文章目录
普通方式创建线程存在的问题
- 首先,每次有任务来时就要创建线程,任务结束就要将这个线程销毁,频繁的创建和销毁需要一定的开销。
- 当任务数远远大于线程可以承载的数量之后,我们需要频繁的创建大量的线程,从而导致内存和CPU占比过高,服务器系统崩溃。我们可以使用线程池化的思想来人为根据服务器配置创建符合的线程数量。多余的任务进行友好的任务拒绝策略。
什么是线程池
线程池(ThreadPool)是一种基于池化思想管理和使用线程的机制。它是将多个线程预先存储在一个“池子”内,当有任务出现时可以避免重新创建和销毁线程所带来性能开销,只需要从“池子”内取出相应的线程执行对应的任务即可,其中核心线程默认+只要线程池不关闭,就不会被销毁,可以反复使用。
池化思想在计算机的应用也比较广泛,比如以下这些:
- 内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
- 连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
- 实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
线程池的好处
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
线程池设计思路
有句话叫做艺术来源于生活,编程语言也是如此,很多设计思想能映射到日常生活中,比如面向对象思想、封装、继承,等等。今天我们要说的线程池,它同样可以在现实世界找到对应的实体——工厂。
先假想一个工厂的生产流程:
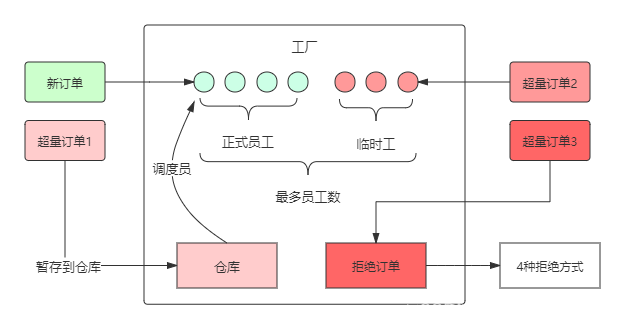
工厂中有固定的一批工人,称为正式工人,工厂接收的订单由这些工人去完成。当订单增加,正式工人已经忙不过来了,工厂会将生产原料暂时堆积在仓库中,等有空闲的工人时再处理(因为工人空闲了也不会主动处理仓库中的生产任务,所以需要调度员实时调度)。仓库堆积满了后,订单还在增加怎么办?工厂只能临时扩招一批工人来应对生产高峰,而这批工人高峰结束后是要清退的,所以称为临时工。当时临时工也以招满后(受限于工位限制,临时工数量有上限),后面的订单只能忍痛拒绝了。
我们做如下一番映射:
工厂——线程池
订单——任务(Runnable)
正式工人——核心线程
临时工——普通线程
仓库——任务队列
调度员——getTask()
getTask()是一个方法,将任务队列中的任务调度给空闲线程。
映射后,形成线程池流程图如下,两者是不是有异曲同工之妙?
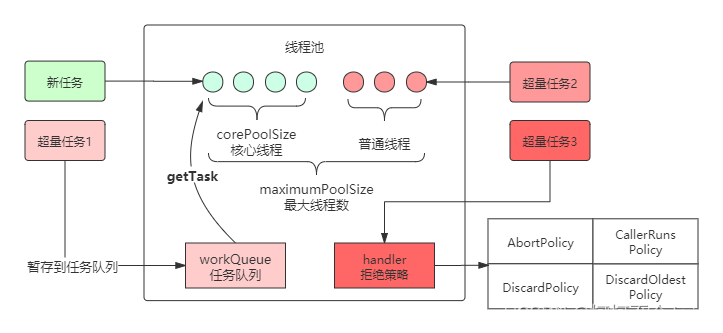
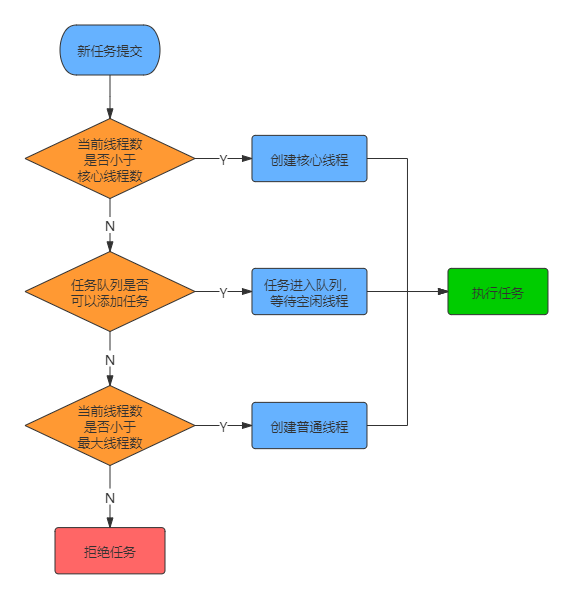
这样,线程池的工作原理或者说流程就很好理解了,提炼成一个简图:
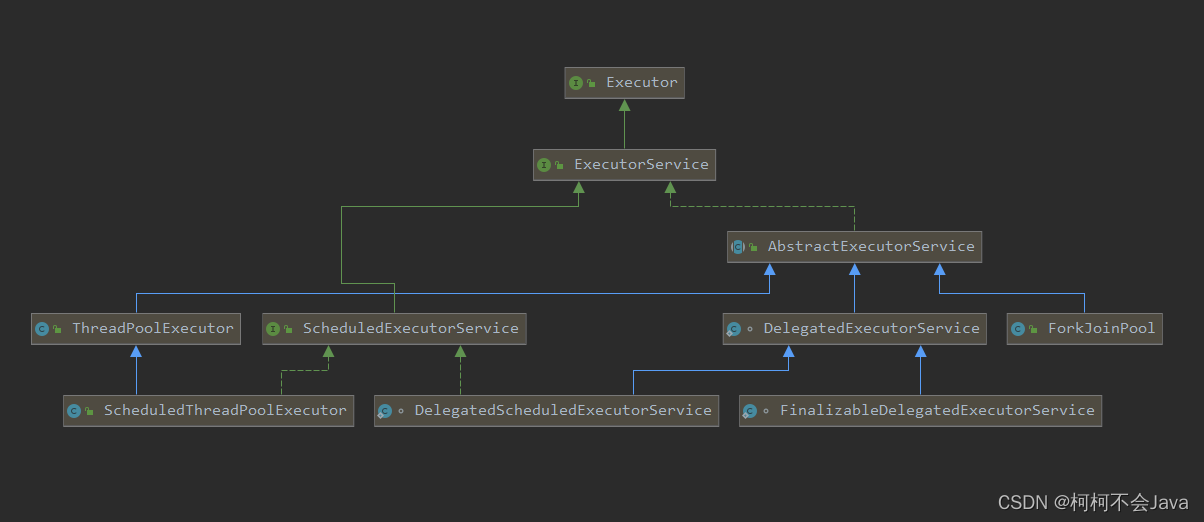
线程池相关类的继承关系
线程池的创建方式
线程池的创建⽅法总共有 7 种,但总体来说可分为 2 类:
- 通过 ThreadPoolExecutor 创建的线程池;
- 通过 Executors 创建的线程池。
线程池的创建⽅式总共包含以下 7 种(其中 6 种是通过 Executors 创建的, 1 种是通过 ThreadPoolExecutor 创建的):
- Executors.newFixedThreadPool:创建⼀个固定⼤⼩的线程池,可控制并发的线程数,超出的线程会在队列中等待;
- Executors.newCachedThreadPool:创建⼀个可缓存的线程池,若线程数超过处理所需,缓存⼀段时间后会回收,若线程数不够,则新建线程;
- Executors.newSingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执⾏顺序;
- Executors.newScheduledThreadPool:创建⼀个可以执⾏延迟任务的线程池;
- Executors.newSingleThreadScheduledExecutor:创建⼀个单线程的可以执⾏延迟任务的线程池;
- Executors.newWorkStealingPool:创建⼀个抢占式执⾏的线程池(任务执⾏顺序不确定)【JDK1.8 添加】。
- ThreadPoolExecutor:最原始的创建线程池的⽅式,它包含了 7 个参数可供设置,后⾯会详细讲。
固定容量线程池——FixedThreadPool
固定容量线程池。其特点是最大线程数就是核心线程数,意味着线程池只能创建核心线程,keepAliveTime为0,即线程执行完任务立即回收。任务队列未指定容量,代表使用默认值Integer.MAX_VALUE。适用于需要控制并发线程的场景。
相关构造方法
// 使用默认线程工厂
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
// 需要自定义线程工厂
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
示例
package com.fastech.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestFixedThreadPool {
public static void main(String[] args) {
// 1. 创建线程池对象,设置核心线程和最大线程数为5
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
// 2. 创建Runnable(任务)
Runnable task = new Runnable(){
public void run() {
System.out.println(Thread.currentThread().getName() + "--->运行");
}
};
// 3. 向线程池提交任务
fixedThreadPool.execute(task);
fixedThreadPool.execute(task);
}
}
运行结果
pool-1-thread-1—>运行
pool-1-thread-2—>运行
缓存线程池——CachedThreadPool
缓存线程池。没有核心线程,普通线程数量为Integer.MAX_VALUE(可以理解为无限),线程闲置60s后回收,任务队列使用SynchronousQueue这种无容量的同步队列。适用于任务量大但耗时低的场景。
相关构造方法
// 使用默认线程工厂
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
// 需要自定义线程工厂
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
示例
package com.fastech.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestCachedThreadPool {
public static void main(String[] args) {
// 1. 创建缓存线程池
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 2. 创建Runnable(任务)
Runnable task = new Runnable(){
public void run() {
System.out.println(Thread.currentThread().getName() + "--->运行");
}
};
// 3. 向线程池提交任务
cachedThreadPool.execute(task);
cachedThreadPool.execute(task);
}
}
运行结果
pool-1-thread-1—>运行
pool-1-thread-2—>运行
单线程线程池——SingleThreadExecutor
单线程线程池。特点是线程池中只有一个线程(核心线程),线程执行完任务立即回收,使用有界阻塞队列(容量未指定,使用默认值Integer.MAX_VALUE)
相关构造方法
// 使用默认线程工厂
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
// 需要自定义线程工厂
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
示例
package com.fastech.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestSingleThreadExecutor {
public static void main(String[] args) {
// 1. 创建单线程线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
// 2. 创建Runnable(任务)
Runnable task = new Runnable(){
public void run() {
System.out.println(Thread.currentThread().getName() + "--->运行");
}
};
// 3. 向线程池提交任务
singleThreadExecutor.execute(task);
singleThreadExecutor.execute(task);
singleThreadExecutor.execute(task);
singleThreadExecutor.execute(task);
singleThreadExecutor.execute(task);
singleThreadExecutor.execute(task);
}
}
运行结果
pool-1-thread-1—>运行
pool-1-thread-1—>运行
pool-1-thread-1—>运行
pool-1-thread-1—>运行
pool-1-thread-1—>运行
pool-1-thread-1—>运行
结果分析
可以看到运行结果中线程名称都是一样的,表示线程池中只有一个线程(核心线程)执行任务。
定时线程池——ScheduledThreadPool
定时线程池。指定核心线程数量,普通线程数量无限,普通线程执行完任务立即回收,任务队列为延时阻塞队列。这是一个比较特别的线程池,适用于执行定时或延迟的任务。
相关构造方法
// 使用默认线程工厂
