前提
- hbase的物理模型是master和regionserver,regionserver存储的是region,region里边很有很多store,一个store对应一个列簇,一个store中有一个memstore和多个storefile,store的底层是hfile,hfile是hadoop的二进制文件,其中HFile和HLog是hbase两大文件存储格式,HFile用于存储数据,HLog保证可以写入到HFile中;
- kudu的物理模型是master和tserver,其中table根据hash和range分区,分为多个tablet存储到tserver中,tablet分为leader和follower,leader负责写请求,follower负责读请求,总结来说,一个ts可以服务多个tablet,一个tablet可以被多个ts服务(基于tablet的分区,最低为2个分区);
联系
- 1、设计理念和想法是一致的;
- 2、kudu的思想是基于hbase的,之前cloudera公司向对hbase改造,支持大数据量更新,可是由于改动源码太大,所以todd直接开发了kudu;
- 3、hbase基于rowkey查询和kudu基于主键查询是很快的;
整体架构
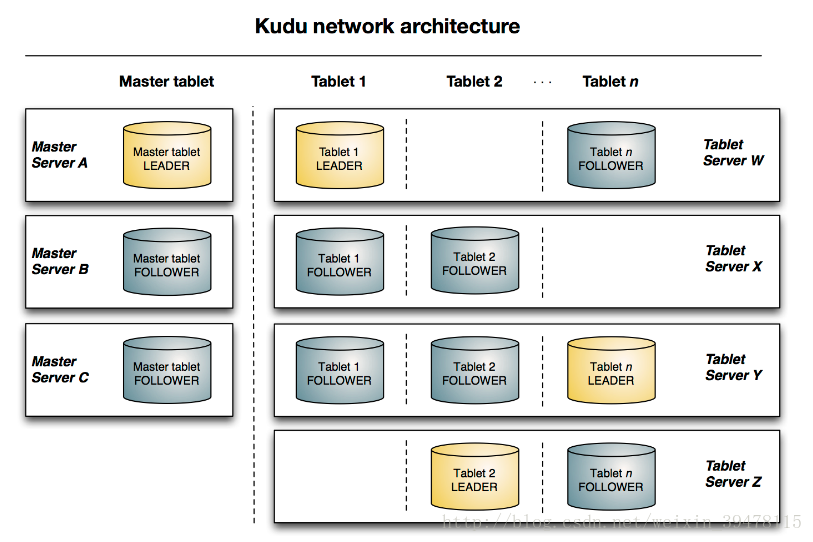
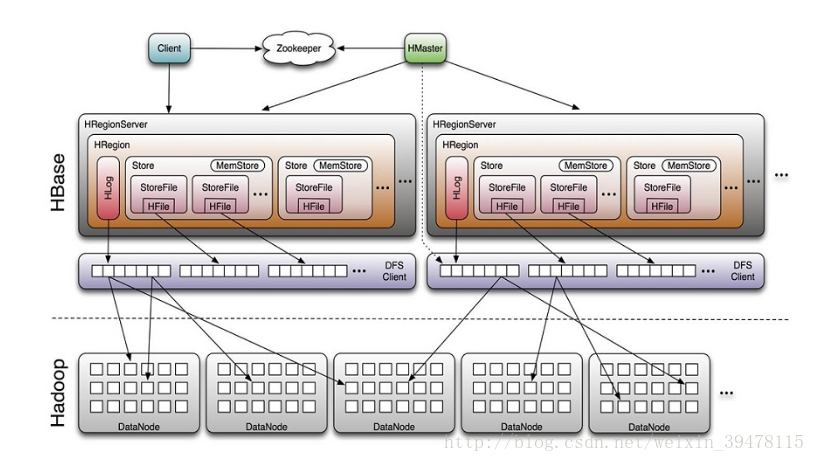
Kudu结构看上去跟HBase差别并不大,主要的区别包括:
Kudu将HBase中zookeeper的功能放进了TMaster内,Kudu中TMaster的功能比HBase中的Master任务要多一些,kudu所有集群的配置信息均存储在本地磁盘中,hbase的集群配置信息是存储在zookeeper中;
Hbase将数据持久化这部分的功能交给了Hadoop中的HDFS,最终组织的数据存储在HDFS上。Kudu自己将存储模块集成在自己的结构中,内部的数据存储模块通过Raft协议来保证leader Tablet和replica Tablet内数据的强一致性,和数据的高可靠性。为什么不像HBase一样利用HDFS来实现数据存储,所以Kudu自己重新完成了底层的数据存储模块,并将其集成在TServer中,但是kudu对磁盘的IO要求很高,它是以写的性能换取读的性能;
数据存储方式
- HBase是面向列族式的存储,每个列族都是分别存放的,HBase表设计时,很少使用设计多个列族,大多情况下是一个列族。这个时候的HBase的存储结构已经与行式存储无太大差别了。而Kudu,实现的是一个真正的面向列的存储方式,表中的每一列都是单独存放的;所以HBase与Kudu的差异主要在于类似于行式存储的列族式存储方式与典型的面向列式的存储方式的差异;
- HBase是一款NoSQL类型的数据库,对表的设计主要在于rowkey与列族的设计,列的类型可以不指定,因为HBase在实际存储中都会将所有的value字段转换成二进制的字节流。因为不需要指定类型,所以在插入数据的时候可以任意指定列名(列限定名),这样相当于可以在建表之后动态改变表的结构。Kudu因为选择了列式存储,为了更好的提高列式存储的效果,Kudu要求在建表时指定每一列的类型,这样的做法是为了根据每一列的类型设置合适的编码方式,实现更高的数据压缩比,进而降低数据读入时的IO压力;
- HBase对每一个cell数据中加入了timestamp字段,这样能够实现记录同一rowkey和列名的多版本数据,另外HBase将数据更新操作、删除操作也是作为一条数据写入,通过timestamp来标记更新时间,type来区分数据是插入、更新还是删除。HBase写入或者更新数据时可以指定timestamp,这样的设置可以完成某些特定的操作;
Kudu也在数据存储中加入了timestamp这个字段,不像HBase可以直接在插入或者更新数据时设置特殊的timestamp值,Kudu的做法是由Kudu内部来控制timestamp的写入。不过Kudu允许在scan的时候设置timestamp参数,使得客户端可以scan到历史数据; - 相对于HBase允许多版本的数据存在,Kudu为了提高批量读取数据时的效率,要求设计表时提供一列或者多列组成一个主键,主键唯一,不允许多个相同主键的数据存在。这样的设置下,Kudu不能像HBase一样将更新操作直接转换成插入一条新版本的数据,Kudu的选择是将写入的数据,更新操作分开存储;
