目录
前言
接着上篇文章 PaddleOCR-PP-OCRv4推理详解及部署实现(上) 来讲,在上篇文章中我们已经导出 PP-OCRv4 模型中的三个 ONNX,这篇文章我们就来梳理下这三个模型的前后处理方便我们后续在 C++ 上的实现,若有问题欢迎各位看官批评指正😄
1. 调试配置
我们分析调试的代码主要是 PaddleOCR 项目下的 tools/infer/predict_system.py 脚本文件,开始之前需要你将相应的环境配置好,这个我们在上篇文章中有介绍过,这边博主不再赘述
另外需要你将 PaddleOCR 项目 clone 下来,并参考上篇文章准备好导出的 ONNX,大家也可以点击 here 下载博主准备好的源码和 ONNX 模型文件(注意代码下载于 2024/7/20 日,如果改动请参考最新)
下面我们就来调试 tools/infer/predict_system.py 文件:
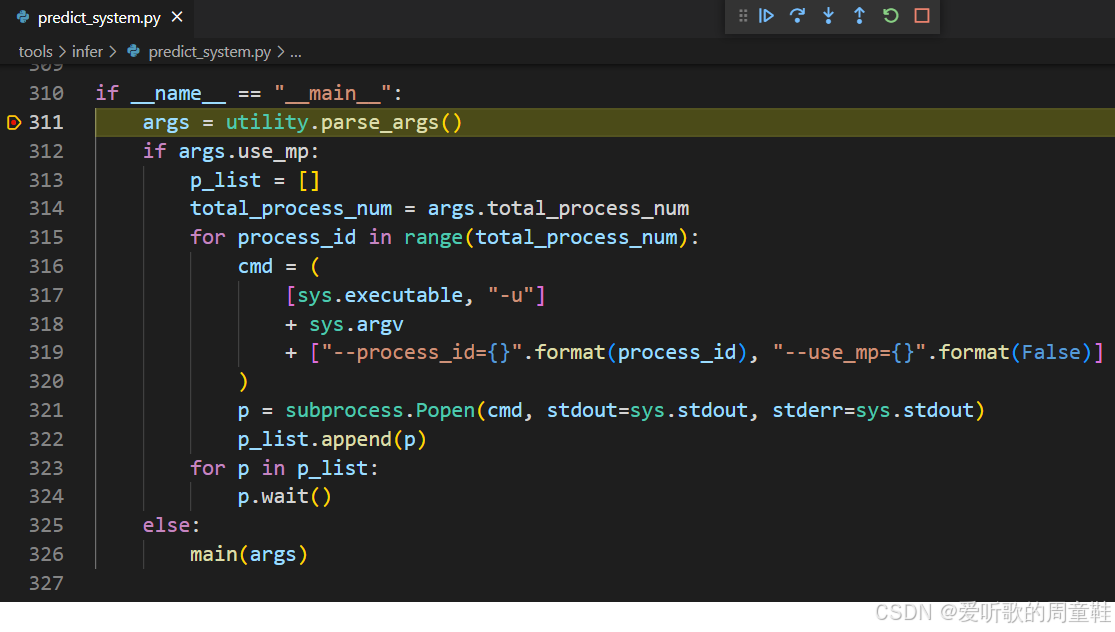
Note:博主这里采用的是 vscode 进行代码的调试,其中的 launch.json 文件内容如下:
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python 调试程序: 当前文件",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/tools/infer/predict_system.py",
"console": "integratedTerminal",
"args": [
"--use_gpu", "False",
"--use_onnx", "True",
"--use_angle_cls", "True",
"--det_model_dir", "./models/det/det.sim.onnx",
"--rec_model_dir", "./models/rec/rec.sim.onnx",
"--cls_model_dir", "./models/cls/cls.sim.onnx",
"--image_dir", "./deploy/lite/imgs/lite_demo.png",
]
}
]
}
2. 检测模型
下面我们调试来分析检测模型的前后处理
2.1 预处理
首先看预处理,找到检测模型的入口:
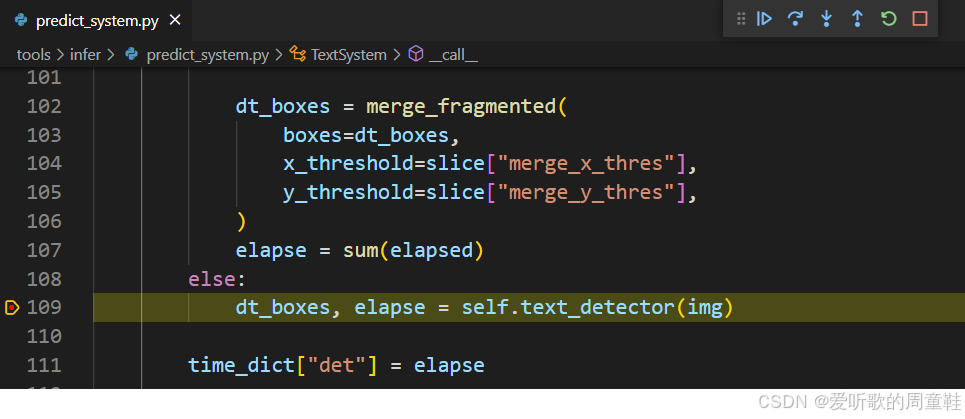
接着找到模型预测部分:
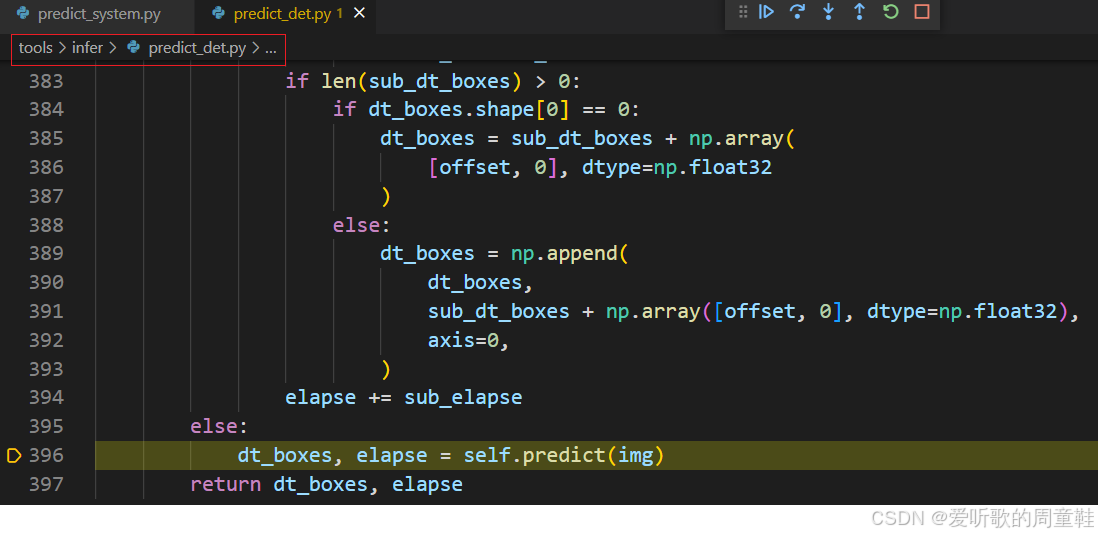
在 predict 函数中通过 transform 函数对传入的图像进行了一系列的预处理:
它包括以下几个操作:
- DetResizeForTest
- NormalizeImage
- ToCHWImage
- KeepKeys
其中 KeepKeys 对图像没有进行操作,因此我们重点看前面三个操作,我们一个个看
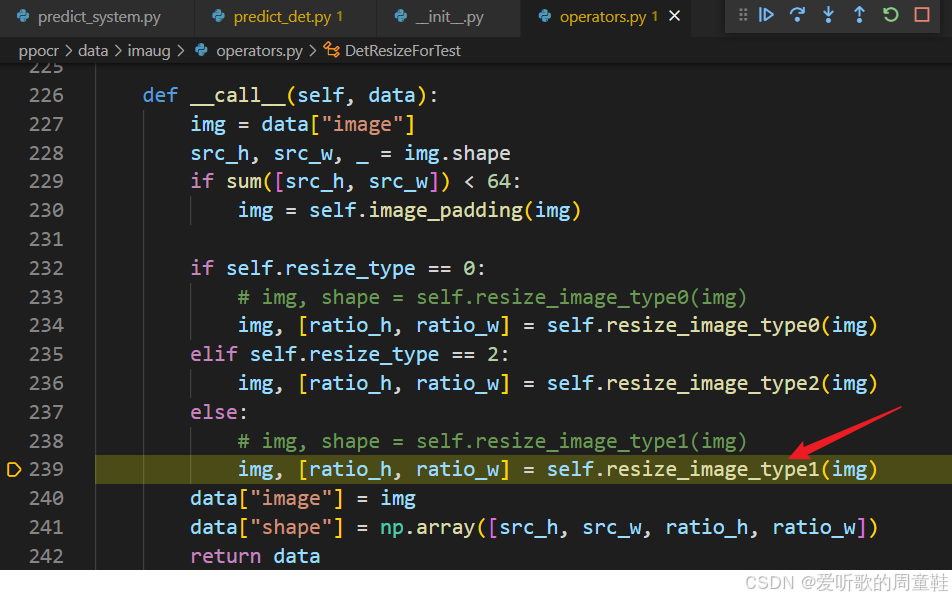
首先是 DetResizeForTest 部分,它其实调用的是 resize_image_type1 这个函数,函数内容如下:
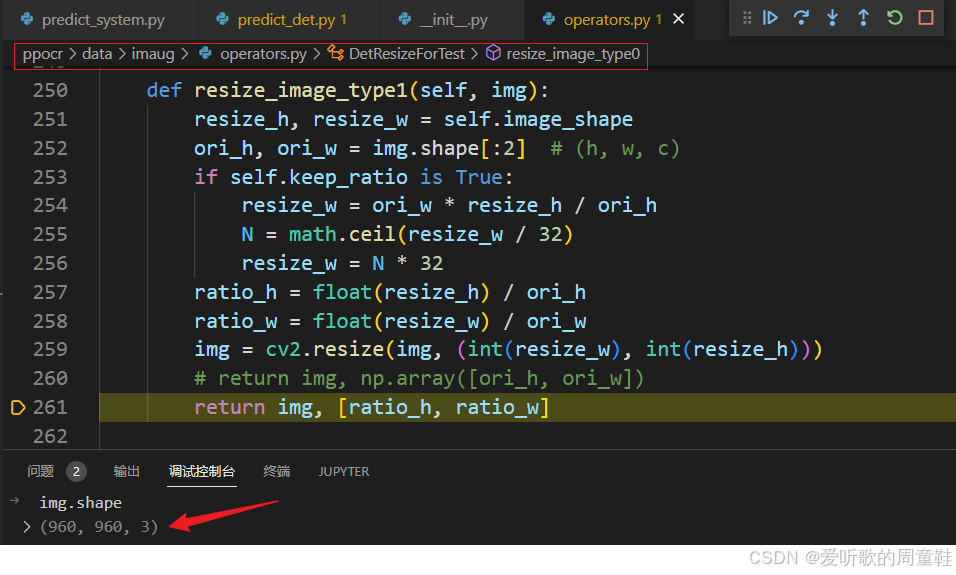
这里其实就是做了一个 resize 操作,把原图直接 resize 缩放到 960x960,我们接着看 NormalizeImage 部分:
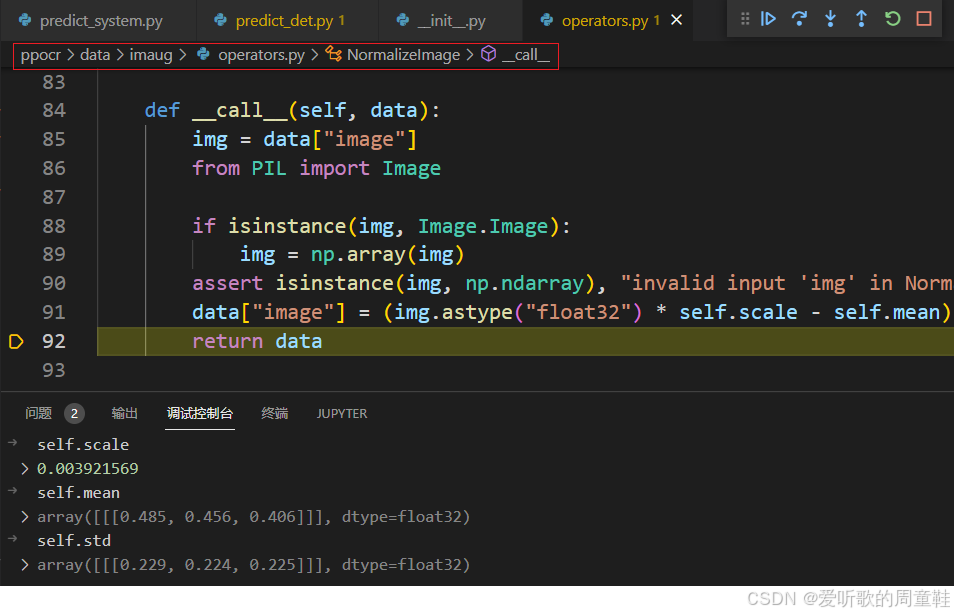
这边将图像乘以 scale 然后做了减均值除以标准差,那这里 scale 的数值 0.003921569 是咋来的呢,那其实它就是 1/255.0,所以这里的操作我们也很熟悉了,就是除以 255.0 然后减均值除以标准差
OK,接着看 ToCHWImage 部分:
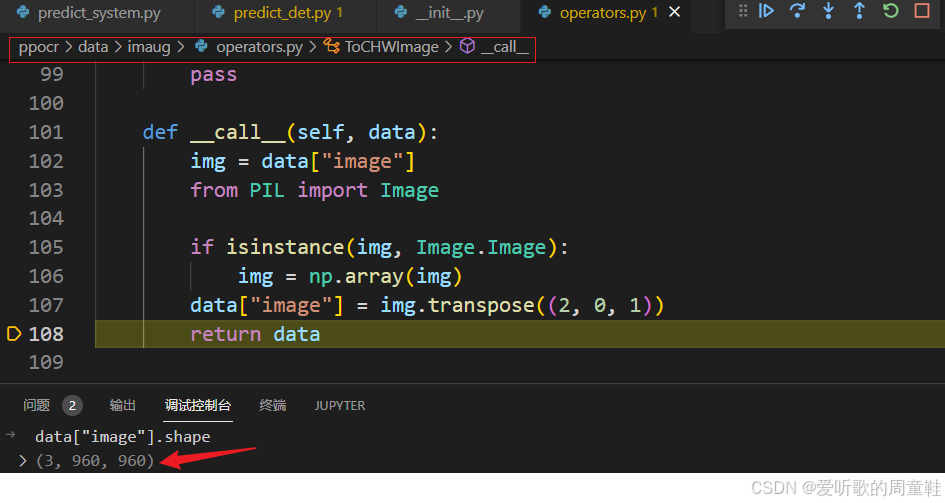
这部分比较简单就是通过 transpose 将 H,W,C 转换成 C,H,W
接着必不可少的添加 batch 维度,如下所示:
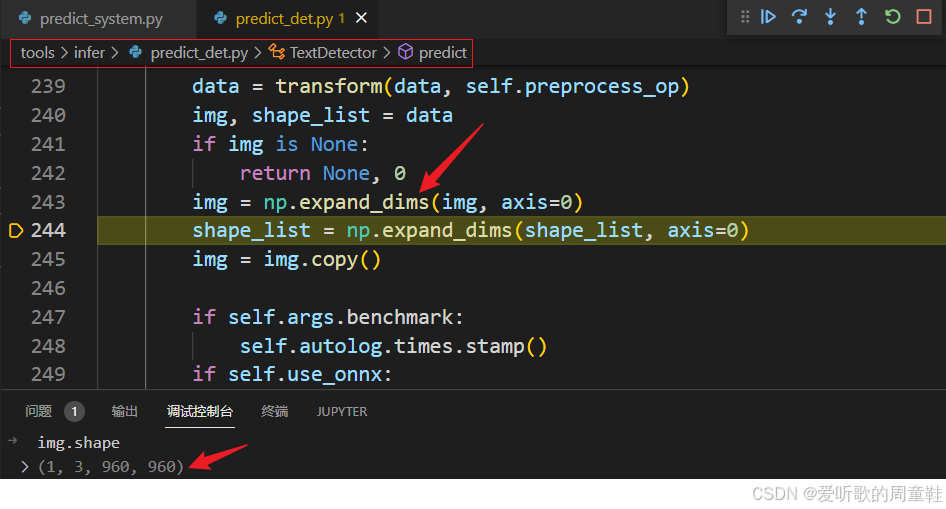
我们简单总结下整个预处理做了哪些操作:
- 1. resize
- 2. /255.0 减均值除标准差
- 3. c,h,w->h,w,c
- 4. h,w,c->b,c,h,w
因此我们不难写出其预处理,代码如下所示:
def preprocess(self, img, tar_w=960, tar_h=960):
# 1. resize
img = cv2.resize(img, (int(tar_w), int(tar_h)))
# 2. normalize
img = img.astype("float32") / 255.0
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape(1, 1, 3).astype("float32")
std = np.array(std).reshape(1, 1, 3).astype("float32")
img = (img - mean) / std
# 3. to bchw
img = img.transpose((2, 0, 1))[None]
return img
至此,检测模型的预处理梳理完毕,下面看其后处理
2.2 后处理
在梳理后处理之前我们先打印下模型推理后的输出维度:
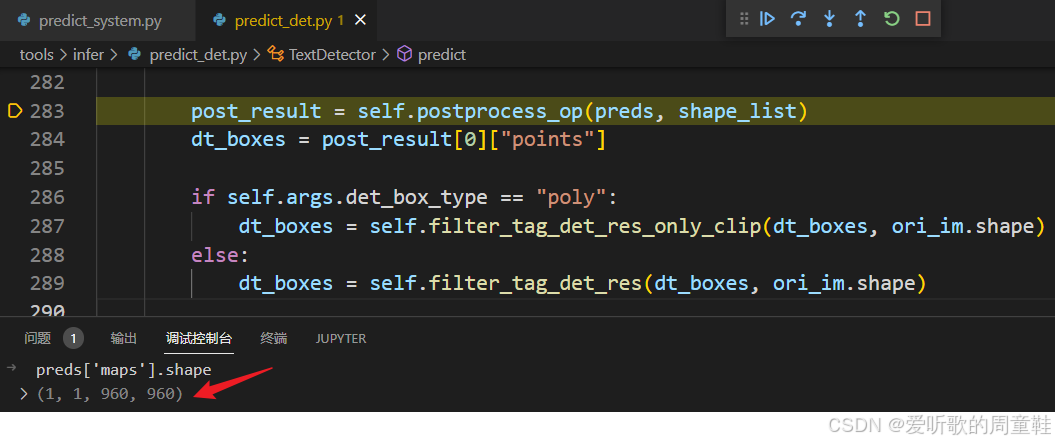
可以看到模型的输出维度是 1x1x960x960,它其实得到的就是一张和原图同样大小的概率图,文本检测模型实际上是一个分割模型,它最终得到的是每个像素点的概率值,只是通过一系列繁琐的后处理能够得到文本检测框,这个我们在上篇文章中提到过
接着我们来看后处理都做了哪些操作:
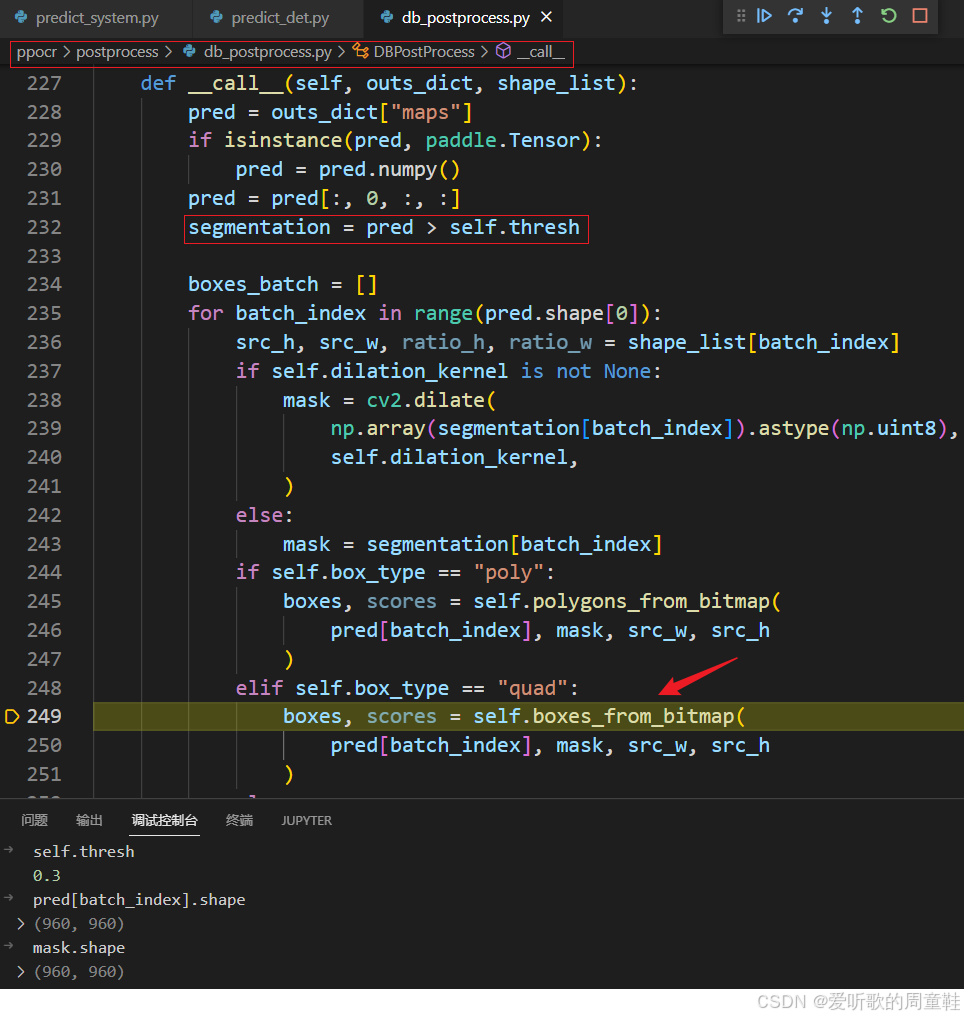
它主要是通过 boxes_from_bitmap 函数从 mask 中得到对应的 boxes 和 scores,我们重点来看下该函数是如何做的:
def boxes_from_bitmap(self, pred, _bitmap, dest_width, dest_height):
"""
_bitmap: single map with shape (1, H, W),
whose values are binarized as {0, 1}
"""
bitmap = _bitmap
height, width = bitmap.shape
outs = cv2.findContours(
(bitmap * 255).astype(np.uint8), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE
)
if len(outs) == 3:
img, contours, _ = outs[0], outs[1], outs[2]
elif len(outs) == 2:
contours, _ = outs[0], outs[1]
num_contours = min(len(contours), self.max_candidates)
boxes = []
scores = []
for index in range(num_contours):
contour = contours[index]
points, sside = self.get_mini_boxes(contour)
if sside < self.min_size:
continue
points = np.array(points)
if self.score_mode == "fast":
score = self.box_score_fast(pred, points.reshape(-1, 2))
else:
score = self.box_score_slow(pred, contour)
if self.box_thresh > score:
continue
box = self.unclip(points, self.unclip_ratio)
if len(box) > 1:
continue
box = np.array(box).reshape(-1, 1, 2)
box, sside = self.get_mini_boxes(box)
if sside < self.min_size + 2:
continue
box = np.array(box)
box[:, 0] = np.clip(np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(
np.round(box[:, 1] / height * dest_height), 0, dest_height
)
boxes.append(box.astype("int32"))
scores.append(score)
return np.array(boxes, dtype="int32"), scores
该函数的主要作用是从给定的二值化位图 _bitmap 中提取检测到的文本框,并根据给定的目标宽高对这些框进行缩放,具体分析如下:(from ChatGPT)
输入参数
- pred:预测结果,通常是文本检测模型的输出,用来获取目标框的 score
- _bitmap:单通道的二值化图像,shape 为 (1,H,W),值为 0 或 1
- dest_width:缩放后的目标宽度
- dest_height:缩放后的目标高度
函数步骤详解
- 提取轮廓:使用 OpenCV 的
findContours函数从二值化图像中提取轮廓。将二值图像乘以 255 是因为 OpenCV 期望输入为 0 或 255 的图像。RETR_LIST标志表示提取所有轮廓,CHAIN_APPROX_SIMPLE标志表示压缩轮廓的水平、垂直和对角线部分,只保留端点。 - 检查轮廓输出:
findContours返回的结果可能有 3 个(图像、轮廓、层级)或 2 个(轮廓、层级)。根据返回值的长度提取轮廓数据。 - 处理每个轮廓:限制要处理的轮廓数量,以
self.max_candidates为上限。 - 从轮廓生成 boxes
- 生成最小框: 调用
self.get_mini_boxes(contour)从每个轮廓生成最小包围框。 - 框大小检查: 检查生成的框的尺寸是否符合最小尺寸要求
self.min_size。 - 计算评分: 使用快速评分函数
box_score_fast计算每个 box 的 score 分数 - 评分阈值过滤: 检查评分是否大于阈值
self.box_thresh。 - 框校正: 调用
self.unclip(points, self.unclip_ratio)对框进行校正。 - 缩放坐标: 将框坐标从原始图像大小缩放到目标图像大小
dest_width和dest_height,确保坐标在目标图像范围内。 - 存储结果: 将框和评分添加到结果列表中。
- 生成最小框: 调用
保存的二值化图如下所示:

get_mini_boxes 函数内容如下:
def get_mini_boxes(self, contour):
bounding_box = cv2.minAreaRect(contour)
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_1 = 0
index_4 = 1
else:
index_1 = 1
index_4 = 0
if points[3][1] > points[2][1]:
index_2 = 2
index_3 = 3
else:
index_2 = 3
index_3 = 2
box = [points[index_1], points[index_2], points[index_3], points[index_4]]
return box, min(bounding_box[1])
get_mini_boxes 函数的主要功能是从给定的轮廓中生成一个最小的矩形框,并将这个框的角点按照特定顺序排序,它的主要功能是:
- 从给定的轮廓中计算一个最小的旋转矩形
- 将矩形的四个角点按照从左到右和从上到下的顺序排序
- 返回排序后的角点和矩形的最小边长度
box_score_fast 函数内容如下:
def box_score_fast(self, bitmap, _box):
"""
box_score_fast: use bbox mean score as the mean score
"""
h, w = bitmap.shape[:2]
box = _box.copy()
xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin : ymax + 1, xmin : xmax + 1], mask)[0]
box_score_fast 函数的目的是计算一个给定框的评分,该评分基于二值化位图的平均值。具体来说,它通过计算框区域内的平均分数来评估框的质量,它的主要功能是:
- 从给定的二值化位图和框中计算该框的评分
- 评分是框区域内的平均值,通过掩膜来只计算框内的像素
- 使用
cv2.mean函数来计算平均值
unclip 函数内容如下:
def unclip(self, box, unclip_ratio):
poly = Polygon(box)