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
// 需要自定义线程工厂
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
ScheduledThreadPoolExecutor类源码
// 继承了ThreadPoolExecutor
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
// 使用默认线程工厂的构造方法
public ScheduledThreadPoolExecutor(int corePoolSize) {
// 调用父类ThreadPoolExecutor的构造方法
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
// 需要自定义线程工厂的构造方法
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
// 调用父类ThreadPoolExecutor的构造方法
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
...
}
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
...
}
}
示例
package com.fastech.thread;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class TestScheduledThreadPool {
public static void main(String[] args) {
// 1. 创建定时线程池
// ExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
// 注意此处不要使用ExecutorService类接收,因为schedule()和scheduleAtFixedRate()方法只是ScheduledExecutorService类的方法
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
// 2. 创建Runnable(任务)
Runnable task = new Runnable(){
public void run() {
System.out.println(Thread.currentThread().getName() + "--->运行," + "任务被执行时间:" + System.currentTimeMillis());
}
};
// 3. 向线程池提交任务
System.out.println("添加任务时间:" + System.currentTimeMillis());
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
// scheduledExecutorService.scheduleAtFixedRate(task,50,2000,TimeUnit.MILLISECONDS);// 延迟50ms后、每隔2000ms执行任务
}
}
运行结果
添加任务时间:1680073402269
pool-1-thread-1—>运行,任务被执行时间:1680073404322
结果分析
可以看到运行结果中任务在两秒后被执行了,符合预期
单线程定时线程池——SingleThreadScheduledExecutor
单线程的可以执行定时或延迟任务的线程池,核心线程数量只有一个,普通线程数量无限,普通线程执行完任务立即回收,任务队列为延时阻塞队列。
相关构造方法
// 使用默认线程工厂
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
// 需要自定义线程工厂
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
示例
package com.fastech.thread;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class TestSingleThreadScheduledExecutor {
public static void main(String[] args) {
// 1. 创建单线程定时线程池
// ExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
// 注意此处不要使用ExecutorService类接收,因为schedule()和scheduleAtFixedRate()方法只是ScheduledExecutorService类的方法
ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
// 2. 创建Runnable(任务)
Runnable task = new Runnable(){
public void run() {
System.out.println(Thread.currentThread().getName() + "--->运行," + "任务被执行时间:" + System.currentTimeMillis());
