资料
- Introduce_to_virtualization
- KVM I/O虚拟化
- AWS EC2 Virtualization 2017: Introducing Nitro
- 从AWS转向KVM,再看KVM与XEN的技术路线之争
简单整理并了解下和aws相关的虚拟化技术
虚拟化技术
相关概念
Hypervisor
Hypervisor是一种运行在物理服务器和操作系统之间的中间软件层,可允许多个操作系统和应用共享一套基础物理硬件,因此也可以看作是虚拟环境中的“元”操作系统。可以协调访问服务器上的所有的物理设备和虚拟机,也叫虚拟机监视器。Hypervisor是所有虚拟化技术的核心。当服务器启动并执行Hypervisor时,他会给每一台虚拟机分配适量的内存、CPU、网络和磁盘,并加载所有虚拟机的客户操作系统,常见的产品有Vmware、KVM、Xen等
Xen
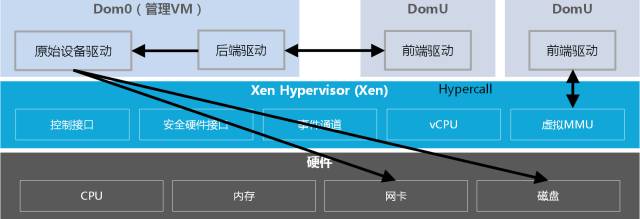
Xen是运行在裸机上的虚拟化管理程序(HyperVisor),是半虚拟化(Para-Virtualization)技术的典型代表。Xen的管理VM为Dom0,虚拟机操作系统被称做DomU。管理VM负责管理整个硬件平台上的所有输入输出设备驱动,半虚拟化中的Hypervisor不对I/O设备作模拟,而仅仅对CPU和内存做模拟
KVM
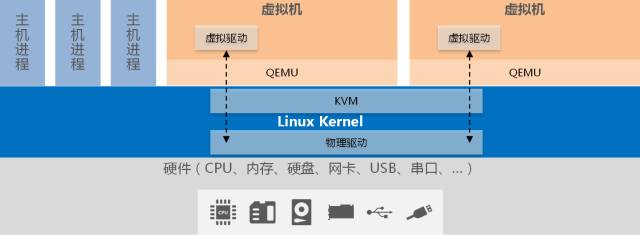
KVM(Kernel-based Virtual Machine,基于内核的虚拟机)是一个基于Linux环境的开源虚拟化解决方案,最早由以色列Qumranet公司开发,在2006年10月出现在Linux内核的邮件列表上,并于2007年2月被集成到Linux 2.6.20内核中,成为内核的一部分
KVM是一个全虚拟化的解决方案。可以在x86架构的计算机上实现虚拟化功能。但KVM需要CPU中虚拟化功能的支持,只可在具有虚拟化支持的CPU上运行,即具有VT功能的Intel CPU和具有AMD-V功能的AMD CPU
QEMU
KVM并不是一个完整的模拟器,而只是一个提供了虚拟化功能的内核插件,具体的模拟器工作需要借助QEMU来完成。QEMU(Quick Emulator)仿真所有硬件,包括BIOS、IDE控制器、VGA显示卡、USB控制器和网卡等
DPDK