distance = poly.area * unclip_ratio / poly.length
offset = pyclipper.PyclipperOffset()
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = offset.Execute(distance)
return expanded
unclip 函数的作用是对给定的框进行扩展处理,具体来说,是通过增加边界的方式来扩大框的区域。这个过程常用于文本检测等任务中,以确保框能够更好地包含实际的文本区域,它的主要功能是:
- 扩展多边形: 根据给定的扩展比例
unclip_ratio扩展输入框box。 - 计算扩展距离: 使用多边形的面积和周长来计算扩展的距离。
- 执行扩展操作: 使用
pyclipper库的PyclipperOffset对象进行实际的多边形扩展。
最终我们从二值化图像中获取到了对应的文本框:
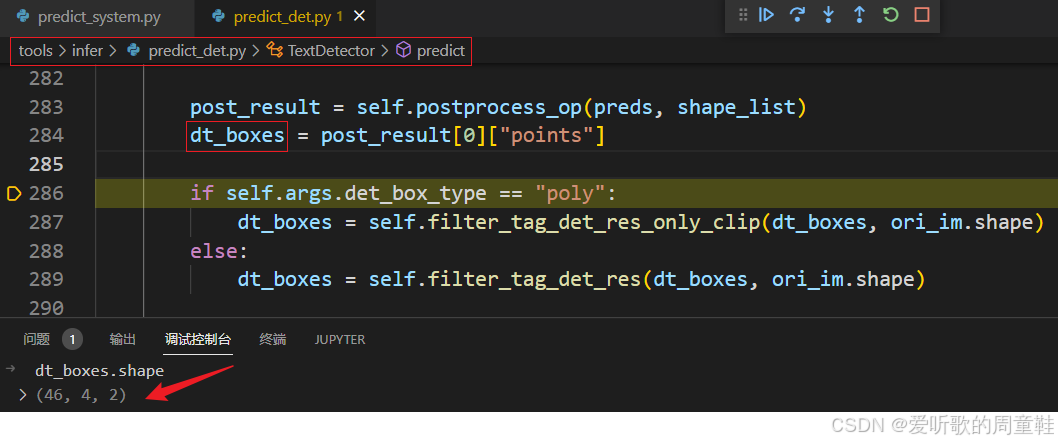
可以看到其 shape 为 46x4x2,其中:
- 46 代表文本框个数
- 4 代表多边形四个点
- 2 代表 x,y
接着我们还会对获取到的文本框过滤:
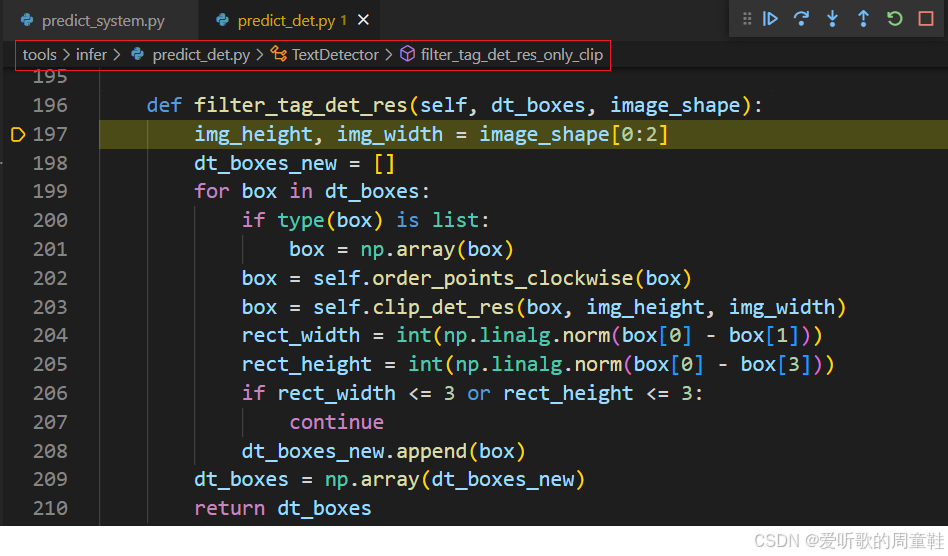
filter_tag_det_res 函数的主要功能是对检测到的文本框进行过滤和处理,以确保只保留有效的框。它对每个文本框进行一系列处理,包括点排序、边界裁剪和尺寸过滤,它的主要功能如下:
- 排序:通过
order_points_clockwise函数确保每个框的四个点按顺时针顺序排列 - 裁剪:通过
clip_det_res函数将框的坐标裁剪到图像的边界内,以避免超出图像范围 - 过滤小框:通过计算框的宽度和高度,并过滤掉那些尺寸小于等于 3 的框,确保只保留有效的文本框。
其实检测模型的后处理到这里就结束了,只不过后续利用文本框进行图像裁剪会先对 boxes 排序:
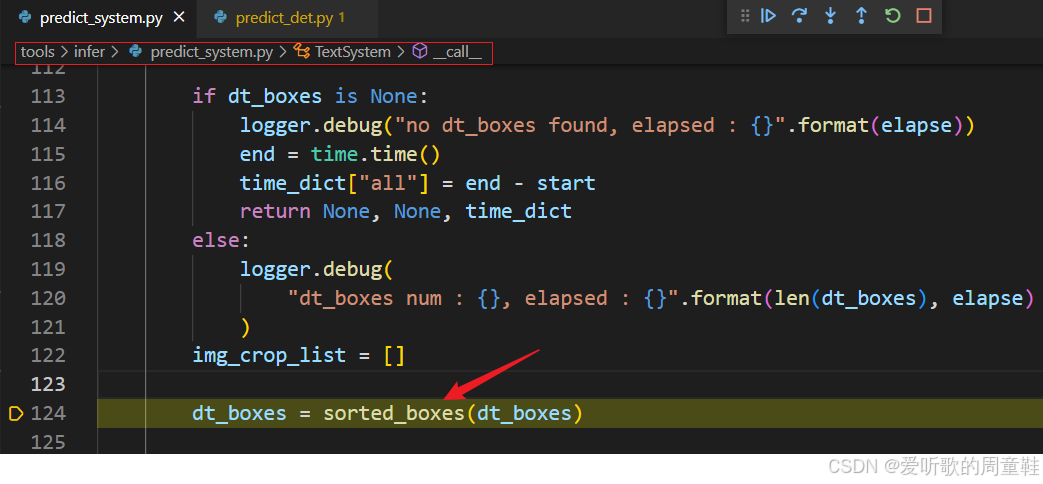
这里我们把它放到后处理中一并做了,排序函数 sorted_boxes 内容如下:
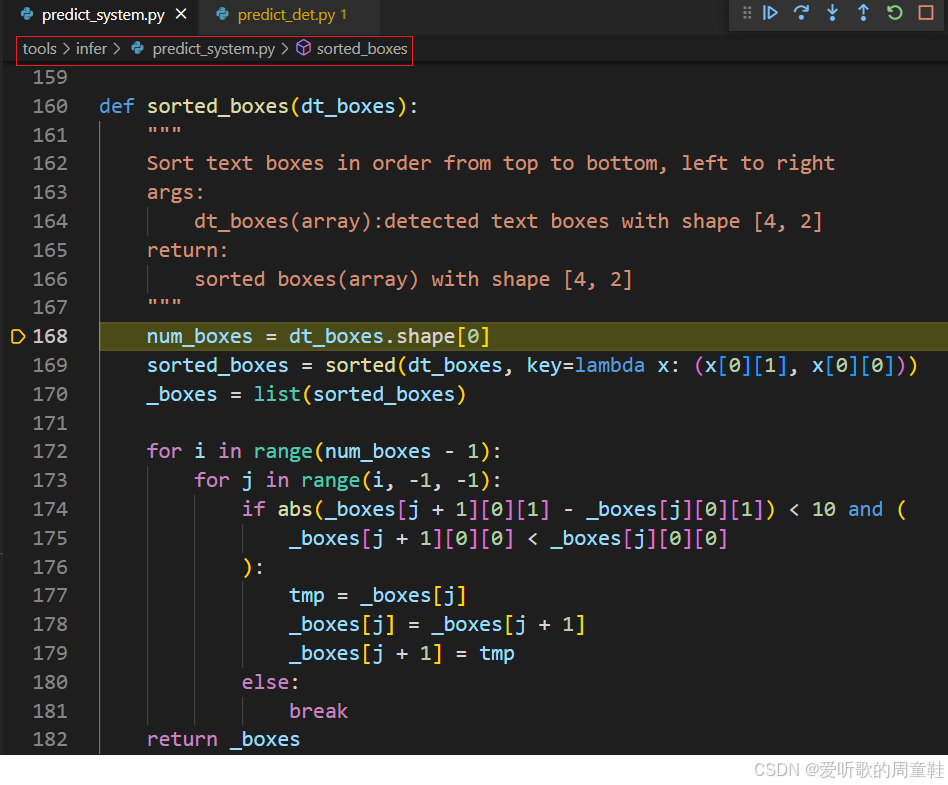
sorted_boxes 函数的主要功能是对检测到的文本框进行排序,按照从上到下、从左到右的顺序排列,它的主要功能是:
- 初步排序: 按照文本框第一个点的 y 坐标(从上到下)和 x 坐标(从左到右)对框进行初步排序。
- 二次排序: 在 y 坐标相近的情况下,根据 x 坐标进一步排序,确保框在相同水平线上的顺序正确。
- 返回排序结果: 返回经过排序的文本框列表。
至此,检测模型的后处理已经全部梳理完,我们简单总结下它做了哪些操作:
- boxes_from_bitmap:从给定的二值化图
_bitmap中提取检测到的文本框并缩放 - filter_tag_det_res:对检测到的文本框进行过滤
- sorted_boxes:对过滤的文本框排序
因此我们不难写出其后处理,代码如下所示:
def postprocess(self, pred, src_h, src_w):
# pred->1x1x960x960
pred = pred[0, 0, :, :]
mask = pred > self.mask_thresh
boxes, _ = self._boxes_from_bitmap(pred, mask, src_w, src_h)
boxes = self._filter_boxes(boxes, src_h, src_w)
boxes = self._sorted_boxes(boxes)
return boxes
def _boxes_from_bitmap(self, pred, bitmap, dest_width, dest_height):
"""
bitmap: single map with shape (H, W),
whose values are binarized as {0, 1}
"""
height, width = bitmap.shape
# bitmap_image = (bitmap * 255).astype(np.uint8)
# cv2.imwrite("bitmap_image.jpg", bitmap_image)
outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
if len(outs) == 3:
_, contours, _ = outs[0], outs[1], outs[2] # opencv3.x
elif len(outs) == 2:
contours, _ = outs[0], outs[1] # opencv4.x
num_contours = min(len(contours), self.max_candidates)
# contour_image = cv2.cvtColor(bitmap_image, cv2.COLOR_GRAY2BGR)
# for contour in contours:
# cv2.drawContours(contour_image, [contour], -1, (0, 0, 255), 2)
# cv2.imwrite('contour_image.jpg', contour_image)
boxes = []
scores = []
for index in range(num_contours):
contour = contours[index]
points, sside = self._get_mini_boxes(contour)
if sside < self.min_size:
continue
points = np.array(points)
score = self._box_score(pred, points.reshape(-1, 2))
if score < self.box_thresh:
continue
box = self._unclip(points, self.unclip_ratio)
if len(box) > 1:
continue
box = np.array(box).reshape(-1, 1, 2)
box, sside = self._get_mini_boxes(box)
if sside < self.min_size + 2:
continue
box = np.array(box)
box[:, 0] = np.clip(np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(np.round(box[:, 1] / height * dest_height), 0, dest_height)
boxes.append(box.astype("int32"))
scores.append(score)
return np.array(boxes, dtype="int32"), scores
def _get_mini_boxes(self, contour):
# [[center_x, center_y], [width, height], angle]
bounding_box = cv2.minAreaRect(contour)
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_1 = 0
index_4 = 1
else:
index_1 = 1
index_4 = 0
if points[3][1] > points[2][1]:
index_2 = 2
index_3 = 3
else:
index_2 = 3
index_3 = 2
box = [points[index_1], points[index_2], points[index_3], points[index_4]]
return box, min(bounding_box[1])
def _box_score(self, bitmap, _box):
"""
box_score: use bbox mean score as the mean score
"""
h, w = bitmap.shape[:2]
box = _box.copy()
xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin : ymax + 1, xmin : xmax + 1], mask)[0]
def _unclip(self, box, unclip_ratio):
poly = Polygon(box)
distance = poly.area * unclip_ratio / poly.length
offset = pyclipper.PyclipperOffset()
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = offset.Execute(distance)
return expanded
def _filter_boxes(self, boxes, src_h, src_w):
boxes_filter = []
for box in boxes:
box = self._order_points_clockwise(box)
box = self._clip(box, src_h, src_w)
rect_width = int(np.linalg.norm(box[0] - box[1]))
rect_height = int(np.linalg.norm(box[0] - box[3]))
if rect_width <= 3 or rect_height <= 3:
continue
boxes_filter.append(box)
return np.array(boxes_filter)
def _order_points_clockwise(self, pts):
rect = np.zeros((4, 2), dtype="float32")
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
tmp = np.delete(pts, (np.argmin(s), np.argmax(s)), axis=0)
diff = np.diff(np.array(tmp), axis=1)
rect[1] = tmp[np.argmin(diff)]
rect[3] = tmp[np.argmax(diff)]
return rect
def _clip(self, points, img_height, img_width):
for idx in range(points.shape[0]):
points[idx, 0] = int(min(max(points[idx, 0], 0), img_width - 1))
points[idx, 1] = int(min(max(points[idx, 1], 0), img_height - 1))
return points
def _sorted_boxes(self, boxes):
"""
Sort text boxes in order from top to bottom, left to right
"""
num_boxes = boxes.shape[0]
boxes_sorted = sorted(boxes, key=lambda x: (x[0][1], x[0][0]))
_boxes = list(boxes_sorted)
for i in range(num_boxes - 1):
for j in range(i, -1, -1):
if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and (_boxes[j + 1][0][0] < _boxes[j][0][0]):
tmp = _boxes[j]
_boxes[j] = _boxes[j + 1]
_boxes[j + 1] = tmp
else:
break
return _boxes
核心就是三个函数,但是由于辅助函数比较多,所以整体看上去后处理比较繁琐,大家稍微有点耐心慢慢梳理就行
至此,检测模型的后处理梳理完毕,下面我们来看推理
2.3 推理
通过上面对检测模型的预处理和后处理分析之后,整个推理过程就显而易见:
import cv2
import math
import copy
import random
import numpy as np
import onnxruntime as ort
from PIL import Image, ImageFont, ImageDraw
import pyclipper
from shapely.geometry import Polygon
class TextDetector(object):
def __init__(self, model_path, mask_thresh=0.3, box_thresh=0.6,
max_candidates=1000, min_size=3, unclip_ratio=1.5) -> None:
self.predictor = ort.InferenceSession(model_path, provider_options=["CPUExecutionProvider"])
