本章介绍Verilog模块和例化、函数与任务的内容。
文章目录
5.1 Verilog 模块与端口
模块
模块是 Verilog 中基本单元的定义形式,是与外界交互的接口。
模块格式定义如下:
module module_name
#(parameter_list)
(port_list) ;
Declarations_and_Statements ;
endmodule
模块定义必须以关键字 module 开始,以关键字 endmodule 结束。
模块名,端口信号,端口声明和可选的参数声明等,出现在设计使用的 Verilog 语句(图中 Declarations_and_Statements)之前。
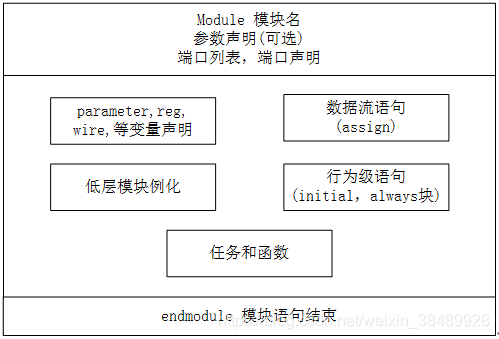
模块内部有可选的 5 部分组成,分别是变量声明,数据流语句,行为级语句,低层模块例化及任务和函数,如下图表示。这 5 部分出现顺序、出现位置都是任意的。但是,各种变量都应在使用之前声明。变量具体声明的位置不要求,但必须保证在使用之前的位置。
端口
端口是模块与外界交互的接口。对于外部环境来说,模块内部是不可见的,对模块的调用只能通过端口连接进行。
端口列表
模块的定义中包含一个可选的端口列表,一般将不带类型、不带位宽的信号变量罗列在模块声明里。下面是一个 PAD 模型的端口列表:
module pad(
DIN, OEN, PULL,
DOUT, PAD);
一个模块如果和外部环境没有交互,则可以不用声明端口列表。例如之前我们仿真时 test.sv 文件中的 test 模块都没有声明具体端口。
module test ; //直接分号结束
...... //数据流或行为级描述
endmodule
端口声明
- 端口信号在端口列表中罗列出来以后,就可以在模块实体中进行声明了。
根据端口的方向,端口类型有 3 种: 输入(input),输出(output)和双向端口(inout)。
input、inout 类型不能声明为 reg 数据类型,因为 reg 类型是用于保存数值的,而输入端口只能反映与其相连的外部信号的变化,不能保存这些信号的值。
output 可以声明为 wire 或 reg 数据类型。
上述例子中 pad 模块的端口声明,在 module 实体中就可以表示如下:
//端口类型声明
input DIN, OEN ;
input [1:0] PULL ; //(00,01-dispull, 11-pullup, 10-pulldown)
inout PAD ; //pad value
output DOUT ; //pad load when pad configured as input
//端口数据类型声明
wire DIN, OEN ;
wire [1:0] PULL ;
wire PAD ;
reg DOUT ;
- 在 Verilog 中,端口隐式的声明为 wire 型变量,即当端口具有 wire 属性时,不用再次声明端口类型为 wire 型。但是,当端口有 reg 属性时,则 reg 声明不可省略。
上述例子中的端口声明,则可以简化为:
input DIN, OEN ;
input [1:0] PULL ;
inout PAD ;
output DOUT ;
reg DOUT ;
- 当然,信号 DOUT 的声明完全可以合并成一句:
output reg DOUT ;
- 还有一种
更简洁且常用的方法来声明端口,即在 module 声明时就陈列出端口及其类型。reg 型端口要么在 module 声明时声明,要么在 module 实体中声明,例如以下 2 种写法是等效的。
module pad(
input DIN, OEN ,
input [1:0] PULL ,
inout PAD ,
output reg DOUT
);
module pad(
input DIN, OEN ,
input [1:0] PULL ,
inout PAD ,
output DOUT
);
reg DOUT ;
inout 端口仿真
对包含有 inout 端口类型的 pad 模型进行仿真。pad 模型完整代码如下:
module pad(
//DIN, pad driver when pad configured as output
//OEN, pad direction(1-input, o-output)
input DIN, OEN ,
//pull function (00,01-dispull, 10-pullup, 11-pulldown)
input [1:0] PULL ,
inout PAD ,
//pad load when pad configured as input
output reg DOUT
);
//input:(not effect pad external input logic), output: DIN->PAD
assign PAD = OEN? 'bz : DIN ;
//input:(PAD->DOUT)
always @(*) begin
if (OEN == 1) begin //input