包处理任务存在内核态与用户态的切换,以及多次的内存拷贝,系统消耗变大,以CPU为核心的系统存在很大的处理瓶颈。为了提升在通用服务器(COTS)的数据包处理效能,Intel推出了服务于IA(Intel Architecture)系统的DPDK技术。DPDK应用程序运行在操作系统的User Space,利用自身提供的数据面库进行收发包处理,绕过了Linux内核态协议栈,以提升报文处理效率。
DPDK主要解决网络虚拟化之后性能大幅度降低的问题。最初性能的瓶颈在于硬件本身。而如今硬件的性能越来越高,内核软件方面已经非常滞后。
- 内核软件栈太长。以存储I/O为例,用户软件发送一个I/O请求,要经过虚拟文件系统、文件系统、通用块设备层、块设备调度层、驱动层等等。经过一层层的的系统软件,一个I/O才能落盘
- 系统要在内核态与用户态之间不断切换,涉及到上下问切换以及内存拷贝问题,耗费了大量的CPU资源。
- 内核大量的中断模式,起初中断模式的设计是在于硬件处理速度较慢,因此采用中断的模式可以避免忙等,待硬件处理完I/O后中断通知CPU。在目前硬件性能如此之快的情况下,中断模式反而不适合
用户态协议栈绕过内核,可以直接操作裸设备。用户态软件栈使用了polling模式,来避免中断模式所产生的瓶颈
SR-IOV
SR-IOV 的全称是 Single Root I/O Virtualization,SR-IOV标准允许在虚拟机之间高效共享PCIe(快速外设组件互连)设备,由于它是在硬件中实现的,所以可以获得能够与本机性能接近的I/O性能。SR-IOV 使用 physical functions (PF) 和 virtual functions (VF) 为 SR-IOV 设备管理全局功能。PF 包含SR-IOV 功能的完整PCIe设备,PF 作为普通的PCIe 设备被发现、管理和配置 。PF 通过分配VF 来配置和管理 SR-IOV 功能。
VF 是轻量级 PCIe 功能(I/O 处理)的 PCIe 设备,每个 VF 都是通过 PF 来生成管理的,VF 的具体数量限制受限于 PCIe 设备自身配置及驱动程序的支持,启用SR-IOV后,主机将在一个物理NIC上创建单个PF和多个VF。 VF的数量取决于配置和驱动程序支持。
虚拟化技术的分类
x86平台指令集分为4个特权模式:Ring0 、Ring1、Ring2、Ring3、OS工作在Ring0级别,应用软件工作在Ring3级别,驱动程序工作在Ring1和Ring2
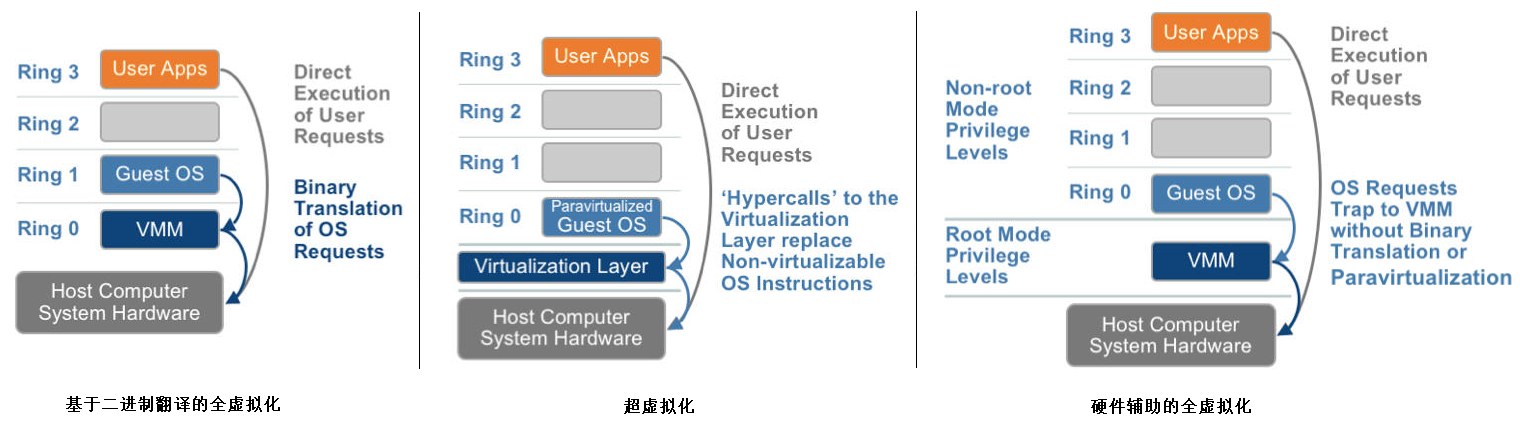
- 软件虚拟化:通过软件完全模拟cpu、芯片组、磁盘、网卡等计算机硬件。
- 全虚拟化:通过VMM截取guestos的ring 0特权指令,转译为宿主机的指令最终由物理设备处理。此时Guestos不知道自身运行在虚拟机环境。
- 半虚拟化:guestos将原先ring0级别的特权指令转换为supercall,仍旧和VMM交互但是不需要转译性能有所提升。但是需要修改OS内核,典型实现为XEN(dom0和domu)
- 硬件辅助虚拟化:intel退出的VT-x技术,避免了指令的转译(除了少数客户端指令),基于硬件进行处理效率较高。当前不仅CPU指令有硬件虚拟化方案,I/O通信也有硬件解决方案,称为VT-d;网络通信的称为VT-c
- 容器虚拟化:基于CGroups、Namespace对进程隔离,例如docker
aws ec2虚拟化发展
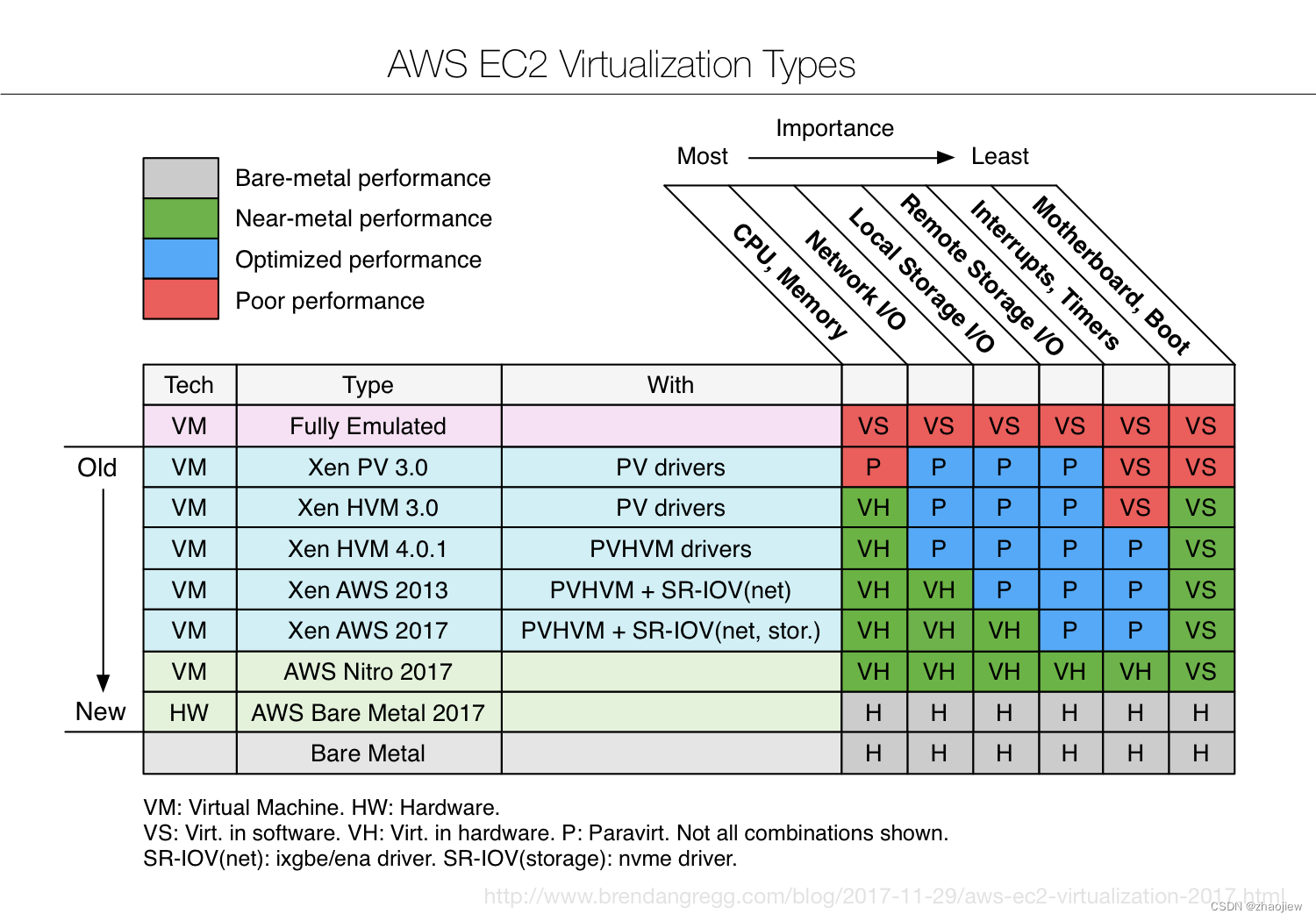
Amazon EC2 虚拟化技术演进:从 Xen 到 Nitro
按照时间顺序有如下发展轨迹
-
早期的Xen虚拟化。Xen 实现了虚拟机的CPU 和内存虚拟化,但是虚拟机的I/O 访问,包括网络和存储等,都是通过虚拟机中的前端模块和 dom0 中的后端模块通信。I/O路径太长,降低了I/O性能。dom0还会和业务虚拟机抢占宿主机资源,很难实现管理虚机和业务虚机之间的平衡,以及避免抖动
-
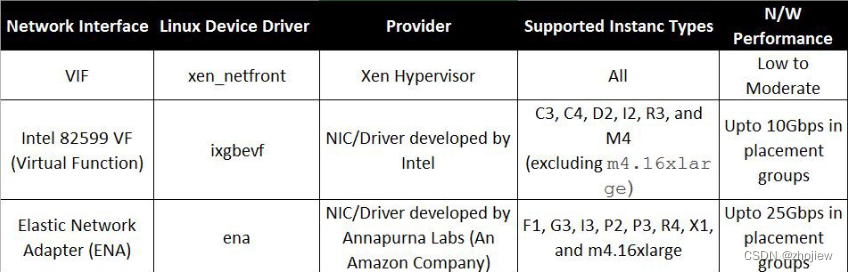
引入单根I/O虚拟化(SR-IOV),采用aws增强型网络(enhanced networking)(通过ixgbe驱动程序实现)
-
引入EBS的硬件虚拟化技术,将远端存储以NMVe形式呈现给虚拟机
-
发展增强网络实现为ENA(Elastic Network Adapter),使得虚拟机能够绕过内核和用户空间网络处理程序,直接操作网卡硬件。Nitro的首个专用硬件卡(完全的网络负载卸载硬件)
-
发展实例存储,Annapurna Labs研发的Nitro存储卡管理的SSD磁盘
-
替换Xeni架构,使用基于KVM的Nitro hypervisor 替换了Xen
Nitro技术
nitro基于KVM的部件,对所有的主要资源提供硬件支持,没有使用QEMU代理,因此未客户虚拟机提供近乎裸机的性能
Nitro - Hypervisor + 网络/存储卡 + 安全芯片
