1.用php打印前一天的时间,格式是2018-01-01 08:00:00?
$a=date("Y-m-d H:i:s",strtotime("-1 day"));print_r($a)
2.echo、print_r、print、var_dump的区别?
echo、print是php语句,var_dump和print_r是函数
echo输出一个或多个字符串,中间以逗号隔开,没有返回值是语言结构而不是真正的函数,因此不能作为表达式的一部分使用
print也是php的一个关键字,有返回值 只能打印出简单类型变量的值(如int,string),如果字符串显示成功则返回true,
否则返回false
print_r 可以打印出复杂类型变量的值(如数组、对象)以列表的形式显示,并以array、object开头,但print_r输出布尔
值和NULL的结果没有意义,因为都是打印"\n",因此var_dump()函数更适合调试
var_dump() 判断一个变量的类型和长度,并输出变量的数值
3.include和require的区别是什么?
require是无条件包含,也就是如果一个流程里加入require,无论条件成立与否都会先执行require,当文件不存在或者无法打开的时候,会提示错误,并且会终止程序执行
include有返回值,而require没有(可能因为如此require的速度比include快),如果被包含的文件不存在的化,那么会提示一个错误,但是程序会继续执行下去
注意:包含文件不存在或者语法错误的时候require是致命的,而include不是
require_once表示了只包含一次,避免了重复包含
4.请说说php中传值与传引用的区别,并说明传值什么时候传引用?
变量默认总是传值赋值,那也就是说,当将一个表达式的值赋予一个变量时,整个表达式的值被赋值到目标变量,这意味着:当一个变量的赋予另外一个变量时,改变其中一个变量的值,将不会影响到另外一个变量
php也提供了另外一种方式给变量赋值:引用赋值。这意味着新的变量简单的__引用__(换言之,成为了其别名或者指向)了原始变量。改动的新的变量将影响到原始变量,反之亦然。使用引用赋值,简单地将一个&符号加到将要赋值的变量前(源变量)
对象默认是传引用
对于较大是的数据,传引用比较好,这样可以节省内存的开销
5.session和cookie有哪些区别?请从协议,产生原因与作用说明?
1、http无状态协议,不能区分用户是否是从同一个网站上来的,同一个用户请求不同的页面不能看做是同一个用户。
2、SESSION存储在服务器端,COOKIE保存在客户端。Session比较安全,cookie用某些手段可以修改,不安全。Session依赖于cookie进行传递。
禁用cookie后,session不能正常使用。Session的缺点:保存在服务器端,每次读取都从服务器进行读取,对服务器有资源消耗。Session保存在服务器端的文件或数据库中,默认保存在文件中,文件路径由php配置文件的session.save_path指定。Session文件是公有的。
6.HTTP中GET与POST的区别
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST没有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
- GET产生一个TCP数据包,POST产生两个TCP数据包。
7、如何实现PHP的安全最大化?怎样避免SQL注入漏洞和XSS跨站脚本攻击漏洞?
基本原则:不对外界展示服务器或程序设计细节(屏蔽错误),不相信任何用户提交的数据(过滤用户提交)
1、1 屏蔽错误,将display_errors 设置为off
2、 过滤用户提交参数,这里需要注意的是不能仅仅通过浏览器端的验证,还需要经过服务器端的过滤
这里是需要注意最多的地方,因为所有用户提交的数据入口都在这里,这是过滤数据的第一步。
1 考虑是否过滤select,insert,update,delete,drop,create等直接操作数据的命令语句
2 使用addslashes 将所有特殊字符过滤
3 打开magic_quotes_gpc,开启该参数数后自动将sql语句转换,将 ' 转换成 \'
3、 可以考虑设置统一入口,只允许用户通过指定的入口访问,不能访问未经许可的文件等内容
4、可以考虑对安全性要求高的文件进行来源验证,比如要想执行b.php必须先执行a.php,可以在b.php中判断来自a.php的referer,避免用户直接执行b.php
8、在程序的开发中,如何提高程序的运行效率?
①优化SQL语句,查询语句中尽量不使用select *,用哪个字段查哪个字段;少用子查询可用表连接代替;少用模糊查询;②数据表中创建索引;③对程序中经常用到的数据生成缓存;
9、现在编程中经常采取MVC三层结构,请问MVC分别指哪三层,有什么优点?
MVC三层分别指:业务模型、视图、控制器,由控制器层调用模型处理数据,然后将数据映射到视图层进行显示,优点是:①可以实现代码的重用性,避免产生代码冗余;②M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式
10、PHP处理数组的常用函数?(重点看函数的‘参数’和‘返回值’)
①array()创建数组;②count()返回数组中元素的数目;③array_push()将一个或多个元素插入数组的末尾(入栈);④array_column()返回输入数组中某个单一列的值;⑤array_combine()通过合并两个数组来创建一个新数组;⑥array_reverse()以相反的顺序返回数组;⑦array_unique()删除数组中的重复值;⑧in_array()检查数组中是否存在指定的值;
11、PHP处理字符串的常用函数?(重点看函数的‘参数’和‘返回值’)
1.trim()移除字符串两侧的空白字符和其他字符;
2.substr_replace()把字符串的一部分替换为另一个字符串;
3.substr_count()计算子串在字符串中出现的次数;
4.substr()返回字符串的一部分;
5.strtolower()把字符串转换为小写字母;
6.strtoupper()把字符串转换为大写字母;
7.strtr()转换字符串中特定的字符;
8.strrchr()查找字符串在另一个字符串中最后一次出现;
9.strstr()查找字符串在另一字符串中的第一次出现(对大小写敏感)_
10.strrev()反转字符串;
11.strlen()返回字符串的长度;
12.str_replace()替换字符串中的一些字符(对大小写敏感)
13.explode()把字符串打散为数组;
14.is_string()检测变量是否是字符串;
15.strip_tags()从一个字符串中去除HTML标签;
16.mb_substr()用来截中文与英文的函数12、PHP处理时间的常用函数?(重点看函数的‘参数’和‘返回值’)
date_default_timezone_get()返回默认时区。
date_default_timezone_set()设置默认时区。
date()格式化本地时间/日期。
getdate()返回日期/时间信息。
gettimeofday()返回当前时间信息。
microtime()返回当前时间的微秒数。
mktime()返回一个日期的 Unix时间戳。
strtotime()将任何英文文本的日期或时间描述解析为 Unix时间戳。
time()返回当前时间的 Unix时间戳。
13、_____函数能返回脚本里的任意行中调用的函数的名称。该函数同时还经常被用在调试中,用来判断错误是如何发生的
debug_backtrace()
14、什么是面向对象?
面向对象OO = 面向对象的分析OOA + 面向对象的设计OOD + 面向对象的编程OOP;通俗的解释就是“万物皆对象”,把所有的事物都看作一个个可以独立的对象(单元),它们可以自己完成自己的功能,而不是像C那样分成一个个函数。
现在纯正的OO语言主要是Java和C#,PHP、C++也支持OO,C是面向过程的。
15、简述 private、 protected、 public修饰符的访问权限。
private : 私有成员, 在类的内部才可以访问。
protected : 保护成员,该类内部和继承类中可以访问。
public : 公共成员,完全公开,没有访问限制。
16、堆和栈的区别?
栈是编译期间就分配好的内存空间,因此你的代码中必须就栈的大小有明确的定义;
堆是程序运行期间动态分配的内存空间,你可以根据程序的运行情况确定要分配的堆内存的大小。
17、以下哪种错误类型无法被自定义的错误处理器捕捉到?(双选)
A、 E_WARNING
B、 E_USER_ERROR
C、 E_PARSE
D、 E_NOTICE
答案:BC
18、面向对象的特征有哪些方面?
主要有封装,继承,多态。如果是4个方面则加上:抽象。
下面的解释为理解:
封装:
封装是保证软件部件具有优良的模块性的基础,封装的目标就是要实现软件部件的高内聚,低耦合,防止程序相互依赖性而带来的变动影响.
继承:
在定义和实现一个类的时候,可以在一个已经存在的类的基础之上来进行,把这个已经存在的类所定义的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法使之更适合特殊的需要,这就是继承。继承是子类自动共享父类数据和方法的机制,这是类之间的一种关系,提高了软件的可重用性和可扩展性。
多态:
多态是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
抽象:
抽象就是找出一些事物的相似和共性之处,然后将这些事物归为一个类,这个类只考虑这些事物的相似和共性之处,并且会忽略与当前主题和目标无关的那些方面,将注意力集中在与当前目标有关的方面。例如,看到一只蚂蚁和大象,你能够想象出它们的相同之处,那就是抽象。
19、抽象类和接口的概念以及区别?
抽象类:它是一种特殊的,不能被实例化的类,只能作为其他类的父类使用。使用abstract关键字声明。
它是一种特殊的抽象类,也是一个特殊的类,使用interface声明。
(1)抽象类的操作通过继承关键字extends实现,而接口的使用是通过implements关键字来实现。
(2)抽象类中有数据成员,可以实现数据的封装,但是接口没有数据成员。
(3)抽象类中可以有构造方法,但是接口没有构造方法。
(4)抽象类的方法可以通过private、protected、public关键字修饰(抽象方法不能是private),而接口中的方法只能使用public关键字修饰。
(5)一个类只能继承于一个抽象类,而一个类可以同时实现多个接口。
(6)抽象类中可以有成员方法的实现代码,而接口中不可以有成员方法的实现代码。
20、什么是构造函数,什么是析构函数,作用是什么?
构造函数(方法)是对象创建完成后第一个被对象自动调用的方法。它存在于每个声明的类中,是一个特殊的成员方法。作用是执行一些初始化的任务。Php中使用__construct()声明构造方法,并且只能声明一个。
析构函数(方法)作用和构造方法正好相反,是对象被销毁之前最后一个被对象自动调用的方法。是PHP5中新添加的内容作用是用于实现在销毁一个对象之前执行一些特定的操作,诸如关闭文件和释放内存等。
21、如何重载父类的方法,举例说明
重载,即覆盖父类的方法,也就是使用子类中的方法替换从父类中继承的方法,也叫方法的重写。
覆盖父类方法的关键是在子类中创建于父类中相同的方法包括方法的名称、参数和返回值类型。PHP中只要求方法的名称相同即可。
22、常用的魔术方法有哪些?举例说明
php规定以两个下划线(__)开头的方法都保留为魔术方法,所以建议大家函数名最好不用__开头,除非是为了重载已有的魔术方法。
__construct() 实例化类时自动调用。
__destruct() 类对象使用结束时自动调用。
__set() 在给未定义的属性赋值的时候调用。
__get() 调用未定义的属性时候调用。
__isset() 使用isset()或empty()函数时候会调用。
__unset() 使用unset()时候会调用。
__sleep() 使用serialize序列化时候调用。
__wakeup() 使用unserialize反序列化的时候调用。
__call() 调用一个不存在的方法的时候调用。
__callStatic()调用一个不存在的静态方法是调用。
__toString() 把对象转换成字符串的时候会调用。比如 echo。
__invoke() 当尝试把对象当方法调用时调用。
__set_state() 当使用var_export()函数时候调用。接受一个数组参数。
__clone() 当使用clone复制一个对象时候调用。
23、$this和self、parent这三个关键词分别代表什么?在哪些场合下使用?
$this 当前对象
self 当前类
parent 当前类的父类
$this在当前类中使用,使用->调用属性和方法。
self也在当前类中使用,不过需要使用::调用。
parent在类中使用。
24、类中如何定义常量、如何类中调用常量、如何在类外调用常量。
类中的常量也就是成员常量,常量就是不会改变的量,是一个恒值。
定义常量使用关键字const.
例如:const PI = 3.1415326;
无论是类内还是类外,常量的访问和变量是不一样的,常量不需要实例化对象,
访问常量的格式都是类名加作用域操作符号(双冒号)来调用。
即:类名 :: 类常量名;
25、作用域操作符::如何使用?都在哪些场合下使用?
调用类常量
调用静态方法
26、__autoload()方法的工作原理是什么?
使用这个魔术函数的基本条件是类文件的文件名要和类的名字保持一致。
当程序执行到实例化某个类的时候,如果在实例化前没有引入这个类文件,那么就自动执行__autoload()函数。
这个函数会根据实例化的类的名称来查找这个类文件的路径,当判断这个类文件路径下确实存在这个类文件后
就执行include或者require来载入该类,然后程序继续执行,如果这个路径下不存在该文件时就提示错误。
使用自动载入的魔术函数可以不必要写很多个include或者require函数。
26、http协议常用状态码解释?
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
26、对于大流量网站,采取什么方式来解决访问量的问题?
1. 确认服务器是否能支撑当前访问量。
2. 优化数据库访问。
3. 禁止外部访问链接(盗链), 比如图片盗链。
4. 控制文件下载。
5. 使用不同主机分流。
6. 使用浏览统计软件,了解访问量,有针对性的进行优化。
26、使用至少三种方法获取一个文件的扩展名?
方法1:使用strrchr()函数
<?php
function getExt($file) {
return strrchr($file, '.');
}
echo getExt('index.php');
?>注:strrchr() 函数查找字符串在另一个字符串中最后一次出现的位置,并返回从该位置到字符串结尾的所有字符。如果成失败,否则返回 false。
方法2:截取字符串
<?php
function getExt($file) {
return substr($file, strrpos($file, '.'));
}
echo getExt('index.php');
?>注:strrpos() 函数查找字符串在另一个字符串中最后一次出现的位置。如果成失败,否则返回 false。
方法3:使用数组
<?php
function getExt($file) {
//PHP 5.4开始,会发出警告,因此使用@屏蔽
return @array_pop(explode('.', $file));
}
echo getExt('index.php');
?>方法4:使用pathinfo()函数
<?php
function getExt($file) {
$temp = pathinfo($file);
return $temp['extension'];
}
echo getExt('index.php');
?>方法五:
function get_ext5($file_name){
return strrev(substr(strrev($file_name), 0, strpos(strrev($file_name), ‘.’)));
} 27、有一个数组array('23','34','56','78','54','63')请使用冒泡排序算法和快速排序算法进行排序,请详细写出过程?
1. 冒泡排序法
* 思路分析:法如其名,就是像冒泡一样,每次从数组当中 冒一个最大的数出来。
* 比如:2,4,1 // 第一次 冒出的泡是4
* 2,1,4 // 第二次 冒出的泡是 2
* 1,2,4 // 最后就变成这样
代码:
$arr=array('23','34','56','78','54','63')
function getpao($arr)
{
$len=count($arr);
//设置一个空数组 用来接收冒出来的泡
//该层循环控制 需要冒泡的轮数
for($i=1;$i<$len;$i++)
{ //该层循环用来控制每轮 冒出一个数 需要比较的次数
for($k=0;$k<$len-$i;$k++)
{
if($arr[$k]>$arr[$k+1])
{
$tmp=$arr[$k+1];
$arr[$k+1]=$arr[$k];
$arr[$k]=$tmp;
}
}
}
return $arr;
} /*
快速排序
*
function quickSort($array)
{
if(!isset($array[1]))
return $array;
$mid = $array[0]; //获取一个用于分割的关键字,一般是首个元素
$leftArray = array();
$rightArray = array();
foreach($array as $v)
{
if($v > $mid)
$rightArray[] = $v; //把比$mid大的数放到一个数组里
if($v < $mid)
$leftArray[] = $v; //把比$mid小的数放到另一个数组里
}
$leftArray = quickSort($leftArray); //把比较小的数组再一次进行分割
$leftArray[] = $mid; //把分割的元素加到小的数组后面,不能忘了它哦
$rightArray = quickSort($rightArray); //把比较大的数组再一次进行分割
return array_merge($leftArray,$rightArray); //组合两个结果
}28、借助继承,我们可以创建其他类的派生类。那么在PHP中,子类最多可以继承几个父类?
A、1个
B、2个
C、取决于系统资源
D、3个
E、想要几个有几个
答案:A
29、什么是反向代理?什么时候需要用反向代理?
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。需要提高性能的时候30.请写一段PHP代码,确保多个进程同时写入同一个文件成功
$file = fopen("test.txt","w+");
// 排它性的锁定 先锁上,写完,打开。
if (flock($file,LOCK_EX))
{
fwrite($file,"Write something");
// release lock
flock($file,LOCK_UN);
}
else
{
echo "Error locking file!";
}
fclose($file);31.怎么解决php创建中文文件夹及中文名出现乱码问题?fopen()里的文件名参 数单独给它编下码就行,php有iconv()这个改换编码的程序,把utf-8转成 gb2312就可以避免中文文件名为乱码了
fopen()里的文件名参数单独给它编下码就行,php有iconv()这个改换编码的程序,把utf-8转成gb2312就可以避免中午文件名乱码了
function iconv_system($str){
global $config;
$result = iconv($config['app_charset'], $config['system_charset'], $str);
if (strlen($result)==0) {
$result = $str;
}
return $result;
}
$dir= '中文目录';
$path = iconv_system($absolute_path .'home/'.$dir);
mk_dir($path);32.以下代码的执行后是,$result值为:
<?php
$x=””;
$result=is_null($x);
?>A、 null
B、 true
C、 false
D、 1
答案:C
33.常用的缓存有哪些?分别的应用场景如何?
1、全页面静态化缓存:将页面全部生成为HTML静态页面,用户访问时直接访问静态页面,不走PHP服务器的解析流程。此种方式在CMS系统中比较常见,如dedecms。
2、页面部分缓存:将页面中不常变动的部分进行静态化缓存,而经常变化的部分不缓存,最后组装在一起显示;可以使用类似ob_get_contents()的方式实现,也可以利用类似ESI之类的页面片段缓存策略,使其用来做动态页面中相对静态的片段部分的缓存。该缓存方式常用与商城中的商品页。
3、数据缓存:缓存数据的一种方式。比如,商城中的某个商品信息,当用商品id去请求时,就会得出包括店铺信息、商品信息等数据,此时就可以将这些 数据缓存到一个php文件中,文件名包含商品id来建一个唯一标示;下一次有人想查看这个商品时,首先就直接调这个文件里面的信息,而不用再去数据库查 询;其实缓存文件中缓存的就是一个php数组之类;Ecmall商城系统里面就用了这种方式;
4、查询缓存:根据查询来进行缓存。将查询得到的数据缓存在一个文件中,下次遇到相同的查询时,就直接先从这个文件里面调数据,不再去查数据库;但此处的缓存文件名可能就需要以查询语句为基点来建立唯一标示.
注意:以上几种缓存方式都需要对缓存的文件设置一个有效时间,在这个时间内,相同的访问会先取缓存文件的内容,超过有效时间后就重新从数据库中获取数据,并生成新的缓存文件。
5、内存式缓存:使用redis,memcached等nosql数据库设置PHP缓存,通过缓存查询结果,来减少数据库的访问次数,从而提高网站的响应速度。
6、apache缓存模块:apache安装完以后,是不允许被cache的。如果外接了cache或squid服务器要求进行web加速的话,就需要在htttpd.conf里进行设置,当然前提是在安装apache的时候要激活mod_cache的模块。
安装apache时:./configure –enable-cache –enable-disk-cache –enable-mem-cache
7、PHP APC缓存扩展:使用PHP中的APC扩展来进行缓存
8、Opcode:首先php代码被解析为Tokens,然后再编译为Opcode码,最后执行Opcode码,返回结果;所以,对于相同的php文件,第一次运行时 可以缓存其Opcode码,下次再执行这个页面时,直接会去找到缓存下的opcode码,直接执行最后一步,而不再需要中间的步骤了。比较知名的是XCache、Turck MM Cache、PHP Accelerator等
34. 请解释php中的垃圾回收机制?
php中的变量存储在变量容器zval中,zval中除了存储变量类型和值外,还有is_ref和refcount字段。refcount表示指向变量的元素个数,is_ref表示变量是否有别名。如果refcount为0时,就回收该变量容器。如果一个zval的refcount大于1,它就会进入垃圾缓冲区。当缓冲区达到最大值后,回收算法会循环遍历zval,判断其是否为垃圾,并进行释放处理。

35. php常用的设计模式有哪些?设计模式的6大原则是什么?
一.6大原则
1.单一职责原则(Single Responsibility Principle)
定义:就一个类而言,应该仅有一个引起它变化的原因;
如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责变化可能会消弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏;
T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。也就是说职责P1和P2被耦合在了一起。
单一职责比较容易理解,但是在实际设计过程中容易发生职责扩散:因为某种原因,某一职责被分化为颗粒度更细的多个职责了。
解决办法:遵守单一职责原则,将不同的职责封装到不同的类或模块中。
2.里氏替换原则(LiskovSubstitution Principle)
定义:子类型必须能够替换掉它们的父类型;
一个软件实体如果使用的是一个父类的话,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,在软件里面,把父类都替换成它的子类,程序的行为没有变化;
只有子类可以替换父类,软件单位功能不受到影响时,父类才能真正被复用,而子类也能够在父类的基础上增加新的行为;里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
在进行设计的时候,我们尽量从抽象类继承,而不是从具体类继承。如果从继承等级树来看,所有叶子节点应当是具体类,而所有的树枝节点应当是抽象类或者接口。
3.依赖倒置原则(DependenceInversion Principle)
定义:
A.高层模块不应该依赖低层模块。两个都应该依赖抽象;
B.抽象不应该依赖细节,细节应该依赖抽象;(针对接口编程,而不是针对实现;)
面向过程的开发,上层调用下层,上层依赖于下层,当下层剧烈变动时上层也要跟着变动,这就会导致模块的复用性降低而且大大提高了开发的成本。依赖倒转很好的解决了这个问题;
4.合成/聚合原则(Composite/Aggregate Reuse Principle)
定义:尽量使用合成/聚合,尽量不要使用类继承;
优先使用对象的合成/聚合将有助于你保持每个类被封装,并被集中在单个任务上。这样类和类继承层次会保持较小规模,并且不太可能增长为不可控制的庞然大物;
为什么尽量不要使用类继承而使用合成/聚合?
对象的继承关系在编译时就定义好了,所以无法在运行时改变从父类继承的子类的实现。
子类的实现和它的父类有非常紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化。
当你复用子类的时候,如果继承下来的实现不适合解决新的问题,则父类必须重写或者被其它更适合的类所替换。
这种依赖关系限制了灵活性,并最终限制了复用性。
5.迪米特法则(Law Of Demeter)
定义:如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用,如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用;
迪米特根本思想是:类之间的松耦合;
类之间的耦合越弱,越有利于复用,一个处于弱耦合的类被修改,不会对有关系的类造成波及。信息的隐藏促进了软件的复用;
广义的迪米特法则在类的设计上的体现:
优先考虑将一个类设置成不变类。
尽量降低一个类的访问权限。
谨慎使用Serializable。
尽量降低成员的访问权限。
6.开放-封闭原则(Open Closed Principle)
定义:软件实体(类,模块,函数等等)应该可以扩展,但是不可以修改;
对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。
对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对类进行任何修改。
这样的设计,能够面对需求改变却可以保持相对稳定,从而使系统在第一个版本以后不断推出新的版本;面对需求,对程序的改动是通过增加新的代码进行的,而不是更改现有的代码;
开放封闭原则,是最为重要的设计原则,Liskov替换原则和合成/聚合复用原则为开放封闭原则的实现提供保证。
二.3种类型
设计模式分为那几类,它们是怎么区分的,每一种模式类型的特点,包含具体模式呢?
设计模式按照目的来分,可以分为创建型模式、结构型模式和行为型模式。
1.创建型
创建型模式用来处理对象的创建过程,主要包含以下5种设计模式:
工厂方法模式(Factory Method Pattern)
抽象工厂模式(Abstract Factory Pattern)
建造者模式(Builder Pattern)
原型模式(Prototype Pattern)
单例模式(Singleton Pattern)
2.结构型
结构型模式用来处理类或者对象的组合,主要包含以下7种设计模式:
适配器模式(Adapter Pattern)
桥接模式(Bridge Pattern)
组合模式(Composite Pattern)
装饰者模式(Decorator Pattern)
外观模式(Facade Pattern)
享元模式(Flyweight Pattern)
代理模式(Proxy Pattern)
3.行为型
行为型模式用来对类或对象怎样交互和怎样分配职责进行描述,主要包含以下11种设计模式:
责任链模式(Chain of Responsibility Pattern)
命令模式(Command Pattern)
解释器模式(Interpreter Pattern)
迭代器模式(Iterator Pattern)
中介者模式(Mediator Pattern)
备忘录模式(Memento Pattern)
观察者模式(Observer Pattern)
状态模式(State Pattern)
策略模式(Strategy Pattern)
模板方法模式(Template Method Pattern)
访问者模式(Visitor Pattern)
三.总结
设计原则是实现代码复用,增加可维护性。而设计模式就是实现了这些原则,达到了代码复用和增加可维护行的目的。设计模式的重点还是熟练理解理论知识的基础上能够做大灵活的应用,让设计出来的系统更加健壮,代码更加优化。前期刚学习的时候,做到能够套用,随着熟练程度的加深,达到无招胜有招,将各种模式融合的系统的实践中。
36. 常用的linux命令有哪些?
1、显示日期的指令: date
2、显示日历的指令:cal
3、简单好用的计算器:bc
4、重要的几个热键[Tab],[ctrl]-c, [ctrl]-d
[Tab]按键---具有『命令补全』不『档案补齐』的功能
[Ctrl]-c按键---让当前的程序『停掉』
[Ctrl]-d按键---通常代表着:『键盘输入结束(End Of File, EOF 戒 End OfInput)』的意思;另外,他也可以用来取代exit
5、数据同步写入磁盘: sync
6、惯用的关机指令:shutdown
7、切换执行等级: init
Linux共有七种执行等级:
0 表示关机
1 表示单用户模式,单用户模式下只有系统管理员才能登陆
2 表示多用户模式,不支持文件共享,例如不支持NFS服务。这种模式不常用。
3 表示完全多用户模式,这是NFS服务。这是最常用的用户模式,默认登陆到系统的字符界面。
4 表示基本不用的用户模式,可以实现某些特些特定的登陆请求
5 表示完全多用户模式,默认登陆到X-Window系统,也就是登陆到Linux图像界面
6 表示重启模式,也就是关闭所有运行进程,然后重启系统服务
使用init这个指令来切换各模式:
如果你想要关机的话,除了上述的shutdown -h now以及poweroff之外,你也可以使用如下的指令来关机: init 0
8、改变文件的所属群组:chgrp
9、改变文件拥有者:chown
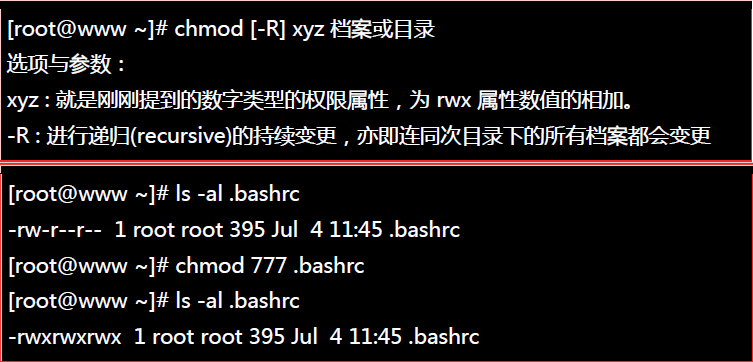
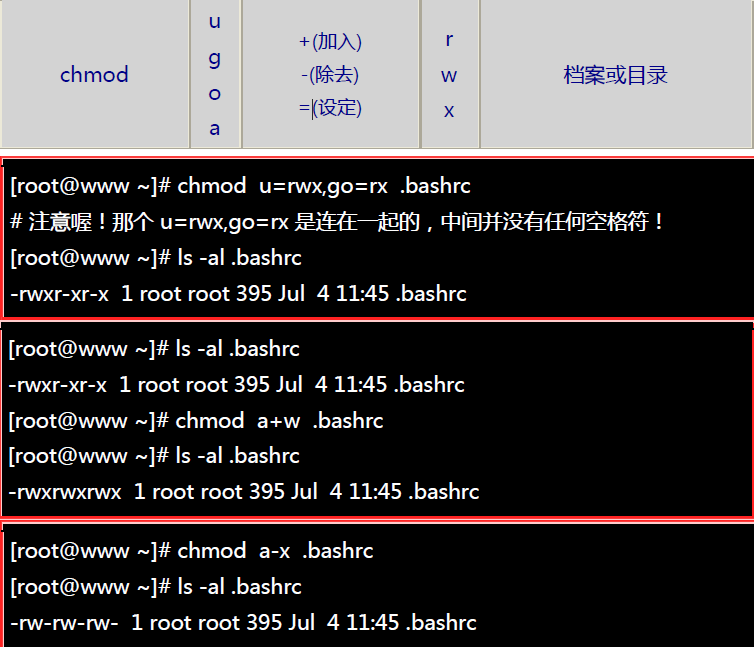
10、改变文件的权限:chmod
| 权限的设定方法有两种, 分别可以使用数字或者是符号来进行权限的变更。 |
--数字类型改变档案权限:
--符号类型改变档案权限:
11、变换目录:cd
12、显示当前所在目录:pwd
13、建立新目录:mkdir
14、删除『空』的目录:rmdir
15、档案与目录的显示:ls
16、复制档案或目录:cp
17、移除档案或目录:rm
18、移动档案与目录,或更名:mv
19、取得路径的文件名与目录名:basename,dirname
20、由第一行开始显示档案内容:cat
21、从最后一行开始显示:tac(可以看出 tac 是 cat 的倒着写)
22、显示的时候,顺道输出行号:nl
23、一页一页的显示档案内容:more
24、与 more 类似,但是比 more 更好的是,他可以往前翻页:less
25、只看头几行:head
26、只看尾几行:tail
27、以二进制的放置读取档案内容:od
28、修改档案时间或新建档案:touch
29、档案预设权限:umask
30、配置文件档案隐藏属性:chattr
31、显示档案隐藏属性:lsattr
32、观察文件类型:file
33、寻找【执行挡】:which
34、寻找特定档案:whereis
35、寻找特定档案:locate
36、寻找特定档案:find
37、压缩文件和读取压缩文件:gzip,zcat
38、压缩文件和读取压缩文件:bzip2,bzcat
39、压缩文件和读取压缩文件:tar
37.echo intval(0.58*100)等于58为什么?
如果你仔细看过在PHP手册中,对于浮点数据类型的说明,就会看到其中有专门的一个警告提示,就谈到这个问题:
关于浮点数精度的警告
显然简单的十进制分数如同 0.1 或 0.7不能在不丢失一点点精度的情况下转换为内部二进制的格式。这就会造成混乱的结果:
例如,floor((0.1+0.7)*10)通常会返回 7 而不是预期中的 8,因为该结果内部的表示其实是类似 7.9。
这和一个事实有关,那就是不可能精确的用有限位数表达某些十进制分数。例如,十进制的 1/3 变成了 0.3。
所以永远不要相信浮点数结果精确到了最后一位,也永远不要比较两个浮点数是否相等。如果确实需要更高的精度,应该使用任意精度数学函数或者 gmp 函数。
实际上,并不是php会有这种现象,对于其他计算机语言,类似的浮点数问题也是差不多的
关于浮点数精度的警告
显然简单的十进制分数如同 0.1 或 0.7不能在不丢失一点点精度的情况下转换为内部二进制的格式。这就会造成混乱的结果:
例如,floor((0.1+0.7)*10)通常会返回 7 而不是预期中的 8,因为该结果内部的表示其实是类似 7.9。
这和一个事实有关,那就是不可能精确的用有限位数表达某些十进制分数。例如,十进制的 1/3 变成了 0.3。
所以永远不要相信浮点数结果精确到了最后一位,也永远不要比较两个浮点数是否相等。如果确实需要更高的精度,应该使用任意精度数学函数或者 gmp 函数。
实际上,并不是php会有这种现象,对于其他计算机语言,类似的浮点数问题也是差不多的38.php使用swoole的应用场景你知道的有哪些?
场景1 - 实时收集定位数据实时输出(例 滴滴司机行驶轨迹)
场景2 - 只收集定位设备入库
场景3-IM系统
39. 协程、进程、线程分别是什么?
进程、线程和协程是三个在多任务处理中常听到的概念,三者各有区别又相互联系。
进程
进程是一个程序在一个数据集中的一次动态执行过程,可以简单理解为“正在执行的程序”,它是CPU资源分配和调度的独立单位。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
进程的局限是创建、撤销和切换的开销比较大。
线程
线程是在进程之后发展出来的概念。 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。一个进程可以包含多个线程。
线程的优点是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生“死锁”。
协程
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。
子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。
协程的起始处是第一个入口点,在协程里,返回点之后是接下来的入口点。在python中,协程可以通过yield来调用其它协程。通过yield方式转移执行权的协程之间不是调用者与被调用者的关系,而是彼此对称、平等的,通过相互协作共同完成任务。其运行的大致流程如下:
第一步,协程A开始执行。
第二步,协程A执行到一半,进入暂停,通过yield命令将执行权转移到协程B。
第三步,(一段时间后)协程B交还执行权。
第四步,协程A恢复执行。协程的特点在于是一个线程执行,与多线程相比,其优势体现在:
- 协程的执行效率非常高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
- 协程不需要多线程的锁机制。在协程中控制共享资源不加锁,只需要判断状态就好了。
Tips:利用多核CPU最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
参考:
1.进程、线程和协程的区别
2.协程-廖雪峰的官方网站
3.阮一峰的网络日志
40.需要设置一个有效期为31天,的memcache值,请补充下面的代码?
<?php
$memcache_obj=new memcache
$memcache_obj->connect(‘memcache_host,11211’);
$memcache_obj->set(‘varKey’,’varValue’,0,____);
?>41. 常见的关系型数据库管理系统产品有?
Oracle、SQL Server、MySQL、Sybase、DB2、Access等。
42. SQL语言包括哪几部分?每部分都有哪些操作关键字?
SQL语言包括数据定义(DDL)、数据操纵(DML),数据控制(DCL)和数据查询(DQL)四个部分。
数据定义:Create Table,Alter Table,Drop Table, Craete/Drop Index等
数据操纵:Select ,insert,update,delete,
数据控制:grant,revoke
数据查询:select
43. 完整性约束包括哪些?
数据完整性(Data Integrity)是指数据的精确(Accuracy)和可靠性(Reliability)。
分为以下四类:
1) 实体完整性:规定表的每一行在表中是惟一的实体。
2) 域完整性:是指表中的列必须满足某种特定的数据类型约束,其中约束又包括取值范围、精度等规定。
3) 参照完整性:是指两个表的主关键字和外关键字的数据应一致,保证了表之间的数据的一致性,防止了数据丢失或无意义的数据在数据库中扩散。
4) 用户定义的完整性:不同的关系数据库系统根据其应用环境的不同,往往还需要一些特殊的约束条件。用户定义的完整性即是针对某个特定关系数据库的约束条件,它反映某一具体应用必须满足的语义要求。
与表有关的约束:包括列约束(NOT NULL(非空约束))和表约束(PRIMARY KEY、foreign key、check、UNIQUE) 。
44. 什么是事务?及其特性?
事务:是一系列的数据库操作,是数据库应用的基本逻辑单位。
事务特性:
(1)原子性:即不可分割性,事务要么全部被执行,要么就全部不被执行。
(2)一致性或可串性。事务的执行使得数据库从一种正确状态转换成另一种正确状态
(3)隔离性。在事务正确提交之前,不允许把该事务对数据的任何改变提供给任何其他事务,
(4) 持久性。事务正确提交后,其结果将永久保存在数据库中,即使在事务提交后有了其他故障,事务的处理结果也会得到保存。
或者这样理解:
事务就是被绑定在一起作为一个逻辑工作单元的SQL语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。要将有组语句作为事务考虑,就需要通过ACID测试,即原子性,一致性,隔离性和持久性。
45. 什么是锁?
数据库是一个多用户使用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。
加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
基本锁类型:锁包括行级锁和表级锁
46. 什么叫视图?游标是什么?
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
47. 什么是存储过程?用什么来调用?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。可以用一个命令对象来调用存储过程。
48. 索引的作用?和它的优点缺点是什么?
索引就一种特殊的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引允许指定单个列或者是多个列。缺点是它减慢了数据录入的速度,同时也增加了数据库的尺寸大小。
49. 如何通俗地理解三个范式?
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。。
50. 什么是基本表?什么是视图?
基本表是本身独立存在的表,在 SQL 中一个关系就对应一个表。 视图是从一个或几个基本表导出的表。视图本身不独立存储在数据库中,是一个虚表
51. 试述视图的优点?
