Faster R-CNN的组成
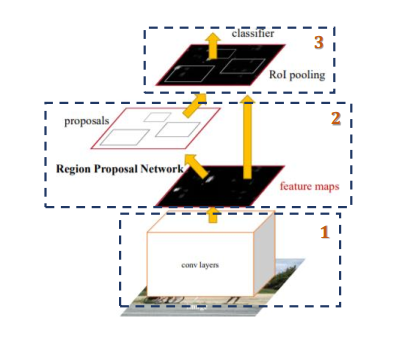
Faster R-CNN主要由两部分组成:Backbone、区域建议网络(RPN)和Fast R-CNN
近似:Faster RCNN = RPN + Fast R-CNN)
1、Backbone(神经网络模型进行特征提取)
- pre-train(预训练)
- fine-tuning(微调)
- re-train
输入的是固定大小的图片,经过卷积层提取特征图(feature maps)
2、RPN:Region Proposal Net(生成区域建议 )
代替selective searchs生成区域建议
1、输入feature map(特征图),然后经过区域建议网络(RPN)生成区域建议(region proposals)
2、然后通过softmax判断锚框(anchors)属于前景(foreground)或者背景(background)
3、再利用边界框(bounding box)回归修正锚框(positive anchors)获得精确的候选区域(proposals)
3、Fast RCNN: ROI + {Classification; Regression}(感兴趣池化)
1、该层输入的是特征图(feature maps)和候选区域(proposals)
2、综合这些信息后提取具有候选区域的特征图(proposal feature maps)
4、分类
将感兴趣池化(Roi pooling)生成的具有候选区域的特征图(proposal feature
maps)分别传入softmax分类和边界盒回归(bounding box regression)获得检测物体类别和检测框最终的精确位置。
1、Backbone
(1)作用:特征提取(一次)
- 不用给每个ROI(感兴趣区域)都提取特征
- 通过RPN(区域建议网络)将提取的特征来生成区域建议
(2)结构:ZF / Resnet / VGG16(13 conv + 13 Relu + 4 Pooling)
- 把网络结构当积木来用的思维
- 比如想要算快一些,网络换成mobile net, shuffle net都是可以的
(3)输出 :Batchsize x Channel x H/16 x W / 16 (VGG16举例)
- faster rcnn将尺寸为1000 x 800大小的feature map归一化到600 x 800的尺寸,则其输出的特征图大小为1 x 256 x 38 x 50