DOUT = PAD ;
end
else begin
DOUT = 'bz ;
end
end
//use tristate gate in Verilog to realize pull up/down function
bufif1 puller(PAD, PULL[0], PULL[1]);
endmodule
testbench代码如下:
`timescale 1ns/1ns
module test ;
reg DIN, OEN ;
reg [1:0] PULL ;
wire PAD ;
wire DOUT ;
reg PAD_REG ;
assign PAD = OEN ? PAD_REG : 1'bz ; //
initial begin
PAD_REG = 1'bz ; //pad with no dirve at first
OEN = 1'b1 ; //input simulation
#0 ; PULL = 2'b10 ; //pull down
#20 ; PULL = 2'b11 ; //pull up
#20 ; PULL = 2'b00 ; //dispull
#20 ; PAD_REG = 1'b0 ;
#20 ; PAD_REG = 1'b1 ;
#30 ; OEN = 1'b0 ; //output simulation
DIN = 1'bz ;
#15 ; DIN = 1'b0 ;
#15 ; DIN = 1'b1 ;
end
pad u_pad(
.DIN (DIN) ,
.OEN (OEN) ,
.PULL (PULL) ,
.PAD (PAD) ,
.DOUT (DOUT)
);
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
仿真结果如下:

- 当 PAD 方向为 input 且没有驱动时,pull 功能能通过 PAD 的值而体现。
- 前 60ns 内,PAD 的驱动端 PAD_REG 为 z, 可认为没有驱动,所以开始时 PULL=2, 下拉,PAD值为 0; 20ns 时,PULL=3,上拉,PAD 值为 1;
- 40ns 时,PULL=0,没有 pull 功能,PAD 值输入为 z。
- 60ns~100ns 后,PAD 的驱动端 PAD_REG 开始正常驱动。此时相当于 PAD 直接与 PAD_REG 相连,所以 PAD 值与其驱动值保持一致。
以上分析,PAD 方向都是 input,所有输出端 DOUT 与 PAD 值保持一致。
当 PAD 方向为 output 时,即 120ns 时 OEN= 0,PAD 值与输入端 DIN 值保持一致。
5.2 Verilog 模块例化
在一个模块中引用另一个模块,对其端口进行相关连接,叫做模块例化。模块例化建立了描述的层次。信号端口可以通过位置或名称关联,端口连接也必须遵循一些规则。
命名端口连接
这种方法将需要例化的模块端口与外部信号按照其名字进行连接,端口顺序随意,可以与引用 module 的声明端口顺序不一致,只要保证端口名字与外部信号匹配即可。
下面是例化一次 1bit 全加器的例子:
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b0 : 1'b1),
.So (so_bit0),
.Co (co_temp[0]));
如果某些输出端口并不需要在外部连接,例化时 可以悬空不连接,甚至删除。一般来说,input 端口在例化时不能删除,否则编译报错,output 端口在例化时可以删除。例如:
//output 端口 Co 悬空
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b0 : 1'b1),
.So (so_bit0),
.Co ());
//output 端口 Co 删除
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b0 : 1'b1),
.So (so_bit0));
顺序端口连接
这种方法将需要例化的模块端口按照模块声明时端口的顺序与外部信号进行匹配连接,位置要严格保持一致。例如例化一次 1bit 全加器的代码可以改为:
full_adder1 u_adder1(
a[1], b[1], co_temp[0], so_bit1, co_temp[1]);
虽然代码从书写上可能会占用相对较少的空间,但代码可读性降低,也不易于调试。有时候在大型的设计中可能会有很多个端口,端口信号的顺序时不时的可能也会有所改动,此时再利用顺序端口连接进行模块例化,显然是不方便的。所以平时,建议采用命名端口方式对模块进行例化。
端口连接规则
输入端口
模块例化时,从模块外部来讲, input 端口可以连接 wire 或 reg 型变量。这与模块声明是不同的,从模块内部来讲,input 端口必须是 wire 型变量。
输出端口
模块例化时,从模块外部来讲,output 端口必须连接 wire 型变量。这与模块声明是不同的,从模块内部来讲,output 端口可以是 wire 或 reg 型变量。
输入输出端口
