目录
前言
在我们上网浏览网页时,会发现各种制作精美的网页,这些网页往往包含文字、链接、图片、视频等各种各样的资源,那么这些网页是怎么实现的呢?我们打开开发工具查看源代码,可能会完全看不懂,仿佛一本难懂的天书,但我们静下心来,一步步学习相关知识,当我们掌握相关知识之后,这些“天书”表达的意思就一目了然了
一. HTML基本结构
以下为HTML的基础结构,看不懂?没关系,我们慢慢学习了解
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>我们先尝试运行这个基础框架,看看会得到什么结果:
我们可以看到,我们的标题为Document,什么内容都没有
而我们在<title>和</title> 之间找到了Document的字样,那么这是不是我们网页写标题的地方呢?
答案是:是的,这就是控制网页的标题的部分,而由两个<>包含起来的内容,称作标签
1. title标签
通过上面的思考我们了解了title标签的作用:在title标签内部的内容,即为网页的标题
现在我们对其进行修改,改成"My First Web Page",看看效果:
<title>My First Web Page</title>
可以看到,我们的网页标题已经可以由我们自由修改了
2. 网页内容
我们可以修改网页标题之后,我们想在网页内部添加内容,该怎么办呢?
我们注意到title标签对应的是head标签,是网页头的部分,在下面还有一个body标签,那是不是就是网页的身体呢?
我们不妨直接输入部分文字,看看具体的效果:
<body>
Hello World!
</body>
我们看到,在body标签中间输入了"Hello World!"的内容,我们的网页上也出现了相应的内容
所以,这个body标签所包含的内容就是网页的主体内容,我们之后会一步一步的介绍
3. 语言
我们注意到html文件一开头有这样一行代码,似乎与语言有关:
<html lang="en">没错,这里的lang其实是language的简写,而en是English的简写,表示这个网页的语言是英语
那么,我们把它修改一下,改成中文,我们的内容会不会变成中文呢?
<html lang="cn">
我们看到,修改语言后并没有实现我们想象中的自动翻译的结果,反而浏览器的翻译标签不见了
这说明,我们修改的语言并不是给我们看的,而是告诉浏览器这个网页的语言是什么,再由浏览器决定需不需要翻译
4. 解码方式
我们还发现了一个熟悉的文字"UTF - 8",这是文件的编码方式,我们在记事本上曾经见过它:
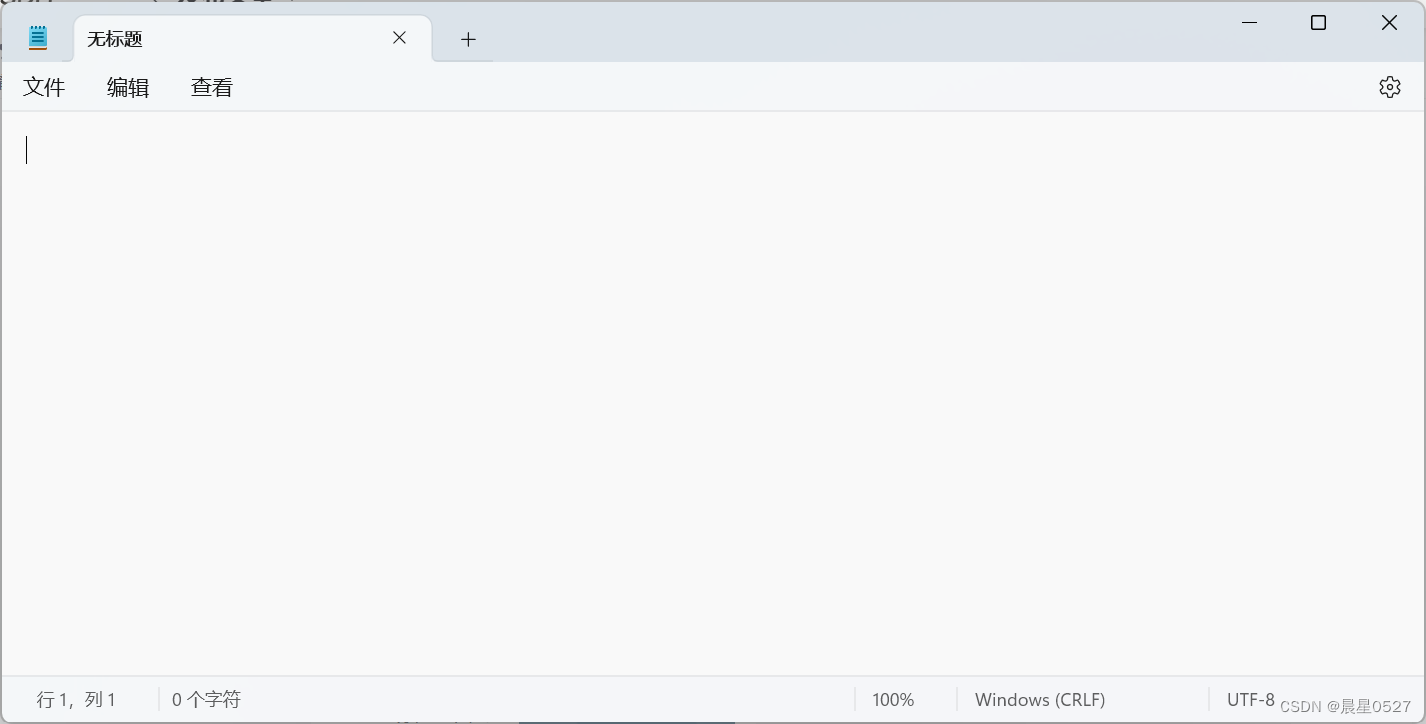
我们可以在右下角看到,记事本默认编码方式为UTF - 8,那么这一行是不是与文件的编码有关系呢?