self.mask_thresh = mask_thresh
self.box_thresh = box_thresh
self.max_candidates = max_candidates
self.min_size = min_size
self.unclip_ratio = unclip_ratio
def preprocess(self, img, tar_w=960, tar_h=960):
# 1. resize
img = cv2.resize(img, (int(tar_w), int(tar_h)))
# 2. normalize
img = img.astype("float32") / 255.0
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape(1, 1, 3).astype("float32")
std = np.array(std).reshape(1, 1, 3).astype("float32")
img = (img - mean) / std
# 3. to bchw
img = img.transpose((2, 0, 1))[None]
return img
def forward(self, input):
# input->1x3x960x960
output = self.predictor.run(None, {"images": input})[0]
return output
def postprocess(self, pred, src_h, src_w):
# pred->1x1x960x960
pred = pred[0, 0, :, :]
mask = pred > self.mask_thresh
boxes, _ = self._boxes_from_bitmap(pred, mask, src_w, src_h)
boxes = self._filter_boxes(boxes, src_h, src_w)
boxes = self._sorted_boxes(boxes)
return boxes
def _boxes_from_bitmap(self, pred, bitmap, dest_width, dest_height):
"""
bitmap: single map with shape (H, W),
whose values are binarized as {0, 1}
"""
height, width = bitmap.shape
# bitmap_image = (bitmap * 255).astype(np.uint8)
# cv2.imwrite("bitmap_image.jpg", bitmap_image)
outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
if len(outs) == 3:
_, contours, _ = outs[0], outs[1], outs[2] # opencv3.x
elif len(outs) == 2:
contours, _ = outs[0], outs[1] # opencv4.x
num_contours = min(len(contours), self.max_candidates)
# contour_image = cv2.cvtColor(bitmap_image, cv2.COLOR_GRAY2BGR)
# for contour in contours:
# cv2.drawContours(contour_image, [contour], -1, (0, 0, 255), 2)
# cv2.imwrite('contour_image.jpg', contour_image)
boxes = []
scores = []
for index in range(num_contours):
contour = contours[index]
points, sside = self._get_mini_boxes(contour)
if sside < self.min_size:
continue
points = np.array(points)
score = self._box_score(pred, points.reshape(-1, 2))
if score < self.box_thresh:
continue
box = self._unclip(points, self.unclip_ratio)
if len(box) > 1:
continue
box = np.array(box).reshape(-1, 1, 2)
box, sside = self._get_mini_boxes(box)
if sside < self.min_size + 2:
continue
box = np.array(box)
box[:, 0] = np.clip(np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(np.round(box[:, 1] / height * dest_height), 0, dest_height)
boxes.append(box.astype("int32"))
scores.append(score)
return np.array(boxes, dtype="int32"), scores
def _get_mini_boxes(self, contour):
# [[center_x, center_y], [width, height], angle]
bounding_box = cv2.minAreaRect(contour)
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_1 = 0
index_4 = 1
else:
index_1 = 1
index_4 = 0
if points[3][1] > points[2][1]:
index_2 = 2
index_3 = 3
else:
index_2 = 3
index_3 = 2
box = [points[index_1], points[index_2], points[index_3], points[index_4]]
return box, min(bounding_box[1])
def _box_score(self, bitmap, _box):
"""
box_score: use bbox mean score as the mean score
"""
h, w = bitmap.shape[:2]
box = _box.copy()
xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin : ymax + 1, xmin : xmax + 1], mask)[0]
def _unclip(self, box, unclip_ratio):
poly = Polygon(box)
distance = poly.area * unclip_ratio / poly.length
offset = pyclipper.PyclipperOffset()
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = offset.Execute(distance)
return expanded
def _filter_boxes(self, boxes, src_h, src_w):
boxes_filter = []
for box in boxes:
box = self._order_points_clockwise(box)
box = self._clip(box, src_h, src_w)
rect_width = int(np.linalg.norm(box[0] - box[1]))
rect_height = int(np.linalg.norm(box[0] - box[3]))
if rect_width <= 3 or rect_height <= 3:
continue
boxes_filter.append(box)
return np.array(boxes_filter)
def _order_points_clockwise(self, pts):
rect = np.zeros((4, 2), dtype="float32")
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
tmp = np.delete(pts, (np.argmin(s), np.argmax(s)), axis=0)
diff = np.diff(np.array(tmp), axis=1)
rect[1] = tmp[np.argmin(diff)]
rect[3] = tmp[np.argmax(diff)]
return rect
def _clip(self, points, img_height, img_width):
for idx in range(points.shape[0]):
points[idx, 0] = int(min(max(points[idx, 0], 0), img_width - 1))
points[idx, 1] = int(min(max(points[idx, 1], 0), img_height - 1))
return points
def _sorted_boxes(self, boxes):
"""
Sort text boxes in order from top to bottom, left to right
"""
num_boxes = boxes.shape[0]
boxes_sorted = sorted(boxes, key=lambda x: (x[0][1], x[0][0]))
_boxes = list(boxes_sorted)
for i in range(num_boxes - 1):
for j in range(i, -1, -1):
if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and (_boxes[j + 1][0][0] < _boxes[j][0][0]):
tmp = _boxes[j]
_boxes[j] = _boxes[j + 1]
_boxes[j + 1] = tmp
else:
break
return _boxes
检测模型的推理包括图像预处理、模型推理、预测结果后处理三部分,其中预处理主要包括 resize 等操作,后处理主要包括文本框的提取、过滤以及排序
3. 方向分类器模型
下面我们接着来调试分析下方向分类器模型的前后处理
Note:该模块并非必需,如果你检测的文本没有旋转的情况可以去除该模块,直接将文本检测框送入到识别模型即可
3.1 预处理
前面我们在检测模型中得到排序后的文本检测框,接下来首先就要根据这些文本框裁剪图像:
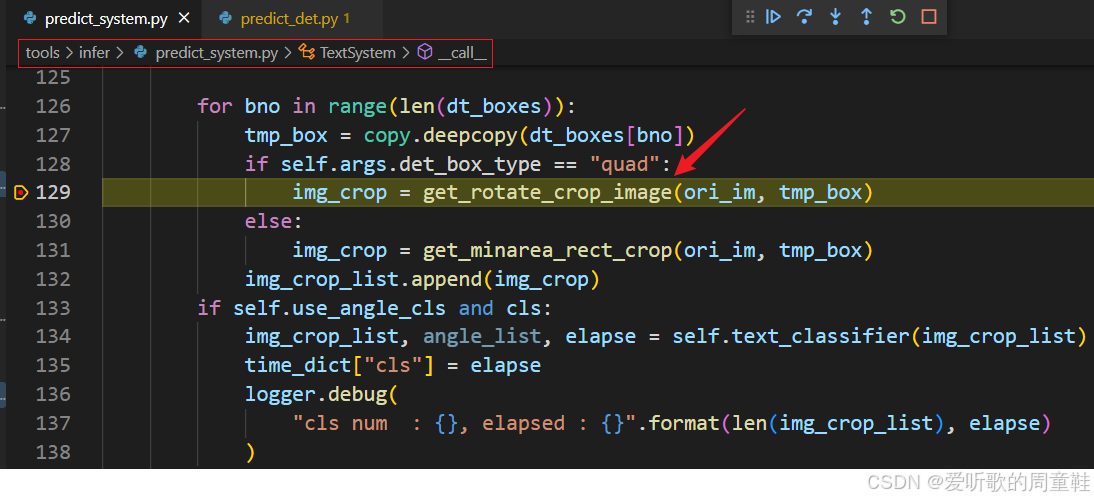
其中 get_rotate_crop_image 函数内容如下:
def get_rotate_crop_image(img, points):
"""
img_height, img_width = img.shape[0:2]
left = int(np.min(points[:, 0]))
right = int(np.max(points[:, 0]))
top = int(np.min(points[:, 1]))
bottom = int(np.max(points[:, 1]))
img_crop = img[top:bottom, left:right, :].copy()
points[:, 0] = points[:, 0] - left
points[:, 1] = points[:, 1] - top
"""
assert len(points) == 4, "shape of points must be 4*2"
img_crop_width = int(
max(
np.linalg.norm(points[0] - points[1]), np.linalg.norm(points[2] - points[3])
)
)
img_crop_height = int(
max(
np.linalg.norm(points[0] - points[3]), np.linalg.norm(points[1] - points[2])
)
)
pts_std = np.float32(
[
[0, 0],
[img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height],
]
)
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M,
(img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC,
)
dst_img_height, dst_img_width = dst_img.shape[0:2]