(1) 视图能够简化用户的操作
(2) 视图使用户能以多种角度看待同一数据;
(3) 视图为数据库提供了一定程度的逻辑独立性;
(4) 视图能够对机密数据提供安全保护。
52. NULL是什么意思
NULL这个值表示UNKNOWN(未知):它不表示“”(空字符串)。对NULL这个值的任何比较都会生产一个NULL值。您不能把任何值与一个 NULL值进行比较,并在逻辑上希望获得一个答案。
使用IS NULL来进行NULL判断
53. 主键、外键和索引的区别?
主键、外键和索引的区别
定义:
主键--唯一标识一条记录,不能有重复的,不允许为空
外键--表的外键是另一表的主键, 外键可以有重复的, 可以是空值
索引--该字段没有重复值,但可以有一个空值
作用:
主键--用来保证数据完整性
外键--用来和其他表建立联系用的
索引--是提高查询排序的速度
个数:
主键--主键只能有一个
外键--一个表可以有多个外键
索引--一个表可以有多个唯一索引
54. 你可以用什么来确保表格里的字段只接受特定范围里的值?
Check限制,它在数据库表格里被定义,用来限制输入该列的值。
触发器也可以被用来限制数据库表格里的字段能够接受的值,但是这种办法要求触发器在表格里被定义,这可能会在某些情况下影响到性能。
55. 说说对SQL语句优化有哪些方法?(选择几条)
(1)Where子句中:where表之间的连接必须写在其他Where条件之前,那些可以过滤掉最大数量记录的条件必须写在Where子句的末尾.HAVING最后。
(2)用EXISTS替代IN、用NOT EXISTS替代NOT IN。
(3) 避免在索引列上使用计算
(4)避免在索引列上使用IS NULL和IS NOT NULL
(5)对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
(6)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
(7)应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
56. SQL语句中‘相关子查询’与‘非相关子查询’有什么区别?
子查询:嵌套在其他查询中的查询称之。
子查询又称内部,而包含子查询的语句称之外部查询(又称主查询)。
所有的子查询可以分为两类,即相关子查询和非相关子查询
(1)非相关子查询是独立于外部查询的子查询,子查询总共执行一次,执行完毕后将值传递给外部查询。
(2)相关子查询的执行依赖于外部查询的数据,外部查询执行一行,子查询就执行一次。
故非相关子查询比相关子查询效率高
57. char和varchar的区别?
是一种固定长度的类型,varchar则是一种可变长度的类型,它们的区别是:
char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些填补出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节).
58. Mysql 的存储引擎,myisam和innodb的区别。
- 1.InnoDB支持事务,MyISAM不支持,这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而MyISAM就不可以了。
- 2.MyISAM适合查询以及插入为主的应用,InnoDB适合频繁修改以及涉及到安全性较高的应用
- 3.InnoDB支持外键,MyISAM不支持
- 4.MyISAM是默认引擎,InnoDB需要指定
- 5.InnoDB不支持FULLTEXT类型的索引
- 6.InnoDB中不保存表的行数,如select count(*) from table时,InnoDB需要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含where条件时MyISAM也需要扫描整个表
- 7.对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立联合索引
- 8.清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表
- 9.InnoDB支持行锁(某些情况下还是锁整表,如 update table set a=1 where user like '%lee%'
59. 请对于据select * from tableExample where ((a and b) and c or (((a and b ) and (c and d)))优化的语句。
select * from tableExample where (a and b and c) or (a and b and c and d);60. MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化?
a. 设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。
b. 选择合适的表字段数据类型和存储引擎,适当的添加索引。
c. mysql库主从读写分离。
d. 找规律分表,减少单表中的数据量提高查询速度。
e.添加缓存机制,比如memcached,apc等。
f. 不经常改动的页面,生成静态页面。
g. 书写高效率的SQL。比如 SELECT * FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE.
61. 数据库的垂直拆分和水平拆分各代表什么意思?
当我们使用读写分离、缓存后,数据库的压力还是很大的时候,这就需要使用到数据库拆分了
数据库拆分简单来说,就是指通过某种特定的条件,按照某个维度,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面以达到分散单库(主机)负载的效果。
切分模式: 垂直(纵向)拆分、水平拆分。
垂直拆分
专库专用
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分类,分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
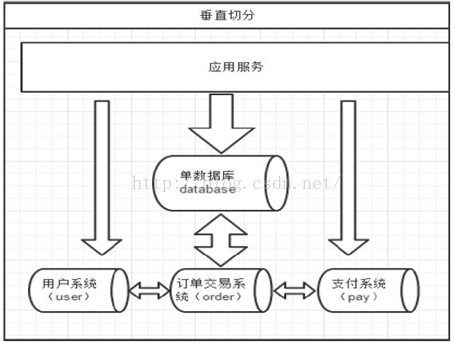
优点:
1. 拆分后业务清晰,拆分规则明确。
2. 系统之间整合或扩展容易。
3. 数据维护简单。
缺点:
1. 部分业务表无法join,只能通过接口方式解决,提高了系统复杂度。
2. 受每种业务不同的限制存在单库性能瓶颈,不易数据扩展跟性能提高。
3. 事务处理复杂。
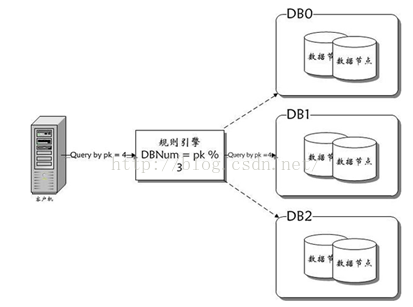
水平拆分
垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式,如图:
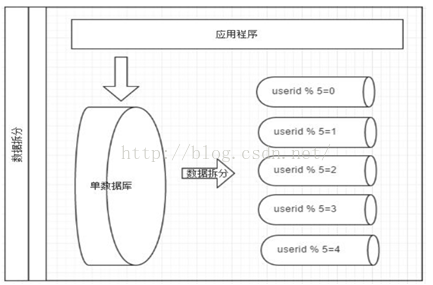
优点:
1. 不存在单库大数据,高并发的性能瓶颈。
2. 对应用透明,应用端改造较少。
3. 按照合理拆分规则拆分,join操作基本避免跨库。
4. 提高了系统的稳定性跟负载能力。
缺点:
1. 拆分规则难以抽象。
2. 分片事务一致性难以解决。
3. 数据多次扩展难度跟维护量极大。
4. 跨库join性能较差。
拆分的处理难点
两张方式共同缺点
1. 引入分布式事务的问题。
2. 跨节点Join 的问题。
3. 跨节点合并排序分页问题。
针对数据源管理,目前主要有两种思路:
A. 客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个 数据库,在模块内完成数据的整合。
优点:相对简单,无性能损耗。
缺点:不够通用,数据库连接的处理复杂,对业务不够透明,处理复杂。
B. 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;
优点:通用,对应用透明,改造少。
缺点:实现难度大,有二次转发性能损失。
拆分原则
1. 尽量不拆分,架构是进化而来,不是一蹴而就。(SOA)
2. 最大可能的找到最合适的切分维度。
3. 由于数据库中间件对数据Join 实现的优劣难以把握,而且实现高性能难度极大,业务读取 尽量少使用多表Join -尽量通过数据冗余,分组避免数据垮库多表join。
4. 尽量避免分布式事务。
5. 单表拆分到数据1000万以内。
切分方案
范围、枚举、时间、取模、哈希、指定等
案例分析
场景一
建立一个历史his系统,将公司的一些历史个人游戏数据保存到这个his系统中,主要是写入,还有部分查询,读写比约为1:4;由于是所有数据的历史存取,所以并发要求比较高;
分析:
历史数据
写多都少
越近日期查询越频繁?
什么业务数据?用户游戏数据
有没有大规模分析查询?
数据量多大?
保留多久?
机器资源有多少?
方案1:按照日期每月一个分片
带来的问题:1.数据热点问题(压力不均匀)
方案2:按照用户取模, --by Jerome 就这个比较合适了
带来的问题:后续扩容困难
方案3:按用户ID范围分片(1-1000万=分片1,xxx)
带来的问题:用户活跃度无法掌握,可能存在热点问题
场景二
建立一个商城订单系统,保存用户订单信息。
分析:
电商系统
一号店或京东类?淘宝或天猫?
实时性要求高
存在瞬时压力
基本不存在大规模分析
数据规模?
机器资源有多少?
维度?商品?用户?商户?
方案1:按照用户取模,
带来的问题:后续扩容困难
方案2:按用户ID范围分片(1-1000万=分片1,xxx)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案3:按省份地区或者商户取模
数据分配不一定均匀
场景3
上海公积金,养老金,社保系统
分析:
社保系统
实时性要求不高
不存在瞬时压力
大规模分析?
数据规模大
数据重要不可丢失
偏于查询?
方案1:按照用户取模,
带来的问题:后续扩容困难
方案2:按用户ID范围分片(1-1000万=分片1,xxx)
带来的问题:用户活跃度无法掌握,可能存在热点问题
方案3:按省份区县地区枚举
数据分配不一定均匀
数据库问题解决后,应用面对的新挑战就是拆分应用等
62. 假设给你5台服务器你如何搭建日pv300w访问的中型网站?请说说思路?
1、5台服务器,应该3台应该设置为web服务器;2台设置为 mysql数据库服务器!
2、3台Web服务器可以结合Memcache缓存或者redis来减少负载!
3、2台mysql服务器采用Master/Slave同步的方式减轻数据库负载!
4、3台Web服务器内容一致,采用DNS进行负载均衡!
63.DNS除了解析域名,还能干吗?
(1)智能DNS,根据用户ip来就近访问服务器;
(2)DNS轮询,水平扩展反向代理层;
(3)利用DNS实施负载均衡;
64.写一个正则表达式,过滤JS脚本(及把script标记及其内容都去掉)
$text = '<script>alert('XSS')</script>';
$pattern = '<script.*>.*<\/script>/i';
$text = preg_replace($pattern, '', $text);
65.mysql_fetch_array与mysql_fetch_row用法的区别是什么?
mysql_fetch_row() 函数从bai结果集中取得一行作为数du字数组
返回zhi根据所取得的行生成的dao数组,zhuan如果没有更多行则返回 false
mysql_fetch_array() 函数从结果集中取得一行作为关联数组,或数字数组,或二者兼有返回根据从结果集取得的行生成的数组,如果没有更多行则返回 false。
mysql_fetch_array() 是 mysql_fetch_row() 的扩展版本。除了将数据以数字索引方式储存在数组中之外,还可以将数据作为关联索引储存,用字段名作为键名。66.isset和empty和is_null的区别
empty()
如果 变量 是非空或非零的值,则 empty() 返回 FALSE。换句话说,""、0、"0"、NULL、FALSE、array()、var $var、未定义,以及没有任何属性的对象都将被认为是空的,如果 var 为空,则返回 TRUE。
isset()
如果 变量 存在且值非NULL,则返回 TRUE,否则返回 FALSE(包括未定义)。变量值设置为:null,返回也是false;unset一个变量后,变量被取消了。注意,isset对于NULL值变量,特殊处理。
is_null()
检测传入值【值,变量,表达式】是否是null,只有一个变量定义了,且它的值是null,它才返回TRUE . 其它都返回 FALSE 【未定义变量传入后会出错!】。67.请举例说明在你的开发过程中用什么方法来加快页面的加载速度
要用到服务器资源时才打开,及时关闭服务器资源,数据库添加索引,页面可生成静态,图片等大文件单独服务器。使用代码优化工具。
68.使用过哪些php框架试描述其优劣点
ThinkPHP
ThinkPHP(FCS)是一个轻量级的中型框架,是从Java的Struts结构移植过来的中文PHP开发框架。它使用面向对象的开发结构和MVC模式,并且模拟实现了Struts的标签库,各方面都比较人性化,熟悉J2EE的开发人员相对比较容易上手,适合php框架初学者。 ThinkPHP的宗旨是简化开发、提高效率、易于扩展,其在对数据库的支持方面已经包括MySQL、MSSQL、Sqlite、PgSQL、 Oracle,以及PDO的支持。ThinkPHP有着丰富的文档和示例,框架的兼容性较强,但是其功能有限,因此更适合用于中小项目的开发。
优点:
1.易于上手,有丰富的中文文档;
2.框架的兼容性较强,PHP4和PHP5完全兼容、完全支持UTF8等。
3. 适合用于中小项目的开发
缺点:
1.对Ajax的支持不是很好;
2.目录结构混乱,需要花时间整理;
3.上手容易,但是深入学习较难。
Yii
Yii 是一个基于组件的高性能php框架,用于开发大型Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从 MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主题化,I18N和L10N,Yii提供了 今日Web 2.0应用开发所需要的几乎一切功能。事实上,Yii是最有效率的PHP框架之一。
优点:
纯OOP
用于大规模Web应用
模型使用方便
开发速度快,运行速度也快。性能优异且功能丰富
使用命令行工具。
缺点:
对Model层的指导和考虑较少
文档实例较少
英文太多
要求PHP技术精通,OOP编程要熟练!
View并不是理想view,理想中的view可能只是html代码,不会涉及PHP代码。
CodeIgniter
优点:
Code Igniter推崇“简单就是美”这一原则。没有花哨的设计模式、没有华丽的对象结构,一切都是那么简单。几行代码就能开始运行,再加几 行代码就可以进行输出。可谓是“大道至简”的典范。 配置简单,全部的配置使用PHP脚本来配置,执行效率高;具有基本的路由功能,能够进行一定程度的路 由;具有初步的Layout功能,能够制作一定程度的界面外观;数据库层封装的不错,具有基本的MVC功能. 快速简洁,代码不多,执行性能高,框架简 单,容易上手,学习成本低,文档详细;自带了很多简单好用的library,框架适合小型应用.
缺点:
本身的实现不太理想。内部结构过于混乱,虽然简单易用,但缺乏扩展能力。 把Model层简单的理解为数据库操作. 框架略显简单,只能够满足小型应用,略微不太能够满足中型应用需要.
评价:
总体来说,拿CodeIgniter来完成简单快速的应用还是值得,同时能够构造一定程度的layout,便于模板的复用,数据操作层来说封装的不 错,并且CodeIgniter没有使用很多太复杂的设计模式,执行性能和代码可读性上都不错。至于附加的library 也还不错,简洁高效。
Lavarel 框架
优点:
Laravel 的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD 和BDD,作为一个框
架,它准备好了一切,composer 是个php 的未来,没有composer,PHP 肯定要走向没落。
laravel 最大的特点和优秀之处就是集合了php 比较新的特性,以及各种各样的设计模式,
Ioc 容器,依赖注入等。
缺点:
基于组件式的框架,所以比较臃肿
69.一次完整的HTTP请求过程
完成一次http请求要大致可以分为7个步骤:
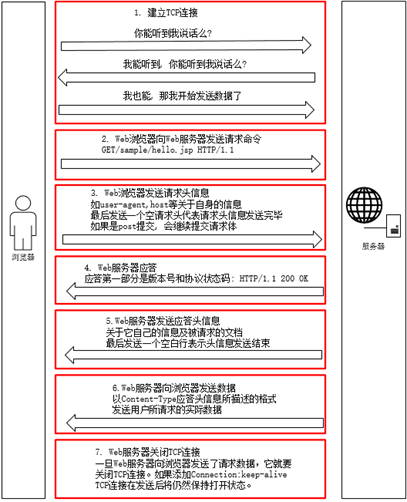
一、TCP三次握手
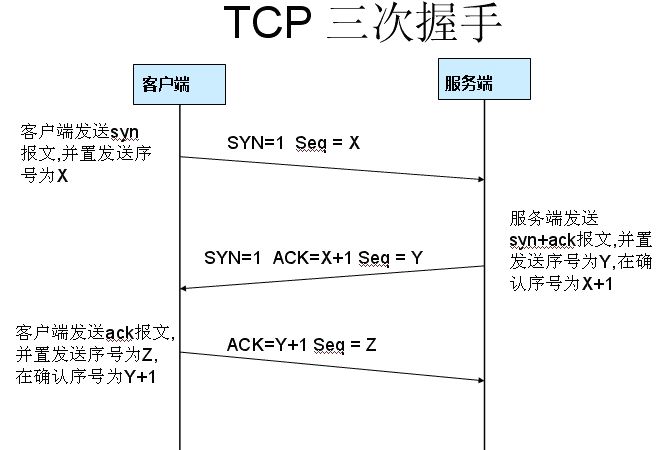
第一次握手:建立连接。客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认;
第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。
为什么要三次握手
为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
具体例子:“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
二~三、HTTP请求报文
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成,下图给出了请求报文的一般格式。
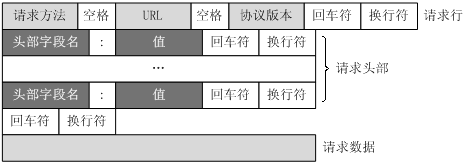
1.请求行
请求行分为三个部分:请求方法、请求地址和协议版本
请求方法
HTTP/1.1 定义的请求方法有8种:GET、POST、PUT、DELETE、PATCH、HEAD、OPTIONS、TRACE。
最常的两种GET和POST,如果是RESTful接口的话一般会用到GET、POST、DELETE、PUT。
请求地址
URL:统一资源定位符,是一种自愿位置的抽象唯一识别方法。
组成:<协议>://<主机>:<端口>/<路径>
端口和路径有时可以省略(HTTP默认端口号是80)
如下例:

有时会带参数,GET请求
协议版本
协议版本的格式为:HTTP/主版本号.次版本号,常用的有HTTP/1.0和HTTP/1.1
2.请求头部
请求头部为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
常见请求头如下:
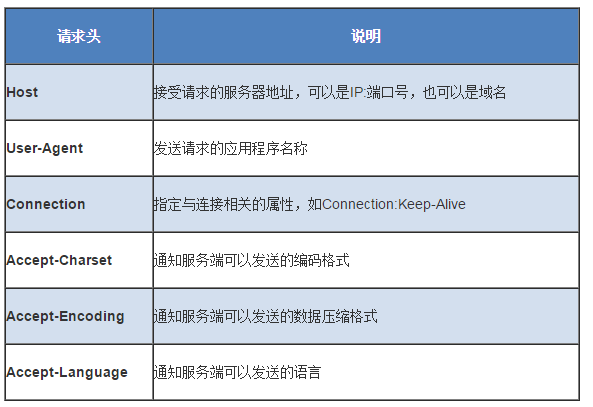
请求头部的最后会有一个空行,表示请求头部结束,接下来为请求数据,这一行非常重要,必不可少。
3.请求数据
可选部分,比如GET请求就没有请求数据。
下面是一个POST方法的请求报文:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
四~六、HTTP响应报文

HTTP响应报文主要由状态行、响应头部、空行以及响应数据组成。
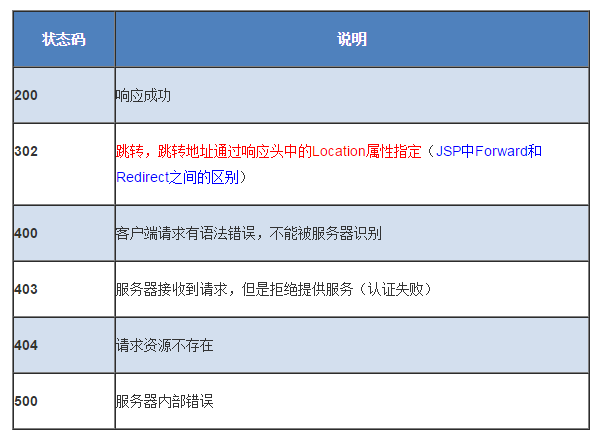
1.状态行
由3部分组成,分别为:协议版本,状态码,状态码描述。
其中协议版本与请求报文一致,状态码描述是对状态码的简单描述,所以这里就只介绍状态码。
状态码
状态代码为3位数字。
1xx:指示信息--表示请求已接收,继续处理。
2xx:成功--表示请求已被成功接收、理解、接受。
3xx:重定向--要完成请求必须进行更进一步的操作。
4xx:客户端错误--请求有语法错误或请求无法实现。
5xx:服务器端错误--服务器未能实现合法的请求。
下面列举几个常见的:
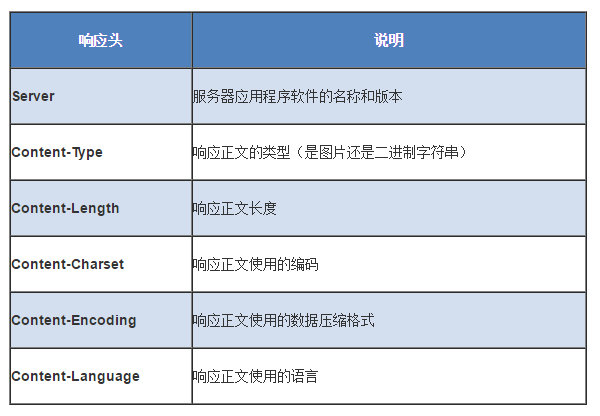
2.响应头部
与请求头部类似,为响应报文添加了一些附加信息
常见响应头部如下:
3.响应数据
用于存放需要返回给客户端的数据信息。
下面是一个响应报文的实例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
关于请求头部和响应头部的知识点很多,这里只是简单介绍。
通过以上步骤,数据已经传递完毕,HTTP/1.1会维持持久连接,但持续一段时间总会有关闭连接的时候,这时候据需要断开TCP连接。
七、TCP四次挥手
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了神秘的“四次分手”。
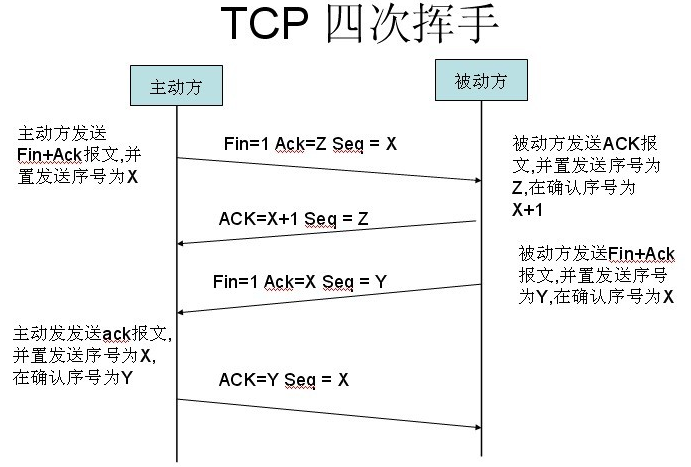
第一次分手:主机1(可以使客户端,也可以是服务器端),设置Sequence Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;
第二次分手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2告诉主机1,我“同意”你的关闭请求;
第三次分手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
第四次分手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
为什么要四次分手
TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
70.长链接的优势有哪些?
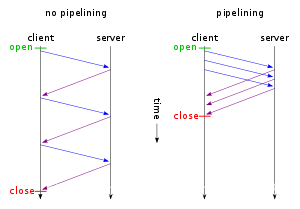
1、减少CPU及内存的使用,因为不需要经常的建立及关闭连接,当然高峰并发时CPU及内存也是比较多的;
2、允许HTTP pipelining(HTTP 1.1中支持)的请求及响应模式:
为了便于理解HTTP pipelining,参见下图:
3、减少网络的堵塞,因为减少了TCP请求; 根据RFC 2616 (page 46)的标准定义,单个客户端不允许开启2个以上的长连接,这个标准的目的是减少HTTP响应的时候,减少网络堵塞
4、减少后续请求的响应时间,因为此时不需要建立TCP,也不需要TCP握手等过程;
5、当发生错误时,可以在不关闭连接的情况下进行提示;
71.如何查看服务器负载
top、htop、free、w、uptime、iostat
相关详细说明https://www.cnblogs.com/Geyoung/p/9516524.html
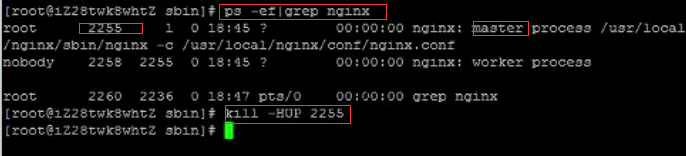
72.linux中如何重启php或nginx?
php
/usr/local/php/sbin/php-fpm restart
nginx
方法一:进入nginx可执行目录sbin下,输入命令./nginx -s reload 即可

方法二:查找当前nginx进程号,然后输入命令:kill -HUP 进程号 实现重启nginx服务
73.春节期间,甲乙丙三人用支付宝玩发红包游戏,只能通过各自账户余额来发红包,第一轮甲给乙的红包金额等于乙支付宝里面的账户余额,甲给丙的红包金额等于丙支付宝钱包的账户余额,与此同时,第二轮乙给甲和丙的红包金额等于他们各自支付宝钱包的账户余额,第三轮丙给甲和乙的红包金额等于他们各自支付宝钱包里面的账户余额,若最后大家支付宝钱包里面的余额都是16元,则甲最初的支付宝钱包账户余额为多少?
1、总金额无疑使48元,16*3
2、考虑到对于甲来说,熬过第一轮后面就是收钱不出钱了,收钱都是2的幂级数增加,所以第一轮过后他只剩4元。
3、此时乙和丙总共收到多少钱呢?答案是 (48-4)/ 2 = 22元
4、所以甲一开始有 22+4 = 26元
74.请写出PHP中的spl堆排序(大顶堆)
/因为是数组,下标从0开始,所以,下标为n根结点的左子结点为2n+1,右子结点为2n+2;
//初始化值,建立初始堆
$arr=array(49,38,65,97,76,13,27,50);
$arrSize=count($arr);
//将第一次排序抽出来,因为最后一次排序不需要再交换值了。
buildHeap($arr,$arrSize);
for($i=$arrSize-1;$i>0;$i--){
swap($arr,$i,0);
$arrSize--;
buildHeap($arr,$arrSize);
}
//用数组建立最小堆
function buildHeap(&$arr,$arrSize){
//计算出最开始的下标$index,如图,为数字"97"所在位置,比较每一个子树的父结点和子结点,将最小值存入父结点中
//从$index处对一个树进行循环比较,形成最小堆
for($index=intval($arrSize/2)-1; $index>=0; $index--){
//如果有左节点,将其下标存进最小值$min
if($index*2+1<$arrSize){
$min=$index*2+1;
//如果有右子结点,比较左右结点的大小,如果右子结点更小,将其结点的下标记录进最小值$min
if($index*2+2<$arrSize){
if($arr[$index*2+2]<$arr[$min]){
$min=$index*2+2;
}
}
//将子结点中较小的和父结点比较,若子结点较小,与父结点交换位置,同时更新较小
if($arr[$min]<$arr[$index]){
swap($arr,$min,$index);
}
}
}
}
//此函数用来交换下数组$arr中下标为$one和$another的数据
function swap(&$arr,$one,$another){
$tmp=$arr[$one];
$arr[$one]=$arr[$another];
$arr[$another]=$tmp;
}https://www.php.net/manual/zh/class.splmaxheap.php
75.redis有几种数据类型?简要说明每种数据类型的使用场景?
一、字符串
字符串类型是redis最基础的数据结构,首先键是字符串类型,而且其他几种结构都是在字符串类型基础上构建的,
所以字符串类型能为其他四种数据结构的学习尊定基础。
字符串类型实际上可以是字符串
(简单的字符串、复杂的字符串(xml、json)、数字(整数、浮点数)、二进制(图片、音频、视频)),
但最大不能超过512M。
使用场景:
缓存功能:字符串最经典的使用场景,redis最为缓存层,Mysql作为储存层,绝大部分请求数据都是
redis中获取,由于redis具有支撑高并发特性,所以缓存通常能起到加速读写和降低 后端压力的作用。
(redis为何具备支撑高并发的特性,下次文章讲解)。
计数器:许多运用都会使用redis作为计数的基础工具,他可以实现快速计数、查询缓存的功能,
同时数据可以一步落地到其他的数据源。
如:视频播放数系统就是使用redis作为视频播放数计数的基础组件。
共享session:出于负载均衡的考虑,分布式服务会将用户信息的访问均衡到不同服务器上,
用户刷新一次访问可能会需要重新登录,为避免这个问题可以用redis将用户session集中管理,
在这种模式下只要保证redis的高可用和扩展性的,每次获取用户更新或查询登录信息
都直接从redis中集中获取。
限速:处于安全考虑,每次进行登录时让用户输入手机验证码,为了短信接口不被频繁访问,
会限制用户每分钟获取验证码的频率。
二、哈希
在redis中哈希类型是指键本身又是一种键值对结构,如 value={{field1,value1},......{fieldN,valueN}}
1
使用场景:
哈希结构相对于字符串序列化缓存信息更加直观,并且在更新操作上更加便捷。
所以常常用于**用户信息**等管理,但是哈希类型和关系型数据库有所不同,哈希类型是稀疏的,
而关系型数据库是完全结构化的,关系型数据库可以做复杂的关系查询,而redis去模拟关系型复杂查询
开发困难,维护成本高。
三、列表
列表类型是用来储存多个有序的字符串,列表中的每个字符串成为元素(element),一个列表最多可以储存
2的32次方-1个元素,在redis中,可以队列表两端插入(pubsh)和弹出(pop),还可以获取指定范围的元素
列表、获取指定索引下表的元素等,列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,
在实际开发中有很多应用场景。
优点:
1.列表的元素是有序的,这就意味着可以通过索引下标获取某个或某个范围内的元素列表。
2.列表内的元素是可以重复的。
使用场景:
消息队列: redis的lpush+brpop命令组合即可实现阻塞队列,生产者客户端是用lupsh从列表左侧插入元素,
多个消费者客户端使用brpop命令阻塞时的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡
和高可用性
消息队列模型↑
文章列表:每个用户都有属于自己的文章列表,现在需要分页展示文章列表,此时可以考虑使用列表,列表不但有序
同时支持按照索引范围获取元素。
使用列表技巧:
lpush+lpop=Stack(栈)
lpush+rpop=Queue(队列)
lpush+ltrim=Capped Collection(有限集合)
lpush+brpop=Message Queue(消息队列)
四、集合
集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中不允许有重复的元素,并且集合中的元素是
无序的,不能通过索引下标获取元素,redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、
差集,并合理的使用好集合类型,能在实际开发中解决很多实际问题。
使用场景:
标签(tag):集合类型比较典型的使用场景,如一个用户对娱乐、体育比较感兴趣,另一个可能对新闻感兴
趣,这些兴趣就是标签,有了这些数据就可以得到同一标签的人,以及用户的共同爱好的标签,
这些数据对于用户体验以及曾强用户粘度比较重要。
(用户和标签的关系维护应该放在一个事物内执行,防止部分命令失败造成数据不一致)
sadd=tagging(标签)
spop/srandmember=random item(生成随机数,比如抽奖)
sadd+sinter=social Graph(社交需求)
五、有序集合
有序集合和集合有着必然的联系,他保留了集合不能有重复成员的特性,但不同得是,有序集合中的元素是可以
排序的,但是它和列表的使用索引下标作为排序依据不同的是,它给每个元素设置一个分数,作为排序的依据。
(有序集合中的元素不可以重复,但是csore可以重复,就和一个班里的同学学号不能重复,但考试成绩可以相
同)。
列表、集合、有序集合三者的异同点
使用场景:
排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:
按照时间、按照播放量、按照获得的赞数等。
还有 bitmaps, hyperloglogs, geospatial indexes ,streams
76.以下代码的执行后是,$result值为:
<?php
$a=’01’;
$result=1;
If(in_array($a,array(‘1’))){
$result=2;
}else if($a= =’1’){
$result=3;
}else if($a= =’01’){
$result=4;
}else{
$result=5;
}
?>A、1
B、2
C、3
D、4
E、5
答案:2
77.简述TCP和UDP的区别以及优缺点?
UDP 是面向无连接的通讯协议,UDP 数据包括目的端口号和源端信息。
优点:UDP 速度快、操作简单、要求系统资源较少,由于通讯不需要连接,可以实现广播发送
缺点:UDP 传送数据前并不与对方建立连接,对接收到的数据也不发送确认信号,发送端不知道数据是否会正确接收,也不重复发送,不可靠。
TCP 是面向连接的通讯协议,通过三次握手建立连接,通讯完成时四次挥手
优点:TCP 在数据传递时,有确认、窗口、重传、阻塞等控制机制,能保证数据正确性,较为可靠。
缺点:TCP 相对于 UDP 速度慢一点,要求系统资源较多。
78.请简述PHP常驻内存的方式cli与php-fpm运行模式的区别和优势
fpm 的优点是设计简单,采用多进程 master-worker 模式,没有线程协程之类的复杂问题,易于扩展,简单粗暴,而且每个 php-fpm 进程的生命周期有限,不用考虑大大减少了因资源泄露产生的问题。还有什么热更新、平滑重启,估计很多 PHP 程序员都没听说过。相较于快速的业务开发非常有利。
fpm缺点是 资源消耗比较大,对性能要求的场景下并不适用,诸如连接池、线程池在 php-fpm 模式下无法使用。
CLI 优点,常驻内存,提供了诸如线程、协程之类等复杂的能力,同时也使 PHP 有了更多的可能,连接池的实现不在话下。也有了和 NodeJS、 GO 等语言一拼的能力。
CLI 缺点,性能提高了,必然就失去 php-fpm 的简洁性。首先,需要支持 CLI 模式下的 web 服务器,裸写的难度比较大。有很多开源的方案可能选择,swoole 就是其中之一。编程难度增加了,上面说的那些 php-fpm 不用考虑的问题,如热更新、平滑重启都要被重视起来。还有,常驻内存的程序,资源泄露也是要谨慎考虑的一点。还有支持了协程、线程,数据竞争就有可能发生。
79. 一个6亿的表a,一个3亿的表b,通过外间tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。请写出相关的sql
1、如果A表TID是自增长,并且是连续的,B表的ID为索引
select * from a,b where a.tid = b.id and a.tid>500000 limit 200;
2、如果A表的TID不是连续的,那么就需要使用覆盖索引.TID要么是主键,要么是辅助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;
80.mysql中不使用事务和锁用sql如何解决高并发库存超卖?
加版本号【先select 后 update】
$db->query('update s_store set amount = amount - $num,version = version+1 where version=$version and postID = 123481.请写出PHP数组合并的几种方式
1、array_merge()
2、’+’
3、array_merge_recursive
array_merge 简单的合并数组
array_merge_recursive 合并两个数组,如果数组中有完全一样的数据,将它们递归合并
array_combine 和 ‘+’ :合并两个数组,前者的值作为新数组的键
82.四个人(A、B、C、D)晚上过桥,并且只有一个手电筒,每次只能过两个人,并且还需要有一个人回来传递手电
筒,每次只能过两个人,并且还需要有一个人回来传递手电筒,四个人过桥的速度不一样分别是1、2、5、10分钟,问怎么过桥最快?总共用多长时间?
来回送的应该是最快的
1、2速度的先过去,1回来,共3分钟
5、10速度的再过去,2回来,共12分钟
1、2速度的再过去,共2分钟
合3+12+2=17分钟
83.请写出815公交路线
我们有一系列公交路线。每一条路线 routes[i] 上都有一辆公交车在上面循环行驶。例如,有一条路线 routes[0] = [1, 5, 7],表示第一辆 (下标为0) 公交车会一直按照 1->5->7->1->5->7->1->… 的车站路线行驶。
假设我们从 S 车站开始(初始时不在公交车上),要去往 T 站。 期间仅可乘坐公交车,求出最少乘坐的公交车数量。返回 -1 表示不可能到达终点车站。
示例:
输入:
routes = [[1, 2, 7], [3, 6, 7]]
S = 1
T = 6
输出: 2
解释:
最优策略是先乘坐第一辆公交车到达车站 7, 然后换乘第二辆公交车到车站 6。
说明:
1 <= routes.length <= 500.
1 <= routes[i].length <= 500.
0 <= routes[i][j] < 10 ^ 6.
思路:这道题目就是个图的知识,
所以我们的出发点就是应该从图的角度来解。
首先呢,一个节点可能对应有多条节点(多条边)(一个公交车节点连接着多个公交车站节点,一个公交车站节点可能连接多个公交车节点) 所以我们需要遍历一遍,用Map存下
公交站节点所对应的多个公交车节点。 eg: 样例一 对应节点0和1.
我们从S开始,把所有符合公交车站节点S的对应的公交车节(这里是0)点加入队列中.
