基于WIN10的64位系统演示
一、写在前面
(1)深度学习图像识别的原理
我们思考一下,当你看到一张椅子的图片,你的大脑会告诉你这是个椅子,但你有没有想过:为什么你知道这是椅子,你的大脑是怎么做推论的?你可能会说因为椅子有腿,有座位,有靠背,但具体是什么形状、大小的腿、座位、靠背才算是椅子,你可能就无法明确解释了。这就是你的大脑通过大量实践经验自我学习得到的结果。
那么,深度学习图像识别就是让机器自己学习识别图片中的内容。例如,你给机器看了很多猫的图片,然后再给它看一张新的猫的图片,它就能告诉你这是猫。这是因为在看很多猫的图片的过程中,机器自己学习到了猫的特征,比如它可能注意到了猫的眼睛、鼻子、耳朵等特征,然后在看到新的图片时,就能通过这些特征判断这是否是猫。
(2)卷积神经网络
我们归纳一下哈:我们能识别一只猫,其实是通过猫的眼睛、鼻子、耳朵等特征来识别的。也就是说,我们不需要对猫的所有细节进行识别,仅仅需要识别某些特征(甚至只是一个轮廓)即可。那么机器如何模拟这种机制?在深度学习里,就是我们今天的主角——卷积神经网络(Convolutional Neural Networks,简称CNN)。CNN是一种特殊的神经网络,是深度学习图像识别中最常用的工具。CNN之所以适合图像识别,是因为它可以识别局部特征,比如猫的眼睛、鼻子、耳朵等,然后再把这些局部特征组合起来,判断这是不是猫。
因此,从某个角度来说,CNN辨别图像的机制和人类很类似。那么,它为什么能做到,其中的原理是什么?往下看。
(3)CNN的结构
CNN的基本构建块包括卷积层、池化层和全连接层。逐一来看:
(a)卷积层是用来提取图像中的局部特征。
卷积层主要通过卷积核来提取特征。举个例子,我们把一张图片想象成一座山,那么卷积层就像是一只鹰在飞翔,卷积核就好比鹰的眼睛,它通过眼睛扫视着山。但是每个时间点仅仅扫视山的一小部分,并抓取那里的信息(实际上在进行一个数学运算,这个运算会将图片的一小块区域转化为一个数字,而这个数字就代表了那个区域的特征)。一遍扫视下来,就大概知道这一座山的概况了。
那么,卷积核又是如何提取特征的?卷积核可以设计为很多种,侧重于提取的特征也不一致。有些专门提取竖线,有些专门提取横线,有些专门提取毛发等等。因此,CNN一次可以使用多个卷积核进行扫描,得到了CNN的第一个卷积层(包含了N个原图的特征图),也就是仅保留了部分重要的图片信息。如下图,只存在一个轮廓了。

(b)池化层是用来降低数据的维度。
经过第一轮扫描得到了第一个卷积层,仅仅保留了重要信息,存在很多冗余的数据(比如上图那些黑色的区域)。因此,需要把多余的部分删了,这个过程就是池化。举个例子,各个地区选出人大代表去北京开会,大概就是这个意思。最终目的在于,缩小图片尺寸,同时保留基本特征。

(c)全连接层则是用来将学习到的各种特征进行组合,进行最后的分类或回归。
一个CNN模型,一般这么设计:卷积(提取特征)——>池化(缩小图片)——>再卷积(再提取特征)——>再池化(再缩小图片)——>循环卷积和池化——>全连接层做分类(类似之前介绍的基础分类模型)。结构如下,希望你么能看懂了:
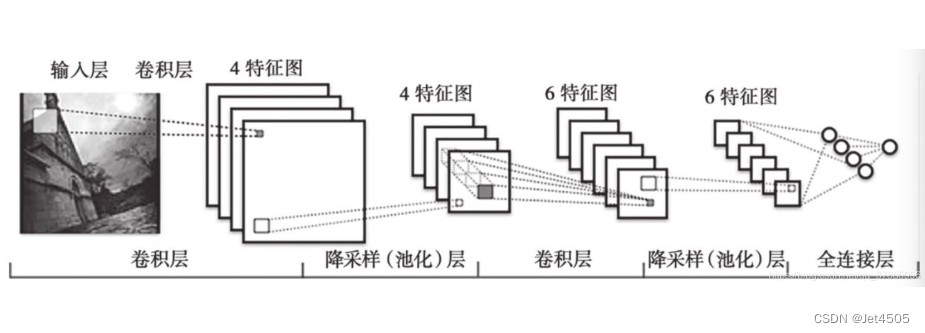