<meta charset="UTF-8">我们对我们的编译器的编码方式进行修改,将其改成"ISO 8859-1",保持代码不动,看看效果:
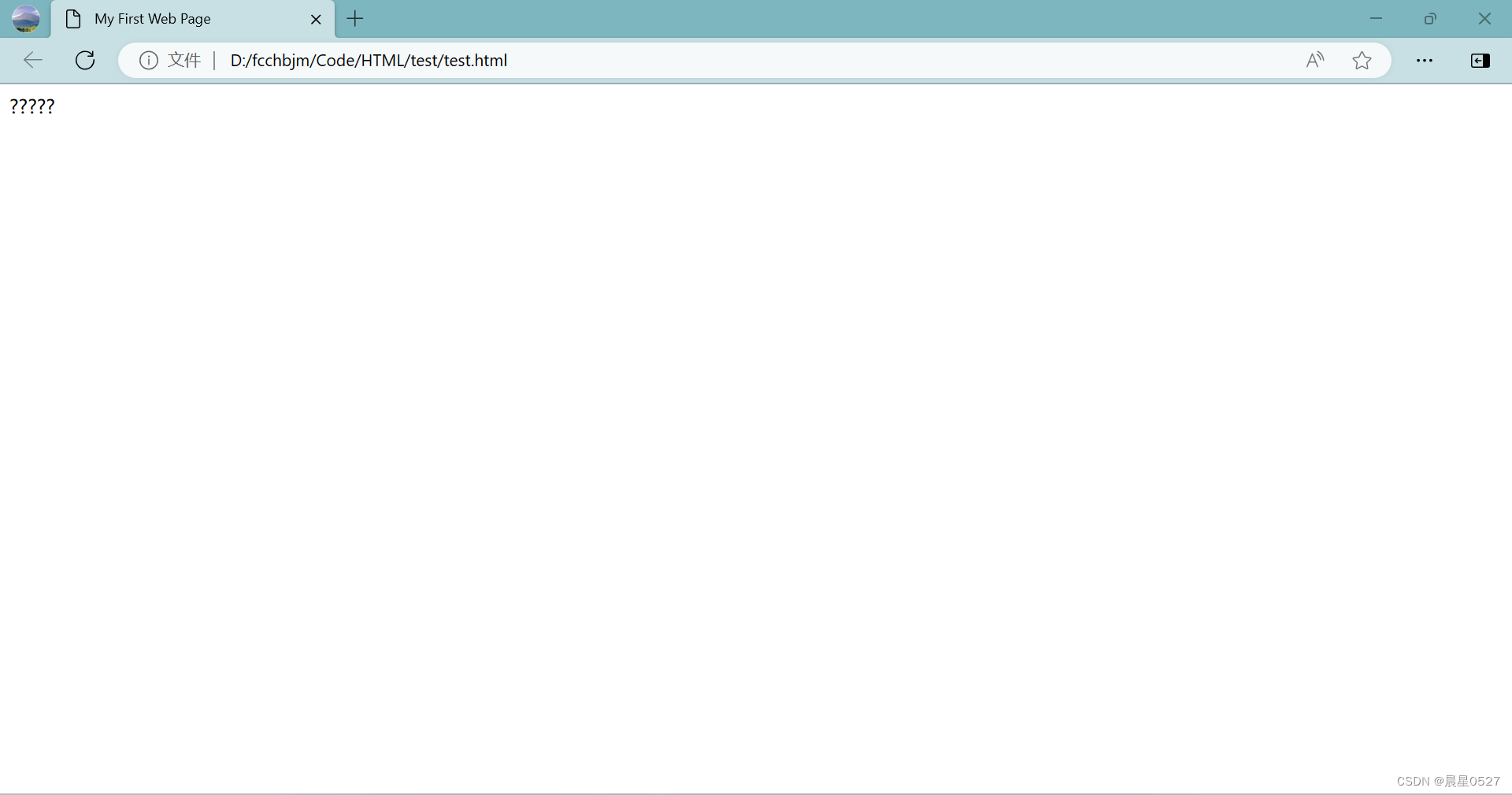
我们可以看到,我们的内容无法显示了,这说明解码格式与编码格式不匹配会影响内容的显示
而这里的 "UTF - 8",其实是浏览器对文件的解码方式
5. 其它部分
我们看看第一行:
<!DOCTYPE html>这表示HTML的版本为HTML5
再看第五行:
<meta name="viewport" content="width=device-width, initial-scale=1.0">这表示对移动端进行适配
二 . 文字编辑
1. 段落与换行
现在,我们的body标签内有一大段文字,我们在代码部分对其进行了排版,显示效果会不会像我们整理的一样井井有条呢?
<body>
1.ASCII编码
8bit(一个字节),能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如'\n','\t','#','@'等字符进行了编码。
2.GB2312编码
16bit(2个字节),适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。该标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
3. GBK编码
16bit(2个字节),兼容GB2312,收录了 21003 个汉字,共有 23940 个码位。而且它与 Unicode 组织的Unicode编码完全兼容。
4.Unicode 编码
通常16bit(2个字节),为了统一所有文字的编码,Unicode应运而生,这是一种所有符号的编码。从0x000000 - 0x10FFFF, 对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP)。从 0x010000 - 0x10FFFF 再划分为其他平面。unicode只是一种编码规范,定义了任意一个字符到数字的一一对应关系,不如”汉字”对应的数字是0x6c49和0x5b57。虽然Unicode给所有的字符一一对应的关系,但是如果用来储存太浪费空间,比如,字符'A',ASCII编码只需要一个字节(8位)。但是用Unicode就翻了一辈。互联网的诞生,需要传输的数据非常多,如果都是用Unicode编码传输会造成很大的浪费。UTF-8,UTF-16,UTF-32就诞生。而且最广泛的就是常用的UTF-8。
5.UTF-8
Unicode Transformation Format,可变长度编码,通常使用1~4字节为每个字符编码,兼容ASCII编码,这是一种Unicode的一种转换格式。
