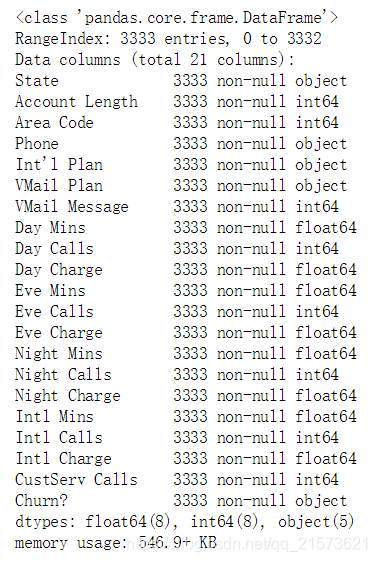
2、探索性数据分析
#我们先来看一下流失比例, 以及关于打客户电话的个数分布
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure()
fig.set(alpha=0.3) # 设定图表颜色alpha参数
plt.subplot2grid((1,2),(0,0))# 图像几行几列,从第0行第0列,
# line bar barsh kde
churn_df['Churn?'].value_counts().plot(kind='bar') #把用户是否流失分组起来,流失的有多少人,没有流失的有多少人
plt.title(u"stat for churn") # 设置标题
plt.ylabel(u"number") #流失与否的数量,一共3333行,没有流失的约占2700 ,流失的占500左右
plt.subplot2grid((1,2),(0,1))
churn_df[u'CustServ Calls'].value_counts().plot(kind='bar') # 客服电话, 客户打电话投诉多那流失率可能会大
plt.title("stat for cusServCalls") # 标题
plt.ylabel(u"number") #客户打1个客服电话的有1400个左右,客户.....总计加起来有3333个
plt.show()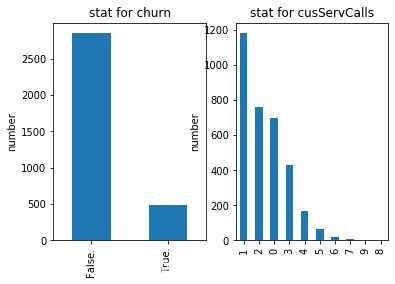
- 一共3333个样本,False代表流失了2700个左右 , 没有流失月400个左右
- 客户打1个客服电话的有1190个左右,客户打2个客服电话的有760个人个左右,客户.....总计加起来有3333个
- 说明打客服电话的越多,流失的越多。
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((1,3),(0,0)) # 在一张大图里分列几个小图
churn_df['Day Mins'].plot(kind='kde') # 白天通话分钟数,图用的kde的图例
plt.xlabel(u"Mins")# 横轴是分钟数
plt.ylabel(u"density") # density:密度
plt.title(u"dis for day mins") #标题
plt.subplot2grid((1,3),(0,1))
churn_df['Day Calls'].plot(kind='kde')# 白天打电话个数
plt.xlabel(u"call")# 客户打电话个数
plt.ylabel(u"density") #密度
plt.title(u"dis for day calls") #标题
plt.subplot2grid((1,3),(0,2))
churn_df['Day Charge'].plot(kind='kde') # 白天收费情况
plt.xlabel(u"Charge")# 横轴是白天收费情况
plt.ylabel(u"density") #密度
plt.title(u"dis for day charge")
plt.show()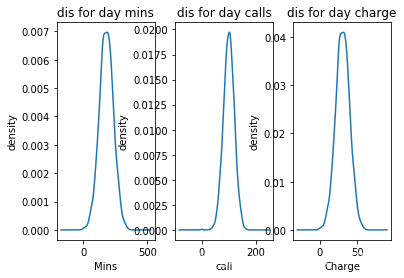
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
#查看流失与国际漫游之间的关系
int_yes = churn_df['Churn?'][churn_df['Int\'l Plan'] == 'yes'].value_counts() # 分组,yes:参与了有国际漫游需求的统计出来
int_no = churn_df['Churn?'][churn_df['Int\'l Plan'] == 'no'].value_counts() #分组:no:没有参与国际漫游的统计出来
#用DataFrame做图例上的标签 ,在右上角
df_int=pd.DataFrame({u'int plan':int_yes, u'no int plan':int_no})
df_int.plot(kind='bar', stacked=True)
plt.title(u"statistic between int plan and churn")
plt.xlabel(u"int or not")
plt.ylabel(u"number")
plt.show()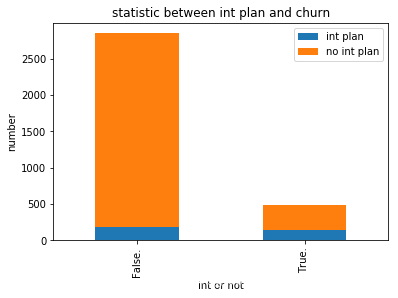
- 我们可以看到, 有国际电话的流失率较高。
#查看客户服务电话和结果的关联
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
cus_0 = churn_df['CustServ Calls'][churn_df['Churn?'] == 'False.'].value_counts()
cus_1 = churn_df['CustServ Calls'][churn_df['Churn?'] == 'True.'].value_counts()
df=pd.DataFrame({u'churn':cus_1, u'retain':cus_0})
df.plot(kind='bar', stacked=True)
plt.title(u"Static between customer service call and churn")
plt.xlabel(u"Call service")
plt.ylabel(u"Num")
plt.show()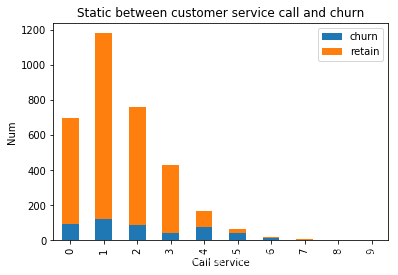
3、特征选择
- 根据对问题的分析, 去除三列无关列。 州名, 电话, 区号