}
};
// 3. 向线程池提交任务
System.out.println("添加任务时间:" + System.currentTimeMillis());
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
scheduledExecutorService.schedule(task, 2, TimeUnit.SECONDS); // 延迟2s后执行任务
// scheduledExecutorService.scheduleAtFixedRate(task,50,2000,TimeUnit.MILLISECONDS);// 延迟50ms后、每隔2000ms执行任务
}
}
运行结果
添加任务时间:1680074041101
pool-1-thread-1—>运行,任务被执行时间:1680074043160
pool-1-thread-1—>运行,任务被执行时间:1680074043160
pool-1-thread-1—>运行,任务被执行时间:1680074043160
pool-1-thread-1—>运行,任务被执行时间:1680074043161
pool-1-thread-1—>运行,任务被执行时间:1680074043161
pool-1-thread-1—>运行,任务被执行时间:1680074043161
结果分析
可以看到运行结果中线程名称都是一样的,表示线程池中只有一个线程(核心线程)执行任务,而且任务在两秒后被执行了,符合预期
抢占式线程池——WorkStealingPool【 JDK 1.8添加】
抢占式线程池,newWorkStealingPool使用的是ForkJoinPool任务拆分合并线程池,**若指定并发数,线程数量就为并发数WorkStealingPool能够做到并行执行与设置的并发数相同的任务数量;若不指定并发数,线程数量固定为CPU处理器个数,最大限度利用CPU进行密集运算。每个线程都有一个任务队列存放任务,当自己队列的任务执行完会窃取其他线程的队列任务,因此又叫抢占式线程池,故不能保证任务的执行顺序 **。适用于任务密集情况,每个任务执行时间长短均可。注意此方法只有在 JDK 1.8 及1.8+ 版本中才能使用。
相关构造方法
// 指定并发数为线程数量
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
// 不指定并发数,线程数量固定为CPU处理器个数
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
示例
package com.fastech.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class TestWorkStealingPool {
// AtomicInteger用来计数
static AtomicInteger number = new AtomicInteger();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newWorkStealingPool(2);
for (int i = 0; i < 10; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("第" + number.incrementAndGet() + "周期线程运行当前时间【" + System.currentTimeMillis() + "】");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
// 避免其它线程任务还没运行完成,但主线程已经运行结束
TimeUnit.SECONDS.sleep(5);
System.out.println("主线程运行当前时间【" + System.currentTimeMillis() + "】");
}
}
运行结果
第2周期线程运行当前时间【1680077725927】
第1周期线程运行当前时间【1680077725927】
第3周期线程运行当前时间【1680077726935】
第4周期线程运行当前时间【1680077726935】
第6周期线程运行当前时间【1680077727943】
第5周期线程运行当前时间【1680077727943】
第7周期线程运行当前时间【1680077728956】
第8周期线程运行当前时间【1680077728956】
第9周期线程运行当前时间【1680077729967】
第10周期线程运行当前时间【1680077729967】
主线程运行当前时间【1680077730935】
结果分析
可以看到是几个任务是并行执行且无序的。而且每两个线程的执行时间是相同的。这是因为并发数只设置了2个,那么第三个任务需要被执行就得等待线程资源了。
ThreadPoolExecutor的使用【推荐使用】
通过上面6种线程池的创建方式,以及每种线程池的构造方法,可以很清楚的知道,除了WorkStealingPool线程池,其它线程池的创建都是直接或者间接的创建ThreadPoolExecutor线程池,相当于对ThreadPoolExecutor线程池做的一些封装,用来提供给不同的场景使用!