(4)整体网络结构:Backbone获取特征图信息,然后用RPN网络筛选候选框和ROIPooling输出相同尺寸的特征图,整个faster rcnn如下图
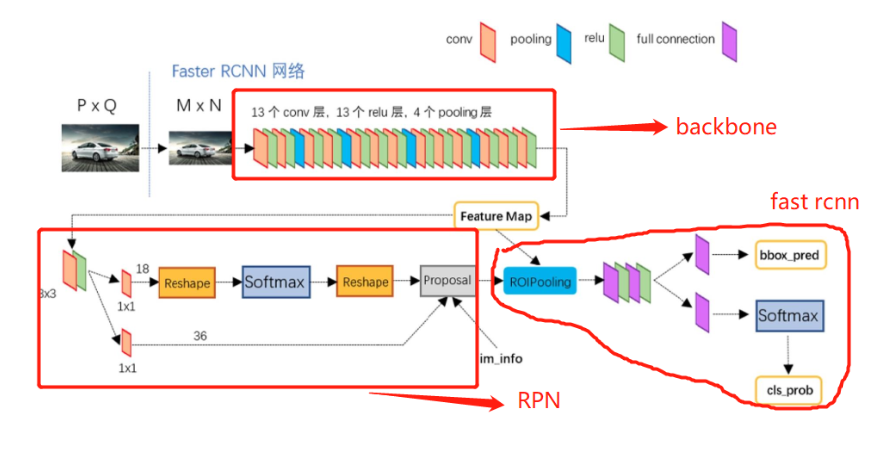
2、 区域建议网络(RPN)
2.1 RPN结构解释
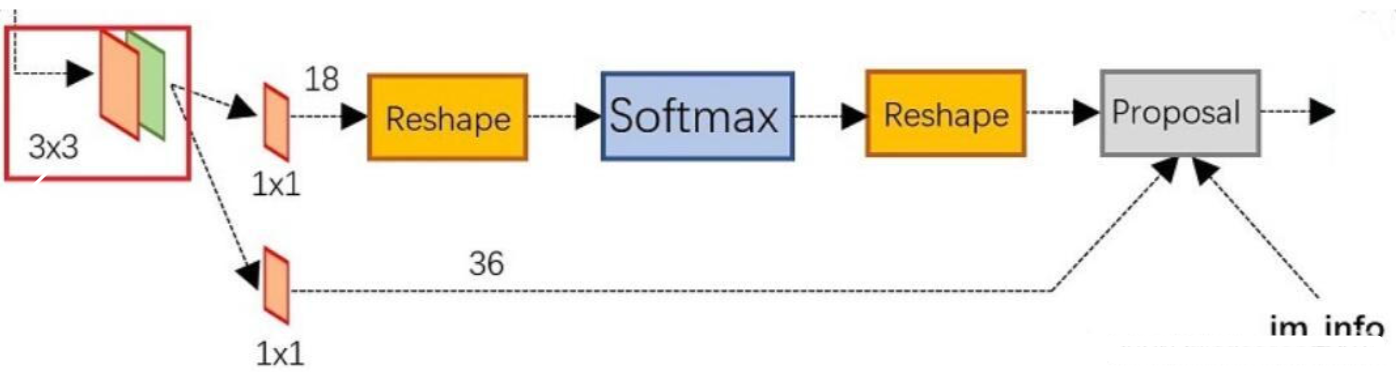
3×3卷积:用于语义转换,可以增加网络网络复杂度,增加区域建议网络(RPN)的你和能力
1x1卷积:用于通道转换,原则上可以转换成任意通道的特征图
feature map经过3×3卷积后,分成了两条线:
第一条线:通过softmax分类锚框(anchors)获得前景(positive)和背景(negative),要检测的目标是前景(positive)。由于是2分类(有无物体两种分类),所以它的维度是2k score(2个分数)。
2k score,因为RPN是提候选框,还不用判断类别,所以只要求区分是不是物体就行,2个分数:前景(物体)的分数,和背景的分数;
第二条线:计算对于锚框(anchors)的边界盒回归(bounding box regression)偏移量,以获得精确的proposal。它的维度是4k coordinates(4个坐标)
4个坐标:是指针对原图坐标的偏移,首先一定要记住是原图;
最后的Proposal层则负责综合积极的锚框(positive anchors)和对应边界盒回归(bounding box regression)偏移量获取最终的区域建议(proposals),同时剔除太小和超出边界的建议(proposals)。
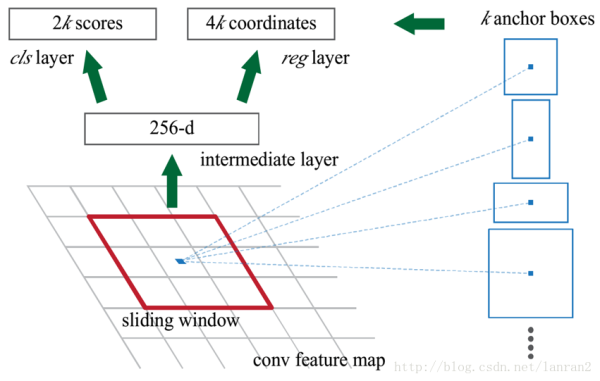
RPN网络的输入是前面CNN output的feature maps。我们在feature map上做一个大小为3x3的滑窗操作, 得到一个channel是256维的特征图,尺寸与input的特征图相同,维度是256HW。
对这个256维的向量,我们分别做两次1x1卷积操作,一个得到2k score, 一个得到4k coordinates。
这个2k score只区分是不是目标,输出候选区域属于前景(物体)和背景的分数,这里注意,这里的分类只区分是否包含目标,至于所包含目标的类别,是Faster-RCNN最后的分类网络干的事情。4k coordinates指的是对原图坐标的偏移。
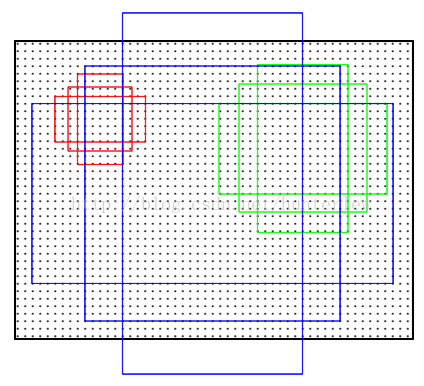