- 转化成数值类型:对于有些特征, 本身不是数值类型的, 这些数据是不能被算法直接使用的, 所以需要处理
# 对于标签数据需要整合
ds_result = churn_df['Churn?']
#shift+tab:condition是布尔类型的数组,每个条件都和x ,y 对应
#等于True为1 ,等于False为0
Y = np.where(ds_result == 'True.',1,0)
dummies_int = pd.get_dummies(churn_df['Int\'l Plan'], prefix='_int\'l Plan') #prefix:前缀
# VMail Plan:某个策划活动 prefix:前缀
dummies_voice = pd.get_dummies(churn_df['VMail Plan'], prefix='VMail')
#concat:用来合并2个或者2个以上的数组
ds_tmp=pd.concat([churn_df, dummies_int, dummies_voice], axis=1)
# 删除州名、地区编号、手机号、用户是否流失、各种策略活动
to_drop = ['State','Area Code','Phone','Churn?', 'Int\'l Plan', 'VMail Plan']
df = ds_tmp.drop(to_drop,axis=1)
print("after convert ")
df.head(5)
4、特征工程
#数量级不一样,,通过Scaler实现去量纲的影响
#在训练模型时之前经常要对数据进行数组转化,as_matrix():把所有的特征都转化为np.float
X = df.as_matrix().astype(np.float)
from sklearn.preprocessing import StandardScaler # 标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
print("Feature space holds %d observations and %d features" % X.shape) # 3333行 * 19列
print("---------------------------------")
print("Unique target labels:", np.unique(Y)) # 标签的唯一值
print("---------------------------------")
print(len(Y[Y==0])) # 没流失的有2850
print("---------------------------------")
print(len(Y[Y==1])) # 流失的有483
# 整理好的数据拿过来
churn_result = churn_df['Churn?']
y = np.where(churn_result == 'True.',1,0)
to_drop = ['State','Area Code','Phone','Churn?']
churn_feat_space = churn_df.drop(to_drop,axis=1)
yes_no_cols = ["Int'l Plan","VMail Plan"]
churn_feat_space[yes_no_cols] = churn_feat_space[yes_no_cols] == 'yes'
features = churn_feat_space.columns
X = churn_feat_space.as_matrix().astype(np.float)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
print("Feature space holds %d observations and %d features" % X.shape)
print("---------------------------------")
print("Unique target labels:", np.unique(y))
print("---------------------------------")
print(X[0])#第1行
print("---------------------------------")
print(len(y[y == 0]))
5、建立模型
# 手写一个交叉验证:调参
from sklearn.model_selection import KFold
def run_cv(X,y,clf_class,**kwargs):
# Construct a kfolds object
kf = KFold(5,shuffle=True) # 5折
y_pred = y.copy() #把所有的标签y拿出来备份一下copy
# 一共是5份,没四份儿当做训练集 ,剩下的一份验证集
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train = y[train_index]
# Initialize a classifier with key word arguments
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)
y_pred[test_index] = clf.predict(X_test)
return y_pred#手写的测试
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression as LR
from sklearn.neighbors import KNeighborsClassifier as KNN
def accuracy(y_true,y_pred):