Executors方式创建线程池可能存在的问题
根据阿里巴巴Java开发手册规定:

OOM 代码演示
package com.fastech.thread;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestOOM {
static class MyOOMClass {
// 1M 空间(M KB Byte)
private byte[] bytes = new byte[1 * 1024 * 1024];
}
public static void main(String[] args) throws InterruptedException {
Thread.sleep(15 * 1000);
ExecutorService service = Executors.newCachedThreadPool();
Object[] objects = new Object[15];
for (int i = 0; i < 15; i++) {
int finalI = i;
service.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep( 200);
} catch (InterruptedException e) {
e.printStackTrace();
}
MyOOMClass myOOMClass = new MyOOMClass();
objects[finalI] = myOOMClass;
System.out.println("任务:" + finalI);
}
});
}
}
}
设置运行时环境变量
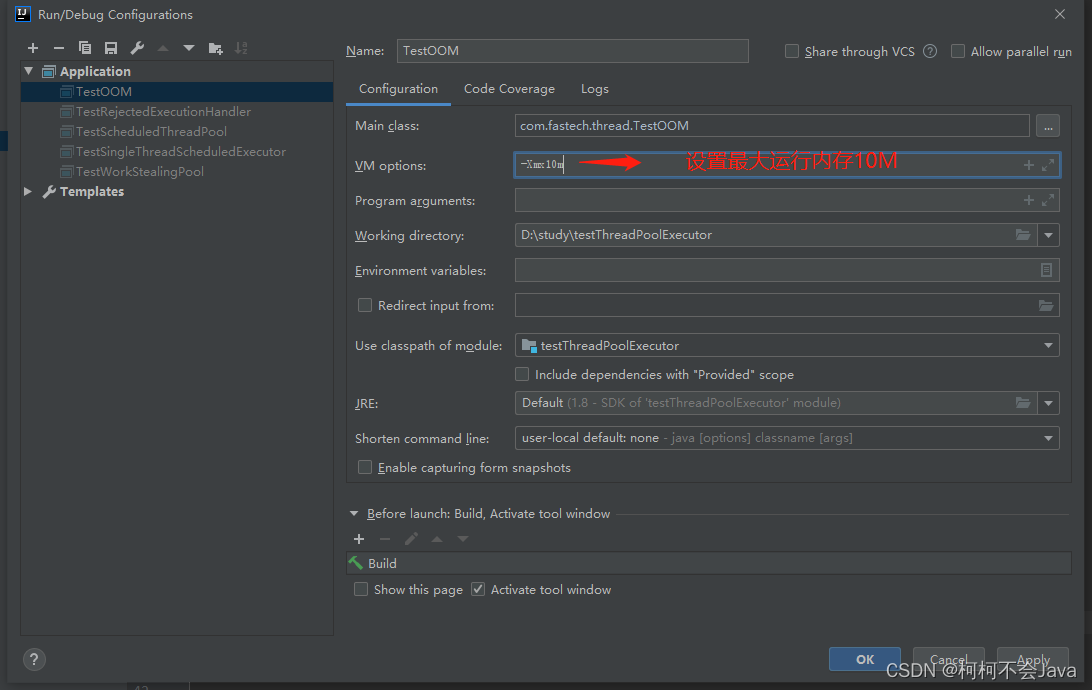
参数设置解释
-XX:标准设置,所有 HotSpot 都⽀持的参数。
-X:⾮标准设置,特定的 HotSpot 才⽀持的参数。
-D:程序参数设置,-D参数=value,程序中使⽤:System.getProperty(“获取”)。
mx 是 memory max 的简称
运行结果
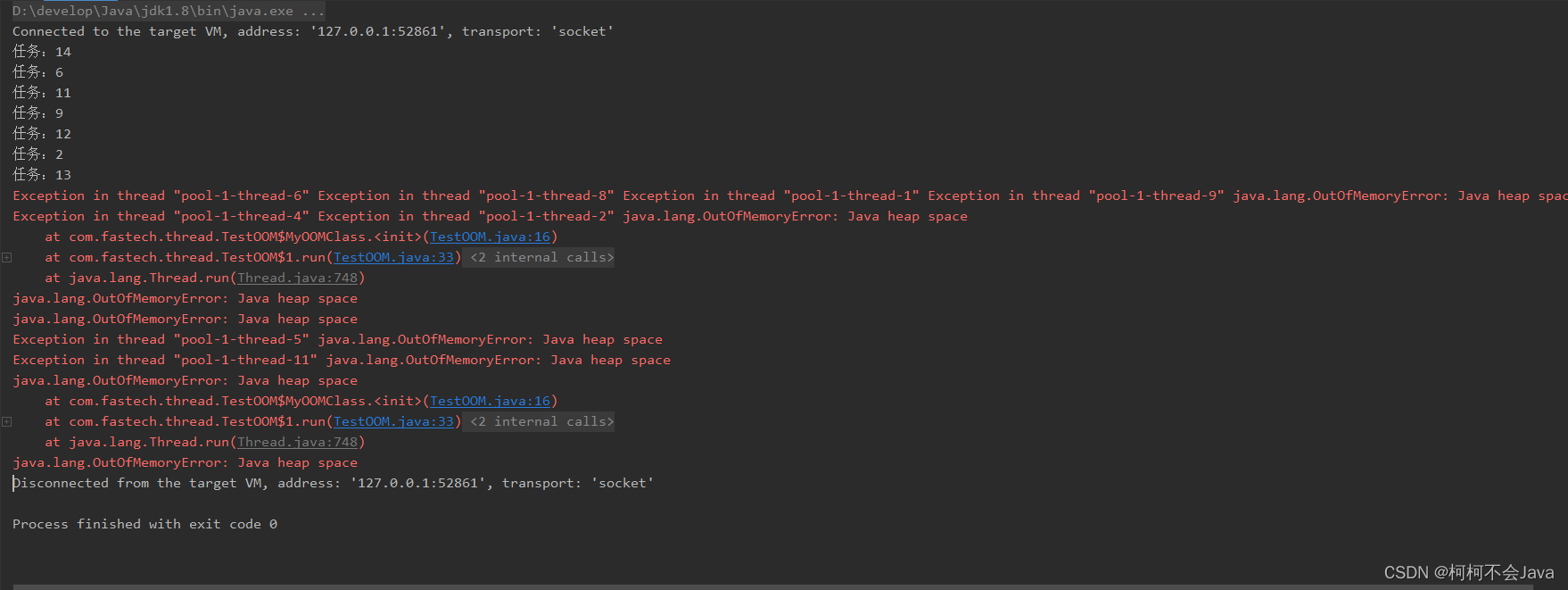
结果分析
演示代码是因为创建大数组,导致堆内存(Heap Space)没有足够空间存放创建的数组,就会抛出 java.lang.OutOfMemoryError:Javaheap space 错误。这就是常说的jvm堆内存溢出的案例。
原因分析
Javaheap space 错误产生的常见原因可以分为以下几类:
1、请求创建一个超大对象,通常是一个大数组。
2、超出预期的访问量/数据量,通常是上游系统请求流量飙升,常见于各类促销/秒杀活动,可以结合业务流量指标排查是否有尖状峰值。
3、过度使用终结器(Finalizer),该对象没有立即被 GC。
4、内存泄漏(Memory Leak),大量对象引用没有释放,JVM 无法对其自动回收,常见于使用了 File 等资源没有回收。
ThreadPoolExecutor的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
参数解释
- corePoolSize(必需):核心线程数。即池中一直保持存活的线程数,即使这些线程处于空闲。但是将allowCoreThreadTimeOut参数设置为true后,核心线程处于空闲一段时间以上,也会被回收。
- maximumPoolSize(必需):池中允许的最大线程数。当核心线程全部繁忙且任务队列打满之后,线程池会临时追加线程,直到总线程数达到maximumPoolSize这个上限。
- keepAliveTime(必需):线程空闲超时时间。当非核心线程处于空闲状态的时间超过这个时间后,该线程将被回收。将allowCoreThreadTimeOut参数设置为true后,核心线程也会被回收。
- unit(必需):keepAliveTime参数的时间单位。有:
- TimeUnit.DAYS(天)
- TimeUnit.HOURS(小时)
- TimeUnit.MINUTES(分钟)
- TimeUnit.SECONDS(秒)
- TimeUnit.MILLISECONDS(毫秒)
- TimeUnit.MICROSECONDS(微秒)
- TimeUnit.NANOSECONDS(纳秒)
- workQueue(必需):任务队列,采用阻塞队列实现。当核心线程全部繁忙时,后续由execute方法提交的Runnable将存放在任务队列中,等待被线程处理。
- threadFactory(可选):线程工厂。指定线程池创建线程的方式。
- handler(可选):拒绝策略。当线程池中线程数达到maximumPoolSize且workQueue打满时,后续提交的任务将被拒绝,handler可以指定用什么方式拒绝任务。
任务队列
使用ThreadPoolExecutor需要指定一个实现了BlockingQueue接口的任务等待队列。在ThreadPoolExecutor线程池的API文档中,一共推荐了三种等待队列,它们是:SynchronousQueue、LinkedBlockingQueue和ArrayBlockingQueue。