if dst_img_height * 1.0 / dst_img_width >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
get_rotate_crop_image 函数的主要功能是从给定的图像中裁剪出一个旋转的矩形区域,并返回裁剪后的图像。这在文本检测和图像处理任务中非常有用,尤其是当文本框或目标区域不总是水平对齐时,它的主要功能是:
- 计算裁剪区域的尺寸: 通过分析输入点计算裁剪区域的宽度和高度。
- 进行透视变换: 将图像中指定的四边形区域变换为标准矩形区域,处理旋转和透视。
- 调整图像方向: 如果裁剪后的图像纵横比过大,则旋转图像以使其更符合预期。
- 返回裁剪和调整后的图像: 使得裁剪出的区域在图像处理或展示时可以正确显示。
获取完裁剪后的图像后找到方向分类器模型的入口:
接着找到预处理部分:
其中的 resize_norm_img 函数内容如下:
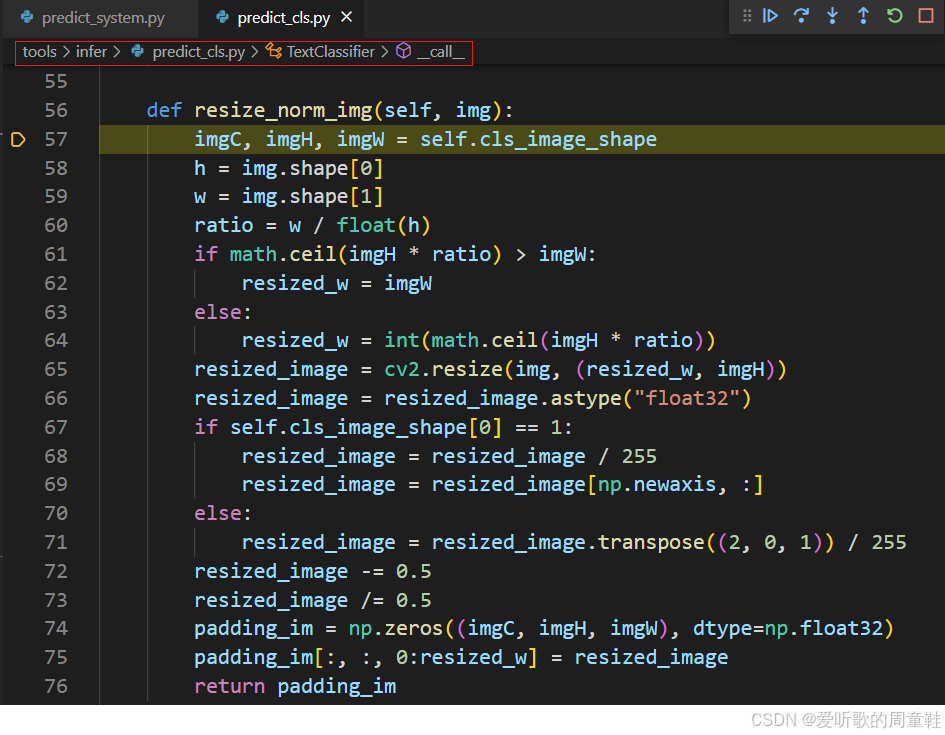
它主要包括以下操作:
- 1. resize
- 2. /255.0,将像素值归一化到 [0,1]
- 3. 减均值(0.5)除标准差(0.5),将像素值转换到 [-1,1]
- 4. 填充
和我们之前的 resize 以及 warpAffine 操作略有不同,这里的 resize 处理是先把高度缩放到指定大小,再根据 ratio 和宽度缩放,如果缩放后的宽度大于指定宽度则只缩放到指定宽度,如果小于则正常缩放,剩余部分填充 0,且没有居中操作
我们下面看两张对比图就清晰了:
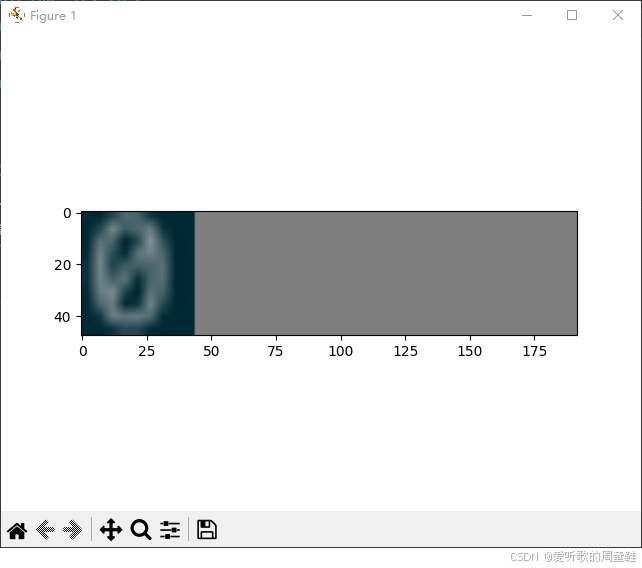
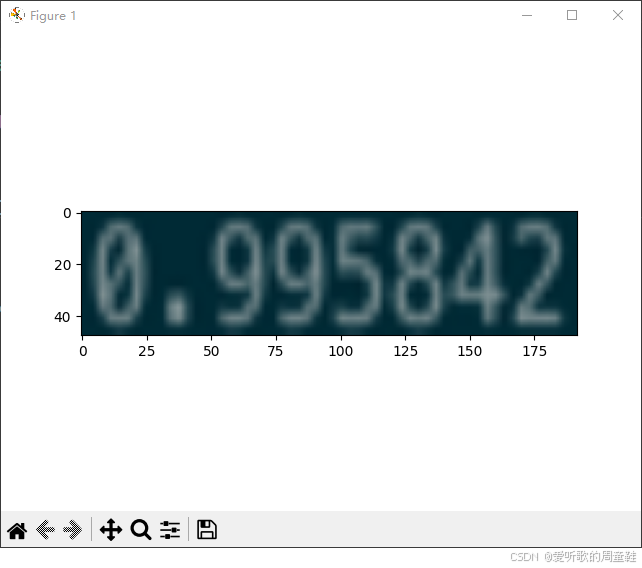
我们的目标是将文本图像缩放到 48x192 大小,所以两张图都是 48x192,但是第一张图宽度正常缩放,剩余部分填充 0,第二张图宽度超出指定范围则直接缩放到 192
因此我们不难写出其预处理,代码如下所示:
def _resize_norm_img(self, img, dest_width, dest_height):
h, w, _ = img.shape
ratio = w / float(h)
if math.ceil(dest_height * ratio) > dest_width:
resized_w = dest_width
else:
resized_w = int(math.ceil(dest_height * ratio))
resized_image = cv2.resize(img, (resized_w, dest_height))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255.0
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((3, dest_height, dest_width), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
至此,方向分类器模型的预处理梳理完毕,下面看其后处理
3.2 后处理
在梳理后处理之前我们下打印下模型推理后的输出维度:
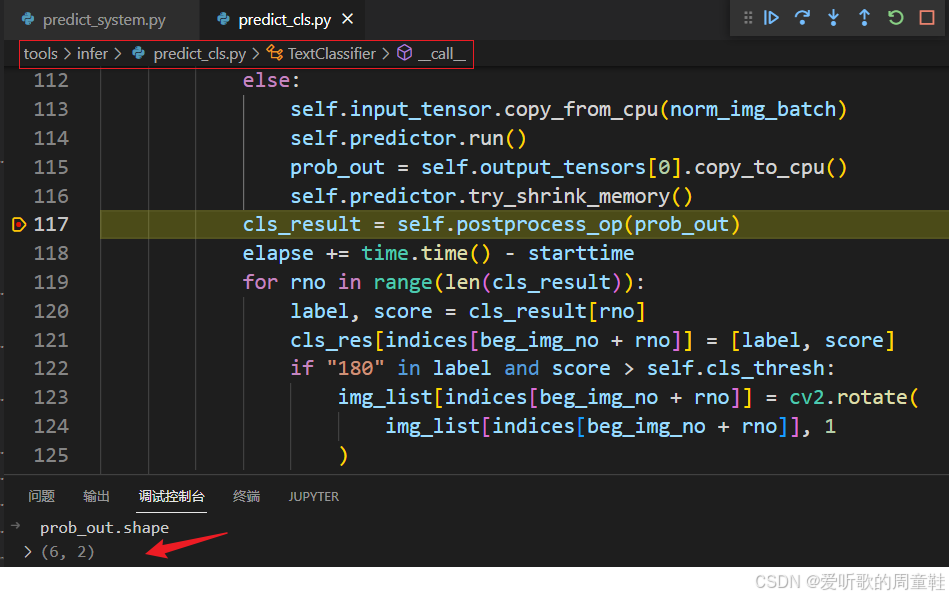
可以看到模型的输出维度是 6x2,其中 6 是 batch 维度,2 代表着预测 0° 和 180° 的概率值,上面文章我们提到过 PP-OCRv4 中的方向分类器只支持 0° 和 180°,因此这里的维度就是 2
接着我们来看后处理都做了哪些操作:
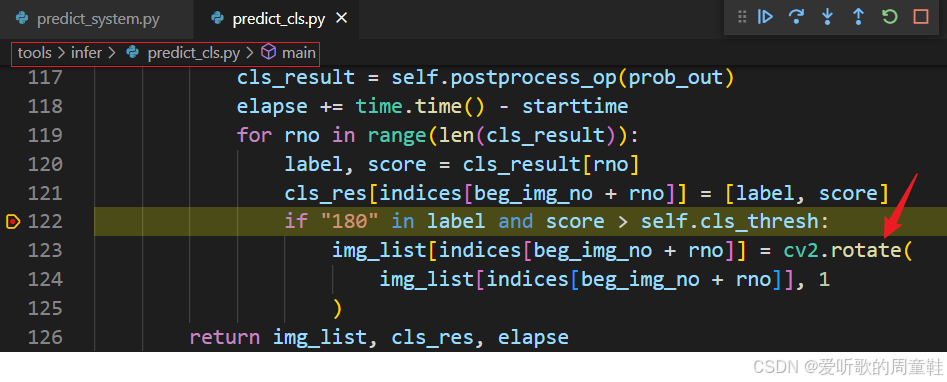
它主要是根据分类标签和得分判断是否需要旋转图像。如果标签包含 "180" 且得分超过阈值,旋转图像 90 度(顺时针)。
因此我们不难写出其后处理,代码如下所示:
def postprocess(self, img_list, imgs_pre_batch, indices):
cls_res = [["", 0.0]] * len(img_list)
for batch in range(len(imgs_pre_batch)):
# infer
cls_pred = self.forward(imgs_pre_batch[batch])
# cls_pred->bx2
pred_idxs = cls_pred.argmax(axis=1)
label_list = ["0", "180"]
cls_result = [(label_list[idx], cls_pred[i, idx]) for i, idx in enumerate(pred_idxs)]
for i in range(len(cls_result)):
label, score = cls_result[i]
cls_res[indices[batch * self.cls_batch_num + i]] = [label, score]
if "180" in label and score > self.cls_thresh:
img_list[indices[batch * self.cls_batch_num + i]] = cv2.rotate(
img_list[indices[batch * self.cls_batch_num + i]], 1)
return img_list, cls_res
至此,方向分类器模型的后处理梳理完毕,下面我们来看推理
3.3 推理
通过上面对方向分类器模型的预处理和后处理分析之后,整个推理过程就显而易见:
class TextClassifier(object):
def __init__(self, model_path, cls_thresh=0.9, cls_batch_num=6) -> None:
self.predictor = ort.InferenceSession(model_path, provider_options=["CPUExecutionProvider"])
self.cls_thresh = cls_thresh
self.cls_batch_num = cls_batch_num
def preprocess(self, img, boxes, tar_w=192, tar_h=48):
img_crop_list = []
for box in boxes:
tmp_box = copy.deepcopy(box)
img_crop = self._get_rotate_crop_image(img, tmp_box)
img_crop_list.append(img_crop)
img_num = len(img_crop_list)
ratio_list = [img.shape[1] / float(img.shape[0]) for img in img_crop_list]
indices = np.argsort(np.array(ratio_list))
imgs_pre_batch = []
for beg_img_idx in range(0, img_num, self.cls_batch_num):
end_img_idx = min(img_num, beg_img_idx + self.cls_batch_num)
norm_img_batch = []
for idx in range(beg_img_idx, end_img_idx):
norm_img = self._resize_norm_img(img_crop_list[indices[idx]], tar_w, tar_h)
norm_img = norm_img[None]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
imgs_pre_batch.append(norm_img_batch)
return img_crop_list, imgs_pre_batch, indices
def forward(self, inputs):
# inputs->bx3x48x196
output = self.predictor.run(None, {"images": inputs})[0]
return output
def postprocess(self, img_list, imgs_pre_batch, indices):
cls_res = [["", 0.0]] * len(img_list)
for batch in range(len(imgs_pre_batch)):
# infer
cls_pred = self.forward(imgs_pre_batch[batch])
# cls_pred->bx2
pred_idxs = cls_pred.argmax(axis=1)
label_list = ["0", "180"]
cls_result = [(label_list[idx], cls_pred[i, idx]) for i, idx in enumerate(pred_idxs)]
for i in range(len(cls_result)):
label, score = cls_result[i]
cls_res[indices[batch * self.cls_batch_num + i]] = [label, score]
if "180" in label and score > self.cls_thresh:
img_list[indices[batch * self.cls_batch_num + i]] = cv2.rotate(
img_list[indices[batch * self.cls_batch_num + i]], 1)
return img_list, cls_res
def _get_rotate_crop_image(self, img, points):
img_crop_width = int(max(np.linalg.norm(points[0] - points[1]), np.linalg.norm(points[2] - points[3])))
img_crop_height = int(max(np.linalg.norm(points[0] - points[3]), np.linalg.norm(points[1] - points[2])))
pts_std = np.float32(
[
[0, 0],
[img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height]
]
)
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M,
(img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC
)
dst_img_height, dst_img_width = dst_img.shape[:2]
if (dst_img_height * 1.0 / dst_img_width) >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def _resize_norm_img(self, img, dest_width, dest_height):
h, w, _ = img.shape
ratio = w / float(h)
if math.ceil(dest_height * ratio) > dest_width:
resized_w = dest_width
else:
resized_w = int(math.ceil(dest_height * ratio))
resized_image = cv2.resize(img, (resized_w, dest_height))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255.0
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((3, dest_height, dest_width), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
方向分类器模型的推理包括图像预处理、模型推理、预测结果后处理三部分,其中预处理主要包括 resize 等操作,后处理主要包括根据预测标签旋转图像
4. 识别模型
最后我们来调试分析下识别模型的前后处理
4.1 预处理
首先看预处理,找到识别模型的入口:
接着找到模型预处理部分:
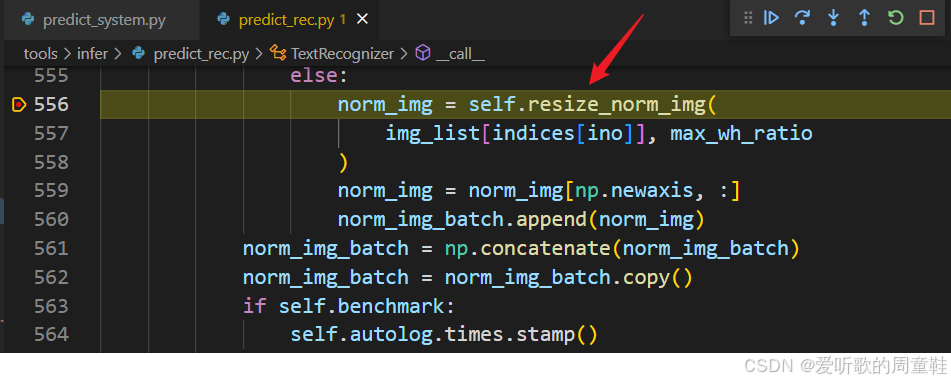
大家可能会发现其实识别模型的预处理和方向分类器的预处理一模一样,它主要包括以下操作:
- 1. resize
- 2. /255.0,将像素值归一化到 [0,1]
- 3. 减均值(0.5)除标准差(0.5),将像素值转换到 [-1,1]
- 4. 填充
因此我们不难写出其预处理,代码如下所示:
def _resize_norm_img(self, img, dest_width, dest_height):
h, w, _ = img.shape
ratio = w / float(h)
