AKConv介绍

AKConv(可改变核卷积),主要用来解决传统卷积中固有的缺陷。
-
卷积窗口的固定大小:
传统卷积中,每个神经元只关注输入数据中一个固定大小的局部区域,而不能有效地捕捉到其他窗口的信息。这在处理全局上下文信息时可能会限制网络的性能。
-
卷积核尺寸的固定性:
传统卷积网络中的卷积核大小通常是固定的(如 3x3, 5x5)。这种固定尺寸的核可能不适合捕捉所有尺度的特征。例如,较小的核可能适合捕捉细粒度的特征,而较大的核可能更适合捕捉更宽泛的特征。固定的卷积核尺寸和结构限制了网络在处理多尺度特征时的灵活性和有效性。
摘要
基于卷积操作的神经网络在深度学习领域取得了显著成果,但标准卷积操作中存在两个固有缺陷。一方面,卷积操作仅限于局部窗口,无法从其他位置捕获信息,且其采样形状是固定的。另一方面,卷积核的大小固定为 k×k,这是一个固定的正方形形状,随着大小的增长,参数的数量呈平方增长。显然,在不同数据集和不同位置,目标的形状和大小是多样的。具有固定采样形状和正方形的卷积核不适应目标的变化。针对上述问题,本工作探索了可变核卷积(AKConv),它使卷积核具有任意数量的参数和任意采样形状,为网络开销与性能之间的权衡提供了更丰富的选择。在AKConv中,我们通过一种新的坐标生成算法定义了任意大小卷积核的初始位置。为适应目标的变化,我们引入偏移量来调整每个位置样本的形状。此外,我们通过使用相同大小和不同初始采样形状的AKConv来探索神经网络的效果。AKConv通过不规则卷积操作完成高效的特征提取过程,并为卷积采样形状带来更多探索选项。在代表性数据集COCO2017、VOC 7+12和VisDrone-DET2021上的目标检测实验充分展示了AKConv的优势。AKConv可以作为即插即用的卷积操作替换卷积操作以提高网络性能。相关任务的代码可在 https://github.com/CV-ZhangXin/AKConv 找到。
AKConv的创新特点:
-
卷积核的灵活性:AKConv支持卷积核参数的任意化设定,能够根据具体的应用需求自由调整其大小与形状,以更精准地适配不同尺度的目标特征。
-
初始采样位置生成算法:AKConv引入了一种创新的算法,用于为各种尺寸的卷积核确定初始采样位置,增强了网络处理不同大小目标的适应性。
-
动态采样位置偏移:为了应对目标形状的多样性,AKConv采用动态偏移技术调整采样位置,以实现更精确的特征捕捉。
-
模型参数与计算效率的优化:AKConv的参数数量可线性调节,有助于在受限的硬件资源下实现计算效率的优化,特别适合于资源受限的轻量级模型部署。
文章链接
论文地址:论文地址
代码地址:代码地址
主要思想
任意形状
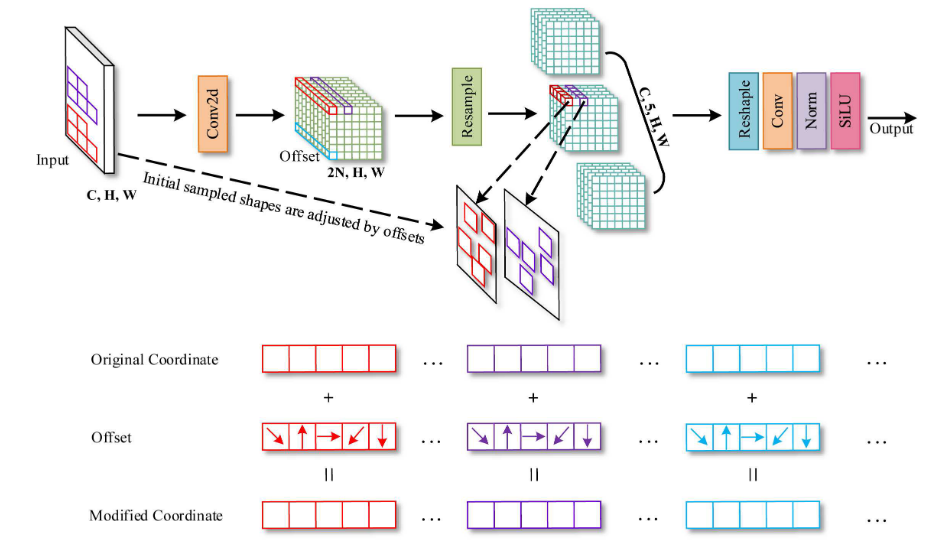
标准卷积是K*K的矩形,而可变形卷积(Deformable Conv)是可以调整形状的,类似可变形卷积,AKConv也会学习偏移量,来改变卷积核的形状,如下图所示。
N是AKConv卷积参数的数量,特征图经过卷积运算得到卷积的位置偏移量,然后进行卷积运算,和可变形卷积一样。
下图展示了AKConv操作流程。下面是对这个流程的逐步解释:
-
输入:图像的输入大小为 C, H, W,其中 C 是通道数,H 是高度,W 是宽度。
-
Conv2d:一个标准的二维卷积层(Conv2d)被用来处理输入图像,并产生偏移量(Offset)。
-
偏移量:这些偏移量用于调整卷积核的初始采样位置。在这个例子中,偏移量的维度是 2N, H, W,其中 N 是每个位置的偏移对数(通常与卷积核中的点数相对应)。
-
重采样:接着,使用偏移量来调整卷积核的采样位置,这样的操作可以称为重采样(Resample)。这允许卷积核对输入特征图进行非标准形状的采样。
-
后续操作:重采样后的特征图通过额外的层进行处理,包括一个卷积层(Conv)、归一化层(Norm)和激活函数(如 Sigmoid 或 ReLU)。
-
输出:最终,经过这一系列操作后,得到输出特征图,这可以用于网络中的后续任务,如分类、检测等。
在底部的图中,展示了如何通过原始坐标和偏移量计算得到修改后的坐标。这一过程是动态的,对于每个特定的输入特征图,都可能有不同的偏移量。
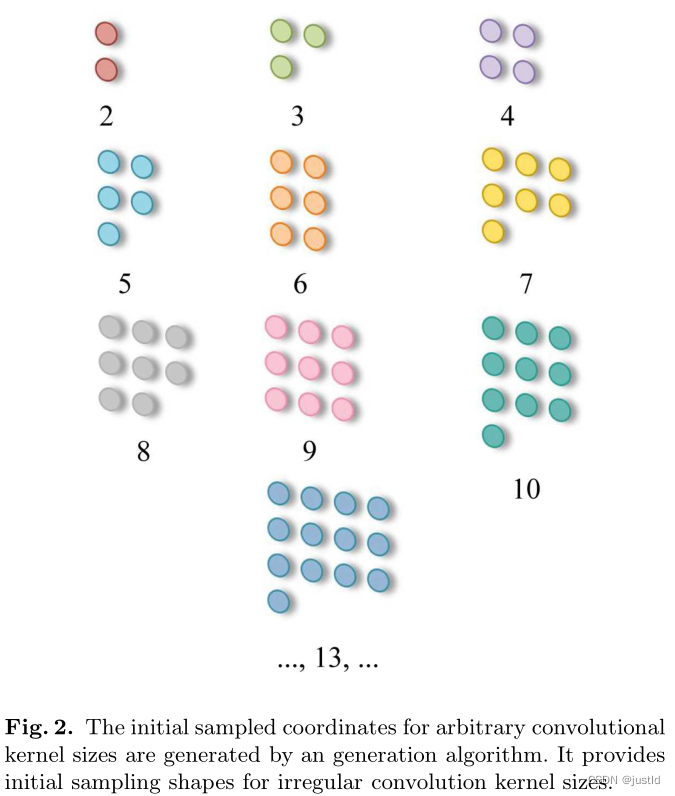
任意参数数量
AKConv的另一个特点就是参数数量是任意的(可以设置为1,2,3,4,5…任意值),如下图,这点是和传统卷积不一样的,摆脱了的参数限制。
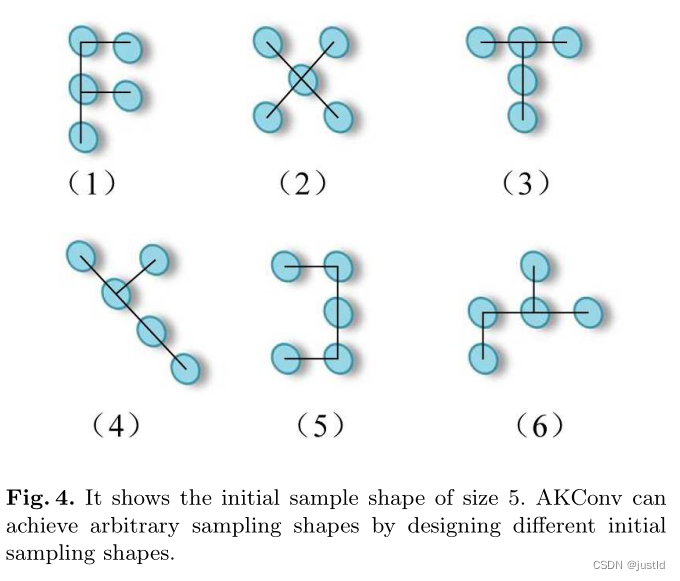
除了参数数量可以任意选择,初始的卷积核形状也是可以任意选择,下图为5个卷积参数时,卷积核的初始形状设计方案。
核心代码
import torch
import torch.nn as nn
import math
from einops import rearrange
