导言
截止目前为止,在自己的技术生涯中,要说哪一种技术体系的学习路径最为曲折,那非大数据技术体系莫属了。相比特定编程语言的学习,相比类如云原生技术这类已然涵盖面很广的技术体系,个人感觉大数据技术的体系“繁杂度”高出了几个量级。具体原因并不是因为大数据技术体系的“难度”,而是因为其“广度”和“自由度”。
- “广度”——在多年的历史发展和众多企业的参与中,大数据技术及工具的门类极其繁多,特性差异化多且很多体现在细节层面;
- “自由度”——大数据技术的实践应用没有统一标准,几乎每个企业(主要指了解到的大型企业,实践中我们这些中小型企业也是如此)都会针对自身的业务场景进行相应的技术选型和实践,组合编排上述种类繁多的技术和工具。
这就导致了在实际的学习中大家常常陷入繁杂的技术和工具的了解和理解中。如果没有大量时间的学习和实践,很难梳理清晰主要的学习脉络和在实践中需要重点学习掌握的技术和工具(当然你也可以挑战都学习精通)。
我个人也是在经历了这些迷茫、试错和求索后,目前感觉对大数据技术体系的主要脉络有了较系统性了解,所以梳理出来,分享给大家,我们一起共勉学习。
主要分为以下几个方面:
- 明确大数据平台的业务目标
- 明晰大数据平台的架构框架
- 了解大数据平台中常用的技术及工具
- 扩展数据治理的知识面
一、业务目标
- 数据汇聚:打破企业数据孤岛
- 数据开发:建造数据价值提炼工厂
- 数据模型体系:开启数据淘金之旅
- 数据治理体系:数据资产管理
- 数据服务体系:解决“数据应用最后一公里”问题
- 数据运营体系:让数据持续用起来
- 数据安全体系:数据安全是生命线
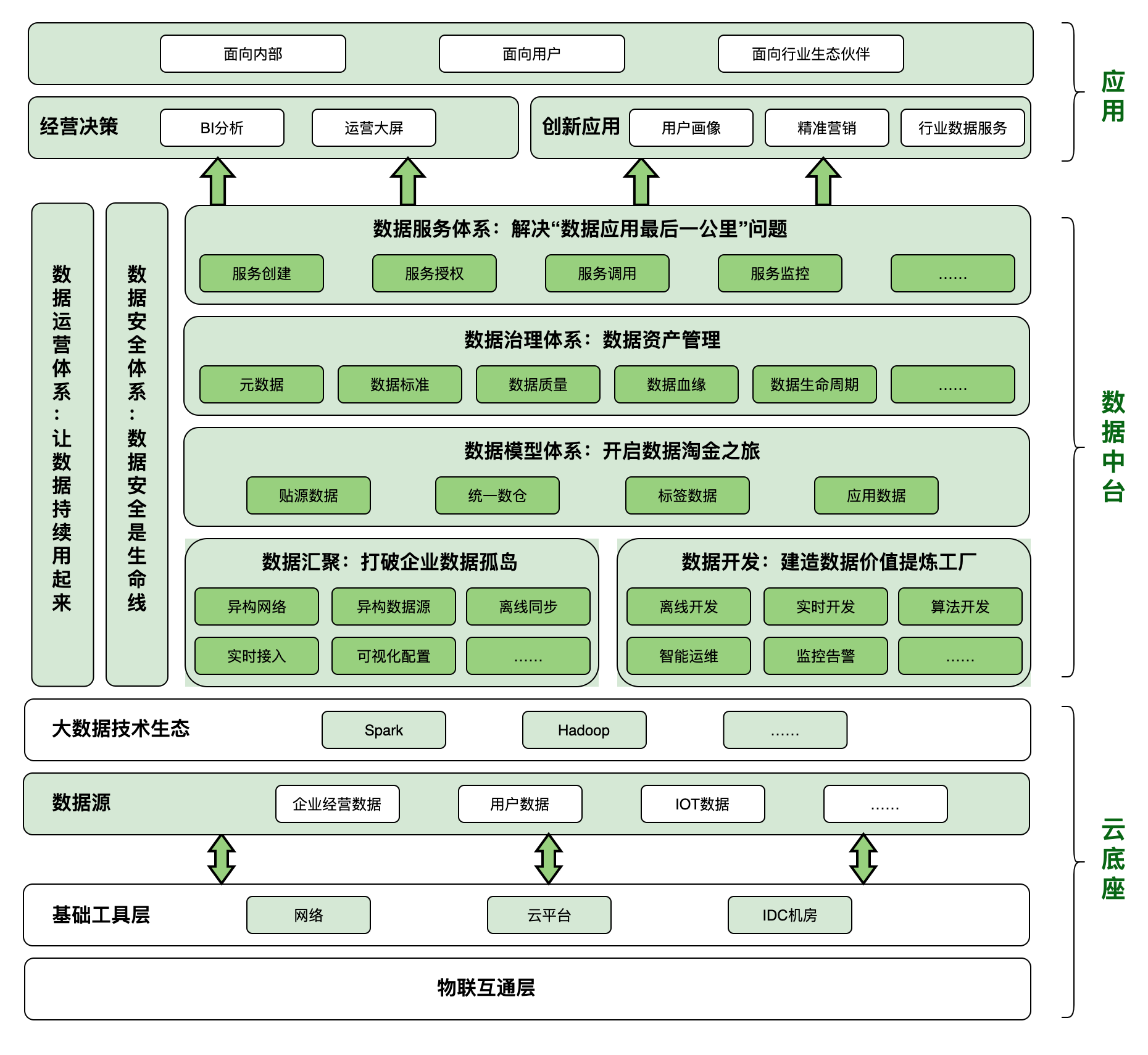
二、技术架构概览
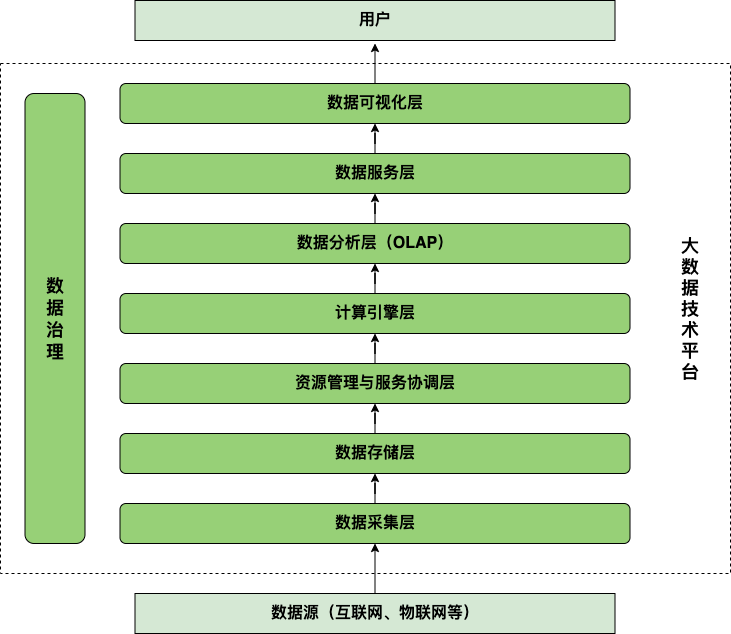
三、技术及工具
数据采集技术
| 离线采集工具 |
描述 |
| Sqoop |
由 Apache 开源的一个可以将 Hadoop 和关系数据库中的数据相互转移的工具,可以将关系数据库(如 MySQL、Oracle、PostgreSQL 等)中的数据导入 Hadoop ,也可以将 Hadoop 中的数据导出到关系数据库中。 |