if math.ceil(dest_height * ratio) > dest_width:
resized_w = dest_width
else:
resized_w = int(math.ceil(dest_height * ratio))
resized_image = cv2.resize(img, (resized_w, dest_height))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255.0
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((3, dest_height, dest_width), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
至此,识别模型的预处理梳理完毕,下面看其后处理
4.2 后处理
在梳理后处理之前我们先打印下模型推理后的输出维度:
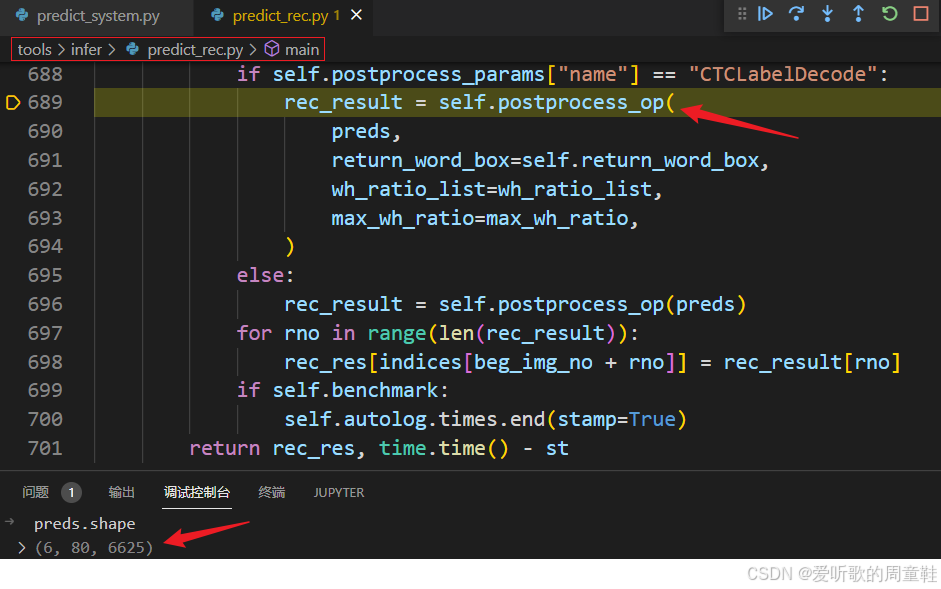
可以看到模型的输出维度是 6x80x6625,分别代表的含义是:
- 6:batch size 大小,表示模型一次处理 6 张图像
- 80:每个图像中可以识别的字符的最大数目,它和模型输入的宽度相关,目前输入宽度是 640,如果设置为 320 该值会变为 40
- 6625:表示每个序列位置的分类输出,这个维度对应于字符集的大小加上一些额外的标记
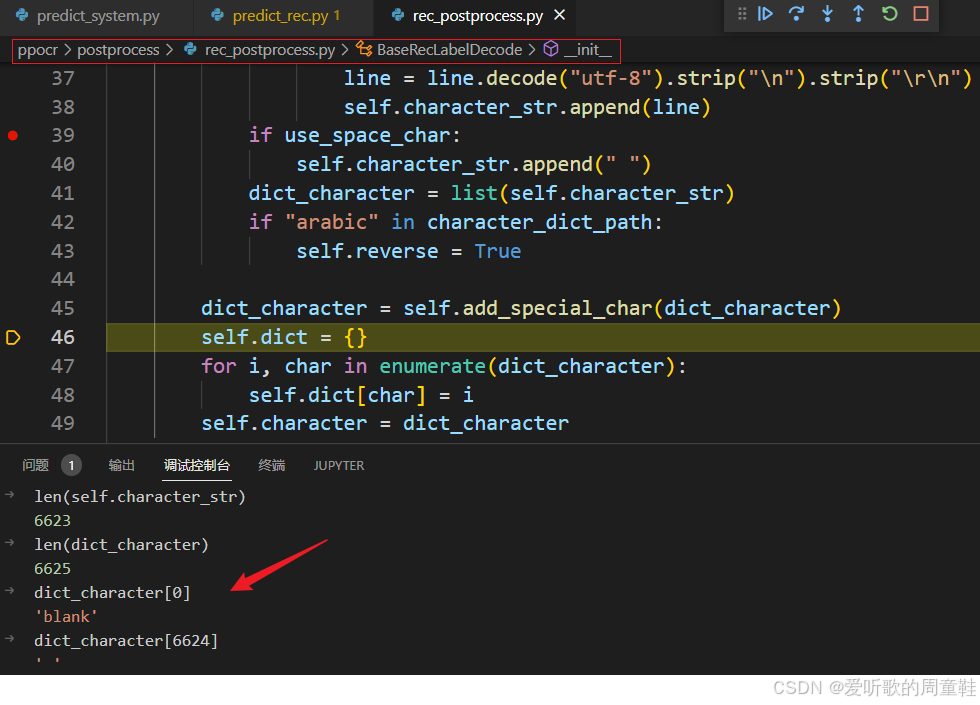
从上图中我们可以清晰的看到原本的字符集长度是 6623,然后再字符集开始添加了 'blank' 字符,结束添加了 ' ' 字符,所以总的字符集长度为 6625,对应识别模型的输出维度
接着我们来看后处理都做了哪些操作:
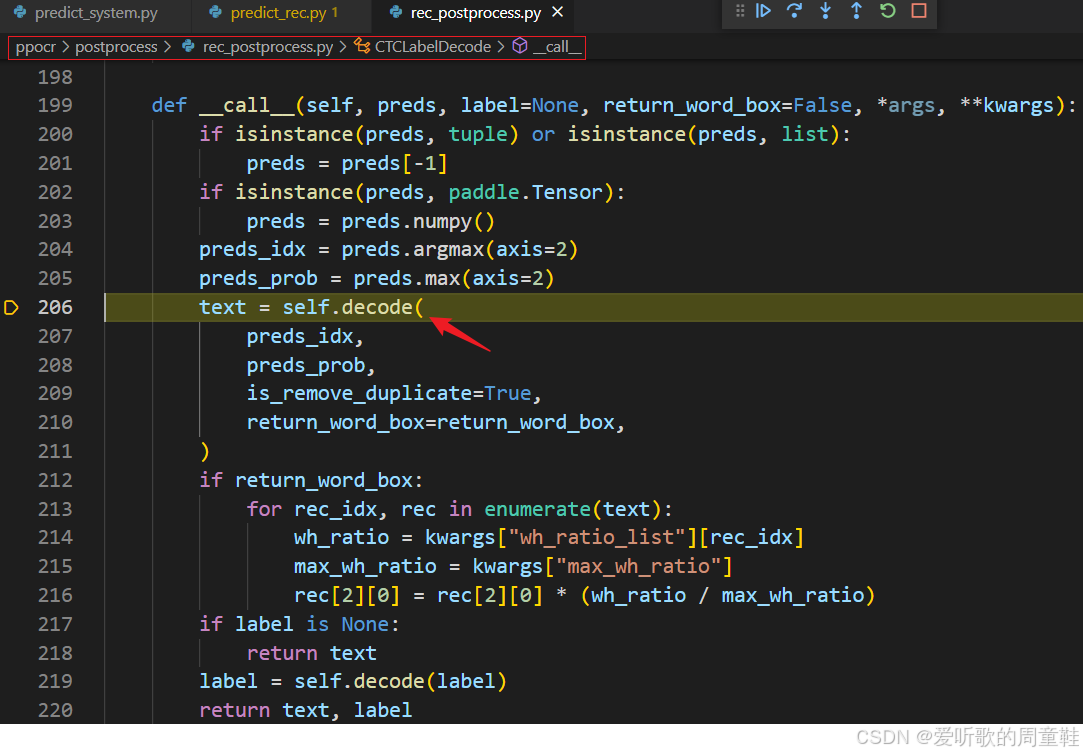
它主要是通过 decode 函数对预测结果进行解码,我们重点来看下该函数的实现:
def decode(
self,
text_index,
text_prob=None,
is_remove_duplicate=False,
return_word_box=False,
):
"""convert text-index into text-label."""
result_list = []
ignored_tokens = self.get_ignored_tokens()
batch_size = len(text_index)
for batch_idx in range(batch_size):
selection = np.ones(len(text_index[batch_idx]), dtype=bool)
if is_remove_duplicate:
selection[1:] = text_index[batch_idx][1:] != text_index[batch_idx][:-1]
for ignored_token in ignored_tokens:
selection &= text_index[batch_idx] != ignored_token
char_list = [
self.character[text_id] for text_id in text_index[batch_idx][selection]
]
if text_prob is not None:
conf_list = text_prob[batch_idx][selection]
else:
conf_list = [1] * len(selection)
if len(conf_list) == 0:
conf_list = [0]
text = "".join(char_list)
if self.reverse: # for arabic rec
text = self.pred_reverse(text)
if return_word_box:
word_list, word_col_list, state_list = self.get_word_info(
text, selection
)
result_list.append(
(
text,
np.mean(conf_list).tolist(),
[
len(text_index[batch_idx]),
word_list,
word_col_list,
state_list,
],
)
)
else:
result_list.append((text, np.mean(conf_list).tolist()))
return result_list
这个 decode 函数的主要目的是将文本识别模型的输出(索引和概率)转换为可读的文本标签,它的主要功能有:
- 处理字符索引: 根据模型的字符索引生成文本字符串,并移除重复字符或忽略特定字符。
- 置信度处理: 计算并存储每个字符的置信度分数,如果未提供置信度,则使用默认值。
- 返回解码结果: 返回包括文本和及其置信度的解码结果列表。
返回的结果如下图所示:
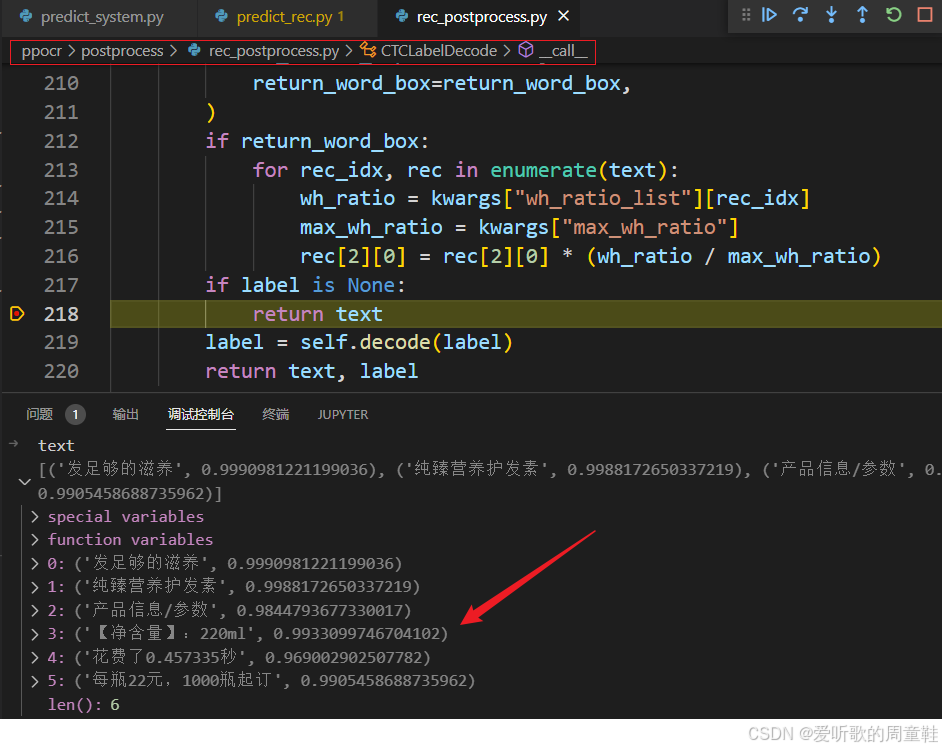
因此我们不难写出其后处理,代码如下所示:
def postprocess(self, imgs_pre_batch, indices):
rec_res = [["", 0.0]] * len(indices)
for batch in range(len(imgs_pre_batch)):
# infer
rec_pred = self.forward(imgs_pre_batch[batch])
# rec_pred->bx80x6625
preds_idx = rec_pred.argmax(axis=2)
preds_prob = rec_pred.max(axis=2)
text = self._decode(preds_idx, preds_prob)
for i in range(len(text)):
rec_res[indices[batch * self.rec_batch_num + i]] = text[i]
return rec_res
def _decode(self, text_index, text_prob):
"convert text-index into text-label"
result_list = []
batch_size = len(text_index)
for batch_idx in range(batch_size):
selection = np.ones(len(text_index[0]), dtype=bool)
selection[1:] = text_index[batch_idx][1:] != text_index[batch_idx][:-1]
selection &= text_index[batch_idx] != 0
char_list = [self.character_str[text_id] for text_id in text_index[batch_idx][selection]]
conf_list = text_prob[batch_idx][selection]
if len(conf_list) == 0:
conf_list = 0
text = "".join(char_list)
result_list.append((text, np.mean(conf_list).tolist()))
return result_list
至此,识别模型的后处理梳理完毕,下面我们来看推理
4.3 推理
通过上面对识别模型的预处理和后处理分析之后,整个推理过程就显而易见:
class TextRecognizer(object):
def __init__(self, model_path, character_dict_path, rec_batch_num=6) -> None:
self.predictor = ort.InferenceSession(model_path, provider_options=["CPUExecutionProvider"])
self.character_str = []
self.rec_batch_num = rec_batch_num
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode("utf-8").strip("\n").strip("\r\n")
self.character_str.append(line)
self.character_str.append(" ")
self.character_str = ["blank"] + self.character_str
self.dict = {}
for i, char in enumerate(self.character_str):
self.dict[char] = i
def preprocess(self, img_list, tar_w=640, tar_h=48):
# for img in img_list:
# plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# plt.show()
img_num = len(img_list)
ratio_list = [img.shape[1] / float(img.shape[0]) for img in img_list]
indices = np.argsort(np.array(ratio_list))
imgs_pre_batch = []
for beg_img_idx in range(0, img_num, self.rec_batch_num):
end_img_idx = min(img_num, beg_img_idx + self.rec_batch_num)
norm_img_batch = []
for idx in range(beg_img_idx, end_img_idx):
norm_img = self._resize_norm_img(img_list[indices[idx]], tar_w, tar_h)
# processed_img = norm_img.transpose(1, 2, 0)
# processed_img = (processed_img * 0.5 + 0.5) * 255
# processed_img = processed_img.astype(np.uint8)
# plt.imshow(cv2.cvtColor(processed_img, cv2.COLOR_BGR2RGB))
# plt.show()
norm_img = norm_img[None]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
imgs_pre_batch.append(norm_img_batch)
return imgs_pre_batch, indices
def forward(self, inputs):
# inputs->bx3x48x640
output = self.predictor.run(None, {"images": inputs})[0]
return output
def postprocess(self, imgs_pre_batch, indices):
rec_res = [["", 0.0]] * len(indices)
for batch in range(len(imgs_pre_batch)):
# infer
rec_pred = self.forward(imgs_pre_batch[batch])
# rec_pred->bx80x6625
preds_idx = rec_pred.argmax(axis=2)
preds_prob = rec_pred.max(axis=2)
text = self._decode(preds_idx, preds_prob)
for i in range(len(text)):
rec_res[indices[batch * self.rec_batch_num + i]] = text[i]
return rec_res
def _resize_norm_img(self, img, dest_width, dest_height):
h, w, _ = img.shape
ratio = w / float(h)
if math.ceil(dest_height * ratio) > dest_width:
resized_w = dest_width
else:
resized_w = int(math.ceil(dest_height * ratio))
resized_image = cv2.resize(img, (resized_w, dest_height))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255.0
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((3, dest_height, dest_width), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