class AKConv(nn.Module):
def __init__(self, inc, outc, num_param, stride=1, bias=None):
"""
AKConv的构造函数。
:param inc: 输入通道数。
:param outc: 输出通道数。
:param num_param: 参数数量,决定了卷积核的大小和偏移量的计算。
:param stride: 卷积的步长。
:param bias: 是否添加偏置项。
"""
super(AKConv, self).__init__()
self.num_param = num_param # 参数数量
self.stride = stride # 卷积步长
# 构建一个卷积层,包括标准卷积、批标准化和SiLU激活函数
self.conv = nn.Sequential(
nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),
nn.BatchNorm2d(outc),
nn.SiLU()
)
# 构建用于计算偏移量的卷积层
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0) # 初始化偏移量卷积层权重为0
self.p_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
"""
在反向传播过程中调整学习率。
:param module: 模块。
:param grad_input: 输入的梯度。
:param grad_output: 输出的梯度。
"""
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
"""
AKConv的前向传播方法。
:param x: 输入的特征图。
:return: 输出的特征图。
"""
offset = self.p_conv(x) # 计算偏移量
dtype = offset.data.type() # 获取数据类型
N = offset.size(1) // 2 # 偏移量的维度
p = self._get_p(offset, dtype) # 根据偏移量计算新的坐标位置
p = p.contiguous().permute(0, 2, 3, 1) # 调整坐标位置的顺序
# 计算插值位置
q_lt = p.detach().floor()
q_rb = q_lt + 1
# 对坐标位置进行裁剪以确保不越界
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# 裁剪原始坐标位置
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# 计算双线性插值
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# 根据新的坐标重采样特征
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# 结合四个角的插值得到偏移特征
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param) # 重塑偏移特征
out = self.conv(x_offset) # 应用卷积
return out
def _get_p_n(self, N, dtype):
"""
生成AKConv的初始采样形状。
:param N: 参数数量。
:param dtype: 数据类型。
:return: 采样形状。
"""
base_int = round(math.sqrt(self.num_param)) # 计算基础整数
row_number = self.num_param // base_int # 行数
mod_number = self.num_param % base_int # 剩余数
p_n_x, p_n_y = torch.meshgrid(torch.arange(0, row_number), torch.arange(0, base_int))
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
# 处理多余的参数
if mod_number > 0:
mod_p_n_x, mod_p_n_y = torch.meshgrid(torch.arange(row_number, row_number + 1), torch.arange(0, mod_number))
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))
p_n = torch.cat([p_n_x, p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
