深拷贝与浅拷贝首先本质上都是赋值一个对象,将a赋给b。
一、从内存来看(本质)
在创建一个对象时,会在内存中开辟一块空间,内存中存储变量的值 ,而变量名则是指向该空间的地址。
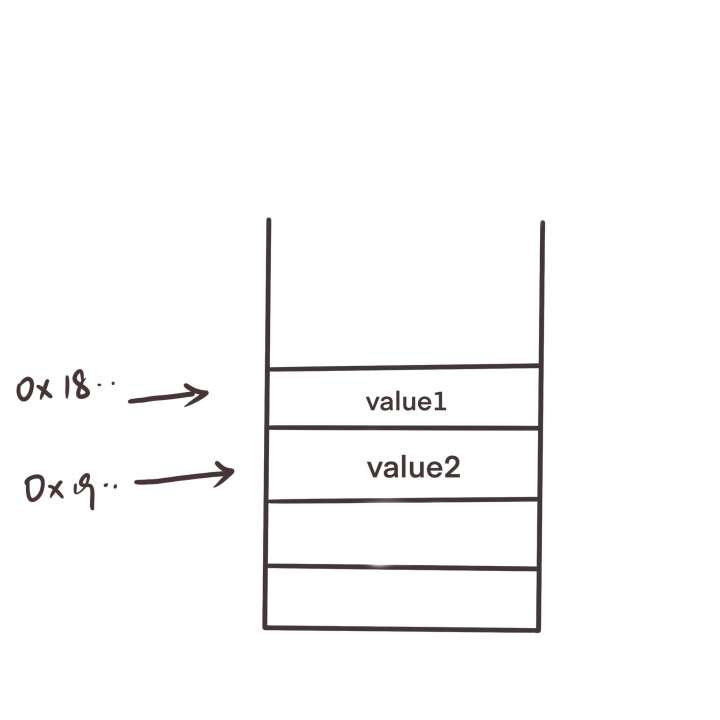
深拷贝是重新开辟一片内存空间,与原先的复制对象值相同,但地址不同,上图为深拷贝情况
如果是浅拷贝,指向的还是同一片内存空间,值相同,地址也相同
二、从赋值对象看
将a赋给b
深拷贝:不管a是什么,number,string,object 还是 array,拷贝出来的b为新对象,会拷贝a的每一层(a中可能有数组,对象的嵌套的情况)
浅拷贝:只拷贝第一层,如果第一层为对象,对象中有一个city也为对象(此时city为第二层),则city不会被拷贝。
如果文字描述难以理解,请看第四点中的例子,可以更好地理解。
三、实现深拷贝的方法
1.最常用的方法,JSON转换
实现也很简单,一句话。可以应用于绝大多数情况
const deepClone1 = (value: any) => {
return JSON.parse(JSON.stringify(value))
}2.structuredClone(value)方法
const deepClone2 = (value: any) => {
return structuredClone(value)
}系统提供的一种深拷贝方法,但对Node及浏览器有版本要求,可适用性不高
要求Node:verison≥17.0.0
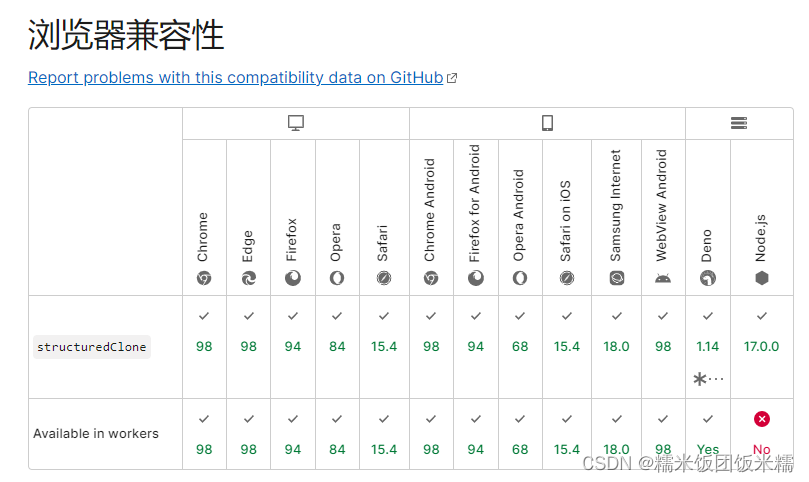
放一下该文档说明的链接,请自行查看 structuredClone() - Web API 接口参考 | MDN
3.手写实现
const deepClone3 = (value: any) => {
if (typeof value != 'object' || value == null) {
return value
}
let res = Array.isArray(value) ? [] : {}
for (let el in value) {
if (value.hasOwnProperty(el)) {
res[el] = deepClone3(value[el])
}
}
return res;
}四、三种深拷贝方法的区别
请看下面的例子:
我们在作拷贝的操作后(obj2 = obj) ,将obj2的值改动,观察obj2与obj值的变动情况。
用例1: string类型
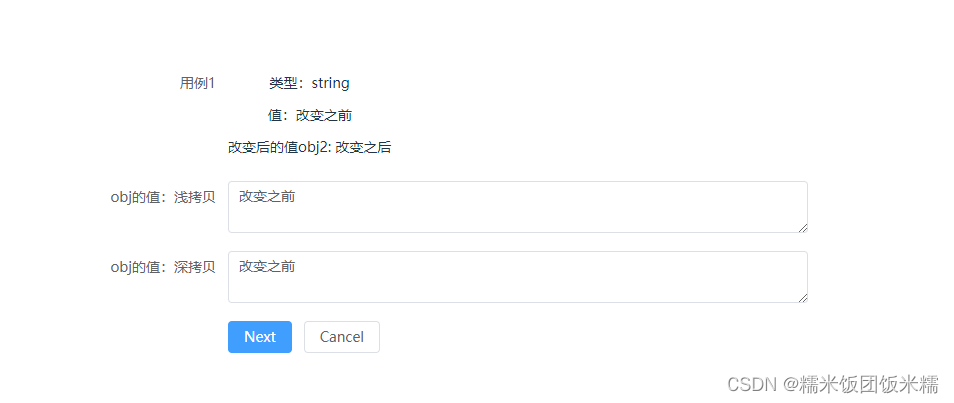
obj = '改变之前',
obj2=obj,
obj2='改变之后' 可以发现,在把obj2的值改变后,此时无论是深拷贝(3种方法都一样)还是浅拷贝,obj的值还是一样。(因为string只有第一层,此时看不出差别)
用例2:对象类型
//obj
{
name: null,
englishName: 'english',
id: 111,
cate: undefined,
detail: {
city: '中国',
custom: ['客户1', '客户2'],
info: {
date: new Date(1998, 1, 1),
price: 20000
}
}
}
//分别深浅拷贝后,obj2的值作改变
{
name: '新名字',
englishName: 'english',
id: 112,
cate: undefined,
detail: {
city: '中国',
custom: ['新客户', '客户2'],
info: {
date: new Date(1998, 1, 1),
price: 20000
}
}
}
先使用深拷贝方法1(JSON转换),接下来我们看结果:

可以发现:
1.无论是深还是浅拷贝,对象中的cate属性消失了,因为它是undefined(用console.log打印cate消失)
2.浅拷贝原来的obj也受到了影响
3.深拷贝中,obj没有受到影响
接下来试一下深拷贝方法2(原生API)

结果与方法1一致
唯一区别:console.log打印cate存在
最后试一下深拷贝方法3(手写)

与方法2一致,cate依旧存在
下图分别为深拷贝方法123所打印的结果:
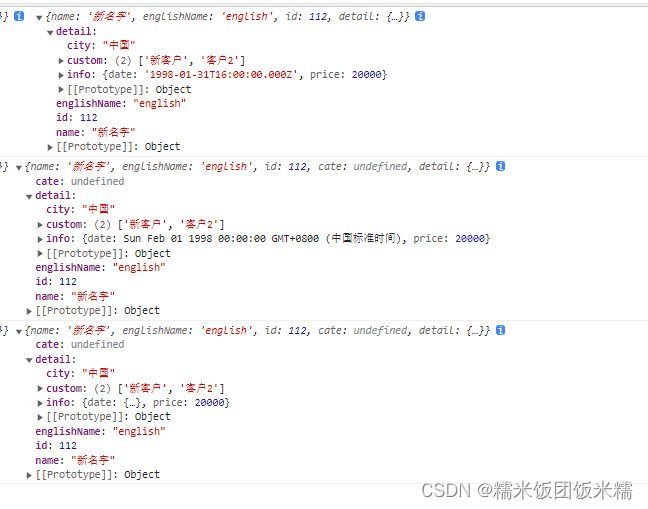
得出结论:
1.浅拷贝仅可以拷贝第一层的数据,深拷贝是新生成一个相同的独立的对象,可以拷贝所有层的数据,之后再做的任何改动,都与原先的对象无关。
2.深拷贝方法中,使用JSON转换的方法可以适用大部分情况,但会深拷贝会丢失undefined数据
3.深拷贝方法中,系统方法对Node及浏览器版本要求较高