def _decode(self, text_index, text_prob):
"convert text-index into text-label"
result_list = []
batch_size = len(text_index)
for batch_idx in range(batch_size):
selection = np.ones(len(text_index[0]), dtype=bool)
selection[1:] = text_index[batch_idx][1:] != text_index[batch_idx][:-1]
selection &= text_index[batch_idx] != 0
char_list = [self.character_str[text_id] for text_id in text_index[batch_idx][selection]]
conf_list = text_prob[batch_idx][selection]
if len(conf_list) == 0:
conf_list = 0
text = "".join(char_list)
result_list.append((text, np.mean(conf_list).tolist()))
return result_list
识别模型的推理包括图像预处理、模型推理、预测结果后处理三部分,其中预处理主要包括 resize 等操作,后处理主要将模型的输出转换为文本标签
至此,PP-OCRv4 中的三个模型的前后处理都已经梳理完毕,下面我们简单看下可视化部分
5. 可视化
在拿到对应的文本框和文本内容后可以进行可视化:
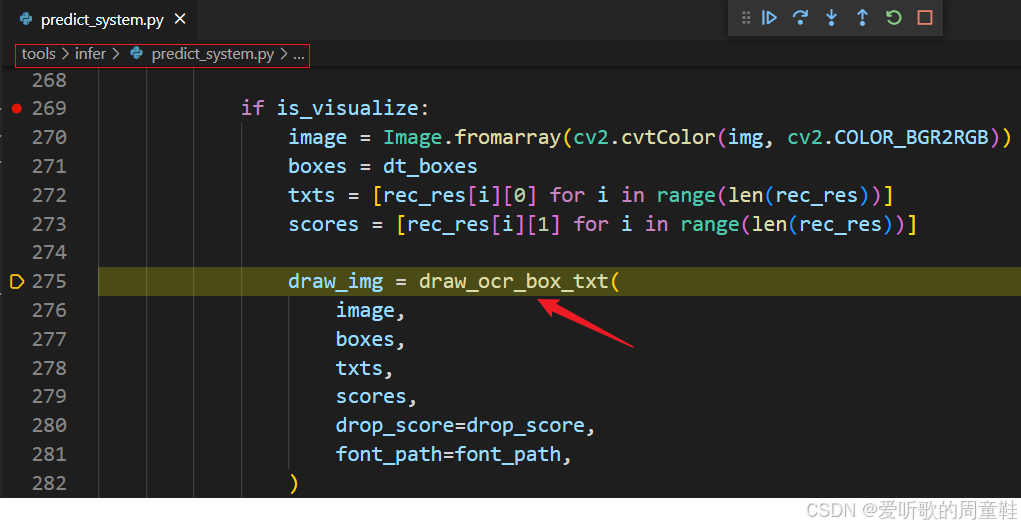
主要是通过 draw_ocr_box_txt 函数,我们重点看下该函数:
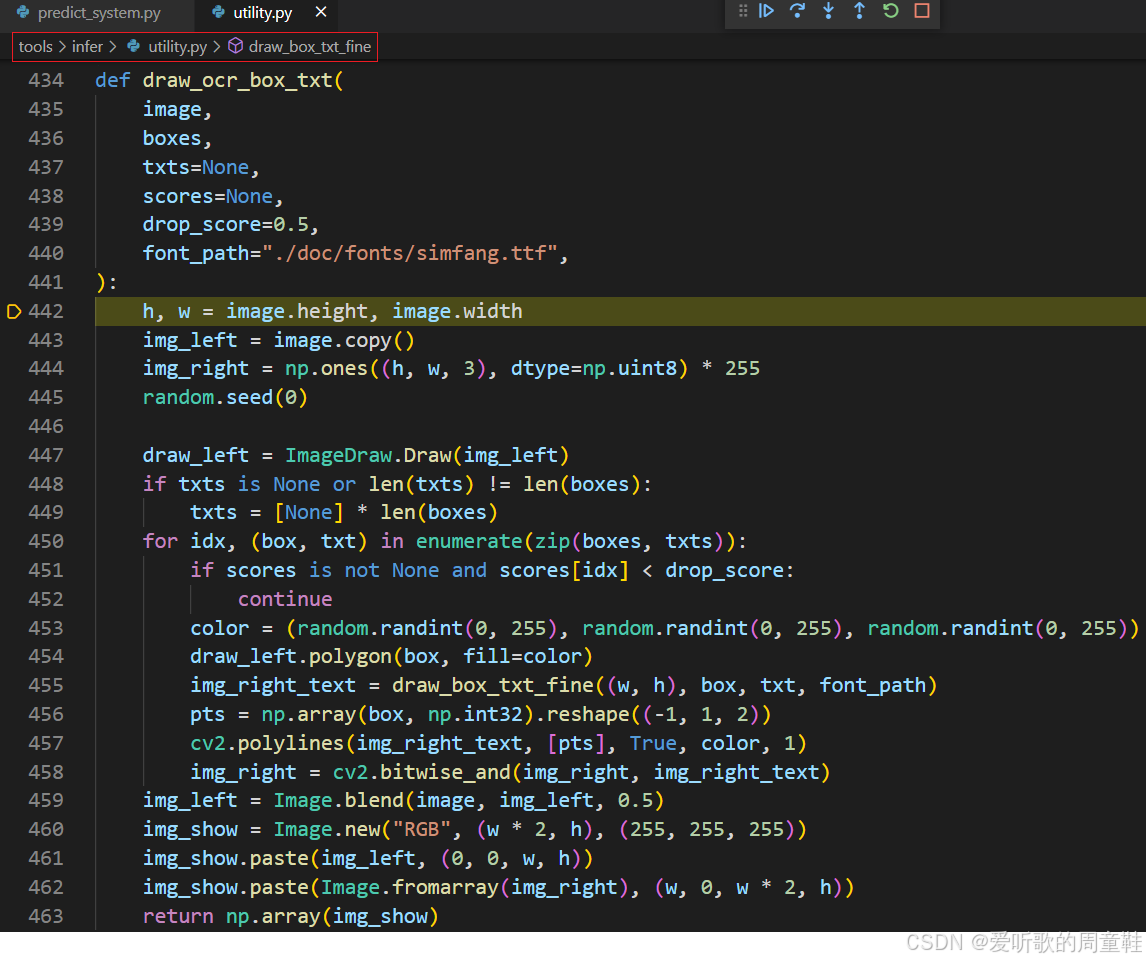
draw_ocr_box_txt 函数负责绘制文本框及其内容,它包含以下步骤:
- 创建一个
ImageDraw对象,用于在img_left上绘制多边形(文本框) - 检查文本识别置信度 score,如果其值低于
drop_score,则跳过该文本框的绘制 - 调用
polygon绘制每个文本框 - 调用
draw_box_txt_fine函数在img_right_text上绘制文本框内的文本 - 使用 OpenCV 的
cv2.polylines绘制文本框边界 - 使用位运算将文本绘制在
img_right图像上。 - 将原始图像与包含文本框的图像
img_left进行融合,生成一个混合图像 - 创建一个新图像
img_show,将原始图像和带有文本的图像拼接在一起。 - 将最终合成的图像转换为 numpy 数组并返回。
其中的 draw_box_txt_fine 函数内容如下:
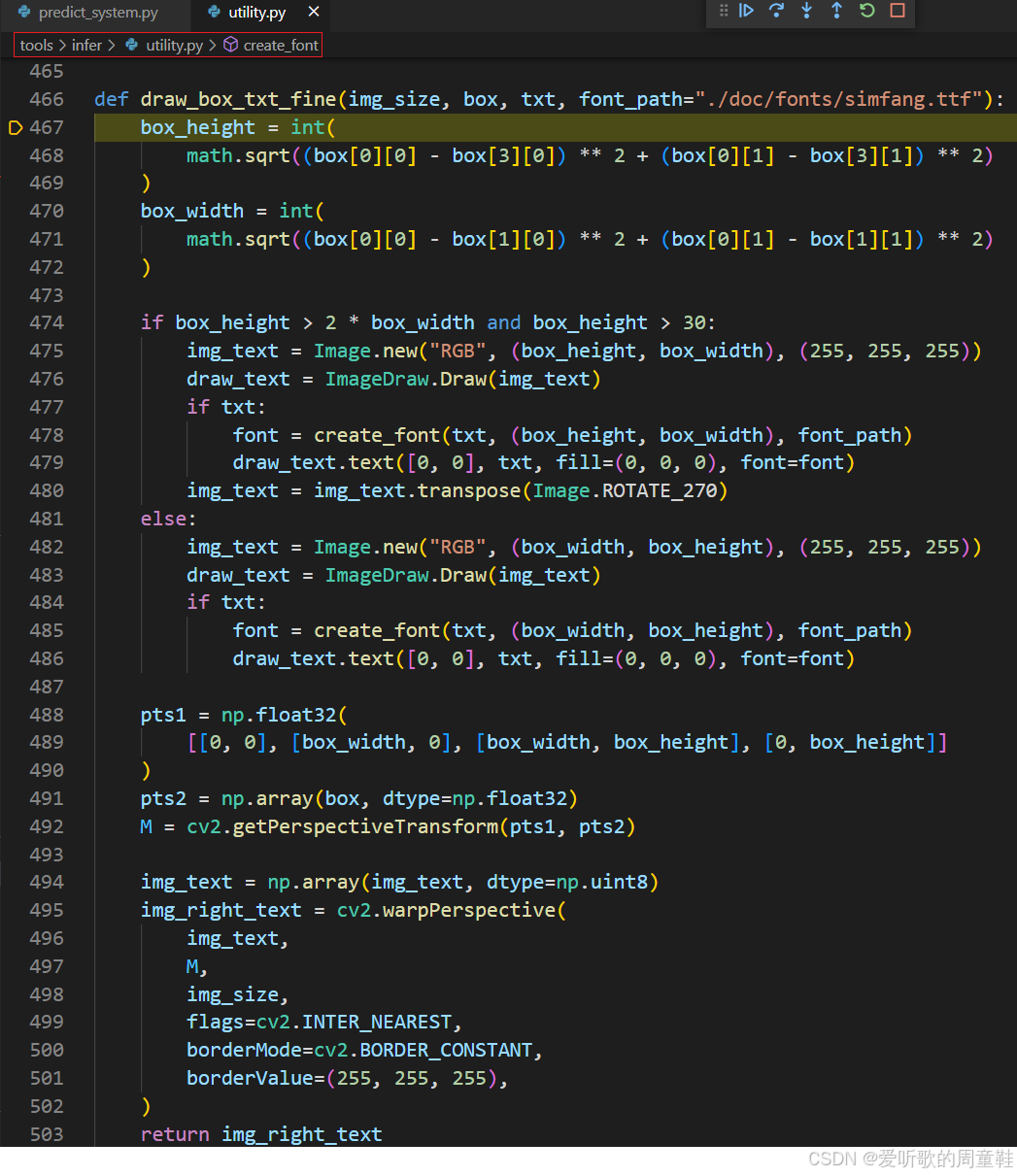
draw_box_txt_fine 函数负责在给定的文本框区域内绘制文本,并将其透视变换到原始图像中对应的位置,它包含以下步骤:
- 计算文本框的尺寸
- 创建文本图像
- 根据文本框的宽度和高度创建一个新的图像
img_text - 使用
create_font函数创建字体,并在图像上绘制文本
- 根据文本框的宽度和高度创建一个新的图像
- 透视变换
- 定义一个矩形区域(
pts1)和文本框的四个顶点(pts2) - 使用 OpenCV 的
cv2.getPerspectiveTransform计算透视变换矩阵M - 使用
cv2.warpPerspective将img_text变换到文本框的位置img_right_text
- 定义一个矩形区域(
- 返回变换后的图像
img_right_text
6. PP-OCRv4推理
前面我们梳理了 PP-OCRv4 中三个模型的推理以及可视化,下面我们来看看完整的推理代码:
import cv2
import math
import copy
import random
import numpy as np
import onnxruntime as ort
import matplotlib.pyplot as plt
from PIL import Image, ImageFont, ImageDraw
import pyclipper
from shapely.geometry import Polygon
class TextDetector(object):
def __init__(self, model_path, mask_thresh=0.3, box_thresh=0.6,
max_candidates=1000, min_size=3, unclip_ratio=1.5) -> None:
self.predictor = ort.InferenceSession(model_path, provider_options=["CPUExecutionProvider"])
self.mask_thresh = mask_thresh
self.box_thresh = box_thresh
self.max_candidates = max_candidates
self.min_size = min_size
self.unclip_ratio = unclip_ratio
def preprocess(self, img, tar_w=960, tar_h=960):
# 1. resize
img = cv2.resize(img, (int(tar_w), int(tar_h)))
# 2. normalize
img = img.astype("float32") / 255.0
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape(1, 1, 3).astype("float32")
std = np.array(std).reshape(1, 1, 3).astype("float32")
img = (img - mean) / std
# 3. to bchw
img = img.transpose((2, 0, 1))[None]
return img
def forward(self, input):
# input->1x3x960x960
output = self.predictor.run(None, {"images": input})[0]
return output
def postprocess(self, pred, src_h, src_w):
# pred->1x1x960x960
pred = pred[0, 0, :, :]
mask = pred > self.mask_thresh
boxes, _ = self._boxes_from_bitmap(pred, mask, src_w, src_h)
boxes = self._filter_boxes(boxes, src_h, src_w)
boxes = self._sorted_boxes(boxes)
return boxes
def _boxes_from_bitmap(self, pred, bitmap, dest_width, dest_height):
"""
bitmap: single map with shape (H, W),
whose values are binarized as {0, 1}
"""
height, width = bitmap.shape
# bitmap_image = (bitmap * 255).astype(np.uint8)
# cv2.imwrite("bitmap_image.jpg", bitmap_image)
outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
if len(outs) == 3:
_, contours, _ = outs[0], outs[1], outs[2] # opencv3.x
elif len(outs) == 2:
contours, _ = outs[0], outs[1] # opencv4.x
num_contours = min(len(contours), self.max_candidates)
# contour_image = cv2.cvtColor(bitmap_image, cv2.COLOR_GRAY2BGR)
# for contour in contours:
# cv2.drawContours(contour_image, [contour], -1, (0, 0, 255), 2)
# cv2.imwrite('contour_image.jpg', contour_image)
boxes = []
scores = []
for index in range(num_contours):
contour = contours[index]
points, sside = self._get_mini_boxes(contour)
if sside < self.min_size:
continue
points = np.array(points)
score = self._box_score(pred, points.reshape(-1, 2))
if score < self.box_thresh:
continue
box = self._unclip(points, self.unclip_ratio)
if len(box) > 1:
continue
box = np.array(box).reshape(-1, 1, 2)
box, sside = self._get_mini_boxes(box)
if sside < self.min_size + 2:
continue
box = np.array(box)
box[:, 0] = np.clip(np.round(box[:, 0] / width * dest_width), 0, dest_width)
box[:, 1] = np.clip(np.round(box[:, 1] / height * dest_height), 0, dest_height)
boxes.append(box.astype("int32"))
scores.append(score)
return np.array(boxes, dtype="int32"), scores
def _get_mini_boxes(self, contour):
# [[center_x, center_y], [width, height], angle]
bounding_box = cv2.minAreaRect(contour)
points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
index_1, index_2, index_3, index_4 = 0, 1, 2, 3
if points[1][1] > points[0][1]:
index_1 = 0
index_4 = 1
else:
index_1 = 1
index_4 = 0
if points[3][1] > points[2][1]:
index_2 = 2
index_3 = 3
else:
index_2 = 3
index_3 = 2
box = [points[index_1], points[index_2], points[index_3], points[index_4]]
return box, min(bounding_box[1])
def _box_score(self, bitmap, _box):
"""
box_score: use bbox mean score as the mean score
"""
h, w = bitmap.shape[:2]
box = _box.copy()
xmin = np.clip(np.floor(box[:, 0].min()).astype("int32"), 0, w - 1)
xmax = np.clip(np.ceil(box[:, 0].max()).astype("int32"), 0, w - 1)
ymin = np.clip(np.floor(box[:, 1].min()).astype("int32"), 0, h - 1)
ymax = np.clip(np.ceil(box[:, 1].max()).astype("int32"), 0, h - 1)
mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
box[:, 0] = box[:, 0] - xmin
box[:, 1] = box[:, 1] - ymin
cv2.fillPoly(mask, box.reshape(1, -1, 2).astype("int32"), 1)
return cv2.mean(bitmap[ymin : ymax + 1, xmin : xmax + 1], mask)[0]
def _unclip(self, box, unclip_ratio):
poly = Polygon(box)
distance = poly.area * unclip_ratio / poly.length
