对于一些简单的动态网页,可以使用我们之前提起过的逆向分析法
之前写过动态网页的逆向分析法。
但是有一些网站非常复杂,如天猫产品评论,使用逆向分析法很难找到请求的url地址。除此之外,有些网站对爬虫非常不友好,会对地址和数据进行加密,分析起来异常困难,如QQ邮箱、百度登录等。
因此,这里介绍另一种方法,即使用浏览器渲染引擎。这个方法在爬取过程中会打开一个浏览器加载该网页,自动操作浏览器浏览各个网页。用一句简单而通俗的话说,就是使用浏览器渲染方法将爬取动态网页变成爬取静态网页。我们可以用Python的Selenium库模拟浏览器完成抓取。
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,浏览器自动按照脚本代码做出单击、输入、打开、验证等操作,就像真正的用户在操作一样。
Selenium支持各种浏览器,包括Chrome、Safari、Firefox等主流界面式浏览器,也支持无界面浏览器。通俗的说Selenium通过浏览器驱动,可以对浏览器进行控制。Selenium的安装既包括Selenium模块的安装,也包括浏览器驱动的下载和安装。
推荐使用谷歌的Chrome浏览器。
一、 安装Selenium
Selenium模块安装 Selenium现在最新的版本为3.1,由于2.X和3.X在使用上有差别,本书选择3.0以上版本。Selenium官方地址为: http://www.seleniumhq.org/。可选择下载后安装。由于pip使用的源多为国外镜像,网速较慢。可以使用pip -i参数,指定国内镜像源。