接着进行bfs搜索,每次搜索,我们将该队列中所有的公交车节点遍历一遍(类似层次遍历),
若遇到公交车站节点T,直接返回ans,若没遇到,每次访问一个公交车站结点,就访问
该公交车站节点所连接的公交车节点,若该公交车节点没有访问过,就加入备用队列(存新添加的未访问的公交车节点)中。
public class __815 {
public int numBusesToDestination(int[][] routes, int S, int T) {
if(S==T){
return 0;
}
Map<Integer,Set<Integer>> map=new HashMap<Integer, Set<Integer>>();
for(int i=0;i<routes.length;++i){
for(int j:routes[i]){
if(!map.containsKey(j)){
map.put(j,new HashSet<Integer>());
}
map.get(j).add(i);
}
}
Queue<Integer> queue=new LinkedList<Integer>();
Set<Integer> vis=new HashSet<Integer>();
for(int st:map.get(S)){
queue.offer(st);
vis.add(st);
}
int ans=1;
while (!queue.isEmpty()){
Queue<Integer> t=new LinkedList<Integer>(); //备用节点存新添加的未访问过的节点
while (!queue.isEmpty()){
int curCar=queue.poll();
for(int k:routes[curCar]){ //遍历当前公交车节点所连接的所有公交车站节点
if(k==T){ //遇到则直接返回结果
return ans;
}
for(int nextCar:map.get(k)){ //遍历当前公交车站节点连接的所有公交车节点
if(!vis.contains(nextCar)){ //未访问过的加入备用队列中
t.offer(nextCar);
vis.add(nextCar);
}
}
}
}
++ans;
queue=t;
}
return -1;
}
public static void main(String[] args) {
int[][] r={{1, 2, 7}, {3, 6, 7}};
System.out.println(new __815().numBusesToDestination(r,1,6));
}
}84.一群猴子排成一圈,按1,2,...,n依次编号。然后从第1只开始数,数到第m只,把它踢出圈,从它后面再开始数,再数到第m只,在把它踢出去...,如此不停的进行下去,直到最后只剩下一只猴子为止,那只猴子就叫做大王。要求编程模拟此过程,输入m、n,输出最后那个大王的编号
<?php
// 方案一,使用php来模拟这个过程
function king($n,$m){
$mokey = range(1, $n);
$i = 0;
while (count($mokey) >1) {
$i += 1;
$head = array_shift($mokey);//一个个出列最前面的猴子
if ($i % $m !=0) {
#如果不是m的倍数,则把猴子返回尾部,否则就抛掉,也就是出列
array_push($mokey,$head);
}
// 剩下的最后一个就是大王了
return $mokey[0];
}
}
// 测试
echo king(10,7);
// 方案二,使用数学方法解决
function josephus($n,$m){
$r = 0;
for ($i=2; $i <= $m ; $i++) {
$r = ($r + $m) % $i;
}
return $r+1;
}
// 测试
print_r(josephus(10,7));
?>85.请写出洗牌算法?
<?php
$card_num = 54;//牌数
function wash_card($card_num){
$cards = $tmp = array();
for($i = 0;$i < $card_num;$i++){
$tmp[$i] = $i;
}
for($i = 0;$i < $card_num;$i++){
$index = rand(0,$card_num-$i-1);
$cards[$i] = $tmp[$index];
unset($tmp[$index]);
$tmp = array_values($tmp);
}
return $cards;
}
// 测试:
print_r(wash_card($card_num));
?>86.请写出64匹马,8个跑道,问最少比赛多少场,可以选出跑得最快的4匹马的最优方案?
问题分析
- step1:需8场比赛
- 首先把64匹马随机分为8组并标记组别,遍历组别,比赛8次,并记录每组赛马名次(eg:A1>A2>...>A7>A8
- 首先可直接剔除各组后四名赛马,剩余64-4*8=32匹赛马待定
- step2:需1场比赛
- 选出每组排名第一的赛马进行一次比赛,记录结果,不失一般性地,记为:A1>B1>C1>D1>E1>F1>G1>H1
- 根据这轮比赛结果,首先可以剔除E、F、G、H这四组所有赛马(因为本组第一都未进入前4),剩余16匹马

-
- 其次可以确定A1就是全场MVP,属全场N01,剩余15匹马待定
- 还可以进一步细化
- D组2-4名赛马:D2>D3>D4,不可能是Top4,可剔除这3匹,剩余15-3=12匹赛马待定
- C组3-4名赛马:C3>C4,不可能是Top4,可剔除这2匹,剩余12-2=10匹赛马待定
- B组第4名赛马:B4,也不可能是Top4,可剔除这1匹,剩余10-1=9匹赛马待定
- step3:需1场or2场比赛
- 当前剩余待定9匹赛马:A2>A3>A4,B1>B2>B3,C1>C2,D1
- 因为可以确定B1>C1>D1,因此挑选:A2>A3>A4,B1>B2>B3,C1>C2( 或者 A2>A3>A4,B1>B2>B3,C1>D1)等8匹马进行一场比赛,剩余一匹赛马D1或者C2待定,重点关注C1名次
- 仅需1场比赛情形
- 当C1排名第3及以后,则选出本场前3名赛马,外加大佬A1,即为所求的Top4匹马
- 需2场比赛情形
- 因为已知B1>C1,所以C1本场名次区间为[2,8]
- 当C1排名第2时,可推知B1排名本场第一,因此A1>B1>C1即为全场Top3匹马,此时可剔除B1,C1两匹马,剩余9-2=7匹马待定(如下)
- 本轮上场剩余6匹:A2>A3>A4,B2>B3,C2
- 未上场1匹:D1
- 将本场剩余7匹赛马再进行一场比赛,一决高低,记录名次,选出本场排名第一的赛马,加上A1>B1>C1,即为全场Top4匹马。
问题答案
- 最少需要10场or11场
87.10 瓶水,其中一瓶有毒,小白鼠喝完有毒的水之后,会在 24 小时后死亡,问:最少用几只小白鼠可以在 24 小时后找到具体是哪一瓶水有毒
四只
二进制问题。薛定谔的老鼠。
一只老鼠有两个状态,死活,对应 01。假设老鼠的个数为 A,则有 2^A>=10; A=4;
思路很简单,十瓶药编号:0,1,10,11….1001;
0 不喝。第一只老鼠喝所有个位是 1 的:13579,第二只喝十位是 1 的,第三只和百位是 1 的,第四只喝千位是 1 的。
24 小时后,看下死了的是 1,活着的是 0。按老鼠的顺序乖乖站好…… 假如第一只和第三只死了,那就是 0101,就是 5 有问题
88.isset(null) isset(false) empty(null) empty(false)输出
false, true, true, true
89.两条相交的单向链表,如何求它们的第一个公共节点
- 如果两个链表相交,则从相交点开始,后面的节点都相同,即最后一个节点肯定相同;
- 从头到尾遍历两个链表,并记录链表长度,当二者的尾节点不同,则二者肯定不相交;
- 尾节点相同,如果A长为LA,B为LB,如果LA>LB,则A前LA-LB个先跳过
如果两个单向链表有公共的结点,也就是说两个链表从某一结点开始,它们的m_pNext都指向同一个结点。但由于是单向链表的结点,每个结点只有一个m_pNext,因此从第一个公共结点开始,之后它们所有结点都是重合的,不可能再出现分叉。所以,两个有公共结点而部分重合的链表,拓扑形状看起来像一个Y,而不可能像X。
参考文献:
https://blog.csdn.net/wcyoot/article/details/6426436
https://blog.csdn.net/Lieacui/article/details/52046548
90.应用中我们经常会遇到在user表随机调取10条数据来展示的情况,简述你如何实现该功能。
rand() 随机0-1之间的数 floor(1.6)=1 下取整 ceil(1.2)=2上取整 round(1.298,1) =1.3四舍五入 第二个参数是小数位数
//可以直接通过sql实现,不建议这么做
SELECT * FROM `user` WHERE id >= (SELECT FLOOR( MAX(id) * RAND()) FROM `user` ) ORDER BY id LIMIT 10;先通过php算出随机的几个id值,然后in的方式查出数据,推荐
function get_random_array($min,$max,$number)
{
$data = [];
for($i = 0;$i<$number;$i++;)
{
$d = mt_rand($min,$max);
if(in_array($d,$data)) {
$i--;
}else{
$data[] = $d;
}
}
return $data;
}
$sql = 'select * from user where user_id in (' .join(",",get_random_array($min,$max,$number)). ')'参考文章:
https://www.cnblogs.com/riasky/p/3367558.html
http://www.jb51.net/article/48801.htm
91.请获取当前客户端的IP地址,并判断是否在(111.111.111.111,222.222.222.222)
如果没有使用代理服务器:
ip =ip=_SERVER['REMOTE_ADDR'];
使用透明代理
ip =ip=_SERVER['HTTP_X_FORWARDED_FOR'];
$ip = sprintf('%u',ip2long($ip);
$begin = sprintf('%u',ip2long('111.111.111.111'))
$end = sprintf('%u',ip2long('222.222.222.222'))
if($ip > $begin && $ip < $end) {
echo "在这个区间里"。
}参考文章
92.从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是连续的
/**
*
* 从扑克牌中随机抽取5张牌,判断是不是一个顺子,
* 即这5张牌是不是连续的2-10位数字本身,A为1,J为11,Q为12,K为13,而大小王可以看成任意数字。
*
* 解题思路:
* 我们需要把扑克牌的背景抽象成计算机语言。不难想象,我们可以把5张牌看成由5个数字组成的数组。
* 大小王是特殊的数字,我们不妨把它们都当成0,这样和其他扑克牌代表的数字就不重复了。
* 接下来我们来分析怎样判断5个数字是不是连续的。最直观的是,我们把数组排序。
* 但值得注意的是,由于0可以当成任意数字,我们可以用0去补满数组中的空缺。
* 也就是排序之后的数组不是连续的,即相邻的两个数字相隔若干个数字,
* 但如果我们有足够的0可以补满这两个数字的空缺,这个数组实际上还是连续的。
*/
public function judge (array $array) {
sort($array);
$count = count($array);
$min = $array[0];
$max = $array[$count - 1];
$zero = 0;
for ($i = 0; $i < $count; $i++) {
if ($array[$i] == 0) {
$zero++;
}
//判断是否有重牌,排除王牌
if ($i < $count - 1) {
if ($array[$i + 1] == $array[$i] && $array[$i] !== 0) {
return false;
}
}
}
$min = $array[$zero];
$distance = $max - $min;
// 没有王牌
// 最大和最小值差4
if ($zero == 0) {
if ($distance == 4) {
return true;
}
return false;
}
// 有一个王牌
if ($zero == 1) {
if ($distance == 4 || $distance == 3) {
return true;
}
return false;
}
// 有2个王牌
// 00 234 distance = 2
// 00 256 distatnce = 4
// 00 235 distance = 3
if ($zero == 2) {
if ($distance == 4 || $distance == 3 || $distance == 2) {
return true;
}
return false;
}
return false;
}
$res1 = $my_test->judge([1, 2, 3, 4, 5]); //没有王
$res2 = $my_test->judge([1, 2, 0, 3, 5]); // 一张王
$res3 = $my_test->judge([1, 5, 0, 3, 0]); // 两张王牌
$res4 = $my_test->judge([1, 5, 8, 3, 7]);93.PHP的数组和C语言的数组结构上有何区别?
但从PHP来讲,考的是PHP数组的实现。可以简单的认为,PHP的数组是hash桶+十字链表(实际上是数列Array,列表List,散列表/关联数组/字典Hashtable的聚合体)。优点是查询效率很高,遍历很方便,缺点是,占内存较多。(还是空间换时间的思路,毕竟现在内存又不值钱)
C语言的数组,就是定长定类型的数列。
94.Redis的跳跃表怎么实现的
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
参考:https://blog.csdn.net/universe_ant/article/details/51134020
95.请写出自少两个支持回调处理的PHP函数,并自己实现一个支持回调的PHP函数
array_map,array_filter, array_walk、array_reduce();
function callBack($parameter, $fn) {
return $fn($parameter);
}
var_dump(callBack(5, function ($n){
return $n * $n;
}));96.ping一个服务器ping不通,用哪个命令跟踪路由包
linux:traceroute,windows:tracert97.$a=[0,1,2,3]; $b=[1,2,3,4,5]; $a+=$b; var_dump($a)等于多少?
结果是01235。PHP用数字索引和STRING索引差别还是很大的
参考:http://www.jb51.net/article/38593.htm
98.$a=[1,2,3]; foreach($a as &$v){} foreach($a as $v){} var_dump($a)等于多少;
此处有一坑。foreach 完之后,$index , $value 并不会消失保留最后一次赋值。
这里的第一次foreach之后,数组中最后一个元素变成引用,引用变量 $v 继续存在且指向数组的最后一个元素。第二次遍历,因为遍历变量名是 $v , 所以等于说每次遍历都将此次遍历的值修改成最后元素的值,直至到遍历最后一个元素(引用元素),因为此时数组的最后一个元素已被修改成上一个元素的值,最后一次赋值就是 自己==自己。 故最后一个等于倒数第二个
https://laravel-china.org/articles/7001/php-ray-foreach-and-references-thunder
99.有10亿条订单数据,属于1000个司机的,请取出订单量前20的司机
从设计上解决这个问题。只有一千个司机。我们可以做个简单哈希,分库分表,%求余数。保证这一千个司机分在一千个表里,每个人有每个人的单独表。引擎用MYSAIM,求表中数据的总数,效率飞快,遍历一千张表,求最大前二十即可。
100.根据access.log文件统计最近5秒的qps,并以如下格式显示,01 1000
tail -f access.log | awk -F '[' '{print $2}' | awk '{print $1}' | uniq -c参考:https://blog.csdn.net/dong_007_007/article/details/78330337
101.海量日志数据,提取出某日访问百度次数最多的那个IP
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
或者如下阐述(雪域之鹰):
算法思想:分而治之+Hash
1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP;
102.假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G
典型的Top K算法,还是在这篇文章里头有所阐述,详情请参见:十一、从头到尾彻底解析Hash表算法。
文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27);
第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。
即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
103.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。
如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
104.有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序
还是典型的TOP K算法,解决方案如下:
方案1:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
105. 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
106.在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
107.给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中
方案1:oo,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
dizengrong:
方案2:这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下:
又因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;
这里我们把40亿个数中的每一个用32位的二进制来表示
假设这40亿个数开始放在一个文件中。
然后将这40亿个数分成两类:
1.最高位为0
2.最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿(这相当于折半了);
与要查找的数的最高位比较并接着进入相应的文件再查找
再然后把这个文件为又分成两类:
1.次最高位为0
2.次最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿(这相当于折半了);
与要查找的数的次最高位比较并接着进入相应的文件再查找。
.......
以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。
附:这里,再简单介绍下,位图方法:
使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效率还能提高一倍。
108.怎么在海量数据中找出重复次数最多的一个?
先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求
109.上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据
上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用堆机制完成
110.一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析
用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个
111.100w个数中找出最大的100个数。
方案1:用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
112.下面员工3的薪水大于其主管的薪水,一条SQL找到薪水比下属低的主管
| id | username | salary | pid |
|---|---|---|---|
| 1 | a | 3000 | null |
| 2 | b | 8000 | null |
| 3 | c | 5000 | 1 |
| 4 | d | 6000 | 3 |
SELECT a.*, b.* FROM `user` as a LEFT JOIN `user` as b ON a.pid = b.id AND a.salary > b.salary WHERE b.id > 0;113.数据库如果出现了死锁,你怎么排查,怎么判断出现了死锁?
一、 数据库死锁的现象
程序在执行的过程中,点击确定或保存按钮,程序没有响应,也没有出现报错。
二、 死锁的原理
当对于数据库某个表的某一列做更新或删除等操作,执行完毕后该条语句不提
交,另一条对于这一列数据做更新操作的语句在执行的时候就会处于等待状态,
此时的现象是这条语句一直在执行,但一直没有执行成功,也没有报错。
三、 死锁的定位方法
通过检查数据库表,能够检查出是哪一条语句被死锁,产生死锁的机器是哪一台。
1)用dba用户执行以下语句
select username,lockwait,status,machine,program from v$session where sid in
(select session_id from v$locked_object)
如果有输出的结果,则说明有死锁,且能看到死锁的机器是哪一台。字段说明:
Username:死锁语句所用的数据库用户;
Lockwait:死锁的状态,如果有内容表示被死锁。
Status: 状态,active表示被死锁
Machine: 死锁语句所在的机器。
Program: 产生死锁的语句主要来自哪个应用程序。
2)用dba用户执行以下语句,可以查看到被死锁的语句。
select sql_text from v$sql where hash_value in
(select sql_hash_value from v$session where sid in
(select session_id from v$locked_object))
四、 死锁的解决方法
一般情况下,只要将产生死锁的语句提交就可以了,但是在实际的执行过程中。用户可
能不知道产生死锁的语句是哪一句。可以将程序关闭并重新启动就可以了。
经常在Oracle的使用过程中碰到这个问题,所以也总结了一点解决方法。
1)查找死锁的进程:
sqlplus "/as sysdba" (sys/change_on_install)
SELECT s.username,l.OBJECT_ID,l.SESSION_ID,s.SERIAL#,
l.ORACLE_USERNAME,l.OS_USER_NAME,l.PROCESS
FROM V$LOCKED_OBJECT l,V$SESSION S WHERE l.SESSION_ID=S.SID;
2)kill掉这个死锁的进程:
alter system kill session ‘sid,serial#’; (其中sid=l.session_id)
3)如果还不能解决:
select pro.spid from v$session ses,
v$process pro where ses.sid=XX and
ses.paddr=pro.addr;
其中sid用死锁的sid替换:
exit
ps -ef|grep spid
其中spid是这个进程的进程号,kill掉这个Oracle进程。
114.写一个程序来查找最长子串
<?php
$a = 'abceee12345309878';
$b = 'abceeew2345i09878fsfsfsfabceeewsfsdfsfsabceeew';
$c = array();
$lenht1 = strlen($a);
$lenth2 = strlen($b);
$startTime = microtime(true);
for ($i=0;$i<$lenht1;$i++) {
for ($j=0;$j<$lenth2;$j++) {
$n = ($i-1>=0 && $j-1>=0)?$c[$i-1][$j-1]:0;
$n = ($a[$i] == $b[$j]) ? $n+1:0;
$c[$i][$j] = $n;
}
}
foreach ($c as $key=>$val) {
$max = max($val);
foreach ($val as $key1 =>$val1) {
if ($val1 == $max && $max>0) {
$cdStr[$max] = substr($b,$key1-$max+1,$max);
}
}
}
ksort($cdStr);
$endTime = microtime(true);
echo "Totle time is " . ($endTime - $startTime) . " s"."<br/>";
print_r(end($cdStr));
exit;
?>
115.分析一个问题:php-fpm的日志正常,但客户端却超时了,你认为可能是哪里出了问题,怎么排查?
检查nginx log,请求是否达到nginx 和是否正常转发给 php-fpm
116.进程间通信方式有哪些
1.管道
管道分为有名管道和无名管道
无名管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用.进程的亲缘关系一般指的是父子关系。无明管道一般用于两个不同进程之间的通信。当一个进程创建了一个管道,并调用fork创建自己的一个子进程后,父进程关闭读管道端,子进程关闭写管道端,这样提供了两个进程之间数据流动的一种方式。
有名管道也是一种半双工的通信方式,但是它允许无亲缘关系进程间的通信。
2.信号量
信号量是一个计数器,可以用来控制多个线程对共享资源的访问.,它不是用于交换大批数据,而用于多线程之间的同步.它常作为一种锁机制,防止某进程在访问资源时其它进程也访问该资源.因此,主要作为进程间以及同一个进程内不同线程之间的同步手段.
3.信号
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生.
4.消息队列
消息队列是消息的链表,存放在内核中并由消息队列标识符标识.消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等特点.消息队列是UNIX下不同进程之间可实现共享资源的一种机制,UNIX允许不同进程将格式化的数据流以消息队列形式发送给任意进程.对消息队列具有操作权限的进程都可以使用msget完成对消息队列的操作控制.通过使用消息类型,进程可以按任何顺序读信息,或为消息安排优先级顺序.
5.共享内存
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问.共享内存是最快的IPC(进程间通信)方式,它是针对其它进程间通信方式运行效率低而专门设计的.它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步与通信.
6.套接字:可用于不同及其间的进程通信
117.事务有几种隔离级别?事务的隔离级别是怎么实现的?
- 读未提交(read-uncommitted)
- 不可重复读(read-committed)
- 可重复读(repeatable-read)
- 串行化(serializable)
https://www.cnblogs.com/huanongying/p/7021555.html
118.写出以下输出:"aa"==1,"bb"==0,1=="1"
false, true, true
119.设计一个秒杀系统,如何保证商品不超卖?
1、前端
面对高并发的抢购活动,前端常用的三板斧是【扩容】【静态化】【限流】
A:扩容
加机器,这是最简单的方法,通过增加前端池的整体承载量来抗峰值。
B:静态化
将活动页面上的所有可以静态的元素全部静态化,并尽量减少动态元素。通过CDN来抗峰值。
C:限流
一般都会采用IP级别的限流,即针对某一个IP,限制单位时间内发起请求数量。
或者活动入口的时候增加游戏或者问题环节进行消峰操作。
D:有损服务
最后一招,在接近前端池承载能力的水位上限的时候,随机拒绝部分请求来保护活动整体的可用性。
2、后端
那么后端的数据库在高并发和超卖下会遇到什么问题呢?主要会有如下3个问题:(主要讨论写的问题,读的问题通过增加cache可以很容易的解决)
I: 首先MySQL自身对于高并发的处理性能就会出现问题,一般来说,MySQL的处理性能会随着并发thread上升而上升,但是到了一定的并发度之后会出现明显的拐点,之后一路下降,最终甚至会比单thread的性能还要差。
II: 其次,超卖的根结在于减库存操作是一个事务操作,需要先select,然后insert,最后update -1。最后这个-1操作是不能出现负数的,但是当多用户在有库存的情况下并发操作,出现负数这是无法避免的。
III:最后,当减库存和高并发碰到一起的时候,由于操作的库存数目在同一行,就会出现争抢InnoDB行锁的问题,导致出现互相等待甚至死锁,从而大大降低MySQL的处理性能,最终导致前端页面出现超时异常。
针对上述问题,如何解决呢? 我们先看眼淘宝的高大上解决方案:
I: 关闭死锁检测,提高并发处理性能。
II:修改源代码,将排队提到进入引擎层前,降低引擎层面的并发度。
III:组提交,降低server和引擎的交互次数,降低IO消耗。
以上内容可以参考丁奇在DTCC2013上分享的《秒杀场景下MySQL的低效》一文。在文中所有优化都使用后,TPS在高并发下,从原始的150飙升到8.5w,提升近566倍,非常吓人!!!
不过结合我们的实际,改源码这种高大上的解决方案显然有那么一点不切实际。于是小伙伴们需要讨论出一种适合我们实际情况的解决方案。以下就是我们讨论的解决方案:
首先设定一个前提,为了防止超卖现象,所有减库存操作都需要进行一次减后检查,保证减完不能等于负数。(由于MySQL事务的特性,这种方法只能降低超卖的数量,但是不可能完全避免超卖)
update number set x=x-1 where (x -1 ) >= 0;
解决方案1:
将存库从MySQL前移到Redis中,所有的写操作放到内存中,由于Redis中不存在锁故不会出现互相等待,并且由于Redis的写性能和读性能都远高于MySQL,这就解决了高并发下的性能问题。然后通过队列等异步手段,将变化的数据异步写入到DB中。
优点:解决性能问题
缺点:没有解决超卖问题,同时由于异步写入DB,存在某一时刻DB和Redis中数据不一致的风险。
解决方案2:
引入队列,然后将所有写DB操作在单队列中排队,完全串行处理。当达到库存阀值的时候就不在消费队列,并关闭购买功能。这就解决了超卖问题。
优点:解决超卖问题,略微提升性能。
缺点:性能受限于队列处理机处理性能和DB的写入性能中最短的那个,另外多商品同时抢购的时候需要准备多条队列。
解决方案3:
将写操作前移到Memcached中,同时利用Memcached的轻量级的锁机制CAS来实现减库存操作。
优点:读写在内存中,操作性能快,引入轻量级锁之后可以保证同一时刻只有一个写入成功,解决减库存问题。
缺点:没有实测,基于CAS的特性不知道高并发下是否会出现大量更新失败?不过加锁之后肯定对并发性能会有影响。
解决方案4:
将提交操作变成两段式,先申请后确认。然后利用Redis的原子自增操作(相比较MySQL的自增来说没有空洞),同时利用Redis的事务特性来发号,保证拿到小于等于库存阀值的号的人都可以成功提交订单。然后数据异步更新到DB中。
优点:解决超卖问题,库存读写都在内存中,故同时解决性能问题。
缺点:由于异步写入DB,可能存在数据不一致。另可能存在少买,也就是如果拿到号的人不真正下订单,可能库存减为0,但是订单数并没有达到库存阀值。
$ttl = 4;
$random = mt_rand(1,1000).'-'.gettimeofday(true).'-'.mt_rand(1,1000);
$lock = fasle;
while (!$lock) {
$lock = $redis->set('lock', $random, array('nx', 'ex' => $ttl));
}
if ($redis->get('goods.num') <= 0) {
echo ("秒杀已经结束");
//删除锁
if ($redis->get('lock') == $random) {
$redis->del('lock');
}
return false;
}
$redis->decr('goods.num');
echo ("秒杀成功");
//删除锁
if ($redis->get('lock') == $random) {
$redis->del('lock');
}
return true;120.写一段代码判断单向链表中有没有形成环,如果形成环,请找出环的入口处,即P点
/*
*单链表的结点类
*/
class LNode{
//为了简化访问单链表,结点中的数据项的访问权限都设为public
public int data;
public LNode next;
}
class LinkListUtli {
//当单链表中没有环时返回null,有环时返回环的入口结点
public static LNode searchEntranceNode(LNode L)
{
LNode slow=L;//p表示从头结点开始每次往后走一步的指针
LNode fast=L;//q表示从头结点开始每次往后走两步的指针
while(fast !=null && fast.next !=null)
{
if(slow==fast) break;//p与q相等,单链表有环
slow=slow.next;
fast=fast.next.next;
}
if(fast==null || fast.next==null) return null;
// 重新遍历,寻找环的入口点
slow=L;
while(slow!=fast)
{
slow=slow.next;
fast=fast.next;
}
return slow;
}
}121.写一个函数,获取一篇文章内容中的全部图片,并下载
function download_images($article_url = '', $image_path = 'tmp'){
// 获取文章类容
$content = file_get_contents($article_url);
// 利用正则表达式得到图片链接
$reg_tag = '/<img.*?\"([^\"]*(jpg|bmp|jpeg|gif|png)).*?>/';
$ret = preg_match_all($reg_tag, $content, $match_result);
$pic_url_array = array_unique($match_result1[1]);
// 创建路径
$dir = getcwd() . DIRECTORY_SEPARATOR .$image_path;
mkdir(iconv("UTF-8", "GBK", $dir), 0777, true);
foreach($pic_url_array as $pic_url){
// 获取文件信息
$ch = curl_init($pic_url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_NOBODY, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE );
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE );
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$fileInfo = curl_exec($ch);
$httpinfo = curl_getinfo($ch);
curl_close($ch);
// 获取图片文件后缀
$ext = strrchr($pic_url, '.');
$filename = $dir . '/' . uniqid() . $ext;
// 保存图片信息到文件
$local_file = fopen($filename, 'w');
if(false !== $local_file){
if( false !== fwrite($local_file, $filecontent) ){
fclose($local_file);
}
}
}
}122.斗地主出现王炸的概率有多少?
设Z = {小明抓到王炸};
设 = {扣牌底下3张牌没有王, 且有一手牌中有2张王};
设 = {扣牌底下3张牌有1张王,且有一手牌中有1张王};
设 = {扣牌底下3张牌有2张王,且任意一手牌};
P() = = 272/2862
P( ) = = 306/2862
P() = = 6/2862
设 = {在情况下,小明抓到那一手有两张王的牌};
设 = {在情况下,小明抓到那一手有1张王的牌};
设 = {在情况加,小明抓到随意一手牌}
P() = = 1/3 * 272/2862
P() = = 1/3 * 306/2862
P() = = 1 * 6/2862
假设叫地主的时候3个人的机会均等都是1/3。
那么,P(Z) = P() * 1 + P() * 1/3 + P() * 1/3 = 1/3 * 272/2862
+ 1/3 * 306/2862 * 1/3 + *1 * 6/2862 * 1/3 = 380/8586 = 0.0443
所以通过计算,特定的一个人抓到王炸的概率为0.0443.就是我们自己大概25把能抓到一把王炸。
123.请写一个函数来检查用户提交的数据是否为整数(不区分数据类型,可以为二进制、八进制、十进制、十六进制数字)
if(!is_numeric($jp_total)||strpos($jp_total,".")!==false){
echo "不是整数";
}else{
echo "是整数";
} 124.PHP的strtolower()和strtoupper()函数在安装非中文系统的服务器下可能会导致将汉字转换为乱码,请写两个替代的函数实现兼容Unicode文字的字符串大小写转换
中文是由多字节组成的,而只有英文系统的单个英文字符只有一个字节,所以该系统把中文的每一个字节都做了strtolower()处理,改变后的中文字节拼接在一起就成了乱码(新生成的编码映射对应的字符可能就不是中文了)
手动解决:用str_split(string string,intstring,intsplit_length = 1)按每个字节切割,像中文能切割成三个字节。对识别到的字节若是英文字母则进行转换。
<?php
function mystrtoupper($a){
$b = str_split($a, 1);
$r = '';
foreach($b as $v){
$v = ord($v);
if($v >= 97 && $v<= 122){
$v -= 32;
}
$r .= chr($v);
}
return $r;
}
$a = 'a中你继续F@#$%^&*(BMDJFDoalsdkfjasl';
echo 'origin string:'.$a."\n";
echo 'result string:';
$r = mystrtoupper($a);
var_dump($r); 125.PHP的is_writeable()函数存在Bug,无法准确判断一个目录/文件是否可写,请写一个函数来判断目录/文件是否绝对可写
其中bug存在两个方面,
1、在windowns中,当文件只有只读属性时,is_writeable()函数才返回false,当返回true时,该文件不一定是可写的。
如果是目录,在目录中新建文件并通过打开文件来判断;
如果是文件,可以通过打开文件(fopen),来测试文件是否可写。
2、在Unix中,当php配置文件中开启safe_mode时(safe_mode=on),is_writeable()同样不可用。
读取配置文件是否safe_mode是否开启。
/**
* Tests for file writability
*
* is_writable() returns TRUE on Windows servers when you really can't write to
* the file, based on the read-only attribute. is_writable() is also unreliable
* on Unix servers if safe_mode is on.
*
* @access private
* @return void
*/
if ( ! function_exists('is_really_writable'))
{
function is_really_writable($file)
{
// If we're on a Unix server with safe_mode off we call is_writable
if (DIRECTORY_SEPARATOR == '/' AND @ini_get("safe_mode") == FALSE)
{
return is_writable($file);
}
// For windows servers and safe_mode "on" installations we'll actually
// write a file then read it. Bah...
if (is_dir($file))
{
$file = rtrim($file, '/').'/'.md5(mt_rand(1,100).mt_rand(1,100));
if (($fp = @fopen($file, FOPEN_WRITE_CREATE)) === FALSE)
{
return FALSE;
}
fclose($fp);
@chmod($file, DIR_WRITE_MODE);
@unlink($file);
return TRUE;
} elseif ( ! is_file($file) OR ($fp = @fopen($file, FOPEN_WRITE_CREATE)) === FALSE) {
return FALSE;
}
fclose($fp);
return TRUE;
}
}126.PHP处理上传文件信息数组中的文件类型$_FILES[‘type’]由客户端浏览器提供,有可能是黑客伪造的信息,请写一个函数来确保用户上传的图像文件类型真实可靠
用getimagesize来判断上传图片的类型比$_FILES函数的type更可靠
同一个文件,使用不同的浏览器php返回的type类型是不一样的,由浏览器提供type类型的话,
就有可能被黑客利用向服务器提交一个伪装撑图片后缀的可执行文件。
可以通过getimagesize()函数来判断上传的文件类型,如果是头像文件 会返回这样的一个数组
Array
(
[0] => 331
[1] => 234
[2] => 3
[3] => width="331" height="234"
[bits] => 8
[mime] => image/png
);
如果通过getimagesize()函数返回的是这样的一个数组 说明上传的是头像文件。其中索引为2的表示类型
1 = GIF,2 = JPG,3 = PNG,4 = SWF,5 = PSD,6 = BMP,7 = TIFF(intel byte
order),8 = TIFF(motorola byte order),9 = JPC,10 = JP2,11 = JPX,12 =
JB2,13 = SWC,14 = IFF,15 = WBMP,16 = XBM,
你可以通过这个再去限制上传的头像类型
<?php
$file=$_FILES['file'];
if(!empty($file))
{
var_dump($file);
var_dump(getimagesize($file["tmp_name"]));
}
?>127.PHP通过对数据的URL编码来实现与Javascript的数据交互,但是对于部分特殊字符的编解码与Javascript的规则不尽相同,请具体说明这种差异,并针对UTF-8字符集的数据,写出PHP的编解码函数和Javascript的编解码函数,确保PHP编码数据可以被Javascript正确解码 、Javascript编码的数据可以被PHP正确解码
<?php
$str = '优库云博客siyuantlw/tlw/sy/俺只是一个打酱油的';
$str = iconv("GB2312",'UTF-8',$str);
$str = urlencode($str);
?>//js decodeURIComponent 貌似对GB2312编码的格式不识别,必须转为utf-8才可以,然后,如果字符串中有空格的 就转为 + 号了
<html>
<script>
var ds = '<?php echo $str;?>';
var dddd= decodeURIComponent (ds);
alert(dddd);
</script>
</html>128.试阐述Memcache的key多节点分布的算法?当任一节点出现故障时PHP的Memcache客户端将如何处置?如何确保Memcache数据读写操作的原子性?
原理:一致性hash
原子性
原子性会导致的问题:简单的说就是A,B都想操作key1,然后都在key1上增加自己的信息,就会有问题
memcached是原子的吗?宏观
所有的被发送到memcached的单个命令是完全原子的。如果您针对同一份数据同时发送了一个set命令和一个get命令,它们不会影响对方。它们将被串行化、先后执行。即使在多线程模式,所有的命令都是原子的;命令序列不是原子的。如果您通过get命令获取了一个item,修改了它,然后想把它set回memcached,我们不保证这个item没有被其他进程(process,未必是操作系统中的进程)操作过。在并发的情况下,您也可能覆写了一个被其他进程set的item。
memcached 1.2.5以及更高版本,提供了gets和cas命令,它们可以解决上面的问题。如果您使用gets命令查询某个key的item,memcached会 给您返回该item当前值的唯一标识。如果您覆写了这个item并想把它写回到memcached中,您可以通过cas命令把那个唯一标识一起发送给 memcached。如果该item存放在memcached中的唯一标识与您提供的一致,您的写操作将会成功。如果另一个进程在这期间也修改了这个 item,那么该item存放在memcached中的唯一标识将会改变,您的写操作就会失败。
129.为什么会出现僵死进程(孤儿进程)?怎样查看僵死进程?如何解决僵死进程问题?
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
查看:使用ps aux
删除:ps aux | grep -e ‘^[Zz]’ | awk ‘{print $2}’ | xargs kill -9
130.请描述Apache 2.x版本的MPM(Multi-Processing Module)机制,并具体说明在不同的MPM机制下如何支持PHP?
常用的应该就只有3个:worker|prefork|perchild
prefork:在功能上就是使用Apache的运行方式,一个父进程,然后根据设置以及连接情况生成相应的子进程数。这种模式可靠性和健壮性都是最好的。但是在性能上,开销过大。达不到我们这些“吸血鬼”的要求了^_^。如果连接数过多的话,会导致我们无法远程登陆,一定要等到连接数下降后才能连接,这也是最让我头痛的事情。
worker:混合线程/进程的MPM。一个父进程,后面是带有线程的子进程。每个子进程的线程数是固定且相同的。这是最“平庸”的一个模式,但也是使用人最多的一种模式。因为它性能等各方面比较均衡。性能上要比prefork好一些,只是牺牲了一点点的健壮性和可靠性而已。一般推荐使用这个选项。
perchild:也是混合线程/进程的MPM。当启动perchild MPM时,它会建立指定数量的子进程,且每个子进程都具有指定数量的线程,如负载增加了,那它不会建立新的进程(子进程是固定的),只是在子进程下建立新的线程。它还有一个特点就是可以为每一个子进程配置不同的用户和组。也可以为每个虚拟主机指定一个子进程。这种模式性能是最佳的,但是可靠性和健壮性就相对是最差的
131.请简述PHP在Apache下的几种运行方式并加以比较?如何让PHP在Linux+Apache下以Fast CGI方式运行?
php在apache有3中运行方式:CGI模式、FastCGI模式、Apache 模块DLL。
比较:
Cgi模式和模块dll加载方式比较:
Cgi模式下,apache调用外部执行器php.exe执行php代码,并将解释后生成的html代码和原html整合,再传递给apache服务器,其在执行时每次都需要重新解析php.ini、重新载入全部dll扩展并重初始化全部数据结构,运行速度非常慢,但因为是外部加载执行器,php代码执行出错不会导致apache崩溃。
在模块化(DLL)中,PHP是与Web服务器一起启动并运行的。所以从某种角度上来说,以apache模块方式安装的 PHP4有着比CGI模式更好的安全性以及更好的执行效率和速度。
Cgi和fastcgi模式比较:
Fastcig是cgi的升级版,Cgi和fastcgi工作模式大抵相同,但fastcgi模式中fastcgi的进程管理器可用来管理cgi解释器,该管理器在cgi解释器完成请求后,会处于挂起状态,用以等待接下来的请求,因为向比较cgi每次都需要重新解析php.ini、重新载入全部dll扩展并重初始化全部数据结构,fastcig模式明显要快很多。
132.请写出让PHP能够在命令行下以脚本方式执行时安装PHP所必须指定的configure参数,并说明如何在命令行下运行PHP脚本(写出两种方式)同时向PHP脚本传递参数?
