这个模型的系列代码阅读我总结了两万多字,算是比较详尽了。为什么要写这么多?除了我自己记性差,还有个原因是“Video Object Detection”方向的可供参考的Pytorch代码非常少,大多数发表的文章都不会开源。
而MEGA模型的作者不但开源了基于maskrcnn-bentchmark编写的十分规范的MEGA模型,还额外实现了FGFA、RDN等模型,对于像我一样编程能力比较差的小白来说我觉得这是非常有价值的资源。我希望自己学习的过程能帮助到更多像我一样科研比较困难的同学。希望后来者能少走点弯路,真的科研太难了55
贤鱼现在有公众号啦,回复“mega1”获得本文内容pdf,有多级标题的标签,结构更清晰~还有我后期重新修改、总结的内容,质量更高
转载请注明出处
知乎没有缩进:(
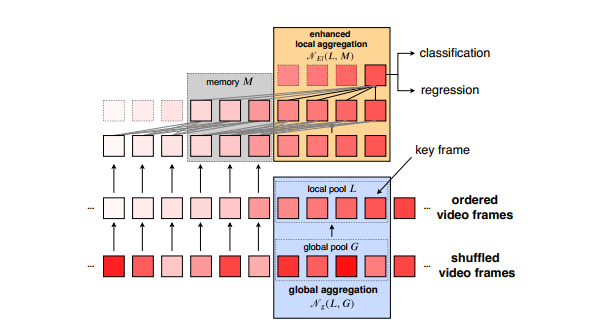
MEGA论文题目:Memory Enhanced Global-Local Aggregation for Video Object Detection
论文:
https://arxiv.org/abs/2003.12063arxiv.org代码:
https://github.com/Scalsol/mega.pytorchgithub.comMEGA的代码基于maskrcnn-bentchmark,我觉得读明白了对自己修改或者使用更新的Detectron2开发都有好处,所以写了这个系列的文章。希望对大家也有所帮助~
数据集
视频数据 VID_train_15frames.txt ——>每个视频中只取15帧
VIDDataset类:
列表:image_set_index(帧所在视频文件名/frame_seg_id)、frame_id(train中没用,test中就是frame_seg_id+1因此也没用)、frame_seg_id(该帧在所在视频中的序号)、frame_seg_len(该帧所在视频被截取的总帧数)
x[0]=..... x[1]=1 x[2]=10 x[3]=300
train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 10 300
train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 30 300
train/ILSVRC2015_VID_train_0000/ILSVRC2015_train_00000000 1 50 300
image_set:指定的某数据集名称
det_vid:image_set的前缀,有可能是VID, DET, coco, VOC
pattern:仅有视频数据集有这个属性,因为视频数据集imageset有大于2个属性,那时候给该类添加了pattern属性
这个pattern实际应该就是用来取当前帧的参考帧的名字的,它保证来自同一个视频文件夹
keep:如果是训练集,通过filter_annotation()检查每一帧是否有目标,没有目标的keep为false,该帧被弃用。keep信息会被保存。
classes_to_ind:字典,每个类的一个字符串特殊编号映射到index
categories:字典,每个类的index映射到类的字符串名称
data_dir指定数据文件夹,其下会生成cache文件夹存放缓存文件
该类中_get_train() _get_test()没太大实际意义,就是取一张图,关键看子类如何重写
VIDFGFADataset类(FGFA模型的数据集):
_C.MODEL.VID.FGFA.MIN_OFFSET = -9
_C.MODEL.VID.FGFA.MAX_OFFSET = 9
_C.MODEL.VID.FGFA.ALL_FRAME_INTERVAL = 19(总的抽选参考帧的范围大小)
_C.MODEL.VID.FGFA.KEY_FRAME_LOCATION = 9(关键帧位置,当前帧?)
