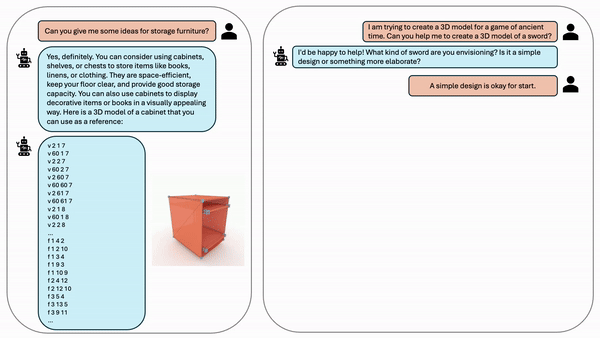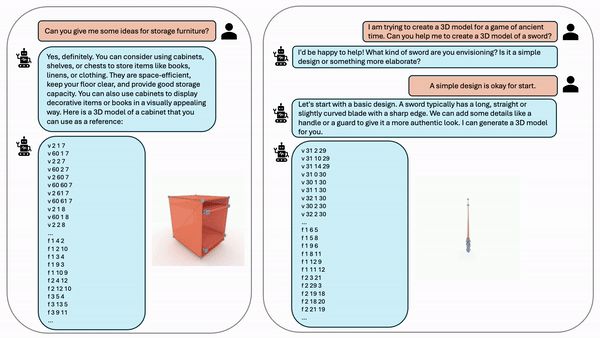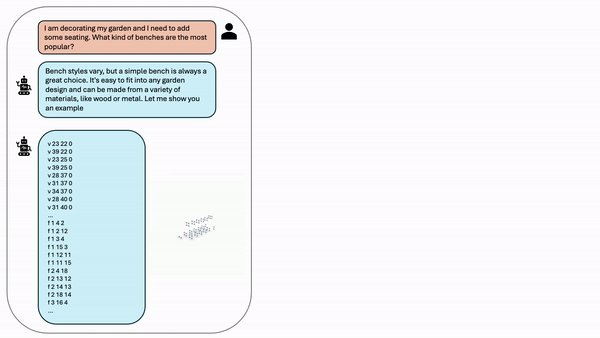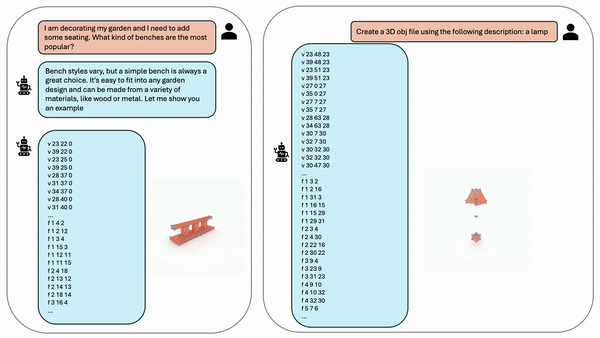
项目地址:https://research.nvidia.com/labs/toronto-ai/LLaMA-Mesh
项目来源:清华/英伟达
文章标题:LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
摘要
本文在一个统一的模型中生成3D网格(mesh)。这提供了 (1)利用已经嵌入在LLM中的空间知识(来源自3D教程等文本),以及(2)支持会话3D生成和网格理解的关键优势 。一个主要的挑战是有效地将3D网格数据标记为LLM可以无缝处理的离散token。为了解决这个问题,LLAMA-MESH将三维网格的顶点坐标和面定义表示为纯文本,允许与LLM直接集成而不扩展词汇表。我们构建了一个带监督的微调(SFT)数据集,使预训练的LLM能够(1)从文本提示生成三维网格,(2)根据需要生成 interleaved text 和3D网格输出,以及(3)理解和解释3D网格。我们的工作首次证明了LLM可以被微调,以获取复杂的空间知识,以基于文本的格式生成三维网格,有效地统一了三维和文本模式。LLAMA-MESH 实现网格生成质量与模型从头开始训练,同时保持强大的文本生成性能。