由于 –enable-cli 和 –enable-cgi 同时默认有效,因此,不必再配置行中加上 –enable-cli 来使得 CLI 在 make install 过程中被拷贝到 {PREFIX}/bin/php
php -f “index.php”
php -r “print_r(get_defined_constants());”133.请列举你能想到的UNIX信号,并说明信号用途。
Unix信号量也可以在文件/usr/include/sys/signal.h中查看
#define SIGHUP 进程由於控制终端死去或者控制终端发出起命令
#define SIGINT 键盘中断所产生的信号
#define SIGQUIT 键盘终止
#define SIGILL 非法的指令
#define SIGTRAP 进程遇到一个追踪(trace)或者是一个中断嵌套
#define SIGABRT 由abort系统调用所产生的中断信号
#define SIGIOT 类似於SIGABRT
#define SIGBUS 进程试图使用不合理的记忆体
#define SIGFPE 浮点异常
#define SIGKILL KILL
#define SIGUSR1 用户自定义
#define SIGSEGV 段错误
#define SIGUSR2 用户自定义
#define SIGPIPE 管道操作时没有读只写
#define SIGALRM 由alarm系统调用产生的timer时钟信号
#define SIGTERM 收到终端信号的进程
#define SIGSTKFLT 堆叠错误
#define SIGCHLD 子进程向父进程发出的子进程已经stop或者终止的信号
#define SIGCONT 继续运行的信号
#define SIGSTOP stop
#define SIGTSTP 键盘所产生的stop信号
#define SIGTTIN 当运行在後状态时却需要读取stdin的资料
#define SIGTTOU 当运行在後状态时却需要写向stdout
#define SIGURG socket的紧急情况
#define SIGXCPU 进程超额使用CPU分配的时间
#define SIGXFSZ 进程使用了超出系统规定文件长度的文件
#define SIGVTALRM 内部的alarm时钟过期
#define SIGPROF 在一个程式段中描绘时钟集过期
#define SIGWINCH 终端视窗的改变
#define SIGIO 非同步IO
#define SIGPOLL SIGIO pollable事件发生 134.有一个IP地址(192.168.0.1),请写出其32位无符号整数形式
是将十进制转换成二进制 采用取余法即可很简单 11000000.10101000.00000000.00000001
135.简述一下PHP短信验证码如何防刷?
1、时间限制:60 秒后才能再次发送
从发送验证码开始,前端(客户端)会进行一个 60 秒的倒数,在这一分钟之内,用户是无法提交多次发送信息的请求的。这种方法虽然使用得比较普遍,但是却不是非常有用,技术稍微好点的人完全可以绕过这个限制,直接发送短信验证码。
2、手机号限制:同一个手机号,24 小时之内不能够超过 5 条
对使用同一个手机号码进行注册或者其他发送短信验证码的操作的时候,系统可以对这个手机号码进行限制,例如,24 小时只能发送 5 条短信验证码,超出限制则进行报错(如:系统繁忙,请稍后再试)。然而,这也只能够避免人工手动刷短信而已,对于批量使用不同手机号码来刷短信的机器,这种方法也是无可奈何的。
3、短信验证码限制:30 分钟之内发送同一个验证码
网上还有一种方法说:30 分钟之内,所有的请求,所发送的短信验证码都是同一个验证码。第一次请求短信接口,然后缓存短信验证码结果,30 分钟之内再次请求,则直接返回缓存的内容。对于这种方式,不是很清楚短信接口商会不会对发送缓存信息收取费用,如果有兴趣可以了解了解。
4、前后端校验:提交 Token 参数校验
这种方式比较少人说到,个人觉得可以这种方法值得一试。前端(客户端)在请求发送短信的时候,同时向服务端提交一个 Token 参数,服务端对这个 Token 参数进行校验,校验通过之后,再向请求发送短信的接口向用户手机发送短信。
5、唯一性限制:微信产品,限制同一个微信 ID 用户的请求数量
如果是微信的产品的话,可以通过微信 ID 来进行识别,然后对同一个微信 ID 的用户限制,24 小时之内最多只能够发送一定量的短信。
6、产品流程限制:分步骤进行
例如注册的短信验证码使用场景,我们将注册的步骤分成 2 步,用户在输入手机号码并设置了密码之后,下一步才进入验证码的验证步骤。
7、图形验证码限制:图形验证通过后再请求接口
用户输入图形验证码并通过之后,再请求短信接口获取验证码。为了有更好的用户体验,也可以设计成:一开始不需要输入图形验证码,在操作达到一定量之后,才需要输入图形验证码。具体情况请根据具体场景来进行设计。
8、IP 及 Cookie 限制:限制相同的 IP/Cookie 信息最大数量
使用 Cookie 或者 IP,能够简单识别同一个用户,然后对相同的用户进行限制(如:24 小时内最多只能够发送 20 条短信)。然而,Cookie 能够清理、IP 能够模拟,而且 IP 还会出现局域网相同 IP 的情况,因此,在使用此方法的时候,应该根据具体情况来思考。
9、短信预警机制,做好出问题之后的防护
以上的方法并不一定能够完全杜绝短信被刷,因此,我们也应该做好短信的预警机制,即当短信的使用量达到一定量之后,向管理员发送预警信息,管理员可以立刻对短信的接口情况进行监控和防护。
136.mySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中的数据都是热点数据
思路:首先计算出20w数据所需的内存空间,设置最大内存,然后选择合适的内存淘汰策略。
内存淘汰策略
在Redis的redis.conf配置文件中,列出了8种策略:
(1)volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰。
(2)volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰。
(3)volatile-random:从已设置过期时间的数据集中任意选择数据淘汰。
(4)volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
(5)allkeys-lru:从数据集中挑选最近最少使用的数据淘汰
(6)allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。
(7)allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
(8) no-enviction(驱逐):禁止驱逐数据,这也是默认策略。意思是当内存不足以容纳新入数据时,新写入操作就会报错,请求可以继续进行,线上任务也不能持续进行,采用no-enviction策略可以保证数据不被丢失。
这八种大体上可以分为4中,lru、lfu、random、ttl。
最大内存设置
同样是在redis.conf配置文件中,可以对最大内存进行设置,单位为bytes:当使用的内存到达指定的限制时,Redis会根据内存淘汰策略删除键,以释放空间。
137.简述一下数据库主从复制,读写分离
* 什么是主从复制
主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;
* 主从复制的原理:
1.数据库有个bin-log二进制文件,记录了所有的sql语句。
2.只需要把主数据库的bin-log文件中的sql语句复制。
3.让其从数据的relay-log重做日志文件中在执行一次这些sql语句即可。
* 主从复制的作用
1.做数据的热备份,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问频率,提高单机的I/O性能
3.主从复制是读写分离的基础,使数据库能制成更大 的并发。例如子报表中,由于部署报表的sql语句十分慢,导致锁表,影响前台的服务。如果前台服务使用master,报表使用slave,那么报表sql将不会造成前台所,保证了前台的访问速度。
* 主从复制的几种方式:
1.同步复制:所谓的同步复制,意思是master的变化,必须等待slave-1,slave-2,…,slave-n完成后才能返回。
2.异步复制:如同AJAX请求一样。master只需要完成自己的数据库操作即可。至于slaves是否收到二进制日志,是否完成操作,不用关心。MYSQL的默认设置。
3.半同步复制:master只保证slaves中的一个操作成功,就返回,其他slave不管。
这个功能,是由google为MYSQL引入的。
* 关于读写分离
在完成主从复制时,由于slave是需要同步master的。所以对于insert/delete/update这些更新数据库的操作,应该在master中完成。而select的查询操作,则落下到slave中。
138.php中实现有权重的随机算法
1 $weight = 0;
2 $tempdata = array();
3 foreach ($data as $one) {
4
5 $weight += $one['weight'];
6
7 for ($i = 0; $i < $one['weight']; $i ++) {
8 $tempdata[] = $one;
9
10 }
11
12 }
13 $use = rand(0, $weight – 1);
14 $one = $tempdata[$use];
15 139.PHP中实现单链表与双链表与循环链表
链表是由一组节点组成的集合。每个节点都使用一个对象的引用指向它的后继。指向另一个节点的引用叫做链。
链表分为单链表、双链表、循环链表。
一、单链表

插入:链表中插入一个节点的效率很高。向链表中插入一个节点,需要修改它前面的节点(前驱),使其指向新加入的节点,而新加入的节点则指向原来前驱指向的节点(见下图)。
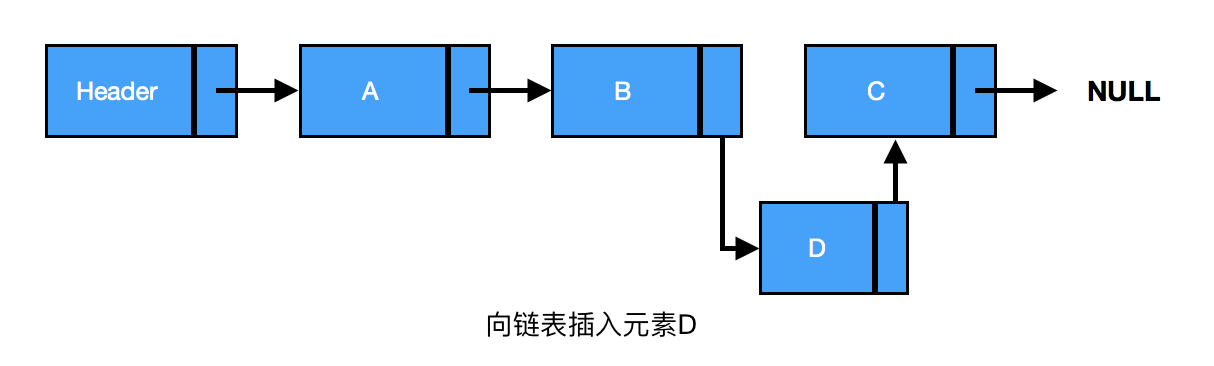
由上图可知,B、C之间插入D,三者之间的关系为
current为插入节点的前驱节点
new->next = current->next // 新节点D指向B的后继节点C
current->next = new // B节点指向新节点D
删除:从链表中删除一个元素,将待删除元素的前驱节点指向待删除元素的后继节点,同时将待删除元素指向 null,元素就删除成功了(见下图)。
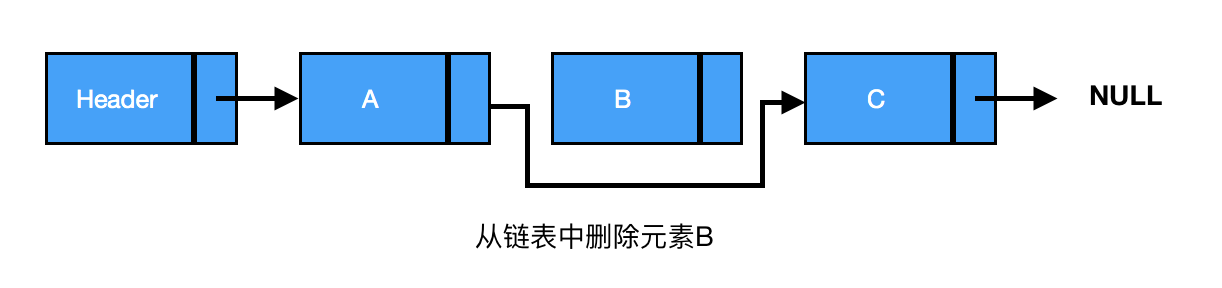
由上图可知,A、C之间删除B,三者之间的关系为
current为要删除节点的前驱节点
current->next = current->next->next // A节点指向C节点
具体代码如下:
<?php
// 节点类
class Node {
public $data; // 节点数据
public $next; // 下一节点
public function __construct($data) {
$this->data = $data;
$this->next = NULL;
}
}
// 单链表类
class SingleLinkedList {
private $header; // 头节点
function __construct($data) {
$this->header = new Node($data);
}
// 查找节点
public function find($item) {
$current = $this->header;
while ($current->data != $item) {
$current = $current->next;
}
return $current;
}
// (在节点后)插入新节点
public function insert($item, $new) {
$newNode = new Node($new);
$current = $this->find($item);
$newNode->next = $current->next;
$current->next = $newNode;
return true;
}
// 更新节点
public function update($old, $new) {
$current = $this->header;
if ($current->next == null) {
echo "链表为空!";
return;
}
while ($current->next != null) {
if ($current->data == $old) {
break;
}
$current = $current->next;
}
return $current->data = $new;
}
// 查找待删除节点的前一个节点
public function findPrevious($item) {
$current = $this->header;
while ($current->next != null && $current->next->data != $item) {
$current = $current->next;
}
return $current;
}
// 从链表中删除一个节点
public function delete($item) {
$previous = $this->findPrevious($item);
if ($previous->next != null) {
$previous->next = $previous->next->next;
}
}
// findPrevious和delete的整合
public function remove($item) {
$current = $this->header;
while ($current->next != null && $current->next->data != $item) {
$current = $current->next;
}
if ($current->next != null) {
$current->next = $current->next->next;
}
}
// 清空链表
public function clear() {
$this->header = null;
}
// 显示链表中的元素
public function display() {
$current = $this->header;
if ($current->next == null) {
echo "链表为空!";
return;
}
while ($current->next != null) {
echo $current->next->data . "  ";
$current = $current->next;
}
}
}
$linkedList = new SingleLinkedList('header');
$linkedList->insert('header', 'China');
$linkedList->insert('China', 'USA');
$linkedList->insert('USA','England');
$linkedList->insert('England','Australia');
echo '链表为:';
$linkedList->display();
echo "</br>";
echo '-----删除节点USA-----';
echo "</br>";
$linkedList->delete('USA');
echo '链表为:';
$linkedList->display();
echo "</br>";
echo '-----更新节点England为Japan-----';
echo "</br>";
$linkedList->update('England', 'Japan');
echo '链表为:';
$linkedList->display();
//echo "</br>";
//echo "-----清空链表-----";
//echo "</br>";
//$linkedList->clear();
//$linkedList->display();
// 输出:
链表为:China USA England Australia
-----删除节点USA-----
链表为:China England Australia
-----更新节点England为Japan-----
链表为:China Japan Australia二、双链表
单链表从链表的头节点遍历到尾节点很简单,但从后向前遍历就没那么简单了。它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
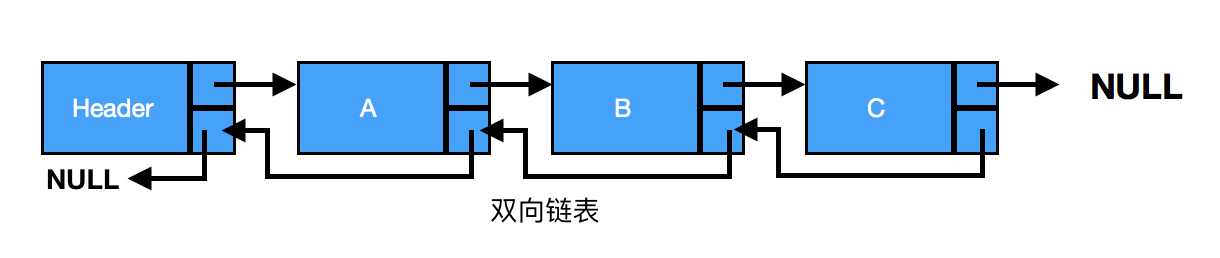
插入:插入一个节点时,需要指出该节点正确的前驱和后继。
修改待插入节点的前驱节点的next属性,使其指向新加入的节点,而新插入的节点的next属性则指向原来前驱指向的节点,同时将原来前驱指向的节点的previous属性指向新节点,而新加入节点的previous属性指向它前驱节点(见下图)。
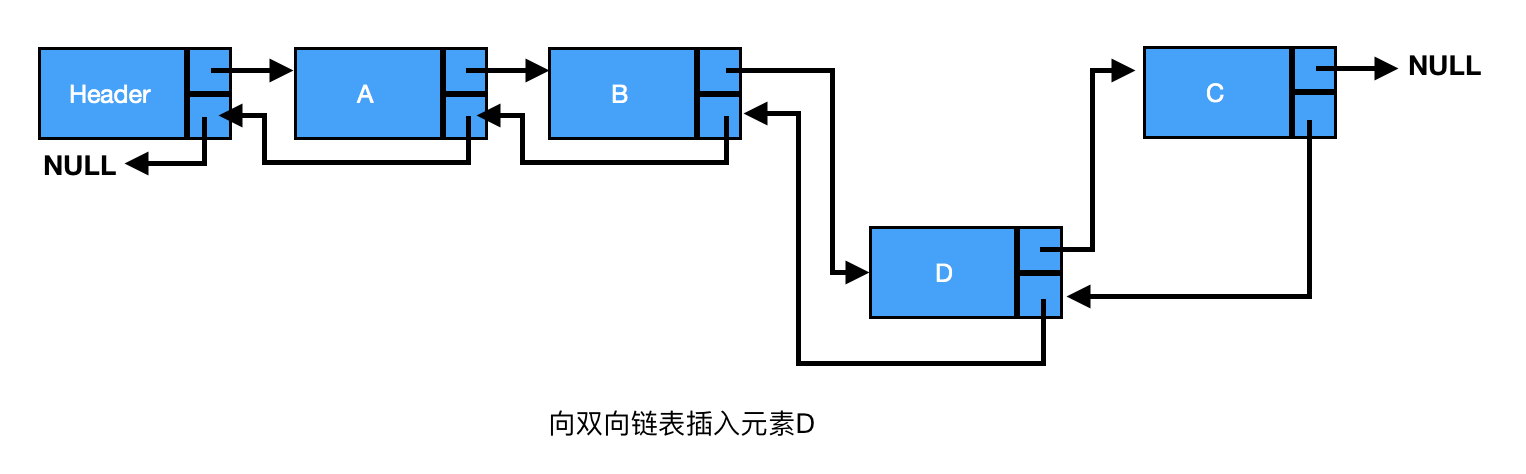
由上图可知,B、C之间插入D,三者之间的关系为
current为插入节点的前驱节点
new->next = current->next // 新节点D的next属性指向B的后继节点C
current->next->previous = new // B的后继节点C的previous属性指向新节点D(原先是C的previous属性指向B)
current->next = new // B的next属性指向新节点D
new->previous = current // B的previous属性指向节点B
删除:双向链表的删除操作比单向链表的效率更高,因为不需要再查找前驱节点了。
首先需要在链表中找出存储待删除数据的节点,然后设置该节点前驱的 next 属性,使其指向待删除节点的后继;设置该节点后继的 previous 属性,使其指向待删除节点的前驱。
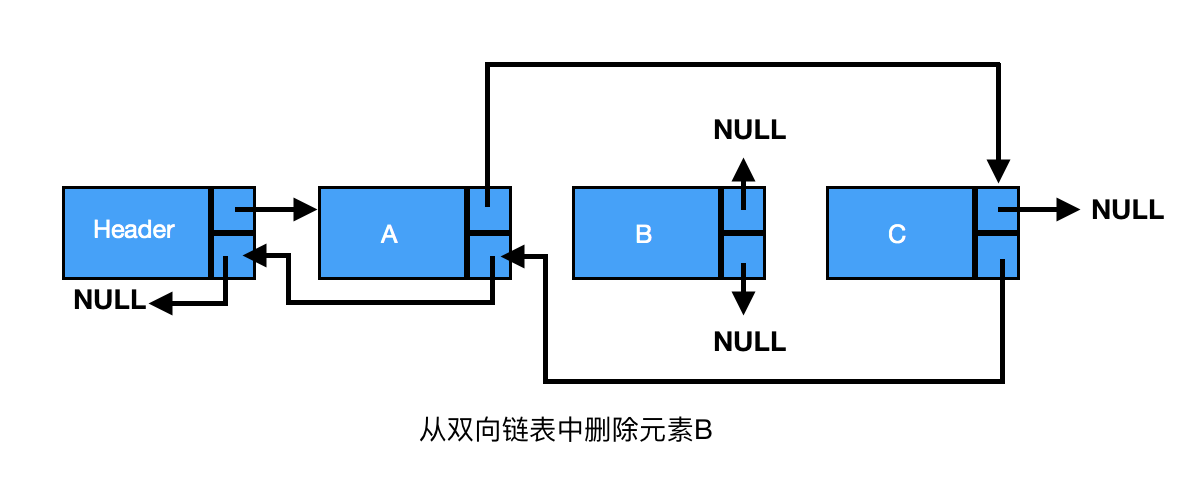
由上图可知,B、C之间删除D,三者之间的关系为
current为要删除的节点
current->previous->next = current->next // B的前驱节点A的next属性指向B的后继节点C
current->next->previous = current->previous // B的后继节点C的previous属性指向B的前驱节点A
current->previous = null // B的previous属性指向null
current->next = null // B的next属性指向null
具体代码如下:
二、双链表
单链表从链表的头节点遍历到尾节点很简单,但从后向前遍历就没那么简单了。它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
插入:插入一个节点时,需要指出该节点正确的前驱和后继。
修改待插入节点的前驱节点的next属性,使其指向新加入的节点,而新插入的节点的next属性则指向原来前驱指向的节点,同时将原来前驱指向的节点的previous属性指向新节点,而新加入节点的previous属性指向它前驱节点(见下图)。
由上图可知,B、C之间插入D,三者之间的关系为
current为插入节点的前驱节点
new->next = current->next // 新节点D的next属性指向B的后继节点C
current->next->previous = new // B的后继节点C的previous属性指向新节点D(原先是C的previous属性指向B)
current->next = new // B的next属性指向新节点D
new->previous = current // B的previous属性指向节点B
删除:双向链表的删除操作比单向链表的效率更高,因为不需要再查找前驱节点了。
首先需要在链表中找出存储待删除数据的节点,然后设置该节点前驱的 next 属性,使其指向待删除节点的后继;设置该节点后继的 previous 属性,使其指向待删除节点的前驱。
由上图可知,B、C之间删除D,三者之间的关系为
current为要删除的节点
current->previous->next = current->next // B的前驱节点A的next属性指向B的后继节点C
current->next->previous = current->previous // B的后继节点C的previous属性指向B的前驱节点A
current->previous = null // B的previous属性指向null
current->next = null // B的next属性指向null
具体代码如下:三、循环链表
循环链表和单向链表相似,节点类型都是一样的。唯一的区别是,在创建循环链表时,让其头节点的 next 属性指向它本身,即:head.next = head,这种行为会传导至链表中的每个节点,使得每个节点的 next 属性都指向链表的头节点。换句话说,链表的尾节点指向头节点,形成了一个循环链表。

在循环链表中,涉及遍历的操作,其终止条件是判断它们是否等于头结点,而不是像单链表那样判别p或p->next是否为空。
插入:如果不是在链表尾端插入,则与单链表相似,将待插入节点的前驱节点指向新加入的节点,而新加入的节点指向原来前驱指向的节点;如果是在尾端插入,则待插入节点的前驱节点指向新加入的节点,而新加入的节点指向头节点(见下图)。
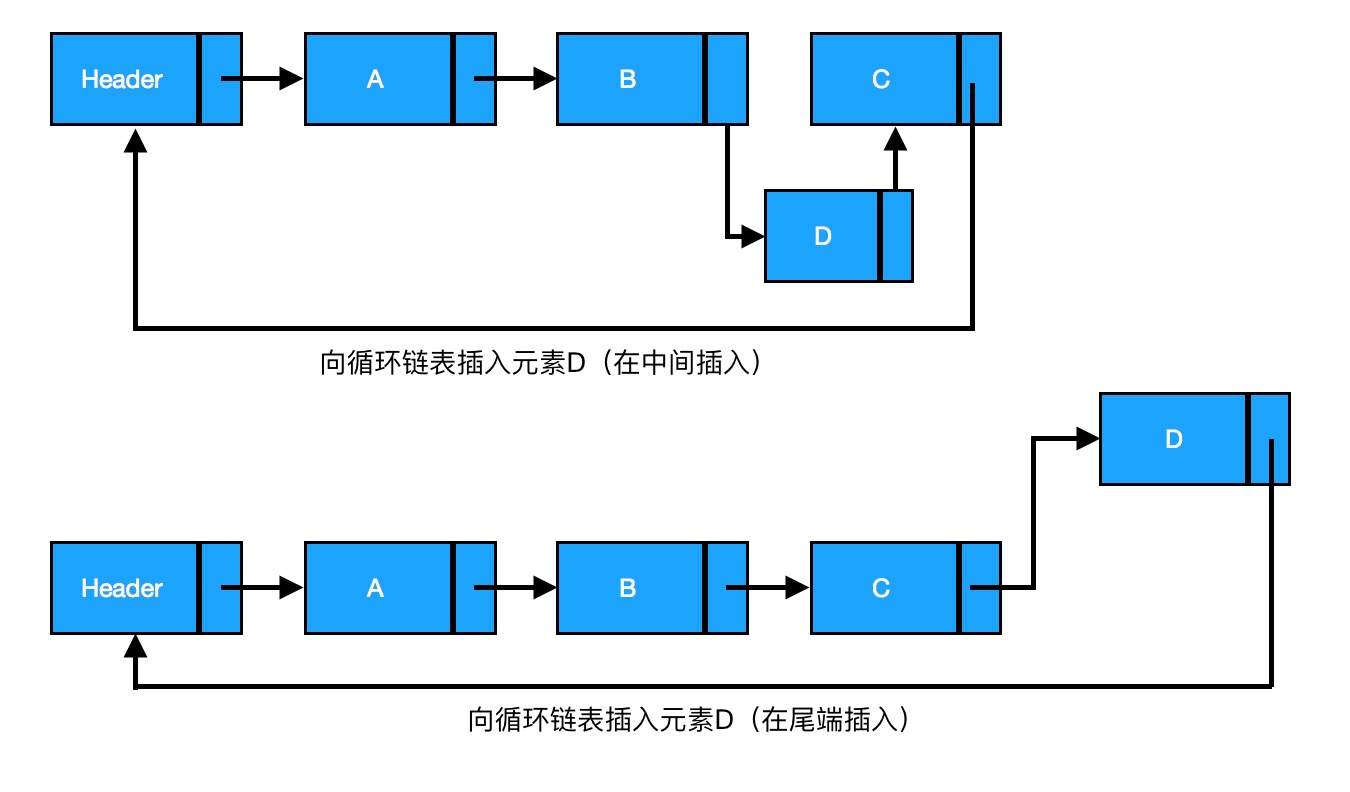
由上图可知,插入节点D,B、C、D三者之间的关系为
current为插入节点的前驱节点
// 中间
new->next = current->next // 新节点D指向B的后继节点C
current->next = new // B节点指向新节点D
// 尾端
current->next = new // C节点指向新节点D
new->next = header // 新节点D指向头节点Header
删除:如果删除的是中间元素,则与单链表操作相同,将待删除节点的前驱节点指向待删除节点的后继节点;如果删除的是尾端元素,则将待删除节点的前驱节点指向头节点。
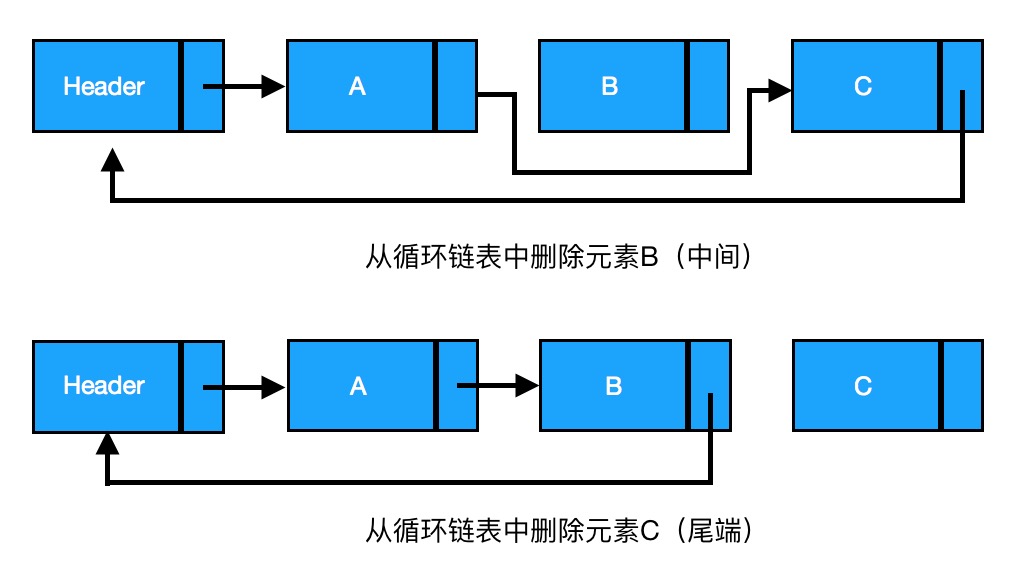
由上图可知,删除节点时,B、C、D三者之间的关系为
current为要删除节点的前驱节点
// 中间
current->next = current->next->next // A节点指向C节点
// 尾端
current->next = header // B节点指向头节点Header
具体代码如下:
三、循环链表
循环链表和单向链表相似,节点类型都是一样的。唯一的区别是,在创建循环链表时,让其头节点的 next 属性指向它本身,即:head.next = head,这种行为会传导至链表中的每个节点,使得每个节点的 next 属性都指向链表的头节点。换句话说,链表的尾节点指向头节点,形成了一个循环链表。
在循环链表中,涉及遍历的操作,其终止条件是判断它们是否等于头结点,而不是像单链表那样判别p或p->next是否为空。
插入:如果不是在链表尾端插入,则与单链表相似,将待插入节点的前驱节点指向新加入的节点,而新加入的节点指向原来前驱指向的节点;如果是在尾端插入,则待插入节点的前驱节点指向新加入的节点,而新加入的节点指向头节点(见下图)。
由上图可知,插入节点D,B、C、D三者之间的关系为
current为插入节点的前驱节点
// 中间
new->next = current->next // 新节点D指向B的后继节点C
current->next = new // B节点指向新节点D
// 尾端
current->next = new // C节点指向新节点D
new->next = header // 新节点D指向头节点Header
删除:如果删除的是中间元素,则与单链表操作相同,将待删除节点的前驱节点指向待删除节点的后继节点;如果删除的是尾端元素,则将待删除节点的前驱节点指向头节点。
由上图可知,删除节点时,B、C、D三者之间的关系为
current为要删除节点的前驱节点
// 中间
current->next = current->next->next // A节点指向C节点
// 尾端
current->next = header // B节点指向头节点Header
具体代码如下:140.php中实现snowflake雪花算法
这个算法的好处很简单可以在每秒产生约400W个不同的16位数字ID(10进制)
扩展阅读:
https://segmentfault.com/a/1190000021244328 laravel框架通过composer安装第三方包实现雪花算法
https://blog.csdn.net/JineD/article/details/107141757 我的另一篇博文,忘掉 Snowflake,感受一下性能高出 587 倍的全局唯一 ID 生成算法
一、雪花算法原理解析
1. 分布式ID常见生成策略:
分布式ID生成策略常见的有如下几种:
数据库自增ID。
UUID生成。
Redis的原子自增方式。
数据库水平拆分,设置初始值和相同的自增步长。
批量申请自增ID。
雪花算法。
百度UidGenerator算法(基于雪花算法实现自定义时间戳)。
美团Leaf算法(依赖于数据库,ZK)。
本文主要介绍SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。
其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,保持自增性且不重复。
2. 雪花算法的结构:
主要分为 5 个部分:
是 1 个 bit:0,这个是无意义的。
是 41 个 bit:表示的是时间戳。
是 10 个 bit:表示的是机房 id,0000000000,因为我传进去的就是0。
是 12 个 bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的 id 的序号,0000 0000 0000。
接下去我们来解释一下四个部分:
1 bit,是无意义的:
因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
41 bit:表示的是时间戳,单位是毫秒。
41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),这里可以随意拆分,比如拿出4位标识业务号,其他6位作为机器号。可以随意组合。
12 bit:这个是用来记录同一个毫秒内产生的不同 id。
12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。也就是同一毫秒内同一台机器所生成的最大ID数量为4096
简单来说,你的某个服务假设要生成一个全局唯一 id,那么就可以发送一个请求给部署了 SnowFlake 算法的系统,由这个 SnowFlake 算法系统来生成唯一 id。这个 SnowFlake 算法系统首先肯定是知道自己所在的机器号,(这里姑且讲10bit全部作为工作机器ID)接着 SnowFlake 算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个 64 bit 的 long 型 id,64 个 bit 中的第一个 bit 是无意义的。接着用当前时间戳(单位到毫秒)占用41 个 bit,然后接着 10 个 bit 设置机器 id。最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成 id 的请求累加一个序号,作为最后的 12 个 bit。
代码示例1
<?php
/**
* 雪花算法类
* @package app\helpers
*/
class SnowFlake
{
const EPOCH = 1479533469598;
const max12bit = 4095;
const max41bit = 1099511627775;
static $machineId = null;
public static function machineId($mId = 0) {
self::$machineId = $mId;
}
public static function generateParticle() {
/*
* Time - 42 bits
*/
$time = floor(microtime(true) * 1000);
/*
* Substract custom epoch from current time
*/
$time -= self::EPOCH;
/*
* Create a base and add time to it
*/
$base = decbin(self::max41bit + $time);
/*
* Configured machine id - 10 bits - up to 1024 machines
*/
if(!self::$machineId) {
$machineid = self::$machineId;
} else {
$machineid = str_pad(decbin(self::$machineId), 10, "0", STR_PAD_LEFT);
}
/*
* sequence number - 12 bits - up to 4096 random numbers per machine
*/
$random = str_pad(decbin(mt_rand(0, self::max12bit)), 12, "0", STR_PAD_LEFT);
/*
* Pack
*/
$base = $base.$machineid.$random;
/*
* Return unique time id no
*/
return bindec($base);
}
public static function timeFromParticle($particle) {
/*
* Return time
*/
return bindec(substr(decbin($particle),0,41)) - self::max41bit + self::EPOCH;
}
}
代码示例2
<?php
public function createID(){
//假设一个机器id
$machineId = 1234567890;
//41bit timestamp(毫秒)
$time = floor(microtime(true) * 1000);
//0bit 未使用
$suffix = 0;
//datacenterId 添加数据的时间
$base = decbin(pow(2,40) - 1 + $time);
//workerId 机器ID
$machineid = decbin(pow(2,9) - 1 + $machineId);
//毫秒类的计数
$random = mt_rand(1, pow(2,11)-1);
$random = decbin(pow(2,11)-1 + $random);
//拼装所有数据
$base64 = $suffix.$base.$machineid.$random;
//将二进制转换int
$base64 = bindec($base64);
$id = sprintf('%.0f', $base64);
return $id;
}
141.一致性hash原理是什么
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形
参考文章https://www.cnblogs.com/lpfuture/p/5796398.html
142.PHP中写个函数把将数字转化为中文
方法1
/**
* @author ja颂
* 把数字1-1亿换成汉字表述,如:123->一百二十三
* @param [num] $num [数字]
* @return [string] [string]
*/
function numToWord($num)
{
$chiNum = array('零', '一', '二', '三', '四', '五', '六', '七', '八', '九');
$chiUni = array('','十', '百', '千', '万', '亿', '十', '百', '千');
$chiStr = '';
$num_str = (string)$num;
$count = strlen($num_str);
$last_flag = true; //上一个 是否为0
$zero_flag = true; //是否第一个
$temp_num = null; //临时数字
$chiStr = '';//拼接结果
if ($count == 2) {//两位数
$temp_num = $num_str[0];
$chiStr = $temp_num == 1 ? $chiUni[1] : $chiNum[$temp_num].$chiUni[1];
$temp_num = $num_str[1];
$chiStr .= $temp_num == 0 ? '' : $chiNum[$temp_num];
}else if($count > 2){
$index = 0;
for ($i=$count-1; $i >= 0 ; $i--) {
$temp_num = $num_str[$i];
if ($temp_num == 0) {
if (!$zero_flag && !$last_flag ) {
$chiStr = $chiNum[$temp_num]. $chiStr;
$last_flag = true;
}
}else{
$chiStr = $chiNum[$temp_num].$chiUni[$index%9] .$chiStr;
$zero_flag = false;
$last_flag = false;
}
$index ++;
}
}else{
$chiStr = $chiNum[$num_str[0]];
}
return $chiStr;
}
$num = 150;
echo numToWord($num);方法2
<?php
/**
* 数字转换为中文
* @param string|integer|float $num 目标数字
* @param integer $mode 模式[true:金额(默认),false:普通数字表示]
* @param boolean $sim 使用小写(默认)
* @return string
*/
function number2chinese($num,$mode = true,$sim = true){
if(!is_numeric($num)) return '含有非数字非小数点字符!';
$char = $sim ? array('零','一','二','三','四','五','六','七','八','九')
: array('零','壹','贰','叁','肆','伍','陆','柒','捌','玖');
$unit = $sim ? array('','十','百','千','','万','亿','兆')
: array('','拾','佰','仟','','萬','億','兆');
$retval = $mode ? '元':'点';
//小数部分
if(strpos($num, '.')){
list($num,$dec) = explode('.', $num);
$dec = strval(round($dec,2));
if($mode){
$retval .= "{$char[$dec['0']]}角{$char[$dec['1']]}分";
}else{
for($i = 0,$c = strlen($dec);$i < $c;$i++) {
$retval .= $char[$dec[$i]];
}
}
}
//整数部分
$str = $mode ? strrev(intval($num)) : strrev($num);
for($i = 0,$c = strlen($str);$i < $c;$i++) {
$out[$i] = $char[$str[$i]];
if($mode){
$out[$i] .= $str[$i] != '0'? $unit[$i%4] : '';
if($i>1 and $str[$i]+$str[$i-1] == 0){
$out[$i] = '';
}
if($i%4 == 0){
$out[$i] .= $unit[4+floor($i/4)];
}
}
}
$retval = join('',array_reverse($out)) . $retval;
return $retval;
}
//实例调用=====================================================
$num = '0123648867.789';
echo $num,'<br>';
//普通数字的汉字表示
echo '普通:',number2chinese($num,false),'';
echo '<br>';
//金额汉字表示
echo '金额(简体):',number2chinese($num,true),'';
echo '<br>';
echo '金额(繁体):',number2chinese($num,true,false);143.redis里的hash类型怎么模糊查询value
users:1 {name:Jack,age:28,location:shanghai}
users:2 {name:Frank,age:30,location:beijing}
users:location:shanghai
其中users:1 users:2 分别定义了两个用户信息,通过Redis中的hash数据结构users:location:shanghai 记录了所有上海的用户id,通过集合数据结构实现。
Jedis jedis = jedisPool.getResource();SetshanghaiIDs = jedis.smembers("users:location:shanghai");//遍历该set//...//通过hgetall获取对应的user信息jedis.hgetAll("users:" + shanghaiIDs[0]);
ID索引的集合,其次对于一些复杂查询无能为力(当然也不能期望Redis实现像关系数据库那样的查询,Redis不是干这的);
但是Redis2.6集成了Lua脚本,可以通过eval命令,直接在RedisServer环境中执行Lua脚本,并且可以在Lua脚本中调用Redis命令。其实,就是说可以让你用Lua这种脚本语言,对Redis中存储的key value进行操作,这个意义就大了,甚至可以将你们系统所需的各种业务写成一个个lua脚本;
public static final String SCRIPT ="local resultKeys={};"+ "for k,v in ipairs(KEYS) do "+ " local tmp = redis.call('hget', v, 'age');"+ " if tmp > ARGV[1] then "+ " table.insert(resultKeys,v);"+ " end;"+ "end;"+ "return resultKeys;";执行脚本代码Jedis jedis = jedisPool.getResource();jedis.auth(auth);Listkeys=Arrays.asList(allUserKeys);Listargs = new ArrayList<>();args.add("28");ListresultKeys = (List)jedis.evalsha(funcKey, keys, args);return resultKeys;
注意:以上的代码中使用的是evalsha命令,该命令参数的不是直接Lua脚本字符串,而是提前已经加载到Redis中的函数的一个SHA索引,通过以下的代码将系统中所有需要执行的函数提前加载到Redis中,我们的系统维护一个函数哈希表,后续需要实现什么功能,就从函数表中获取对应功能的SHA索引,通过evalsha调用就行。144.为什么项目中要用分布式锁
高并发下争夺共享资源,比如秒杀对于库存这种共享资源需要用到分布式锁,如果不用分布式锁很可能造成超卖。
参考文章https://www.cnblogs.com/myseries/p/10784410.html
145.分布式锁的释放需要注意什么
1 互斥性 => 任意时刻,只有一个客户端持有锁
2 不会发生死锁 => 即使一个客户端持有锁后没有释放锁,也能保证后续其他客户端能加锁
3 具有容错性 => 只要大部分Redis节点正常运行,客户端就能加锁,解锁
4 加锁解锁必须是同一个客户端
146.redis单线程如何实现阻塞队列
redis中blpop可以实现链表的阻塞操作
对BLPOP命令的处理流程是这样的:
redis先找到对应的key的list,如果list不为空则pop一个数据返回给客户端;
如果list为空,或者list不存在,就将该key添加到一个blockling_keys的字典中,value就是想订阅该key的client链表。此时对应的client的为block状态
当有PUSH 类型的命令进来的时候,先从blocking_keys中查找是否存在对应的key,如果存在就往ready_keys这个链表中添加该key;同时将value插入到对应的list中,并响应客户端。
每次处理完客户端命令后都会遍历ready_keys,并通过blocking_keys找到对应的client,依次将对应list的数据pop出来并响应对应的client;同时检查是否需要再次block。
整个阻塞执行过程相当于是分散开的,每次请求结束后都判断之前的阻塞列表是否满足执行条件,类似我们用轮询来实现长连接的功能。所以看似阻塞的命令对其他命令的执行时不会有影响的,它们依然是单线程的。
参考:https://www.cnblogs.com/barrywxx/p/8570821.html
147.如何搭建mysql分布式集群
参考文章https://www.cnblogs.com/dz11/p/10137945.html
148.php中socket网络通信是如何实现的
由于socket服务端的代码要监听端口,等待接收请求,所以php在做socket服务的时候需要将php文件运行在CMD里面。
如果要使php文件可以在CMD里面运行,则需要进行如下设置:
1.添加环境变量,名字为PHP_HOME,值为php文件安装目录下的.exe文件地址,如D:\wamp\bin\php\php5.5.12\php.exe
2.修改系统变量path的值
在path的值里面添加php安装的目录:如D:\wamp\bin\php\php5.5.12;
好了,到这里我们就配置好了环境变量,下一步我们打开CMD,想要在里面运行php文件,比如aaa.php文件,则我们写上这一句话:
php d:\wamp\www\aaa.php
然后按下回车键,好了,我们的php文件在cmd里面运行了,输出了一句:hello
这样的话php文件能够成功在cmd里面运行,接下来我们来看一下php怎么实现socket通信。
1.php制作的socket服务端
主要功能是设置socket通信的IP地址及端口号,监听端口,有客户端连接的话,接收连接请求接收数据,处理并且返回数据。
代码如下:
//确保在连接客户端时不会超时
set_time_limit(0);
//设置IP和端口号
$address = "127.0.0.1";
$port = 2048; //调试的时候,可以多换端口来测试程序!