- 当然还有一些其他的行式存储与列式存储之间在不同应用场景下的性能差异。
- hbase中,同一个主键数据是可以存在多个storefile里的,为了让mutation和磁盘的存在的key组合在一起,hbase需要基于rowkey执行merge。Rowkey可以是任意长度的字符串,因此对比rowkey是非常耗性能的。另外,在一个查询中,即使key列没有被使用(例如聚合计算),它们也要被读取出来,这导致了额外的IO。复合主键在hbase应用中很常见,主键的大小可能比你关注的列大一个数量级,特别是查询的列被压缩的情况下;
kudu中,读取一条数据或者执行非排序查询,不需要merge操作。例如,聚合一定范围内的key可以独立的查询每个RowSet(甚至可以并行的),然后执行求和,因为key的顺序是不重要的,显然查询的效率更高,kudu中,mutation是与rowid绑定的。所以merge会更加高效,通过维护计数器的方式,给定下一个需要保存的mutation,我们可以简单的相减,就可以得到从base data到当前版本有多少个mutation。或者,直接寻址可以用来高效的获取最新版本的数据。获取block也非常的高效,因为mutation直接指向了block的索引地址; - hbase的系统中,每个cell的timstamp都是暴露给用户的,本质上组成了这个cell的一个符合主键。意味着,这种方式可以高效的直接访问指定版本的cell,且它存储了一个cell的整个时间序列的所有版本;
而Kudu却不高效(需要执行多个mutation),它的timestamp是从MVCC实现而来的,它不是主键的另外一个描述; - hbase采用的LSM(LogStructured Merge,很难对数据进行特殊编码,所以处理效率不高),hbase会将多条更新记录先后Flush到不同的Storefile中,所以读取时需要扫描多个文件,比较rowkey,比较版本等,然后进行更新操作,特别是major compaction操作的时候,会占用大量的性能;
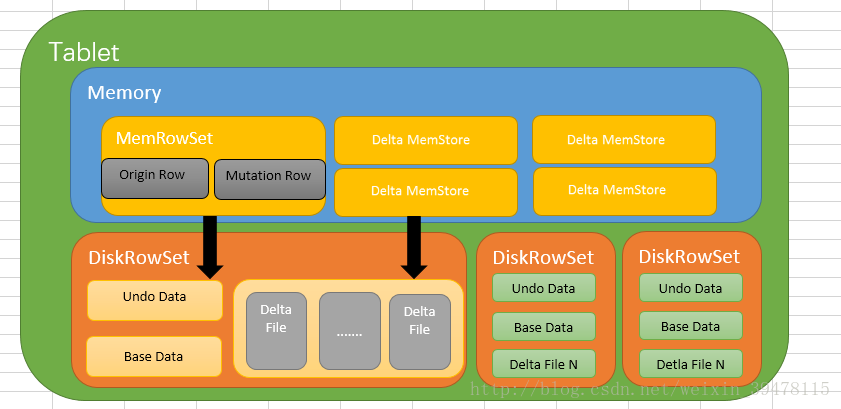
Kudu对同一行的数据更新记录的合并工作,不是在查询的时候发生的,而是在更新的时候进行,在Kudu中一行数据只会存在于一个DiskRowSet中,避免读操作时的比较合并工作。对于列式存储的数据文件,要原地变更一行数据是很困难的,所以在Kudu中,对于Flush到磁盘上的DiskRowSet(DRS)数据,实际上是分两种形式存在的,一种是Base的数据,按列式存储格式存在,一旦生成,就不再修改,另一种是Delta文件,存储Base数据中有变更的数据,一个Base文件可以对应多个Delta文件(Kudu用MVCC(多版本并发控制)来实现数据的删改功能。更新、删除操作需要记录到特殊的数据结构里,保存在内存中的DeltaMemStore或磁盘上的DeltaFIle里面。DeltaMemStore是B-Tree实现的,因此速度快,而且可修改。磁盘上的DeltaFIle是二进制的列式的块,和base数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的DeltaFiles文件,Kudu借鉴了Hbase的方式,会定期对这些文件进行合并),这种方式意味着,插入数据时相比HBase,需要额外走一次检索流程来判定对应主键的数据是否已经存在。因此,Kudu是牺牲了写性能来换取读取性能的提升。另外,如果在查询中没有指定key,那执行计划就不会查阅key,除了需要确定key边界情况; - hbase中insert和mutation是相同的操作,直接存储到storefile中。