- SynchronousQueue:同步队列。这是一个内部没有任何容量的阻塞队列,任何一次插入操作的元素都要等待相对的删除操作,否则进行插入操作的线程就要一直等待,反之亦然。
- LinkedBlockingQueue:无界队列(严格来说并非无界,上限是Integer.MAX_VALUE),基于链表结构。使用无界队列后,当核心线程都繁忙时,后续任务可以无限加入队列,因此线程池中线程数不会超过核心线程数。这种队列可以提高线程池吞吐量,但代价是牺牲内存空间,甚至会导致内存溢出。另外,使用它时可以指定容量,这样它也就是一种有界队列了。
- ArrayBlockingQueue:有界队列,基于数组实现。在线程池初始化时,指定队列的容量,后续无法再调整。这种有界队列有利于防止资源耗尽,但可能更难调整和控制。
另外,Java还提供了另外4种队列:
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列。存放在PriorityBlockingQueue中的元素必须实现Comparable接口,这样才能通过实现compareTo()方法进行排序。优先级最高的元素将始终排在队列的头部;PriorityBlockingQueue不会保证优先级一样的元素的排序,也不保证当前队列中除了优先级最高的元素以外的元素,随时处于正确排序的位置。
- DelayQueue:延迟队列。基于二叉堆实现,同时具备:无界队列、阻塞队列、优先队列的特征。DelayQueue延迟队列中存放的对象,必须是实现Delayed接口的类对象。通过执行时延从队列中提取任务,时间没到任务取不出来。更多内容请见DelayQueue。
- LinkedBlockingDeque:双端队列。基于链表实现,既可以从尾部插入/取出元素,还可以从头部插入元素/取出元素。
- LinkedTransferQueue:由链表结构组成的无界阻塞队列。这个队列比较特别的时,采用一种预占模式,意思就是消费者线程取元素时,如果队列不为空,则直接取走数据,若队列为空,那就生成一个节点(节点元素为null)入队,然后消费者线程被等待在这个节点上,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,并唤醒该节点等待的线程,被唤醒的消费者线程取走元素。
线程工厂
线程工厂指定创建线程的方式,这个参数不是必选项,Executors类已经为我们非常贴心地提供了一个默认的线程工厂,如果不指定线程工厂则使用默认的线程工厂。
/**
* The default thread factory
*/
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
当然我们也可以自定义工厂,实现ThreadFactory类,重写newThread方法即可。
package com.fastech.thread;
import java.util.concurrent.ThreadFactory;
public class SimpleThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable r) {
return new Thread(r);
}
}
上述线程工厂,只是创建了一个新线程,其他什么都没干。实际使用时,一般不会创建这么简单的线程工厂。
自定义一个能指定最大线程数上限的工厂。
package com.fastech.thread;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @ClassName: FixCountThreadFactory
* @Description:
* @Author: zhangjin
* @Date: 2023/3/29
*/
public class FixCountThreadFactory implements ThreadFactory {
private final int MAX_THREAD;
private final AtomicInteger count = new AtomicInteger(0);
public FixCountThreadFactory(int maxThread) {
MAX_THREAD = maxThread;
}
@Override
public Thread newThread(Runnable r) {
int incrementAndGet = count.incrementAndGet();
if(incrementAndGet > MAX_THREAD)
{
count.decrementAndGet();
return null;
}
return new Thread(r);
}
}
拒绝策略
线程池有一个重要的机制:拒绝策略。当线程池workQueue已满且无法再创建新线程池时,就要拒绝后续任务了。拒绝策略需要实现RejectedExecutionHandler接口,不过Executors框架已经为我们实现了4种拒绝策略。除此之外,也可以自定义拒绝策略。
-
AbortPolicy(默认):丢弃任务并抛出RejectedExecutionException异常。
