今天是参加昇思25天学习打卡营的第15天,今天打卡的课程是“FCN图像语义分割”,这里做一个简单的分享。
1.简介
FCN图像语义分割是的计算机视觉领域的深度学习模型,今天学习的目标就是如何在mindspore环境下实现FCN图像语义分割。首先今天需要掌握的两个核心概念是全卷积网络(FCN)和图像语义分割。
全卷积网络(FCN)
全卷积网络(Fully Convolutional Networks,FCN)是UC Berkeley的Jonathan Long等人于2015年在Fully Convolutional Networks for Semantic Segmentation[1]一文中提出的用于图像语义分割的一种框架。
FCN是首个端到端(end to end)进行像素级(pixel level)预测的全卷积网络。
5d338438707040750cae91f0415d35c0.png
图像语义分割
图像语义分割(semantic segmentation)是图像处理和机器视觉技术中关于图像理解的重要一环,AI领域中一个重要分支,常被应用于人脸识别、物体检测、医学影像、卫星图像分析、自动驾驶感知等领域。语义分割的目的是对图像中每个像素点进行分类。与普通的分类任务只输出某个类别不同,语义分割任务输出与输入大小相同的图像,输出图像的每个像素对应了输入图像每个像素的类别。语义在图像领域指的是图像的内容,对图片意思的理解。
2.FCN图像语义分割模型
FCN主要用于图像分割领域,是一种端到端的分割方法。核心包括三种技术:
卷积化
本次采用的模型为VGG16模型,。VGG16是深度学习中经典的卷积神经网络(Convolutional Neural Network,CNN)之一,由牛津大学的Karen Simonyan和Andrew Zisserman在2014年提出。VGG16网络以其深度和简洁性而闻名,是图像分类中的重要里程碑。VGG16网络由多个卷积层和全连接层组成。它的整体结构相对简单,所有的卷积层都采用小尺寸的卷积核(通常为3x3),步幅为1,填充为1。每个卷积层后面都会跟着一个ReLU激活函数来引入非线性。
VGG16网络主要由三个部分组成:
输入层:接受图像输入,通常为224x224大小的彩色图像(RGB)。
卷积层:VGG16包含13个卷积层,其中包括五个卷积块。
全连接层:在卷积层后面是3个全连接层,用于最终的分类。
c2acb5c79c10c1c24288eebb02f0ecbe.png
上采样
在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图的大小的稠密图像预测,需要对得到的特征图进行上采样操作。使用双线性插值的参数来初始化上采样逆卷积的参数,后通过反向传播来学习非线性上采样。在网络中执行上采样,以通过像素损失的反向传播进行端到端的学习。
跳跃结构
利用上采样技巧对最后一层的特征图进行上采样得到原图大小的分割是步长为32像素的预测,称之为FCN-32s。由于最后一层的特征图太小,损失过多细节,采用skips结构将更具有全局信息的最后一层预测和更浅层的预测结合,使预测结果获取更多的局部细节。将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。 Skips结构将深层的全局信息与浅层的局部信息相结合。
e749c9bfc7c319ac3bf8fc66db435f6d.png
3.模型实现
整个模型实习的步骤包括:
数据下载
数据预处理
训练集可视化
网络构建
训练准备
模型训练
模型推理
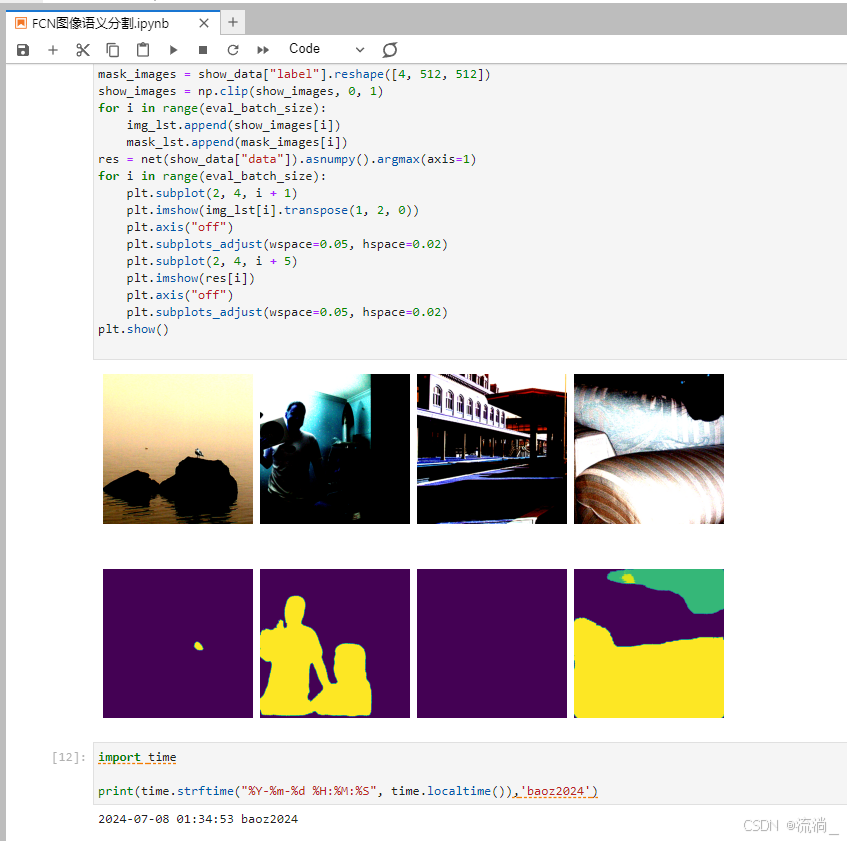
其中模型构建的代码 和 训练准备的代码如下所示:
#模型定义
import mindspore.nn as nn
class FCN8s(nn.Cell):
def init(self, n_class):
super().init()
self.n_class = n_class
self.conv1 = nn.SequentialCell(
nn.Conv2d(in_channels=3, out_channels=64,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.SequentialCell(
nn.Conv2d(in_channels=64, out_channels=128,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.SequentialCell(
nn.Conv2d(in_channels=128, out_channels=256,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv4 = nn.SequentialCell(
nn.Conv2d(in_channels=256, out_channels=512,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5 = nn.SequentialCell(
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512,
kernel_size=3, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv6 = nn.SequentialCell(
nn.Conv2d(in_channels=512, out_channels=4096,
kernel_size=7, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(4096),
nn.ReLU(),
)
self.conv7 = nn.SequentialCell(
nn.Conv2d(in_channels=4096, out_channels=4096,
kernel_size=1, weight_init=‘xavier_uniform’),
nn.BatchNorm2d(4096),
nn.ReLU(),
)
self.score_fr = nn.Conv2d(in_channels=4096, out_channels=self.n_class,
kernel_size=1, weight_init=‘xavier_uniform’)
self.upscore2 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=4, stride=2, weight_init=‘xavier_uniform’)
self.score_pool4 = nn.Conv2d(in_channels=512, out_channels=self.n_class,
kernel_size=1, weight_init=‘xavier_uniform’)
