官方连接:Vanna.AI - Personalized AI SQL Agent
1.背景
基于大模型的TextToSql的关键为给大模型提供正确有效的数据库信息及问题,以提升大模型生成sql的正确率。database_info + question形成prompt,但是实际中通常会遇到一个问题,生产中的数据库结构之复杂,通常一个数据库可能200-500个表,那么prompt通常容不下这么多信息?这是面临的主要问题:如何在有效的prompt长度限制之内传递给大模型有效的信息辅助生成sql?
选表!
让大模型根据问题自动选择相关的表信息组合形成prompt。
完全可以借助RAG完成自动选表!将数据库相关信息存入向量知识库,每次查询检索相关表信息形成prompt,可以很好的解决上述问题。Vanna-ai正是借助RAG增强了大模型SQL的生成能力。
Vanna 使用一种称为 LLM(大型语言模型)的生成式人工智能。简而言之,这些模型是在大量数据(包括一堆在线可用的 SQL 查询)上进行训练的,并通过预测响应提示中最有可能的下一个单词或“标记”来工作。Vanna 优化了提示(通过向量数据库使用嵌入搜索)并微调 LLM 模型以生成更好的 SQL。
Vanna 正在使用和试验许多不同的LLM,以获得最准确的结果。OpenAI 的 GPT 模型通常表现出色,但有时 Google 的 Bard、Meta 的 LLAMA 和 Falcon 模型表现最好。
2.关于Vanna-ai
从本质上讲,Vanna 是一个 Python 包,它使用检索增强来帮助您使用 LLM 为数据库生成准确的 SQL 查询。
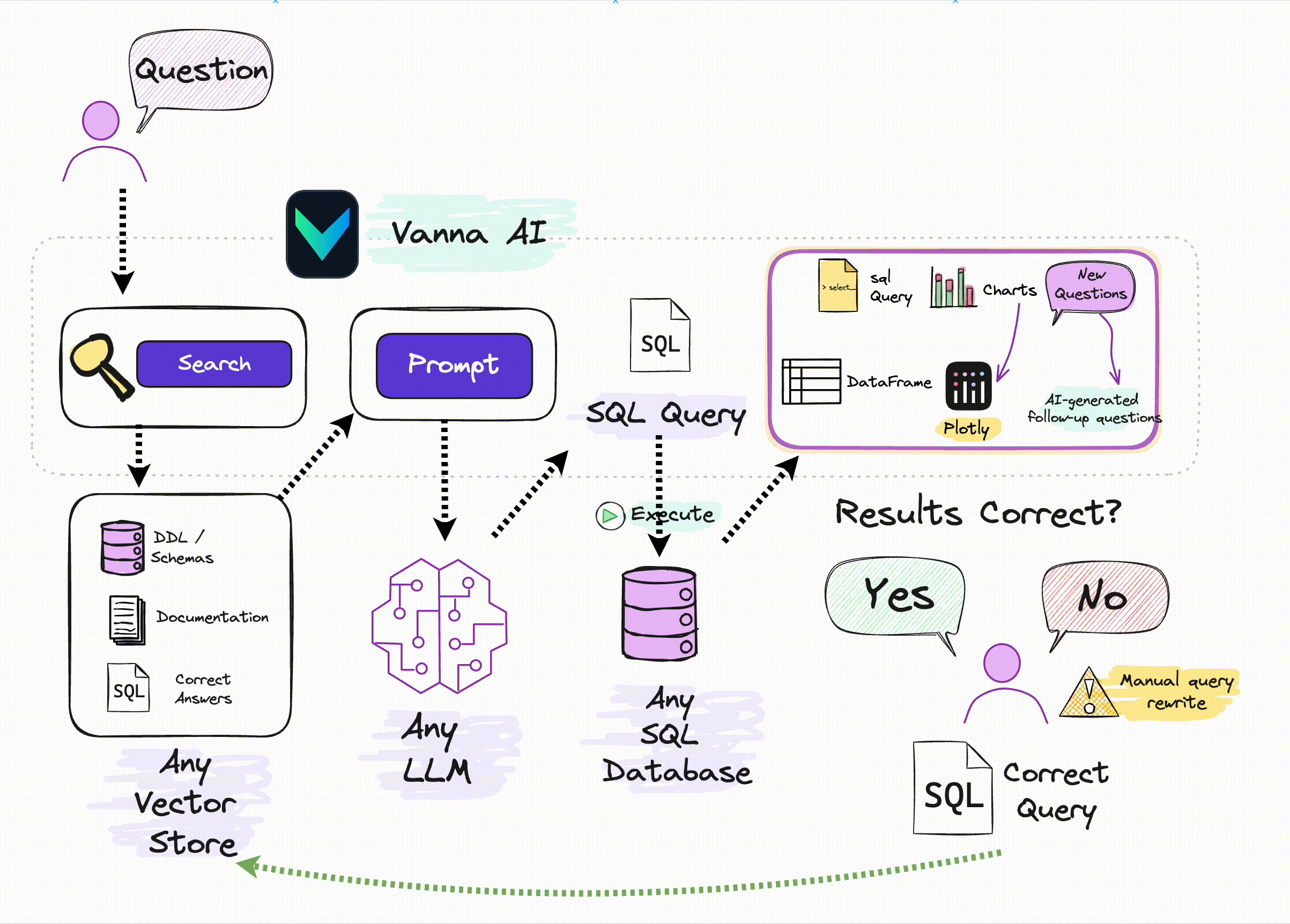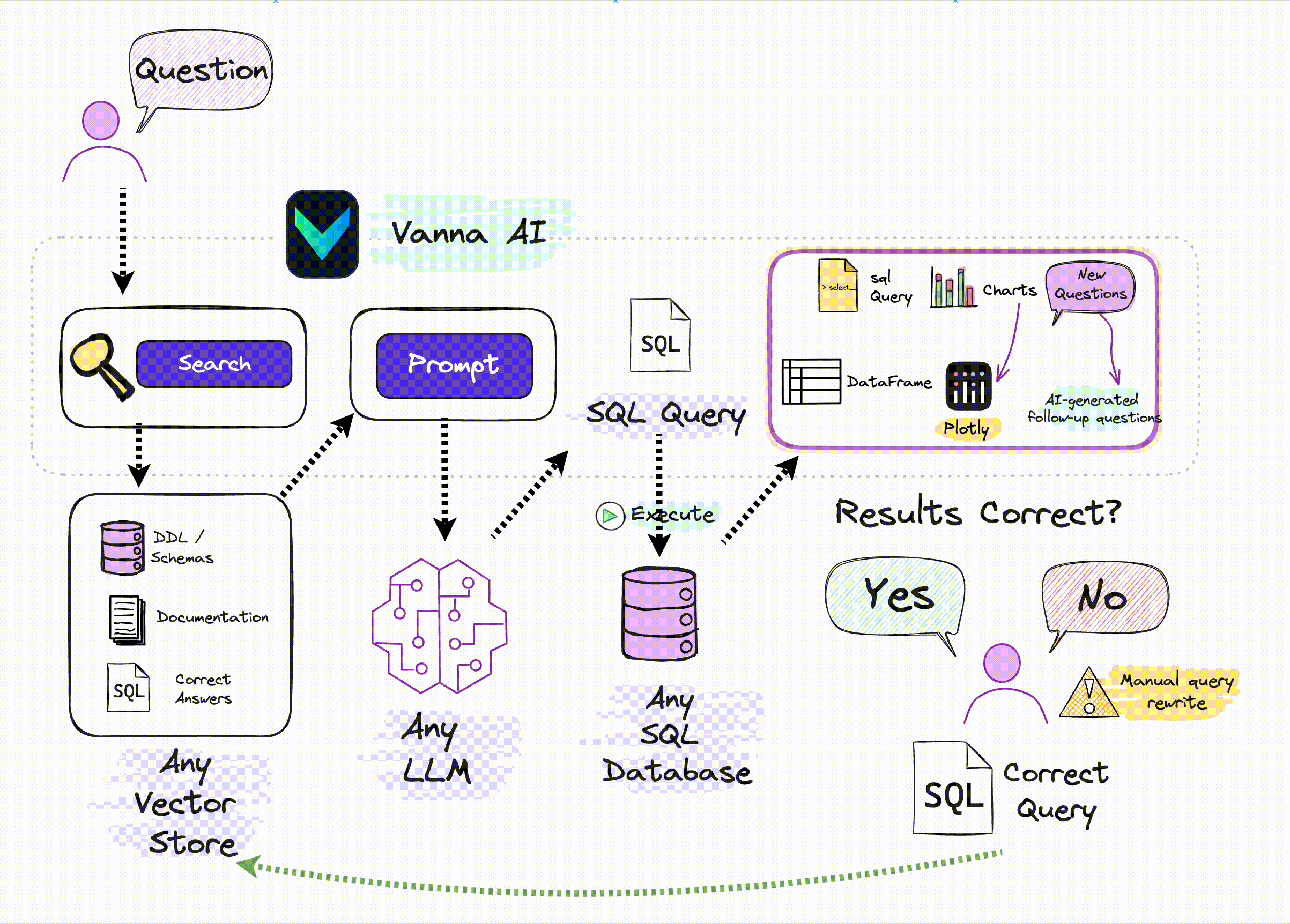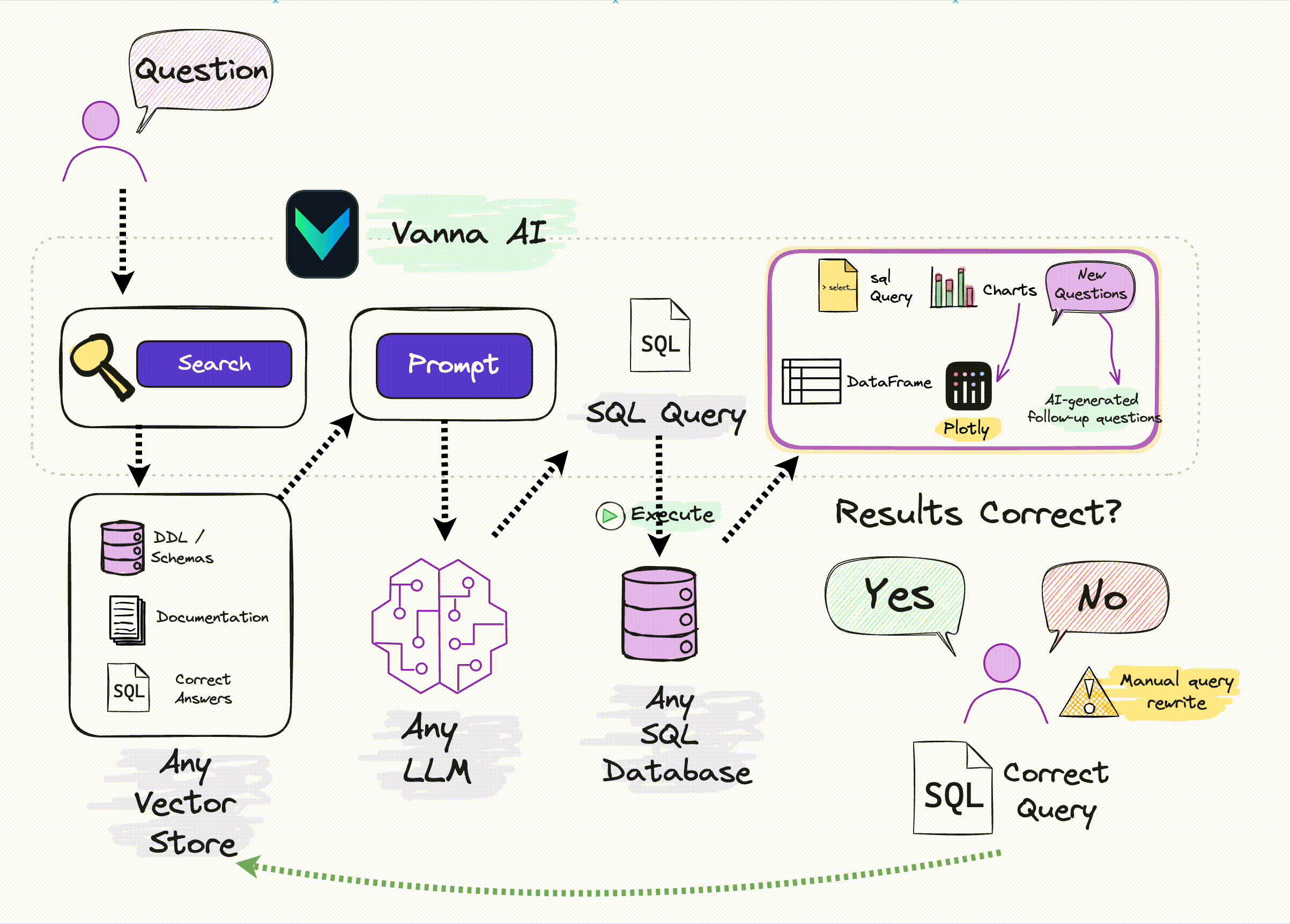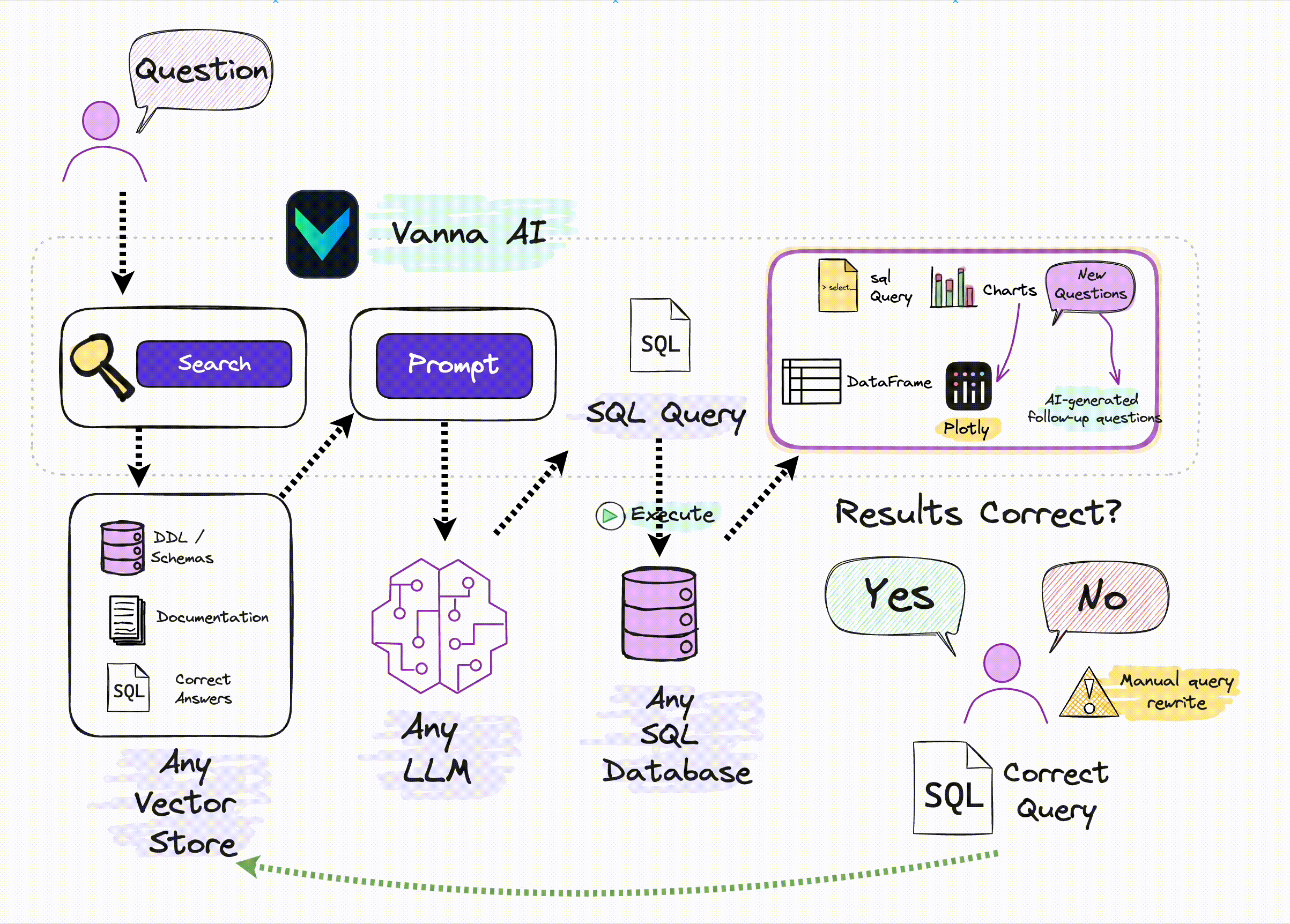