</body>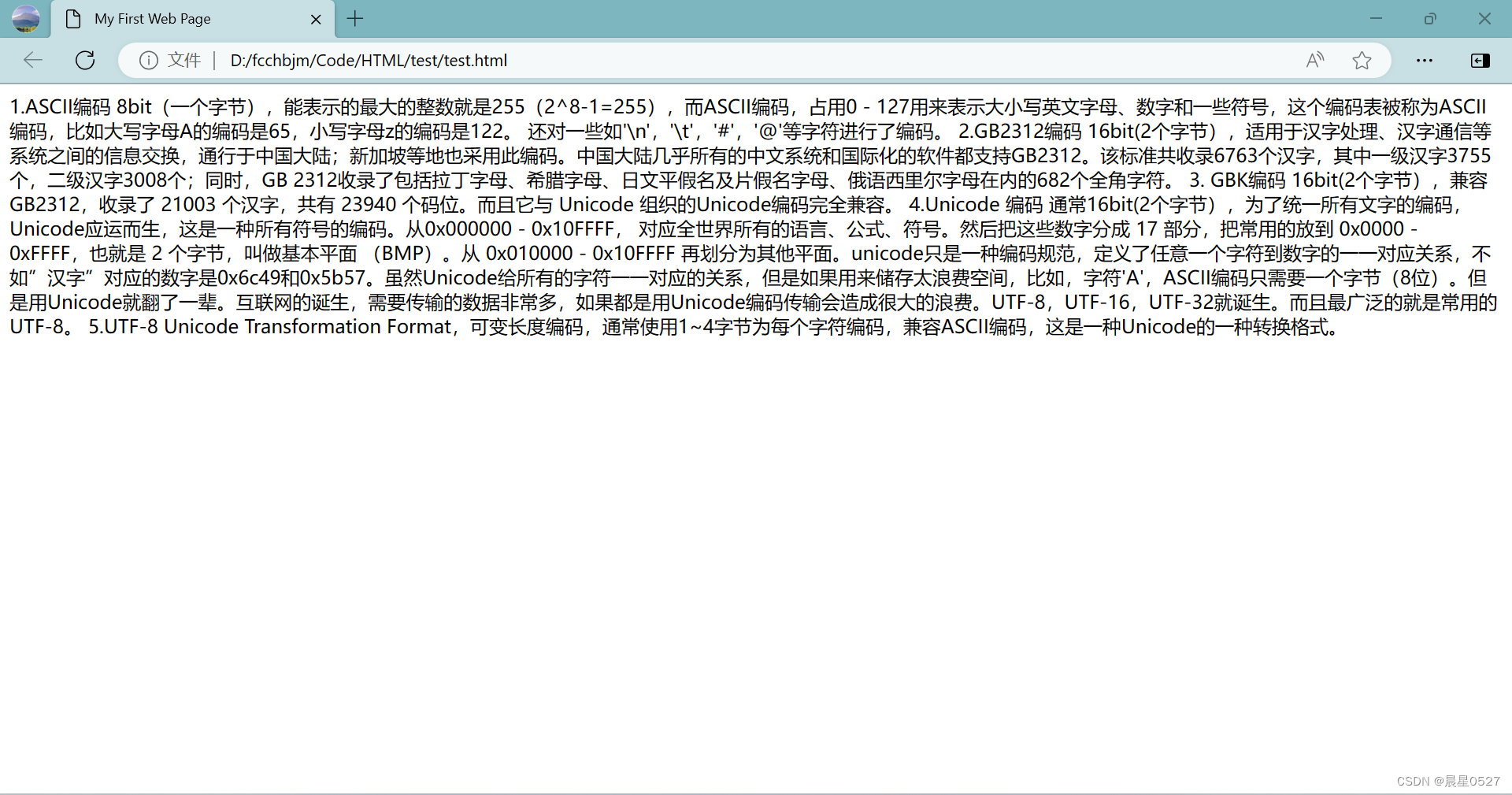
我们可以看到,在代码层面进行排版与规划 ,并不能在我们的网页界面上显示出来
这里,我们就要所以段落标签与换行标签
1.1 段落换行标签
<p>与</p>适用于对文字进行分段,分别在段落的头和尾加上这两个标签,就可以实现分段
<body>
<p>1.ASCII编码</p>
8bit(一个字节),能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如'\n','\t','#','@'等字符进行了编码。
<p>2.GB2312编码</p>
16bit(2个字节),适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。该标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
<p>3. GBK编码</p>
16bit(2个字节),兼容GB2312,收录了 21003 个汉字,共有 23940 个码位。而且它与 Unicode 组织的Unicode编码完全兼容。
<p>4.Unicode 编码</p>
通常16bit(2个字节),为了统一所有文字的编码,Unicode应运而生,这是一种所有符号的编码。从0x000000 - 0x10FFFF, 对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP)。从 0x010000 - 0x10FFFF 再划分为其他平面。unicode只是一种编码规范,定义了任意一个字符到数字的一一对应关系,不如”汉字”对应的数字是0x6c49和0x5b57。虽然Unicode给所有的字符一一对应的关系,但是如果用来储存太浪费空间,比如,字符'A',ASCII编码只需要一个字节(8位)。但是用Unicode就翻了一倍。互联网的诞生,需要传输的数据非常多,如果都是用Unicode编码传输会造成很大的浪费。UTF-8,UTF-16,UTF-32就诞生。而且最广泛的就是常用的UTF-8。
<p>5.UTF-8</p>
Unicode Transformation Format,可变长度编码,通常使用1~4字节为每个字符编码,兼容ASCII编码,这是一种Unicode的一种转换格式。
</body> 可以看到,我们使用p标签顺利的对文字进行了分段:
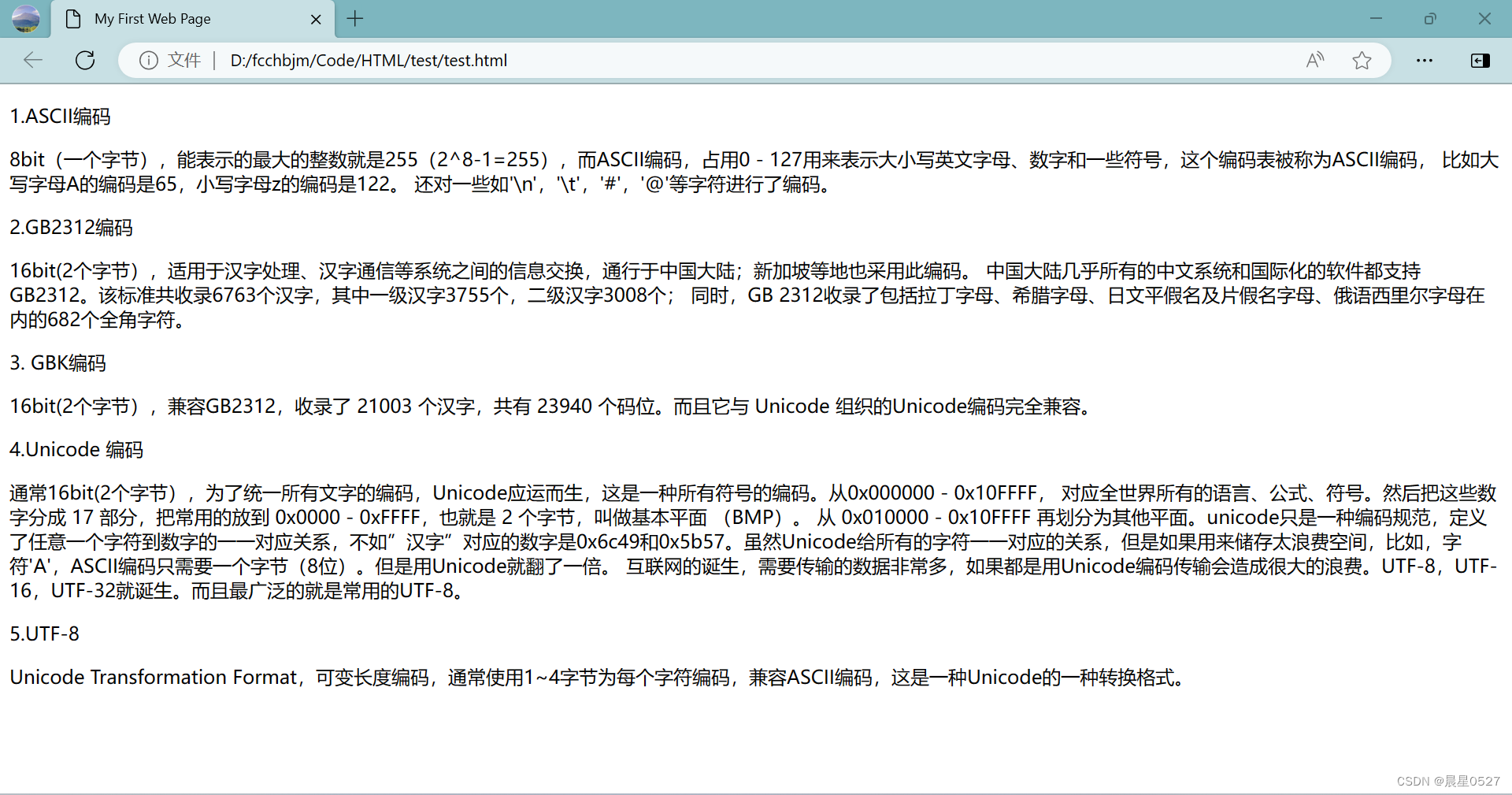
1.2 换行标签
<br>适用于对文字进行换行,在需要换行的地方加上这个标签,就可以实现分段
<body>
<p>1.ASCII编码</p>