# NumPy interprets True and False as 1. and 0.
return np.mean(y_true == y_pred) # 相等为True ,不等为False , 1+0+1+0.../3333
print("Support vector machines:")
print("%.3f" % accuracy(y, run_cv(X,y,SVC)))
print("----------------------------")
print("LogisticRegression :")
print("%.3f" % accuracy(y, run_cv(X,y,LR)))
print("----------------------------")
print("K-nearest-neighbors:")
print("%.3f" % accuracy(y, run_cv(X,y,KNN)))
# 调入工具包
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score,KFold
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
# 初始化模型
models = []
models.append(('KNN', KNeighborsClassifier()))
models.append(('LR', LogisticRegression()))
models.append(('SVM', SVC()))
# 初始化
results = []
names = []
scoring = 'accuracy' # 准确率
for name, model in models:
#random_state = 0
kfold = KFold(5,shuffle=True,random_state = 0) # 5折
cv_results = cross_val_score(model, X, Y, cv=kfold)#scoring=scoring 默认为None
results.append(cv_results)#交叉验证给的结果分
names.append(name)
#模型的标准差,体现模型的分值的波动,std越小越稳定
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
print("------------------------------")
# boxplot algorithm comparison
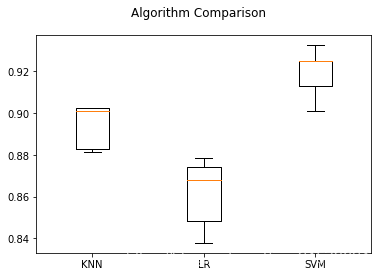
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
# 总结:SVM的效果比较好
6、模型调参/提升模型
from sklearn.ensemble import RandomForestClassifier as RF
num_trees = 100
max_features = 3
kfold = KFold(n_splits=10, random_state=7)
model = RF(n_estimators=num_trees, max_features=max_features)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())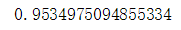
from sklearn.ensemble import GradientBoostingClassifier
seed = 7
num_trees = 100
kfold = KFold(n_splits=10, random_state=seed)
model = GradientBoostingClassifier(n_estimators=num_trees, random_state=seed)
results = cross_val_score(model, X, Y, cv=kfold)
print(results.mean())7、评估测试
def run_prob_cv(X, y, clf_class, **kwargs):
kf = KFold(5,True)
y_prob = np.zeros((len(y),2))
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train = y[train_index]
clf = clf_class(**kwargs)
clf.fit(X_train,y_train)
# Predict probabilities, not classes
y_prob[test_index] = clf.predict_proba(X_test) #返回的是概率值 ,属于0的概率多少,属于1的概率是多少
return y_prob
import warnings
warnings.filterwarnings('ignore')
# Use 10 estimators so predictions are all multiples of 0.1
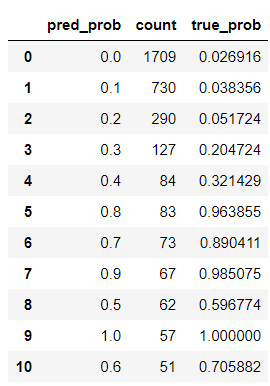
pred_prob = run_prob_cv(X, y, RF, n_estimators=10)
#print pred_prob[0]
pred_churn = pred_prob[:,1]#只要属于1的概率是多少 ,因为咱们关注的是流失的
is_churn = y == 1
# Number of times a predicted probability is assigned to an observation
counts = pd.value_counts(pred_churn) # 属于1的概率多少进行分组统计 , 即:pred_prob count
#print counts
# calculate true probabilities
true_prob = {}
for prob in counts.index:
true_prob[prob] = np.mean(is_churn[pred_churn == prob])
true_prob = pd.Series(true_prob)
# pandas-fu
counts = pd.concat([counts,true_prob], axis=1).reset_index()
counts.columns = ['pred_prob', 'count', 'true_prob']
counts