-
CallerRunsPolicy:直接运行这个任务的run方法,但并非是由线程池的线程处理,而是交由任务的调用线程处理。
-
DiscardPolicy:直接丢弃任务,不抛出任何异常。
-
DiscardOldestPolicy:将当前处于等待队列列头的等待任务强行取出,然后再试图将当前被拒绝的任务提交到线程池执行。
-
自定义拒绝策略:
package com.fastech.thread; import java.util.concurrent.*; public class TestRejectedExecutionHandler { public static void main(String[] args) { // 自定义拒绝策略 ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 10, TimeUnit.SECONDS, new LinkedBlockingDeque<>(2), new RejectedExecutionHandler() { @Override public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { System.out.println("我执行了自定义拒绝策略"); } }); for (int i = 0; i < 5; i++) { executor.submit(()->{ System.out.println("任务名:"+Thread.currentThread().getName()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } }); } // 关闭线程池 executor.shutdown(); } }运行结果
我执行了自定义拒绝策略
任务名:pool-1-thread-2
任务名:pool-1-thread-1
任务名:pool-1-thread-1
任务名:pool-1-thread-2结果分析
定义了一个核心线程和最大线程都为2(即只有2个核心线程)、线程空闲超时时间10s,任务队列采用双端队列,长度为2,线程工厂默认,自定义拒绝策略的线程池,提交了五个任务,可以看到有一个任务被拒绝了,打印在最前面因为5个任务同时被加入线程池有两个任务被核心线程执行,两个任务放到了任务队列,还有一个任务被拒绝。拒绝的这个任务肯定是最快执行到的。
测试代码
package com.fastech.thread;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class TestThreadPoolExecutor {
public static void main(String[] args) {
// 创建线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(3,
5,
5,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(5));
// 向线程池提交任务
for (int i = 0; i < executor.getCorePoolSize(); i++) {
executor.execute(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 2; j++) {
System.out.println(Thread.currentThread().getName() + ":" + j);
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
// 关闭线程
executor.shutdown(); // 设置线程池的状态为SHUTDOWN,然后中断所有没有正在执行任务的线程
// executor.shutdownNow(); // 设置线程池的状态为STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表,该方法要慎用,容易造成不可控的后果
}
}
运行结果
pool-1-thread-1:0
pool-1-thread-3:0
pool-1-thread-2:0
pool-1-thread-2:1
pool-1-thread-3:1
pool-1-thread-1:1
线程池状态
线程池有5种状态
volatile int runState;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
runState表示当前线程池的状态,它是一个 volatile 变量用来保证线程之间的可见性。
下面的几个static final变量表示runState可能的几个取值,有以下几个状态:
线程池各个状态切换框架图:
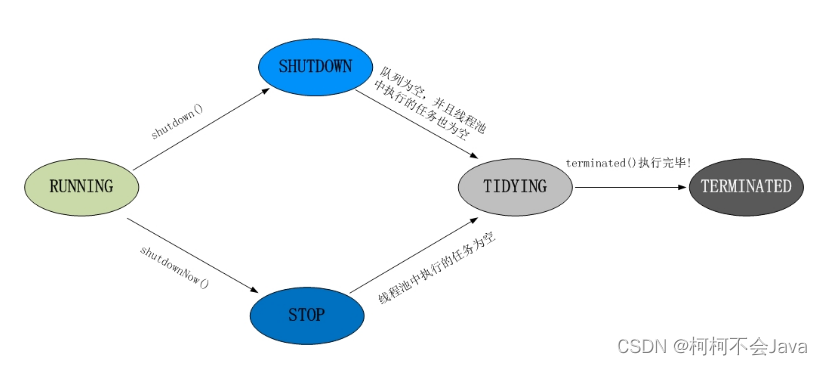
1、RUNNING
(1) 状态说明:线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
(2) 状态切换:线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0!