(4)推荐up主的视频,配合着动画,一目了然:https://www.bilibili.com/video/BV15A411w7By/?share_source=copy_web&vd_source=d597186b38ff003ed61c90d3c6693cf3
二、CNN代码实战
直接演示一个案例:猴痘皮损和水痘皮损的识别。其中,猴痘皮损279张,水痘皮损107张,分别存入单独的文件夹中。
(a)导入包
from tensorflow import keras
import tensorflow as tf
from tensorflow.python.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout, Activation, Reshape, Softmax
from tensorflow.python.keras.layers.convolutional import Convolution2D, MaxPooling2D
from tensorflow.python.keras import Sequential
from tensorflow.python.keras import Model
from tensorflow.python.keras.optimizers import adam_v2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator, image_dataset_from_directory
from tensorflow.python.keras.layers.preprocessing.image_preprocessing import RandomFlip, RandomRotation
import os,PIL,pathlib
import warnings
#设置GPU
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号保姆级别提醒:
在新版本中,很多旧的导入包的代码似乎不管用了,比如我让GPT-4写一个CNN模型的代码:
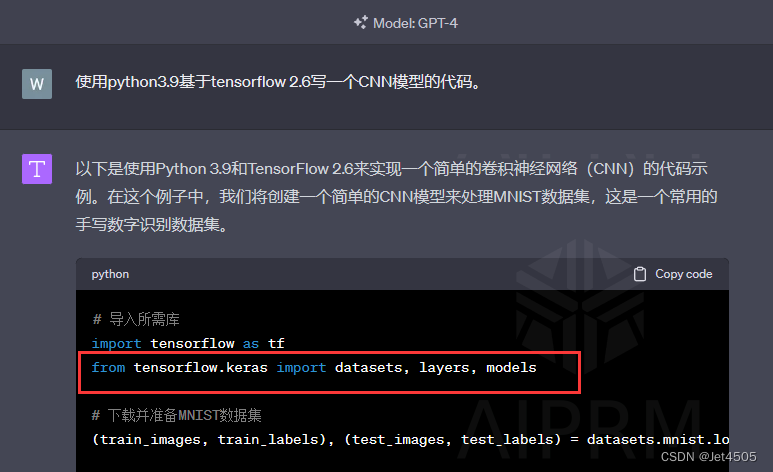
这么输入,肯定报错:
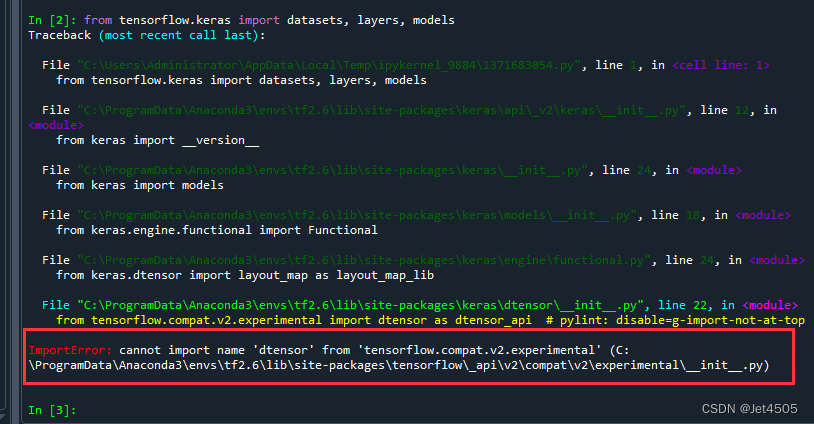
为什么咧?我之前也说过(传送门)包的调用逻辑,其实就是文件夹的包含顺序,比如说要找Dense, Flatten包,看看他们文件夹的位置:
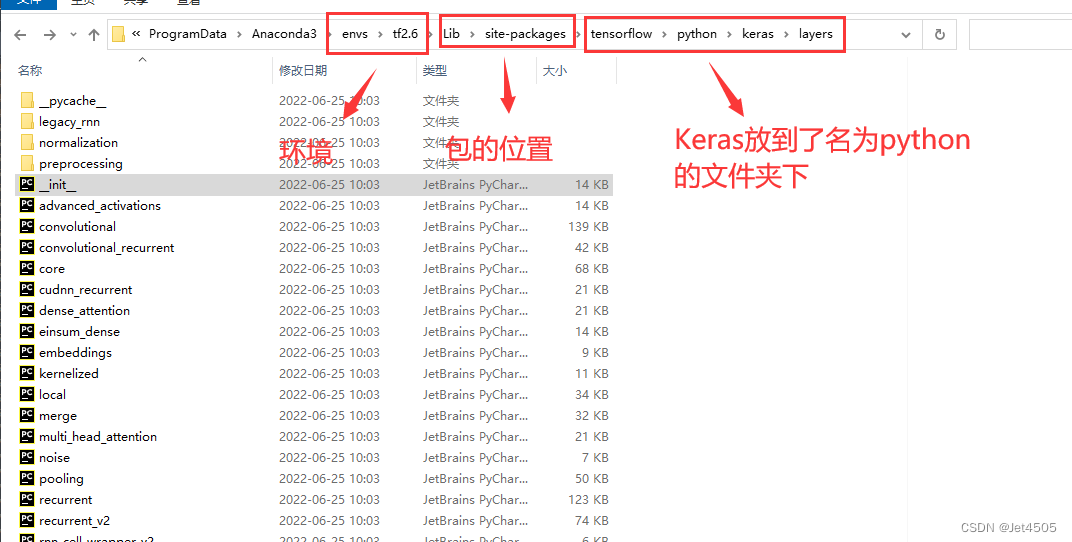
打开“__init__.py”,找到正确的导入代码(不用core也行):
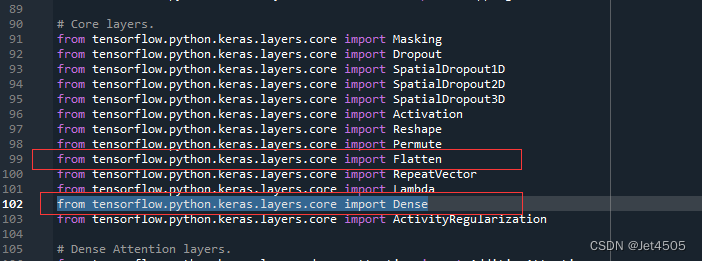
大家好好体会哈。
(b)导入数据集
#1.导入数据
data_dir = "./jet"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
batch_size = 32
img_height = 250
img_width = 250
train_ds = image_dataset_from_directory(
data_dir,
validation_split=0.3,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = image_dataset_from_directory(
data_dir,
validation_split=0.3,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
#2.检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
#3.配置数据
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.shuffle(1000)
.map(train_preprocessing)
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.shuffle(1000)
.map(train_preprocessing)
.prefetch(buffer_size=AUTOTUNE)
)
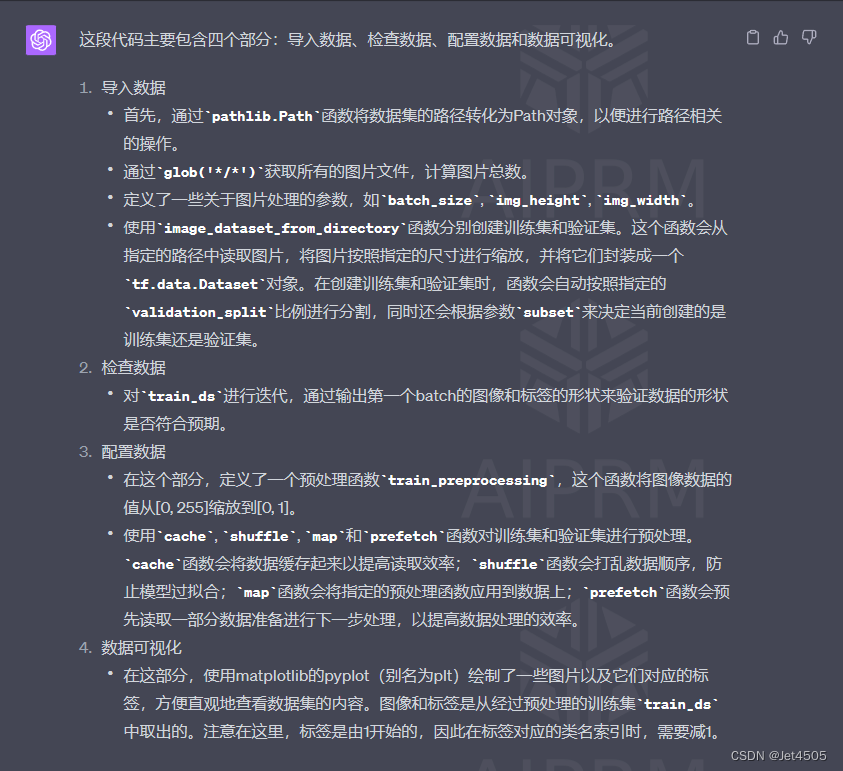
#4. 数据可视化
plt.figure(figsize=(10, 8))
plt.suptitle("数据展示")
class_names = ["Monkeypox","Chickenpox"]
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(images[i])
plt.xlabel(class_names[labels[i]-1])
plt.show()GPT-4解析(真方便):
记得把工作路劲设置好,然后我们运行:

(c)构建CNN网络
#搭建一个卷起网络
# 设置层
model = Sequential([
Conv2D(filters=32, kernel_size=(3,3), padding='same',
input_shape=(img_width,img_height,3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(filters=64, kernel_size=(3,3), padding='same',
activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(filters=128, kernel_size=(3,3), padding='same',
activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(filters=256, kernel_size=(3,3), padding='same',
activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(filters=256, kernel_size=(3,3), padding='same',
activation='relu'),
Flatten(),
Dense(512, activation='relu'),
Dense(2,activation='sigmoid')
])
#打印模型结构
print(model.summary())GPT-4解析(舒畅):
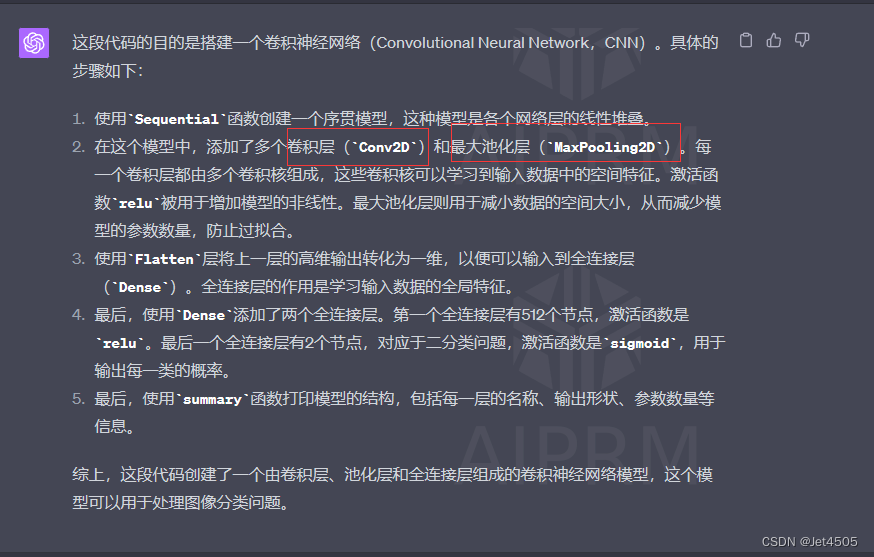
配合之前说的基础知识,应该看得懂吧。模型结构如下:
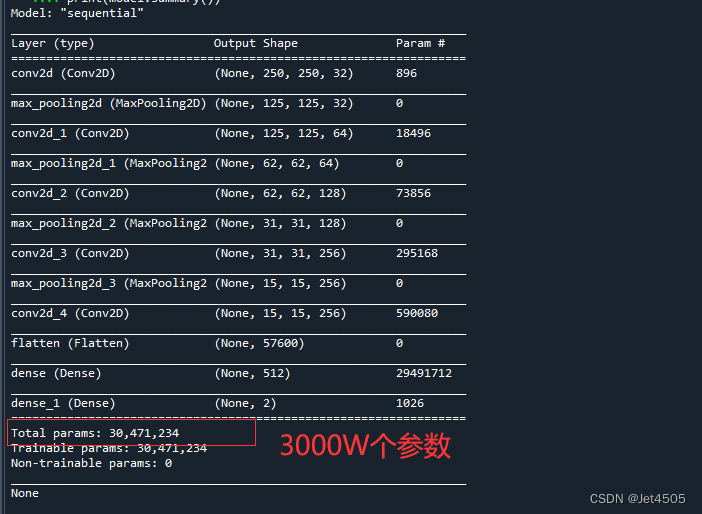
一共使用了4个“卷积-池化”套装,大约3000万个参数,看看你这个数量级!!!
(d)编译模型
#定义优化器
from tensorflow.python.keras.optimizers import adam_v2, rmsprop_v2
from tensorflow.python.keras.optimizer_v2.gradient_descent import SGD
optimizer = adam_v2.Adam()
#optimizer = SGD(learning_rate=0.001)
#optimizer = rmsprop_v2.RMSprop()
#编译模型
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#训练模型
from tensorflow.python.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateScheduler
NO_EPOCHS = 20
PATIENCE = 10
VERBOSE = 1
# 设置动态学习率
annealer = LearningRateScheduler(lambda x: 1e-3 * 0.99 ** (x+NO_EPOCHS))
# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)
#
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=VERBOSE,
save_best_only=True,
save_weights_only=True)
train_model = model.fit(train_ds,
epochs=NO_EPOCHS,
verbose=1,
validation_data=val_ds,
callbacks=[earlystopper, checkpointer, annealer])
#保存模型
model.save('JET_new.h5')
print("The trained model has been saved.")GPT-4解析(省事):
这个优化器的导入也是个坑,所以我这里帮你们整理了三个最常用的(选择其中一个即可):
from tensorflow.python.keras.optimizers import adam_v2, rmsprop_v2
from tensorflow.python.keras.optimizer_v2.gradient_descent import SGD
