在C++中字符串类的string的模板原型是basic_string
class basic_string{
 };
};
第一个参数_Elem表示类型。第二个参数traits的缺省值使用char_traits类型,定义了类型和字符操作的函数,如比较、等价、分配等。第三个参数_Ax的默认值是allocator类,表示了内存模式,不同的内存结构将操作指针的不同行为,例如栈、堆或段内存模式等。
在C++标准里定义了两个字符串string和wstring
typedef basic_string < wchar_t > wstring;
前者string是常用类型,可以看作char[],其实这正是与string定义中的_Elem=char相一致。而wstring,使用的是wchar_t类型,这是宽字符,用于满足非ASCII字符的要求,例如Unicode编码,中文,日文,韩文什么的。对于wchar_t类型,实际上C++中都用与char函数相对应的wchar_t的函数,因为他们都是从同一个模板类似于上面的方式定义的。因此也有wcout, wcin, werr等函数。
实际上string也可以使用中文,但是它将一个汉字写在2个char中。而如果将一个汉字看作一个单位wchar_t的话,那么在wstring中就只占用一个单元,其它的非英文文字和编码也是如此。这样才真正的满足字符串操作的要求,尤其是国际化等工作。
看一下下面的程序,就会理解两者的差别。
#include < string >
using namespace std;
#define tab "\t"
int main()
{
locale def;
cout << def.name() << endl;
locale current = cout.getloc();
cout << current.name() << endl;
float val = 1234.56 ;
cout << val << endl;
// chage to french/france
cout.imbue(locale( " chs " ));
current = cout.getloc();
cout << current.name() << endl;
cout << val << endl;
// 上面是说明locale的用法,下面才是本例的内容,因为其中用到了imbue函数
cout << " ********************************* " << endl;
// 为了保证本地化输出(文字/时间/货币等),chs表示中国,wcout必须使用本地化解析编码
wcout.imbue(std::locale( " chs " ));
// string 英文,正确颠倒位置,显示第二个字符正确
string str1( " ABCabc " );
string str11(str1.rbegin(),str1.rend());
cout << " UK\ts1\t: " << str1 << tab << str1[ 1 ] << tab << str11 << endl;
// wstring 英文,正确颠倒位置,显示第二个字符正确
wstring str2 = L " ABCabc " ;
wstring str22(str2.rbegin(),str2.rend());
wcout << " UK\tws4\t: " << str2 << tab << str2[ 1 ] << tab << str22 << endl;
// string 中文,颠倒后,变成乱码,第二个字符读取也错误
string str3( " 你好么? " );
string str33(str3.rbegin(),str3.rend());
cout << " CHN\ts3\t: " << str3 << tab << str3[ 1 ] << tab << str33 << endl;
// 正确的打印第二个字符的方法
cout << " CHN\ts3\t:RIGHT\t " << str3[ 2 ] << str3[ 3 ] << endl;
// 中文,正确颠倒位置,显示第二个字符正确
wstring str4 = L " 你好么? " ;
wstring str44(str4.rbegin(),str4.rend());
wcout << " CHN\tws4\t: " << str4 << tab << str4[ 1 ] << tab << str44 << endl;
wstring str5(str1.begin(),str1.end()); // 只有char类型的string时才可以如此构造
wstring str55(str5.rbegin(),str5.rend());
wcout << " CHN\tws5\t: " << str5 << tab << str5[ 1 ] << tab << str55 << endl;
wstring str6(str3.begin(),str3.end()); // 如此构造将失败!!!!
wstring str66(str6.rbegin(),str6.rend());
wcout << " CHN\tws6\t: " << str6 << tab << str6[ 1 ] << tab << str66 << endl;
return 0 ;
}
结果如下:
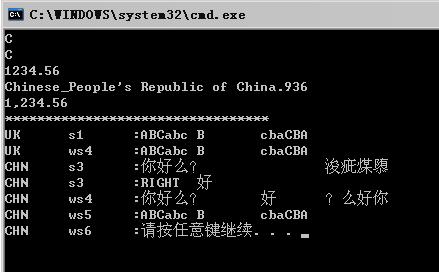
上面显示了本地化的作用,是在数字中每三位加一个逗号,其实对时间/文字等都是用影响的。
下面的输出说明了,如何正确使用string和wstring的方法。第三个因为使用string来表示汉字,出现了一些错误。最后一行也是错误,导致了输出也受到了影响,没有空格与回车。(最后两个就不要管中英文了,仅仅说明一下中文构造方法是错误的)
《掌握标准C++类》在第十二章《语言支持》中专门讲C++的国际化和本地化问题,C++提供了I18N的标准处理,软件开发者可以参考。
C++标准库还是非常博大精深的,功能比较齐全的。继续学习。