By Jonathan Ellis,系统架构师, Translated by Jametong
空前的数据量正在驱动商业寻找传统关系型数据库的替代方案,它已经为我们服务30多年了(今年5月份ACM刚刚给关系型数据庆祝40岁生日).总体来讲,这些替代方案就是目前知名的“NoSQL数据库.”
关系型数据库的基本问题是无法处理许多现代的工作负载.有三个具体的问题领域:向外扩展(Scale out)类似于Digg(3TB的绿色徽章数据)或Facebook(50T的收件箱搜索数据)或Ebay(总共2PB的数据)的数据集,单机性能限制以及僵化的概要设计.
商业上(包含Rackspace Cloud公司)需要寻找新的方式来存储并扩展大规模的数据.我最近写了一篇关于Cassandra的文章,一个我们投入了资源的非关系型数据库.还有另外一些正在运作中的非关系型数据库,它们汇总在一起被我们称为”NoSQL运动”.
“NoSQL”这个术语实际上是由一个Rackspace的员工Eric Evans最先提出的,当时来自Last.fm网站的Johan Oskarsson提议组织一次开源分布式数据库的研讨会.这个名称与概念就一起流行了起来.
有些人反对NoSQL这个说法,因为它听起来像是仅仅表明了我们不做什么,而不是我们在做什么. 事实确实是这样,我也基本同意此说法,但是这个术语仍然有其价值,因为当关系型数据库是你所知道的唯一工具时,每个问题看起来都像个拇指(俗语,如果你手里有一个锤子,你看到什么都是钉子,译者补充).NoSQL这个术语起码让人们知道还有其他的选项可供选择.但是,当关系型数据库是解决问题的最佳工具时,我们并不是反关系型数据库者;它的涵义应该是“不仅仅有SQL(Not Only SQL)”而不是“不再有SQL(No SQL at all)”.
有关NoSQL名称的一个真实的忧虑是,它是如此大的一个概念,以致于差异巨大的设计都可以涵盖其中.如果在讨论各种产品时没有搞清楚这一点,就会导致概念混乱.因此,我建议大家沿着下面三个维度来思考这些数据库选项: 可伸缩性(scalability)、数据模型与查询模型(data and query model)以及持久化设计(persistence design).
我选择了10种NoSQL数据库作为示例.这不是一份详尽的清单,但是这里讨论的概念对于评估其他的NoSQL数据库也至关重要.
可伸缩性(Scalability)
通过使用复制, 就可以轻易扩展读的规模,因此,每当我在此文中谈到规模伸缩(scaling),都是表示通过自动分区将数据分布到多台机器以扩展写的规模.我们将做这种事情的系统称为“分布式数据库”.它们包括Cassandra、HBase、Riak、Scalaris、Voldemort以及其他很多类似的系统.如果你的写容量或写数据大小已经无法在一台机器上进行处理,如果你不想自己手工来管理分区的话,这些就是你的唯一选项了.(你不会这么做吧?)
人们使用分布式数据库主要关注两件事情: 1) 是否支持多个数据中心以及2) 能否在对应用透明的前提下往正在运行的集群中添加新机器的能力.
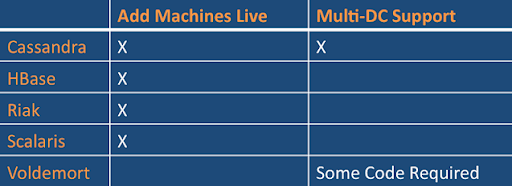
非分布式NoSQL数据库包括CouchDB、MongoDB、Neo4j、Redis以及Tokyo Cabinet.它们可作为分布式系统的持久层; MongoDB提供了受限制的数据分片(Sharding)功能,CouchDB也有一个独立的Lounge项目来支持做类似的分片功能,Tokyo Cabinet可用作Voldemort的存储引擎.
数据模型与查询模型
NoSQL数据库之间的数据模型与查询API千差万别.