optimizer = adam_v2.Adam()
optimizer = SGD(learning_rate=0.001)
optimizer = rmsprop_v2.RMSprop()运行代码(我只迭代20次):
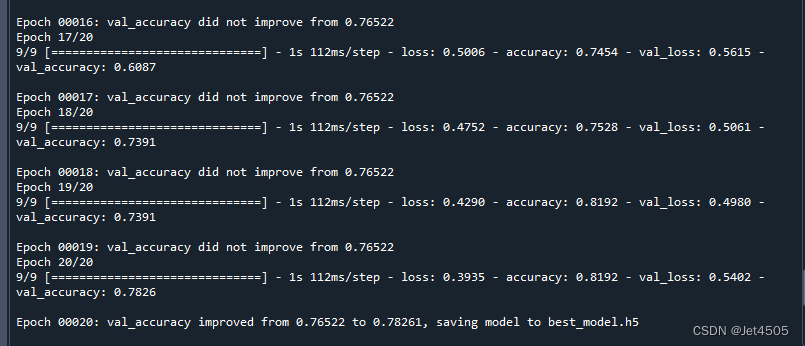
可以看到准确率在81.92%(训练集的),验证集的准确率在78.26%。继续迭代下去,验证集的准确率应该还会提升。
(e)Accuracy和Loss可视化
import matplotlib.pyplot as plt
loss = train_model.history['loss']
acc = train_model.history['accuracy']
val_loss = train_model.history['val_loss']
val_acc = train_model.history['val_accuracy']
epoch = range(1, len(loss)+1)
fig, ax = plt.subplots(1, 2, figsize=(10,4))
ax[0].plot(epoch, loss, label='Train loss')
ax[0].plot(epoch, val_loss, label='Validation loss')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, acc, label='Train acc')
ax[1].plot(epoch, val_acc, label='Validation acc')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
plt.show()通过这个图,观察模型训练情况:
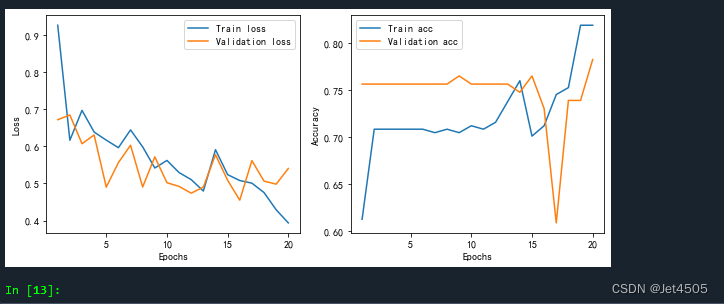
蓝色为训练集,橙色为验证集。
左图的纵坐标你可以理解为误差,越低越好。可以看到,训练集和验证集随着模型迭代次数的增加,误差总体下降。但是,在迭代至18-19的时候,验证集的误差下降开始放缓,甚至增加;而训练集的误差依旧下降,记得这个叫什么不?嗯,有点过拟合的趋势了。
同样,右边是准确率和迭代次数的关系,具体不详细解释了。
(f)混淆矩阵可视化以及模型参数
没啥好说的,都跟之前的ML模型类似:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.models import load_model
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import math
# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):
# 生成混淆矩阵
conf_numpy = confusion_matrix(labels, predictions)
# 将矩阵转化为 DataFrame
conf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names)