"""
计算没有零填充的初始位置。
:param h: 高度。
:param w: 宽度。
:param N: 参数数量。
:param dtype: 数据类型。
:return: 初始位置。
"""
p_0_x, p_0_y = torch.meshgrid(torch.arange(0, h * self.stride, self.stride), torch.arange(0, w * self.stride, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
"""
根据偏移量计算新的位置。
:param offset: 偏移量。
:param dtype: 数据类型。
:return: 新的位置。
"""
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
p_n = self._get_p_n(N, dtype) # 初始采样形状
p_0 = self._get_p_0(h, w, N, dtype) # 初始位置
p = p_0 + p_n + offset # 结合偏移量计算新位置
return p
def _get_x_q(self, x, q, N):
"""
根据给定的采样位置 q 从输入特征图 x 中采集特征。
:param x: 输入的特征图,形状为 (batch_size, channels, height, width)。
:param q: 采样位置,形状为 (batch_size, height, width, 2*N)。
:param N: 采样点的数量。
:return: 采集后的特征,形状为 (batch_size, channels, height, width, N)。
"""
b, h, w, _ = q.size() # 提取batch_size, height, width
padded_w = x.size(3) # 输入特征图的宽度
c = x.size(1) # 输入特征图的通道数
# 将输入特征图 x 重塑为 (batch_size, channels, height*width) 的形状。
# 这样做是为了方便后续通过索引提取特征。
x = x.contiguous().view(b, c, -1)
# 计算索引,这里用于提取特征的索引是基于 q 中的采样位置。
# q[..., :N] 和 q[..., N:] 分别表示 x 和 y 方向的偏移量。
# 索引的计算方式是 offset_x * width + offset_y。
index = q[..., :N] * padded_w + q[..., N:]
# 将计算得到的索引调整形状,并扩展到与 x 的通道数相同。
# 这样做是为了在每个通道上都应用相同的索引来提取特征。
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
# 使用 gather 函数根据计算的索引从 x 中提取特征。
# 提取后的特征 x_offset 的形状为 (batch_size, channels, height*width*N)。
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
# 将提取的特征 x_offset 重塑回 (batch_size, channels, height, width, N) 的形状。
# 这样每个位置上都包含了 N 个采样点的特征。
return x_offset
def _reshape_x_offset(self, x_offset, num_param):
"""
重塑偏移特征的形状以适应卷积操作。
:param x_offset: 偏移特征。
:param num_param: 参数数量。
:return: 调整形状后的特征。
"""
b, c, h, w, N = x_offset.size()
x_offset = x_offset.permute(0, 1, 4, 2, 3)
x_offset = x_offset.contiguous().view(b, c * N, h, w)
return x_offset
在YOLOv10中使用AKconv
下载YOLOv10代码
直接下载
Git Clone
git clone https://github.com/THU-MIG/yolov10.git
安装环境
进入代码根目录并安装依赖。
创建虚拟环境并安装依赖
conda create -n yolov10
conda activate yolov10
pip install -r requirements.txt
pip install -e .
新建ultralytics/nn/conv/AKConv.py
新建文件,并添加核心代码。