/**
* 创建一个SOCKET
* AF_INET=是ipv4 如果用ipv6,则参数为 AF_INET6
* SOCK_STREAM为socket的tcp类型,如果是UDP则使用SOCK_DGRAM
*/
$sock = socket_create(AF_INET, SOCK_STREAM, SOL_TCP) or die("socket_create() 失败的原因是:" . socket_strerror(socket_last_error()) . "/n");
//阻塞模式
socket_set_block($sock) or die("socket_set_block() 失败的原因是:" . socket_strerror(socket_last_error()) . "/n");
//绑定到socket端口
$result = socket_bind($sock, $address, $port) or die("socket_bind() 失败的原因是:" . socket_strerror(socket_last_error()) . "/n");
//开始监听
$result = socket_listen($sock, 4) or die("socket_listen() 失败的原因是:" . socket_strerror(socket_last_error()) . "/n");
echo "OK\nBinding the socket on $address:$port ... ";
echo "OK\nNow ready to accept connections.\nListening on the socket ... \n";
do { // never stop the daemon
//它接收连接请求并调用一个子连接Socket来处理客户端和服务器间的信息
$msgsock = socket_accept($sock) or die("socket_accept() failed: reason: " . socket_strerror(socket_last_error()) . "/n");
//读取客户端数据
echo "Read client data \n";
//socket_read函数会一直读取客户端数据,直到遇见\n,\t或者\0字符.PHP脚本把这写字符看做是输入的结束符.
$buf = socket_read($msgsock, 8192);
echo "Received msg: $buf \n";
//数据传送 向客户端写入返回结果
$msg = "welcome \n";
socket_write($msgsock, $msg, strlen($msg)) or die("socket_write() failed: reason: " . socket_strerror(socket_last_error()) ."/n");
//一旦输出被返回到客户端,父/子socket都应通过socket_close($msgsock)函数来终止
socket_close($msgsock);
} while (true);
socket_close($sock);2.调取socket服务的客户端文件
客户端依然是要设置好要访问服务器的IP地址及端口号(即上一步骤中的IP及端口),完了创建一个socket连接,发送数据到服务器,接收返回数据。
set_time_limit(0);
$host = "127.0.0.1";
$port = 2048;
$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP)or die("Could not create socket\n"); // 创建一个Socket
$connection = socket_connect($socket, $host, $port) or die("Could not connet server\n"); // 连接
socket_write($socket, "hello socket") or die("Write failed\n"); // 数据传送 向服务器发送消息
while ($buff = @socket_read($socket, 1024, PHP_NORMAL_READ)) {
echo("Response was:" . $buff . "\n");
}
socket_close($socket);3.在cmd里面运行服务端代码
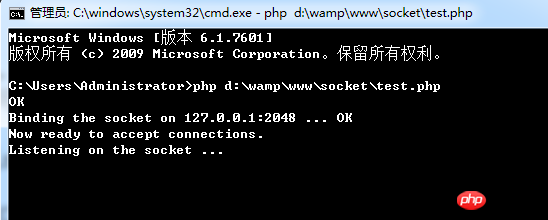
运行成功,已经在监听端口了。。。
4.在网页里面运行我们的客户端网页,来向服务器交互数据
运行起来,浏览器显示:
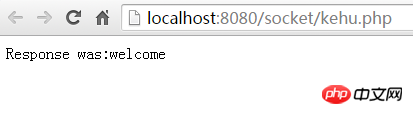
cmd里面的服务端显示:
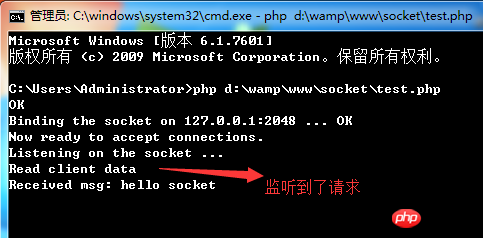
149.如何设计一个rbac系统?
RBAC(基于角色的权限控制)模型的核心是在用户和权限之间引入了角色的概念。取消了用户和权限的直接关联,改为通过用户关联角色、角色关联权限的方法来间接地赋予用户权限(如下图),从而达到用户和权限解耦的目的。
RABC的好处
- 职能划分更谨慎。对于角色的权限调整不仅仅只影响单个用户,而是会影响关联此角色的所有用户,管理员下发/回收权限会更为谨慎;
- 便于权限管理。对于批量的用户权限调整,只需调整用户关联的角色权限即可,无需对每一个用户都进行权限调整,既大幅提升权限调整的效率,又降低漏调权限的概率;
在不断的发展过程中,RBAC也因不同的需求而演化出了不同的版本,目前主要有以下几个版本:
- RBAC0,这是RBAC的初始形态,也是最原始、最简单的RBAC版本;
- RBAC1,基于RBAC0的优化,增加了角色的分层(即:子角色),子角色可以继承父角色的所有权限;
- RBAC2,基于RBAC0的另一种优化,增加了对角色的一些限制:角色互斥、角色容量等;
- RBAC3,最复杂也是最全面的RBAC模型,它在RBAC0的基础上,将RBAC1和RBAC2中的优化部分进行了整合;
二、基于RBAC的几种权限体系设计
1、用户-角色-权限
这种权限体系其实就是RBAC0的模式了。这里面又包含了2种:
- 用户和角色是多对一关系,即:一个用户只充当一种角色,一种角色可以有多个用户担当;
- 用户和角色是多对多关系,即:一个用户可同时充当好几种角色,一种角色可以有多个用户担当;
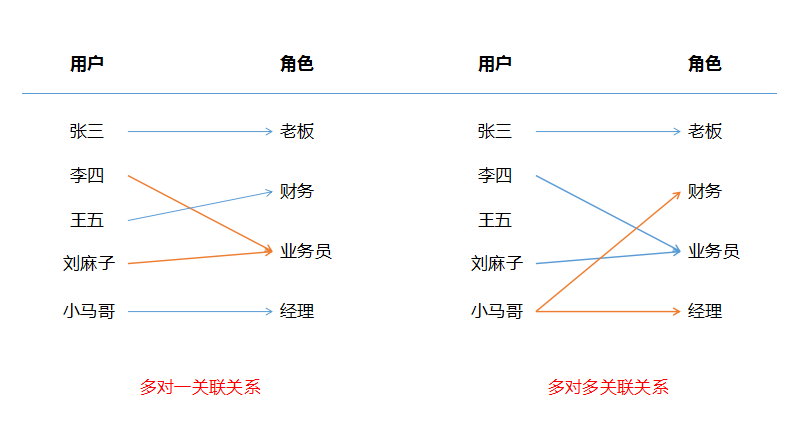
如上图:对于左边的用户-角色对应,每个人只能同时拥有一种角色,但是同一个角色里边,可能会含有多个用户(如:李四和王麻子都是业务员);而右边的用户-角色对应,是在左边的基础上,增加了一个用户可拥有多种角色的情况(如:小马哥既是经理,也要负责财务的工作);
那么,什么时候该使用多对一的权限体系,什么时候又该使用多对多的权限体系呢?
我的建议是:尽量可能地使用多对多的权限体系。如果这个系统的功能比较单一、使用人员较少、岗位权限相对清晰且不会出现兼岗的情况,这种情况也可以考虑用多对一的权限体系。
2、用户-组织-角色-权限
一般公司的业务管理系统,都有数据私密性的要求:哪些人可以看到哪些数据,哪些人不可以看到哪些数据。这个时候,我们就需要把这些东西也考虑到你的权限体系内了。
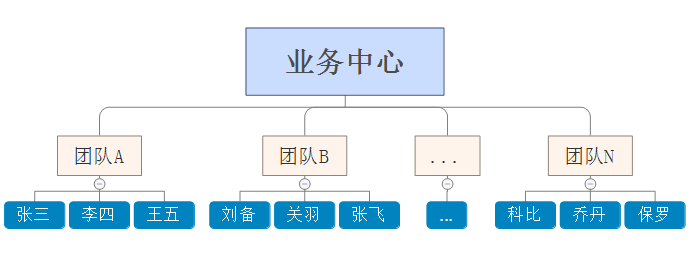
假设上图是一家公司业务部门的组织架构图,公司要求你基于这个组织架构设计一个业务管理系统,并要求系统需要满足不同用户的数据私密性,比如:“张三”登录时,只能看到“张三”负责的数据;“张三”的领导登录时,能看到“团队A”的所有业务员负责的数据,但看不到其他团队业务员负责的数据等等。
在这种情况下,上一种权限体系就不适用了,但我们可以对其进行一些小改造后,即可达到数据管控的目的,如下图:
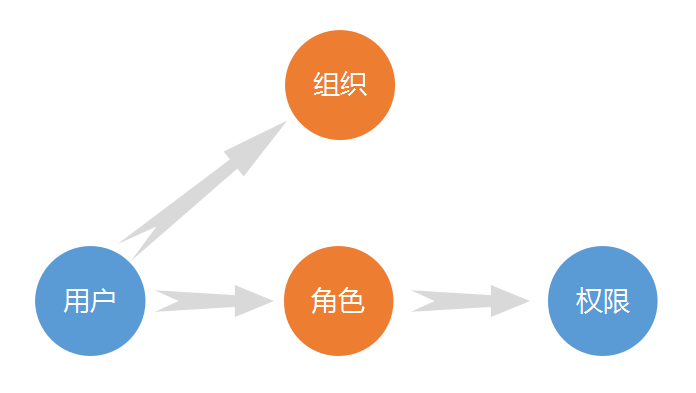
在“用户-角色-权限”的基础上,我们增加了用户与组织的关联关系,组织决定了用户的数据可视权限。但要想真正达到这个效果,我们还需要做2件事:
- 组织层级划分。如下图,我们需要对组织进行梳理,并划分层级;
- 数据可视权限规则制定。比如:上级组织职能看到下级组织员工负责的数据,而不能看到其他平级组织及其下级组织的员工数据等。
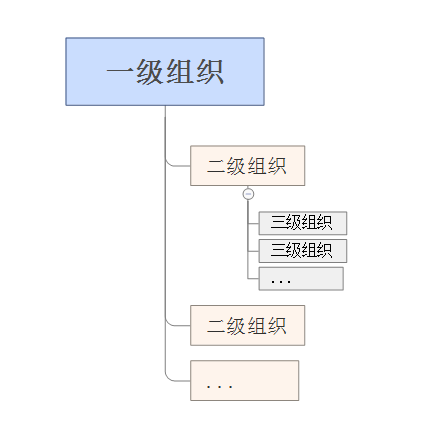
通过以上两点,系统就可以在用户登录时,自动判断要给用户展示哪些数据了!
3、用户-组织-岗位-角色-权限
第三种权限体系又是在第二种权限体系上进行优化的,增加了用户与岗位的关联关系,示意图如下:
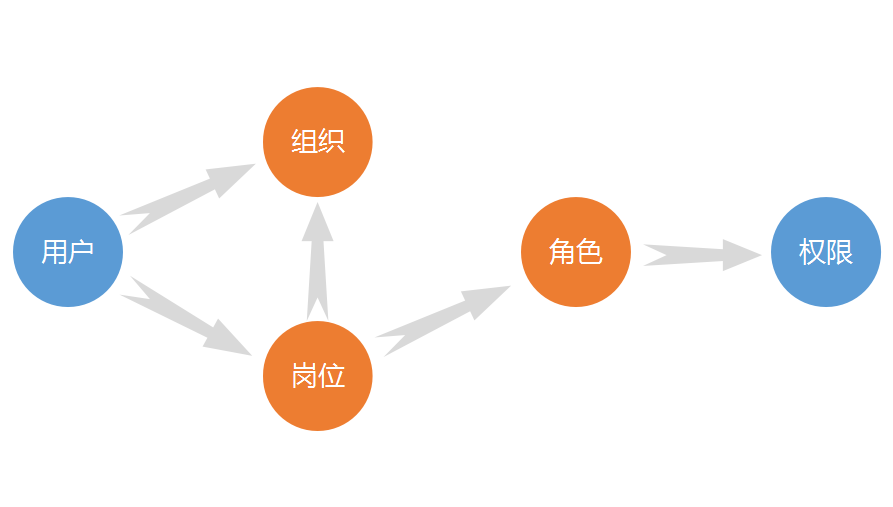
增加岗位有以下几点好处:
- 识别用户的主要身份。一个人可能身兼多职(多个角色),但是他的主要职能是固定的,那怎么告诉系统用户的主要职能是什么呢?答案就是:通过岗位!拿上面的小马哥举例:小马哥虽然身兼经理和财务两种身份,但他的本职工作是“经理”,因此,他的系统岗位应该“经理”。当他登录时,系统会识别他的身份为“经理”,只不过这个“经理”刚好兼具了其他岗位的职能而已;
- 通过“组织-岗位”关联,快速甄别用户岗位。公司在不断地发展的过程中,系统的用户角色也会不断增加,当角色达到一定数量以后,管理员每新增一个用户都要花相当的时间去寻找角色。引入岗位后,可将组织和岗位、岗位和角色提前进行关联,配置账号时,管理员只要选定组织,系统就给出与该组织关联的岗位,而这些岗位,又是提前关联好角色的,选择起来,既方便又高效!
三、总结
以上是基于RBAC模型的三种权限体系,不难看出,三种权限体系的本质都是用户和权限进行解耦,以达到权限的灵活运用。
150.docker、docker-compose、docker swarm和k8s的区别
Docker
Docker 这个东西所扮演的角色,容易理解,它是一个容器引擎,也就是说实际上我们的容器最终是由Docker创建,运行在Docker中,其他相关的容器技术都是以Docker为基础,它是我们使用其他容器技术的核心。
Docker-Compose
Docker-Compose 是用来管理你的容器的,有点像一个容器的管家,想象一下当你的Docker中有成百上千的容器需要启动,如果一个一个的启动那得多费时间。有了Docker-Compose你只需要编写一个文件,在这个文件里面声明好要启动的容器,配置一些参数,执行一下这个文件,Docker就会按照你声明的配置去把所有的容器启动起来,只需docker-compose up即可启动所有的容器,但是Docker-Compose只能管理当前主机上的Docker,也就是说不能去启动其他主机上的Docker容器
Docker Swarm
Docker Swarm 是一款用来管理多主机上的Docker容器的工具,可以负责帮你启动容器,监控容器状态,如果容器的状态不正常它会帮你重新帮你启动一个新的容器,来提供服务,同时也提供服务之间的负载均衡,而这些东西Docker-Compose 是做不到的
Kubernetes
Kubernetes它本身的角色定位是和Docker Swarm 是一样的,也就是说他们负责的工作在容器领域来说是相同的部分,都是一个跨主机的容器管理平台,当然也有自己一些不一样的特点,k8s是谷歌公司根据自身的多年的运维经验研发的一款容器管理平台。而Docker Swarm则是由Docker 公司研发的。
既然这两个东西是一样的,那就面临选择的问题,应该学习哪一个技术呢?实际上这两年Kubernetes已经成为了很多大公司的默认使用的容器管理技术,而Docker Swarm已经在这场与Kubernetes竞争中已经逐渐失势,如今容器管理领域已经开始已经逐渐被Kubernetes一统天下了。所以建议大家学习的时候,应该多考虑一下这门技术在行业里面是不是有很多人在使用。
需要注意的是,虽然Docker Swarm在与Kubernetes的竞争中败下阵来,但是这个跟Docker这个容器引擎没有太大关系,它还是整个容器领域技术的基石,Kubernetes离开他什么也不是。
总结
Docker是容器技术的核心、基础,Docker Compose是一个基于Docker的单主机容器编排工具.而k8s是一个跨主机的集群部署工具,功能并不像Docker Swarm和Kubernetes是基于Dcoker的跨主机的容器管理平台那么丰富
151.$a='137.20'; $b=intval($a*100); $c=intval(strval('137.89')*100); $d=intval(bcmul('137.20',100,0)); echo $b.','.$c.','.$d;
13719,13788,13720
152.$x=1; ++$x; $y=$x++;
2
153.$num="24linux"+6;
30
154. empty为true有哪些情况
var_dump(empty(0));
var_dump(empty('0'));
var_dump(empty(array()));
var_dump(empty(null));
var_dump(empty($a));
var_dump(empty(false));
var_dump(empty(''));155. if($a=100&&$b=200){ var_dump($a,$b); }
1.&& 优先于=
2.&& 具有短路作用,它在运行的时候先计算左值,如果左值为ture,再计算右值。如果左值为false,则不计算右值
3.100表示true,需要计算右值,200赋值给b, 100 && 200 结果为true; 最后赋值给a;
输出结果:
bool(true)
int(200)
156.for($k=0;$k=1;$k++)和for($k=0;$k==1;$k++)执行的次数分别是?
无限和0
for (k=0; k=1; k++)
先执行自变量初始化k=0,而后判断是否满足条件,但是由于本句中的判定条件为k=1,是一个赋值表达式,按照赋值运算的规则,表达式k=1的值将始终为1,即逻辑真。这将导致该循环成为一个死循环。
for (k=0; k==1; k++)
同样,先给自变量赋初值k=0,而后判定是否满足条件,由于k此时等于0,不满足判定条件k==1,因此该循环体实际上一次也不会执行。
157.php表达式$foo=1+"bob3",则$foo的值是
字符串在php运算中相当于把0进行加减,本题是把右边的1赋值给$foo,则$foo=1。
158.var val=‘Tencent’ console.log('Result is' +(val==='Tencent'?'yes':'no'))
+ 优先级大于 ?
此题等价于: 'Result is true' ? 'yes' : 'no'
所以结果是:yes
159.请写出以下js表达式的值: '12'+12;'12'-12
1212,0
js中字符串与数字间的运算分三种情况
第一种,加号“+”:
"12" + 12 = 12 + "12" = "1212"
无论怎么变换位置,结果都为字符串,因为“ + ”是个特殊的符号,除了基本运算外,在程序里还有个作用就是——连接,除非两个都是数字,否则都会把其中的数字转换为字符串相连接。
第二种,第一个(无论是字串还是数字)前面有符号:
+"12" + 12 = +12 + 12 = 24 因为"12"前面有+号(或者叫连字符),+号前面没有别的东西了,所以就判断它表示的是 一个“正”数,进而将“12”转换成了数字。
+12 + "12" = 12 + "12" ="1212" 这个就跟第一种一样了
第三种,其他运算符:
"12" - 12 = 0 "12" * 12 = 144 "12" / 12 = 1
其他运算符仅此一种作用,因而当字串遇到它们时,就自转为数字了。
160.$a='zs';$i=1;$a[$i]=$i;
z1
161.$a=3; $a +=$a-=$a*$a;
-12
162.进程中有哪几种状态
- 创建: 进程正在被创建,尚未转到就绪状态。
- 就绪状态:进程已经处于准备运行状态,即进程获得了除处理器一切的所需资源,一旦得到处理器即可运行。
- 运行状态:进程正在处理器上运行。在单处理器环境下,每一个时刻最多只有一个进程处于运行状态。
- 阻塞状态:进程正在等待某一时间而暂停运行,如等待某资源为可用(不包括处理器)或等待输入、输出完成。即处理器空闲,该进程也不能运行。
- 结束状态:进程正从系统消失,可能是进程正常结束或者其他原因中断退出运行。
163.进程中的通信方式
1. 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2.有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
3..信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
4. 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5. 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
6.共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
7. 套接字( socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
164.进程中的调度算法有哪些
- 01. 进程调度算法概述
- 02. 先来先服务调度算法
- 03. 时间片轮转调度法
- 04. 短作业(SJF)优先调度算法
- 05. 最短剩余时间优先
- 06. 高响应比优先调度算法
- 07. 优先级调度算法
- 08. 多级反馈队列调度算法
01. 进程调度算法概述
调度算法是指:根据系统的资源分配策略所规定的资源分配算法
02. 先来先服务调度算法
先来先服务调度算法是一种最简单的调度算法,也称为先进先出或严格排队方案。当每个进程就绪后,它加入就绪队列。当前正运行的进程停止执行,选择在就绪队列中存在时间最长的进程运行。该算法既可以用于作业调度,也可以用于进程调度。先来先去服务比较适合于常作业(进程),而不利于段作业(进程)。
FCFS调度算法是一种最简单的调度算法,该调度算法既可以用于作业调度也可以用于进程调度。在作业调度中,算法每次从后备作业队列中选择最先进入该队列的一个或几个作业,将它们调入内存,分配必要的资源,创建进程并放入就绪队列。
在进程调度中,FCFS调度算法每次从就绪队列中选择最先进入该队列的进程,将处理机分配给它,使之投入运行,直到完成或因某种原因而阻塞时才释放处理机。
下面通过一个实例来说明FCFS调度算法的性能。假设系统中有4个作业,它们的提交时间分别是8、8.4、8.8、9,运行时间依次是2、1、0.5、0.2,系统釆用FCFS调度算法,这组作业的平均等待时间、平均周转时间和平均带权周转时间如下表所示。
| 作业号 | 提交时间 | 运行时间 | 开始时间 | 等待时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|---|
| 1 | 8 | 2 | 8 | 0 | 10 | 2 | 1 |
| 2 | 8.4 | 1 | 10 | 1.6 | 11 | 2.6 | 2.6 |
| 3 | 8.8 | 0.5 | 11 | 2.2 | 11.5 | 2.7 | 5.4 |
| 4 | 9 | 0.2 | 11.5 | 2.5 | 11.7 | 2.7 | 13.5 |
平均等待时间 t = (0+1.6+2.2+2.5)/4=1.575
平均周转时间 T = (2+2.6+2.7+2.7)/4=2.5
平均带权周转时间 W = (1+2.6+5.牡13.5)/4=5.625
FCFS调度算法属于不可剥夺算法。从表面上看,它对所有作业都是公平的,但若一个长作业先到达系统,就会使后面许多短作业等待很长时间,因此它不能作为分时系统和实时系统的主要调度策略。但它常被结合在其他调度策略中使用。例如,在使用优先级作为调度策略的系统中,往往对多个具有相同优先级的进程按FCFS原则处理。
FCFS调度算法的特点是算法简单,但效率低;对长作业比较有利,但对短作业不利(相对SJF和高响应比);有利于CPU繁忙型作业,而不利于I/O繁忙型作业。
03. 时间片轮转调度法
时间片轮转调度算法主要适用于分时系统。在这种算法中,系统将所有就绪进程按到达时间的先后次序排成一个队列,进程调度程序总是选择就绪队列中第一个进程执行,即先来先服务的原则,但仅能运行一个时间片,如100ms。在使用完一个时间片后,即使进程并未完成其运行,它也必须释放出(被剥夺)处理机给下一个就绪的进程,而被剥夺的进程返回到就绪队列的末尾重新排队,等候再次运行。
在时间片轮转调度算法中,时间片的大小对系统性能的影响很大。如果时间片足够大,以至于所有进程都能在一个时间片内执行完毕,则时间片轮转调度算法就退化为先来先服务调度算法。如果时间片很小,那么处理机将在进程间过于频繁切换,使处理机的开销增大,而真正用于运行用户进程的时间将减少。因此时间片的大小应选择适当。
时间片的长短通常由以下因素确定:系统的响应时间、就绪队列中的进程数目和系统的处理能力。
04. 短作业(SJF)优先调度算法
短作业(进程)优先调度算法是指对短作业(进程)优先调度的算法。短作业优先(SJF)调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。而短进程优先(SPF)调度算法,则是从就绪队列中选择一个估计运行时间最短的进程,将处理机分配给它,使之立即执行,直到完成或发生某事件而阻塞时,才释放处理机。
短作业优先调度算法是一个非抢占策略,他的原则是下一次选择预计处理时间最短的进程,因此短进程将会越过长作业,跳至队列头。该算法即可用于作业调度,也可用于进程调度。但是他对长作业不利,不能保证紧迫性作业(进程)被及时处理,作业的长短只是被估算出来的。
缺点:
- 该算法对长作业不利,SJF调度算法中长作业的周转时间会增加。更严重的是,如果有一长作业进入系统的后备队列,由于调度程序总是优先调度那些 (即使是后进来的)短作业,将导致长作业长期不被调度(“饥饿”现象,注意区分“死锁”。后者是系统环形等待,前者是调度策略问题)。
- 该算法完全未考虑作业的紧迫程度,因而不能保证紧迫性作业会被及时处理。
- 由于作业的长短只是根据用户所提供的估计执行时间而定的,而用户又可能会有意或无意地缩短其作业的估计运行时间,致使该算法不一定能真正做到短作业优先调度。
【注意】 SJF调度算法的平均等待时间、平均周转时间最少。
05. 最短剩余时间优先
最短剩余时间是针对最短进程优先增加了抢占机制的版本。在这种情况下,进程调度总是选择预期剩余时间最短的进程。当一个进程加入到就绪队列时,他可能比当前运行的进程具有更短的剩余时间,因此只要新进程就绪,调度程序就能可能抢占当前正在运行的进程。像最短进程优先一样,调度程序正在执行选择函数是必须有关于处理时间的估计,并且存在长进程饥饿的危险。
06. 高响应比优先调度算法
根据比率:R=(w+s)/s (R为响应比,w为等待处理的时间,s为预计的服务时间)
如果该进程被立即调用,则R值等于归一化周转时间(周转时间和服务时间的比率)。R最小值为1.0,只有第一个进入系统的进程才能达到该值。调度规则为:当前进程完成或被阻塞时,选择R值最大的就绪进程,它说明了进程的年龄。当偏向短作业时,长进程由于得不到服务,等待时间不断增加,从而增加比值,最终在竞争中赢了短进程。和最短进程优先、最短剩余时间优先一样,使用最高响应比策略需要估计预计服务时间。
高响应比优先调度算法主要用于作业调度,该算法是对FCFS调度算法和SJF调度算法的一种综合平衡,同时考虑每个作业的等待时间和估计的运行时间。在每次进行作业调度时,先计算后备作业队列中每个作业的响应比,从中选出响应比最高的作业投入运行。
根据公式可知:
- 当作业的等待时间相同时,则要求服务时间越短,其响应比越高,有利于短作业。
- 当要求服务时间相同时,作业的响应比由其等待时间决定,等待时间越长,其响应比越高,因而它实现的是先来先服务。
- 对于长作业,作业的响应比可以随等待时间的增加而提高,当其等待时间足够长时,其响应比便可升到很高,从而也可获得处理机。克服了饥饿状态,兼顾了长作业。
07. 优先级调度算法
优先级调度算法又称优先权调度算法,该算法既可以用于作业调度,也可以用于进程调度,该算法中的优先级用于描述作业运行的紧迫程度。
在作业调度中,优先级调度算法每次从后备作业队列中选择优先级最髙的一个或几个作业,将它们调入内存,分配必要的资源,创建进程并放入就绪队列。在进程调度中,优先级调度算法每次从就绪队列中选择优先级最高的进程,将处理机分配给它,使之投入运行。
根据新的更高优先级进程能否抢占正在执行的进程,可将该调度算法分为:
- 非剥夺式优先级调度算法。当某一个进程正在处理机上运行时,即使有某个更为重要或紧迫的进程进入就绪队列,仍然让正在运行的进程继续运行,直到由于其自身的原因而主动让出处理机时(任务完成或等待事件),才把处理机分配给更为重要或紧迫的进程。
- 剥夺式优先级调度算法。当一个进程正在处理机上运行时,若有某个更为重要或紧迫的进程进入就绪队列,则立即暂停正在运行的进程,将处理机分配给更重要或紧迫的进程。
而根据进程创建后其优先级是否可以改变,可以将进程优先级分为以下两种:
-
静态优先级。优先级是在创建进程时确定的,且在进程的整个运行期间保持不变。确定静态优先级的主要依据有进程类型、进程对资源的要求、用户要求。
-
动态优先级。在进程运行过程中,根据进程情况的变化动态调整优先级。动态调整优先级的主要依据为进程占有CPU时间的长短、就绪进程等待CPU时间的长短。
08. 多级反馈队列调度算法
多级反馈队列算法,不必事先知道各种进程所需要执行的时间,他是当前被公认的一种较好的进程调度算法。
多级反馈队列调度算法的实现思想如下:
- 应设置多个就绪队列,并为各个队列赋予不同的优先级,第1级队列的优先级最高,第2级队列次之,其余队列的优先级逐次降低。
- 赋予各个队列中进程执行时间片的大小也各不相同,在优先级越高的队列中,每个进程的运行时间片就越小。例如,第2级队列的时间片要比第1级队列的时间片长一倍, ……第i+1级队列的时间片要比第i级队列的时间片长一倍。
- 当一个新进程进入内存后,首先将它放入第1级队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第2级队列的末尾,再同样地按FCFS 原则等待调度执行;如果它在第2级队列中运行一个时间片后仍未完成,再以同样的方法放入第3级队列……如此下去,当一个长进程从第1级队列依次降到第 n 级队列后,在第 n 级队列中便釆用时间片轮转的方式运行。
- 仅当第1级队列为空时,调度程序才调度第2级队列中的进程运行;仅当第1 ~ (i-1)级队列均为空时,才会调度第i级队列中的进程运行。如果处理机正在执行第i级队列中的某进程时,又有新进程进入优先级较高的队列(第 1 ~ (i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第i级队列的末尾,把处理机分配给新到的更高优先级的进程。
多级反馈队列的优势有:
-
- 终端型作业用户:短作业优先。
- 短批处理作业用户:周转时间较短。
- 长批处理作业用户:经过前面几个队列得到部分执行,不会长期得不到处理。
- 终端型作业用户:短作业优先。
165.mysql把一张大表水平拆分多张表后如何解决跨表查询效率问题
大表分表后每个表的结构相同,可以用sql的union
比如a,b表结构相同可以通过union来联接
select * from a
union all
select * from b
where
。。。。
其实你还可以建一张主表将你要连表查询的字段放在其中,做好索引;你还记录下用户经常查询的条件,把查出的数据缓存,以便用户经常调用。
166.用一条SQL语句查询出每门课都大于80分的学生姓名
name kecheng fenshu 张三 语文 81 张三 数学 75 李四 语文 76 李四 数学 90 王五 语文 81 王五 数学 100 王五 英语 90
A: select distinct name from score where name not in (select distinct name from score where score<=80)
B:select distince name t1 from score where 80< all (select score from score where name=t1);
167.前后端分离的情况下前端在a.com下向b.com请求接口后端如何解决前端跨域问题
nginx反响代理api接口
参考文章https://segmentfault.com/a/1190000012859206
168.你用什么方法检查 PHP 脚本的执行效率(通常是脚本执行时间)和数据库 SQL 的效率(通常是数据库 Query 时间), 并定位和分析脚本执行和数据库查询的瓶颈所在?