无镜像下载:
pip install selenium
有镜像下载:
pip install selenium -i https:/pypi.tuna.tsinghua.edu.cn/simple
// https://pypi.tuna.tsinghua.edu.cn/simple为清华镜像
当然你也可以去找其他镜像 。
二、浏览器驱动下载
浏览器驱动的下载安装
浏览器驱动也是一个独立的程序,是由浏览器厂商提供的,不同的浏览器需要不同的浏览器驱动。比如Chrome浏览器和火狐浏览器有各自不同的驱动程序。
浏览器驱动在接收到我们自动化程序发送的界面操作请求后,会转发请求给浏览器,
让浏览器去执行对应的自动化操作。浏览器执行完操作后,会将自动化的结果返回给浏览器驱动,浏览器驱动再通过HTTP响应的消息返回给我们的自动化程序的客户端库。自动化程序的客户端库接收到响应后,将结果转化为数据对象返回给程序代码。
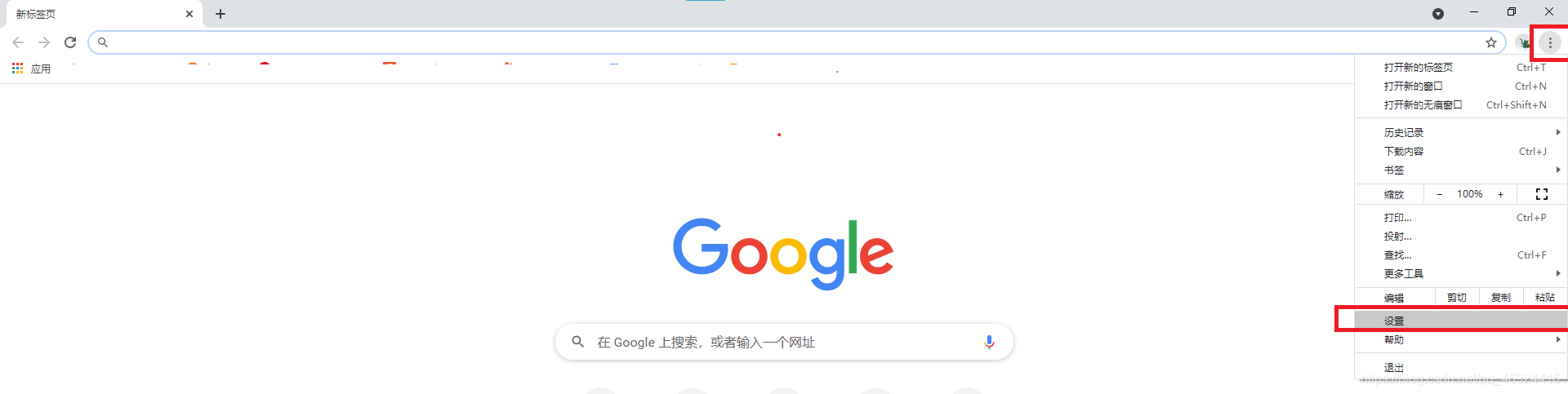
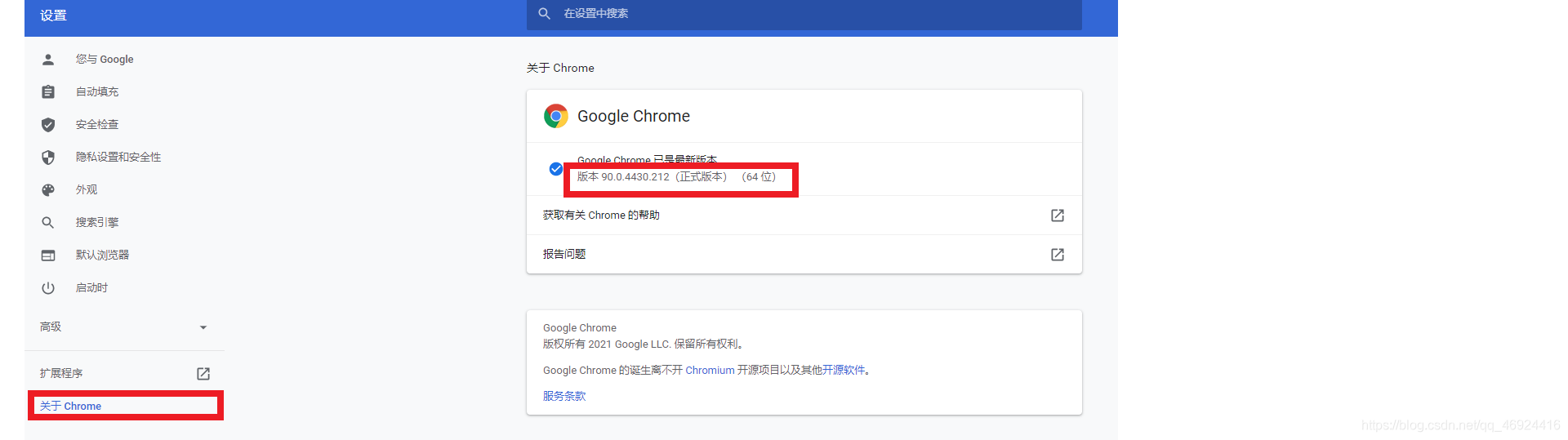
在下载Chrome浏览器驱动前,首先确定Chrome浏览器的版本。点击Chrome浏览器“自定义及控制Goole Chrome”按钮,选择“帮助”、“关于Google Chrome(G)”,查看浏览器的实际版本号。