一、引言
大型语言模型(LLMs)[5,52]在理解和生成类人文本方面表现出了非凡的能力,在会话代理、代码生成和视觉内容推理[1,16,30]等应用程序中取得了成功。尽管有了这些进展,但它们的生成能力主要局限于文本内容,这限制了它们在更广泛的任务中的效用
我们的工作试图将LLMs扩展到一种新的方式——3D网格生成——释放计算机图形学、工程、机器人技术和虚拟/增强现实等领域的巨大潜力。通过使llm能够从文本描述中生成3D网格,我们将语言理解与3D内容创建统一起来,扩展了llm的功能范围。这种方法为由基于语言的指令驱动的3D内容创建中更直观和高效的工作流铺平了道路。
然而,将一种新的模态集成到LLM中是具有挑战性的,特别是在处理新模态的标记化过程中。据我们所知,目前还没有尝试将3D网格和文本生成统一在一个单一的框架中。一些研究探索了统一的图像和文本生成。在这些工作中,一种常见的方法是训练一种新的标记器,如向量量化变分自编码器(VQ-VAE)[17,51],将新的模态编码为离散标记,用于训练。然而,这就需要扩展词汇量,从而增加了适应能力的学习成本。此外,该方法在自动编码过程中还引入了信息丢失。
为了解决这些挑战,我们引入了LLAMA-MESH,这是一个新的框架,它允许大型语言模型(llm)通过用纯文本表示来生成3D网格。我们的方法使用了OBJ文件格式,这是一种被广泛采用的基于文本的标准,用于包含顶点坐标和面定义的3D模型,如图4所示。