8bit(一个字节),能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,
<br>比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如'\n','\t','#','@'等字符进行了编码。
<p>2.GB2312编码</p>
16bit(2个字节),适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。
<br>中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。该标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;
<br>同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
<p>3. GBK编码</p>
16bit(2个字节),兼容GB2312,收录了 21003 个汉字,共有 23940 个码位。而且它与 Unicode 组织的Unicode编码完全兼容。
<p>4.Unicode 编码</p>
通常16bit(2个字节),为了统一所有文字的编码,Unicode应运而生,这是一种所有符号的编码。从0x000000 - 0x10FFFF, 对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP)。
<br>从 0x010000 - 0x10FFFF 再划分为其他平面。unicode只是一种编码规范,定义了任意一个字符到数字的一一对应关系,不如”汉字”对应的数字是0x6c49和0x5b57。虽然Unicode给所有的字符一一对应的关系,但是如果用来储存太浪费空间,比如,字符'A',ASCII编码只需要一个字节(8位)。但是用Unicode就翻了一倍。
<br>互联网的诞生,需要传输的数据非常多,如果都是用Unicode编码传输会造成很大的浪费。UTF-8,UTF-16,UTF-32就诞生。而且最广泛的就是常用的UTF-8。
<p>5.UTF-8</p>
Unicode Transformation Format,可变长度编码,通常使用1~4字节为每个字符编码,兼容ASCII编码,这是一种Unicode的一种转换格式。
</body>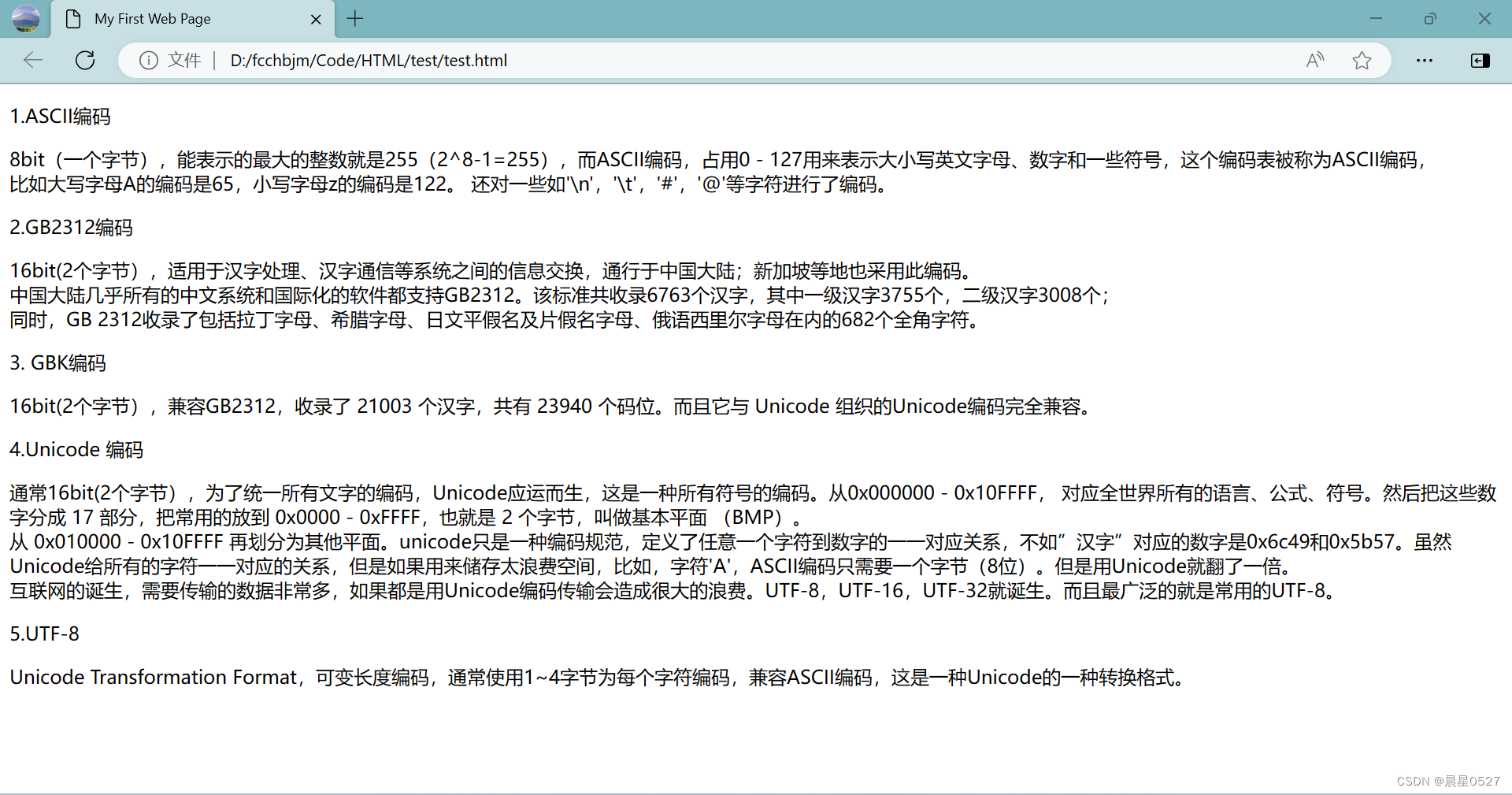
1.3 区别
通过上面的两张图片的对比,我们可以知道:
段落标签换行比换行标签换行间距更大
1.4 分级标题标签
我们可以使用<h1>~<h6>的六种标题标签对标题进行分级,具体效果如下
<body>
<h1>这是h1标题</h1>