_C.MODEL.VID.FGFA.REF_NUM = 2 (局部参考帧数量)
start_index(测试集用)保存每个视频序列第一帧在所有帧中的总的id,根据训练集frame_seg_id==0判断
_get_train():
对于视频数据集,在当前的帧的邻域抽取指定数量的参考帧,参数都在前面大写字母设定中。
返回的target就是真值,只有当前帧的(参考帧的真值本身也没有读取)
返回的images是字典,"cur""ref"分别对应当前帧、多个参考帧的列表
_get_test():
frame_category:某个视频序列的第一帧是0,其他都是1
ref_id(测试集只用一个参考帧):取当前帧id+MAX_OFFSET(不是必须最后一帧为参考帧)(如果超过frame_seg_len那就取当前帧最后一个frame)
返回的target也是当前帧真值
返回的images除了跟训练集一样的以外,还有"frame_category""seg_len""pattern""img_dir""transforms"
VIDMEGADataset类(MEGA模型的数据集):
_C.MODEL.VID.MEGA.MIN_OFFSET = -12
_C.MODEL.VID.MEGA.MAX_OFFSET = 12
_C.MODEL.VID.MEGA.ALL_FRAME_INTERVAL = 25
_C.MODEL.VID.MEGA.KEY_FRAME_LOCATION = 12
_C.MODEL.VID.MEGA.MEMORY.ENABLE = True
_C.MODEL.VID.MEGA.MEMORY.SIZE = 25
_C.MODEL.VID.MEGA.GLOBAL.RES_STAGE = 1
_C.MODEL.VID.MEGA.GLOBAL.ENABLE = True
_C.MODEL.VID.MEGA.GLOBAL.SIZE = 10
_C.MODEL.VID.MEGA.GLOBAL.SHUFFLE = True
_C.MODEL.VID.MEGA.REF_NUM_LOCAL = 2(实际使用的局部帧的数量)
_C.MODEL.VID.MEGA.REF_NUM_MEM = 3(实际使用memory中帧的数量)
_C.MODEL.VID.MEGA.REF_NUM_GLOBAL = 2(实际使用的全局帧的数量)
_C.MODEL.VID.MEGA.RATIO = 0.2
构造函数中跟FGFA的一样,相比父类仅多了对于测试集的处理:
start_index:仅保存每个视频序列第一帧在所有帧中的总的id,根据训练集frame_seg_id==0判断
start_id:不同于前一个变量仅保存第一帧id,该变量保存当前帧所在视频的第一帧的id(存的量更多而已)
shuffled_index:专门应对需要全局帧的情况。该变量值为当前测试集的所有
帧的id的np.arrange(一共frame_seg_len个)。一般是需要shuffle的,应该是用于取当前帧全局帧
_get_train():
对于视频数据集:(对于图片数据集,以下所有的参考帧全都是当前帧的复制...)
img_refs_l(局部帧):在当前的帧的邻域抽取指定数量的参考帧,参数都在前面大写字母设定中。
img_refs_m(memory帧,看代码实际只是稍远一点的临近帧):
ref_id_center:当前帧总的id-ALL_FRAME_INTERVAL (选择memory帧时选择的中心帧位置,默认是当前帧前面第25帧)
跟添加局部帧一样,只是中心帧位置变了,然后取的img数量变了
img_refs_g(全局帧):从当前帧所在视频的所有帧中随机抽取指定数量的帧
返回当前帧的target,以及字典images(包含"cur""ref_l""ref_m""ref_g")
_get_test():
仍然是测试的时候用的帧远少于训练
frame_category:某个视频序列的第一帧是0,其他都是1
img_refs_l:列表但仅一帧,测试集只用当前领域最后一帧作为局部帧(类似FGFA的一张参考帧)
img_refs_g:全局帧,从构造函数的shuffled_index抽取(视频第一帧抽REF_NUM_GLOBAL个,普通帧只抽1个)
测试仅在视频数据集上进行,且【测试时没有memory帧!!!】
返回当前帧的target,以及字典images(包含"cur""ref_l""ref_g""frame_category""seg_len""pattern""img_dir""transforms")
模型大框架
GeneralizedRCNNFGFA类:(frame-level的特征聚合)
backbone、flownet、embednet?、rpn、roi_heads
all_frame_interval(设定中的19)、key_frame_location(设定中的9)
【images 和 features 队列】(设定长度为all_frame_interval)——>真正用到这个队列的好像就是测试,训练时不需要额外存储,需要什么帧直接读取
get_grid(self, flow):根据光流计算一个flow_grid,利用它可以把一个特征对齐到当前帧
resample(self, feats, flow):调用前一个函数,根据光流warp输入的feats,实现对齐
compute_weight(self, embed_ref, embed_cur):
根据当前帧和临近参考帧的归一化嵌入,通过内积(元素乘再求和)计算权重weight
_forward_train:
当前帧和参考帧先连接起来(batch维度)通过backbone提取特征 concat_feats
当前帧复制和参考帧同样的数量(batch维度),分别和参考帧再连接(通道维度),然后通过flownet得到光流
连接的特征在(batch维度)分开为当前帧的和参考帧的特征:feats_cur, feats_refs
通过光流把参考帧特征 feats_refs 对齐到当前帧,得到 warped_feats_refs(用resample函数)
对齐的参考帧特征再次与当前帧的特征连接(batch维度),得到新的 concat_feats
用新的 concat_feats计算当前帧、参考帧特征的嵌入(embednet)
根据嵌入计算参考帧特征 warped_feats_refs 的权重,并将其乘以权重后在batch维度(第一个维度)上加和得到 feats
rpn网络计算出 proposals 和 proposal_losses (self.rpn(img, feats, targets) 这里感觉有问题,不使用当前帧特征..)
roi_heads网络得到最终检测结果:x, result, detector_losses = self.roi_heads(feats, proposals, targets)
_forward_test(self, imgs, infos, targets=None):
首先定义了 update_feature 函数,用于更新 images 和 features 队列 中存储的 img、feats、embeds
end_id:队列中最后一帧的id
对于新的视频的第一帧(infos["frame_category"] == 0):
重新建立该类的【 images 和 features 队列】(设定长度为all_frame_interval)
计算当前帧的backbone特征feats_cur、相应嵌入embeds_cur
由于是新视频第一帧,end_id重置为0
由于是第一帧,所以两个队列先填充第一帧相应数据 key_frame_location + 1个(刚好过一半),
队列剩下的空位由第二帧及之后的帧的数据填满,同时end_id更新成为队列最后一帧的id(这样做就能立马预测第一帧,否则没有相邻帧数据)
(好像有点问题的是,SSVD中到了视频最后一帧也得专门处理直到所有帧都预测了,但这里好像没写?