模块例化时,从模块外部来讲,inout 端口必须连接 wire 型变量。这与模块声明是相同的。
悬空端口
模块例化时,如果某些信号不需要与外部信号进行连接交互,我们可以将其悬空,即端口例化处保留空白即可,上述例子中有提及。
output 端口正常悬空时,我们甚至可以在例化时将其删除。
input 端口正常悬空时,悬空信号的逻辑功能表现为高阻状态(逻辑值为 z)。但是,例化时一般不能将悬空的 input 端口删除,否则编译会报错,例如:
//下述代码编译会报Warning
full_adder4 u_adder4(
.a (a),
.b (b),
.c (),
.so (so),
.co (co));
/如果模块full_adder4有input端口c,则下述代码编译是会报Error
full_adder4 u_adder4(
.a (a),
.b (b),
.so (so),
.co (co));
一般来说,建议 input 端口不要做悬空处理,无其他外部连接时赋值其常量,例如:
full_adder4 u_adder4(
.a (a),
.b (b),
.c (1'b0),
.so (so),
.co (co));
位宽匹配
当例化端口与连续信号位宽不匹配时,端口会通过无符号数的右对齐或截断方式进行匹配。
假如在模块 full_adder4 中,端口 a 和端口 b 的位宽都为 4bit,则下面代码的例化结果会导致:u_adder4.a = {2’bzz, a[1:0]}, u_adder4.b = b[3:0] 。
full_adder4 u_adder4(
.a (a[1:0]), //input a[3:0]
.b (b[5:0]), //input b[3:0]
.c (1'b0),
.so (so),
.co (co));
端口连续信号类型
连接端口的信号类型可以是,1)标识符,2)位选择,3)部分选择,4)上述类型的合并,5)用于输入端口的表达式。
当然,信号名字可以与端口名字一样,但他们的意义是不一样的,分别代表的是 2 个模块内的信号。
用 generate 进行模块例化
当例化多个相同的模块时,一个一个的手动例化会比较繁琐。用 generate 语句进行多个模块的重复例化,可大大简化程序的编写过程。
重复例化 4 个 1bit 全加器组成一个 4bit 全加器的代码如下:
module full_adder4(
input [3:0] a , //adder1
input [3:0] b , //adder2
input c , //input carry bit
output [3:0] so , //adding result
output co //output carry bit
);
wire [3:0] co_temp ;
//第一个例化模块一般格式有所差异,需要单独例化
full_adder1 u_adder0(
.Ai (a[0]),
.Bi (b[0]),
.Ci (c==1'b1 ? 1'b1 : 1'b0),
.So (so[0]),
.Co (co_temp[0]));
genvar i ;
generate
for(i=1; i<=3; i=i+1) begin: adder_gen
full_adder1 u_adder(
.Ai (a[i]),
.Bi (b[i]),
.Ci (co_temp[i-1]), //上一个全加器的溢位是下一个的进位
.So (so[i]),
.Co (co_temp[i]));
end
endgenerate
assign co = co_temp[3] ;
endmodule
testbench 如下:
`timescale 1ns/1ns
module test ;
reg [3:0] a ;
reg [3:0] b ;
//reg c ;
wire [3:0] so ;
wire co ;
//简单驱动
initial begin
a = 4'd5 ;
b = 4'd2 ;
#10 ;
a = 4'd10 ;
b = 4'd8 ;
end
full_adder4 u_adder4(
.a (a),
.b (b),
.c (1'b0), //端口可以连接常量
.so (so),
.co (co));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
仿真结果如下,可知 4bit 全加器工作正常:
层次访问
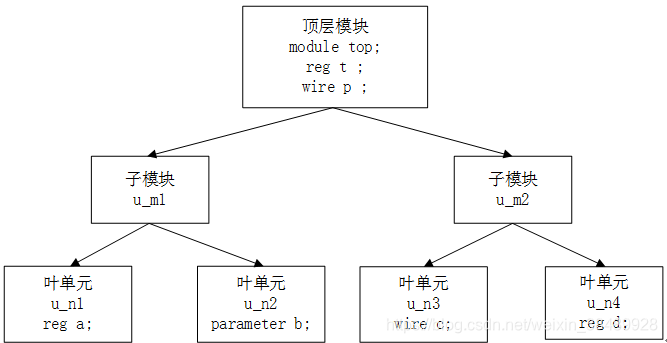
每一个例化模块的名字,每个模块的信号变量等,都使用一个特定的标识符进行定义。在整个层次设计中,每个标识符都具有唯一的位置与名字。
Verilog 中,通过使用一连串的 . 符号对各个模块的标识符进行层次分隔连接,就可以在任何地方通过指定完整的层次名对整个设计中的标识符进行访问。
层次访问多见于仿真中。
例如,有以下层次设计,则叶单元、子模块和顶层模块间的信号就可以相互访问。

//u_n1模块中访问u_n3模块信号:
a = top.u_m2.u_n3.c ;
//u_n1模块中访问top模块信号
