项目描述
本实战项目实时分析处理用户对广告点击的行为数据。
项目数据生成方式
使用代码的方式持续的生成数据,然后写入到kafka中,然后从kafka消费数据,并对数据根据需求进行分析。
项目数据格式
时间戳, 地区, 城市, 用户id, 广告id
1566035129449, 华南, 深圳, 101, 2
项目准备
- 步骤1: 开启集群
启动 zookeeper 和 Kafka
- 步骤2: 创建 Topic
#查看kakfa都有哪些主题
bin/kafka-topics.sh --list --zookeeper hadoop201:2181
#创建主题 指定3个分区,2个副本
bin/kafka-topics.sh --zookeeper hadoop201:2181 --create --topic my-ads-bak --partitions 3 --replication-factor 2
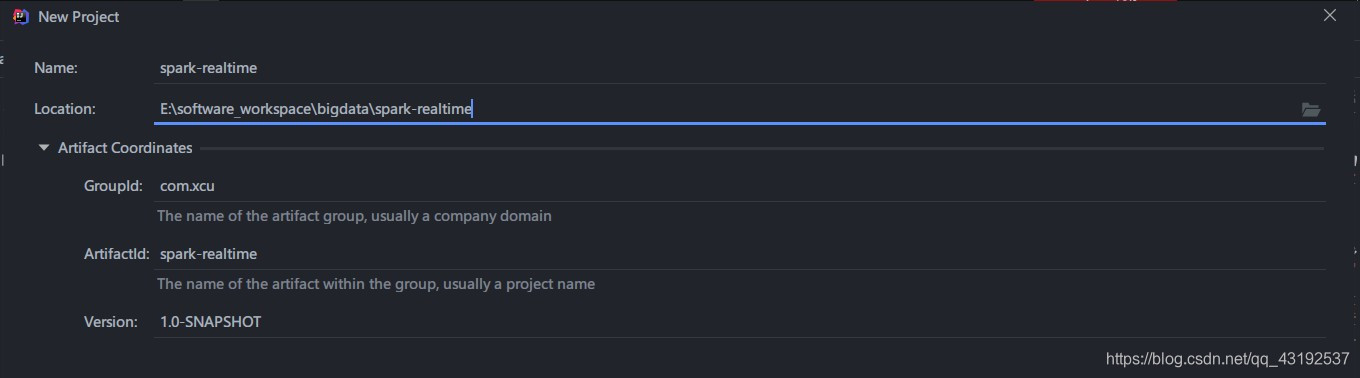
- 步骤3: 创建项目spark-realtime
4) 拷贝依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<!-- https://mvnrepository.com/artifact/org.json4s/json4s-native -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-native_2.11</artifactId>
<version>3.2.11</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.json4s/json4s-jackson -->
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_2.11</artifactId>
<version>3.2.11</version>
</dependency>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
</dependencies>
-
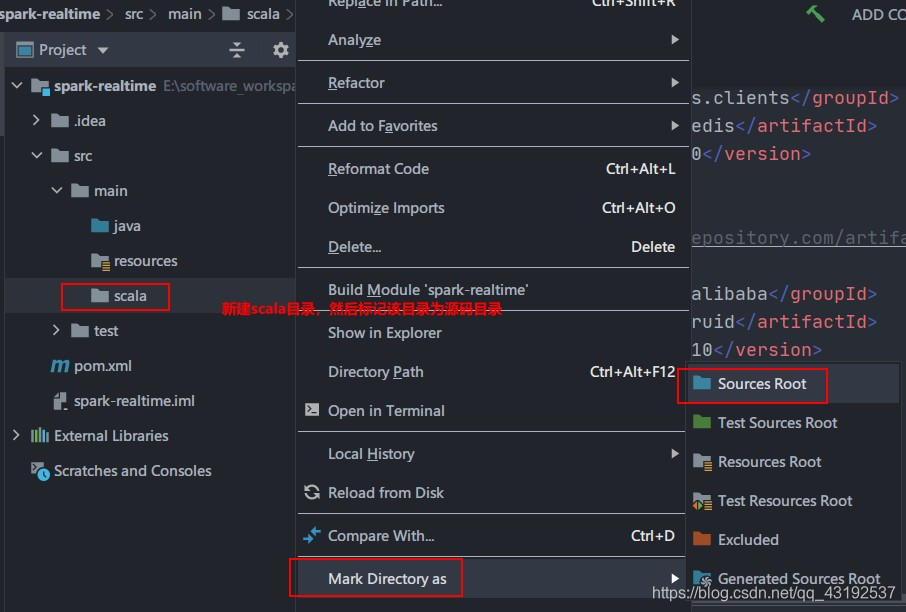
添加框架支持(scala)
-
新建scala目录,然后标记为源码目录
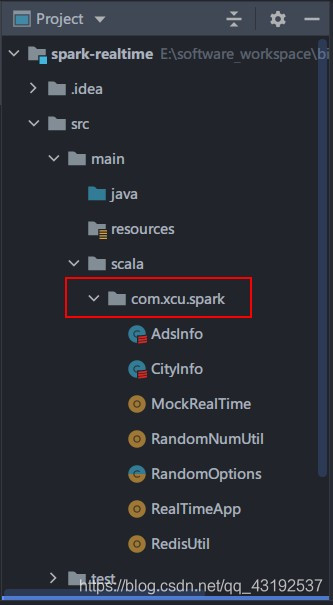
7) 拷贝如下类到要编写代码的目录
AdsInfo,样例类
CityInfo,样例类
RandomNumUtil,用于生成随机数
RandomOptions,用于生成带有比重的随机选项
MockRealTime,生成模拟数据
RealtimeApp,测试从kafka读取数据(直接拷贝Kafka数据源高级API即可)
eg: 我要编写的代码目录
项目需求一:每天每地区热门广告Top3
package com.xcu.spark
import java.text.SimpleDateFormat
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
/**
* @Package : com.xcu.spark
* @Author :
* @Date : 2020 11月 星期一
* @Desc :
*/
object RealTime_req1 {
def main(args: Array[String]): Unit = {
//创建配置文件
val conf: SparkConf = new SparkConf().setAppName("RealTime_req1").setMaster("local[*]")
//创建SparkStreaming执行上下文
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
//设置检测点目录
ssc.sparkContext.setCheckpointDir("./cp")
//kafka参数声明
val brokers = "hadoop201:9092,hadoop202:9092,hadoop203:9092"
val topic = "my-ads-bak"
val group = "bigdata"
val deserialization = "org.apache.kafka.common.serialization.StringDeserializer"
val kafkaParams = Map(
ConsumerConfig.GROUP_ID_CONFIG -> group,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> deserialization,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> deserialization
)
//创建DS
val kafkaDS: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, Set(topic)
)
//从Kafka的kv值中取value msg = 1590136353874,华北,北京,103,1
val dataDS: DStream[String] = kafkaDS.map(_._2)
//将原始数据进行转换 ==> (天_地区_广告,1)
val mapDS: DStream[(String, Int)] = dataDS.map {
line => {
val fields: Array[String] = line.split(",")
//获取时间戳
val timeStamp: Long = fields(0).toLong
//根据时间戳创建日期对象
val day: Date = new Date(timeStamp)
//创建SimpleDateFormat,对日期对象进行转换