kudu中insert和mutation是不同的操作:insert写入数据至MemRowSet,而mutation(delete、update)写入存在这条数据的RowSet的DeltaMemStore里,写入时必须确定这是一条新数据。这会产生一个bloom filter查询所有RowSet。如果布隆过滤器得到一个可能的match(即计算出可能在一个RowSet里),接着为了确定是否是insert还是update,一个寻址就必须被执行。 假设,只要RowSet足够小,bloom filter的结果就会足够精确,那么大部分插入将不需要物理磁盘寻址。另外,如果插入的key是有序的,例如timeseries+“_”+xxx,由于频繁使用,key所在的block可能会被保存在数据块缓存中。Update时,需要确定key在哪个RowSet。与上雷同,需要执行bloom filter。 这有点类似于关系型数据库RDBMS,当插入一条主键存在的数据时会报错,且不会更新这条数据。类似的,更新一条数据时,如果这条数据不存在也会报错。hbase的语法却不是这样,它不存在主键的概念;
写入和读取过程
写过程
- HBase写的时候,不管是新插入一条数据还是更新数据,都当作插入一条新数据来进行;而Kudu将插入新数据与更新操作分别看待;
- Kudu表结构中必须设置一个唯一键,插入数据的时候必须判断一些该数据的主键是否唯一,所以插入的时候其实有一个读的过程;而HBase没有太多限制,待插入数据将直接写进memstore;
- HBase实现数据可靠性是通过将落盘的数据写入HDFS来实现,而Kudu是通过将数据写入和更新操作同步在其他副本上实现数据可靠性;
- 结合以上几点,可以看出Kudu在写的性能上相对HBase有一定的劣势;
读过程
- 在HBase中,读取的数据可能有多个版本,所以需要结合多个storefile进行查询;Kudu数据只可能存在于一个DiskRowset或者MemRowset中,但是因为可能存在还未合并进原数据的更新,所以Kudu也需要结合多个DeltaFile进行查询;
- HBase写入或者更新时可以指定timestamp,导致storefile之间timestamp范围的规律性降低,增加了实际查询storefile的数量;Kudu不允许人为指定写入或者更新时的timestamp值,DeltaFile之间timestamp连续,可以更快的找到需要的DeltaFile;
- HBase通过timestamp值可以直接取出数据;而Kudu实现多版本是通过保留UNDO records(已经合并过的操作)和REDO records(未合并过的操作)完成的,在一些情况下Kudu需要将base data结合UNDO records进行回滚或者结合REDO records进行合并然后才能得到真正所需要的数据;
- 结合以上三点可以得出,不管是HBase还是Kudu,在读取一条数据时都需要从多个文件中搜寻相关信息。相对于HBase,Kudu选择将插入数据和更新操作分开,一条数据只可能存在于一个DiskRowset或者memRowset中,只需要搜寻到一个rowset中存在指定数据就不用继续往下找了,用户不能设置更新和插入时的timestamp值,减少了在rowset中DeltaFile的读取数量。这样在scan的情况下可以结合列式存储的优点实现较高的读性能,特别是在更新数量较少的情况下能够有效提高scan性能;
- 另外,本文在描述HBase读写过程中没有考虑读写中使用的优化技术如Bloomfilter、timestamp range等。其实Kudu中也有使用类似的优化技术来提高读写性能,本文只是简单的分析,因此就不再详细讨论读写过程;
其他差异
- HBase:使用的java,内存的释放通过GC来完成,在内存比较紧张时可能引发full GC进而导致服务不稳定;
- Kudu:核心模块用的C++来实现,没有full gc的风险;
总结
- Kudu通过要求完整的表结构设置,主键的设定,以列式存储作为数据在磁盘上的组织方式,更新和数据分开等技巧,使得Kudu能够实现像HBase一样实现数据的随机读写之外,在HBase不太擅长的批量数据扫描(scan)具有较好的性能。而批量读数据正是olap型应用所关注的重点,正如Kudu官网主页上描述的,Kudu实现的是既可以实现数据的快速插入与实时更新,也可以实现数据的快速分析。Kudu的定位不是取代HBase,而是以降低写的性能为代价,提高了批量读的性能,使其能够实现快速在线分析。