if (top.p == 'b0) a = 1'b1 ;
//top模块中访问u_n4模块信号
assign p = top.u_m2.u_n4.d ;
5.3 Verilog 带参数例化
当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行改写。这样就允许在编译时将不同的参数传递给多个相同名字的模块,而不用单独为只有参数不同的多个模块再新建文件。
参数覆盖有 2 种方式:1)使用关键字 defparam,2)带参数值模块例化。
defparam 语句
可以用关键字 defparam 通过模块层次调用的方法,来改写低层次模块的参数值。
例如对一个单口地址线和数据线都是 4bit 宽度的 ram 模块的 MASK 参数进行改写:
//instantiation
defparam u_ram_4x4.MASK = 7 ;
ram_4x4 u_ram_4x4
(
.CLK (clk),
.A (a[4-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q) );
ram_4x4 的模型如下:
module ram_4x4
(
input CLK ,
input [4-1:0] A ,
input [4-1:0] D ,
input EN ,
input WR , //1 for write and 0 for read
output reg [4-1:0] Q );
parameter MASK = 3 ;
reg [4-1:0] mem [0:(1<<4)-1] ;
always @(posedge CLK) begin
if (EN && WR) begin
mem[A] <= D & MASK;
end
else if (EN && !WR) begin
Q <= mem[A] & MASK;
end
end
endmodule
对此进行一个简单的仿真,testbench 编写如下:
`timescale 1ns/1ns
module test ;
parameter AW = 4 ;
parameter DW = 4 ;
reg clk ;
reg [AW:0] a ;
reg [DW-1:0] d ;
reg en ;
reg wr ;
wire [DW-1:0] q ;
//clock generating
always begin
#15 ; clk = 0 ;
#15 ; clk = 1 ;
end
initial begin
a = 10 ;
d = 2 ;
en = 'b0 ;
wr = 'b0 ;
repeat(10) begin
@(negedge clk) ;
en = 1'b1;
a = a + 1 ;
wr = 1'b1 ; //write command
d = d + 1 ;
end
a = 10 ;
repeat(10) begin
@(negedge clk) ;
a = a + 1 ;
wr = 1'b0 ; //read command
end
end // initial begin
//instantiation
defparam u_ram_4x4.MASK = 7 ;
ram_4x4 u_ram_4x4
(
.CLK (clk),
.A (a[AW-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q)
);
//stop simulation
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
仿真结果如下:

图中黄色部分,当地址第一次为 c 时写入数据 4, 当第二次地址为 c 时读出数据为 4;可知此时 ram 行为正确,且 MASK 不为 3。 因为 ram 的 Q 端 bit2 没有被屏蔽。
当第一次地址为 1 时写入数据为 9,第二次地址为 1 时读出的数据却是 1,因为此时 MASK 为 7,ram 的 Q 端信号 bit3 被屏蔽。由此可知,MASK 参数被正确改写。
带参数模块例化
第二种方法就是例化模块时,将新的参数值写入模块例化语句,以此来改写原有 module 的参数值。
例如对一个地址和数据位宽都可变的 ram 模块进行带参数的模块例化:
ram #(.AW(4), .DW(4))
u_ram
(
.CLK (clk),
.A (a[AW-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q)
);
ram 模型如下:
module ram
#( parameter AW = 2 ,
parameter DW = 3 )
(
input CLK ,
input [AW-1:0] A ,
input [DW-1:0] D ,
input EN ,
input WR , //1 for write and 0 for read
output reg [DW-1:0] Q
);
reg [DW-1:0] mem [0:(1<<AW)-1] ;
always @(posedge CLK) begin
