学习了
这篇文章点我~,然后想到能不能自己写个查学校网络认证使用流量的爬虫来锻炼一下,然后就有了下面的学习笔记~~
-----------------------------------------------------------我是分割线-----------------------------------------------------------------------------------
学校的网络是每个月限额的,用完之后会自动锁定,需要付钱再激活,所以注意流量是非常必要的。而查询的话需要登陆外加点击好几次鼠标,至少需要十几秒时间吧,说实话一般不会主动看。那能不能用爬虫简化过程呢?必须可以~下面开始!
首先,查询登陆地址是:https://selfservice.seu.edu.cn/selfservice/campus_login.php,界面如下图:
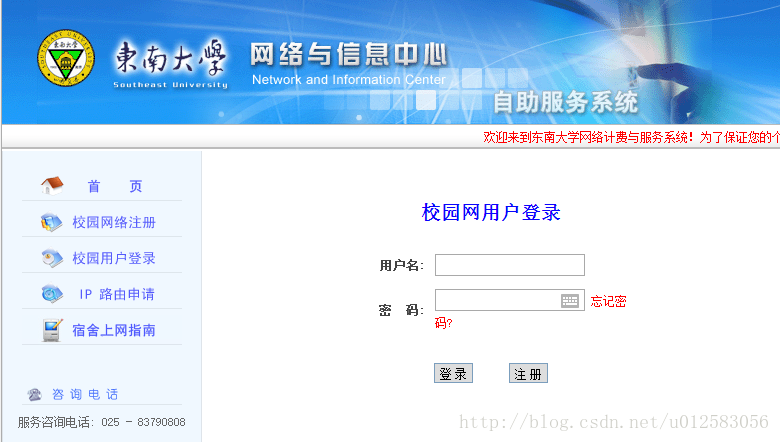
输入用户名、密码,用httpfox拦截http包文件(httpfox是firefox的插件,可以在附加组件里搜索、安装,之后在工具栏右击,选定制后拖动到喜欢的位置,之后就可以单击打开):

查看POST的内容(即上图第一行),在POST DATA中可以看到:

说明用户点击“登陆”时向服务器递交了username和password参数,所以我们在请求中需要加入该项参数。此部分代码如下:
import cookielib
import urllib2
import urllib
#初始化一个cookie
cookie = cookielib.CookieJar()
#创建一个opener来使用cookiejar
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#创建要POST的数据
postdata1 = urllib.urlencode({
'username': '输入用域名',
'password': '输入密码'
})
#定义一个请求
request1 = urllib2.Request(
url='https://nic.seu.edu.cn/selfservice/campus_login.php',
data=postdata1
)
#访问链接
result = opener.open(request1)
print(result.read().decode('gbk'))
for item in cookie:
print 'Cookie:Name = '+item.name
print 'Cookie:Value = '+item.value
可以打印出取得的html代码,里面的数据应该是和GET中“TYPE”为text/html的那项返回的content一致。最后的代码是查看cookie中的数据。
由于点击登陆并验证密码后是该界面(即为上述代码取得的html代码):
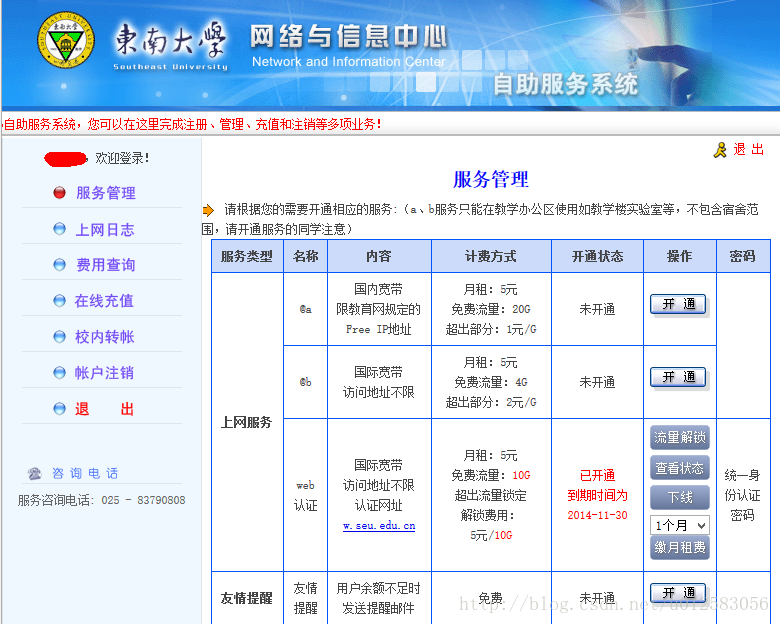
里面没有我们需要的信息,我们需要的信息在“上网服务”的“web认证”的“查看状态”里。
我们点击此按钮,接着又可以从httpfox中看到一个POST:

