[实验目的]
- 熟悉Apache Web服务器的日志文件格式;
- 熟悉在Spark中分析Web服务器日志。
[实验原理]
服务器日志分析是Spark一个理想的应用场景。日志文件通常很大,Spark能够以低成本存储这些日志,同时提供简单而高效的方式进行分析。日志分析对于改善商业运营、建立推荐系统和欺诈检测都十分有用。
1. 常见日志格式
Apache Web服务器日志的每一行格式与下面的例子类似。
127.0.0.1 - - [01/Aug/1995:00:00:01 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1839
其中各部分的定义描述如下。
- 127.0.0.1,请求服务的客户端IP地址;
- -,远程机器的用户身份,“-”表示信息无法获取;
- -,本地登录的用户身份,“-”表示信息无法获取;
- [01/Aug/1995:00:00:01 -0400],服务器处理完请求的时间,其格式为“[日/月/年:时:分:秒 时区]”;
- "GET /images/launch-logo.gif HTTP/1.0",请求字符串的第一行,包含了请求方法(Get、Post等等)、资源标识符和客户端协议版本;
- 200, 服务器发送给客户端的状态代码,包括响应成功(代码以2开头)、跳转(代码以3开头)、客户端错误(代码以4开头)或服务器错误(代码以5开头);
- 1839,返回客户端的内容大小。
2. 所涉及变换函数和动作函数
本实验涉及到的几个新的动作函数有以下这些。
- 函数min(),返回RDD中的最小元素;
- 函数max(),返回RDD中的最大元素。
3. 实验数据
本实验使用的数据集是美国国家航天局(NASA)位于美国佛罗里达数据中心的Web服务器日志,截取了大约100万条记录。数据集已经存放在HDFS上,路径为“/data/12/3/”。
[实验步骤]
1. 定义函数解析日志行
首先载入所需的类库。再定义一个月份名称与数字的字典以及日志行的正则表达式。然后定义函数 parse_apache_time() ,将日志行中的日期字符串转换为Python的 datetime 对象。最后定义函数 parseApacheLogLine() ,调用正则表达式匹配函数 search() 解析出日志行的9个字段,如果日志行能够成功匹配正则表达式则返回包含 Row 对象和1的二元列表,否则则返回包含原始日志行字符串和0的二元列表。所有的“-”都会被替换成0。
>>> import re
>>> import datetime
>>>
>>> from pyspark.sql import Row
>>>
>>> month_map = {'Jan': 1, 'Feb': 2, 'Mar':3, 'Apr':4, 'May':5, 'Jun':6, 'Jul':7,
... 'Aug':8, 'Sep': 9, 'Oct':10, 'Nov': 11, 'Dec': 12}
>>>
>>> APACHE_ACCESS_LOG_PATTERN = '^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+)\s*(\S*)\s*" (\d{3}) (\S+)'
>>>
>>> def parse_apache_time(s):
... return datetime.datetime(int(s[7:11]),
... month_map[s[3:6]],
... int(s[0:2]),
... int(s[12:14]),
... int(s[15:17]),
... int(s[18:20]))
...
>>>
>>> def parseApacheLogLine(logline):
... match = re.search(APACHE_ACCESS_LOG_PATTERN, logline)
... if match is None:
... return (logline, 0)
... size_field = match.group(9)
... if size_field == '-':
... size = long(0)
... else:
... size = long(match.group(9))
... return (Row(
... host = match.group(1),
... client_identd = match.group(2),
... user_id = match.group(3),
... date_time = parse_apache_time(match.group(4)),
... method = match.group(5),
... endpoint = match.group(6),
... protocol = match.group(7),
... response_code = int(match.group(8)),
... content_size = size
... ), 1)
...
