
来源:一个数据人的自留地 作者:鲸歌
如果说在数据海洋里我是一艘乘风破浪的舰艇,那么明确的职业目标就是航行的方向,统计学业务思维等知识则是船体严密的构造,而Excel和Python等工具的使用就是航行的动力。不同于前面2篇文章,今天会结合统计学的内容,重点讲述如何使用Excel进行实操,在实操的过程中会伴随着思路的校正与发散统一。
首先,我们需要明确数据分析的步骤,没有条理的秩序,很容易在海量数据中陷入一团乱麻中。
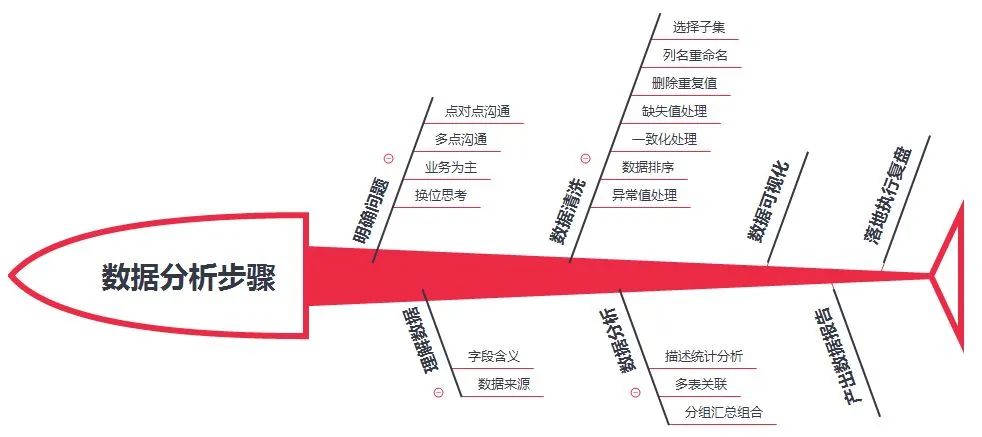
其次,请让我根据以上步骤来描述我是如何用Excel进行探索性分析的?本期以前4个步骤为主(明确问题、理解数据、数据清洗和数据分析,其余请关注后续推送)。
本期实操报表:淘宝和天猫上购买婴儿用户的交易明细表、用户信息表;
数据来源于:https://tianchi.aliyun.com/dataset/dataDetail?dataId=45
01
明确问题
在手头拿到数据后,不要着急做清洗和分析,而是先根据掌握的信息进行脑暴,通过这份数据我们能大体确定些什么问题,可以通过脑图(比如Xmind)在罗列的诸多猜想后,根据重要性进行排序。
为什么要怎么做?古话云:磨刀不误砍柴工,先把问题了解清楚,有利于后期的分析,而不是贸贸然上手,花费了诸多功夫,到头来悲凉地发现得出的结论与要分析的方向南辕北辙。
根据已有信息,可假设如下需验证的问题:

02
理解数据
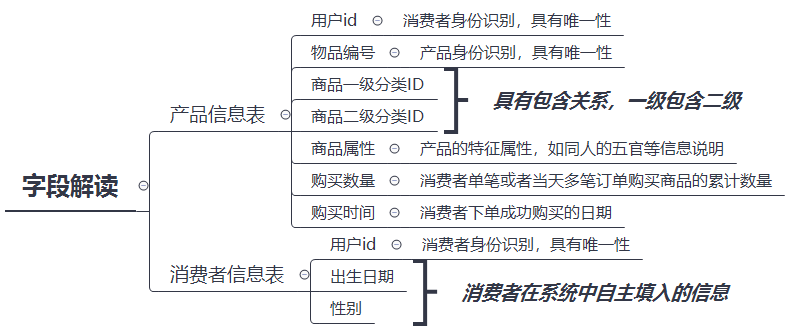
网上有一个说法让我印象深刻,将”理解数据”比作炒菜前准备的“葱蒜姜末”等佐料,对于数据分析这道大餐,表格中的不同字段,其背后的含义要能理解清楚,否则就是菜不对味儿。
03
清洗数据
切记:数据清洗不要在原始表格上直接处理,可以复制表格再生成一份,防止原始数据被破坏,影响工作效率。
选择子集:可以遵循二八原则,面对众多字段要有取舍,选择核心的字段
以产品信息表为例:7个字段中,商品属性初步来看分析价值不大,可隐藏,后面可视具体情况如有用再取消隐藏

列名重命名:一般从数据库导出的数据字段名可能是英文的,那么可以切换到中文,方便自己和他人了解

转化为:

