文章目录
论文: 《Prompt-to-Prompt Image Editing with Cross Attention Control》
github: https://github.com/google/prompt-to-prompt
1.摘要
文生图到图像编辑充满挑战,图像编辑需要保留原始图片大部分信息,而对于文生图,只要prompt稍微更改将导致生成完全不同图像。当前SOTA方法用户需要提供编辑位置的mask,忽略mask区域内容。作者探究一种仅通过文本进行编辑的框架,对此对条件文本模型进行深入探究,发现cross-attention层控制图像空间布局与prompt中每个word之间的相关性。作者通过仅编辑纹理prompt进行图像生成,包括:替换单词进行局部编辑、增加明细进行全局编辑、甚至精细化控制哪个单词映射到图像中哪部分。
2.算法
对于依据文本
p
r
o
m
p
t
P
prompt P
promptP生成图像
I
I
I,通过编辑的
p
r
o
m
p
t
P
∗
prompt P^*
promptP∗,生成编辑后图像
I
∗
I^*
I∗。
作者发现生成图像的结构与外观不仅依赖于随机种子还依赖于像素及文本embedding之间交互。注入输入图
I
I
I的cross-attention层使得保留原始构图和结构,整体结构如图3所示。
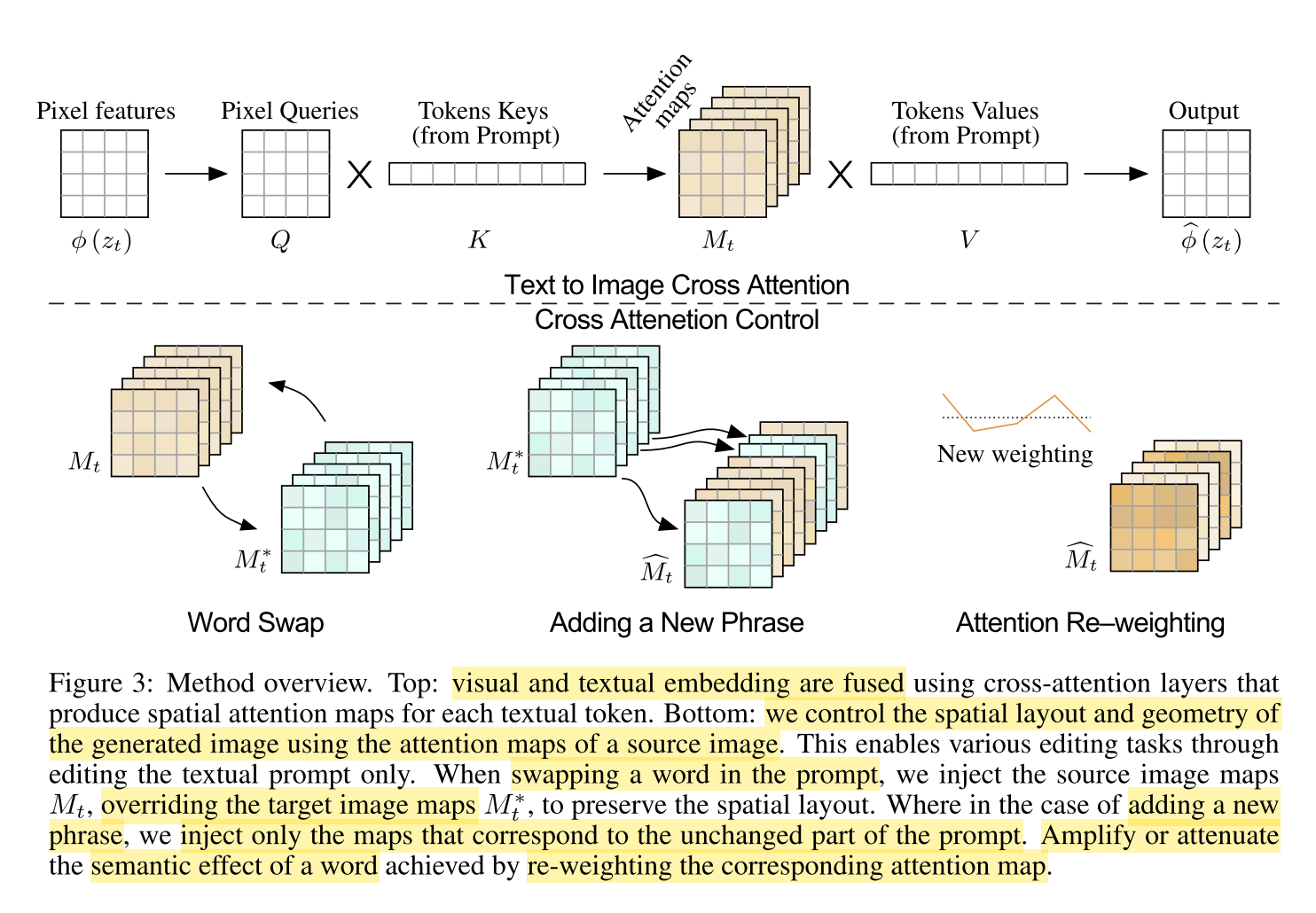
2.1 Cross-attention in text-conditioned Diffusion Models
噪声图经过映射得到查询矩阵
Q
Q
Q、
p
r
o
m
p
t
prompt
prompt分别经过映射得到
K
、
V
K、V
K、V,
a
t
t
e
n
t
i
o
n
m
a
p
M
attention map M
attentionmapM计算如式1,cross-attention输出为
M
V
MV
MV,用于更新空间特征
ϕ
(
z
t
)
\phi(z_t)
ϕ(zt)。

2.2 Controlling the Cross-attention
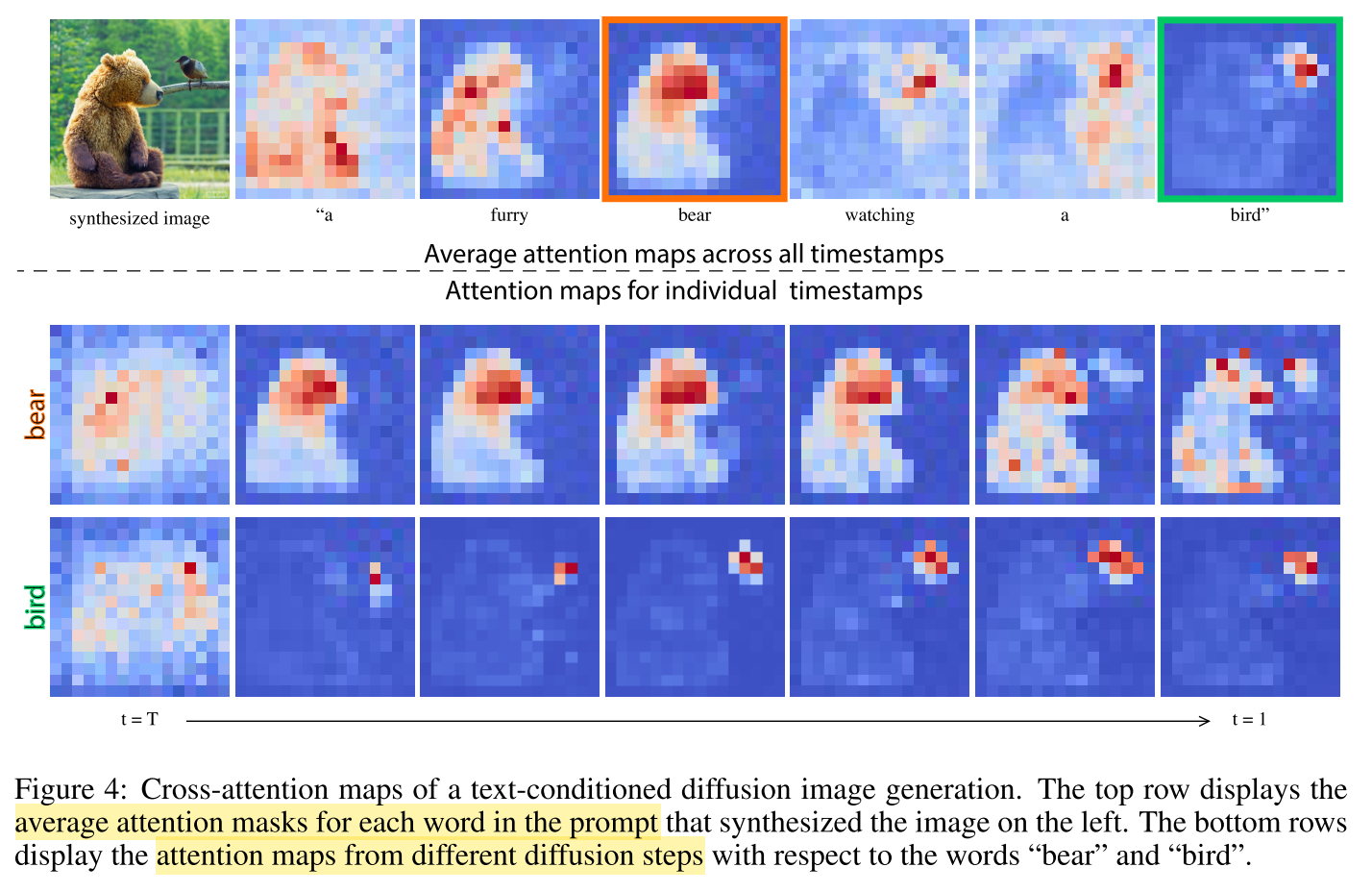
像素与文本交互如图4,第一行展示每个单词的attention mask,第二行展示随着扩散过程,attention map变化。我们发现在扩散早期阶段图像结构已经确定。
由于attention映射整体架构,因此可将原始
p
r
o
m
p
t
prompt
prompt生成过程的
a
t
t
e
n
t
i
o
n
m
a
p
M
attention map M
attentionmapM引入更改后
p
r
o
m
p
t
P
∗
prompt P^*
promptP∗二次生成过程,这使得生成图不仅与编辑
p
r
o
m
p
t
prompt
prompt一致,同时保留原始输入图I的结构。
作者定义扩散过程DM,输出图像
z
t
−
1
z_{t-1}
zt−1及
a
t
t
e
n
t
i
o
n
m
a
p
M
t
attention map M_t
attentionmapMt,使用编辑
p
r
o
m
p
t
P
∗
prompt P^*
promptP∗生成
a
t
t
e
n
t
i
o
n
m
a
p
M
t
∗
attention map M_t^*
attentionmapMt∗,作者定义
E
d
i
t
(
M
t
,
M
t
∗
,
t
)
Edit(M_t,M_t^*,t)
Edit(Mt,Mt∗,t)用于重写
a
t
t
e
n
t
i
o
n
m
a
p
M
attention map M
attentionmapM。为减少编辑过程随机性,作者固定随机种子,Prompt-to-Prompt图像编辑算法如算法1所示,
E
d
i
t
(
M
t
,
M
t
∗
,
t
)
Edit(M_t,M_t^*,t)
Edit(Mt,Mt∗,t)如图3底部,