plt.figure(figsize=(8,7))
sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")
plt.title('混淆矩阵',fontsize=15)
plt.ylabel('真实值',fontsize=14)
plt.xlabel('预测值',fontsize=14)
val_pre = []
val_label = []
for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵
for image, label in zip(images, labels):
# 需要给图片增加一个维度
img_array = tf.expand_dims(image, 0)
# 使用模型预测图片中的人物
prediction = model.predict(img_array)
val_pre.append(np.argmax(prediction))
val_label.append(label)
plot_cm(val_label, val_pre)
cm_val = confusion_matrix(val_label, val_pre)
a_val = cm_val[0,0]
b_val = cm_val[0,1]
c_val = cm_val[1,0]
d_val = cm_val[1,1]
acc_val = (a_val+d_val)/(a_val+b_val+c_val+d_val) #准确率:就是被分对的样本数除以所有的样本数
error_rate_val = 1 - acc_val #错误率:与准确率相反,描述被分类器错分的比例
sen_val = d_val/(d_val+c_val) #灵敏度:表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力
sep_val = a_val/(a_val+b_val) #特异度:表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力
precision_val = d_val/(b_val+d_val) #精确度:表示被分为正例的示例中实际为正例的比例
F1_val = (2*precision_val*sen_val)/(precision_val+sen_val) #F1值:P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)
MCC_val = (d_val*a_val-b_val*c_val) / (math.sqrt((d_val+b_val)*(d_val+c_val)*(a_val+b_val)*(a_val+c_val))) #马修斯相关系数(Matthews correlation coefficient):当两个类别具有非常不同的大小时,可以使用MCC
print("验证集的灵敏度为:",sen_val,
"验证集的特异度为:",sep_val,
"验证集的准确率为:",acc_val,