我们可以看到POST Data里的数据是:

我们又可以继续写我们的代码:
postdata2 = urllib.urlencode({
'opration': 'status',
'item': 'web',
'web_sel': '1'
})
#定义另一个请求
request2 = urllib2.Request(
url='https://nic.seu.edu.cn/selfservice/service_manage_status_web.php',
data=postdata2
)
result2 = opener.open(request2).read().decode('gbk')
print(result2)
此处注意,应该继续使用我们定义的第一个opener,因为里面有cookie信息,否则我们的连接将失败。result2的结果类似于上面,是点击后返回的html代码,直接展示为下图:
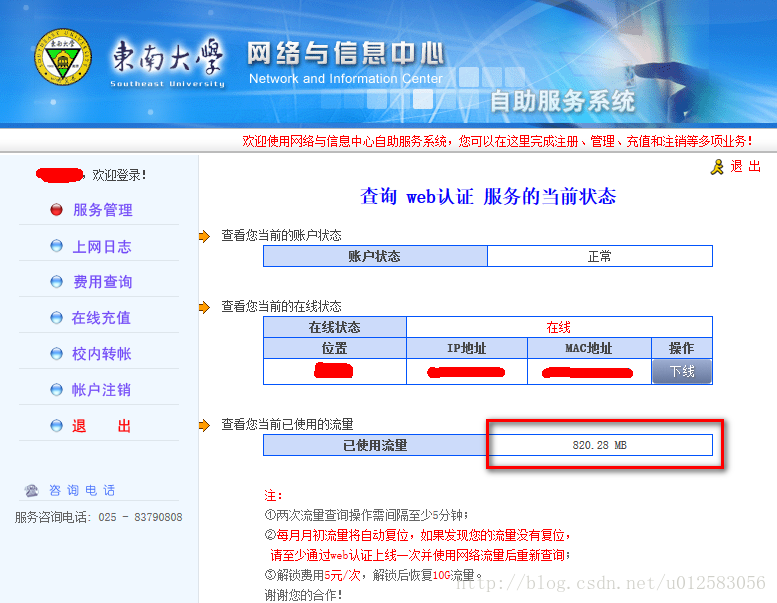
我们发现需要的数据在红色框内。然后我们审查元素,有如下的信息:

蓝色的一行就是红框位置的html代码,然后我们就需要从返回的result2的信息里扣出中间所夹的数据,这就需要正则表达式了。具体的解释可以看下面的链接:http://blog.csdn.net/pleasecallmewhy/article/details/8929576
正则表达式的代码如下:
import re
pattern = re.compile(r'<td.*?width="50%".*?align="center".*?bgcolor="#FFFFFF">(.*?)</td>', re.S)
mydata = re.findall(pattern, result2)
print mydata
mydata里就是我们取得的数据,但是我们可以看到输出为:

这里我们输出的unicode的编码,但是有2项,为什么呢?
我们利用print mydata[0].encode('utf-8')看到输出为:“正常”,然后看到该页有“正常”的地方然后审查元素如下:

可见符合我们的正则表达式,那我们无法从表达式去除它了,那我们直接使用
mydata[1]就达成我们的目的了。所以最终代码如下:
# -*- coding: utf-8 -*-
import cookielib
import urllib2
import urllib
import re
#初始化一个cookie
cookie = cookielib.CookieJar()
#创建一个opener来使用cookiejar
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#创建要POST的数据,用户名和密码此处没有传值
postdata1 = urllib.urlencode({
'username': ' ',
'password': ' '
})
#定义一个请求
request1 = urllib2.Request(
url='https://nic.seu.edu.cn/selfservice/campus_login.php',
data=postdata1
)
#访问链接,获取cookies
opener.open(request1)
postdata2 = urllib.urlencode({
'opration': 'status',
'item': 'web',
'web_sel': '1'
})
#定义另一个请求
request2 = urllib2.Request(
url='https://nic.seu.edu.cn/selfservice/service_manage_status_web.php',
data=postdata2
)
#访问链接,获取html
result2 = opener.open(request2).read().decode('gbk')
#正则匹配,取数据
pattern = re.compile(r'<td.*?width="50%".*?align="center".*?bgcolor="#FFFFFF">(.*?)</td>', re.S)
mydata = re.findall(pattern, result2)
#输出结果
print(u'您本月已经使用的流量为:\n%s' % mydata[1].strip())
输入正确的用户名和密码后实测没有错误,当然我后续又加入了一些其他功能,包括输入用户名密码,加密,保存信息等等,有兴趣的可以讨论,找我要代码也是可以的。~~