PHP脚本的执行效率
1, 代码脚本里计时。
function getmicrotime(){
list(usec,sec) = explode(" ",microtime());
num=((float)usec+(float)$sec);
return sprintf("%.4f",$num);
}
用法:
$t_start = getmicrotime();
//这里放你要检查的代码
$t_end = getmicrotime();
echo tend−t_start;
2, xdebug统计函数执行次数和具体时间进行分析。,最好使用工具winCacheGrind分析
3, 用strace跟踪相关进程的具体系统调用。
数据库SQL的效率
sql的explain(mysql),启用slow query log记录慢查询。
通常还要看数据库设计是否合理,需求是否合理等。
169.多个网站域名(www.a.com,wwwb.com,www.c.com)在www.a.com登录如何保证www.b.com和www.c.com也能同时登录
sso https://www.jianshu.com/p/75edcc05acfd
170.在高并发环境下请列举提高接口响应速度的方法或关注点
1、流量优化
防盗链处理(去除恶意请求)
2、前端优化
(1) 减少HTTP请求[将css,js等合并]
(2) 添加异步请求(先不将所有数据都展示给用户,用户触发某个事件,才会异步请求数据)
(3) 启用浏览器缓存和文件压缩
(4) CDN加速
(5) 建立独立的图片服务器(减少I/O)
3、服务端优化
(1) 页面静态化
(2) 并发处理
(3) 队列处理
4、数据库优化
(1) 数据库缓存
(2) 分库分表,分区
(3) 读写分离
(4) 负载均衡
5、web服务器优化
(1) nginx反向代理实现负载均衡
(2) lvs实现负载均衡
171.数据库优化:
有一个表 PRODUCT(ID,NAME,PRICE,COUNT);
在执行一下查询的时候速度总是很慢:
SELECT * FROM PRODUCT WHERE PRICE=100;
在price字段上加上一个非聚簇索引,查询速度还是很慢。
(1)分析查询慢的原因。
(2)如何进行优化。

172.移除元素 给定一个数组 NUMS 和一个值 VAL,你需要原地移除所有数值等于 VAL 的元素,返回移除后数组的新长度。 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1)
public int removeElement(int[] nums, int val) {
int k=0;
for(int i=0;i<nums.length;i++){
if(nums[i]!=val){
nums[k]=nums[i];
k++;
}
}
return k;
}https://www.freesion.com/article/5182467012/
173.给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
var towSum = function(nums, target){
for(let i=0, len = nums.length; i<len; i++) {
for(let j = i+1; j < nums.length; j++) {
if(nums[i] + nums[j] == target) {
return [i, j]
}
}
}
}https://www.cnblogs.com/liugang-vip/p/13066841.html
174.一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
示例 1:
输入: [0,1,3]
输出: 2
示例 2:
输入: [0,1,2,3,4,5,6,7,9]
输出: 8
限制:
1 <= 数组长度 <= 10000
测试用例:
[1,2]
[0,1,3]
[0,1,2,3,4,5,6,7,9]
[]
[0]
思路一:一次循环遍历
class Solution {
public:
int missingNumber(vector<int>& nums) {
int n = nums.size();
for (int i=0; i<n; i++) {
if (nums[i] != i){
return i;
}
}
return n;
}
};
/*20ms,19.5MB*/
时间复杂度:O(n)
空间复杂度:O(1)
思路二:二分查找
class Solution {
public:
int missingNumber(vector<int>& nums) {
int n = nums.size();
int left = 0, right = n, mid = 0;
while (left < right) {
mid = left + (right - left) / 2;
if (nums[mid] > mid) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
};
/*24ms,19.5MB*/
时间复杂度:O(logn)
空间复杂度:O(1)
175.A,B,C三个随机bool值如何判断A为true并且B或C有一个为true
1.
return (a&&b) || (b&&c) || (a&&c);
2.
int count = 0;
if(a) count++;
if(b) count++;
if(c) count++;
return count >= 2;
3. 卡诺图
return a?(b||c):(b&&c);
4.
return a==b?a:c;
5. 异或(与4的条件相反)
return a^b?c:a;
6.
return (a?1:0)+(b?1:0)+(c?1:0) >= 2;
7. 与或
return (a&b) | (b&c) | (a&c);
8. (3的变种)
return (a&&(b||c)) || (b&&c);176.PHP编写一个Log日志类按需加载避免多次初始化
使用单例模式
<?php
//设置时区
ini_set('date.timezone','Asia/Shanghai');
//以下为日志
interface ILogHandler
{
public function write($msg);
}
class CLogFileHandler implements ILogHandler
{
private $handle = null;
public function __construct($file = '')
{
$this->handle = fopen($file,'a');
}
public function write($msg)
{
fwrite($this->handle, $msg, 4096);
}
public function __destruct()
{
fclose($this->handle);
}
}
class Log
{
private $handler = null;
private $level = 15;
private static $instance = null;
private function __construct(){}
private function __clone(){}
public static function Init($handler = null,$level = 15)
{
if(!self::$instance instanceof self)
{
self::$instance = new self();
self::$instance->__setHandle($handler);
self::$instance->__setLevel($level);
}
return self::$instance;
}
private function __setHandle($handler){
$this->handler = $handler;
}
private function __setLevel($level)
{
$this->level = $level;
}
public static function DEBUG($msg)
{
self::$instance->write(1, $msg);
}
public static function WARN($msg)
{
self::$instance->write(4, $msg);
}
public static function ERROR($msg)
{
$debugInfo = debug_backtrace();
$stack = "[";
foreach($debugInfo as $key => $val){
if(array_key_exists("file", $val)){
$stack .= ",file:" . $val["file"];
}
if(array_key_exists("line", $val)){
$stack .= ",line:" . $val["line"];
}
if(array_key_exists("function", $val)){
$stack .= ",function:" . $val["function"];
}
}
$stack .= "]";
self::$instance->write(8, $stack . $msg);
}
public static function INFO($msg)
{
self::$instance->write(2, $msg);
}
private function getLevelStr($level)
{
switch ($level)
{
case 1:
return 'debug';
break;
case 2:
return 'info';
break;
case 4:
return 'warn';
break;
case 8:
return 'error';
break;
default:
}
}
protected function write($level,$msg)
{
if(($level & $this->level) == $level )
{
$msg = '['.date('Y-m-d H:i:s').']['.$this->getLevelStr($level).'] '.$msg."\n";
$this->handler->write($msg);
}
}
}177.mysql默认隔离级别是什么
可重复读https://www.cnblogs.com/shoshana-kong/p/10516404.html
178.php中@符号的作用是什么
不显示错误信息(加在变量前)
179.$a=null; $b=false; var_dump(isset($a)); var_dump(isset($b)); var_dump(empty($a)); var_dump(empty($b));
bool(false) bool(true) bool(true) bool(true)
180.jquery绑定点击事件的方法,动态加载的元素绑定事件方法
click ,on
181.settimeout和setinterval的区别
这两个函数的区别就在于,setInterval在执行完一次代码之后,经过了那个固定的时间间隔,它还会自动重复执行代码,而setTimeout只执行一次那段代码。
https://segmentfault.com/a/1190000007685252
182.如果你有无穷多的水,一个3公升的提捅,一个5公升的提捅,两只提捅形状上下都不均匀,
问你如何才能准确称出4公升的水?
1.用5升桶满桶,倒入3升桶中,倒满后大桶里剩2升;
2,把3升桶倒空,把那2升倒入3升桶中。
3,用5升桶满桶再向3升里倒,倒入一升就满,大桶里剩下的是4 升
183.linux查看当前http服务的端口号80并杀死进程
1、首先是

2、查看此端口下进程以及进程号
3、我们使用awk命令过滤出第二列,即进程号
4、杀死进程

报错的这一行表示,要杀死的进程PID为3754,但是没有这个PID。
5、查看进程是否已经杀死

此时linux系统中没有这个端口号,并且端口下没有进程。说明进程成功被杀死
184.linux服务器下如何监控error.log错误日志文件
对日志文件中的error进行监控,当日志文件中出现error关键字时,就截取日志(grep -i error 不区分大小写进行搜索"error"关键字,但是会将包含error大小写字符的单词搜索出来),大家可以去看这编 文章
在每天的日志目录下生产的error日志,此日志文件每天都会自动生成,里面有没有error日志内容不一定,日志内容写入不频繁,日志文件比较小。
举例说明:
采用sendemail发送告警邮件,sendemail安装参考:http://www.cnblogs.com/kevingrace/p/5961861.html
185.show database、show processlist、show full processlist三个命令的作用是
show database 语句来查看或显示当前用户权限范围以内的数据库 http://c.biancheng.net/view/2419.html
show processlist 是显示用户正在运行的线程,需要注意的是,除了 root 用户能看到所有正在运行的线程外,其他用户都只能看到自己正在运行的线程,看不到其它用户正在运行的线程。除非单独个这个用户赋予了PROCESS 权限 https://www.cnblogs.com/remember-forget/p/10400496.html
mysql show full processlist 用来查看当前线程处理情况 https://www.cnblogs.com/jifengblog/p/12855434.html
186.多台服务器如何做会话保持
1.nginx中的iphash
2.使用redis来保持会话。
https://blog.csdn.net/li12412414/article/details/81026209
187.spl_autoload_register这个函数的作用是什么
同等于自动加载函数__autoload()
188.PHP中&作用是什么?
变量的引用https://www.cnblogs.com/alsf/p/9621362.html
189.symfony/var-dumper的功能是什么
Symfony VarDumper是旨在替换var_dump的组件。 它执行的功能基本相同,但是以更漂亮的格式为您提供了更多的信息。 这就是您一直想要的var_dump 。
https://www.jianshu.com/p/df5752dc546e
190.dd dump有什么区别
在laravel中dd和dump 都是打印的数据的,但是 dd会终止程序的运行,dump不会。
而且dump打印出来的数据在浏览器上是高亮的哦(很有逼格的~)。
上图为dump打印出来的。

上图为dd打印出来的。
191.现有 student(sid.sname)学生表,course(cid,cname)课程表,sc(sid,cid,score)成绩表
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`sname` varchar(255) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(255) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `sc` (
`scid` int(11) NOT NULL AUTO_INCREMENT,
`sid` int(11) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
`score` float(5,2) DEFAULT NULL,
PRIMARY KEY (`scid`)
) ENGINE=InnoDB AUTO_INCREMENT=29 DEFAULT CHARSET=utf8mb4;
1、查询各科平均戊绩格式如下:cid,cname,avg_score
SELECT AVG(sc.score) as avg_score,sc.cid,course.cname
FROM `sc`
LEFT JOIN course on sc.scid = course.cid
GROUP BY sc.cid2.直询总分前3的学生数据,格式如下:sid,sname,total_score
SELECT SUM(sc.score) as total_score ,sc.sid,student.sname
FROM sc
left JOIN student on sc.sid = student.sid
GROUP BY sc.sid
ORDER BY total_score desc limit 3
3.查询各科前三名学生
select sc.score,sc.cid,sc.sid,course.cname,student.sname from sc
LEFT JOIN course on sc.cid = course.cid
LEFT JOIN student on sc.sid = student.sid
where (
select count(*)
from
sc b
where sc.cid = b.cid
and sc.score < b.score
) < 3
ORDER BY cid,score desc
4.查询各科都及格学生
select distinct sc.sid,student.sname
from sc
LEFT join student on sc.sid = student.sid
where sc.sid not in (select distinct sid from sc where score<=60)
5.各科成绩超过平均分的同学,格式如下:sid,sname,score,cid,cname,avg_score
SELECT
s.sid,
s.sname,
sc.score,
sc.cid,
c.cname,
avg_score
FROM
sc
LEFT JOIN ( SELECT cid, AVG( score ) avg_score FROM sc GROUP BY cid ) tmp ON sc.cid = tmp.cid
LEFT JOIN student s ON s.sid = sc.sid
LEFT join course c on c.cid = sc.cid
WHERE
sc.score > tmp.avg_score
6.各科成绩都超过平均分的同学,格式如下:sid,sname
SELECT
s.sid,
s.sname
FROM
sc
LEFT JOIN ( SELECT cid, AVG( score ) avg_score FROM sc GROUP BY cid ) tmp ON sc.cid = tmp.cid
LEFT JOIN student s ON s.sid = sc.sid
WHERE
sc.score > tmp.avg_score
GROUP BY sc.sid
HAVING COUNT(s.sid) = (select COUNT(*) from course)
7.统计并列出各科成绩、各分数段入数;课程ID,课程名称,[100-90],[89-70],[69-60][ <60]
select
sc.cid,
course.cname,
count(case when sc.score >= 90 then 1 end) as '[100-90]',
count(case when sc.score < 90 and sc.score >=70 then 1 end) as '[89-70]',
count(case when sc.score < 70 and sc.score >=60 then 1 end) as '[69-60]',
count(case when sc.score<60 then 1 end) as '[59-0]'
FROM sc
left JOIN course on sc.cid = course.cid
GROUP BY sc.cid
192.localhost与127.0.01的区别
localhost:不通过网卡传输,不受网络防火墙和网卡相关的限制。
127.0.0.1:通过网卡传输,依赖网卡,并受到网卡和防火墙相关的限制。
https://www.cnblogs.com/xuwendong/p/7575179.html
193.mysql的执行步骤是怎样的
•连接器: 身份认证和权限相关(登录 MySQL 的时候)。
•查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
•分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
•优化器: 按照 MySQL 认为最优的方案去执行。
•执行器: 执行语句,然后从存储引擎返回数据。
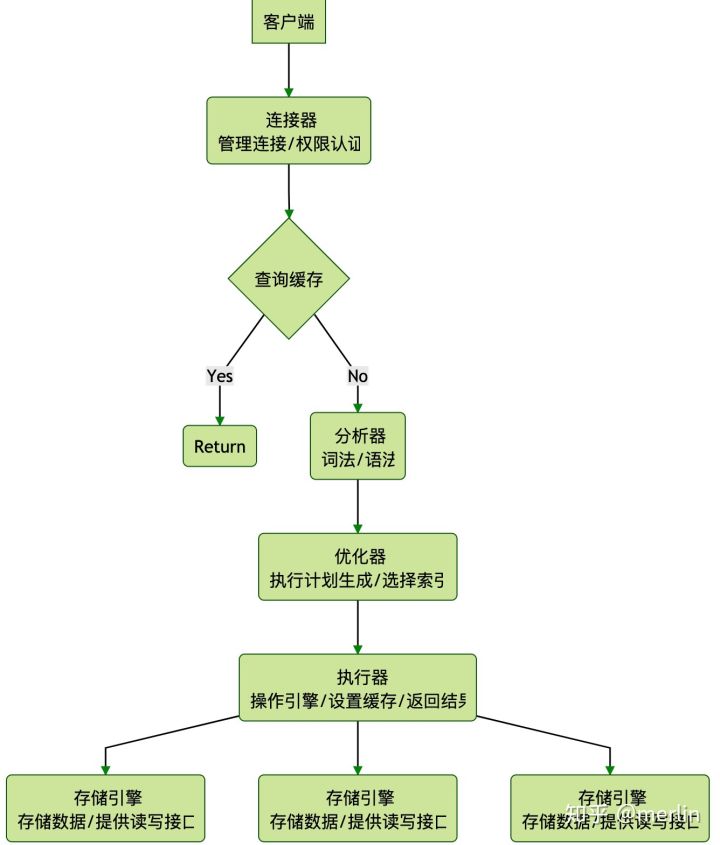
https://zhuanlan.zhihu.com/p/266042021
194.php现有两组排好序的数组,如何以高效率判断两组中重复数字,请写出代码
public function findTheSameItems($arr1,$arr2)
{
$size1 = count($arr1);
$size2 = count($arr2);
$i = $j = 0;
$re = [];
while(true)
{//移动值较小的
if($arr1[$i] > $arr2[$j])
$j++;
elseif($arr1[$i] < $arr2[$j])
$i++;
else
{
array_push($re,$arr1[$i]);
$j++;
}
if($i == $size1 || $j == $size2)
break;
}
return $re;
}
195.TCP/IP协议 四层模型是哪四个?TCP四次挥手过程具体描述?
-
应用层:应用程序间沟通的层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
-
传输层:在此层中,它提供了节点间的数据传送,应用程序之间的通信服务,主要功能是数据格式化、数据确认和丢失重传等。如传输控制协议(TCP)、用户数据报协议(UDP)等,TCP和UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
-
互连网络层:负责提供基本的数据封包传送功能,让每一块数据包都能够到达目的主机(但不检查是否被正确接收),如网际协议(IP)。
-
网络接口层(主机-网络层):接收IP数据报并进行传输,从网络上接收物理帧,抽取IP数据报转交给下一层,对实际的网络媒体的管理,定义如何使用实际网络(如Ethernet、Serial Line等)来传送数据。
描述四次挥手就是:
1.A与B交谈结束之后,A要结束此次会话,对B说:我要关闭连接了(seq=u,FIN=1)。(第一次挥手,A进入FIN-WAIT-1)
2.B收到A的消息后说:确认,你要关闭连接了。(seq=v,ack=u+1,ACK=1)(第二次挥手,B进入CLOSE-WAIT)
3.A收到B的确认后,等了一段时间,因为B可能还有话要对他说。(此时A进入FIN-WAIT-2)
4.B说完了他要说的话(只是可能还有话说)之后,对A说,我要关闭连接了。(seq=w, ack=u+1,FIN=1,ACK=1)(第三次挥手)
5.A收到B要结束连接的消息后说:已收到你要关闭连接的消息。(seq=u+1,ack=w+1,ACK=1)(第四次挥手,然后A进入CLOSED)
6.B收到A的确认后,也进入CLOSED。
https://blog.csdn.net/qq_35216516/article/details/80554575
196.ab压测使用及参数释义
ab命令解析
ab -n 100 -c 10 https://csdn.net/
-n总共请求次数
-c每次请求并发量
Server Software: openresty
Server Hostname: csdn.net
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Server Temp Key: ECDH P-256 256 bits
TLS Server Name: csdn.net
Document Path: /
Document Length: 182 bytes
Concurrency Level: 10
Time taken for tests: 1.348 seconds
Complete requests: 100
Failed requests: 0
Non-2xx responses: 100
Total transferred: 37000 bytes
HTML transferred: 18200 bytes
Requests per second: 74.17 [#/sec] (mean)
Time per request: 134.823 [ms] (mean)
Time per request: 13.482 [ms] (mean, across all concurrent requests)
Transfer rate: 26.80 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 39 94 18.4 95 128
Processing: 6 25 20.7 13 85
Waiting: 6 20 15.4 11 69
Total: 92 119 21.4 116 202
Percentage of the requests served within a certain time (ms)
50% 116
66% 119
75% 127
80% 129
90% 148
95% 181
98% 183
99% 202
100% 202 (longest request)
Concurrency Level: 10 并发数
Time taken for tests: 1.348 seconds (压力测试消耗的总时间)
Requests per second: 74.17 [#/sec] (mean) 平均每秒请求数
Time per request: 13.482 [ms] (mean, across all concurrent requests) 单个用户请求一次的平均时间
197.PHP性能优化
1.优化点:多使用PHP内置变量、常量、函数
2.优化点:尽可能少用魔法函数
3.优化点:少用产生额外开销的错误抑制符@
4.优化点:合理使用内存
5.优化点:尽量少的使用正则表达式 (正则表达式的回溯开销比较大)
6.优化点:减少计算密集型业务
7.优化点:务必使用带引号字符串做键值(PHP会将没有引号的键值当做常量,产生查找常量的开销)
https://blog.csdn.net/ligupeng7929/article/details/87883956
198.mysql 性能调优
1. 选择合适的存储引擎: InnoDB
除非你的数据表使用来做仅仅读或者全文检索 (相信如今提到全文检索,没人会用 MYSQL 了)。你应该默认选择 InnoDB 。
你自己在測试的时候可能会发现 MyISAM 比 InnoDB 速度快。这是由于: MyISAM 仅仅缓存索引,而 InnoDB 缓存数据和索引,MyISAM 不支持事务。可是 假设你使用 innodb_flush_log_at_trx_commit = 2 能够获得接近的读取性能 (相差百倍) 。
1.1 怎样将现有的 MyISAM 数据库转换为 InnoDB:
mysql -u [USER_NAME] -p -e "SHOW TABLES IN [DATABASE_NAME];" | tail -n +2 | xargs -I '{}' echo "ALTER TABLE {} ENGINE=InnoDB;" > alter_table.sql
perl -p -i -e 's/(search_[a-z_]+ ENGINE=)InnoDB//1MyISAM/g' alter_table.sql
mysql -u [USER_NAME] -p [DATABASE_NAME] < alter_table.sql1.2 为每一个表分别创建 InnoDB FILE:
innodb_file_per_table=1这样能够保证 ibdata1 文件不会过大。失去控制。尤其是在运行 mysqlcheck -o –all-databases 的时候。
2. 保证从内存中读取数据。讲数据保存在内存中
2.1 足够大的 innodb_buffer_pool_size
推荐将数据全然保存在 innodb_buffer_pool_size ,即按存储量规划 innodb_buffer_pool_size 的容量。这样你能够全然从内存中读取数据。最大限度降低磁盘操作。
2.1.1 怎样确定 innodb_buffer_pool_size 足够大。数据是从内存读取而不是硬盘?
方法 1
mysql> SHOW GLOBAL STATUS LIKE 'innodb_buffer_pool_pages_%';
+----------------------------------+--------+
| Variable_name | Value |
+----------------------------------+--------+
| Innodb_buffer_pool_pages_data | 129037 |
| Innodb_buffer_pool_pages_dirty | 362 |
| Innodb_buffer_pool_pages_flushed | 9998 |
| Innodb_buffer_pool_pages_free | 0 | !!!!!!!!
| Innodb_buffer_pool_pages_misc | 2035 |
| Innodb_buffer_pool_pages_total | 131072 |
+----------------------------------+--------+
6 rows in set (0.00 sec)发现 Innodb_buffer_pool_pages_free 为 0,则说明 buffer pool 已经被用光,须要增大 innodb_buffer_pool_size
InnoDB 的其它几个參数:
innodb_additional_mem_pool_size = 1/200 of buffer_pool
innodb_max_dirty_pages_pct 80%方法 2
或者用iostat -d -x -k 1 命令,查看硬盘的操作。
2.1.2 server上是否有足够内存用来规划
运行 echo 1 > /proc/sys/vm/drop_caches 清除操作系统的文件缓存。能够看到真正的内存使用量。
2.2 数据预热
默认情况,仅仅有某条数据被读取一次,才会缓存在 innodb_buffer_pool。所以,数据库刚刚启动,须要进行数据预热,将磁盘上的全部数据缓存到内存中。
数据预热能够提高读取速度。
对于 InnoDB 数据库,能够用下面方法,进行数据预热:
1. 将下面脚本保存为 MakeSelectQueriesToLoad.sql
SELECT DISTINCT
CONCAT('SELECT ',ndxcollist,' FROM ',db,'.',tb,
' ORDER BY ',ndxcollist,';') SelectQueryToLoadCache
FROM
(
SELECT
engine,table_schema db,table_name tb,
index_name,GROUP_CONCAT(column_name ORDER BY seq_in_index) ndxcollist
FROM
(
SELECT
B.engine,A.table_schema,A.table_name,
A.index_name,A.column_name,A.seq_in_index
FROM
information_schema.statistics A INNER JOIN
(
SELECT engine,table_schema,table_name
FROM information_schema.tables WHERE
engine='InnoDB'
) B USING (table_schema,table_name)
WHERE B.table_schema NOT IN ('information_schema','mysql')
ORDER BY table_schema,table_name,index_name,seq_in_index
) A
GROUP BY table_schema,table_name,index_name
) AA
ORDER BY db,tb
;2. 运行
mysql -uroot -AN < /root/MakeSelectQueriesToLoad.sql > /root/SelectQueriesToLoad.sql3. 每次重新启动数据库,或者整库备份前须要预热的时候运行:
mysql -uroot < /root/SelectQueriesToLoad.sql > /dev/null 2>&12.3 不要让数据存到 SWAP 中
假设是专用 MYSQL server。能够禁用 SWAP,假设是共享server,确定 innodb_buffer_pool_size 足够大。或者使用固定的内存空间做缓存,使用 memlock 指令。
3. 定期优化重建数据库
mysqlcheck -o –all-databases 会让 ibdata1 不断增大。真正的优化仅仅有重建数据表结构:
CREATE TABLE mydb.mytablenew LIKE mydb.mytable;
INSERT INTO mydb.mytablenew SELECT * FROM mydb.mytable;
ALTER TABLE mydb.mytable RENAME mydb.mytablezap;
ALTER TABLE mydb.mytablenew RENAME mydb.mytable;
DROP TABLE mydb.mytablezap;4. 降低磁盘写入操作
4.1 使用足够大的写入缓存 innodb_log_file_size
可是须要注意假设用 1G 的 innodb_log_file_size 。假如server当机。须要 10 分钟来恢复。
推荐 innodb_log_file_size 设置为 0.25 * innodb_buffer_pool_size
4.2 innodb_flush_log_at_trx_commit
这个选项和写磁盘操作密切相关:
innodb_flush_log_at_trx_commit = 1 则每次改动写入磁盘
innodb_flush_log_at_trx_commit = 0/2 每秒写入磁盘假设你的应用不涉及非常高的安全性 (金融系统),或者基础架构足够安全,或者 事务都非常小,都能够用 0 或者 2 来减少磁盘操作。
4.3 避免双写入缓冲
innodb_flush_method=O_DIRECT5. 提高磁盘读写速度
RAID0 尤其是在使用 EC2 这样的虚拟磁盘 (EBS) 的时候,使用软 RAID0 很重要。
6. 充分使用索引
6.1 查看现有表结构和索引
SHOW CREATE TABLE db1.tb1/G6.2 加入必要的索引
索引是提高查询速度的唯一方法。比方搜索引擎用的倒排索引是一样的原理。
索引的加入须要依据查询来确定。比方通过慢查询日志或者查询日志,或者通过 EXPLAIN 命令分析查询。
ADD UNIQUE INDEX
ADD INDEX6.2.1 比方,优化用户验证表:
加入索引
ALTER TABLE users ADD UNIQUE INDEX username_ndx (username);
ALTER TABLE users ADD UNIQUE INDEX username_password_ndx (username,password);每次重新启动server进行数据预热
echo “select username,password from users;” > /var/lib/mysql/upcache.sql加入启动脚本到 my.cnf
[mysqld]
init-file=/var/lib/mysql/upcache.sql6.2.2 使用自己主动加索引的框架或者自己主动拆分表结构的框架
比方。Rails 这种框架。会自己主动加入索引。Drupal 这种框架会自己主动拆分表结构。
会在你开发的初期指明正确的方向。所以,经验不太丰富的人一開始就追求从 0 開始构建,实际是不好的做法。
7. 分析查询日志和慢查询日志
记录全部查询。这在用 ORM 系统或者生成查询语句的系统非常实用。
log=/var/log/mysql.log注意不要在生产环境用。否则会占满你的磁盘空间。
记录运行时间超过 1 秒的查询:
long_query_time=1
log-slow-queries=/var/log/mysql/log-slow-queries.log8. 激进的方法。使用内存磁盘
如今基础设施的可靠性已经非常高了,比方 EC2 差点儿不用操心server硬件当机。并且内存实在是廉价。非常easy买到几十G内存的server,能够用内存磁盘。定期备份到磁盘。
将 MYSQL 文件夹迁移到 4G 的内存磁盘
mkdir -p /mnt/ramdisk
sudo mount -t tmpfs -o size=4000M tmpfs /mnt/ramdisk/
mv /var/lib/mysql /mnt/ramdisk/mysql
ln -s /tmp/ramdisk/mysql /var/lib/mysql
chown mysql:mysql mysql9. 用 NOSQL 的方式使用 MYSQL
B-TREE 仍然是最高效的索引之中的一个,全部 MYSQL 仍然不会过时。
用 HandlerSocket 跳过 MYSQL 的 SQL 解析层。MYSQL 就真正变成了 NOSQL。
10. 其它
- 单条查询最后添加 LIMIT 1,停止全表扫描。
- 将非”索引”数据分离,比方将大篇文章分离存储,不影响其它自己主动查询。
- 不用 MYSQL 内置的函数。由于内置函数不会建立查询缓存。
- PHP 的建立连接速度很快,全部能够不用连接池。否则可能会造成超过连接数。当然不用连接池 PHP 程序也可能将
- 连接数占满比方用了 @ignore_user_abort(TRUE);
- 使用 IP 而不是域名做数据库路径。避免 DNS 解析问题
199.PHP计算最大公约数
思路
-
使用递归求最大公约数
最大公约数的递归:
1、若a可以整除b,则最大公约数是b
2、如果步骤1不成立,最大公约数便是b与a%b的最大公约数
示例:求(140,21)
140%21 = 14
21%14 = 7
14%7 = 0
返回7
实现
-
最大公约数
/**
* 求最大公约数 Greatest Common Divisor(GCD)
* @param $a
* @param $b
* @return mixed
*/
function gcd($a, $b)
{
// 防止因除数为0而崩溃
if ($a == 0 || $b == 0) {
return 1;
}
if ($a % $b == 0) {
return $b;
}
return gcd($b, $a % $b);
}
200.负载均衡方式有那些
理解负载均衡,必须先搞清楚正向代理和反向代理。
注:
- 正向代理,代理的是用户。
- 反向代理,代理的是服务器
什么是负载均衡
当一台服务器的单位时间内的访问量越大时,服务器压力就越大,大到超过自身承受能力时,服务器就会崩溃。为了避免服务器崩溃,让用户有更好的体验,我们通过负载均衡的方式来分担服务器压力。
我们可以建立很多很多服务器,组成一个服务器集群,当用户访问网站时,先访问一个中间服务器,在让这个中间服务器在服务器集群中选择一个压力较小的服务器,然后将该访问请求引入该服务器。如此以来,用户的每次访问,都会保证服务器集群中的每个服务器压力趋于平衡,分担了服务器压力,避免了服务器崩溃的情况。
负载均衡是用反向代理的原理实现的。
1、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
}2、weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的
情况。
upstream backserver {
server 192.168.0.14 weight=3;
server 192.168.0.15 weight=7;
}权重越高,在被访问的概率越大,如上例,分别是30%,70%。
3、上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。
我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}4、fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
upstream backserver {
server server1;
server server2;
fair;
}5、url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}123456每个设备的状态设置为:
-
down 表示单前的server暂时不参与负载
-
weight 默认为1.weight越大,负载的权重就越大。
max_fails:允许请求失败的次数默认为1.当超过最大次数时,返回proxy_next_upstream模块定义的错误fail_timeout:max_fails次失败后,暂停的时间。-
backup: 其它所有的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
配置实例:
#user nobody;
worker_processes 4;
events {
# 最大并发数
worker_connections 1024;
}
http{
# 待选服务器列表
upstream myproject{
# ip_hash指令,将同一用户引入同一服务器。
ip_hash;
server 125.219.42.4 fail_timeout=60s;
server 172.31.2.183;
}
server{
# 监听端口
listen 80;
# 根目录下
location / {
# 选择哪个服务器列表
proxy_pass http://myproject;
}
}201.linux 中存在一日志文件非常大,打开速度很慢,如何查找其中部分指定内容
sed -n '几行,到几行' file文件名https://www.cnblogs.com/chuanzhang053/p/10232773.html
202.php判断给定的整数是否是2的幂_判断一个整数是不是2的整数次幂
第一种方法利用循环
bool MakeDecision(const int& M,int &pow) //pow表示M是2的多少次幂
{
int i=2;
int s=1;
pow=0;
if(M<0) return false;
if(M==0) return true;
do
{
s*=i;
pow++;
}while(sif(s==M) return true;
else
{
pow=0;
return false;
}
}
第二种方法,如果M/2是2的整数次幂,那么M就是2的整数次幂,递归实现
bool MakeDecision(int M,int *pow)
{
if(M<0) return false;
if(M%2!=0) return false;
if(M==0) return true;
else if(M==2)
{
*pow=*pow+1;
return true;
}
else
{
*pow=*pow+1;
MakeDecision(M/2,pow);
}
}203.什么是Redis高可用
全年时间里,99%的时间里都能对外提供服务,就是高可用https://www.cnblogs.com/mengchunchen/p/10044840.html
204.Redis淘汰策略有那些
- noeviction: 不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息。 大多数写命令都会导致占用更多的内存(有极少数会例外, 如 DEL )。
- allkeys-lru: 所有key通用; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- volatile-lru: 只限于设置了 expire 的部分; 优先删除最近最少使用(less recently used ,LRU) 的 key。
- allkeys-random: 所有key通用; 随机删除一部分 key。
- volatile-random: 只限于设置了 expire 的部分; 随机删除一部分 key。
- volatile-ttl: 只限于设置了 expire 的部分; 优先删除剩余时间(time to live,TTL) 短的key。
205.什么是静态延迟绑定
延迟静态绑定指的是在父类中获取子类的最终状态(父类可以使用子类重载的静态方法)
https://blog.csdn.net/whd526/article/details/70243328
206.Laravel的依赖注入实现原理
原理主要运用了 PHP 反射 api 的 ReflectionMethod 类,在 PHP 运行状态中,扩展分析 PHP 程序
https://learnku.com/laravel/t/843/laravel-dependency-injection-principle
207.Redis String 的底层实现方式有那些
字符串对象底层数据结构实现为 简单动态字符串(SDS) 和 直接存储
208.Redis 的持久化了解么?请简单介绍一下
Redis 持久化有两种, RDB 和 AOF
RDB 做全量持久化(Redis 默认的持久化方式)。按照一定的时间周期策略把内存的数据以快照的形式保存到硬盘的二进制文件。对应产生的数据文件为 dump.rdb,通过配置文件中的 save 参数来定义快照的周期。( 快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。)
AOF 做增量持久化:Redis 会将每一个收到的写命令都通过 Write 函数追加到文件最后,类似于 MySQL 的 binlog。必要时,可以通过重新执行文件中保存的写命令来在内存中重建整个 redis 数据库。
Redis 本身的机制是:当 AOF 持久化开启且存在 AOF 文件时,优先加载 AOF 文件。当 AOF 持久化关闭或不存在 AOF 文件时,加载 RDB 文件。加载 AOF/RDB 文件成功之后,Redis 启动成功。如果 AOF/RDB 文件存在错误,则 Redis 启动失败并打印错误信息
209.了解 Pipeline 吗?请简单介绍一下
可以将多条命令一起打包发送至 redis 处理,处理完成后,将处理结果按照顺序打包,一起返回。好处是可以减少 I/O 次数,提升 redis 吞吐量。不过有两点需要注意:一个 pipeline 中的命令互相之间不能有因果关系。另外,一个 pipeline 中的命令不宜过多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞。可以将大量命令的拆分多个小的 pipeline 命令完成。
210.使用过 Redis 分布式锁吗?怎么实现,那如果在执行 setnx 之后,执行 expire 之前进程意外 crash 或者要重启维护了,会怎么样?