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
2、 SHUTDOWN
(1) 状态说明:线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务,它会等待所有任务执行完毕。
(2) 状态切换:调用线程池的shutdown()方法时,线程池由RUNNING -> SHUTDOWN。
3、STOP
(1) 状态说明:线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
(2) 状态切换:调用线程池的shutdownNow()方法时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
4、TIDYING
(1) 状态说明:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
(2) 状态切换:当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
5、 TERMINATED
(1) 状态说明:线程池彻底终止,就变成TERMINATED状态。
(2) 状态切换:线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
初始化&容量调整&关闭&任务提交
线程初始化
默认情况下,创建线程池之后,线程池中是没有线程的,需要提交任务之后才会创建线程。
在实际中如果需要线程池创建之后立即创建线程,可以通过以下两个方法办到:
prestartCoreThread():初始化一个核心线程
prestartAllCoreThreads():初始化所有核心线程,并返回初始化的线程数
public boolean prestartCoreThread() {
return addIfUnderCorePoolSize(null); //注意传进去的参数是null
}
public int prestartAllCoreThreads() {
int n = 0;
while (addIfUnderCorePoolSize(null)) //注意传进去的参数是null
++n;
return n;
}
线程池关闭
ThreadPoolExecutor提供了两个方法,用于线程池的关闭:
shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务
shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
线程池容量调整
ThreadPoolExecutor提供了动态调整线程池容量大小的方法:
setCorePoolSize():设置核心池大小
setMaximumPoolSize():设置线程池最大能创建的线程数目大小
当上述参数从小变大时,ThreadPoolExecutor进行线程赋值,还可能立即创建新的线程来执行任务。
向线程池提交任务
向线程池提交任务可以使用两个方法,分别为 execute() 和 submit()。
execute() 方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。execute() 方法中传入的是 Runnable 类的实例。
submit() 方法用于提交需要返回值的任务。线程池会返回一个 Future 类型的对象,通过 future 对象可以判断任务是否执行成功,并且可以通过 future 的 get() 方法来获取返回值。get() 方法会阻塞当前线程直到任务完成,使用 get(long timeout, TimeUnit unit)方法会阻塞当前线程一段时间后立即返回,这时候可能任务没有执行完。
常见面试题
Q:假设我们有一个线程池,核心线程数为10,最大线程数也为20,任务队列为100。现在来了100个任务,线程池里现在有几个线程运行?
A:平常人可能就直接回答10个,但是基本这样回答就回去等通知了~这道题正确的答案是"不一定!",因为并没指明是哪一种线程池机制。如果是ThreadPoolExecutor线程池,没什么问题就是10个。但是,有一种线程池机制的是这样的,这一种线程池叫EagerThreadPoolExecutor线程池。EagerThreadPoolExecutor线程池通过自定义队列的这么一种形式,改写了线程池的机制。这种线程池的机制是核心线程数不够了,先起线程,当线程达到最大值后,后面的任务就丢进队列!
Q:线程只能在任务到达时才启动吗?
A:默认情况下,即使是核心线程也只能在新任务到达时才创建和启动。但是我们可以使用 prestartCoreThread(启动一个核心线程)或 prestartAllCoreThreads(启动全部核心线程)方法来提前启动核心线程。
Q:线程池创建的线程会一直运行吗?
A:可以通过keepAliveTime参数来控制线程是否一直运行,一般来说当线程数超过核心线程数之后如果多出来的线程没有任务执行那么在等待keepAliveTime时间之后就会被销毁。核心线程一般不受keepAliveTime参数影响,也就是说它会一直存在,因为allowCoreThreadTimeOut默认为false,但是如果将allowCoreThreadTimeOut参数为true,核心线程也会受KeepAliveTime参数的影响。需要注意的是如果你想将allowCoreThreadTimeOut参数设置为true,那么keepAliveTime参数必须大于0。否则会抛出非法参数异常。
Q:线程池中核心线程数量大小怎么设置?
A:「CPU密集型任务」:比如像加解密,压缩、计算等一系列需要大量耗费 CPU 资源的任务,大部分场景下都是纯 CPU 计算。尽量使用较小的线程池,一般为CPU核心数+1。因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,会造成CPU过度切换。
「IO密集型任务」:比如像 MySQL 数据库、文件的读写、网络通信等任务,这类任务不会特别消耗 CPU 资源,但是 IO 操作比较耗时,会占用比较多时间。可以使用稍大的线程池,一般为2*CPU核心数。IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候有其他线程去处理别的任务,充分利用CPU时间。
另外:线程的平均工作时间所占比例越高,就需要越少的线程;线程的平均等待时间所占比例越高,就需要越多的线程;
以上只是理论值,实际项目中建议在本地或者测试环境进行多次调优,找到相对理想的值大小。
Q:说说submit(和 execute两个方法有什么区别?
A:submit() 和 execute() 都是用来执行线程池的,只不过使用 execute() 执行线程池不能有返回值,而使用 submit() 可以使用 Future 接收线程池执行的返回值。
Q:线程池为什么需要使用(阻塞)队列,不使用非阻塞队列?
A:阻塞队列主要是用于生产者-消费者模型的情况。举例一种情况,当核心线程达到最大时,此时新建的任务会加到任务队列里面去,后续,核心线程有线程空闲时,就会从任务队列里面取出任务执行。后续当任务队列中任务数为空时。如果使用的时阻塞队列,此时线程会被阻塞直到阻塞队列中有了元素。当队列中有元素后,被阻塞的线程会自动被唤醒(不需要我们编写代码去唤醒)。这样提供了极大的方便性。如果使用非阻塞队列,它不会对当前线程产生阻塞,就必须额外地实现同步策略以及线程间唤醒策略,这个实现起来就非常麻烦。