由于需要使用一个纯单词组成的文件,在网上下载到了一个存放单词的文件,但是里面有中文的解释,那就需要做一下提取了。
文本的形式如下:
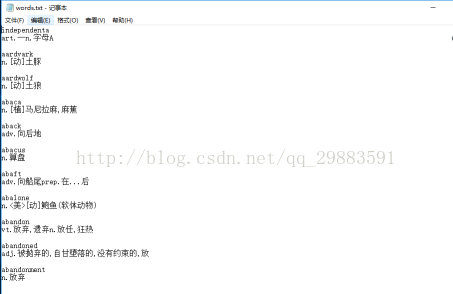
所见即所得,这个文本是有规律的,每个单词为一行,紧接着下一行便是单词的解释,有了这种规律我们就很好处理了。
首先我们来将文件的数据读取出来:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
for line in lines:
print line
显然,这不是我们想要的结果,因为这里面有太多的空行了,现在最主要的就是要处理掉这些妨碍我们的空行,对于中文的乱码呢,我们是不需要中文的解释的,所以它是无妨碍的,如果想看得舒服些,那么我们就转码一下就好了。现在最主要的就是要知道为什么会出现这么多的空行,因为我们的文件是已将看过了,显然是这些空行的出现是有点“匪夷所思”的,这也是由于python读文件的机制导致的,下面我们修改下代码,来看看原因:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
print lines
我们随意拿出这句'runlet\n', 'n.\xcd\xb0,\xd0\xa1\xba\xd3\n', '\n', 'runnel\n', 'n.\xd0\xa1\xba\xd3,\xcf\xb8\xc1\xf7\n', '\n',从中可以看出,对于每行的文件,在读取的时候,换行符“\n”也是会被读取在单词和对应的解释的后面的,所以这也就是为什么会有那么多空行的原因了,这显然不是我们想要看见的,下面我们处理一下,让这些多余的空行失去效果:

#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
for line in lines:
if line!='\n':
print line.decode('gb2312','ignore'), #逗号得带着,因为文件自身带了换行,可以代替pirnt的换行

好了,这下就是我们想看到的东西了,那么,现在我们可以将这些输出写入 到新的文件里了,然后就可以得到我们想要的单词文本了。
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
myfile=open('newfile.txt','w')
num=0
for word in lines:
if word!='\n':
num+=1
if num%2: #只有奇数行为单词
myfile.write(word)
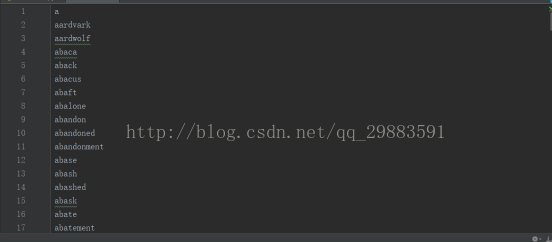
很显然,满足我们最终想要实现的要求,那么可以收工了。
最后附上两个文件的链接:http://pan.baidu.com/s/1cMvmbG。