先使用 setnx 争抢锁,抢到之后使用 expire 给锁加一个过期时间,防止忘记释放锁
如果这样的话,这个锁就永远得不到释放了!此时你可以作思考状(思考时间别太长,可能会让面试官误以为你不知道怎么处理,建议 3s 左右为宜),说道: set 命令后面可以跟参数,实现加锁和设置过期时间两个操作,保证操作原子性。(命令:SET key value EX second NX )
211.使用过 redis 做异步队列么?讲解一下实现方式
一般使用 list 结构做队列, lpush 生产消息, rpop 消费消息,当 rpop 没有消息的时候,适当的 sleep 一会儿再重试
可不可以不用 sleep 呢?
可以,使用 list 结构中的阻塞指令,如 brpop 。在列表没有元素时,会阻塞列表直到等待超时或发现可弹出元素为止。
再再追问,如果我想生产一次,消费多次呢?
可以使用 pub/sub 发布订阅模式 ,实现 1:N 的消息队列
再再再追问,pub /sub 模式有什么缺点?
在消费者下线的情况下,生产的消息会丢失。可以使用专业的消息队列保证消息不丢失,如 rocketMQ、rabbitMQ 等
再再再再追问,Redis 如何实现延时队列?
使用 sortedset,用时间戳作为 score,消息内容作为 key,生产者调用 zadd 生产消息,消费者用 zrangebyscore 指令获取 N 秒之前的消息,轮询进行处理
212.Redis 事务了解吗,如果事务中有某条 / 某些命令执行失败了会怎么样呢?
事务中的某条命令执行失败了,事务中的其他指令依然会继续执行。另外,Redis 事务不支持 roolback
213.假如 Redis 里面有 1 亿个 key,其中有 10w 个 key 是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。
如果这个 redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?
这个时候你要回答 redis 关键的一个特性:redis 是单线程的。 roolback keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令, scan 指令可以无阻塞的提取出指定模式的 key 列表,但是 key 可能会有一定的重复,在客户端做一次去重就可以了。 scan 整体所花费的时间会比用 keys 指令长。
214.使用过 Redis 集群吗,集群的高可用怎么保证,集群的原理是什么?
Redis Sentinal(哨兵)着眼于高可用,在 master 宕机时会自动将 slave 提升为 master,继续提供服务。
Redis Cluster(集群)着眼于扩展性,在单个 redis 内存不足时,使用 Cluster 进行分片存储。
215.说说 Redis 集群的数据分片
Redis 集群没有使用一致性 hash, 而是引入了 哈希槽的概念。Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
216.什么是LRU 算法
[内存管理] 的一种页面置换算法,对于在内存中但又不用的 [数据块](内存块)叫做 LRU,操作系统会根据哪些数据属于 LRU 而将其移出内存而腾出空间来加载另外的数据,常用于页面置换算法,是为虚拟页式存储管理服务的。
设计原则
如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
实现 LRU
1. 用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为 0 并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为 0。当数组空间已满时,将时间戳最大的数据项淘汰。
2. 利用一个链表来实现,每次新插入数据的时候将新数据插到链表的头部;每次缓存命中(即数据被访问),则将数据移到链表头部;那么当链表满的时候,就将链表尾部的数据丢弃。
3. 利用链表和 hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回 - 1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
对于第一种方法,需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是 O (n)。对于第二种方法,链表在定位数据的时候时间复杂度为 O (n)。所以在一般使用第三种方式来是实现 LRU 算法。
217.什么事覆盖索引
- 所谓覆盖索引,是指被查询的列,数据能从索引中取得,而不用通过行定位符再到数据表上获取,能够极大的提高性能。
218.大量数据的分页如何解决
直接用 limit start, count 分页语句
当起始页较小时,查询没有性能问题,随着起始记录的增加,时间也随着增大
发现
1.limit 语句的查询时间与起始记录的位置成正比
2.mysql 的 limit 语句是很方便,但是对记录很多的表并不适合直接使用
对 limit 分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外 Mysql 中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
id 字段是主键,自然就包含了默认的主键索引。
覆盖索引
如果一个索引包含 (或覆盖) 所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
覆盖索引优点
1.索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。
2.因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。
3.一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
4.innodb的聚簇索引,覆盖索引对innodb表特别有用。
覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以 mysql 只能用 B-tree 索引做覆盖索引。
例子
select id from product limit 866613, 20
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id219.百万级的数据的导出如何解决
一。对于数据超过了 65535 行的问题,很自然的就会想到将整个数据分块,利用 excel 的多 sheet 页的功能,将超出 65535 行后的数据写入到下一个 sheet 页中,即通过多 sheet 页的方式,突破了最高 65535 行数据的限定,具体做法就是,单独做一个链接,使用 JSP 导出,在 JSP 上通过程序判断报表行数,超过 65535 行后分 SHEET 写入。这样这个问题就得以解决了
二。在这种大数据量的报表生成和导出中,要占用大量的内存,尤其是在使用 TOMCAT 的情况下,JVM 最高只能支持到 2G 内存,则会发生内存溢出的情况。此时的内存开销主要是两部分,一部分是该报表生成时的开销,另一部分是该报表生成后写入一个 EXCEL 时的开销。由于 JVM 的 GC 机制是不能强制回收的,因此,对于此种情形,我们要改变一种方式:
将该报表设置起始行和结束行参数,在 API 生成报表的过程中,分步计算报表,比如一张 20 万行数据的报表,在生成过程中,可通过起始行和结束行分 4-5 次进行。这样,就降低了报表生成时的内存占用,在后面报表生成的过程中,如果发现内存不够,即可自动启动 JVM 的 GC 机制,回收前面报表的缓存
导出 EXCEL 的过程,放在每段生成报表之后立即进行,改多个 SHEET 页为多个 EXCEL,即在分步生成报表的同时分步生成 EXCEL,则通过 POI 包生成 EXCEL 的内存消耗也得以降低。通过
多次生成,同样可以在后面 EXCEL 生成所需要的内存不足时,有效回收前面生成 EXCEL 时占用的内存
再使用文件操作,对每个客户端的导出请求在服务器端根据 SESSIONID 和登陆时间生成唯一的临时目录,用来放置所生成的多个 EXCEL,然后调用系统控制台,打包多个 EXCEL 为 RAR
或者 JAR 方式,最终反馈给用户一个 RAR 包或者 JAR 包,响应客户请求后,再次调用控制台删除该临时目录。
通过分段运算和生成,有效降低了报表从生成结果到生成 EXCEL 的内存开销。其次是通过使用压缩包,响应给用户的生成文件体积大大缩小,降低了多用户并
发访问时服务器下载文件的负担,有效减少多个用户导出下载时服务器端的流量,从而达到进一步减轻服务器负载的效果
220.cgi ,fastcgi,php-fpm 区别
cgi
CGI 的英文是(COMMON GATEWAY INTERFACE)公共网关接口,它的作用就是帮助服务器与语言通信,这里就是 nginx 和 php 进行通信,因为 nginx 和 php 的语言不通,因此需要一个沟通转换的过程,而 CGI 就是这个沟通的协议。
nginx 服务器在接受到浏览器传递过来的数据后,如果请求的是静态的页面或者图片等无需动态处理的则会直接根据请求的 url 找到其位置然后返回给浏览器,这里无需 php 参与,但是如果是一个动态的页面请求,这个时候 nginx 就必须与 php 通信,这个时候就会需要用到 cgi 协议,将请求数据转换成 php 能理解的信息,然后 php 根据这些信息返回的信息也要通过 cgi 协议转换成 nginx 可以理解的信息,最后 nginx 接到这些信息再返回给浏览器。
fast-cgi
传统的 cgi 协议在每次连接请求时,会开启一个进程进行处理,处理完毕会关闭该进程,因此下次连接,又要再次开启一个进程进行处理,因此有多少个连接就有多少个 cgi 进程,这也就是为什么传统的 cgi 会显得缓慢的原因,因此过多的进程会消耗资源和内存。
而 fast-cgi 每次处理完请求后,不会 kill 掉这个进程,而是保留这个进程,使这个进程可以一次处理多个请求。这样每次就不用重新 fork 一个进程了,大大提高效率。
php-cgi
php-cgi 是 php 提供给 web serve 也就是 http 前端服务器的 cgi 协议接口程序,当每次接到 http 前端服务器的请求都会开启一个 php-cgi 进程进行处理,而且开启的 php-cgi 的过程中会先要重载配置,数据结构以及初始化运行环境,如果更新了 php 配置,那么就需要重启 php-cgi 才能生效,例如 phpstudy 就是这种情况。
php-fpm
php-fpm 是 php 提供给 web serve 也就是 http 前端服务器的 fastcgi 协议接口程序,它不会像 php-cgi 一样每次连接都会重新开启一个进程,处理完请求又关闭这个进程,而是允许一个进程对多个连接进行处理,而不会立即关闭这个进程,而是会接着处理下一个连接。它可以说是 php-cgi 的一个管理程序,是对 php-cgi 的改进。
php-fpm 会开启多个 php-cgi 程序,并且 php-fpm 常驻内存,每次 web serve 服务器发送连接过来的时候,php-fpm 将连接信息分配给下面其中的一个子程序 php-cgi 进行处理,处理完毕这个 php-cgi 并不会关闭,而是继续等待下一个连接,这也是 fast-cgi 加速的原理,但是由于 php-fpm 是多进程的,而一个 php-cgi 基本消耗 7-25M 内存,因此如果连接过多就会导致内存消耗过大,引发一些问题,例如 nginx 里的 502 错误。
同时 php-fpm 还附带一些其他的功能:
例如平滑过渡配置更改,普通的 php-cgi 在每次更改配置后,需要重新启动才能初始化新的配置,而 php-fpm 是不需要,php-fpm 分将新的连接发送给新的子程序 php-cgi,这个时候加载的是新的配置,而原先正在运行的 php-cgi 还是使用的原先的配置,等到这个连接后下一次连接的时候会使用新的配置初始化,这就是平滑过渡。
参考链接:https://blog.csdn.net/belen_xue/article/details/65950658
221.PHP5 跟 php7 的区别
PHP7.0 号称是性能提升上革命性的一个版本。面对 Facebook 家的 HHVM 引擎带来的压力,开发团队重写了底层的 Zend Engine,名为 Zend Engine 2。
底层内核解析
PHP7 中最重要的改变就是 zval 不再单独从堆上分配内存并且不自己存储引用计数。需要使用 zval 指针的复杂类型(比如字符串、数组和对象)会自己存储引用计数。这样就可以有更少的内存分配操作、更少的间接指针使用以及更少的内存分配。在 PHP7 中的 zval, 已经变成了一个值指针,它要么保存着原始值,要么保存着指向一个保存原始值的指针。也就是说现在的 zval 相当于 PHP5 的时候的 zval * . 只不过相比于 zval * , 直接存储 zval, 我们可以省掉一次指针解引用,从而提高缓存友好性.
参考链接:www.jb51.net/article/76732.htm
PHP7 为什么比 PHP5 性能提升了
1、变量存储字节减小,减少内存占用,提升变量操作速度
2、改善数组结构,数组元素和 hash 映射表被分配在同一块内存里,降低了内存占用、提升了 cpu 缓存命中率
3、改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率
安全
函数修改
preg_replace () 不再支持 /e 修饰符,,同时官方给了我们一个新的函数 preg_replace_callback
create_function () 被废弃,实际上它是通过执行 eval 实现的。
mysql_* 系列全员移除,如果你要在 PHP7 上面用老版本的 mysql_* 系列函数需要你自己去额外装了,官方不在自带,现在官方推荐的是 mysqli 或者 pdo_mysql。
unserialize () 增加一个可选白名单参数,其实就是一个白名单,如果反序列数据里面的类名不在这个白名单内,就会报错。
assert () 默认不在可以执行代码
语法修改
foreach 不再改变内部数组指针
8 进制字符容错率降低,在 php5 版本,如果一个八进制字符如果含有无效数字,该无效数字将被静默删节。在 php7 里面会触发一个解析错误。
十六进制字符串不再被认为是数字
移除了 ASP 和 script PHP 标签
超大浮点数类型转换截断,将浮点数转换为整数的时候,如果浮点数值太大,导致无法以整数表达的情况下, 在 PHP5 的版本中,转换会直接将整数截断,并不会引发错误。 在 PHP7 中,会报错。
参考链接:https://www.freebuf.com/articles/web/197013.html
总体
性能提升:PHP7 比 PHP5.0 性能提升了两倍。
全面一致的 64 位支持。
以前的许多致命错误,现在改成 [抛出异常]。
PHP 7.0 比 PHP5.0 移除了一些老的不在支持的 SAPI([服务器端] 应用编程端口)和扩展。
.PHP 7.0 比 PHP5.0 新增了空接合操作符。
PHP 7.0 比 PHP5.0 新增加了结合比较运算符。
PHP 7.0 比 PHP5.0 新增加了函数的返回类型声明。
PHP 7.0 比 PHP5.0 新增加了标量类型声明。
PHP 7.0 比 PHP5.0 新增加匿名类。
php7卓越性能背后的优化#
- 减少内存分配次数
- 多使用栈内存
- 缓存数组的hash值
- 字符串解析成桉树改为宏展开
- 使用大块连续内存代替小块破碎内存 详细的可以参考鸟哥的PPT:PHP7性能之源
222.执行以下代码,输入结果是
<?php
Class a{
Function __construct(){
Echo “Echo Class a Something”;
}
}
Class b extend a{
Function __construct(){
Echo “Echo Class b Something”;
}
}
$a=new b();
?>A、 echo class a something echo class b something
B、 echo class b something echo class a something
C、 echo class as something
D、 echo class b something
答案:D
223.什么是php 的生命周期
模块初始化阶段 (Module init):即调用每个拓展源码中的的 PHP_MINIT_FUNCTION 中的方法初始化模块,进行一些模块所需变量的申请,内存分配等。
请求初始化阶段 (Request init):即接受到客户端的请求后调用每个拓展的 PHP_RINIT_FUNCTION 中的方法,初始化 PHP 脚本的执行环境。
执行该 PHP 脚本。
请求结束 (Request Shutdown):这时候调用每个拓展的 PHP_RSHUTDOWN_FUNCTION 方法清理请求现场,并且 ZE 开始回收变量和内存
关闭模块 (Module shutdown):Web 服务器退出或者命令行脚本执行完毕退出会调用拓展源码中的 PHP_MSHUTDOWN_FUNCTION 方法
224.什么是laravel 的生命周期
加载项目依赖,注册加载 composer 自动生成的 class loader,也就是加载初始化第三方依赖。
创建应用实例,生成容器 Container,并向容器注册核心组件,是从 bootstrap/app.php 脚本获取 Laravel 应用实例,并且绑定内核服务容器,它是 HTTP 请求的运行环境的不同,将请求发送至相应的内核: HTTP 内核 或 Console 内核。
接收请求并响应,请求被发送到 HTTP 内核或 Console 内核,这取决于进入应用的请求类型。HTTP 内核继承自 Illuminate\Foundation\Http\Kernel 类,该类定义了一个 bootstrappers 数组,这个数组中的类在请求被执行前运行,这些 bootstrappers 配置了错误处理、日志、检测应用环境以及其它在请求被处理前需要执行的任务。HTTP 内核还定义了一系列所有请求在处理前需要经过的 HTTP 中间件,这些中间件处理 HTTP 会话的读写、判断应用是否处于维护模式、验证 CSRF 令牌等等。
发送请求,在 Laravel 基础的服务启动之后,把请求传递给路由了。路由器将会分发请求到路由或控制器,同时运行所有路由指定的中间件。传递给路由是通过 Pipeline(管道)来传递的,在传递给路由之前所有请求都要经过 app\Http\Kernel.php 中的 $middleware 数组,也就是中间件,默认只有一个全局中间件,用来检测你的网站是否暂时关闭。所有请求都要经过,你也可以添加自己的全局中间件。然后遍历所有注册的路由,找到最先符合的第一个路由,经过它的路由中间件,进入到控制器或者闭包函数,执行你的具体逻辑代码,把那些不符合或者恶意的的请求已被 Laravel 隔离在外。
基础组件 - 日志
Laravel 提供了强大的日志服务来记录日志信息到文件、系统错误日志、甚至是 Slack 以便通知整个团队。在日志引擎之下,Laravel 集成了 Monolog 日志库以便提供各种功能强大的日志处理器,从而允许你通过它们来定制自己应用的日志处理。
应用日志系统的所有配置都存放在配置文件 config/logging.php 中,该文件允许你配置应用的日志通道,因此需要查看每个可用通道及其配置项,默认情况下,Laravel 使用 stack 通道来记录日志信息,stack 通道被用于聚合多个日志通道到单个通道
配置通道名称
默认情况下,Monolog 通过与当前环境匹配的「通道名称」实例化,例如 production 或 local,要改变这个值,添加 name 项到通道配置
有效通道驱动列表
stack 用于创建「多通道」通道的聚合器
single 基于单文件 / 路径的日志通道(StreamHandler)
daily 基于 RotatingFileHandler 的 Monolog 驱动,以天为维度对日志进行分隔
slack 基于 SlackWebhookHandler 的 Monolog 驱动
syslog 基于 SyslogHandler 的 Monolog 驱动
errorlog 基于 ErrorLogHandler 的 Monolog 驱动
monolog Monolog 改成驱动,可以使用所有支持的 Monolog 处理器
custom 调用指定改成创建通道的驱动
配置 Single 和 Daily 通道
single 和 daily 通道有三个可选配置项:bubble、permission 和 locking。
bubble 表示消息在被处理后是否冒泡到其它通道 ,默认为 true
permission 日志文件权限,默认为 644
locking 在日志文件写入前尝试锁定它,默认为 false
配置 Slack 通道
slack 通道需要一个 url 配置项,这个 URL 需要和你配置的 Slack 团队 [请求 URL] 相匹配。
构建日志堆栈
stack 驱动允许你将多个通道合并到单个日志通道,stack 通道通过 channels 项将聚合了其他两个通道:syslog 和 slack。因此,记录日志信息时,这两个通道都有机会记录信息。
参考链接:laravelacademy.org/post/19467.html
225.什么是单页 Web 应用
单页 Web 应用(single page web application,SPA),就是只有一张 Web 页面的应用。单页应用程序 (SPA) 是加载单个 HTML 页面并在用户与应用程序交互时动态更新该页面的 Web 应用程序。^ [1]^ 浏览器一开始会加载必需的 HTML、CSS 和 JavaScript,所有的操作都在这张页面上完成,都由 JavaScript 来控制。因此,对单页应用来说模块化的开发和设计显得相当重要。
226.什么是 vue 生命周期?
Vue 实例从创建到销毁的过程,就是生命周期。从开始创建、初始化数据、编译模板、挂载 Dom→渲染、更新→渲染、销毁等一系列过程,称之为 Vue 的生命周期。
227.Vue 生命周期的作用
它的生命周期中有多个事件钩子,让我们在控制整个 Vue 实例的过程时更容易形成好的逻辑。
228.Vue 生命周期的过程
它可以总共分为 8 个阶段:创建前 / 后,载入前 / 后,更新前 / 后,销毁前 / 销毁后。
beforeCreate(创建前) 在数据观测和初始化事件还未开始
created(创建后) 完成数据观测,属性和方法的运算,初始化事件,$el 属性还没有显示出来
beforeMount(载入前) 在挂载开始之前被调用,相关的 render 函数首次被调用。实例已完成以下的配置:编译模板,把 data 里面的数据和模板生成 html。注意此时还没有挂载 html 到页面上。
mounted(载入后) 在 el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用。实例已完成以下的配置:用上面编译好的 html 内容替换 el 属性指向的 DOM 对象。完成模板中的 html 渲染到 html 页面中。此过程中进行 ajax 交互。
beforeUpdate(更新前) 在数据更新之前调用,发生在虚拟 DOM 重新渲染和打补丁之前。可以在该钩子中进一步地更改状态,不会触发附加的重渲染过程。
updated(更新后) 在由于数据更改导致的虚拟 DOM 重新渲染和打补丁之后调用。调用时,组件 DOM 已经更新,所以可以执行依赖于 DOM 的操作。然而在大多数情况下,应该避免在此期间更改状态,因为这可能会导致更新无限循环。该钩子在服务器端渲染期间不被调用。
beforeDestroy(销毁前) 在实例销毁之前调用。实例仍然完全可用。
destroyed(销毁后) 在实例销毁之后调用。调用后,所有的事件监听器会被移除,所有的子实例也会被销毁。该钩子在服务器端渲染期间不被调用。
. 第一次页面加载会触发哪几个钩子?
会触发 下面这几个 beforeCreate, created, beforeMount, mounted 。
DOM 渲染在 哪个周期中就已经完成?
DOM 渲染在 mounted 中就已经完成了。
229.Vue 三种常用传值方式
父组件向子组件传值
使用 props 建立数据通道的渠道
在子组件中通过 props 传递过来的数据
子组件向父组件传值
子组件中需要一个点击事件触发一个自定义事件
在父组件中的子标签监听该自定义事件得到传递的值
非父子组件传值
1 他们之间有一个共同的容器,假设 A 和 B 之间传值,我们可以用 localstoage 和 SessionStorage 把 A 的数据传给共同的容器,然后 B 从这个容器中再把 A 的数据取出来。
2. 可以先定义一个 bus 的空对象,首先 A 通过‘emit 发送数据到 bus 这个空对象中,然后 B 通过 emit 发送数据到 bus 这个空对象中,然后 B 通过 on 来接收这个空对象的数据。
3.vuex 集中管理的方式传值也是和上面一样的办法,只是在数据较多且复杂的情况下才用,具体操作都是通过一个中间人来传递数据。
230.Vuex 是什么
Vuex 是一个专门为 Vue.js 应用程序开发的状态管理模式,它采用集中式存储管理所有组件的公共状态,并以相应的规则保证状态以一种可预测的方式发生变化.
231.执行以下代码,输出结果是
<?php
Abstract class a{
Function __construct(){
Echo “a”;
}
}
$a=new a();
?>A、 a
B、 一个错误警告
C、 一个致命性的报错
答案:C
232.为什么有的项目选择rabbitmq
Rabbit mq 是一个高级消息队列,在分布式的场景下,拥有高性能。,对负载均衡也有很好的支持。
拥有持久化的机制,进程消息,队列中的信息也可以保存下来。
实现消费者和生产者之间的解耦。
对于高并发场景下,利用消息队列可以使得同步访问变为串行访问达到一定量的限流,利于数据库的操作。
可以使用消息队列达到异步下单的效果,排队中,后台进行逻辑下单。
AMQP,即 Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在
rabbitMQ 的优点(适用范围)
基于 erlang 语言开发具有高可用高并发的优点,适合集群服务器。
健壮、稳定、易用、跨平台、支持多种语言、文档齐全。
有消息确认机制和持久化机制,可靠性高。
开源
使用场景
跨系统的异步通信,所有需要异步交互的地方都可以使用消息队列。就像我们除了打电话(同步)以外,还需要发短信,发电子邮件(异步)的通讯方式。
多个应用之间的耦合,由于消息是平台无关和语言无关的,而且语义上也不再是函数调用,因此更适合作为多个应用之间的松耦合的接口。基于消息队列的耦合,不需要发送方和接收方同时在线。在企业应用集成(EAI)中,文件传输,共享数据库,消息队列,远程过程调用都可以作为集成的方法。
应用内的同步变异步,比如订单处理,就可以由前端应用将订单信息放到队列,后端应用从队列里依次获得消息处理,高峰时的大量订单可以积压在队列里慢慢处理掉。由于同步通常意味着阻塞,而大量线程的阻塞会降低计算机的性能。
消息驱动的架构(EDA),系统分解为消息队列,和消息制造者和消息消费者,一个处理流程可以根据需要拆成多个阶段(Stage),阶段之间用队列连接起来,前一个阶段处理的结果放入队列,后一个阶段从队列中获取消息继续处理。
应用需要更灵活的耦合方式,如发布订阅,比如可以指定路由规则。
跨局域网,甚至跨城市的通讯(CDN 行业),比如北京机房与广州机房的应用程序的通信。
rabbitmq 三个主要角色
生产者:消息的创建者,负责创建和推送数据到消息服务器;
消费者:消息的接收方,用于处理数据和确认消息;
代理:就是 RabbitMQ 本身,用于扮演 “快递” 的角色,本身不生产消息,只是扮演 “快递” 的角色。
消息发送流程
首先客户端必须连接到 RabbitMQ 服务器才能发布和消费消息,客户端和 rabbit server 之间会创建一个 tcp 连接,一旦 tcp 打开并通过了认证(认证就是你发送给 rabbit 服务器的用户名和密码),你的客户端和 RabbitMQ 就创建了一条 amqp 信道(channel),信道是创建在 “真实” tcp 上的虚拟连接,amqp 命令都是通过信道发送出去的,每个信道都会有一个唯一的 id,不论是发布消息,订阅队列都是通过这个信道完成的。
生产者通过网络将消息发送给消费者,在中间会有一个应用 RabbitMQ (转发和存储的功能),这时 RabbitMQ 收到消息后,根据消息指定的 exchange (交换机) 来查找绑定然后根据规则分发到不同的 Queue(队列),queue 将消息转发到具体的消费者。
消费者收到消息后,会根据自己对消息的处理对 RabbitMQ 进行返回,如果返回 ack,就表示已经确认这条消息,RabbitMQ 会对这条消息进行处理(一般是删除)。
如果消费者接收到消息后处理不了,就可能不对 RabbitMQ 进行处理,或者拒绝对消息处理,返回 reject。
ACK 消息确认机制
ACK 消息确认机制,保证数据能被正确处理而不仅仅是被 Consumer (接收端) 收到,我们就不能采用 no-ack 或者 auto-ack,我们需要手动 ack (manual-ack)。在数据处理完成后手动发送 ack,这个时候 Server 才将 Message 删除。
ACK 机制可以起到限流的作用,比如在消费者处理后,sleep 一段时间,然后再 ACK,这可以帮助消费者负载均衡。
当然,除了 ACK,有两个比较重要的参数也在控制着 consumer (接收端) 的 load-balance,即 prefetch 和 concurrency
Broker (消息队列服务器实体)
接收和分发消息的应用,RabbitMQ Server 就是 Message Broker。
Virtual host (虚拟消息服务器)
出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当多个不同的用户使用同一个 RabbitMQ server 提供的服务时,可以划分出多个 vhost,每个用户在自己的 vhost 创建 exchange/queue 等
Connection (TCP 连接)
publisher (发送端)/consumer (接收端) 和 broker (消息队列服务器实体) 之间的 TCP 连接。断开连接的操作只会在 client 端进行,Broker (消息队列服务器实体) 不会断开连接,除非出现网络故障或 broker (消息队列服务器实体) 服务出现问题。
Channel (connection 内部建立的逻辑连接)
如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection 的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个 thread 创建单独的 channel 进行通讯,AMQP method 包含了 channel id 帮助客户端和 message broker 识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的 Connection 极大减少了操作系统建立 TCP connection 的开销。
Exchange (交换机)
message 到达 broker (消息队列服务器实体) 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到 queue 中去。
Queue (队列)
消息最终被送到这里等待 consumer (接收端) 取走。一个 message 可以被同时拷贝到多个 queue 中。
Binding (交换机和队列之间的虚拟连接)
exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key。Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据。
发送 / 接收信息
Send.py (发送信息)
权限验证
链接参数: virtual_host, 在多租户系统中隔离 exchange, queue
建立链接
从链接中获得信道
声明交换机
consumer (接收端) 创建队列,如果没有就创建
队列一旦被创建,再进行的重复创建会简单的失效,所以建议在 producer (发送端) 和 consumer 同时创建队列,避免队列创建失败
创建队列回调函数,callback.
auto_delete=True, 如果 queue 失去了最后一个 subscriber 会自动删除,队列中的 message 也会失效.
默认 auto_delete=False, 没有 subscriber 的队列会 cache message, subscriber 出现后将缓存的 message 发送.
delivery_mode=2 表示让消息持久化,重启 RabbitMQ 也不丢失。考虑成本,开启此功能,建议把消息存储到 SSD 上.
发布消息到 exchange
关闭链接
receive.py (接收信息)
权限验证
链接参数: virtual_host, 在多租户系统中隔离 exchange, queue
建立链接
从链接中获得信道
声明交换机,直连方式,后面将会创建 binding 将 exchange 和 queue 绑定在一起
consumer (接收端) 创建队列,如果没有就创建
队列一旦被创建,再进行的重复创建会简单的失效,所以建议在 producer (发送端) 和 consumer (接收端) 同时创建队列,避免队列创建失败
创建队列回调函数,callback.
auto_delete=True, 如果 queue 失去了最后一个 subscriber 会自动删除,队列中的 message 也会失效.
默认 auto_delete=False, 没有 subscriber 的队列会 cache message, subscriber 出现后将缓存的 message 发送.
通过 binding 将队列 queue 和交换机 exchange 绑定
处理接收到的消息的回调函数,method_frame 携带了投递标记,header_frame 表示 AMQP 信息头的对象
订阅队列,我们设置了不进行 ACK, 而把 ACK 交给了回调函数来完成
关闭连接
233.rabbitmq 持久化有什么缺点
持久化的缺地就是降低了服务器的吞吐量,因为使用的是磁盘而非内存存储,从而降低了吞吐量。可尽量使用 ssd 硬盘来缓解吞吐量的问题。
234.电商中优惠券功能如何设计
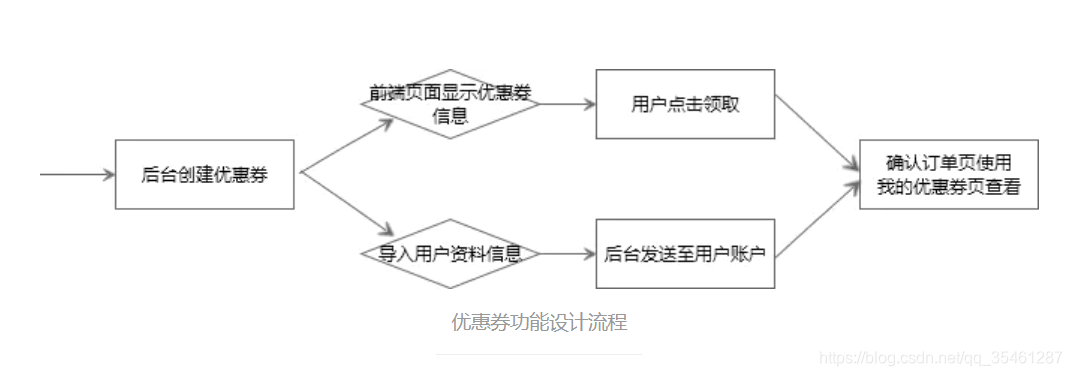
https://www.jianshu.com/p/269a54846a9c
https://blog.csdn.net/HUXU981598436/article/details/78048919
https://blog.csdn.net/t_332741160/article/details/86591243优惠券表设计
https://blog.csdn.net/egworkspace/article/details/80414953
235.php 实现重定向的三种方式
1.header()函数;
header('location:http://www.baidu.com');
2. meta标签
echo '<meta http-equiv="refresh" content="1;url=http://www.baidu.com">';
3.script标签;
echo '<script>window.location.href="http://www.baidu.com"</script>';236.JS中布尔值为 false 的情况
JS:
1、undefined(未定义,找不到值时出现)
2、null(代表空值)
3、false(布尔值的false,字符串"false"布尔值为true)
4、0(数字0,字符串"0"布尔值为true)
5、NaN(无法计算结果时出现,表示"非数值";但是tapeof NaN==="number")
6、""(双引号)或''(单引号) (空字符串,中间有空格时也是true)
原文:https://blog.csdn.net/Lisunlight/article/details/82733939
237.PHP 中布尔值为 false 的情况
1、null(代表空值)为false
2、false(布尔值的false,字符串"false"布尔值为true)
3、0(数字0,字符串"0"布尔值都为false)
4、""(双引号)或''(单引号)为false (中间有空格时是true)
238.Protobuf,json,xml之间的区别?
1、json: 一般的web项目中,最流行的主要还是json。因为浏览器对于json数据支持非常好,有很多内建的函数支持。
2、xml: 在webservice中应用最为广泛,但是相比于json,它的数据更加冗余,因为需要成对的闭合标签。json使用了键值对的方式,不仅压缩了一定的数据空间,同时也具有可读性。
3、protobuf:是后起之秀,是谷歌开源的一种数据格式,适合高性能,对响应速度有要求的数据传输场景。因为profobuf是二进制数据格式,需要编码和解码。数据本身不具有可读性。因此只能反序列化之后得到真正可读的数据。
相对于其它protobuf更具有优势
1:序列化后体积相比Json和XML很小,适合网络传输
2:支持跨平台多语言
3:消息格式升级和兼容性还不错
4:序列化反序列化速度很快,快于Json的处理速速
239.Protobuf 中packed的编码含义
packed = true 主要使让 ProtoBuf 为我们把 repeated primitive 的编码结果打包,从而进一步压缩空间,进一步提高效率、速度。这里打包的含义其实就是:原先的 repeated 字段的编码结构为 Tag-Length-Value-Tag-Length-Value-Tag-Length-Value...,因为这些 Tag 都是相同的(同一字段),因此可以将这些字段的 Value 打包,即将编码结构变为 Tag-Length-Value-Value-Value...
https://www.jianshu.com/p/73c9ed3a4877
240.简述什么是orm
ORM(Object-relational mapping),即对象关系映射,是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。也就是说,ORM是通过使用描述对象和数据库之间映射的元数据(映射文件信息),将程序中的对象自动持久化到关系数据库中
https://www.cnblogs.com/MirZhai/p/9252817.html
241.PHP是单继承还是多继承
单继承,PHP是不支持多继承的,那么如何实现多继承呢?
可以使用interface或trait 实现
252.parse_str() 函数作用
定义和用法
parse_str() 函数把查询字符串解析到变量中。
注释
如果未设置 array 参数,由该函数设置的变量将覆盖已存在的同名变量。
php.ini 文件中的 magic_quotes_gpc 设置影响该函数的输出。如果已启用,那么在 parse_str() 解析之前,变量会被 addslashes() 转换。
语法
parse_str(string,array)- string
-
- 必需。
- 规定要解析的字符串。
- array
-
- 可选。
- 规定存储变量的数组名称。
- 该参数指示变量存储到数组中。
实例
把查询字符串解析到变量中:
<?php
parse_str("name=Peter&age=43");
echo $name."<br>";
echo $age;
?>
存储变量到一个数组中:
<?php
parse_str("name=Peter&age=43",$myArray);
print_r($myArray);
?>253.left join right join inner join,full join区别
left join,在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
right join,在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
inner join(内连接),在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
full join,在两张表进行连接查询时,返回左表和右表中所有没有匹配的行
254.mysql中索引失效的原因是?
1、对单字段建了索引,where条件多字段。
例:建了以下索引:
查询语句:
select * from template t where t.logicdb_id = 4 and t.sync_status = 1
2、建立联合索引,where条件单字段。与上面情况正好相反。
例:建了以下索引:
查询语句:
select * from template t where t.sync_status = 4
3、对索引列运算,运算包括(+、-、*、/、!、<>、%、like'%_'(%放在前面)、or、in、exist等),导致索引失效。
4、类型错误,如字段类型为varchar,where条件用number。
例:template_id字段是varchar类型。
错误写法:select * from template t where t.template_id = 1
正确写法:select * from template t where t.template_id = '1'
5、对索引应用内部函数,这种情况下应该建立基于函数的索引。
例:
select * from template t where ROUND(t.logicdb_id) = 1
此时应该建ROUND(t.logicdb_id)为索引。
6、查询表的效率要比应用索引查询快的时候。
7、is null 索引失效;is not null Betree索引生效。导致的原因,个人认为应该是,mysql没有在null写进索引。还要看应用的数据库而定。
255.B 树 平衡二叉树 有什么区别?为什么不用 平衡二叉树 实现索引呢
平衡二叉树是一种左右树高度 ≤ 1 的二叉树,B 树是多叉树。由于 B 树每个节点可以存多个元素,所以相同数据量情况下,B 树的树高往往要 小于 二叉树的树高,数据检索的速度更快
注:数据检索总是从根节点开始,树的高度 = 磁盘 I/O 的次数
256.索引下推是什么?