通过将这些数值视为一个文本序列,我们将3D网格转换为一种LLM可以直接处理的格式,避免了对标记化器或词汇表的修改,从而最大限度地减少了额外的训练开销。这种设计利用了预先训练的llm中嵌入的广泛知识。图6显示了预先训练的LLM展示了在文本中表示3D结构的原生能力。
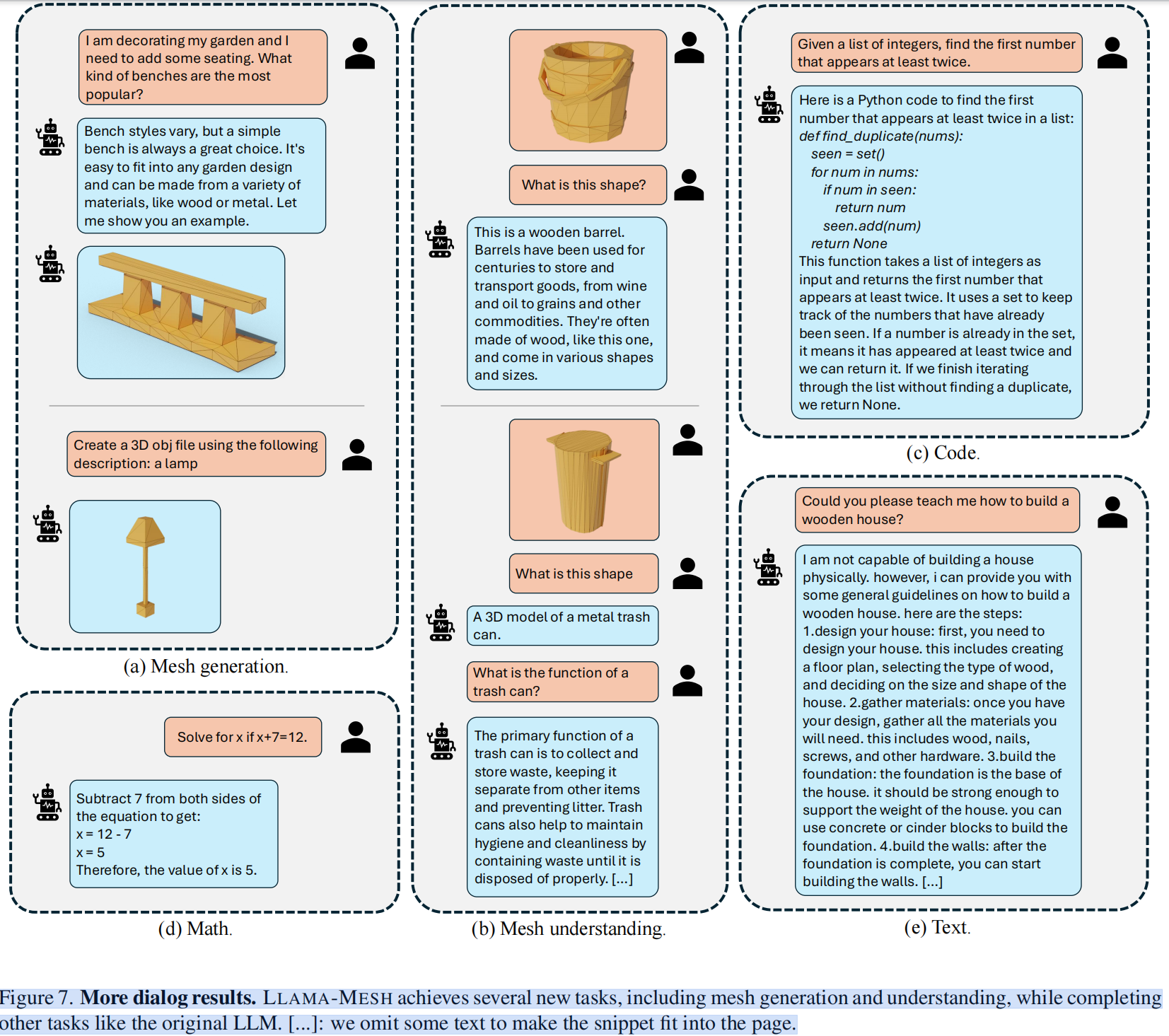
我们构建了一个有监督微调(SFT)数据集,其中包括文本3D对和交互的文本3D对话。我们在我们管理的数据集上微调了一个预先训练过的LLaMA-3.1-8B-Instruct [16]模型。我们发现LLM可以通过学习文本格式网格的数值来获得复杂的空间知识。经过微调后,我们的模型展示了(1)给给定的文本提示生成3D网格的能力,(2)在会话设置中生成文本和3D网格的交交互输出,以及(3)用自然语言描述网格的能力。
二、相关工作-3D物体生成
DreamFusion[41],Magic3D [27],ProlificDreamer[56]和许多其他方法,[6,8,11,20,25,29,35,47,48,54,63,69,75]使用分数蒸馏从预先训练的大规模文本到图像扩散模型[42,43]生成3D对象。前馈方法包括LRM [19,23,53,65]、CRM [57]、InstantMesh[64],以及其他方法[24,33,34,49,60,71,76]生成3D对象。然而,上述方法通常将3D对象视为数值字段,并使用行进的立方体或它们的变体[44,45]来提取网格,这不容易允许表示为离散标记