"验证集的错误率为:",error_rate_val,
"验证集的精确度为:",precision_val,
"验证集的F1为:",F1_val,
"验证集的MCC为:",MCC_val)
train_pre = []
train_label = []
for images, labels in train_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵
for image, label in zip(images, labels):
# 需要给图片增加一个维度
img_array = tf.expand_dims(image, 0)
# 使用模型预测图片中的人物
prediction = model.predict(img_array)
train_pre.append(np.argmax(prediction))
train_label.append(label)
plot_cm(train_label, train_pre)
cm_train = confusion_matrix(train_label, train_pre)
a_train = cm_train[0,0]
b_train = cm_train[0,1]
c_train = cm_train[1,0]
d_train = cm_train[1,1]
acc_train = (a_train+d_train)/(a_train+b_train+c_train+d_train)
error_rate_train = 1 - acc_train
sen_train = d_train/(d_train+c_train)
sep_train = a_train/(a_train+b_train)
precision_train = d_train/(b_train+d_train)
F1_train = (2*precision_train*sen_train)/(precision_train+sen_train)
MCC_train = (d_train*a_train-b_train*c_train) / (math.sqrt((d_train+b_train)*(d_train+c_train)*(a_train+b_train)*(a_train+c_train)))
print("训练集的灵敏度为:",sen_train,
"训练集的特异度为:",sep_train,
"训练集的准确率为:",acc_train,
"训练集的错误率为:",error_rate_train,
"训练集的精确度为:",precision_train,
"训练集的F1为:",F1_train,
"训练集的MCC为:",MCC_train)特异度很差:
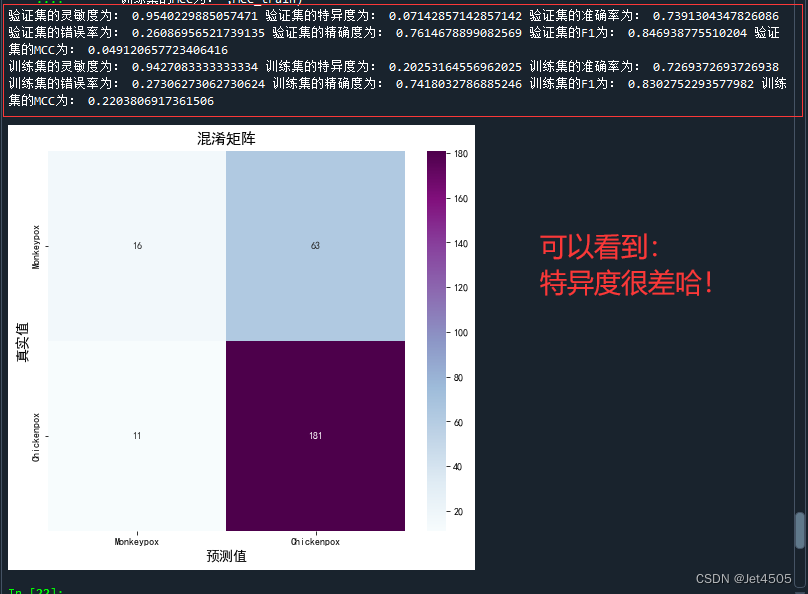
AUC值呢,别急,往下看。
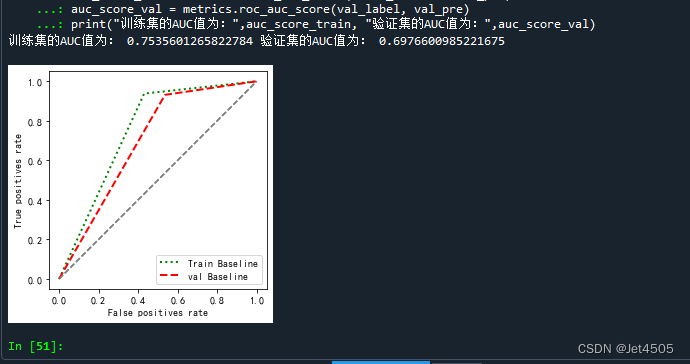
(g)AUC曲线绘制
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.models import load_model