self.upscore_pool4 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=4, stride=2, weight_init=‘xavier_uniform’)
self.score_pool3 = nn.Conv2d(in_channels=256, out_channels=self.n_class,
kernel_size=1, weight_init=‘xavier_uniform’)
self.upscore8 = nn.Conv2dTranspose(in_channels=self.n_class, out_channels=self.n_class,
kernel_size=16, stride=8, weight_init=‘xavier_uniform’)
def construct(self, x):
x1 = self.conv1(x)
p1 = self.pool1(x1)
x2 = self.conv2(p1)
p2 = self.pool2(x2)
x3 = self.conv3(p2)
p3 = self.pool3(x3)
x4 = self.conv4(p3)
p4 = self.pool4(x4)
x5 = self.conv5(p4)
p5 = self.pool5(x5)
x6 = self.conv6(p5)
x7 = self.conv7(x6)
sf = self.score_fr(x7)
u2 = self.upscore2(sf)
s4 = self.score_pool4(p4)
f4 = s4 + u2
u4 = self.upscore_pool4(f4)
s3 = self.score_pool3(p3)
f3 = s3 + u4
out = self.upscore8(f3)
return out
#模型评价
import numpy as np
import mindspore as ms
import mindspore.nn as nn
import mindspore.train as train
class PixelAccuracy(train.Metric):
def init(self, num_class=21):
super(PixelAccuracy, self).init()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def eval(self):
pixel_accuracy = np.diag(self.confusion_matrix).sum() / self.confusion_matrix.sum()
return pixel_accuracy
class PixelAccuracyClass(train.Metric):
def init(self, num_class=21):
super(PixelAccuracyClass, self).init()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
mean_pixel_accuracy = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
mean_pixel_accuracy = np.nanmean(mean_pixel_accuracy)
return mean_pixel_accuracy
class MeanIntersectionOverUnion(train.Metric):
def init(self, num_class=21):
super(MeanIntersectionOverUnion, self).init()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
mean_iou = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
mean_iou = np.nanmean(mean_iou)
return mean_iou
class FrequencyWeightedIntersectionOverUnion(train.Metric):
def init(self, num_class=21):
super(FrequencyWeightedIntersectionOverUnion, self).init()
self.num_class = num_class
def _generate_matrix(self, gt_image, pre_image):
mask = (gt_image >= 0) & (gt_image < self.num_class)
label = self.num_class * gt_image[mask].astype('int') + pre_image[mask]
count = np.bincount(label, minlength=self.num_class**2)
confusion_matrix = count.reshape(self.num_class, self.num_class)
return confusion_matrix
def update(self, *inputs):
y_pred = inputs[0].asnumpy().argmax(axis=1)
y = inputs[1].asnumpy().reshape(4, 512, 512)
self.confusion_matrix += self._generate_matrix(y, y_pred)
def clear(self):
self.confusion_matrix = np.zeros((self.num_class,) * 2)
def eval(self):
freq = np.sum(self.confusion_matrix, axis=1) / np.sum(self.confusion_matrix)
iu = np.diag(self.confusion_matrix) / (
np.sum(self.confusion_matrix, axis=1) + np.sum(self.confusion_matrix, axis=0) -
np.diag(self.confusion_matrix))
frequency_weighted_iou = (freq[freq > 0] * iu[freq > 0]).sum()
return frequency_weighted_iou
4.小结
今天学习了在Mindspore环境下,使用FCN模型来实现的图像语义分割。本次使用的模型方法也属于传统深度学习的的方法, 与基于预训练模型的图像语义分割的方案相比,本次属于从0开始的训练、推理的方法。这里面主要学习的要点是理解的FCN模型模型的原理,模型评价指标的计算原理和方法,另外一方面是着重掌握基于mindspore进行模型开发的相关代码。
以上是第15天的学习内容,附上今日打卡记录: