目标检测的基本思路:定位localization+识别recognition
- 一个分支用于做图像分类,即全连接 + Softmax 判断目标类别,和单纯图像分类区别在于这里还另外需要一个「背景」类。
- 另一个分支用于识别目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为「背景」时才使用
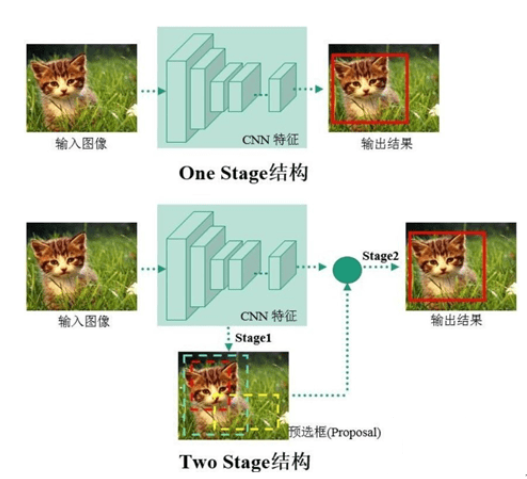
一阶段(One Stage )
不需要产生候选框,只需一次提取特征即可实现目标检测。直接将目标框定位的问题转化为回归(Regression)问题处理(Process)。
常见的算法有YOLO、SSD等等。
是怎么等效成回归问题的呢?
两阶段(Two Stages)
首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行分类。
常见的算法有 R-CNN、Fast R-CNN、Faster R-CNN 等等。
一阶段模型将目标检测看作端到端的回归问题,输入图片,输出五个结果(x,y,w,h,score)+类别,其中score是框的置信度,即该位置是否包含目标以及包含目标的准确性(IoU)。(x,y,w,h)是相对于Anchor的四个偏移量
ssd输出
发展历程
目标检测模型对比:
Huang et al,"Speedlaccuracy trade-offs for modern convolutional object detectors", CVPR2017