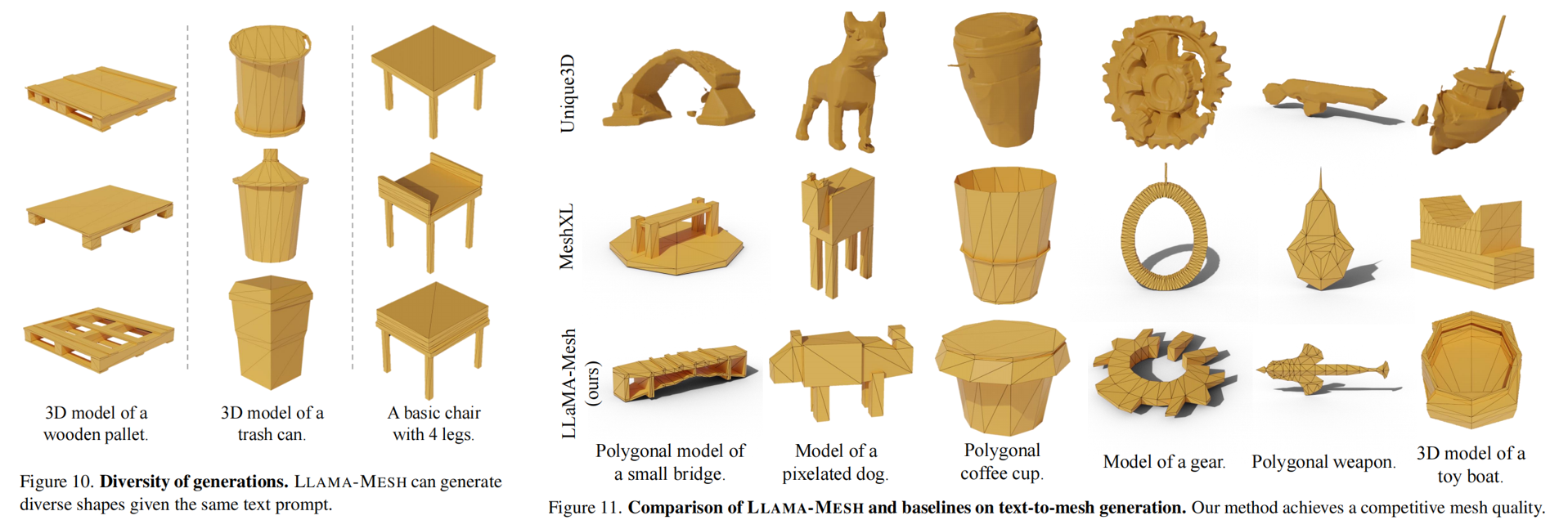
自动回归网格生成:诸如PolyGen [39]、MeshGPT [46]、MeshXL [7]等方法将3D对象建模为一个标记坐标的离散序列,并使用自回归转换器生成具有艺术家创建的拓扑的对象。MeshAnything [9, 10], PivotMesh [58] 和EdgeRunner [50]将点云作为更好控制的输入条件。这些工作也将网格视为使用自回归变压器生成的离散标记,但它们是从零开始训练的,缺乏语言能力
三、主要方法
3.1.3D 表示
我们观察到,预训练的LLM可以以零样本的方式生成3D对象——一种简单且广泛使用的纯文本格式,如图6所示。尽管这些生成的形状很简单,而且不能立即使用,但它们证明了一些OBJ格式的3D知识本质上是编码在llm中的。此外,由于OBJ文件以纯文本格式描述了3D几何图形,因此它们是与llm集成的理想候选文件,而不需要修改标记器或词汇表。
OBJ文件由顶点坐标和面定义组成:顶点(v):以字母v开头的每一行,定义三维空间中一个顶点的 x 、 y 和 z x、y和z x、y和z坐标,例如 v 0.1230.2340.345 v 0.123 0.234 0.345 v0.1230.2340.345。