缺失值处理:容易忘记的一个环节,尤其是遇到大量级的数据,一定要检查一下,可以使用countblank()函数,补全的4个方法:缺失值较少可手动补齐、删除、数值的话采用平均值代替和通过统计模型算出的值进行替代。
本文使用的2张报表中的产品信息表的【产品属性】有缺,但此列已隐藏,故不作补充。
一致化处理:将表格中不规范数据进行批量处理,2张表中的日期数据需要处理成正确可计算的日期型数据,可以先用len()+left/mid/right()+find()函数进行组合,本例中的数据比较齐整,也可以采用分列来拆分,具体使用以实际情况为准。

异常值处理:与缺失值一样,不可遗漏,对于输入性的数据值尤其是要检查,消费者信息表中【性别】和【出生日期】作为重点排查对象,使用vlookup()将2张表格进行互联,通过【购买日期】和【出生日期】相减除以365取整得到年龄,再对【年龄】进行排序会发现有”28”这个异常值,通过与其他值对比,可以推测原因是出生日期填写的是父母,排查出的异常值可剔除。
04
数据分析
在分析版块中,我重点采用了Excel的【数据透视表】、【数据分析】中的【描述统计】和Vlookup()函数,具体详见如下:
产品信息表的分析思路:在对一级类目进行基础汇总统计时发现不同类目之间的销量差异明显,对该表的销量进行描述统计发现极值差悬殊,在此基础上针对销量这一列进行分组产生新的字段【订单类型】,由此结合一级类目、订单类型和购买日期3个维度组合分析(注:购买数量默认统一为当天单笔订单)。
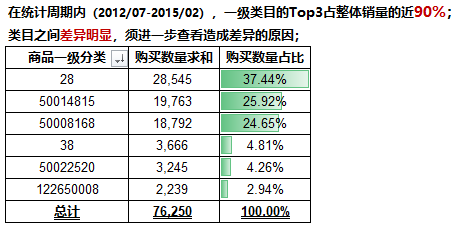
提取整体销量和6个一级大类的分别对应销量,使用【数据分析】中的【描述统计】,返回结果如下(共3列,后2列选取标准差最低和最高的2个一级大类):
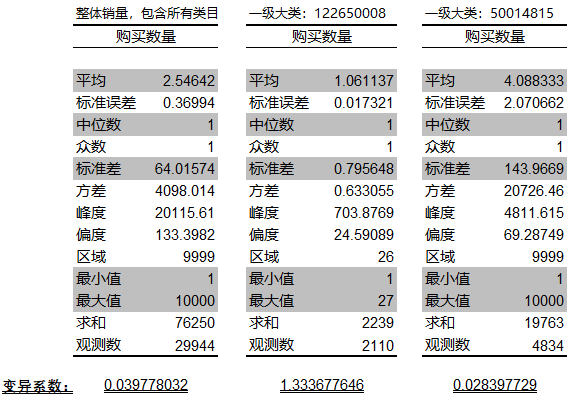
由上可得,不同类目间的销量存在波动,可以初步推断类目之间的差异与各大类之间的销量波动密切相关。
使用Vlookup()模糊匹配进行分组,根据电商业务场景,存在批发订单的可能,5个以内为个人常规订单范畴,6个及以上都算作批发订单,再根据实际购买数量分成:小、中及大批量,具体见如下截图:

通过对订单分类进行透视统计,数据及发现如下:
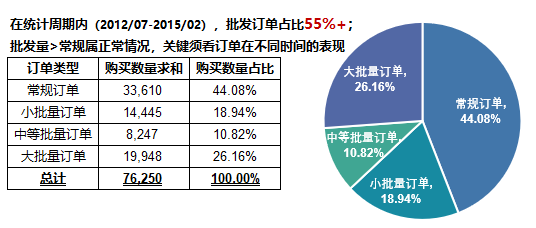
再看订单类型与一级大类的关系:
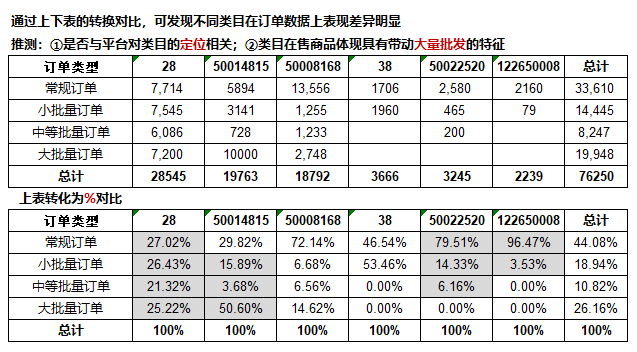
根据上表是否可以推测目前平台的发展侧重点在于大批量订单的引导?
初步论证如下:
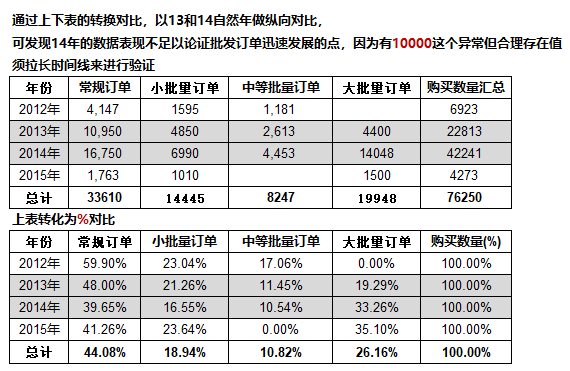
如果剔除10000这个值会发现,常规订单在14年还处于上升状态,占比达到52%;
结合一级类目和13/14自然年组合分析:可发现在14年,“5004815”一级类目赶超13年排名第一的“28”成为14年Top1,且对比两年的发展速度,“5004815”增长达到300%,“5008168”增长近200%。
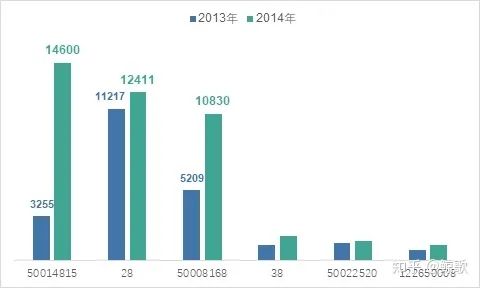
根据上图,进一步深挖,可发现:“5004815”还是与那10000的订单相关,排除10000这个值来看,14年的各大类整体销售依然达到141%的增速,Top3中“28”增速较缓。
用户信息表的分析思路:相对于产品信息表,用户的数据量较少,算是产品的一个小样本,在使用Vlookup()进行多表关联后,在拼接字段后,根据用户ID的唯一性可以分为2张表:其一不含交易信息(字段包括:用户ID、购买日期、性别、出生日期、年龄和年龄分类)不具有重复值,另一张则包含交易信息(在Vlookup产品信息表时会发现复购的交易记录),根据年龄新增字段“年龄分类”,通过年龄分类、性别、用户ID及购买数量进行多维分析。
因考虑文章篇幅较长,这部分分析简略呈现,具体可看后续推送:
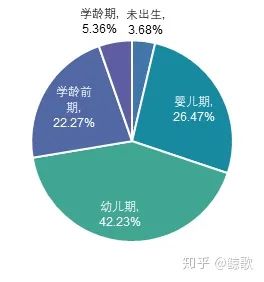
结合下面2图,可得宝宝年龄集中在0-6岁,占比达到90%,女性宝宝占比略高于男性宝宝。
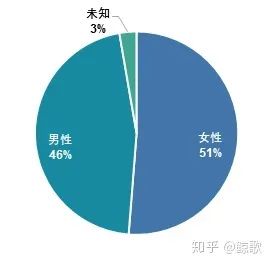
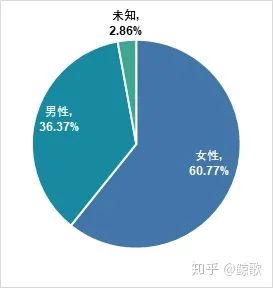
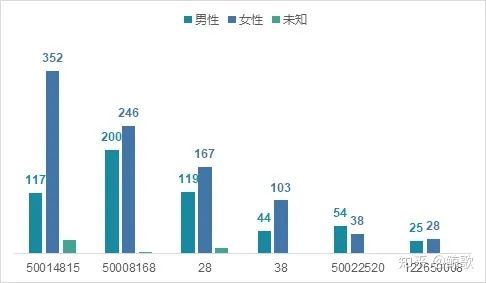
下图是添加了”购买数量”这一字段,可以发现在男女宝宝人数占比相近的前提下,女宝宝的销量将近是男宝宝的2倍,可见女宝宝的消费需求更强劲。
根据上图,再进一步分析男女宝宝在各一级大类的选择上呈现出什么样的特征,由下图可知,Top1的“50014815”说明女宝宝是消费者主力贡献者,可推测该大类主打女宝宝的产品,紧随其后的第二和第三,男女宝宝的产品受欢迎程度差距没有Top1那么明显,但相较而言女宝宝占比更高。
最后,对前4步进行小结,纵观以上的图表更多是对数据的解读和推测,并未根据数据提供下一步的落地建议,且在分析上思维相对狭隘,后期会更进一步调整优化。面对数据需保持好奇心,能够由挖到的一点再进一步的下钻,达到剥丝抽茧的程度。