需要安装einops :pip install einops
import torch.nn as nn
import torch
from einops import rearrange
import math
class AKConv(nn.Module):
def __init__(self, inc, outc, num_param, stride=1, bias=None):
super(AKConv, self).__init__()
self.num_param = num_param
self.stride = stride
self.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),
nn.BatchNorm2d(outc),
nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.
self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_full_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
# N is num_param.
offset = self.p_conv(x)
dtype = offset.data.type()
N = offset.size(1) // 2
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],
dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# resampling the features based on the modified coordinates.
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# bilinear
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
x_offset = self._reshape_x_offset(x_offset, self.num_param)
out = self.conv(x_offset)
return out
# generating the inital sampled shapes for the AKConv with different sizes.
def _get_p_n(self, N, dtype):
base_int = round(math.sqrt(self.num_param))
row_number = self.num_param // base_int
mod_number = self.num_param % base_int
p_n_x, p_n_y = torch.meshgrid(
torch.arange(0, row_number),
torch.arange(0, base_int), indexing='xy')
p_n_x = torch.flatten(p_n_x)
p_n_y = torch.flatten(p_n_y)
if mod_number > 0:
mod_p_n_x, mod_p_n_y = torch.meshgrid(
torch.arange(row_number, row_number + 1),
torch.arange(0, mod_number),indexing='xy')
mod_p_n_x = torch.flatten(mod_p_n_x)
mod_p_n_y = torch.flatten(mod_p_n_y)
p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))
p_n = torch.cat([p_n_x, p_n_y], 0)
p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)
return p_n
# no zero-padding
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(0, h * self.stride, self.stride),
torch.arange(0, w * self.stride, self.stride),indexing='xy')
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
# 根据实际情况调整
index = index.clamp(min=0, max=x.shape[-1] - 1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
