python现在处理word、Excel、pdf等文档有很多的库,今天学习一个处理pdf的库:pdfplumber,主要学习提取文本内容和表格。
安装
pip install pdfplumber提取文本 extract_text()
import pdfplumber
# 打开一PDF文档,比如打开《浪潮之巅》
pdf = pdfplumber.open('浪潮之巅.pdf')
# 提取第一页的本文内容
text = pdf.pages[0].extract_text()
print(text)如下输出,左边是我们的代码输出,右边是PDF的第一页内容,提取的text整体是一个字符串;


提取文本 extract_words()
提取文本还提供了另一个方法
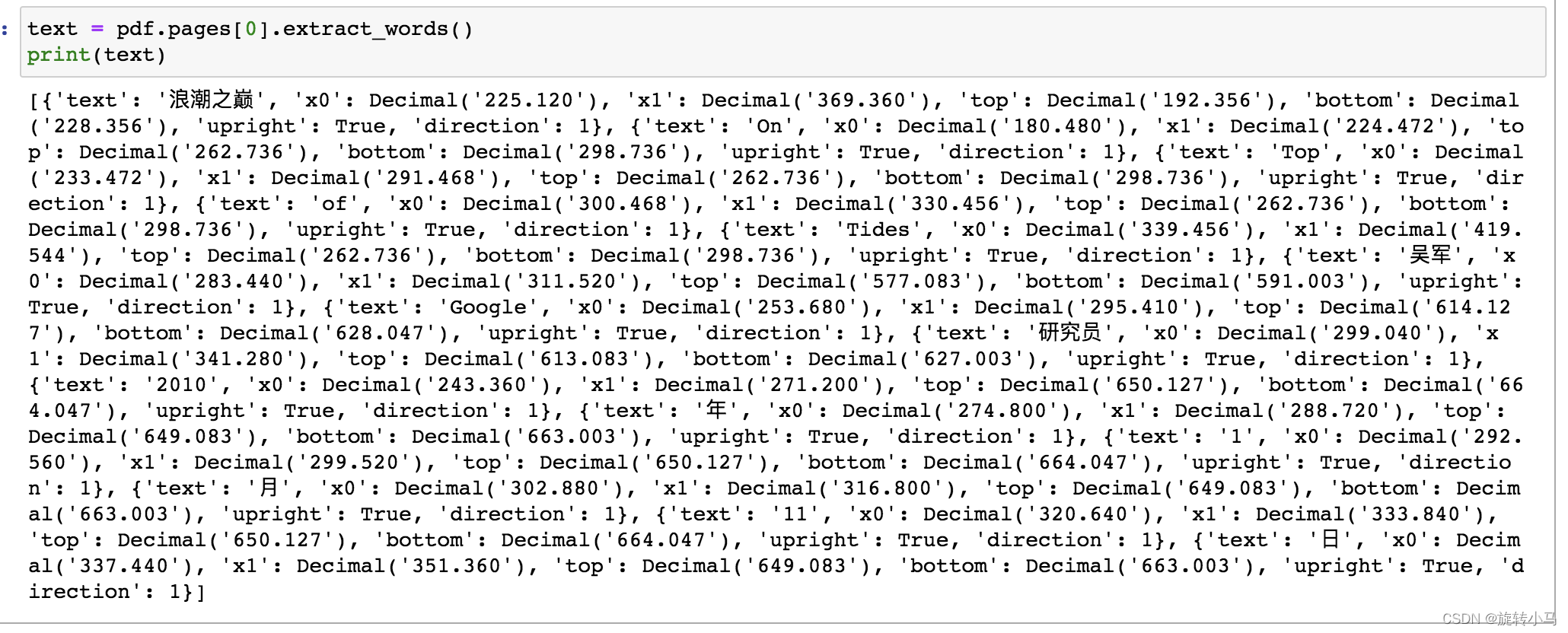
text = pdf.pages[0].extract_words()
print(text)其输出如下,提取出各部分的页面位置信息整体放在一个list中;
提取表格 extract_table() 和 extract_tables()
我们换另外一个有表格的PDF文档来尝试一下,文档第一页内容如下(文档若侵权,请联系删除):

pdf_table = pdfplumber.open('M2021011300001742_1.pdf')
print(pdf_table.pages[0].extract_table())结果发现只提取页面中的最后一个表格内容信息,输出如下:

所以我们再试一试extract_tables()

此时发现便可以把所有的表格信息都提取出来,这便是两个方法的区别。