if (EN && WR) begin
mem[A] <= D ;
end
else if (EN && !WR) begin
Q <= mem[A] ;
end
end
endmodule
仿真时,只需在上一例的 testbench 中,将本次例化的模块 u_ram 覆盖掉 u_ram_4x4, 或重新添加之即可。
仿真结果如下。由图可知,ram 模块的参数 AW 与 DW 均被改写为 4, 且 ram 行为正确。
区别与建议
(1) 和模块端口实例化一样,带参数例化时,也可以不指定原有参数名字,按顺序进行参数例化,例如 u_ram 的例化可以描述为:

ram #(4, 4) u_ram (......) ;
(2) 当然,利用 defparam 也可以改写模块在端口声明时声明的参数,利用带参数例化也可以改写模块实体中声明的参数。例如 u_ram 和 u_ram_4x4 的例化分别可以描述为:
defparam u_ram.AW = 4 ;
defparam u_ram.DW = 4 ;
ram u_ram(......);
ram_4x4 #(.MASK(7)) u_ram_4x4(......);
(3) 那能不能混合使用这两种模块参数改写的方式呢?当然能!前提是所有参数都是模块在端口声明时声明的参数或参数都是模块实体中声明的参数,例如 u_ram 的声明还可以表示为(模块实体中参数可自行实验验证):
defparam u_ram.AW = 4 ;
ram #(.DW(4)) u_ram (......);
(4) 那如果一个模块中既有在模块在端口声明时声明的参数,又有在模块实体中声明的参数,那这两种参数还能同时改写么?例如在 ram 模块中加入 MASK 参数,模型如下:
module ram
#( parameter AW = 2 ,
parameter DW = 3 )
(
input CLK ,
input [AW-1:0] A ,
input [DW-1:0] D ,
input EN ,
input WR , //1 for write and 0 for read
output reg [DW-1:0] Q );
parameter MASK = 3 ;
reg [DW-1:0] mem [0:(1<<AW)-1] ;
always @(posedge CLK) begin
if (EN && WR) begin
mem[A] <= D ;
end
else if (EN && !WR) begin
Q <= mem[A] ;
end
end
endmodule
此时再用 defparam 改写参数 MASK 值时,编译报 Error:
//都采用defparam时会报Error
defparam u_ram.AW = 4 ;
defparam u_ram.DW = 4 ;
defparam u_ram.MASK = 7 ;
ram u_ram (......);
//模块实体中parameter用defparam改写也会报Error
defparam u_ram.MASK = 7 ;
ram #(.AW(4), .DW(4)) u_ram (......);
重点来了!!!如果你用带参数模块例化的方法去改写参数 MASK 的值,编译不会报错,MASK 也将被成功改写!
ram #(.AW(4), .DW(4), .MASK(7)) u_ram (......);
可能的解释为,在编译器看来,如果有模块在端口声明时的参数,那么实体中的参数将视为 localparam 类型,使用 defparam 将不能改写模块实体中声明的参数。
也可能和编译器有关系,大家也可以在其他编译器上实验。
(5)建议,对已有模块进行例化并将其相关参数进行改写时,不要采用 defparam 的方法。除了上述缺点外,defparam 一般也不可综合。
(6)而且建议,模块在编写时,如果预知将被例化且有需要改写的参数,都将这些参数写入到模块端口声明之前的地方(用关键字井号 # 表示)。这样的代码格式不仅有很好的可读性,而且方便调试。
5.4 Verilog 函数
在 Verilog 中,可以利用任务(关键字为 task)或函数(关键字为 function),将重复性的行为级设计进行提取,并在多个地方调用,来避免重复代码的多次编写,使代码更加的简洁、易懂。
函数
函数只能在模块中定义,位置任意,并在模块的任何地方引用,作用范围也局限于此模块。函数主要有以下几个特点:
- 1)不含有任何延迟、时序或时序控制逻辑
- 2)至少有一个输入变量
- 3)只有一个返回值,且没有输出
- 4)不含有非阻塞赋值语句
- 5)函数可以调用其他函数,但是不能调用任务
Verilog 函数声明格式如下:
function [range-1:0] function_id ;
input_declaration ;
other_declaration ;
procedural_statement ;
endfunction
函数在声明时,会隐式的声明一个宽度为 range、 名字为 function_id 的寄存器变量,函数的返回值通过这个变量进行传递。当该寄存器变量没有指定位宽时,默认位宽为 1。
函数通过指明函数名与输入变量进行调用。函数结束时,返回值被传递到调用处。
函数调用格式如下:
function_id(input1, input2, …);
下面用函数实现一个数据大小端转换的功能。
当输入为 4’b0011 时,输出可为 4’b1100。例如:
module endian_rvs
#(parameter N = 4)
(
input en, //enable control
input [N-1:0] a ,
output [N-1:0] b
);
reg [N-1:0] b_temp ;
always @(*) begin
if (en) begin
b_temp = data_rvs(a);
end
else begin
b_temp = 0 ;
end
end
assign b = b_temp ;
//function entity
function [N-1:0] data_rvs ;
input [N-1:0] data_in ;
parameter MASK = 32'h3 ;
integer k ;
begin
for(k=0; k<N; k=k+1) begin
data_rvs[N-k-1] = data_in[k] ;
end
end
endfunction
endmodule
函数里的参数也可以改写,例如:
defparam data_rvs.MASK = 32'd7 ;
但是仿真时发现,此种写法编译可以通过,仿真结果中,函数里的参数 MASK 实际并没有改写成功,仍然为 32’h3。这可能和编译器有关,有兴趣的学者可以用其他 Verilog 编译器进行下实验。
函数在声明时,也可以在函数名后面加一个括号,将 input 声明包起来。
例如上述大小端声明函数可以表示为:
function [N-1:0] data_rvs(
input [N-1:0] data_in
......
) ;
常数函数
常数函数是指在仿真开始之前,在编译期间就计算出结果为常数的函数。常数函数不允许访问全局变量或者调用系统函数,但是可以调用另一个常数函数。
这种函数能够用来引用复杂的值,因此可用来代替常量。
例如下面一个常量函数,可以来计算模块中地址总线的宽度:
parameter MEM_DEPTH = 256 ;
reg [logb2(MEM_DEPTH)-1: 0] addr ; //可得addr的宽度为8bit
function integer logb2;
input integer depth ;
//256为9bit,我们最终数据应该是8,所以需depth=2时提前停止循环
for(logb2=0; depth>1; logb2=logb2+1) begin
depth = depth >> 1 ;
end
endfunction
automatic 函数
在 Verilog 中,一般函数的局部变量是静态的,即函数的每次调用,函数的局部变量都会使用同一个存储空间。若某个函数在两个不同的地方同时并发的调用,那么两个函数调用行为同时对同一块地址进行操作,会导致不确定的函数结果。
Verilog 用关键字 automatic 来对函数进行说明,此类函数在调用时是可以自动分配新的内存空间的,也可以理解为是可递归的。因此,automatic 函数中声明的局部变量不能通过层次命名进行访问,但是 automatic 函数本身可以通过层次名进行调用。
下面用 automatic 函数,实现阶乘计算:
wire [31:0] results3 = factorial(4);
function automatic integer factorial ;
input integer data ;
integer i ;
begin
factorial = (data>=2)? data * factorial(data-1) : 1 ;
end
endfunction // factorial
下面是加关键字 automatic 和不加关键字 automatic 的仿真结果。
由图可知,信号 results3 得到了我们想要的结果,即 4 的阶乘。
而信号 results_noauto 值为 1,不是可预知的正常结果,这里不再做无用分析。

5.5 Verilog 任务
任务与函数的区别
和函数一样,任务(task)可以用来描述共同的代码段,并在模块内任意位置被调用,让代码更加的直观易读。函数一般用于组合逻辑的各种转换和计算,而任务更像一个过程,不仅能完成函数的功能,还可以包含时序控制逻辑。下面对任务与函数的区别进行概括:
| 比较点 | 函数 | 任务 |
|---|---|---|
| 输入 | 函数至少有一个输入,端口声明不能包含 inout 型 | 任务可以没有或者有多个输入,且端口声明可以为 inout 型 |
| 输出 | 函数没有输出 | 任务可以没有或者有多个输出 |
| 返回值 | 函数至少有一个返回值 | 任务没有返回值 |
| 仿真时刻 | 函数总在零时刻就开始执行 | 任务可以在非零时刻执行 |
| 时序逻辑 | 函数不能包含任何时序控制逻辑 | 任务不能出现 always 语句,但可以包含其他时序控制,如延时语句 |