<h2>这是h2标题</h2>
<h3>这是h3标题</h3>
<h4>这是h4标题</h4>
<h5>这是h5标题</h5>
<h6>这是h6标题</h6>
<p>1.ASCII编码</p>
8bit(一个字节),能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,
<br>比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如'\n','\t','#','@'等字符进行了编码。
<p>2.GB2312编码</p>
16bit(2个字节),适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。
<br>中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。该标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;
<br>同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
<p>3. GBK编码</p>
16bit(2个字节),兼容GB2312,收录了 21003 个汉字,共有 23940 个码位。而且它与 Unicode 组织的Unicode编码完全兼容。
<p>4.Unicode 编码</p>
通常16bit(2个字节),为了统一所有文字的编码,Unicode应运而生,这是一种所有符号的编码。从0x000000 - 0x10FFFF, 对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP)。
<br>从 0x010000 - 0x10FFFF 再划分为其他平面。unicode只是一种编码规范,定义了任意一个字符到数字的一一对应关系,不如”汉字”对应的数字是0x6c49和0x5b57。虽然Unicode给所有的字符一一对应的关系,但是如果用来储存太浪费空间,比如,字符'A',ASCII编码只需要一个字节(8位)。但是用Unicode就翻了一倍。
<br>互联网的诞生,需要传输的数据非常多,如果都是用Unicode编码传输会造成很大的浪费。UTF-8,UTF-16,UTF-32就诞生。而且最广泛的就是常用的UTF-8。
<p>5.UTF-8</p>
Unicode Transformation Format,可变长度编码,通常使用1~4字节为每个字符编码,兼容ASCII编码,这是一种Unicode的一种转换格式。
</body>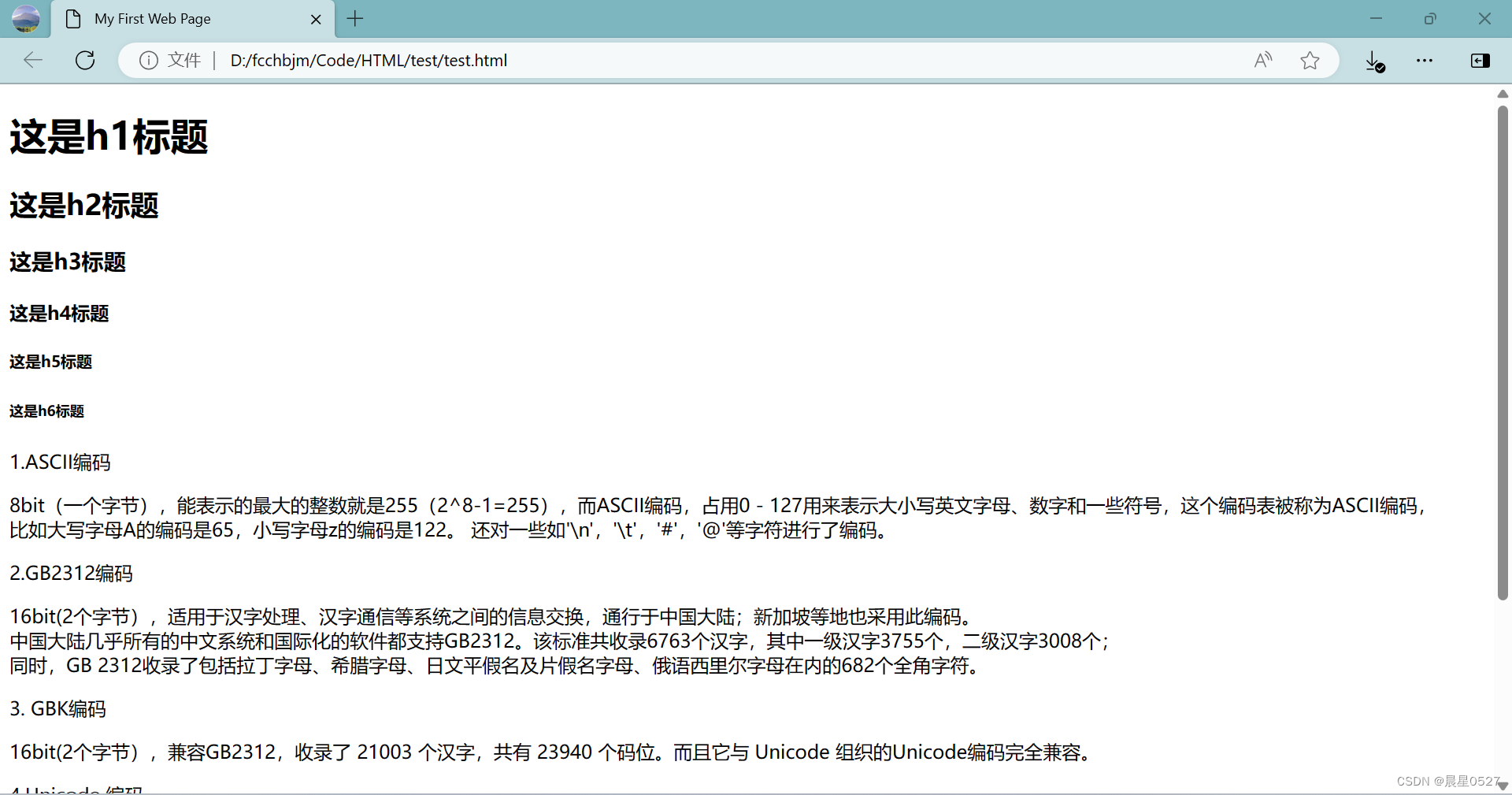
2. 标签标记