后来觉得没问题,原因在于队列是通过当前帧的最后一张参考帧不断添加更新的,这个在dataset类里就确定了不会超过当前帧视频最后一帧)
对于不是视频第一帧的普通帧:
end_id 更新为+1或者是最后一帧,infos["ref"][0] (根据VIDFGFADataset,
这恰好就是当前帧作为key_frame时邻域队列中最后一帧)作为最后一帧填充进images队列
以上的步骤首先把【 images 和 features 队列】填充满了或者更新好了
后续步骤类似训练,但是有两点区别:
embeds不用embednet计算,而是直接从backbone计算的特征中通道维度分离一部分出来
训练时只在领域抽取 REF_NUM = 2 帧作为参考帧,而测试时使用整个邻域的参考帧(18),这肯定会很慢
GeneralizedRCNNMEGA类:
backbone、rpn、roi_heads
base_num:VID.RPN.REF_POST_NMS_TOP_N=75
advanced_num:base_num * VID.MEGA.RATIO(0.2)=15
all_frame_interval(设定中的25)、key_frame_location(设定中的12)
_forward_train:
1.memory:【proposals_m_list】【feats_m_list】
图片在batch维度连接,通过backbone计算特征
对每一张memory中帧都通过rpn预测proposal并将 proposal[0](应该就是对应第一层特征上的proposal) 保存到 proposals_m_list (【注意】rpn用的ref版本,无loss)
2.local:【proposals,proposal_losses,proposals_l_list】【feats_g_list(第一个是当前帧的)】
这里把当前帧放在第一张,跟局部参考帧 imgs_l 都在batch维度连接了起来,然后计算基本的特征,之后再分离开
对于 当前帧 使用 【key版本的rpn】预测了proposals并且计算了proposal_losses
另外,包括当前帧在内的临近帧又使用【ref 版本的rpn】预测了proposals并且把 proposal[0] 保存到 proposals_l_list
3.global:【proposals_g_list】【feats_g_list】
同memory
以上步骤得到了三种proposals与features(frame-level),再放在一个列表中:
feats_list = [feats_l_list, feats_m_list, feats_g_list]
proposals_list = [proposals, proposals_l_list, proposals_m_list, proposals_g_list]
将两个list与targets送入 roi_heads 即可得到当前帧检测结果以及检测器的loss
_forward_test:
如果遇到新视频第一帧,初始化该类的【五种deque属性】(FGFA中是两个),它们每个长度都是all_frame_interval(邻域范围大小,设定=25):
feats:backbone提取的第一层特征
proposals:除了当前帧是所有的proposal,其他参考帧只考虑与feats对应的第一层上的proposal
proposals_dis:前一队列proposals中存的前 advanced_num(15)个proposals
proposals_feat:某一帧所有proposal(所有层)从feats上提取到的部分特征 (用roi_heads.box.feature_extractor)
proposals_feat_dis:前一个变量的前 advanced_num(15)个
还初始化了指示当前视频帧总数的seg_len、指示当前邻域最后一帧在该视频中的id end_id=0
self.roi_heads.box.feature_extractor.init_memory() roi_heads.box.feature_extractor.init_global() 这两个目前不清楚,不过感觉就是memory和global初始化
后面FGFA类似的:
对当前帧通过backbone提取一层特征 feats_cur,通过 rpn(ref 版本) 预测 proposals_cur,通过roi_heads.box.feature_extractor 提取 proposals_feat_cur (与FGFA的frame级别的特征融合不同)
然后就是对于第一帧,相应的先把【五个队列】填充好,跟FGFA做法一样
不是第一帧的普通帧:就更新一下【五个队列】就行(根据最新的end_id)
其实以上都是在处理【五个队列】,它们就是邻域特征等信息的存储器
接着是对每张全局帧:
提取backbone特征、proposals(ref版本rpn)、proposals_feat,然后关键是用 proposals_feat 去更新 roi_heads.box.feature_extractor (全局记忆好像在那里,使用update_global方法)
然后是专门再搞一遍当前帧,用 feats = self.feats[self.key_frame_location] 取出backbone特征,然后专门通过key版本的rpn得到 proposals
最后用roi_heads检测:
self.roi_heads(feats, proposals_list, None)
其中 proposals_list = [proposals, proposals_ref, proposals_ref_dis, proposals_feat_ref, proposals_feat_ref_dis],很奇怪的是feats仅是当前帧的(直观上和train不一样)
注意,全局信息已经更新在roi_heads内部了,test时不用memory
MEGA 总的来说:训练靠抽取local、memory、global帧;测试一直维持邻域信息的队列、global信息融入roi_heads、不使用memory