# Stacking resampled features in the row direction.
@staticmethod
def _reshape_x_offset(x_offset, num_param):
b, c, h, w, n = x_offset.size()
# using Conv3d
# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)
# using 1 × 1 Conv
# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)
# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)
x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')
return x_offset
修改tasks.py
引入刚才添加的代码
from ultralytics.nn.conv.AKConv import AKConv
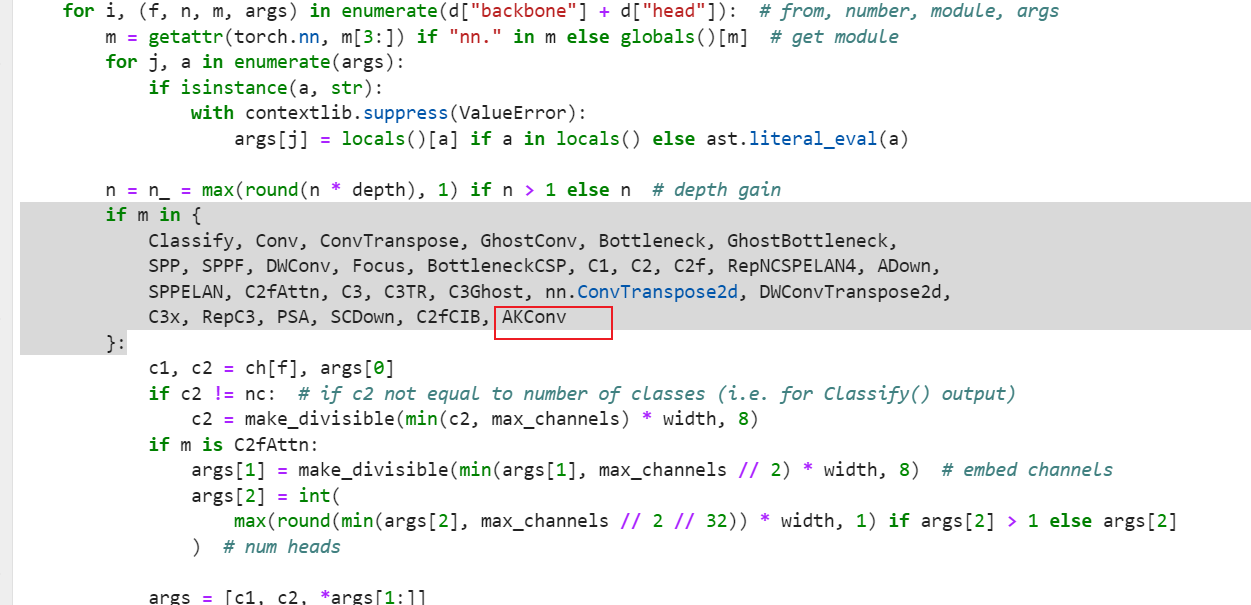
修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
if m in {
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck,
SPP, SPPF, DWConv, Focus, BottleneckCSP, C1, C2, C2f, RepNCSPELAN4, ADown,
SPPELAN, C2fAttn, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d,
C3x, RepC3, PSA, SCDown, C2fCIB, AKConv
}:
配置yolov10n_AKConv.yaml
ultralytics/cfg/models/v10/yolov10n_AKConv.yaml
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, AKConv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, AKConv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, AKConv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import os
from ultralytics import YOLOv10
yaml = 'ultralytics/cfg/models/v10/yolov10n_AKConv.yaml'
model = YOLOv10(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='coco128.yaml',
name='AKConv',
epochs=10,
workers=8,
batch=1)
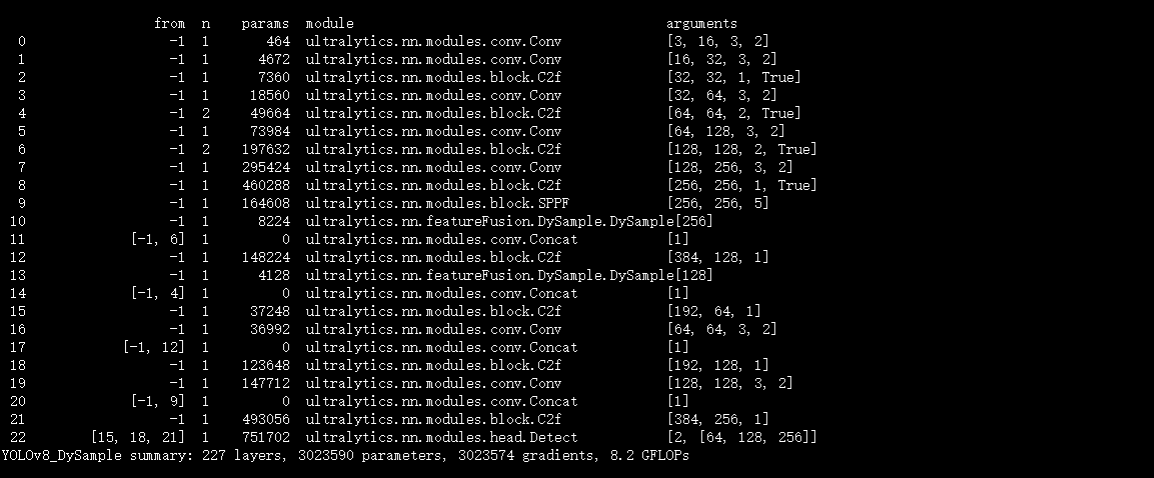
结果
文章目录