论文预先设定好生成9个anchors。我们前面说到对于feature map, 我们有一个3*3的滑窗操作。对于每次滑窗所划到的3x3的区域,就以该区域中心点为坐标,生成9个anchor。anchor它的本质是,将相同尺寸的输入,得到不同尺寸的输出。它们的中心相同,但是有不同的长宽比和尺度。这9个anchor, 中心坐标一样,但是大小各不相同,如下图:
RPN的目标:
- 生成region proposal(区域建议)
- 因为流程是:先RPN找出区域建议的物体,然后在做更加精细的类别划分和Bbox回归,这种方式被称为Two-Stage
- 因此有人认为两阶段检测比一阶段检测更准
3、 Fast R-CNN
Fast R-CNN = ROI + {Classification; Regression}
4、RPN损失函数+Fast R-CNN损失
上文提到的k就是anchors的数量,所以2k个分数就是9个anchors的共18个分数,36(4×9)个坐标。对于每个anchor, 计算anchor与ground-truth bounding boxes的IoU,大于0.7则判定为有目标,小于0.3则判定为背景,介于0.3-0.7,则设为0,不参与训练,RPN损失函数:
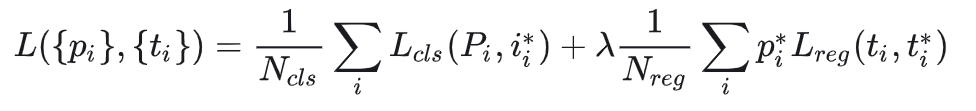
损失函数有两部分:分类损失和回归损失
分类损失:

回归损失:
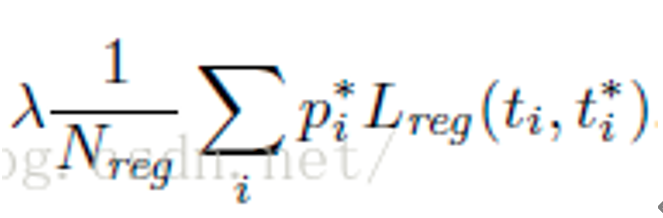
对应着RPN的两条路线,即是否包含目标和bbox的坐标与anchor坐标的回归误差。
注意回归误差这一项中 ,L与p相称,也就是说,如果anchor不包含目标,那么box输出位置是不算误差的,对于Lreg,只计算 Lcls,判定为有目标的anchor。
Lcls就是交叉熵,Lreg是分类的损失;
计算每个anchor分配的四个坐标和ground truth的坐标的偏移量,用的是L1范数。看一下pytorch的官方实现:
self.rpn_loss_cls = F.cross_entropy(rpn_cls_score, rpn_label)
self.rpn_loss_box = _smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, rpn_bbox\
inside_weights,rpn_bbox_outside_weights, sigma=3, dim=[1,2,3])