(相关链接: Thrift, map/reduce views, Thrift, Cursor, Graph, Collection, Nested hashes, get/put, get/put, get/put)
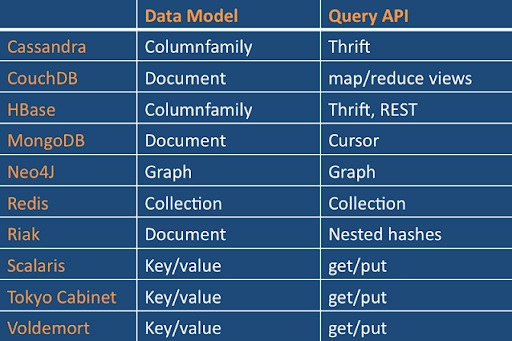
部分重点内容介绍:
Cassandra与HBase共同使用的ColumnFamily模型都是受到Google的Bigtable论文第2节的启发. (Cassandra丢弃了历史版本,并增加了超级列(SuperColumn)的概念).在这两个系统中,都有与你之前看到的关系型数据库类似的行/列概念,但是此处的行是稀疏的行:你想要一行有多少列,一行就可以有多少列,这些列并不需要事先定义好.
键值(Key/value)模型是最简单也最容易实现的模型,但是,如果你仅想对值(Value)的一部分进行查询/更新时,它的效率会比较低.要想在一个分布式的键值上,实现更加复杂的结构也会非常困难.
文档数据库实际上是更高级的键/值(Key/Value)数据库,允许在每个键上关联嵌套的值.相对于每次简单地返回整个BLOB(二进制大对象)来讲,文档数据库支持更高效的查询.
Neo4j拥有一个非常独特的数据模型,它以节点与边的形式在图中存储对象与关系.对于适合这个模型(例如,分层数据)的查询,它的性能可能会达到其替代选项的1000倍.
Scalaris的独特之处在于,它可以提供跨越多个键的分布式事务.(关于一致性与可用性的权衡的讨论超出了本文的范围,但是,在评估分布式系统时,它也是需要记住的一方面.)
持久化设计
关于持久化设计,我的意思是“数据在内部是如何存储的?”

持久化模型可以为我们提供大量关于这些数据库适合处理多大工作负载的信息.
内存数据库非常非常快(单台机器上的Redis可以处理100,000次操作/秒),但是无法处理超过可用内存的数据集.持久性(Durability,数据不会由于服务器崩溃或停电而丢失)也是个问题; 在两次刷新到磁盘的时间间隔内预期数据丢失量可能非常大.Scalaris是我们此列表中唯一的内存数据库,它通过复制来解决持久性的问题,但是,由于它不支持跨越多个数据中心,因此,如果遇到类似电源故障一类的问题数据仍将非常脆弱.
在为了持久性写入一个仅可追加的提交日志之后,Memtable与SSTable会缓冲内存中的写操作.在接受了足够多的写操作之后(Memtable达到一定的阈值),就会对memtable中的数据进行排序,并一次性写入到磁盘,写入的文件就是一个“sstable.” 这样它就可以提供接近于内存处理的性能,因为它不涉及任何检索操作,同时又可以避免纯粹在内存中的方法那样遭遇持久性问题.(在前面引用的Bigtable论文的第5.3与5.4两节,以及论文日志结构的合并树(The Log-Structured merge-tree)中对此都有详细的描述)
几乎从有数据库开始,B-树就开始在数据库中使用了.它们提供健壮的索引支持,但是在旋转磁盘(仍然是目前最经济实用的存储介质)上, 它的性能表现比较差,因为它读写任何内容都会涉及到多次磁盘检索.
CouchDB的仅可做追加操作的B-树(Append-Only B-tree)是一个比较有趣的变体,它以限制CouchDB并发写(one write at a time)的代价避免了其检索的开销.
结论
NoSQL运动在2009年取得了爆发性的效果,因为越来越多的企业需要处理大规模的数据.Rackspace Cloud公司很高兴在NoSQL运动扮演了一个较早期的角色,还会持续为Cassandra投入资源并支持与NoSQL East类似的活动.
可以到Google讨论组找到与NoSQL相关的会议通知与讨论.
原文链接:http://www.dbthink.com/?p=458