本专栏按照 https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html 顺序进行总结 。
文章目录
双延迟深度确定性策略梯度,也就是说TD3是DDPG的一个优化版本。
T D 3 \color{red}TD3 TD3 :[ paper:Addressing Function Approximation Error in Actor-Critic Methods | code ]
原理解析
TD3是DDPG的一个优化版本。主要解决两个问题,一个是overestimation bias,另一个是high variance。主要优化之处在于三点:
背景介绍
什么是overestimation?
有离散动作空间的强化学习中,典型的算法如DQN,值函数往往会被过高估计。这是因为,我们对于Q函数的估计会有误差,在取最大化Q值的时候,会高于真实的最大Q值。由于过高的估计偏差,这种累积的错误会导致任意的坏状态被估计为高值,从而导致次优的策略更新和发散的行为。
算法介绍
1. overestimation in actor-critic
double network
DDPG起源于DQN,是DQN解决连续控制问题的一个解决方法。而DQN有一个众所周知的问题,就是Q值会被高估。这是因为我们用argmaxQ(s’)去代替V(s’),去评估Q(s)。当我们每一步都这样做的时候,很容易就会出现高估Q值的情况。
而这个问题也会出现在DDPG中。而要解决这个问题的思路,也在DQN的优化版本中。相信大家很快就明白,就是double DQN。
在TD3中,我们可以用了两套网络估算Q值,相对较小的那个作为我们更新的目标。这就是TD3的基本思路。
但要注意,DDPG算法涉及了4个网络,所以TD3需要用到6个网络。所以在实做得时候是比较容易出错的。所以我们有必要理清楚之间的关系。
我们先看看DDPG中的网络架构:
关注上图中,我们通过Critic网络估算动作的A值。一个Critic的评估可能会较高。所以我们加一个。
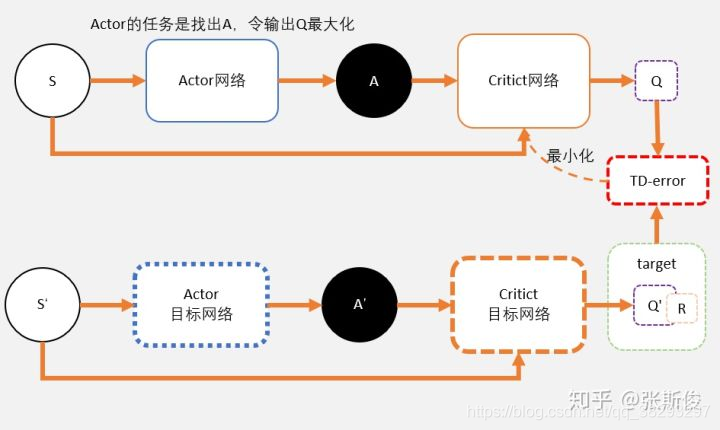
这就相当于我们把途中的Critic的框框,一个变为两个。
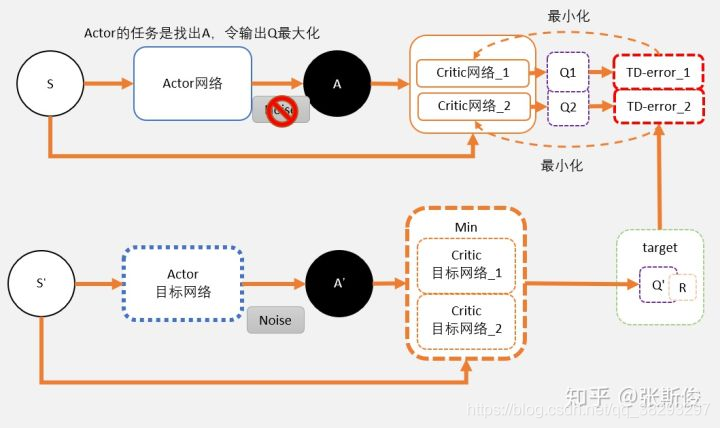
-
在目标网络中,我们估算出来的Q值会用min()函数求出较少值。以这个值作为更新的目标。
(因为更新较慢,这两个网络可能比较相近难以做出独立判断,所以采用两个网络中较小的去更新避免过估计。) -
这个目标会更新两个网络 Critic网络_1 和 Critic网络_2。
-
你可以理解为这两个网络是完全独立,他们只是都用同一个目标进行更新。
-
剩余的就和DDPG一样了。过一段时间,把学习好的网络赋值给目标网络。
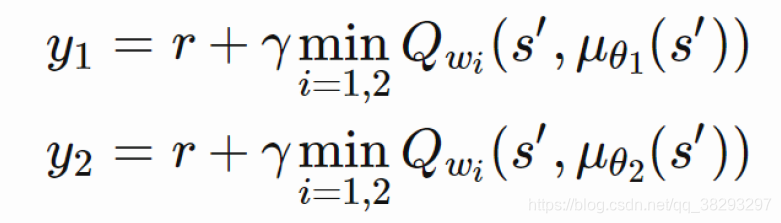
我们再仔细分别看Critic部分和Actor部分的学习。
Critic部分的学习
只有我们在计算Critic的更新目标时,我们才用target network。其中就包括了一个Policy network,用于计算 A ′ A' A′;两个Q network ,用于计算两个Q值: Q 1 ( A ′ ) Q_1(A') Q1(A′) 和 Q 2 ( A ′ ) Q_2(A') Q2(A′)。
Q 1 ( A ′ ) Q_1(A') Q1(A′) 和 Q 2 ( A ′ ) Q_2(A') Q2(A′) 取最小值 m i n ( Q 1 , Q 2 ) min(Q_1,Q_2) min(Q1,Q2) 将代替DDPG的 Q ( a ′ ) Q(a') Q(a′) 计算更新目标,也就是说: t a r g e t = m i n ( Q 1 , Q 2 ) ∗ γ + r target = min(Q_1,Q_2) * \gamma + r target=min(Q1,Q2)∗γ+r
target 将会是 Q_network_1 和 Q_network_2 两个网络的更新目标。
这里可能会有同学问,既然更新目标是一样的,那么为什么还需要两个网络呢?