offset = pyclipper.PyclipperOffset()
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = offset.Execute(distance)
return expanded
def _filter_boxes(self, boxes, src_h, src_w):
boxes_filter = []
for box in boxes:
box = self._order_points_clockwise(box)
box = self._clip(box, src_h, src_w)
rect_width = int(np.linalg.norm(box[0] - box[1]))
rect_height = int(np.linalg.norm(box[0] - box[3]))
if rect_width <= 3 or rect_height <= 3:
continue
boxes_filter.append(box)
return np.array(boxes_filter)
def _order_points_clockwise(self, pts):
rect = np.zeros((4, 2), dtype="float32")
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
tmp = np.delete(pts, (np.argmin(s), np.argmax(s)), axis=0)
diff = np.diff(np.array(tmp), axis=1)
rect[1] = tmp[np.argmin(diff)]
rect[3] = tmp[np.argmax(diff)]
return rect
def _clip(self, points, img_height, img_width):
for idx in range(points.shape[0]):
points[idx, 0] = int(min(max(points[idx, 0], 0), img_width - 1))
points[idx, 1] = int(min(max(points[idx, 1], 0), img_height - 1))
return points
def _sorted_boxes(self, boxes):
"""
Sort text boxes in order from top to bottom, left to right
"""
num_boxes = boxes.shape[0]
boxes_sorted = sorted(boxes, key=lambda x: (x[0][1], x[0][0]))
_boxes = list(boxes_sorted)
for i in range(num_boxes - 1):
for j in range(i, -1, -1):
if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and (_boxes[j + 1][0][0] < _boxes[j][0][0]):
tmp = _boxes[j]
_boxes[j] = _boxes[j + 1]
_boxes[j + 1] = tmp
else:
break
return _boxes
class TextClassifier(object):
def __init__(self, model_path, cls_thresh=0.9, cls_batch_num=6) -> None:
self.predictor = ort.InferenceSession(model_path, provider_options=["CPUExecutionProvider"])
self.cls_thresh = cls_thresh
self.cls_batch_num = cls_batch_num
def preprocess(self, img, boxes, tar_w=192, tar_h=48):
img_crop_list = []
for box in boxes:
tmp_box = copy.deepcopy(box)
img_crop = self._get_rotate_crop_image(img, tmp_box)
img_crop_list.append(img_crop)
img_num = len(img_crop_list)
ratio_list = [img.shape[1] / float(img.shape[0]) for img in img_crop_list]
indices = np.argsort(np.array(ratio_list))
imgs_pre_batch = []
for beg_img_idx in range(0, img_num, self.cls_batch_num):
end_img_idx = min(img_num, beg_img_idx + self.cls_batch_num)
norm_img_batch = []
for idx in range(beg_img_idx, end_img_idx):
norm_img = self._resize_norm_img(img_crop_list[indices[idx]], tar_w, tar_h)
norm_img = norm_img[None]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
imgs_pre_batch.append(norm_img_batch)
return img_crop_list, imgs_pre_batch, indices
def forward(self, inputs):
# inputs->bx3x48x196
output = self.predictor.run(None, {"images": inputs})[0]
return output
def postprocess(self, img_list, imgs_pre_batch, indices):
cls_res = [["", 0.0]] * len(img_list)
for batch in range(len(imgs_pre_batch)):
# infer
cls_pred = self.forward(imgs_pre_batch[batch])
# cls_pred->bx2
pred_idxs = cls_pred.argmax(axis=1)
label_list = ["0", "180"]
cls_result = [(label_list[idx], cls_pred[i, idx]) for i, idx in enumerate(pred_idxs)]
for i in range(len(cls_result)):
label, score = cls_result[i]
cls_res[indices[batch * self.cls_batch_num + i]] = [label, score]
if "180" in label and score > self.cls_thresh:
img_list[indices[batch * self.cls_batch_num + i]] = cv2.rotate(
img_list[indices[batch * self.cls_batch_num + i]], 1)
return img_list, cls_res
def _get_rotate_crop_image(self, img, points):
img_crop_width = int(max(np.linalg.norm(points[0] - points[1]), np.linalg.norm(points[2] - points[3])))
img_crop_height = int(max(np.linalg.norm(points[0] - points[3]), np.linalg.norm(points[1] - points[2])))
pts_std = np.float32(
[
[0, 0],
[img_crop_width, 0],
[img_crop_width, img_crop_height],
[0, img_crop_height]
]
)
M = cv2.getPerspectiveTransform(points, pts_std)
dst_img = cv2.warpPerspective(
img,
M,
(img_crop_width, img_crop_height),
borderMode=cv2.BORDER_REPLICATE,
flags=cv2.INTER_CUBIC
)
dst_img_height, dst_img_width = dst_img.shape[:2]
if (dst_img_height * 1.0 / dst_img_width) >= 1.5:
dst_img = np.rot90(dst_img)
return dst_img
def _resize_norm_img(self, img, dest_width, dest_height):
h, w, _ = img.shape
ratio = w / float(h)
if math.ceil(dest_height * ratio) > dest_width:
resized_w = dest_width
else:
resized_w = int(math.ceil(dest_height * ratio))
resized_image = cv2.resize(img, (resized_w, dest_height))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255.0
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((3, dest_height, dest_width), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
class TextRecognizer(object):
def __init__(self, model_path, character_dict_path, rec_batch_num=6) -> None:
self.predictor = ort.InferenceSession(model_path, provider_options=["CPUExecutionProvider"])
self.character_str = []
self.rec_batch_num = rec_batch_num
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode("utf-8").strip("\n").strip("\r\n")
self.character_str.append(line)
self.character_str.append(" ")
self.character_str = ["blank"] + self.character_str
self.dict = {}
for i, char in enumerate(self.character_str):
self.dict[char] = i
def preprocess(self, img_list, tar_w=640, tar_h=48):
# for img in img_list:
# plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# plt.show()
img_num = len(img_list)
ratio_list = [img.shape[1] / float(img.shape[0]) for img in img_list]
indices = np.argsort(np.array(ratio_list))
imgs_pre_batch = []
for beg_img_idx in range(0, img_num, self.rec_batch_num):
end_img_idx = min(img_num, beg_img_idx + self.rec_batch_num)
norm_img_batch = []
for idx in range(beg_img_idx, end_img_idx):
norm_img = self._resize_norm_img(img_list[indices[idx]], tar_w, tar_h)
# processed_img = norm_img.transpose(1, 2, 0)
# processed_img = (processed_img * 0.5 + 0.5) * 255
# processed_img = processed_img.astype(np.uint8)
# plt.imshow(cv2.cvtColor(processed_img, cv2.COLOR_BGR2RGB))
# plt.show()
norm_img = norm_img[None]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