| 调用 | 函数只能调用函数,不能调用任务 | 任务可以调用函数和任务 |
| 书写规范 | 函数不能单独作为一条语句出现,只能放在赋值语言的右端 | 任务可以作为一条单独的语句出现语句块中 |
任务
任务声明
任务在模块中任意位置定义,并在模块内任意位置引用,作用范围也局限于此模块。
模块内子程序出现下面任意一个条件时,则必须使用任务而不能使用函数。
- 1)子程序中包含时序控制逻辑,例如延迟,事件控制等
- 2)没有输入变量
- 3)没有输出或输出端的数量大于 1
Verilog 任务声明格式如下:
task task_id ;
port_declaration ;
procedural_statement ;
endtask
任务中使用关键字 input、output 和 inout 对端口进行声明。input 、inout 型端口将变量从任务外部传递到内部,output、inout 型端口将任务执行完毕时的结果传回到外部。
进行任务的逻辑设计时,可以把 input 声明的端口变量看做 wire 型,把 output 声明的端口变量看做 reg 型。但是不需要用 reg 对 output 端口再次说明。
对 output 信号赋值时也不要用关键字 assign。为避免时序错乱,建议 output 信号采用阻塞赋值。
例如,一个带延时的异或功能 task 描述如下:
task xor_oper_iner;
input [N-1:0] numa;
input [N-1:0] numb;
output [N-1:0] numco ;
//output reg [N-1:0] numco ; //无需再注明 reg 类型,虽然注明也可能没错
#3 numco = numa ^ numb ;
//assign #3 numco = numa ^ numb ; //不用assign,因为输出默认是reg
endtask
任务在声明时,也可以在任务名后面加一个括号,将端口声明包起来。
上述设计可以更改为:
task xor_oper_iner(
input [N-1:0] numa,
input [N-1:0] numb,
output [N-1:0] numco ) ;
#3 numco = numa ^ numb ;
endtask
任务调用
任务可单独作为一条语句出现在 initial 或 always 块中,调用格式如下:
task_id(input1, input2, …,outpu1, output2, …);
任务调用时,端口必须按顺序对应。
输入端连接的模块内信号可以是 wire 型,也可以是 reg 型。输出端连接的模块内信号要求一定是 reg 型,这点需要注意。
对上述异或功能的 task 进行一个调用,完成对异或结果的缓存。
module xor_oper
#(parameter N = 4)
(
input clk ,
input rstn ,
input [N-1:0] a ,
input [N-1:0] b ,
output [N-1:0] co );
reg [N-1:0] co_t ;
always @(*) begin //任务调用
xor_oper_iner(a, b, co_t);
end
reg [N-1:0] co_r ;
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
co_r <= 'b0 ;
end
else begin
co_r <= co_t ; //数据缓存
end
end
assign co = co_r ;
/*------------ task -------*/
task xor_oper_iner;
input [N-1:0] numa;
input [N-1:0] numb;
output [N-1:0] numco ;
#3 numco = numa ^ numb ; //阻塞赋值,易于控制时序
endtask
endmodule
对上述异或功能设计进行简单的仿真,testbench 描述如下。
激励部分我们使用简单的 task 进行描述,激励看起来就更加的清晰简洁。
其实,task 最多的应用场景还是应用于 testbench 中进行仿真。task 在一些编译器中也不支持综合。
`timescale 1ns/1ns
module test ;
reg clk, rstn ;
initial begin
rstn = 0 ;
#8 rstn = 1 ;
forever begin
clk = 0 ; # 5;
clk = 1 ; # 5;
end
end
reg [3:0] a, b;
wire [3:0] co ;
initial begin
a = 0 ;
b = 0 ;
sig_input(4'b1111, 4'b1001, a, b);
sig_input(4'b0110, 4'b1001, a, b);
sig_input(4'b1000, 4'b1001, a, b);
end
task sig_input ;
input [3:0] a ;
input [3:0] b ;