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import math
def plot_roc(name, labels, predictions, **kwargs):
fp, tp, _ = metrics.roc_curve(labels, predictions)
plt.plot(fp, tp, label=name, linewidth=2, **kwargs)
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlabel('False positives rate')
plt.ylabel('True positives rate')
ax = plt.gca()
ax.set_aspect('equal')
plot_roc("Train Baseline", train_label, train_pre, color="green", linestyle=':')
plot_roc("val Baseline", val_label, val_pre, color="red", linestyle='--')
plt.legend(loc='lower right')
auc_score_train = metrics.roc_auc_score(train_label, train_pre)
auc_score_val = metrics.roc_auc_score(val_label, val_pre)
print("训练集的AUC值为:",auc_score_train, "验证集的AUC值为:",auc_score_val)输出如下:
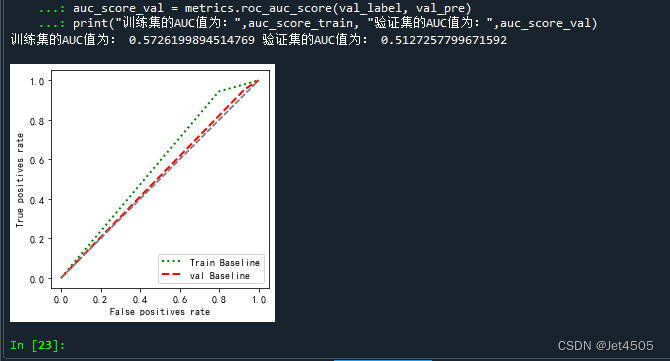
也很差,哈哈哈。
三、优化模型
(a)迭代100次,其他不变:
妥妥过拟合:
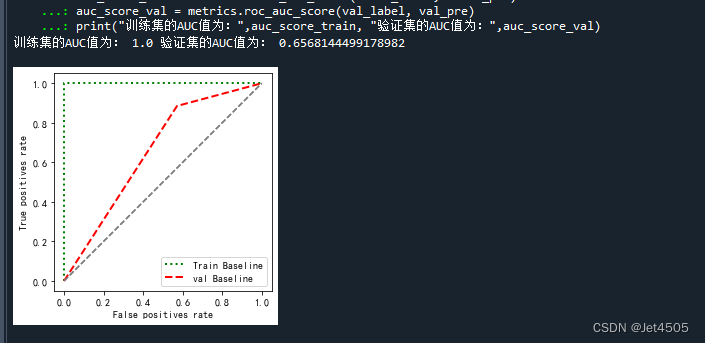
(b)做数据增强:
在 构建网络 前加入一段数据增强代码:
data_augmentation = Sequential([
RandomFlip("horizontal_and_vertical"),
RandomRotation(0.2),
])
def prepare(ds):
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)
return ds
train_ds = prepare(train_ds)GPT-4解释如下:
那么,除了RandomFlip和RandomRotation,还有哪些数据增强操作的函数?

看看数据增强之后的结果,至少不是过拟合了:
(c)换其他结构的CNN模型:
后面几期再慢慢测试。
四、写在最后
我没说错吧,相比于单纯的ML,CNN代码的门槛高了不少哦。
不过最难的代码我都帮你们搞定了,加上GPT的加持,其他还怕啥。
也有!怕的只是没有好的显卡!!!
五、数据
链接:https://pan.baidu.com/s/14VAHuRKE5ksKQcgCJK3sRg?pwd=xc48
提取码:xc48