索引下推是数据库检索数据过程中为减少回表次数而做的优化
257.解释一下脏读、不可重复读、幻读
脏读 是指一个事务读取到另一个事务修改后还没有 COMMIT 的数据;不可重复读 是指一个事务多次读取同一数据,在多次读取之间有另外的事务对这一数据进行修改并 COMMIT,导致多次读取同一数据的结果不一致;幻读 和不可重复读类似,区别在于不可重复读的重点是修改,幻读的重点在于新增或者删除
258.laravel 路由隐式绑定的原理
Laravel 会自动处理在路由或控制器方法中,与类型提示的变量名相匹配的路由段名称的的 Eloquent 模型。
259.实现删除一个数组里面的重复值
array_flip();
<?php
$a1=array("a"=>"red","b"=>"green","c"=>"blue","d"=>"yellow");
$result=array_flip($a1);
print_r($result);
?>
260.js中实现删除一个数组里面的重复值
function unique3(array){
var n = [array[0]];//结果数组
//从第二项开始遍历
for(var i = 1; i<array.length; i++){
//如果当前数组的第i项在当前数组中第一次出现的位置不是i;
//那么表示第i项是重复的,忽略掉。否则存入结果数组。
if(array.indexOf(array[i]) == i){
n.push(array[i]);
}
}
return n;}261.bin.log 日志是什么
记录数据库变化操作的二进制日志文件 记录了所有的数据库变化操作(数据增删改,创建表等) 在数据丢失的紧急情况下,我们往往会想到用binlog日志功能进行数据恢复
262.聚簇索引和非聚簇索引的区别?
聚簇索引: 聚簇索引是顺序结构与数据存储物理结构一致的一种索引,并且一个表的聚簇索引只能有唯一的一条;
说明:
平时习惯逛图书馆的童鞋可能比较清楚,如果你要去图书馆借一本书,最开始是去电脑里面查书名然后根据书名来定位藏书在那个区,哪个书柜,哪一行,第多少本。。。清晰明确,一目了然,因为藏书的结构与图书室的位置,书架的顺序,书本的摆放顺序与书籍的编号都是从大到小一致的顺序摆放的,所以很容易找到。比如,你的目标藏书在C区2柜3排5仓,那么你走到B区你就很快知道前面就快到了C区了,你直接奔着2柜区就能找到了。 这就是雷同于聚簇索引的功效了,聚簇索引,实际存储的循序结构与数据存储的物理机构是一致的,所以通常来说物理顺序结构只有一种,那么一个表的聚簇索引也只能有一个,通常默认都是主键,设置了主键,系统默认就为你加上了聚簇索引,当然有人说我不想拿主键作为聚簇索引,我需要用其他字段作为索引,当然这也是可以的,这就需要你在设置主键之前自己手动的先添加上唯一的聚簇索引,然后再设置主键,这样就木有问题啦。
非聚簇索引: 非聚簇索引记录的物理顺序与逻辑顺序没有必然的联系,与数据的存储物理结构没有关系;一个表对应的 非聚簇索引可以有多条,根据不同列的约束可以建立不同要求的非聚簇索引;
说明:
同样的,如果你去的不是图书馆,而是某城市的商业性质的图书城,那么你想找的书就摆放比较随意了,由于商业图书城空间比较紧正,藏书通常按照藏书上架的先后顺序来摆放的,所以如果查询到某书籍放在C区2柜3排5仓,但你可能要绕过F区,而不是A.B.C.D...连贯一致的,也可能同在C区的2柜,书柜上第一排是计算机类的书记,也可能最后一排就是医学类书籍;
263.mysql 分区有哪几种
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
264.InnoDB 共享表空间和独立表空间的优缺点
优点:
共享表空间:
可以放表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以 分布在不同步的文件上)。数据和文件放在一起方便管理
独立表空间:
1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通 过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会 处理.
缺点:
共享表空间:
所有的数据和索引存放到一个文件中意味着将有一个很常大的文件,虽然可以把一个大文件分成多 个小文件,但是多个表及索引在表空间中混合存储,这样对于一个表做了大量删除操作后表空间中 将会有大量的空隙,特别是对于统计分析,日值系统这类应用最不适合用共享表空间
独立表空间:
单表增加过大,如超过100个G
相比较之下,使用独占表空间的效率以及性能会更高一点
265.Node.js 的优缺点?
1). 优点
善于 I/O,不善于计算.
处理高并发
服务器推送Copy2). 缺点
单一线程,一旦崩溃,整个服务就挂了.
超人死了,世界都末日了.266.Yii2 的自动加载原理
1、检查类名是否已缓存在$classMap或$_coreClasses数组中,如果是则直接require相应的文件路径,$_coreClasses是框架自有类的映射表;否则去第2步;
2、检测YiiBase::$enableIncludePath是否为false,如果是则去第3步,否则直接include($className . '.php')
3、遍历$includePaths数组,将目录名拼接上类名,检查是否为合法的php文件,如果是则include,然后跳出循环
4、结束。
267.如何设计支付接口
1.接口规则
传输方式 为保证交易安全性,采用HTTPS传输
提交方式 采用POST方法提交
数据格式 提交和返回数据都为XML格式,根节点名为xml
字符编码 统一采用UTF-8字符编码
签名算法 MD5,后续会兼容SHA1、SHA256、HMAC等。
签名要求 请求和接收数据均需要校验签名,详细方法请参考安全规范-签名算法
证书要求 调用申请退款、撤销订单接口需要商户证书
判断逻辑 先判断协议字段返回,再判断业务返回,最后判断交易状态
2.参数规定
1、交易金额
交易金额默认为人民币交易,接口中参数支付金额单位为【分】,参数值不能带小数。对账单中的交易金额单位为【元】。
外币交易的支付金额精确到币种的最小单位,参数值不能带小数点。
2、交易类型
JSAPI--JSAPI支付(或小程序支付)、NATIVE--Native支付、APP--app支付,MWEB--H5支付,不同trade_type决定了调起支付的方式,请根据支付产品正确上传
MICROPAY--付款码支付,付款码支付有单独的支付接口,所以接口不需要上传,该字段在对账单中会出现
3、货币类型
货币类型的取值列表:
CNY:人民币
4、时间
标准北京时间,时区为东八区;如果商户的系统时间为非标准北京时间。参数值必须根据商户系统所在时区先换算成标准北京时间, 例如商户所在地为0时区的伦敦,当地时间为2014年11月11日0时0分0秒,换算成北京时间为2014年11月11日8时0分0秒。
5、时间戳
标准北京时间,时区为东八区,自1970年1月1日 0点0分0秒以来的秒数。注意:部分系统取到的值为毫秒级,需要转换成秒(10位数字)。
6、商户订单号
商户支付的订单号由商户自定义生成,仅支持使用字母、数字、中划线-、下划线_、竖线|、星号*这些英文半角字符的组合,请勿使用汉字或全角等特殊字符。微信支付要求商户订单号保持唯一性(建议根据当前系统时间加随机序列来生成订单号)。重新发起一笔支付要使用原订单号,避免重复支付;已支付过或已调用关单、撤销(请见后文的API列表)的订单号不能重新发起支付。
7、body字段格式
使用场景 支付模式 商品字段规则 样例 备注
PC网站 扫码支付 浏览器打开的网站主页title名 -商品概述 腾讯充值中心-QQ会员充值
微信浏览器 公众号支付 商家名称-销售商品类目 腾讯-游戏 线上电商,商家名称必须为实际销售商品的商家
门店扫码 公众号支付 店名-销售商品类目 小张南山店-超市 线下门店支付
门店扫码 扫码支付 店名-销售商品类目 小张南山店-超市 线下门店支付
门店刷卡 刷卡支付 店名-销售商品类目 小张南山店-超市 线下门店支付
第三方手机浏览器 H5支付 浏览器打开的移动网页的主页title名-商品概述 腾讯充值中心-QQ会员充值
第三方APP APP支付 应用市场上的APP名字-商品概述 天天爱消除-游戏充值
8、银行类型
3.安全规范
1、签名算法
(签名校验工具)
签名生成的通用步骤如下:
第一步,设所有发送或者接收到的数据为集合M,将集合M内非空参数值的参数按照参数名ASCII码从小到大排序(字典序),使用URL键值对的格式(即key1=value1&key2=value2…)拼接成字符串stringA。
特别注意以下重要规则:
◆ 参数名ASCII码从小到大排序(字典序);
◆ 如果参数的值为空不参与签名;
◆ 参数名区分大小写;
◆ 验证调用返回或微信主动通知签名时,传送的sign参数不参与签名,将生成的签名与该sign值作校验。
◆ 微信接口可能增加字段,验证签名时必须支持增加的扩展字段
第二步,在stringA最后拼接上key得到stringSignTemp字符串,并对stringSignTemp进行MD5运算,再将得到的字符串所有字符转换为大写,得到sign值signValue。
◆ key设置路径:微信商户平台(pay.weixin.qq.com)-->账户设置-->API安全-->密钥设置
第一步:对参数按照key=value的格式,并按照参数名ASCII字典序排序如下:
第二步:拼接API密钥:
2、生成随机数算法
微信支付API接口协议中包含字段nonce_str,主要保证签名不可预测。我们推荐生成随机数算法如下:调用随机数函数生成,将得到的值转换为字符串。
3、API证书
(1)获取API证书(什么是api证书?如何升级?)
微信支付接口中,涉及资金回滚的接口会使用到API证书,包括退款、撤销接口。商家在申请微信支付成功后,收到的相应邮件后,可以按照指引下载API证书,也可以按照以下路径下载:微信商户平台(pay.weixin.qq.com)-->账户中心-->账户设置-->API安全 。证书文件说明如下:
证书附件 描述 使用场景 备注
pkcs12格式
(apiclient_cert.p12、 包含了私钥信息的证书文件,为p12(pfx)格式,由微信支付签发给您用来标识和界定您的身份 撤销、退款申请API中调用 windows上可以直接双击导入系统,导入过程中会提示输入证书密码,证书密码默认为您的商户ID(如:10010000)
以下两个证书在PHP环境中使用:
证书附件 描述 使用场景 备注
证书pem格式
(apiclient_cert.pem) 从apiclient_cert.p12中导出证书部分的文件,为pem格式,请妥善保管不要泄漏和被他人复制 PHP等不能直接使用p12文件,而需要使用pem,为了方便您使用,已为您直接提供 您也可以使用openssl命令来自己导出:openssl pkcs12 -clcerts -nokeys -in apiclient_cert.p12 -out apiclient_cert.pem
证书密钥pem格式
(apiclient_key.pem) 从apiclient_key.pem中导出密钥部分的文件,为pem格式,请妥善保管不要泄漏和被他人复制 PHP等不能直接使用p12文件,而需要使用pem,为了方便您使用,已为您直接提供 您也可以使用openssl命令来自己导出:openssl pkcs12 -nocerts -in apiclient_cert.p12 -out apiclient_key.pem
(2)使用API证书
◆ apiclient_cert.p12是商户证书文件,除PHP外的开发均使用此证书文件。
◆ 商户如果使用.NET环境开发,请确认Framework版本大于2.0,必须在操作系统上双击安装证书apiclient_cert.p12后才能被正常调用。
◆ API证书调用或安装需要使用到密码,该密码的值为微信商户号(mch_id)
(3)API证书安全
1.证书文件不能放在web服务器虚拟目录,应放在有访问权限控制的目录中,防止被他人下载;
2.建议将证书文件名改为复杂且不容易猜测的文件名;
3.商户服务器要做好病毒和木马防护工作,不被非法侵入者窃取证书文件。
4、商户回调API安全
在普通的网络环境下,HTTP请求存在DNS劫持、运营商插入广告、数据被窃取,正常数据被修改等安全风险。商户回调接口使用HTTPS协议可以保证数据传输的安全性。所以微信支付建议商户提供给微信支付的各种回调采用HTTPS协议。
https://pay.weixin.qq.com/wiki/doc/api/app/app.php?chapter=4_2
268.Facades 是什么
Facades(一种设计模式,通常翻译为外观模式)提供了一个”static”(静态)接口去访问注册到 IoC 容器中的类。提供了简单、易记的语法,而无需记住必须手动注入或配置的长长的类名。此外,由于对 PHP 动态方法的独特用法,也使测试起来非常容易。
269.Contract 是什么?
Contract(契约)是 laravel 定义框架提供的核心服务的接口。Contract 和 Facades 并没有本质意义上的区别,其作用就是使接口低耦合、更简单。
270.两个有序int集合是否有相同元素的最优算法
/**
* 寻找两个有序数组里相同的元素
* @param array $arr1
* @param array $arr2
* @return array
*/
function find_common($arr1, $arr2)
{
$common = array();
$i = $j = 0;
$count1 = count($arr1);
$count2 = count($arr2);
while ($i < $count1 && $j < $count2) {
if ($arr1[$i] < $arr2[$j]) {
$i++;
} elseif ($arr1[$i] > $arr2[$j]) {
$j++;
} else {
$common[] = $arr[$i];
$i++;
$j++;
}
}
return array_unique($common);
}271.给一个有数字和字母的字符串,让连着的数字和字母对应
function number_alphabet($str)
{
$number = preg_split('/[a-z]+/', $str, -1, PREG_SPLIT_NO_EMPTY);
$alphabet = preg_split('/\d+/', $str, -1, PREG_SPLIT_NO_EMPTY);
$n = count($number);
for ($i = 0; $i < $count; $i++) {
echo $number[$i] . ':' . $alphabet[$i] . '</br>';
}
}
$str = '1a3bb44a2ac';
number_alphabet($str);//1:a 3:bb 44:a 2:ac272.求n以内的质数(质数的定义:在大于1的自然数中,除了1和它本身意外,无法被其他自然数整除的数
思路: 1.(质数筛选定理)n不能够被不大于根号n的任何质数整除,则n是一个质数
2.除了2的偶数都不是质数
代码如下:
/**
* 求n内的质数
* @param int $n
* @return array
*/
function get_prime($n)
{
$prime = array(2);//2为质数
for ($i = 3; $i <= $n; $i += 2) {//偶数不是质数,步长可以加大
$sqrt = intval(sqrt($i));//求根号n
for ($j = 3; $j <= $sqrt; $j += 2) {//i是奇数,当然不能被偶数整除,步长也可以加大。
if ($i % $j == 0) {
break;
}
}
if ($j > $sqrt) {
array_push($prime, $i);
}
}
return $prime;
}
print_r(getPrime(1000));273.编写一个PHP函数,求任意n个正负整数里面最大的连续和,要求算法时间复杂度尽可能低
动态规划
/**
* 获取最大的连续和
* @param array $arr
* @return int
*/
function max_sum_array($arr)
{
$currSum = 0;
$maxSum = 0;//数组元素全为负的情况,返回最大数
$n = count($arr);
for ($i = 0; $i < $n; $i++) {
if ($currSum >= 0) {
$currSum += $arr[$i];
} else {
$currSum = $arr[$i];
}
}
if ($currSum > $maxSum) {
$maxSum = $currSum;
}
return $maxSum;
}274.Cookie存在哪
- 如果设置了过期时间,Cookie存在硬盘里
- 没有设置过期时间,Cookie存在内存里
275.Linux进程属性
- 进程:是用pid表示,它的数值是唯一的
- 父进程:用ppid表示
- 启动进程的用户:用UID表示
- 启动进程的用户所属的组:用GID表示
- 进程的状态:运行R,就绪W,休眠S,僵尸Z
276.统计某一天网站的访问量
awk '{print $1}' /var/log/access.log | sort | uniq | wc -l推荐篇文章,讲awk实际使用的shell在手分析服务器日志不愁
277.Memcache缓存命中率如何计算
缓存命中率 = get_hits/cmd_get * 100%
278.用php写一个函数,获取一个文本文件最后n行内容,要求尽可能效率高,并可以跨平台使用
function tail($file, $num)
{
$fp = fopen($file,"r");
$pos = -2;
$eof = "";
$head = false; //当总行数小于Num时,判断是否到第一行了
$lines = array();
while ($num > 0) {
while($eof != PHP_EOL){
if (fseek($fp, $pos, SEEK_END) == 0) { //fseek成功返回0,失败返回-1
$eof = fgetc($fp);
$pos--;
} else { //当到达第一行,行首时,设置$pos失败
fseek($fp, 0, SEEK_SET);
$head = true; //到达文件头部,开关打开
break;
}
}
array_unshift($lines, str_replace(PHP_EOL, '', fgets($fp)));
if ($head) {//这一句,只能放上一句后,因为到文件头后,把第一行读取出来再跳出整个循环
break;
}
$eof = "";
$num--;
}
fclose($fp);
return $lines;
} 279.打开php.ini的safe_mode会影响哪些参数
当safe_mode=On时,会出现下面限制:
- 所有输入输出函数(例如fopen()、file()和require())的适用会受到限制,只能用于与调用这些函数的脚本有相同拥有者的文件。例如,假定启用了安全模式,如果Mary拥有的脚本调用fopen(),尝试打开由Jonhn拥有的一个文件,则将失败。但是,如果Mary不仅拥有调用 fopen()的脚本,还拥有fopen()所调用的文件,就会成功。
- 如果试图通过函数popen()、system()或exec()等执行脚本,只有当脚本位于safe_mode_exec_dir配置指令指定的目录才可能。
- HTTP验证得到进一步加强,因为验证脚本用于者的UID划入验证领域范围内。此外,当启用安全模式时,不会设置PHP_AUTH。
- 如果适用MySQL数据库服务器,链接MySQL服务器所用的用户名必须与调用mysql_connect()的文件拥有者用户名相同。
详细的解释可以查看官网:http://www.php.net/manual/zh/ini.sect.safe-mode.php php safe_mode影响参数
| 函数名 | 限制 |
|---|---|
| dbmopen() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| dbase_open() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| filepro() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| filepro_rowcount() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| filepro_retrieve() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| ifx_* sql_safe_mode | 限制, (!= safe mode) |
| ingres_* sql_safe_mode | 限制, (!= safe mode) |
| mysql_* sql_safe_mode | 限制, (!= safe mode) |
| pg_loimport() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| posix_mkfifo() | 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| putenv() | 遵循 ini 设置的 safe_mode_protected_env_vars 和 safe_mode_allowed_env_vars 选项。请参考 putenv() 函数的有关文档。 |
| move_uploaded_file() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| chdir() | 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| dl() | 本函数在安全模式下被禁用。 |
| backtick operator | 本函数在安全模式下被禁用。 |
| shell_exec() | (在功能上和 backticks 函数相同) 本函数在安全模式下被禁用。 |
| exec() | 只能在 safe_mode_exec_dir 设置的目录下进行执行操作。基于某些原因,目前不能在可执行对象的路径中使用 ..。escapeshellcmd() 将被作用于此函数的参数上。 |
| system() | 只能在 safe_mode_exec_dir 设置的目录下进行执行操作。基于某些原因,目前不能在可执行对象的路径中使用 ..。escapeshellcmd() 将被作用于此函数的参数上。 |
| passthru() | 只能在 safe_mode_exec_dir 设置的目录下进行执行操作。基于某些原因,目前不能在可执行对象的路径中使用 ..。escapeshellcmd() 将被作用于此函数的参数上。 |
| popen() | 只能在 safe_mode_exec_dir 设置的目录下进行执行操作。基于某些原因,目前不能在可执行对象的路径中使用 ..。escapeshellcmd() 将被作用于此函数的参数上。 |
| fopen() | 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| mkdir() | 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| rmdir() | 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| rename() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| unlink() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| copy() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 (on source and target ) |
| chgrp() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| chown() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| chmod() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 另外,不能设置 SUID、SGID 和 sticky bits |
| touch() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 |
| symlink() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 (注意:仅测试 target) |
| link() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 (注意:仅测试 target) |
| apache_request_headers() | 在安全模式下,以“authorization”(区分大小写)开头的标头将不会被返回。 |
| header() | 在安全模式下,如果设置了 WWW-Authenticate,当前脚本的 uid 将被添加到该标头的 realm 部分。 |
| PHP_AUTH 变量 | 在安全模式下,变量 PHP_AUTH_USER、PHP_AUTH_PW 和 PHP_AUTH_TYPE 在 $_SERVER 中不可用。但无论如何,您仍然可以使用 REMOTE_USER 来获取用户名称(USER)。(注意:仅 PHP 4.3.0 以后有效) |
| highlight_file(), show_source() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 (注意,仅在 4.2.1 版本后有效) |
| parse_ini_file() | 检查被操作的文件或目录是否与正在执行的脚本有相同的 UID(所有者)。 检查被操作的目录是否与正在执行的脚本有相同的 UID(所有者)。 (注意,仅在 4.2.1 版本后有效) |
| set_time_limit() | 在安全模式下不起作用。 |
| max_execution_time | 在安全模式下不起作用。 |
| mail() | 在安全模式下,第五个参数被屏蔽。 |
280.验证ip是否正确
function check_datetime($datetime)
{
if (date('Y-m-d H:i:s', strtotime($datetime)) === $datetime) {
return true;
} else {
return false;
}
}281.下单后30分钟未支付取消订单
第一种方案:被动过期+cron,就是用户查看的时候去数据库查有没有支付+定时清理。 第二种方案:延迟性任务,到时间检查订单是否支付成功,如果没有支付则取消订单
282.请设计一个实现方式,可以给某个ip找到对应的省和市,要求效率竟可能的高
//ip2long,把所有城市的最小和最大Ip录进去
$redis_key = 'ip';
$redis->zAdd($redis_key, 20, '#bj');//北京的最小IP加#
$resid->zAdd($redis_key, 30, 'bj');//最大IP
function get_ip_city($ip_address)
{
$ip = ip2long($ip_address);
$redis_key = 'ip';
$city = zRangeByScore($redis_key, $ip, '+inf', array('limit' => array(0, 1)));
if ($city) {
if (strpos($city[0], "#") === 0) {
echo '城市不存在!';
} else {
echo '城市是' . $city[0];
}
} else {
echo '城市不存在!';
}
}283.网页/应用访问慢突然变慢,如何定位问题
- top、iostat查看cpu、内存及io占用情况
- 内核、程序参数设置不合理 查看有没有报内核错误,连接数用户打开文件数这些有没有达到上限等等
- 链路本身慢 是否跨运营商、用户上下行带宽不够、dns解析慢、服务器内网广播风暴什么的
- 程序设计不合理 是否程序本身算法设计太差,数据库语句太过复杂或者刚上线了什么功能引起的
- 其它关联的程序引起的 如果要访问数据库,检查一下是否数据库访问慢
- 是否被攻击了 查看服务器是否被DDos了等等
284.如何设计/优化一个访问量比较大的博客/论坛
- 减少http请求(比如使用雪碧图)
- 优化数据库(范式、SQL语句、索引、配置、读写分离)
- 缓存使用(Memcache、Redis)
- 负载均衡
- 动态内容静态化+CDN
- 禁止外部盗链(refer、图片添加水印)
- 控制大文件下载
- 使用集群
285.如何搭建Composer私有库
使用satis搭建
相关文章介绍:使用satis搭建Composer私有库
286.
$a = 0;
while ($a < 5) {
switch($a) {
case 0:
case 3:
$a = $a+2;
case 1:
case 2:
$a = $a+3;
default:
$a = $a+5;
}
}
echo $a;
上述代码的输出结果 10
为避免错误,理解 switch 是怎样执行的非常重要。switch 语句一行接一行地执行(实际上是语句接语句)。开始时没有代码被执行。仅当一个 case 语句中的值和 switch 表达式的值匹配时 PHP 才开始执行语句,直到 switch 的程序段结束或者遇到第一个 break 语句为止。如果不在 case 的语句段最后写上 break 的话,PHP 将继续执行下一个 case 中的语句段.
- 第一次走到
case 3:然后$a = 2 - 第二次走到
case 2:此时$a=5 - 最后到
default此时$a = 10跳出循环
286.XSS,CSRF,SSRF区别和共同点
相同点:
XSS,CSRF,SSRF三种常见的Web服务端漏洞均是由于,服务器端对用户提供的可控数据过于信任或者过滤不严导致的。
不同点:
XSS是服务器对用户输入的数据没有进行足够的过滤,导致客户端浏览器在渲染服务器返回的html页面时,出现了预期值之外的 脚本语句被执行。
CSRF是服务器端没有对用户提交的数据进行随机值校验,且对http请求包内的refer字段校验不严,导致攻击者可以 利用用户的Cookie信息伪造用户请求发送至服务器。
SSRF是服务器对 用户提供的可控URL过于信任,没有对攻击者提供的RUL进行地址限制和足够的检测,导致攻击者可以以此为跳板攻击内网或其他服务器。
287.mysql_real_escape_string mysql_escape_string有什么本质的区别,有什么用处,为什么被弃用?
mysql_real_escape_string需要预先连接数据库,并可在第二个参数传入数据库连接(不填则使用上一个连接)
两者都是对数据库插入数据进行转义,但是mysql_real_escape_string转义时,会考虑数据库连接的字符集。
它们的用处都是用来能让数据正常插入到数据库中,并防止sql注入,但是并不能做到100%防止sql注入。
再问:为什么不能100%防止?
答;因为客户端编码以及服务器端编码不同,可能产生注入问题,但是其实这种场景不多见。
继续答:被弃用的原因是官方不再建议使用mysql_xx的数据库操作方式,建议使用pdo和mysqli,因为不管从性能跟安全来看,mysqli都比mysql要好。
衍生出来的问题是mysqli的连接复用(持久化)问题
288.什么是内存泄漏,js内存泄漏是怎么产生的?
内存泄漏是因为一块被分配内存既不能被使用,也不能被回收,直到浏览器进程结束。
产生泄漏的原因是闭包维持函数内局部变量,不能被释放,尤其是使用闭包并存在外部引用还setInterval的时候危害很大。
产生泄漏的原因有好几种:
(1) 页面元素被删除,但是绑定在该元素上的事件未被删除;
(2) 闭包维持函数内局部变量(外部不可控),使其得不到释放;
(3) 意外的全局变量;
(4) 引用被删除,但是引用内的引用,还存在内存中。
从上述原因上看,内存泄漏产生的根本原因是引用无法正确回收,值类型并不能引发内存泄漏。
对于每个引用,都有自己的引用计数,当引用计数归零或被标记清除时,js垃圾回收器会认为该引用可以回收了。
289.什么是原型、原型链、作用域、作用域链、闭包
原型:相当于一个模具,用来生产实例对象。
原型链:原型对象有个指针指向构造函数,实例对象又有一个指针指向原型对象,就形成了一条原型链,最终指向null。
作用域,就是变量或者是函数能作用的范围。
作用率链变量随着作用长辈函数一级一级往上搜索,直到找到为止,找不到就报错,这个过程就是作用域链起的作用。
290.一台电脑配置无限好,可以同时打开多少个网页
65535-1000 = 64535(端口数)
291.数据链路层的数据是怎么校验的,有哪些校验方式
常用的几种数据校验方式有奇偶校验、CRC校验、LRC校验、格雷码校验、和校验、异或校验等。
一、奇偶校验
1. 定义
根据被传输的一组二进制代码中“1”的个数是奇数或偶数来进行校验。
使用:通常专门设置一个奇偶校验位,存放代码中“1”的个数为奇数还是偶数。若用奇校验,则奇偶校验位为奇数,表示数据正确。若用偶校验,则奇偶校验位为偶数,表示数据正确。
2. 应用
eg. 数据位为 10001100 (1) -> 最后一位为校验位
此时若约定好为奇校验,那么数据表示为正确的,若为偶校验,那么数据传输出错了。
二、CRC校验(循环冗余校验码)
1. 定义
CRC校验是数据通信领域中最常用的一种查错校验码,其特征是信息字段和校验字段的长度可以任意选定。循环冗余检查(CRC)是一种数据传输检错功能,对数据进行多项式计算,并将得到的结果附在帧的后面,接收设备也执行类似的算法,以保证数据传输的正确性和完整性。
2. 计算过程:
a> 设置CRC寄存器,并给其赋值FFFF(hex)。
b> 将数据的第一个8-bit字符与16位CRC寄存器的低8位进行异或,并把结果存入CRC寄存器。
c> CRC寄存器向右移一位,MSB补零,移出并检查LSB。
d> 如果LSB为0,重复第三步;若LSB为1,CRC寄存器与多项式码相异或。
e> 重复第3与第4步直到8次移位全部完成。此时一个8-bit数据处理完毕。
f> 重复第2至第5步直到所有数据全部处理完成。
g> 最终CRC寄存器的内容即为CRC值。
常用的CRC循环冗余校验标准多项式如下: CRC(16位) = X16+X15+X2+1 CRC(CCITT) = X16+X12 +X5+1
CRC(32位) = X32+X26+X23+X16+X12+X11+X10+X8+X7+X5+X4+X2+X+1
以CRC(16位)多项式为例,其对应校验二进制位列为1 1000 0000 0000 0101。
3. 应用:在发送端根据要传送的k位二进制码序列,以一定的规则产生一个校验用的r位监督码(CRC码),附在原始信息后边,构成一个新的二进制码序列数共k+r位,然后发送出去。在接收端,根据信息码和CRC码之间所遵循的规则进行检验,以确定传送中是否出错。
三、LRC校验
1. 定义:LRC校验用于ModBus协定的ASCII模式,这各校验比较简单,通讯速率较慢,它在ASCII协议中使用,检测了消息域中除开始的冒号及结束的回车换行号外的内容。它仅仅是把每一个需要传输的数据字节迭加后取反加1即可。
2. 应用
eg. 5个字节:01H+03H+21H+02H+00H+02H = 29H,然后取2的补码=D7H。
四、格雷码校验
1. 定义
格雷码是一种无权码,也是一种循环码。是指任意两组相邻的代码之间只有一位不同,其余为都相同。
如:5的二进制为0101 6的二进制为0110
5的格雷码为0111 6的二进制为0101
五、校验和
1. 定义
校验一组数据项的和是否正确。通常是以十六进制为数制表示的形式。如果校验和的数值超过十六进制的FF,也就是255。
2. 应用
eg. 数据01020304的校验和为a。
六、异或校验
1. 定义
BCC校验其实是奇偶校验的一种,但也是经常使用并且效率较高的一种。所谓BCC校验法,就是在发送前和发送后分别把BCC以前包括ETX字符的所有字符按位异或后,按要求变换(增加或去除一个固定的值)后所得到的字符进行比较。相等即认为通信无错误,不相等则认为通信出错。
七、MD5校验
292.b+树的查询时间复杂度是多少,哈希表是多少,为什么数据库索引用b+树存储,而不是哈希表,数据库索引存储还有其他数据结构吗?
O(log(n)),O(1)
因为哈希表是散列的,在遇到`key`>'12'这种查找条件时,不起作用,并且空间复杂度较高。
备注:b+数根据层数决定时间复杂度,数据量多的情况下一般4-5层,然后用二分法查找页中的数据,时间复杂度远小于log(n)。
293.apache是怎么跟php通讯的,sapi是什么
使用sapi通讯,sapi是php封装的对外数据传递接口,通常有cgi/fastcgi/cli/apache2handler四种运行模式。
294.jquery的sizzle引擎工作原理
一,sizzle的基本原理
sizzle是jquery选择器引擎模块的名称,早在1.3版本就独立出来,并且被许多其他的js库当做默认的选择器引擎。
首先,sizzle最大的特点就是快。那么为什么sizzle当时其他引擎都快了,因为当时其他的引擎都是按照从左到右逐个匹配的方式来进行查找的,而sizzle刚好相反是从右到左找的。
举个简单的例子 “.a .b .c”来说明为什么sizzle比较快。这个例子如果按照从左到右的顺序查找,很明显需要三次遍历过程才能结束,即先在document中查找.a,然后再结果中查找.b,再在.b的结果中查找.c。
采用这种方式,其时间复杂度是 a*b*c,其实也就是时间复杂度 O(n3)。注意这里的O(n3)只算对dom的遍历查找,因为现对于对PO的操作这个是特别耗时。
下面再看看sizzle是怎么做的,sizzle是从右到左查找,也就是直接在页面中查找.c,这时会得到一个候选结果集seed,然后对seed的每一个结果把parents不符合.a .b的结果剔除掉,就是最终结果。这个过程实际上只对dom进行了一次遍历查找,剩下的过滤操作是沿着parent指针直接查找非常快速。可以认为这是一个时间复杂度O(n)的算法。
所以,可以看出只需要遍历查找一次dom的sizzle在理论上是有明显的速度优势的,当然实践检验也证明了这点。
二,sizzle的实现
1,首先调用Sizzle(selector, context)方法
此方法做的事:
1.1 先设置上下文context,然后调用rquickExpr正则式来判断是不是简单的id/class/tag选择器,如果是则直接调用相应的方法就可以得到结果
1.2 如果不是简单的选择器,则查看是否支持qsa(即querySelectorAll)方法,如果支持则调用querySelectorAll方法来取结果
1.3 否则,没有任何捷径,则调用 select(selector, context, results, seed)
2, 调用select(selector, context, results, seed) 方法
2.1 首先调用tokenize(selector)方法把selector分解成单个token
2.2 如果没有种子seed,那么2.3
2.3 如果分解出来的token只有一组,那么根据tokens从右往左查找seed,比如选择器是".a .b .c",那么先找到所有的.c元素存到候选集seed里,以后所要做的就是过滤掉seed中不符合的元素即可
2.4 最后调用 compile(selector, match)(seed, context)剔除seed中不符合条件的元素即可
3, 调用 compile 方法
此方法返回一个函数,这个函数被调用之后:
3.1,对每一个seed中得元素调用matcher逐个过滤,把符合的结果存到results数组中。matcher方法的实现,参见4
4,matcher方法
matcher的作用是,对候选集seed进行过滤,matcher的实现过程就是对一个元素不断向上找parentNode并且判断parentNode是不是满足条件,不满足条件的就返回false。
295.md5逆向原理
先用字典查找,再尝试暴力破解。使用TB级的海量特征库用数据库存起来,然再分片查找。
296.父类方法是protected,子类重构为private,会发生什么?
会发生fatal错误,因为继承的方法或属性只能维持或放大权限,不能缩小,比如protected重载为public是可行的。
297.keep-alive的概念
长连接机制,表示keep-alive-timeout时间内,如果连接没有closed,再次传输数据不再需要三次握手了。
298.mysql线上数据库的大表新增字段如何解决
可使用工具mysql pt-online-schema-change http://blog.itpub.net/22996654/viewspace-2661328/
299.redis中hyperloglog可以解决哪些场景的问题
HyperLogLog 主要的应用场景就是进行基数统计。这个问题的应用场景其实是十分广泛的。例如:对于 Google 主页面而言,同一个账户可能会访问 Google 主页面多次。于是,在诸多的访问流水中,如何计算出 Google 主页面每天被多少个不同的账户访问过就是一个重要的问题。那么对于 Google 这种访问量巨大的网页而言,其实统计出有十亿 的访问量或者十亿零十万的访问量其实是没有太多的区别的,因此,在这种业务场景下,为了节省成本,其实可以只计算出一个大概的值,而没有必要计算出精准的值。
对于上面的场景,可以使用 HashMap 、 BitMap 和 HyperLogLog 来解决。对于这三种解决方案,这边做下对比:
HashMap:算法简单,统计精度高,对于少量数据建议使用,但是对于大量的数据会占用很大内存空间;BitMap:位图算法,具体内容可以参考我的这篇文章,统计精度高,虽然内存占用要比HashMap少,但是对于大量数据还是会占用较大内存;HyperLogLog:存在一定误差,占用内存少,稳定占用 12k 左右内存,可以统计 2^64 个元素,对于上面举例的应用场景,建议使用。
参考
- https://mp.weixin.qq.com/s/AvPoG8ZZM8v9lKLyuSYnHQ
- https://blog.csdn.net/m0_37558251/article/details/105436370
300.有一个100层高的大厦,有一堆材质大小一模一样的石块,从这个大厦的某一层(临界楼层)扔下,石块就会碎,使用哪种算法能最快的得到这个临界楼层?
分段算法
将整个大厦的层数分成x段,在这x段中查找那个临界段,然后在临界段中再一层一层地找临界层。比如可以将大楼分成4段,我们分别在25层、50层、75层投掷棋子,以确定临界段;如果临界段在25层到50层,我们再从26层开始一层一层查找临界层。确定分段数x使棋子投掷的次数最少
由于csdn篇幅不能过长后续文章看 PHP面试题(二)持续更新中.....

优库云是一个致力于分享学习干货、实用工具、优秀博客、面试宝典、互联网资讯技术、新闻观察、热点资讯、京东淘宝好物、优惠活动的平台。不定时推送,关注置顶公众号不错过任何福利!点击加入组织https://mp.weixin.qq.com/s/XHMsZaQYK-PkmudA_JXLSA