| DataX |
由阿里巴巴开源的一个异构数据源离线同步工具,用于实现包括关系数据库(如 MySQL、Oracle 等)、HDFS、Hive、HBase、FTP 等各种异构数据源之间稳定且高效的数据同步。 |
| Kettle |
是一款开源的 ETL 工具(新名称是PDI Pentaho Data Integeration)。Kettle 支持图形化的 GUI 设计界面,可以管理来自不同数据库的数据,然后可以以工作流的形式流转,在做一些简单或复杂的数据抽取、质量检测、数据清洗、数据转换、数据过滤等方面有着比较稳定的表现。 |
| 实时采集工具 |
描述 |
| Maxwell |
由 Zendesk 开源的一个基于 MySQL 数据库的增量日志(Binlog)解析工具,可以将 MySQL 中的增量数据以 JSON 格式写入 kafka、Kinesis、RabbitMQ 及 Redis 中。 |
| Canal |
由阿里巴巴开源的一个基于 MySQL 数据库的增量日志(Binlog)解析工具,可以提供增量数据订阅及消费,支持将 MySQL 中的增量数据采集到 Kafka、RabbitMQ、Elasticsearch 及 HBase 中。 |
| Flume |
由 Apache 开源的日志采集工具,是一个高可用、高可靠、分布式的海量日志采集、处理、聚合和传输的系统。 |
| Nifi |
Apache NiFi是一个易用、可靠的数据处理与分发系统,Apache NiFi的设计目标是自动化管理系统间的数据流。Apache Nifi是一个基于WEB-UI用户界面,具有很强交互性和易用性,为不同系统间或系统内提供数据流管理与处理的系统。 |
分布式存储技术
| 分布式文件系统 |
描述 |
| HDFS |
HDFS(Hadoop Distributed File System)是 Apache 的顶级开源项目,解决了海量数据存储的问题,具有良好的扩展性、容错性以及易用的API。它的核心思想是将文件切分成等大的数据块,以多副本的形式存储到多个节点上。 |