Nitro卡
AWS Nitro 系统是模块化组件的集合,使用广泛的计算、存储、内存和网络选项来设计 EC2 实例(Nitro卡)
- VPC Data Plane(用于VPC访问的Nitro卡):通过PCIe附加到宿主机上的一块定制网卡,支持网络封包和解包、安全组、限速器和路由,网络加速等功能。实例通过ENA驱动和它通信。
- EBS Data Plane(用于EBS卷访问的Nitro卡):通过PCIe附加到宿主机上的一块定制卡。远端存储被以NVMe设备形式展现给实例,实例通过标准NVMe驱动程序访问该卡。支持卷加密、存储加速
- Instance Storage Data Plane(用于实例存储访问的Nitro卡):本地磁盘被以NVMe设备形式展现给实例,实例通过标准NVMe驱动程序访问这些磁盘。支持加密、限速器和本地磁盘监控
- 卡控制器(Card Controller)。提供API端点,负责协调所有Nitro卡、Nitro Hypervisor和Nitro安全芯片。利用Nitro安全芯片实现了Hardware Root Of Trust(硬件信任根),支持实例监控、计量和认证。它还为Nitro EBS卡实现了NVMe控制器。
Nitro 安全芯片
Nitro安全芯片整合到宿主机主板中,控制对所有非易失性存储的访问,持续监控和保护硬件资源,并在每次系统启动时独立验证固件。
Nitro hypervisor
Nitro hypervisor基于KVM位于极简化的定制的Linux 内核中,带有定制的VMM和小用户空间应用。只负责管理内存和CPU分配,将Nitro卡虚拟功能分配给实例,监控和计量硬件等,不再需要提供任何网络功能。
2017年hypervisor仍旧在宿主机上,2018年后hypervisor被集成到了硬件中
Firecracker
资料
- 深度解析:AWS Fargate 数据平面
- Firecracker – 无服务器计算的轻量级虚拟化
- 深度解析 AWS Firecracker 原理篇 – 虚拟化与容器运行时技术
- 深度解析 AWS Firecracker 实战篇 – 一起动手点炮竹
- Firecracker: Lightweight Virtualization for Serverless Applications
- Firecracker:无服务器应用程序的轻量级虚拟化(翻译)
github
