AI视野·今日CS.CV 计算机视觉论文速览
Mon, 27 Sep 2021
Totally 42 papers
👉上期速览✈更多精彩请移步主页

Interesting:
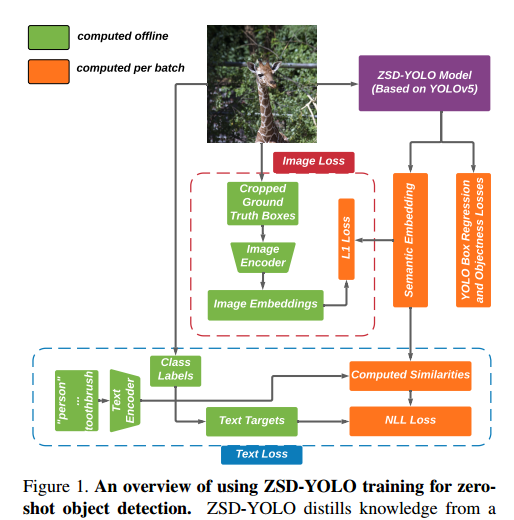
📚SPNet, 用于点云分割的多层核卷积算子,一种径向的多尺度分层思想。(from University of Missouri)
📚Paint4Poem,从诗句生成描述古诗的小图。 (from )

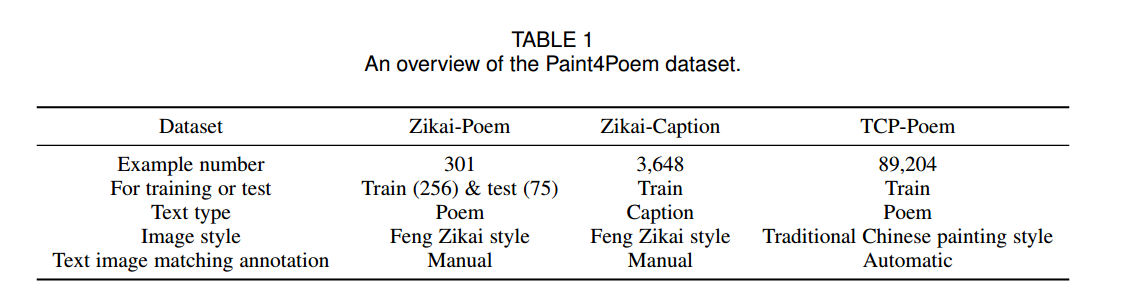
📚ZSD-YOLO, 基于语义描述的目标检测。(from Dawnlight )
Daily Computer Vision Papers
| ZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language KnowledgeDistillation Authors Johnathan Xie, Shuai Zheng 现实世界的对象采样会产生长尾分布,需要为稀有类型成倍增加图像。旨在检测看不见的物体的零镜头检测是解决这个问题的一个方向。诸如 COCO 之类的数据集在许多图像上进行了广泛的注释,但类别数量很少,并且对跨不同域的所有对象类进行注释既昂贵又具有挑战性。为了推进零镜头检测,我们开发了一种视觉语言蒸馏方法,该方法将来自零镜头预训练模型(如 CLIP)的图像和文本嵌入与来自单级检测器(如 YOLOv5)的修改后的语义预测头对齐。使用这种方法,我们能够训练一个物体检测器,该检测器在 COCO 零镜头检测分裂上以较少的模型参数达到最先进的精度。在推理过程中,我们的模型可以适用于检测任意数量的对象类,而无需额外训练。我们还发现,我们方法的缩放提供的改进在各种 YOLOv5 尺度上是一致的。 |
| DeepStroke: An Efficient Stroke Screening Framework for Emergency Rooms with Multimodal Adversarial Deep Learning Authors Tongan Cai, Haomiao Ni, Mingli Yu, Xiaolei Huang, Kelvin Wong, John Volpi, James Z. Wang, Stephen T.C. Wong 在急诊室 ER 环境中,中风的诊断是一个常见的挑战。由于过多的执行时间和成本,急诊室通常不提供 MRI 扫描。中风筛查中通常会提到临床测试,但神经科医生可能无法立即获得。我们提出了一种新的多模式深度学习框架 DeepStroke,通过识别急性情况下怀疑中风的患者的面部运动不协调和言语障碍的模式,实现计算机辅助中风存在评估。我们提出的 DeepStroke 将视频数据用于局部面部麻痹检测,将音频数据用于全局语音障碍分析。它进一步利用多模态横向融合来结合低层和高层特征,并为联合训练提供相互正则化。还引入了一种新的对抗性训练损失来获得身份独立和中风判别特征。在我们的视频音频数据集上对实际 ER 患者进行的实验表明,所提出的方法优于最先进的模型,并且比 ER 医生获得了更好的性能,当特异性一致时,灵敏度提高了 6.60,准确度保持了 4.62。 |
| From images in the wild to video-informed image classification Authors Marc B hlen, Varun Chandola, Wawan Sujarwo, Raunaq Jain 图像分类器在应用于结构化图像时有效,但当应用于具有非常高视觉复杂度的图像时,它们通常会失败。本文描述了将最先进的对象分类器应用于在巴厘岛收集的具有高视觉复杂性的一组独特的野外图像的实验。 |
| Visual Scene Graphs for Audio Source Separation Authors Moitreya Chatterjee, Jonathan Le Roux, Narendra Ahuja, Anoop Cherian 用于视觉引导的音频源分离的现有技术方法通常假设具有特征声音的源,例如乐器。这些方法通常会忽略这些声源的视觉上下文或避免对可能有助于更好地表征声源的对象交互进行建模,尤其是当同一对象类可能从不同的交互中产生不同的声音时。为了解决这个具有挑战性的问题,我们提出了视听场景图分割器 AVSGS,这是一种新颖的深度学习模型,将场景的视觉结构嵌入为图并将该图分割为子图,每个子图与通过共同分割获得的独特声音相关联音频频谱图。在其核心,AVSGS 使用递归神经网络,该网络使用多头注意力发出视觉图的相互正交的子图嵌入。这些嵌入用于调节音频编码器解码器以实现源分离。我们的管道通过自监督任务进行端到端训练,该任务包括使用视觉图从人工混合的声音中分离音频源。在本文中,我们还介绍了一个用于声源分离的野外视频数据集,其中包含多个非音乐源,我们将其称为野外音频分离 ASIW。该数据集改编自 AudioCaps 数据集,并为源分离提供了具有挑战性、自然和日常生活的设置。 |
| Two-Stage Mesh Deep Learning for Automated Tooth Segmentation and Landmark Localization on 3D Intraoral Scans Authors Tai Hsien Wu, Chunfeng Lian, Sanghee Lee, Matthew Pastewait, Christian Piers, Jie Liu, Fang Wang, Li Wang, Christina Jackson, Wei Lun Chao, Dinggang Shen, Ching Chang Ko 在计算机辅助正畸治疗中,准确分割牙齿并识别牙网模型上相应的解剖标志是必不可少的。手动执行这两项任务既费时又乏味,更重要的是,由于患者牙齿的异常和大规模差异,高度依赖正畸医生的经验。一些基于机器学习的方法已被设计并应用于正畸领域,以自动分割牙齿网格,例如口内扫描。相比之下,关于牙齿标志定位的研究数量仍然有限。本文提出了一个基于网格深度学习的两阶段框架,称为 TS MDL,用于对原始口腔扫描进行关节牙齿标记和界标识别。我们的 TS MDL 首先采用端到端 emph i MeshSegNet 方法,即现有 MeshSegNet 的变体,具有更高的准确性和效率,可以在下采样扫描中标记每个牙齿。在分割输出的指导下,我们的 TS MDL 进一步选择原始网格上每个牙齿的感兴趣区域 ROI,以构建先驱 PointNet 的轻量级变体,即 PointNet Reg,用于回归相应的地标热图。我们的 TS MDL 在真实的临床数据集上进行了评估,显示出有希望的分割和定位性能。具体而言,TS MDL 第一阶段的 emph i MeshSegNet 在 0.953 pm0.076 时达到了平均 Dice 相似系数 DSC,明显优于原始 MeshSegNet。在第二阶段,PointNet Reg 实现了 0.623 pm0.718 的平均绝对误差 MAE,44 个地标的预测和地面实况之间的距离为毫米,与其他地标检测网络相比,这是优越的。 |
| RSDet++: Point-based Modulated Loss for More Accurate Rotated Object Detection Authors Wen Qian, Xue Yang, Silong Peng, Junchi Yan, Xiujuan Zhang 我们将五参数和八参数旋转对象检测方法中的损失不连续性归类为旋转灵敏度误差 RSE,这将导致性能退化。我们引入了一种新的调制旋转损失来缓解这个问题,并提出了一个旋转灵敏度检测网络 RSDet,它由一个八参数单级旋转物体检测器和调制旋转损失组成。我们提出的 RSDet 有几个优点 1 它将旋转对象检测问题重新表述为预测对象的角点,而大多数以前的方法采用具有不同测量单位的基于五参数的回归方法。 2 调制旋转损失通过解决损失的不连续性,在五参数和八参数旋转目标检测方法上实现了一致的改进。为了进一步提高我们的方法对小于 10 像素的物体的准确性,我们引入了一种新颖的 RSDet,它由基于点的锚自由旋转物体检测器和调制旋转损失组成。大量实验证明了 RSDet 和 RSDet 的有效性,它们在具有挑战性的基准 DOTA1.0、DOTA1.5 和 DOTA2.0 中在旋转对象检测方面取得了有竞争力的结果。我们希望所提出的方法可以为设计算法以解决旋转物体检测问题提供一个新的视角,并更多地关注微小物体。 |
| Tackling Inter-Class Similarity and Intra-Class Variance for Microscopic Image-based Classification Authors Aishwarya Venkataramanan, Martin Laviale, C cile Figus, Philippe Usseglio Polatera, C dric Pradalier 水生微生物的自动分类是基于从单个图像中提取的形态特征。目前对其分类的工作没有考虑导致误分类的类间相似性和类内方差。我们对由于显微图像中的离散视觉变化而发生类内差异的情况特别感兴趣。在本文中,我们建议通过基于视觉特征划分具有高方差的类来解释它。我们的算法会自动决定要创建的最佳子类数量,并将它们中的每一个都视为单独的训练类。通过这种方式,网络学习更细粒度的视觉特征。 |
| Localizing Infinity-shaped fishes: Sketch-guided object localization in the wild Authors Pau Riba, Sounak Dey, Ali Furkan Biten, Josep Llados 这项工作研究了草图引导对象定位 SGOL 的问题,其中人类草图被用作查询以在自然图像中进行对象定位。在这种跨模态设置中,我们首先贡献了一个难以超越的基线,无需任何特定的 SGOL 训练就能够在一组固定的类上优于以前的作品。基线对于基于可用的简单而强大的方法分析 SGOL 方法的性能很有用。我们通过提出以草图为条件的 DETR 检测转换器架构来推进现有技术,该架构避免了硬分类并减轻了草图和图像之间的域差距以定位对象实例。尽管 SGOL 的主要目标集中在对象检测上,但我们探索了它对草图引导实例分割的自然扩展。这项新颖的任务允许在像素级别识别对象,这在多个应用程序中至关重要。我们通过实验证明,我们的模型及其变体比以前的最先进结果显着进步。 |
| Catadioptric Stereo on a Smartphone Authors Kristijan Bartol, David Bojani , Tomislav Petkovi , Tomislav Pribani 我们展示了一个带有平面镜的 3D 打印适配器,用于使用前后智能手机摄像头进行立体重建。该适配器提供了一种实用且低成本的解决方案,使任何智能手机都可以用作立体相机,目前只能使用配备昂贵 3D 传感器的高端手机。使用适配器的原型版本,我们试验了诸如相机和镜子之间的角度以及与每个相机的距离立体基线之类的参数。我们找到最方便的配置并校准立体声对。基于所呈现的初步分析,我们确定了当前设计中可能的改进。为了演示工作原型,我们使用来自立体对的 2D 关键点检测重建 3D 人体姿势并评估提取的身体长度。 |
| Training dataset generation for bridge game registration Authors Piotr Wzorek, Tomasz Kryjak 本文提出了一种自动生成用于纸牌检测的深度卷积神经网络训练数据集的方法。该解决方案允许跳过手动图像收集和标记识别对象的耗时过程。在生成的数据集上训练的 YOLOv4 网络在卡片检测任务中实现了 99.8 的效率。 |
| How to find a good image-text embedding for remote sensing visual question answering? Authors Christel Chappuis, Sylvain Lobry, Benjamin Kellenberger, Bertrand Le Saux, Devis Tuia 视觉问答 VQA 最近被引入到遥感中,使每个人都可以更容易地从高空图像中提取信息。 VQA 考虑自然语言的问题,因此很容易对图像进行表述,旨在通过基于计算机视觉和自然语言处理方法的模型提供答案。因此,VQA 模型需要联合考虑视觉和文本特征,这通常通过融合步骤完成。在这项工作中,我们在 VQA 的背景下研究了三种不同的遥感融合方法,并分析了模型复杂性方面的准确性增益。 |
| Learnable Triangulation for Deep Learning-based 3D Reconstruction of Objects of Arbitrary Topology from Single RGB Images Authors Tarek Ben Charrada, Hedi Tabia, Aladine Chetouani, Hamid Laga 我们提出了一种新的基于深度强化学习的方法,用于从单目图像重建 3D 对象。使用网格表示的先前工作是基于模板的。因此,它们仅限于与模板具有相同拓扑结构的对象的重建。使用体积网格作为中间表示的方法在计算上很昂贵,这限制了它们在实时场景中的应用。在本文中,我们提出了一种新颖的端到端方法,该方法可以从单目图像重建任意拓扑的 3D 对象。它由 1 顶点生成网络 VGN 组成,它从输入的 RGB 图像中预测对象顶点的初始 3D 位置,2 一个可微的三角剖分层,它使用一种新颖的强化学习算法以非监督方式进行学习,对象顶点的最佳三角剖分,最后,3 一个分层网格细化网络,它使用图卷积来细化初始网格。我们的主要贡献是可学习的三角测量过程,它以无监督的方式恢复输入形状的拓扑。 |
| Frequency Pooling: Shift-Equivalent and Anti-Aliasing Downsampling Authors Zhendong Zhang 卷积利用图像的平移等效先验,从而在图像处理任务中取得巨大成功。然而,卷积神经网络 CNN 中常用的池化,例如最大池化、平均池化和跨步卷积,并不是平移等价的。因此,当卷积和池化堆叠时,CNN 的移位等效性被破坏。此外,从信号处理的角度来看,抗混叠是池化的另一个基本特性。然而,最近的池化既不是移位等效也不是抗锯齿。为了解决这个问题,我们提出了一种新的池化方法,即移位等效和抗混叠,称为频率池化。频率池化首先将特征变换到频域,然后去除奈奎斯特频率以外的频率分量。最后,它将特征转换回空间域。我们基于傅里叶变换和奈奎斯特频率的特性证明了频率池化是平移等效和抗混叠的。 |
| GSIP: Green Semantic Segmentation of Large-Scale Indoor Point Clouds Authors Min Zhang, Pranav Kadam, Shan Liu, C. C. Jay Kuo 在这项工作中提出了一种有效的大规模室内场景点云语义分割的解决方案。它被命名为室内点云的 GSIP 绿色分割,其性能在具有代表性的大规模基准斯坦福 3D 室内分割 S3DIS 数据集上进行评估。 GSIP 有两个新颖的组件:1 一个房间风格的数据预处理方法,它选择适当的点子集进行进一步处理,2 一个从 PointHop 扩展的新特征提取器。对于前者,每个房间的采样点形成一个输入单元。对于后者,PointHop 的特征提取在将其扩展到大规模点云时的弱点被识别并通过更简单的处理管道进行修复。与开创性的基于深度学习的解决方案 PointNet 相比,GSIP 是绿色的,因为它具有显着更低的计算复杂度和更小的模型尺寸。 |
| MODNet-V: Improving Portrait Video Matting via Background Restoration Authors Jiayu Sun, Zhanghan Ke, Lihe Zhang, Huchuan Lu, Rynson W.H. Lau 为了更精确地解决具有挑战性的肖像视频抠图问题,现有作品通常应用一些需要额外用户努力才能获得的抠图先验,例如带注释的trimaps 或背景图像。在这项工作中,我们观察到,不是要求用户明确提供背景图像,我们可以从输入视频本身中恢复它。为此,我们首先提出了一种新颖的背景恢复模块 BRM,可以从输入视频中动态恢复背景图像。 BRM 非常轻巧,可以轻松集成到现有的消光模型中。通过将 BRM 与最近的图像抠图模型 MODNet 相结合,我们将 MODNet V 用于人像视频抠图。受益于 BRM 提供的强大的背景先验,MODNet V 的参数只有 MODNet 的 1 3 ,但实现了相当甚至更好的性能。我们的设计允许在单个 NVIDIA 3090 GPU 上以端到端的方式训练 MODNet V。 |
| CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models Authors Yuan Yao, Ao Zhang, Zhengyan Zhang, Zhiyuan Liu, Tat Seng Chua, Maosong Sun 预训练的视觉语言模型 VL PTM 在图像数据中的自然语言基础方面显示出有前途的能力,促进了广泛的跨模式任务。然而,我们注意到模型预训练和微调的目标形式之间存在显着差距,导致需要大量标记数据来刺激 VL PTM 对下游任务的视觉基础能力。为了应对这一挑战,我们提出了 Cross modal Prompt Tuning CPT,或者,Colorful Prompt Tuning,这是一种用于调整 VL PTM 的新范式,它最大限度地将视觉基础重新构建为在图像和文本中使用基于颜色的共指标记填充空白问题缩小差距。通过这种方式,我们的快速调整方法可以实现 VL PTM 的强大的少镜头甚至零镜头视觉接地能力。综合实验结果表明,在 RefCOCO 评估中,即时调整的 VL PTM 的性能大大优于其微调的对应物,例如,17.3 的绝对精度提高和 73.8 的平均相对标准偏差降低。 |
| Dense Contrastive Visual-Linguistic Pretraining Authors Lei Shi, Kai Shuang, Shijie Geng, Peng Gao, Zuohui Fu, Gerard de Melo, Yunpeng Chen, Sen Su 受 BERT 成功的启发,已经提出了几种联合表示图像和文本的多模态表示学习方法。这些方法通过从大规模多模态预训练中捕获高级语义信息来实现卓越的性能。特别是LXMERT和UNITER采用视觉区域特征回归和标签分类作为借口任务。然而,基于在众包数据集上预训练的视觉特征具有有限且不一致的语义标签,它们往往会遇到标签嘈杂和语义注释稀疏的问题。为了克服这些问题,我们提出了无偏的密集对比视觉语言预训练 DCVLP,它用不需要注释的跨模态区域对比学习代替了区域回归和分类。开发了两种数据增强策略 Mask Perturbation 和 Intra Inter Adversarial Perturbation 来提高对比学习中使用的负样本的质量。总体而言,DCVLP 允许在独立于任何对象注释的自监督设置中进行跨模态密集区域对比学习。 |
| Quantifying point cloud realism through adversarially learned latent representations Authors Larissa T. Triess, David Peter, Stefan A. Baur, J. Marius Z llner 判断生成模型合成的样本质量可能既乏味又耗时,尤其是对于复杂的数据结构,例如点云。本文提出了一种量化 LiDAR 点云中局部区域真实性的新方法。通过代理分类任务的训练,从现实世界和合成点云中学习相关特征。受公平网络的启发,我们使用对抗性技术来阻止数据集特定信息的编码。 |
| Fine-Grained Image Generation from Bangla Text Description using Attentional Generative Adversarial Network Authors Md Aminul Haque Palash, Md Abdullah Al Nasim, Aditi Dhali, Faria Afrin 从文本生成细粒度、逼真的图像在视觉和语义领域有许多应用。考虑到这一点,我们提出了 Bangla Attentional Generative Adversarial Network AttnGAN,它允许对高分辨率 Bangla 文本到图像生成进行强化的多阶段处理。我们的模型可以整合图像不同子区域的最具体细节。我们特别关注自然语言描述中的相关词。该框架在 CUB 数据集上取得了更好的初始分数。首次使用注意力 GAN 从孟加拉语文本生成细粒度图像。孟加拉语在 100 种最常用语言中排名第 7。这激励我们明确关注这种语言,这将确保许多人的不可避免的需求。 |
| Multi-View Video-Based 3D Hand Pose Estimation Authors Leyla Khaleghi, Alireza Sepas Moghaddam, Joshua Marshall, Ali Etemad 手姿势估计 HPE 可用于各种人机交互应用,例如基于手势的物理或虚拟增强现实设备控制。最近的工作表明,视频或多视图图像携带有关手的丰富信息,从而可以开发更强大的 HPE 系统。在本文中,我们提出了基于多视图视频的 3D 手部 MuViHand 数据集,包括手部的多视图视频以及地面实况 3D 姿势标签。我们的数据集包括 4,560 个视频中提供的超过 402,000 张合成手部图像。这些视频是从六个不同角度同时拍摄的,具有复杂的背景和随机的动态照明水平。数据是从 10 个不同的动画对象中捕获的,使用 12 个摄像头在半圆形拓扑中,其中六个跟踪摄像头只聚焦在手上,其他六个固定摄像头捕获整个身体。接下来,我们实现了 MuViHandNet,这是一个神经管道,由用于获取手部视觉嵌入的图像编码器、用于学习时间和角度序列信息的循环学习器以及用于估计最终 3D 姿态信息的 U 网络架构的图网络组成。我们进行了广泛的实验,并展示了这个新数据集的挑战性以及我们提出的方法的有效性。 |
| Unaligned Image-to-Image Translation by Learning to Reweight Authors Shaoan Xie, Mingming Gong, Yanwu Xu, Kun Zhang 无监督图像到图像的翻译旨在学习从源域到目标域的映射,而无需使用配对图像进行训练。无监督图像翻译的一个基本但限制性的假设是两个域是对齐的,例如,对于 selfie2anime 任务,动漫自拍域必须只包含可以转换为其他域中某些图像的动漫自拍面部图像。收集对齐的域可能很费力,需要大量关注。在本文中,我们考虑了两个未对齐域之间的图像转换任务,这可能由于各种可能的原因而出现。为了解决这个问题,我们建议基于重要性重新加权来选择图像,并开发一种方法来学习权重并同时自动执行翻译。我们将所提出的方法与最先进的图像翻译方法进行比较,并在具有未对齐域的不同任务上呈现定性和定量结果。 |
| A 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer Authors Jinxiang Liu, Yangheng Zhao, Siheng Chen, Ya Zhang 人体姿态转移通常被建模为 2D 图像到图像的转换问题。此公式忽略了 3D 空间中的先验人体形状,并且不可避免地会导致难以置信的伪像,尤其是在面对遮挡时。为了解决这个问题,我们提出了一个提升和投影框架来在 3D 网格空间中执行姿势转移。我们框架的核心是前景生成模块,它由两个新颖的网络组成:提升和投影网络 LPNet 和外观细节补偿网络 ADCNet。为了利用人体形状先验,LPNet 利用身体网格的拓扑信息来学习 3D 网格空间中目标人物的富有表现力的视觉表示。为了保留纹理细节,进一步引入 ADCNet 以增强 LPNet 产生的特征与源前景图像。前景生成模块的这种设计使模型能够更好地处理诸如遮挡等困难情况。 |
| Feasibility study of urban flood mapping using traffic signs for route optimization Authors Bahareh Alizadeh, Diya Li, Zhe Zhang, Amir H. Behzadan 水事件是世界上最频繁、代价最高的气候灾害。在美国,估计有 1.27 亿生活在沿海地区的人面临着因飓风或洪水而遭受重大房屋损坏的风险。在洪水应急管理中,及时有效的空间决策和智能路由依赖于精细时空尺度的洪水深度信息。在本文中,利用众包收集淹没停车标志的照片,并将每张照片与在同一位置拍摄的洪水前照片配对。然后使用深度神经网络和图像处理分析每对照片,以估计照片所在位置的洪水深度。生成的逐点深度数据被转换为洪水淹没图,并由 A 搜索算法使用,以确定连接感兴趣点的最佳洪水自由路径。 |
| Paint4Poem: A Dataset for Artistic Visualization of Classical Chinese Poems Authors Dan Li, Shuai Wang, Jie Zou, Chang Tian, Elisha Nieuwburg, Fengyuan Sun, Evangelos Kanoulas 在这项工作中,我们提出了一个新的中国古典诗歌艺术可视化任务,其目标是为中国古典诗歌生成某种艺术风格的绘画。为此,我们构建了一个名为 Paint4Poem 的新数据集。 Paint4Poem的第一部分由301幅高质量的诗画对组成,由中国现代艺术家冯子恺手工收集而成。由于其小规模对有效训练诗歌到绘画生成模型提出了挑战,我们介绍了 Paint4Poem 的第二部分,它包括从冯子恺的绘画中手动收集的 3,648 个字幕绘画对和从网络上自动收集的 89,204 个诗歌绘画对。我们希望前者有助于学习艺术家的绘画风格,因为它包含了他的大部分画作,而后者有助于学习诗与画之间的语义关联。此外,我们分析了 Paint4Poem 的诗歌多样性、绘画风格以及诗歌与绘画之间的语义相关性。我们为 Paint4Poem 创建了一个基准,我们训练两个有代表性的文本到图像生成模型 AttnGAN 和 MirrorGAN,并评估它们在绘画图像质量、绘画风格相关性以及诗与绘画之间的语义相关性方面的表现。结果表明这些模型能够生成绘画具有良好的画面质量,模仿冯子恺的风格,但对诗歌语义的反映有限。 |
| Keypoints-Based Deep Feature Fusion for Cooperative Vehicle Detection of Autonomous Driving Authors Yunshuang Yuan, Hao Cheng, Monika Sester 研究在车辆之间共享集体感知消息CPM以减少遮挡,从而提高自动驾驶的感知准确性和安全性。然而,高度准确的数据共享和低通信开销是集体感知的一大挑战,尤其是在联网和自动化车辆之间需要实时通信时。在本文中,我们提出了一种高效且有效的基于关键点的深度特征融合框架,称为 FPV RCNN,用于集体感知,它建立在 3D 对象检测器 PV RCNN 之上。我们引入了一个边界框建议匹配模块和一个关键点选择策略来压缩 CPM 大小并解决多车辆数据融合问题。与鸟瞰图 BEV 关键点特征融合相比,FPV RCNN 在专门用于集体感知的合成数据集 COMAP 上以高评估标准 IoU 0.7 实现了大约 14 的检测精度提高。此外,其性能可与共享中没有数据丢失的两个原始数据融合基线相媲美。此外,我们的方法还将 CPM 大小显着降低到小于 0.3KB,这比以前工作中使用的 BEV 特征图共享小约 50 倍。即使 CPM 特征通道的数量进一步减少,即从 128 到 32,检测性能也仅下降约 1。 |
| Fast Point Voxel Convolution Neural Network with Selective Feature Fusion for Point Cloud Semantic Segmentation Authors Xu Wang, Yuyan Li, Ye Duan 我们提出了一种用于点云分析的新型轻量级卷积神经网络。与当前许多通过对点云进行下采样来增加感受野的 CNN 相比,我们的方法直接对整个点集进行操作而无需采样,并有效地实现了良好的性能。我们的网络由点体素卷积 PVC 层作为构建块组成。每层有两个平行的分支,即体素分支和点分支。特别是对于体素分支,我们在非空体素中心聚合局部特征以减少体素化引起的几何信息损失,然后应用体积卷积来增强局部邻域几何编码。对于点分支,我们使用多层感知器 MLP 来提取精细的逐点特征。这两个分支的输出通过特征选择模块自适应融合。此外,我们监督每个 PVC 层的输出以学习不同级别的语义信息。最终预测是通过平均所有中间预测来做出的。我们凭经验证明我们的方法能够在快速和内存高效的同时获得可比较的结果。 |
| SPNet: Multi-Shell Kernel Convolution for Point Cloud Semantic Segmentation Authors Yuyan Li, Chuanmao Fan, Xu Wang, Ye Duan 特征编码对于点云分析至关重要。在本文中,我们提出了一种名为 Shell Point Convolution SPConv 的新型点卷积算子,用于形状编码和局部上下文学习。具体来说,SPConv 将 3D 邻域空间拆分为壳,在手动设计的内核点上聚合局部特征,并在壳上执行卷积。此外,SPConv 包含一个简单而有效的注意力模块,可增强局部特征聚合。基于SPConv构建了一个名为SPNet的深度神经网络来处理大规模点云。泊松盘采样和特征传播被纳入 SPNet 以提高效率和准确性。我们提供了外壳设计的详细信息,并对具有挑战性的大规模点云数据集进行了大量实验。 |
| Long Short View Feature Decomposition via Contrastive Video Representation Learning Authors Nadine Behrmann, Mohsen Fayyaz, Juergen Gall, Mehdi Noroozi 自监督视频表示方法通常侧重于视频中时间属性的表示。然而,静止属性与非静止属性的作用较少探索 静止特征在整个视频中保持相似,能够预测视频级别的动作类。代表随时间变化的属性的非平稳特征对于涉及更细粒度的时间理解的下游任务更有利,例如动作分割。我们认为捕获两种类型特征的单一表示是次优的,并建议通过从长视频和短视频(即长视频序列及其较短的子序列)的对比学习来将表示空间分解为静态和非静态特征。固定特征在短视图和长视图之间共享,而非固定特征聚合短视图以匹配相应的长视图。为了凭经验验证我们的方法,我们证明了我们的静态特征在动作识别下游任务中特别有效,而我们的非静态特征在动作分割上表现更好。 |
| Weakly-Supervised Monocular Depth Estimationwith Resolution-Mismatched Data Authors Jialei Xu, Yuanchao Bai, Xianming Liu, Junjun Jiang, Xiangyang Ji 从单个图像进行深度估计是计算机视觉领域的一个活跃研究课题。最准确的方法是基于完全监督学习模型,该模型依赖于大量密集且高分辨率的 HR 地面实况深度图。然而,在实践中,通常以比深度图高得多的分辨率捕获彩色图像,从而导致分辨率不匹配的效果。在本文中,我们提出了一种新的弱监督框架来训练单目深度估计网络以生成具有分辨率不匹配监督的 HR 深度图,即输入是 HR 彩色图像,而地面实况是低分辨率 LR 深度图。所提出的弱监督框架由共享权重单目深度估计网络和用于蒸馏的深度重建网络组成。具体来说,对于单目深度估计网络,输入的彩色图像首先被下采样以获得与地面实况深度相同分辨率的 LR 版本。然后,将 HR 和 LR 彩色图像都输入到所提出的单目深度估计网络中以获得相应的估计深度图。我们引入了三个损失来训练网络 1 估计 LR 深度和地面实况 LR 深度之间的重建损失 2 下采样估计 HR 深度和地面实况 LR 深度之间的重建损失 3 估计 LR 深度和下采样估计 HR 之间的一致性损失深度。此外,我们设计了一个从深度到深度的深度重建网络。通过蒸馏损失,两个网络之间的特征保持了亲和空间的结构一致性,最终提高了估计网络的性能。 |
| ImplicitVol: Sensorless 3D Ultrasound Reconstruction with Deep Implicit Representation Authors Pak Hei Yeung, Linde Hesse, Moska Aliasi, Monique Haak, the INTERGROWTH 21st Consortium, Weidi Xie, Ana I.L. Namburete 这项工作的目标是从一组具有深度隐式表示的 2D 手绘超声图像中实现 3D 体积的无传感器重建。与将 3D 体积表示为离散体素网格的传统方式相比,我们通过将其参数化为连续函数的零级集来实现,即将 3D 体积隐式表示为从空间坐标到相应强度的映射值。我们提出的模型称为 ImplicitVol,将一组 2D 扫描及其在 3D 中的估计位置作为输入,联合参考估计的 3D 位置并学习 3D 体积的完整重建。在对真实 2D 超声图像进行测试时,从 ImplicitVol 采样的新型横截面视图显示出比从现有重建方法采样的图像质量明显更好的视觉质量,在 3D 体积测试的输出和地面实况之间的性能优于它们 30 NCC 和 SSIM数据。 |
| CLIPort: What and Where Pathways for Robotic Manipulation Authors Mohit Shridhar, Lucas Manuelli, Dieter Fox 我们如何才能让机器人具备精确操纵物体的能力,同时还能根据抽象概念对它们进行推理?最近的操纵工作表明,端到端网络可以学习需要精确空间推理的灵巧技能,但这些方法往往无法推广到新目标或快速学习跨任务的可转移概念。同时,通过对大规模互联网数据进行训练,在学习视觉和语言的可概括语义表示方面取得了很大进展,但是这些表示缺乏细粒度操作所需的空间理解。为此,我们提出了一个框架,它结合了两个世界中最好的两个流体系结构与语义和空间路径,用于基于视觉的操作。具体来说,我们提出了 CLIPort,这是一种语言条件模仿学习代理,它结合了 CLIP 1 的广泛语义理解和 Transporter 2 的空间精度 where。我们的端到端框架能够解决各种语言指定的桌面任务,从打包看不见的物体到折叠布料,所有这些任务都没有任何物体姿势、实例分割、记忆、符号状态或句法结构的明确表示。在模拟和现实世界设置中的实验表明,我们的方法在少数镜头设置中具有数据效率,并且可以有效地推广到可见和不可见的语义概念。 |
| Quantitative Matching of Forensic Evidence Fragments Utilizing 3D Microscopy Analysis of Fracture Surface Replicas Authors Bishoy Dawood, Carlos Llosa Vite, Geoffrey Z. Thompson, Barbara K. Lograsso, Lauren K. Claytor, John Vanderkolk, William Meeker, Ranjan Maitra, Ashraf Bastawros 断裂表面带有独特的细节,可以提供准确的定量比较,以支持对这些断裂表面的比较取证分析。在这项研究中,统计分析比较协议应用于一组断裂表面对及其复制品的 3D 拓扑图像,以提供对断裂物品及其复制品之间的定量统计比较的信心。一组 10 个断裂的不锈钢样品在受控条件下从同一金属棒断裂,并使用标准法医铸造技术进行铸造。为每个断裂对获取了六个具有 50 个重叠的 3D 拓扑图。利用光谱分析来确定表面拓扑不同长度尺度下拓扑表面特征之间的相关性。我们在大于两个晶粒直径的临界波长上选择了两个频段进行统计比较。我们的统计模型使用了矩阵变量 t 分布,该分布考虑了图像重叠来模拟匹配和非匹配人口密度。开发了一个决策规则来识别匹配和不匹配的表面对的概率。所提出的方法以超过 99.96 的后验概率正确地对断裂的钢表面及其复制品进行了分类。此外,复制技术显示了在波长大于 20 微米的情况下准确复制断裂表面拓扑细节的潜力,这远远超过了大多数金属合金 50 200 微米的比较范围。 |
| Towards Autonomous Crop-Agnostic Visual Navigation in Arable Fields Authors Alireza Ahmadi, Michael Halstead, Chris McCool 机器人在农田中的自主导航对于从作物监测到杂草管理和施肥的每一项任务都是必不可少的。许多当前的方法依赖于精确的 GPS,然而,这种技术很昂贵并且也容易出现故障,例如由于缺乏报道。因此,通过可以解释其环境的传感器(例如相机)进行导航对于实现农业自主目标非常重要。在本文中,我们介绍了一种纯粹基于视觉的导航方案,该方案能够可靠地引导机器人穿过大田。独立于任何全局定位或映射,这种方法能够准确地跟踪作物行并在行之间切换,仅使用机载摄像头。借助新型作物行检测和新型作物行切换技术,我们的导航方案可以部署在具有不同生长阶段不同冠层类型的广泛领域。我们使用我们的农业机器人平台 BonnBot I 在各种照明条件下在五个不同领域广泛测试了我们的方法。 |
| Learning-based Noise Component Map Estimation for Image Denoising Authors Sheyda Ghanbaralizadeh Bahnemiri, Mykola Ponomarenko, Karen Egiazarian 本文考虑了当图像被非平稳噪声破坏时的图像去噪问题。由于实际上没有关于噪声的先验信息可用,因此应对图像去噪预先估计噪声统计数据。在本文中,提出了基于深度卷积神经网络 CNN 的方法,用于估计局部的、逐块的、噪声标准差的图,即所谓的西格玛图。它在非平稳噪声情况下的 sigma 图估计精度以及加性高斯白噪声情况下的噪声方差估计方面达到了最先进的性能。使用估计的 sigma 映射进行图像去噪的大量实验表明,我们的方法在 PSNR 方面优于最近基于 CNN 的盲图像去噪方法高达 6 dB,以及基于 sigma 映射估计的其他最先进的方法高达 0.5 dB,提供同时更好的使用灵活性。 |
| Few-shot Learning Based on Multi-stage Transfer and Class-Balanced Loss for Diabetic Retinopathy Grading Authors Lei Shi, Junxing Zhang 糖尿病视网膜病变DR是目前已知的主要致盲疾病之一。使用深度学习方法对 DR 进行自动分级,不仅可以加快疾病的诊断速度,还可以降低误诊率。然而,DR数据集中样本不足、类别分布不平衡等问题制约了分级性能的提升。在本文中,我们将多阶段迁移的思想引入到 DR 的分级任务中。新的迁移学习技术利用具有不同规模的多个数据集,使模型能够学习更多的特征表示信息。同时,为了应对不平衡的 DR 数据集,我们提出了一种在自然图像分类任务中表现良好的类平衡损失函数,并对其采用了一种简单易行的训练方法。实验结果表明,应用多阶段转移和类平衡损失函数可以有效提高精度和二次加权kappa等分级性能指标。 |
| SIM2REALVIZ: Visualizing the Sim2Real Gap in Robot Ego-Pose Estimation Authors Theo Jaunet, Guillaume Bono, Romain Vuillemot, Christian Wolf 机器人社区已经开始严重依赖越来越逼真的 3D 模拟器,以对大量数据的机器人进行大规模训练。但是一旦机器人部署在现实世界中,模拟差距以及现实世界中的变化,例如灯光、物体位移导致错误。在本文中,我们介绍了 Sim2RealViz,这是一种可视化分析工具,可帮助专家理解和缩小机器人自我姿态估计任务的差距,即使用训练有素的模型估计机器人的位置。 Sim2RealViz 显示给定模型的详细信息及其实例在模拟和现实世界中的性能。专家可以识别在给定位置影响模型预测的环境差异,并通过与模型假设的直接交互进行探索以修复它。 |
| Adversarial Domain Feature Adaptation for Bronchoscopic Depth Estimation Authors Mert Asim Karaoglu, Nikolas Brasch, Marijn Stollenga, Wolfgang Wein, Nassir Navab, Federico Tombari, Alexander Ladikos 从单眼图像进行深度估计是支气管镜导航定位和 3D 重建管道中的一项重要任务。各种基于监督和自监督深度学习的方法已经在自然图像的这项任务中证明了自己。然而,标记数据的缺乏和支气管组织特征稀少的纹理使得这些方法在支气管镜场景中的利用效果不佳。在这项工作中,我们提出了一种替代域自适应方法。我们新颖的两步结构首先以有监督的方式训练带有标记合成图像的深度估计网络,然后采用无监督的对抗域特征适应方案来提高真实图像的性能。 |
| Holistic Semi-Supervised Approaches for EEG Representation Learning Authors Guangyi Zhang, Ali Etemad 最近,通常需要大量类别标签的监督方法在 EEG 表示学习方面取得了可喜的成果。然而,标记 EEG 数据是一项具有挑战性的任务。最近,只需要很少输出标签的整体半监督学习方法在计算机视觉领域显示出有希望的结果。然而,这些方法尚未适用于 EEG 学习。在本文中,我们采用了三种最先进的整体半监督方法,即 MixMatch、FixMatch 和 AdaMatch,以及五种用于 EEG 学习的经典半监督方法。我们在两个基于 EEG 的公共情感识别数据集(即 SEED 和 SEED IV)上使用所有 8 种方法进行了严格的实验。使用不同数量的有限标记样本进行的实验表明,即使每个类只使用 1 个标记样本,整体方法也能取得很好的结果。 |
| Training Automatic View Planner for Cardiac MR Imaging via Self-Supervision by Spatial Relationship between Views Authors Dong Wei, Kai Ma, Yefeng Zheng 心脏磁共振成像 CMR 采集的视图规划需要熟悉心脏解剖结构,并且在临床实践中仍然是一项具有挑战性的任务。其自动化的现有方法要么依赖于通常在临床常规中未获得的额外体积图像,要么依赖于费力的心脏结构标志的手动注释。这项工作提出了一种用于自动 CMR 视图规划的诊所兼容且无注释的系统。该系统更具体地挖掘空间关系,定位和利用源视图和目标视图之间的交叉线,并训练深度网络以回归由这些交叉线定义的热图。由于空间关系本身包含在正确存储的数据中,例如,在 DICOM 格式中,消除了手动注释的需要。然后,提出了一种多视图规划策略,从目标视图的所有源视图的预测热图中聚合信息,以获得全局最优处方。多视图聚合模仿了熟练的人类开药者所采用的类似策略。 181 次临床 CMR 考试的实验结果表明,我们的系统在规定四个标准 CMR 视图时,比现有方法(包括基于传统图谱和基于新的深度学习的方法)具有更高的准确性。 |
| Chinese Abs From Machine Translation |