面(f):以字母f开头的每一行,都通过列出顶点索引来定义一个多边形(通常是一个三角形或四边形)例如, f 123 f 1 2 3 f123。通过将这些数值视为纯文本,我们将3D网格转换为LLM原生处理的顺序文本格式。图4显示了一个简单的OBJ文件及其相应的3D对象渲染的示例。
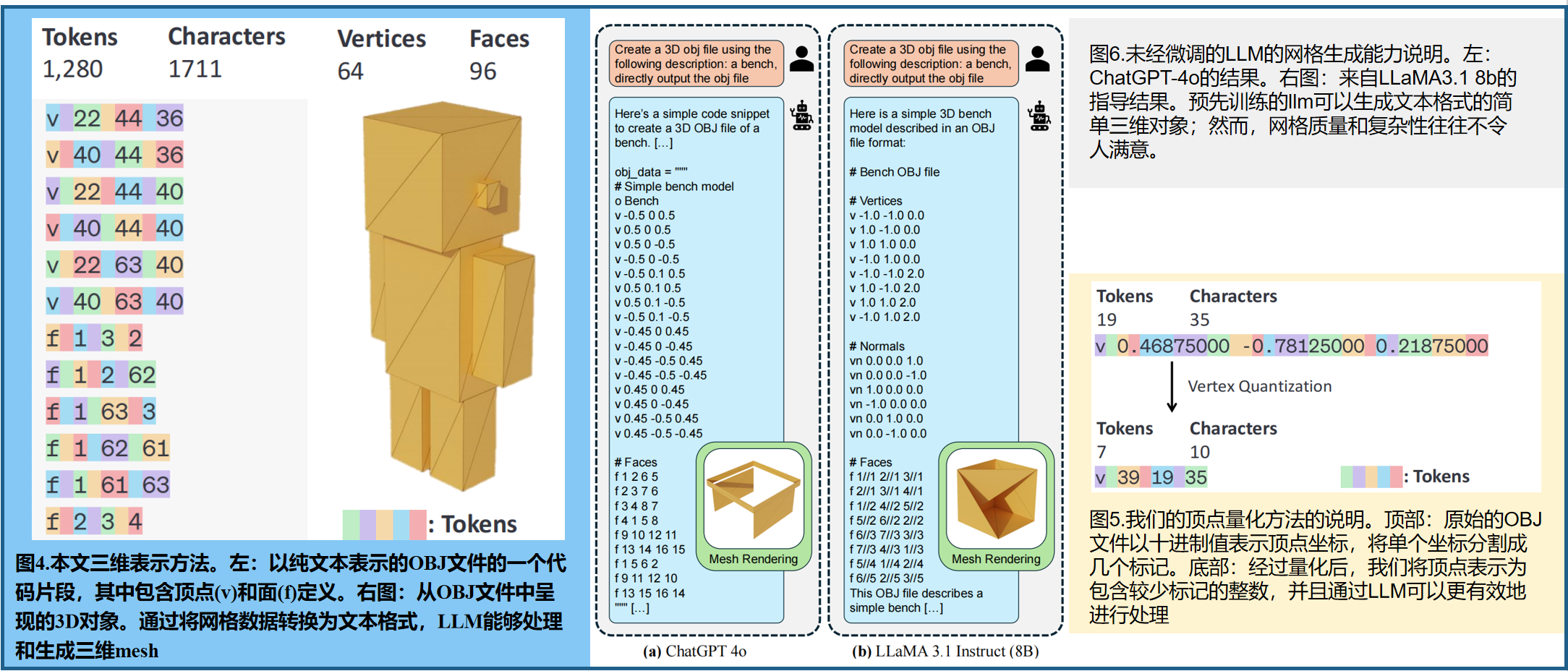
请注意,三维网格坐标通常存储为浮点数。对顶点坐标使用浮点数直接导致长的token序列,超过了大多数LLM的上下文长度限制,并增加了计算成本。为了解决这个问题,我们将顶点坐标量化为一个固定数量的bins(在我们的例子中,每个轴64个)。我们将mesh扩展到范围[0,64],并将坐标量化到最接近的整数。图5显示了我们的量化,这略微降低了坐标的精度。然而,它显著地减少了token数,使得LLM可以在不牺牲几何保真度的情况下处理更长的序列。
3.2 预训练模型
预先训练过的LLMs,如LLaMA [16]变体,是生成网格文本的自然候选者,因为它们是用于建模任意序列的最强工具。**本文使用LLaMA3.1-8B-Instruct [16]作为我们的base模型。**该模型在性能和计算效率之间达到平衡。经过了指令调整,可以遵循提示并生成一致的响应。
3.3 3D-task 微调
为了使LLM具有3D能力,我们构建了一个有监督的微调(SFT)数据集进行训练。我们使用来自 Objaverse[14]数据的三维网格,一个全面的一般对象的三维数据集。为了构建聊天数据集,我们采用了(1)基于规则的方法和(2)基于LLM的增强方法。