chromedriver的版本一定要与Chrome的版本一致(也不是很严格 ),不然就不起作用。
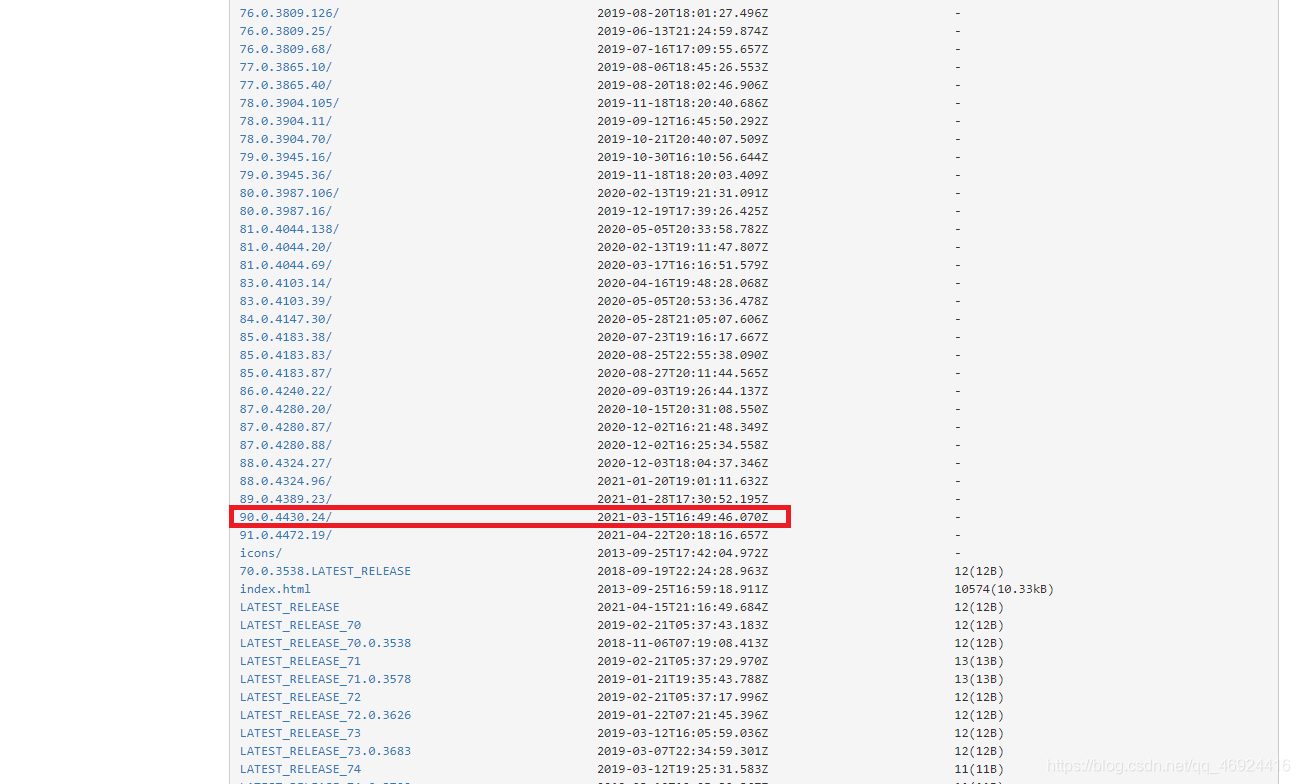
有两个下载地址:
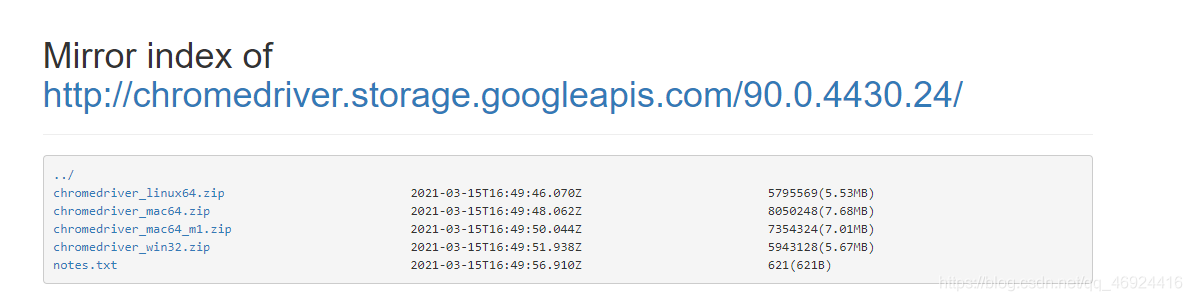
例如我的版本书是90.0.4430.212 但是我在官网上并没有找到版本号相同的,这个时候呢,就可以找版本号相近的。所以我找的90.0.4430.24这个版本的chromedriver。
然后就看你的自己的系统是什么 下载对应的版本就好了。
然后就是配置环境的问题了 ,我没有配置。因为不配置也行 [手动滑稽]。
要是需要配置环境的同学 ,也可以去搜索一下啦怎么配置啦!
三、Selenium基本使用
from selenium import webdriver #导入webdriver
import time
wd=webdriver.Chrome("D:\..\chromedriver.exe") #获取Chrome驱动实例
wd.get("https://www.baidu.com") #打开百度
time.sleep(3) #睡眠3秒
print(wd.page_source)
wd.close() #关闭当前一个窗口
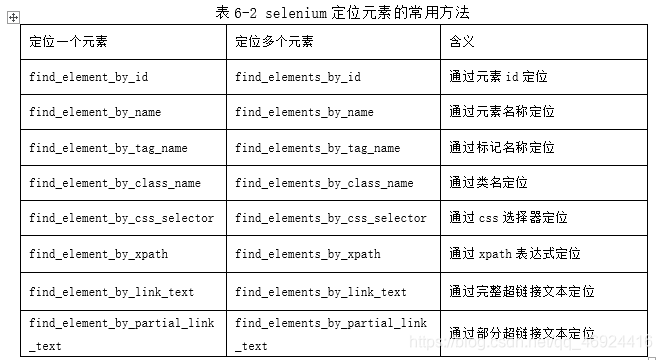
3.1 元素选择器
从命名上看,定位一个元素的单词是element,定位多个单词使用的单词是elements。
从使用角度来讲