2. 创建初始日志RDD
日志文件已经存放在HDFS上,路径为 “/data/12/3/apache.access.log.PROJECT” 。我们将整个创建RDD的过程封装在了函数 parseLogs() 中。首先调用函数 sc.textfile(logFile) 将文件的每一行转换为RDD中的一个元素,紧接着调用函数 map(parseApacheLogLine) 将解析函数应用于RDD中的每一个元素(即每一行日志),将其转换为包含 Row 对象的二元列表,并将该RDD缓存在内存中。最后分别生成解析成功和失败的记录,并输出其个数。最终输出的结果中,可以看出所有的日志行都已被成功解析。
>>> import sys
>>> import os
>>>
>>> baseDir = os.path.join('/data')
>>> inputPath = os.path.join('12', '3', 'apache.access.log.PROJECT')
>>> logFile = os.path.join(baseDir, inputPath)
>>>
>>> def parseLogs():
... parsed_logs = (sc
... .textFile(logFile)
... .map(parseApacheLogLine)
... .cache())
... access_logs = (parsed_logs
... .filter(lambda s: s[1] == 1)
... .map(lambda s: s[0])
... .cache())
... failed_logs = (parsed_logs
... .filter(lambda s: s[1] == 0)
... .map(lambda s: s[0]))
... failed_logs_count = failed_logs.count()
... if failed_logs_count > 0:
... print 'Number of invalid logline: %d' % failed_logs.count()
... for line in failed_logs.take(20):
... print 'Invalid logline: %s' % line
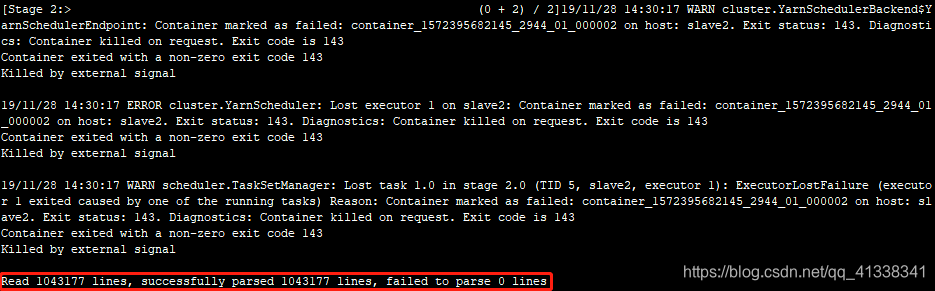
... print 'Read %d lines, successfully parsed %d lines, failed to parse %d lines' % (parsed_logs.count(), access_logs.count(), failed_logs.count())
... return parsed_logs, access_logs, failed_logs
...
>>> parsed_logs, access_logs, failed_logs = parseLogs()
输出结果:
3. 统计内容大小
统计Web服务器返回的内容大小,即字段 content_size ,包括其平均值、最小值和最大值。首先调用变换函数 map() 并传入一个只取出字段 content_size 的匿名函数创建一个新的RDD。再调用动作函数 reduce() 和 count() 求出内容大小的总和以及个数,其比值即内容大小的平均值。最后调用动作函数 min() 和 max() 得到内容大小的最小值和最大值。
>>> content_sizes = access_logs.map(lambda log: log.content_size).cache()
>>> print 'Content Size Avg: %i, Min: %i, Max: %s' % (
... content_sizes.reduce(lambda a, b : a + b) / content_sizes.count(),
... content_sizes.min(),
... content_sizes.max())
输出结果:

4. 统计状态代码
统计不同的状态代码出现的次数。与上一步类似,首先调用变换函数 map() 取出字段 response_code ,不同的是,这里取出的是一个二元列表,即字段 response_code 和1,使得之后能够计数。再调用变换函数 reduceByKey() 按照不同的状态代码统计出现次数,并调用函数 cache() 在内存中缓存。最后调用动作函数 take() 输出成列表。
>>> responseCodeToCount = (access_logs
... .map(lambda log: (log.response_code, 1))
... .reduceByKey(lambda a, b : a + b)
... .cache())
>>> responseCodeToCountList = responseCodeToCount.take(100)
>>>> print responseCodeToCountList
输出结果:

5. 查看频繁访问的客户端主机
这一步需要查看频繁访问(大于10次)的客户端主机。与上一步类似,首先调用变换函数 map() 取出包含字段 host 和1的二元列表。再调用变换函数 reduceByKey() 按照不同的主机地址统计出现次数。然后调用变换函数 filter() 取出出现次数大于10的主机地址。最后调用动作函数 take() 输出成列表。