在基于规则的方法中,我们设计了几个简单的模式,比如“(用户){obj}这是什么?”(助理)说明。”和“(用户)创建一个3D模型。(助理)。”为网格生成。对于每个3D对象,我们随机选择一个模式,并用网格定义和标题替换占位符。虽然这些对话很简单,但它们为LLM提供了文本和3D表示之间对应关系的基础知识。
为了实现更复杂的对话,我们创建了复杂的文本-3d对话:以文本-3D交互格式编写示例对话,并使用上下文学习提示预训练的LLM根据其文本描述为每个3D对象生成对话,这结合了基于规则和LLM增强方法。我们从基于规则的方法和基于LLM的增强方法中随机选择每个mesh来构建对话框。图8显示了我们的训练数据的示例

为了保持LLM的语言功能,我们使用了UltraChat[15],一个通用的会话数据集。我们最终的数据集是网格生成、网格理解和一般对话数据的混合,比率见表1。
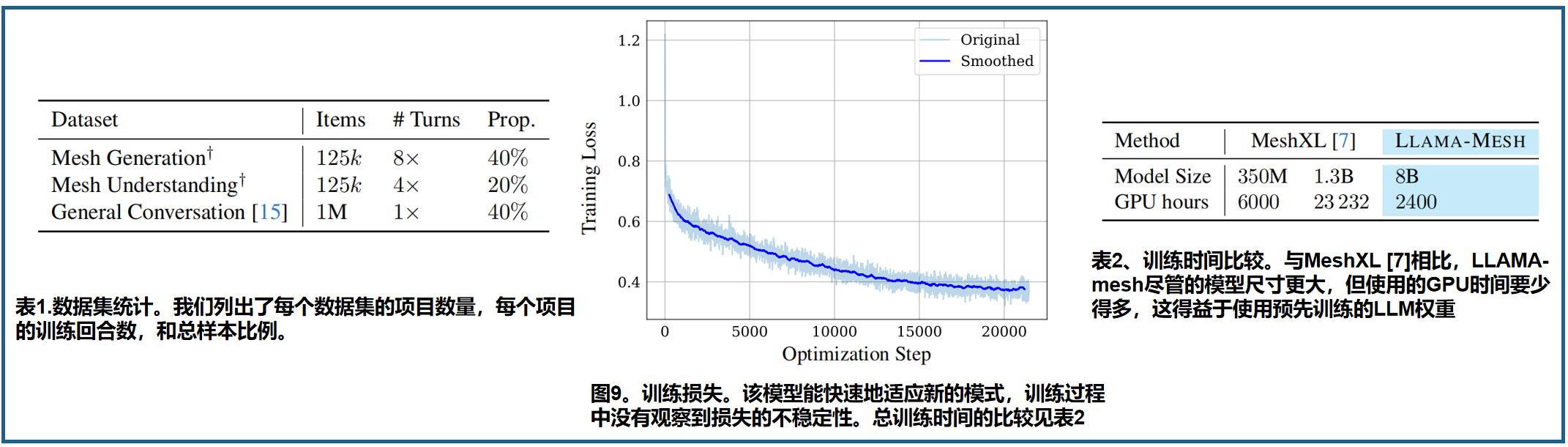
训练。模型在32个 A100gpu上进行21k次迭代训练。我们进行了全参数的微调。我们使用了AdamW优化器[36],学习速率为 1 e − 5 1^{e−5} 1e−5,预热30步,采用余弦调度,全局批处理大小为128。总训练时间约为3天。图9可视化了训练损失,这显示了模型在新的模态上快速收敛,表明了知识的快速适应。我们在训练过程中没有观察到损失的峰值或不稳定。
效果