output [3:0] ao ;
output [3:0] bo ;
@(posedge clk) ;
ao = a ;
bo = b ;
endtask ; // sig_input
xor_oper u_xor_oper
(
.clk (clk ),
.rstn (rstn ),
.a (a ),
.b (b ),
.co (co ));
initial begin
forever begin
#100;
if ($time >= 1000) $finish ;
end
end
endmodule // test
仿真结果如下。
由图可知,异或输出逻辑结果正确,相对于输入有 3ns 的延迟。
且连接信号 a,b,co_t 与任务内部定义的信号 numa,numb,numco 状态也保持一致。

任务操作全局变量
因为任务可以看做是过程性赋值,所以任务的 output 端信号返回时间是在任务中所有语句执行完毕之后。
任务内部变量也只有在任务中可见,如果想具体观察任务中对变量的操作过程,需要将观察的变量声明在模块之内、任务之外,可谓之"全局变量"。
例如有以下 2 种尝试利用 task 产生时钟的描述方式。
//way1 to decirbe clk generating, not work
task clk_rvs_iner ;
output clk_no_rvs ;
# 5 ; clk_no_rvs = 0 ;
# 5 ; clk_no_rvs = 1 ;
endtask
reg clk_test1 ;
always clk_rvs_iner(clk_test1);
//way2: use task to operate global varialbes to generating clk
reg clk_test2 ;
task clk_rvs_global ;
# 5 ; clk_test2 = 0 ;
# 5 ; clk_test2 = 1 ;
endtask // clk_rvs_iner
always clk_rvs_global;
仿真结果如下:
第一种描述方式,虽然任务内部变量会有赋值 0 和赋值 1 的过程操作,但中间变化过程并不可见,最后输出的结果只能是任务内所有语句执行完毕后输出端信号的最终值。所以信号 clk_test1 值恒为 1,此种方式产生不了时钟。
第二种描述方式,虽然没有端口信号,但是直接对"全局变量"进行过程操作,因为该全局变量对模块是可见的,所以任务内信号翻转的过程会在信号 clk_test2 中体现出来。

automatic 任务
和函数一样,Verilog 中任务调用时的局部变量都是静态的。可以用关键字 automatic 来对任务进行声明,那么任务调用时各存储空间就可以动态分配,每个调用的任务都各自独立的对自己独有的地址空间进行操作,而不影响多个相同任务调用时的并发执行。
如果一任务代码段被 2 处及以上调用,一定要用关键字 automatic 声明。
当没有使用 automatic 声明任务时,任务被 2 次调用,可能出现信号间干扰,例如下面代码描述:
task test_flag ;
input [3:0] cnti ;
input en ;
output [3:0] cnto ;
if (en) cnto = cnti ;
endtask
reg en_cnt ;
reg [3:0] cnt_temp ;
initial begin
en_cnt = 1 ;
cnt_temp = 0 ;
#25 ; en_cnt = 0 ;
end
always #10 cnt_temp = cnt_temp + 1 ;
reg [3:0] cnt1, cnt2 ;
always @(posedge clk) test_flag(2, en_cnt, cnt1); //task(1)
always @(posedge clk) test_flag(cnt_temp, !en_cnt, cnt2);//task(2)
仿真结果如下:
en_cnt 为高时,任务 (1) 中信号 en 有效, cnt1 能输出正确的逻辑值;
此时任务 (2) 中信号 en 是不使能的,所以 cnt2 的值被任务 (1) 驱动的共用变量 cnt_temp 覆盖。
en_cnt 为低时,任务 (2) 中信号 en 有效,所以任务 (2) 中的信号 cnt2 能输出正确的逻辑值;而此时信号 cnt1 的值在时钟的驱动下,一次次被任务 (2) 驱动的共用变量 cnt_temp 覆盖。
可见,任务在两次并发调用中,共用存储空间,导致信号相互间产生了影响。
其他描述不变,只在上述 task 声明时加入关键字 automatic,如下所以。

task automatic test_flag ;
此时仿真结果如下:
en_cnt 为高时,任务 (1) 中信号 cnt1 能输出正确的逻辑值,任务 (2) 中信号 cnt2 的值为 X;
en_cnt 为低时,任务 (2) 中信号 cnt2 能输出正确的逻辑值,任务 (1) 中信号 cnt1 的值为 X;
可见,任务在两次并发调用中,因为存储空间相互独立,信号间并没有产生影响。