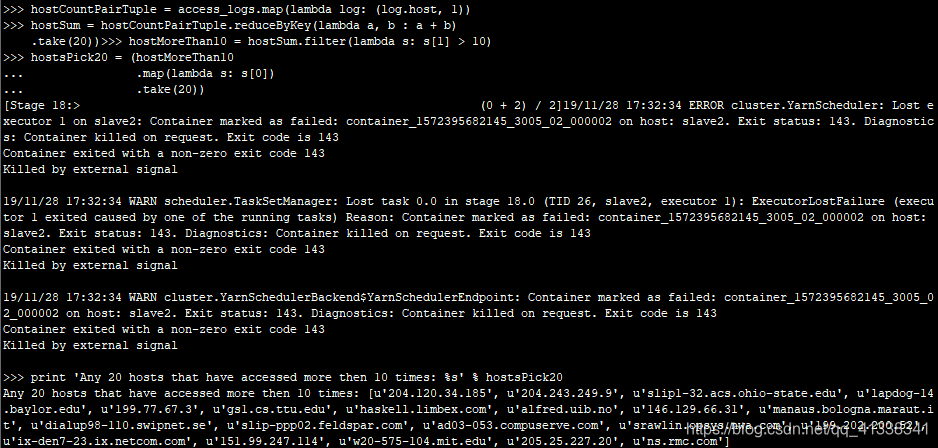
>>> hostCountPairTuple = access_logs.map(lambda log: (log.host, 1))
>>> hostSum = hostCountPairTuple.reduceByKey(lambda a, b : a + b)
>>> hostMoreThan10 = hostSum.filter(lambda s: s[1] > 10)
>>> hostsPick20 = (hostMoreThan10
... .map(lambda s: s[0])
... .take(20))
>>> print 'Any 20 hosts that have accessed more then 10 times: %s' % hostsPick20
输出结果:
6. 查看被访问最多的资源标识符
查看被访问最多的资源标识符。与上一步类似,首先调用变换函数 map() 取出包含字段 endpoint 和1的二元组。再调用变换函数 reduceByKey() 按照不同的资源标识符统计出现次数。最后调用动作函数 takeOrdered() 取出前10被访问最多的资源标识符。
>>> endpointCounts = (access_logs
... .map(lambda log: (log.endpoint, 1))
... .reduceByKey(lambda a, b : a + b))
>>> topEndpoints = endpointCounts.takeOrdered(10, lambda s: -1 * s[1])
>>> print 'Top Ten Endpoints: %s' % topEndpoints
输出结果:

7. (练习)查看出现错误最多的资源标识符
查看前10个出现错误(即状态代码不是 200 )最多的资源标识符(即字段 endpoint ),最终的返回结果是按访问次数倒序排列的前10个标识符及其相应的访问次数。
>>>errorEndpointCounts = (access_logs
... .map(lambda log: (log.endpoint, 1))
... .reduceByKey(lambda a, b : a + b)
... .filter(lambda x:x[0]!='200'))
>>>topErrorEndpoints = errorEndpointCounts.takeOrdered(10, lambda s: -1 * s[1])
>>>print topErrorEndpoints

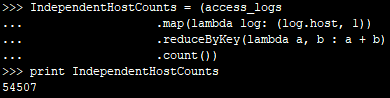
8. (练习)统计独立主机数
统计独立主机地址(字段 host )数。
>>>IndependentHostCounts = (access_logs
... .map(lambda log: (log.host, 1))
... .reduceByKey(lambda a, b : a + b)
... .count())
>>>print IndependentHostCounts
[附录:输入代码清单]
1. 定义函数解析日志行
import re
import datetime
from pyspark.sql import Row
month_map = {'Jan': 1, 'Feb': 2, 'Mar':3, 'Apr':4, 'May':5, 'Jun':6, 'Jul':7,
'Aug':8, 'Sep': 9, 'Oct':10, 'Nov': 11, 'Dec': 12}
APACHE_ACCESS_LOG_PATTERN = '^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+)\s*(\S*)\s*" (\d{3}) (\S+)'
def parse_apache_time(s):
return datetime.datetime(int(s[7:11]),
month_map[s[3:6]],
int(s[0:2]),
int(s[12:14]),
int(s[15:17]),
int(s[18:20]))
def parseApacheLogLine(logline):
match = re.search(APACHE_ACCESS_LOG_PATTERN, logline)
if match is None:
return (logline, 0)
size_field = match.group(9)
if size_field == '-':
size = long(0)
else:
size = long(match.group(9))
return (Row(
host = match.group(1),
client_identd = match.group(2),
user_id = match.group(3),
date_time = parse_apache_time(match.group(4)),
method = match.group(5),
endpoint = match.group(6),
protocol = match.group(7),
response_code = int(match.group(8)),