Vanna 的工作过程分为两个简单步骤 :
- 在您的数据上训练 RAG“模型”-本质上是基于文档(建表语句、相关sql查询、表或者字段的comment)作为资料,进行Embedding后存入向量库
- 然后提出问题,基于这些问题去向量库检索相关信息,这些问题传给大模型返回 SQL 查询,这些查询可以设置为在您的数据库上自动运行。
3.工作原理
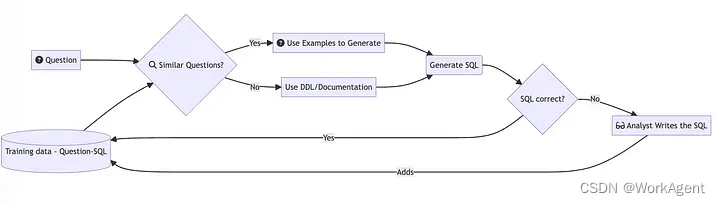
当你向 Vanna 提出问题时,会执行以下过程
- 我们首先在我们的训练集中搜索过去提出过的类似问题。
- 如果我们发现类似的问题,我们会将这些问题中经过验证的 SQL 传递到我们的模型。
- 否则,我们会传入 DDL、文档或引导查询。 -本质上是一个检索增强的过程。
- 然后,您的架构特有的 Vanna 模型会生成 SQL。
- 然后我们运行 SQL 来验证它。如果经过验证,它将进入训练数据。
- 否则,分析师可以更正 SQL 并将其放入训练数据中。
随着时间的推移,Vanna 不断提高对您的模式的理解,并正确回答越来越多的问题。
4.Vanna-ai简单案例
import vanna
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-*************', 'model': 'gpt-3.5-turbo'})
# 训练向量库
vn.train(ddl="""
SELECT customer_name, SUM(sales_amount) as total_sales
FROM sales_wn
GROUP BY customer_name
ORDER BY total_sales DESC
LIMIT 10;
""")
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
# 询问问题
vn.ask("What are the top 10 customers by sales?")