2.1 更改背景色、文字颜色
要想更改整体背景色和文字颜色,就要数字body标签的参数,相关参数如下
<body bgcolor="#RRGGBB" text="#RRGGBB">16进制颜色代码,语法格式:#RRGGBB
如:
| HTML / CSS 颜色名称 | 十六进制代码 #RRGGBB |
|---|---|
| 浅蓝 | #E0FFFF |
| 青色 | #00FFFF |
| 水色 | #00FFFF |
| 蓝晶 | #7FFFD4 |
| 海蓝宝石 | #66CDAA |
| 浅绿色 | #AFEEEE |
| 绿松石 | #40E0D0 |
| 绿松石色 | #48D1CC |
| 深蓝绿色 | #00CED1 |
| 浅海绿色 | #20B2AA |
| cadetblue | #5F9EA0 |
| 深蓝 | #008B8B |
| 蓝绿色 | #008080 |
<body bgcolor="#66CDAA" text="#000000">设置背景颜色为 海蓝宝石,文字默认颜色为黑色:
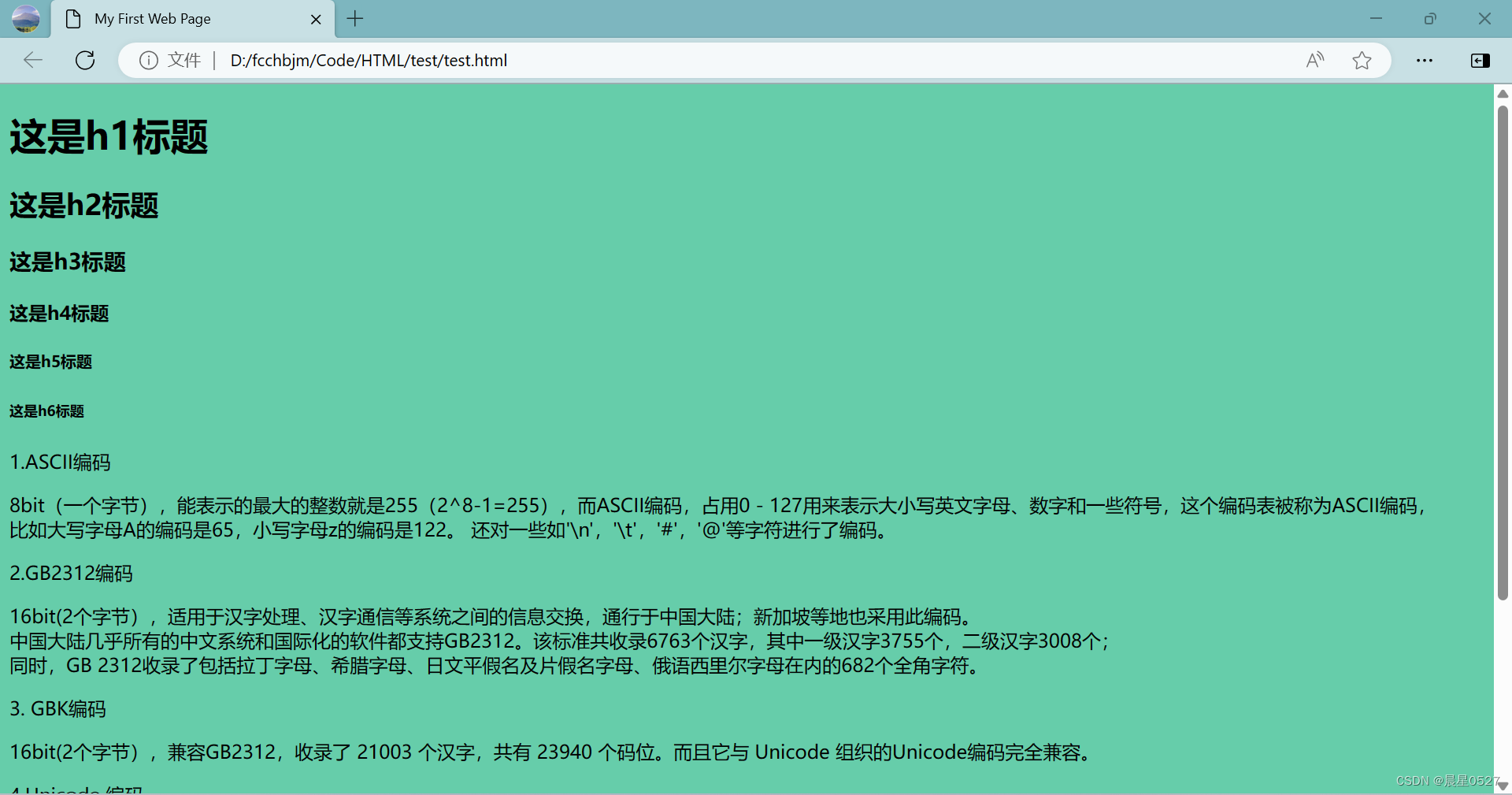
2.2 更改部分文字颜色、字号、字体
想要更改部分文字颜色,需要使用font标签,并配置相关参数
<font size="字号" color="字体颜色" face="字体"> 文字 </font>
如:将部分文字大小改为10号,颜色改为红色,字体为微软雅黑
<font size="10" color="#FF0000" face="微软雅黑">Unicode Transformation Format,可变长度编码</font>
2.3 文字加粗、斜体、下划线、删除线
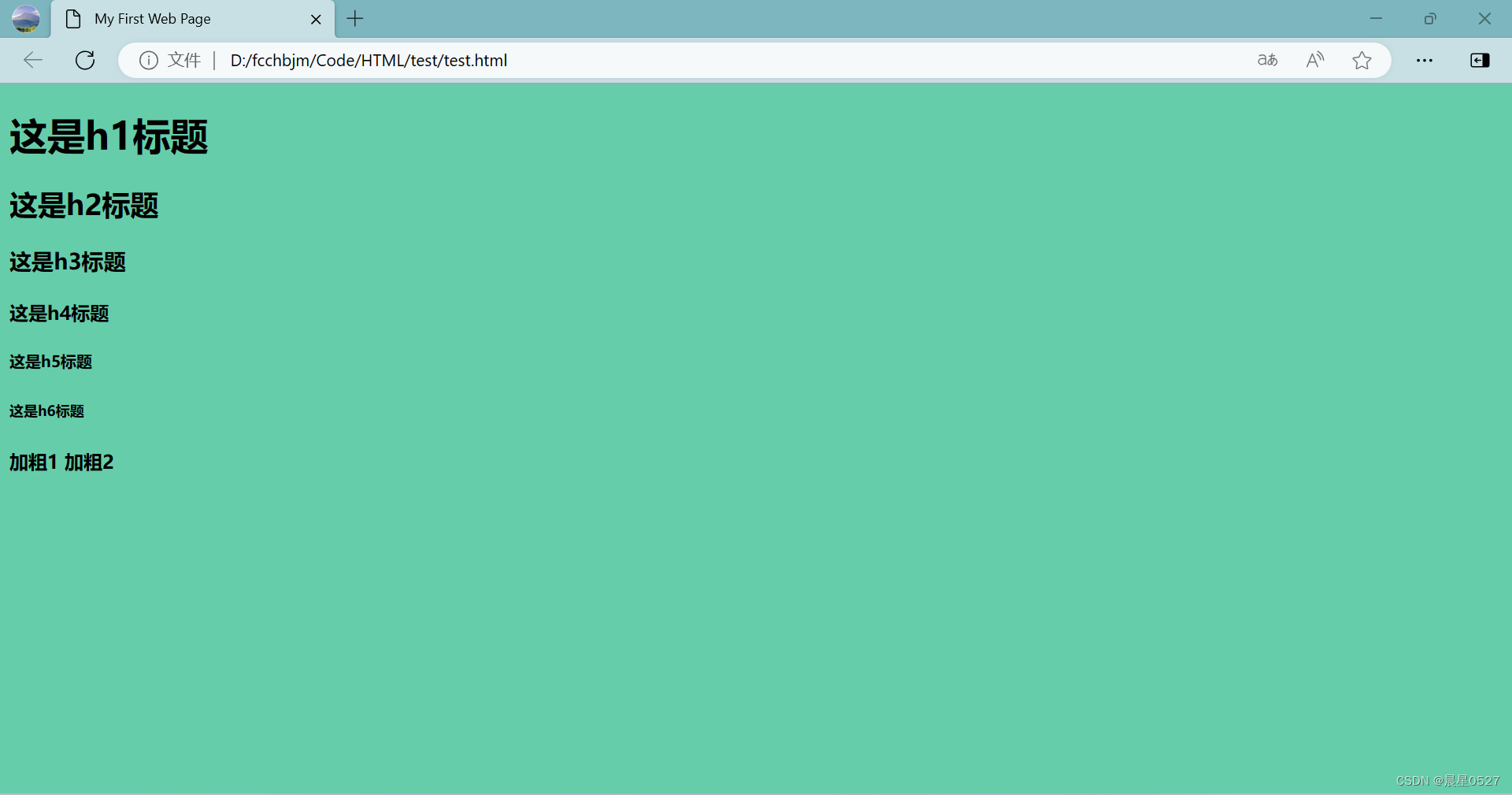
2.3.1 加粗
要想使文字加粗,可以使用strong标签或者b标签
<strong>加粗1</strong>
<b>加粗2</b>
2.3.2 斜体
要想使文字变成斜体,可以使用em标签或者i标签
<em>倾斜1</em>
<i>倾斜2</i>
2.3.3 删除线
要想使文字带上删除线,可以使用del标签或者s标签
<del>删除线1</del>
<s>删除线2</s>
2.3.4 下划线
要想使文字带上下划线,可以使用ins标签或者u标签
<ins>下划线1</ins>
<u>下划线2</u>
2.3.5 区别
以上每种文字变化都有两种方式,效果相同,但前者相当于后者有强调作用
2.4 其它标签标记
还有其它许许多多的标签标记,如:
2.4.1 预格式化标记:
如果我们像让空格和换行像我们代码里写的一样,就可以使用预格式化标记
因为HTML的输出会把文本上一些额外的字符(包括空格、制表符和回车符等)都忽略。
如果不需要重新排版内容,可以用预格式化标记<pre>…</pre>通知浏览器
如:
</head>
<body bgcolor="#66CDAA" text="#000000">
<h1>这是h1标题</h1>
<h2>这是h2标题</h2>
<h3>这是h3标题</h3>
<h4>这是h4标题</h4>
<h5>这是h5标题</h5>
<h6>这是h6标题</h6>
<pre>
ASCII编码
8bit(一个字节),能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如'\n','\t','#','@'等字符进行了编码。
GB2312编码
16bit(2个字节),适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。该标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
GBK编码
16bit(2个字节),兼容GB2312,收录了 21003 个汉字,共有 23940 个码位。而且它与 Unicode 组织的Unicode编码完全兼容。
Unicode 编码
通常16bit(2个字节),为了统一所有文字的编码,Unicode应运而生,这是一种所有符号的编码。从0x000000 - 0x10FFFF, 对应全世界所有的语言、公式、符号。然后把这些数字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 个字节,叫做基本平面 (BMP)。从 0x010000 - 0x10FFFF 再划分为其他平面。unicode只是一种编码规范,定义了任意一个字符到数字的一一对应关系,不如”汉字”对应的数字是0x6c49和0x5b57。虽然Unicode给所有的字符一一对应的关系,但是如果用来储存太浪费空间,比如,字符'A',ASCII编码只需要一个字节(8位)。但是用Unicode就翻了一辈。互联网的诞生,需要传输的数据非常多,如果都是用Unicode编码传输会造成很大的浪费。UTF-8,UTF-16,UTF-32就诞生。而且最广泛的就是常用的UTF-8。
UTF-8,Unicode Transformation Format,可变长度编码
通常使用1~4字节为每个字符编码,兼容ASCII编码,这是一种Unicode的一种转换格式。
</pre>
</body>
2.4.2 标题标记:
<hn align="对齐方式"> 标题文本</hn>
三. 图片
1. 添加本地图片
1.1 同一级文件夹添加
想要在网页中添加图片,就要使用img标签
<img src="图片文件路径" alt="提示文本" height="图片高度" width="图片宽度" />
src是文件路径,包含本地路径和网络路径
alt是提示文本,如果图片加载失败,就会显示该文字
height和width是对图片的高和宽进行调整
现在,我在代码文件夹内放了一张图片test.png,我们尝试显示该图片到网页:
<body bgcolor="#66CDAA" text="#000000">
<img src="./test.png" alt="photo"/>
</body>
可以看到,图片成功的显示了出来
1.2 下一级文件夹添加
我们现在创建了一个名为photo的新文件夹,并将test.png移入,代码就应当这样修改:
<body bgcolor="#66CDAA" text="#000000">
<img src="./photo/test.png" alt="photo"/>
</body>由于显示效果相同,这里就不放网页图片了
1.3 上一级文件夹添加
现在现在将test.png移入上上一级文件夹中,代码就应当这样修改:
<body bgcolor="#66CDAA" text="#000000">
<img src="../test.png" alt="photo"/>
</body>由于显示效果相同,这里就不放网页图片了
2. 添加网络照片
想要使用网络上的图片,只需要将src项修改成网络图片链接就行了
<body bgcolor="#66CDAA" text="#000000">
<img src="https://ts1.cn.mm.bing.net/th/id/R-C.a12a85c8cba0bfdd33ea75de310adcf1?rik=a1HEamY8pbA1Bg&riu=http%3a%2f%2fpic1.arkoo.com%2fsllyc%2fpicture%2fp1abk21onrers9df1o741h251pq7.jpg&ehk=pVDnQz8TDa%2bS4O89gR4v3Y%2fZmR9bXCaMQmy6h6VCpp0%3d&risl=&pid=ImgRaw&r=0" alt="photo"/>
</body>
四. 超链接
要想在网页中使用超链接,就要使用a标签
<a href="目标URL" target="目标窗口"> 指针文本 </a>
我们做一个百度的超链接:
<body bgcolor="#66CDAA" text="#000000">
<a href="http://www.baidu.com" target="_blank">百度</a>
</body>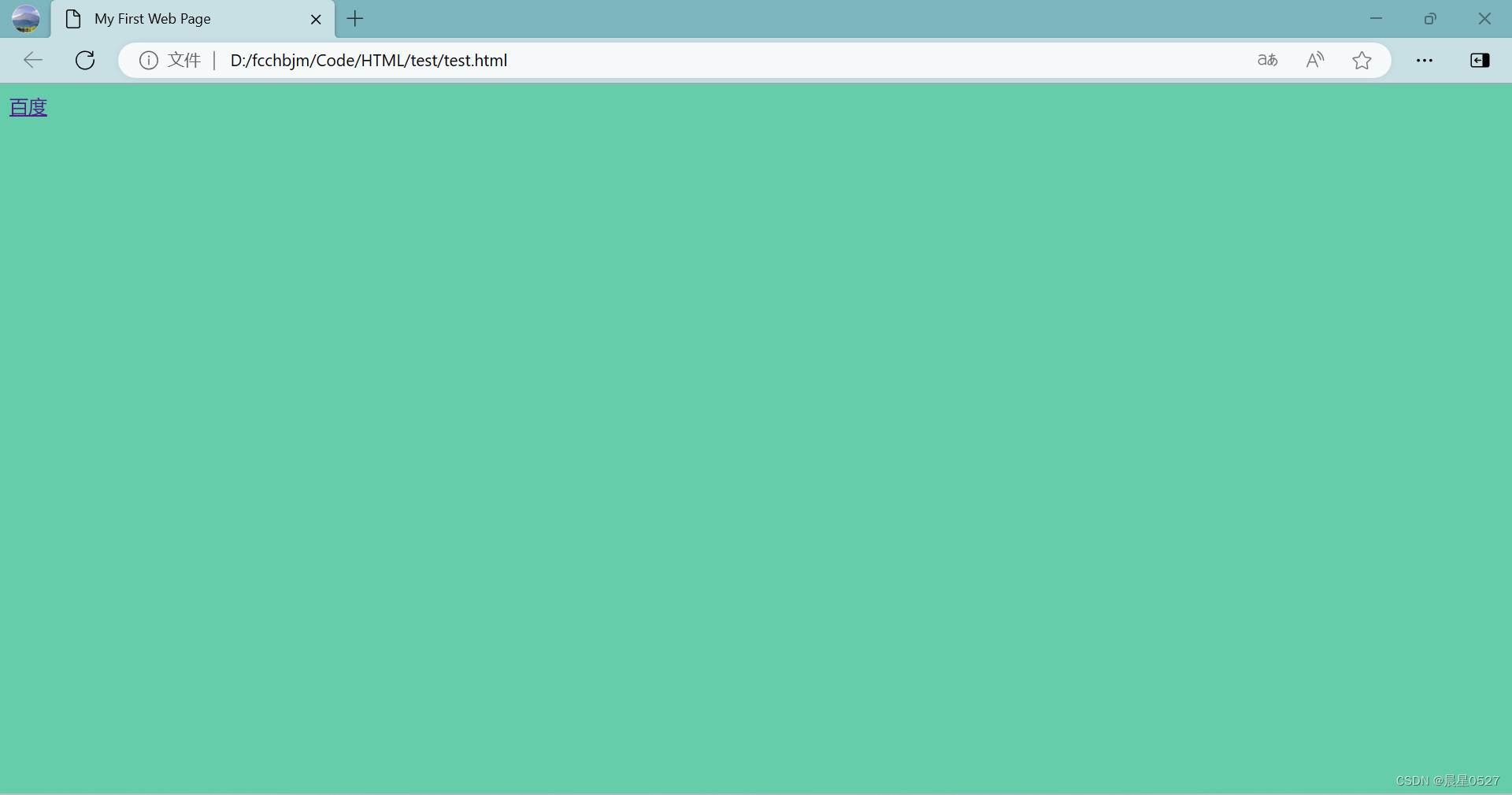
本篇文章到这里就结束了,如果你有好的建议与意见,欢迎在评论区友好交流,或者私信我,我们一起学习,一起进步。
感谢观看!