val sdf: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd")
//将日期对象转换为字符串
val str: String = sdf.format(day)
//获取地区
val area: String = fields(1)
//获取广告
val adv: String = fields(4)
//封装元组
(str + "_" + area + "_" + adv, 1)
}
}
//对每天每地区广告点击数进行聚合处理 (天_地区_广告,sum)
//注意:这里要统计的是一天的数据,所以要将每一个采集周期的数据,进行统计。所以需要传递状态,所以要用
val updateDS: DStream[(String, Int)] = mapDS.updateStateByKey(
(seq: Seq[Int], buffer: Option[Int]) => {
Option(seq.sum + buffer.getOrElse(0))
}
)
//再次对结构进行转换
val mapDS1: DStream[(String, (String, Int))] = updateDS.map {
//(天_地区_广告,sum)
case (k, sum) => {
val fields: Array[String] = k.split("_")
//天_地区,(广告,sum))
(fields(0) + "_" + fields(1), (fields(2), sum))
}
}
//将相同的天和地区放到一组
val groupDS: DStream[(String, Iterable[(String, Int)])] = mapDS1.groupByKey()
//对分组后的数据进行排序
val resDS: DStream[(String, List[(String, Int)])] = groupDS.mapValues {
datas => {
datas.toList.sortBy(-_._2).take(3)
}
}
//打印输出结果
resDS.print()
//启动采集器
ssc.start()
//等待线程结束,关闭采集器
ssc.awaitTermination()
}
}
项目需求二:最近12s广告点击量实时统计
package com.xcu.spark
import java.text.SimpleDateFormat
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Package : com.xcu.spark
* @Author :
* @Date : 2020 11月 星期一
* @Desc :
*/
object RealTime_req2 {
def main(args: Array[String]): Unit = {
//创建配置文件
val conf: SparkConf = new SparkConf().setAppName("RealTime_req2").setMaster("local[*]")
//创建SparkStreaming执行上下文
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
//设置检测点目录
ssc.sparkContext.setCheckpointDir("./cp")
//kafka参数声明
val brokers = "hadoop201:9092,hadoop202:9092,hadoop203:9092"
val topic = "my-ads-bak"
val group = "bigdata"
val deserialization = "org.apache.kafka.common.serialization.StringDeserializer"
val kafkaParams = Map(
ConsumerConfig.GROUP_ID_CONFIG -> group,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> deserialization,
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> deserialization
)
//创建DS
val kafkaDS: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, Set(topic)
)
//从Kafka的kv值中取value msg = 1590136353874,华北,北京,103,1
val dataDS: DStream[String] = kafkaDS.map(_._2)
//定义窗口的大小以及滑动的步长
val windowDS: DStream[String] = dataDS.window(Seconds(12), Seconds(3))
//对结构进行转换
val mapDS: DStream[(String, Int)] = windowDS.map {
line => {
val fields: Array[String] = line.split(",")
val timeStmp: Long = fields(0).toLong
val day: Date = new Date(timeStmp)
//
val sdf = new SimpleDateFormat("mm:ss")
val time: String = sdf.format(day)
(fields(4) + "_" + time, 1)
}
}
//对数据进行聚合
val resDS: DStream[(String, Int)] = mapDS.reduceByKey(_ + _)
//打印输出
resDS.print()
//启动采集器
ssc.start()
//等待线程结束,关闭采集器
ssc.awaitTermination()
}
}