imgs_pre_batch.append(norm_img_batch)
return imgs_pre_batch, indices
def forward(self, inputs):
# inputs->bx3x48x640
output = self.predictor.run(None, {"images": inputs})[0]
return output
def postprocess(self, imgs_pre_batch, indices):
rec_res = [["", 0.0]] * len(indices)
for batch in range(len(imgs_pre_batch)):
# infer
rec_pred = self.forward(imgs_pre_batch[batch])
# rec_pred->bx80x6625
preds_idx = rec_pred.argmax(axis=2)
preds_prob = rec_pred.max(axis=2)
text = self._decode(preds_idx, preds_prob)
for i in range(len(text)):
rec_res[indices[batch * self.rec_batch_num + i]] = text[i]
return rec_res
def _resize_norm_img(self, img, dest_width, dest_height):
h, w, _ = img.shape
ratio = w / float(h)
if math.ceil(dest_height * ratio) > dest_width:
resized_w = dest_width
else:
resized_w = int(math.ceil(dest_height * ratio))
resized_image = cv2.resize(img, (resized_w, dest_height))
resized_image = resized_image.astype("float32")
resized_image = resized_image.transpose((2, 0, 1)) / 255.0
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((3, dest_height, dest_width), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
def _decode(self, text_index, text_prob):
"convert text-index into text-label"
result_list = []
batch_size = len(text_index)
for batch_idx in range(batch_size):
selection = np.ones(len(text_index[0]), dtype=bool)
selection[1:] = text_index[batch_idx][1:] != text_index[batch_idx][:-1]
selection &= text_index[batch_idx] != 0
char_list = [self.character_str[text_id] for text_id in text_index[batch_idx][selection]]
conf_list = text_prob[batch_idx][selection]
if len(conf_list) == 0:
conf_list = 0
text = "".join(char_list)
result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def create_font(txt, sz, font_path):
font_size = int(sz[1] * 0.99)
font = ImageFont.truetype(font_path, font_size, encoding="utf-8")
length = font.getlength(txt)
if(length > sz[0]):
font_size = int(font_size * sz[0] / length)
font = ImageFont.truetype(font_path, font_size, encoding="utf-8")
return font
def draw_box_txt(img_size, box, txt, font_path=None):
box_height = int(np.linalg.norm(box[0] - box[3]))
box_width = int(np.linalg.norm(box[0] - box[1]))
if box_height > 2 * box_width and box_height > 30:
img_text = Image.new("RGB", (box_height, box_width), (255, 255, 255))
draw_text = ImageDraw.Draw(img_text)
font = create_font(txt, (box_height, box_width), font_path)
draw_text.text([0, 0], txt, fill=(0, 0, 0), font=font)
img_text = img_text.transpose(Image.ROTATE_270)
else:
img_text = Image.new("RGB", (box_width, box_height), (255, 255, 255))
draw_text = ImageDraw.Draw(img_text)
font = create_font(txt, (box_width, box_height), font_path)
draw_text.text([0, 0], txt, fill=(0, 0, 0), font=font)
pts1 = np.float32([[0, 0], [box_width, 0], [box_width, box_height], [0, box_height]])
pts2 = np.array(box, dtype=np.float32)
M = cv2.getPerspectiveTransform(pts1, pts2)
img_text = np.array(img_text, dtype=np.uint8)
img_right_text = cv2.warpPerspective(
img_text,
M,
img_size,
flags=cv2.INTER_NEAREST,
borderMode=cv2.BORDER_CONSTANT,
borderValue=(255, 255, 255)
)
return img_right_text
def draw_ocr_box_txt(image, boxes, txts, scores, font_path=None, drop_score=0.5):
image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
h, w = image.height, image.width
img_left = image.copy()
img_right = np.ones((h, w, 3), dtype=np.uint8) * 255
random.seed(0)
draw_left = ImageDraw.Draw(img_left)
if txts is None or len(txts) != len(boxes):
txts = [None] * len(boxes)
for idx, (box, txt) in enumerate(zip(boxes, txts)):
if scores is not None and scores[idx] < drop_score:
continue
color = tuple(random.randint(0, 255) for _ in range(3))
draw_left.polygon(box, fill=color)
img_right_text = draw_box_txt((w, h), box, txt, font_path)
pts = np.array(box, np.int32).reshape((-1, 1, 2))
cv2.polylines(img_right_text, [pts], True, color, 1)
img_right = cv2.bitwise_and(img_right, img_right_text)
img_left = Image.blend(image, img_left, 0.5)
img_show = Image.new("RGB", (w * 2, h), (255, 255, 255))
img_show.paste(img_left, (0, 0, w, h))
img_show.paste(Image.fromarray(img_right), (w, 0, w * 2, h))
return np.array(img_show)
if __name__ == "__main__":
image = cv2.imread("deploy/lite/imgs/lite_demo.png")
src_h, src_w, _ = image.shape
det_model_file_path = "models/det/det.sim.onnx"
cls_model_file_path = "models/cls/cls.sim.onnx"
rec_model_file_path = "models/rec/rec.sim.onnx"
character_dict_path = "ppocr/utils/ppocr_keys_v1.txt"
font_path = "doc/fonts/simfang.ttf"
# 1. text detection
text_detector = TextDetector(det_model_file_path)
img_pre = text_detector.preprocess(image)
det_pred = text_detector.forward(img_pre)
det_boxes = text_detector.postprocess(det_pred, src_h, src_w)
# 2. text classification
if det_boxes is None:
print("warning, no det_boxes found")
exit()
else:
print(f"det_boxes num: {len(det_boxes)}")
text_classifier = TextClassifier(cls_model_file_path)
img_list, imgs_pre_batch, indices = text_classifier.preprocess(image, det_boxes)
img_list, _ = text_classifier.postprocess(img_list, imgs_pre_batch, indices)
# 3. text recognition
text_recognizer = TextRecognizer(rec_model_file_path, character_dict_path)
imgs_pre_batch, indices = text_recognizer.preprocess(img_list)
rec_txts = text_recognizer.postprocess(imgs_pre_batch, indices)
# 4. visualization
txts = [rec_txts[i][0] for i in range(len(rec_txts))]
scores = [rec_txts[i][1] for i in range(len(rec_txts))]
draw_img = draw_ocr_box_txt(image, det_boxes, txts, scores, font_path)
cv2.imwrite("result.jpg", draw_img[:, :, ::-1])
执行该代码在当前目录下会保存 result.jpg 推理的图片,如下图所示:

可以看到效果还是不错的,和 PaddlePaddle 推理的结果差不多,这说明我们梳理的各个模型的前后处理没有问题
最后我们再来看一下其它图片的推理结果:



结语
这篇文章我们主要梳理了 PP-OCRv4 中的检测、方向分类器以及识别三个模块的前后处理,整个代码还是比较清晰的,只是某些步骤可能有些繁琐,大家稍微细心一些就行
OK,以上就是 PP-OCRv4 前后处理梳理的全部内容了,下篇我们来看看如何在 TensorRT 上推理得到结果,敬请期待😄