虽然更新目标一样,两个网络会越来越趋近与和实际 q q q 值相同。但由于网络参数的初始值不一样,会导致计算出来的值有所不同。所以我们可以有空间选择较小的值去估算 q q q 值,避免 q q q 值被高估。
Actor部分的学习
我们在DDPG中说过,DDPG网络图像上就可以想象成一张布,覆盖在qtable上。当我们输入某个状态的时候,相当于这块布上的一个截面,我们我们能够看到在这个状态下的一条曲线。
而actor的任务,就是用梯度上升的方法,寻着这条线的最高点。
对于actor来说,其实并不在乎Q值是否会被高估,他的任务只是不断做梯度上升,寻找这条最大的Q值。随着更新的进行Q1和Q2两个网络,将会变得越来越像。所以用Q1还是Q2,还是两者都用,对于actor的问题不大。
2. Delayed update of Target and Policy Networks
为避免policy在value function训练不够好时,互相影响。那样policy会通过过估计来达到收敛,所以TD3用delayed的机制,让policy慢于Q 网络更新
详细说一下:
这里说的Dalayed ,是actor更新的delay。也就是说相对于critic可以更新多次后,actor再进行更新。
为什么要这样做呢?
还是回到我们qnet拟合出来的那块"布"上。
qnet在学习过程中,我们的q值是不断变化的,也就是说这块布是不断变形的。所以要寻着最高点的任务有时候就挺难为为的actor了。
可以想象,本来是最高点的,当actor好不容易去到最高点;q值更新了,这并不是最高点。这时候actor只能转头再继续寻找新的最高点。更坏的情况可能是actor被困在次高点,没有找到正确的最高点。
所以我们可以把Critic的更新频率,调的比Actor要高一点。让critic更加确定,actor再行动。
因为actor-critic方法中参数更新缓慢,进行延时更新一方面可以减少不必要的重复更新,另一方面也可以减少在多次更新中累积的误差。
3. Target Policy Smoothing Regularization
上面我们通过延时更新policy来避免误差被过分累积,接下来我们我们再思考能不能把误差本身变小呢?那么我们首先就要弄清楚误差的来源。
误差的根源是值函数估计产生的偏差。知道了原因我们就可以去解决它,在机器学习中消除估计的偏差的常用方法就是对参数更新进行正则化,同样的,我们也可以将这种方法引入强化学习中来:
在强化学习中一个很自然的想法就是:对于相似的action,他们应该有着相似的value。
所以我们希望能够对action空间中target action周围的一小片区域的值能够更加平滑,从而减少误差的产生。paper中的做法是对target action的Q值加入一定的噪声
ϵ
\epsilon
ϵ :
这里的噪声可以看作是一种正则化方式,这使得值函数更新更加平滑。
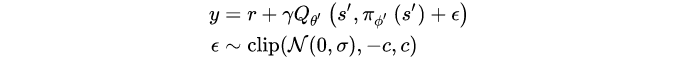
算法实现
总体流程
总结来说TD3中一共使用了三个技巧来消除AC方法中的偏差问题:
-
Trick One: Clipped Double-Q Learning.使用两个Q函数进行学习,并在更新参数时使用其中最小的一个来避免value的过高估计。
-
Trick Two: “Delayed” Policy Updates.对Target以及policy都进行延时更新,避免更新过程中的累积误差。
-
Trick Three: Target Policy Smoothing.对target action增加噪音,对Q函数进行平滑操作,减少policy的误差。

代码实现
略