content_size = size
), 1)
2. 创建初始日志RDD
import sys
import os
baseDir = os.path.join('/data')
inputPath = os.path.join('12', '3', 'apache.access.log.PROJECT')
logFile = os.path.join(baseDir, inputPath)
def parseLogs():
parsed_logs = (sc
.textFile(logFile)
.map(parseApacheLogLine)
.cache())
access_logs = (parsed_logs
.filter(lambda s: s[1] == 1)
.map(lambda s: s[0])
.cache())
failed_logs = (parsed_logs
.filter(lambda s: s[1] == 0)
.map(lambda s: s[0]))
failed_logs_count = failed_logs.count()
if failed_logs_count > 0:
print 'Number of invalid logline: %d' % failed_logs.count()
for line in failed_logs.take(20):
print 'Invalid logline: %s' % line
print 'Read %d lines, successfully parsed %d lines, failed to parse %d lines' % (parsed_logs.count(), access_logs.count(), failed_logs.count())
return parsed_logs, access_logs, failed_logs
parsed_logs, access_logs, failed_logs = parseLogs()
3. 统计内容大小
content_sizes = access_logs.map(lambda log: log.content_size).cache()
print 'Content Size Avg: %i, Min: %i, Max: %s' % (
content_sizes.reduce(lambda a, b : a + b) / content_sizes.count(),
content_sizes.min(),
content_sizes.max())
4. 统计状态代码
responseCodeToCount = (access_logs
.map(lambda log: (log.response_code, 1))
.reduceByKey(lambda a, b : a + b)
.cache())
responseCodeToCountList = responseCodeToCount.take(100)
# 省略部分输出
print responseCodeToCountList
5. 查看频繁访问的客户端主机
hostCountPairTuple = access_logs.map(lambda log: (log.host, 1))
hostSum = hostCountPairTuple.reduceByKey(lambda a, b : a + b)
hostMoreThan10 = hostSum.filter(lambda s: s[1] > 10)
hostsPick20 = (hostMoreThan10
.map(lambda s: s[0])
.take(20))
# 省略部分输出
print 'Any 20 hosts that have accessed more then 10 times: %s' % hostsPick20
6. 查看被访问最多的资源标识符
endpointCounts = (access_logs
.map(lambda log: (log.endpoint, 1))
.reduceByKey(lambda a, b : a + b))
topEndpoints = endpointCounts.takeOrdered(10, lambda s: -1 * s[1])
# 省略部分输出
print 'Top Ten Endpoints: %s' % topEndpoints
7. (练习)查看出现错误最多的资源标识符
errorEndpointCounts = (access_logs
.map(lambda log: (log.endpoint, 1))
.reduceByKey(lambda a, b : a + b)
.filter(lambda x:x[0]!='200'))
topErrorEndpoints = errorEndpointCounts.takeOrdered(10, lambda s: -1 * s[1])
print topErrorEndpoints
8. (练习)统计独立主机数
IndependentHostCounts = (access_logs
.map(lambda log: (log.host, 1))
.reduceByKey(lambda a, b : a + b)
.count())
print IndependentHostCounts