Word Swap
用户将原始prompt中个别词替换。该问题挑战为保存原始结构同时与新prompt内容一致,将原图attention map直接引入可能会过于限制几何形状。因此作者提出softer attention限制,如下式,
τ
\tau
τ为时间戳,
在前期使用原始图片
a
t
t
e
n
t
i
o
n
m
a
p
M
t
attention map M_t
attentionmapMt,后期使用新
p
r
o
m
p
t
P
∗
prompt P^*
promptP∗生成图像的
a
t
t
e
n
t
i
o
n
m
a
p
M
t
∗
attention map M_t^*
attentionmapMt∗
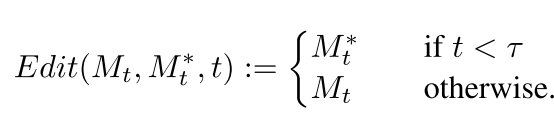
Adding a New Phrase
此情况表示用户在prompt中增加新的token。为保留共同细节,作者仅将attention注入共同token,使用对齐功能A,对于目标
p
r
o
m
p
t
P
∗
prompt P^*
promptP∗token index输出
P
P
P中对应token index,编辑功能如下式,
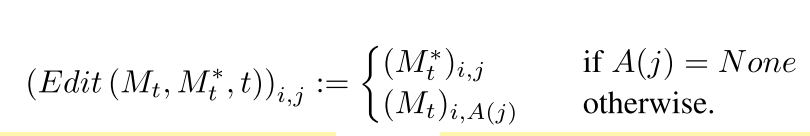
Attention Re–weighting
此情况适用于用户希望加强或削弱某个token对生成图影响。对此作者通过参数
c
∈
[
−
2
,
2
]
c \in [−2, 2]
c∈[−2,2]将token j对应attention map放大,如下式,
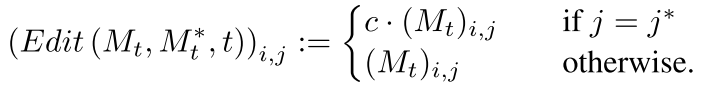
3.应用
Text-Only Localized Editing
图2上展示通过引入原始prompt的attention map可保留物体结构,同时背景区域得到还不错保留。
图5展示attention map仅作用于特定词“butterfly",能够很好保留前景,同时背景区域变化。
图6展示本方法不仅可更改纹理,同时可更改结构。最佳结果不是整个扩散过程引入attention map。
图7上展示目标增加修饰词情况,保留背景同时生成图与新增词一致。




Global editing
图7下及图8展示保留原始目标位置及特性的同时,对全局进行编辑。

Fader Control using Attention Re-weighting
图9展示通过增加或降低特定词权重所产生影响。

Real Image Editing
编辑真实图像需要找到初始噪声,通过扩散过程可生成输入图。常规方法是对输入图添加高斯噪声,进行扩散,但容易导致失真,因此作者使用一种改进的反向方法,如图10,可生成满意效果;
如图11,许多情况反向过程不够准确。这归因于乱序与编辑的均衡,降低prompt权重提升重建能力,但限制编辑能力。
因此作者使用mask仅对无编辑区域进行重构。如图12



4.结论
作者揭示了文生图扩散模型中cross-attention层强大能力。作者展示通过操纵prompt可进行本地或全局编辑。
限制:
1、当前反向过程导致在一些测试集出现失真;
2、attention map为低分辨率,这限制了进行精确本地化编辑的能力;作者建议在高分辨率增加cross-attention层。
3、当前方法不能对图中物体进行空间移动。