1、Vosk
下载
下载vosk-untiy-asr
Github链接:https://github.com/alphacep/vosk-unity-asr
进不去Github的可以用网盘
夸克网盘链接:https://pan.quark.cn/s/780337ab5dbf
下载后解压,将Assets文件夹中的所有文件拷贝到项目中。
下载模型
模型地址:https://alphacephei.com/vosk/models,下载后不用解压,直接将模型压缩包放到项目中的Assets\StreamingAssets文件夹下。
- 我下载的是轻量级中文模型
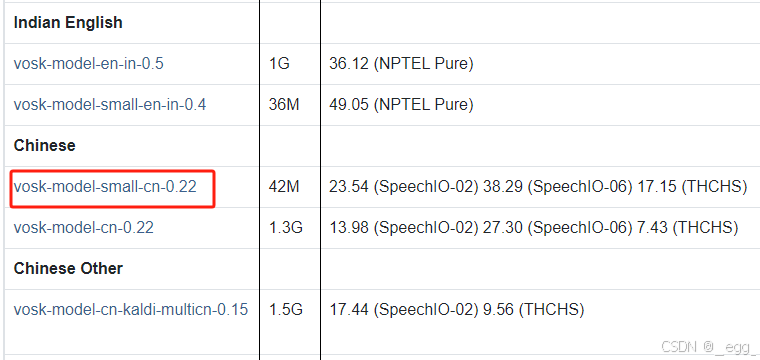
在项目中使用
语音转文字
1、先搭建一个界面
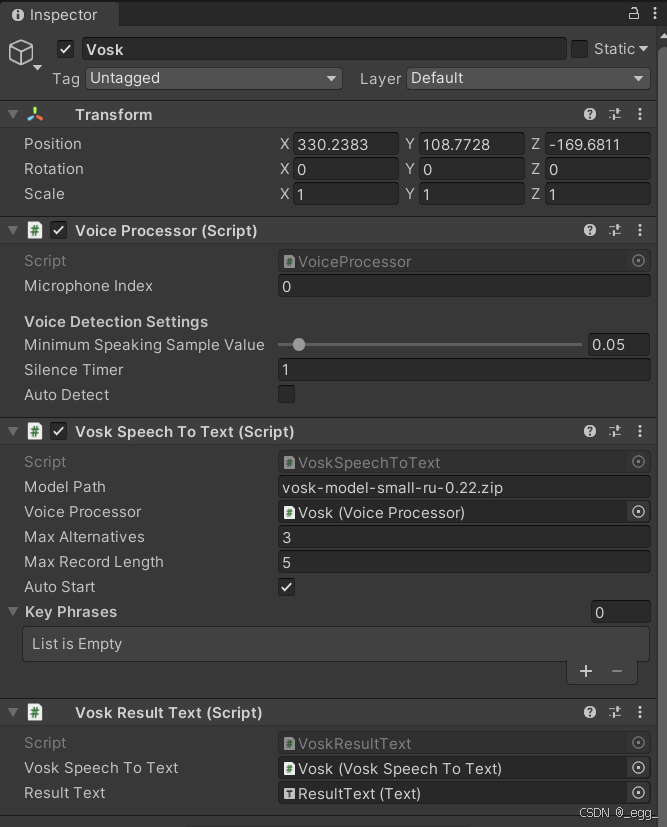
2、在场景中将以下三个脚本挂载到空物体上。
更改上方所述脚本VoskSpeechToText中ModelPath路径为自己下载的模型压缩包名称,比如我下载的模型为vosk-model-small-cn-0.22,则ModelPath应该为vosk-model-small-cn-0.22.zip

音频转文字
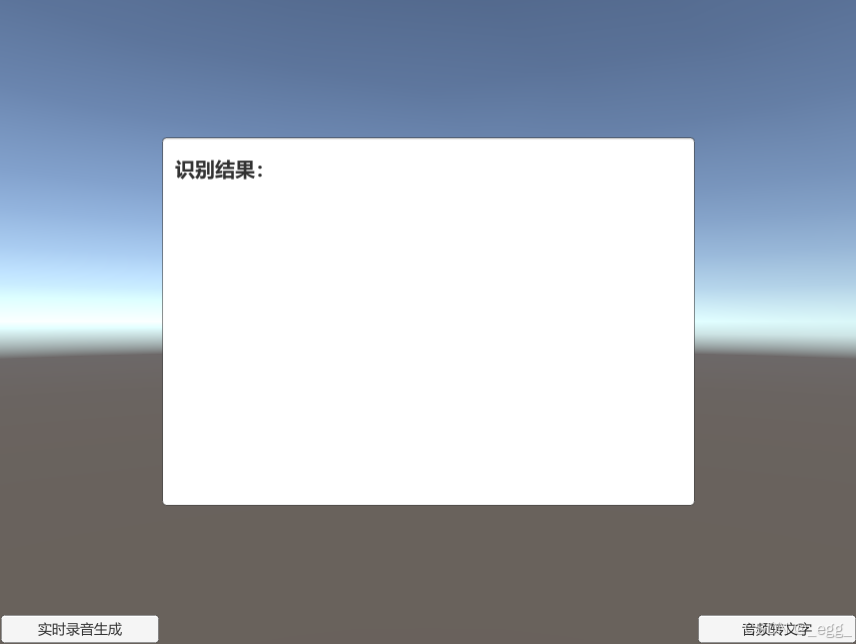
我根据vosk-unity-asr的案例改了一个将音频转文字的demo,界面如下,可自行下载使用。
csdn:https://download.csdn.net/download/vegetable_haker/90304939
夸克网盘:https://pan.quark.cn/s/d74361da0963
2、whisper
下载
下载unity项目
github地址:https://github.com/Macoron/whisper.unity
网盘地址:https://pan.quark.cn/s/546dd7c7339f
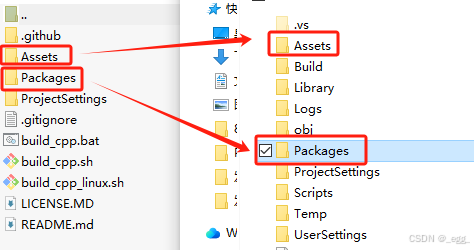
下载完成后解压,将Assets文件夹下的文件全部放入项目中,同样将Packages文件夹下的com.whisper.unity复制到项目中的Packages文件夹下
下载模型
模型地址:https://huggingface.co/ggerganov/whisper.cpp/tree/main
找到想要使用的模型,点击后面的下载图标即可。如图,我下载的是tiny模型。
在unity中使用
-
首先搭建好界面