- https://firecracker-microvm.github.io/
- firecracker-microvm/firecracker
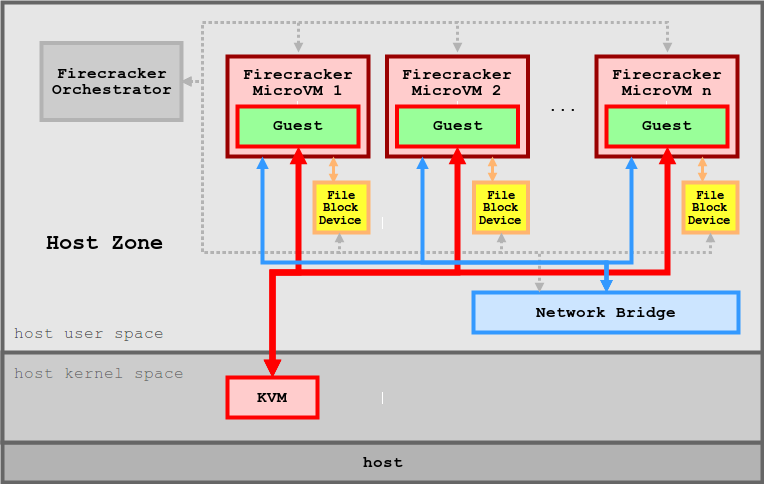
FireCracker是为AWS Lambda和AWS Fargate提供动力的虚拟机监视器(VMM)。Firecracker的核心是一个新的VMM,它使用Linux内核的KVM基础设施来提供支持现代Linux主机以及Linux和OSv客户机的最小虚拟机(microms)
每个工作节点都有数百或数千个MicroVMs。为每个microm启动一个Firecracker微管理进程,负责创建和管理microm、提供设备仿真和处理出口。与microm的通信是通过TCP/IP套接字进行的。
firecracker作为一款轻量级虚拟机,仅提供了有限功能
firecracker和docker比较

Docker容器技术采用共享宿主机内核方式运行,利用内核特性实现对不同用户的命名空间进行隔离(6种方式),使用 CGroups进行硬件资源分配与限制,POSIX Capabilities进行 root 权限分割等。由于操作系统内核漏洞,Docker 组件设计缺陷,以及不当的配置都会导致 Docker 容器发生逃逸,从而获取宿主机权限。docker实现原理决定了容器的其隔离性、封闭性还是远远低于拥有独立 GuestOS 的虚拟机。而分配、管理、运维这些传统虚拟机与容器轻量、灵活、弹性的初衷背道而驰
firecracker能够为类似 AWS Lambda 和 Fargate 这样的服务提供高安全性、灵活性和效率的运行时环境
firecraker的优势
- 应用负载的隔离性。每个 MicroVM 内部仅运行一个应用容器,或者仅运行一个应用 Pod。而不同租户的不同应用之间,实现了虚拟化级别的隔离,每个应用不再共享 HostOS 内核,而是拥有独立的 GeustOS Linux 内核。
- 安全。抛弃 QEMU 使用的 C 语言,选择内存安全的 Rust 作为开发语言。基于 crosvm 使用极简设备模型,模拟尽可能少的必要设备,减小暴露的攻击面
- 高性能和低开销。Firecracker 取消了 SeaBIOS (开源的 X86 BIOS),移除了 PCI 总线,取消了 VGA 显示等等硬件模拟。GuestOS(MicroVM) 使用定制过的精简 Linux 内核,裁剪掉对应的设备驱动程序、子系统等等