https://github.com/ivipsourcecode/dxslam
编译过程跟orbslam类似。
git clone https://github.com/raulmur/DXSLAM.git DXSLAM
安装库,Opencv 推荐3.4版本就可以了;Eigen3 去官网源码编译即可,Pangolin 这是个毒瘤
编译出错大多是因为Pangolin的版本有问题,会报一堆Glew的错误,所以一定要找Orbslam2的Pangolin版本来编译,GitHub里什么0.6、0.5版本的Pangolin全都会报错!!!编译过不了
cd dxslam
chmod +x build.sh
./build.sh
它的build.sh脚本写的不太好,如果第一次没编译通过,会报model和dxslam的东西已经下载过而中断编译,所以我改了一下
#!/bin/bash -e
echo "Configuring and building Thirdparty/cnpy ..."
cd Thirdparty/cnpy
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j8
echo "configuring and building Thirdparty/fbow"
cd ../../fbow
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j8
echo "configuring and building Thirdparty/Dbow2"
cd ../../DBoW2
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j8
cd ../../g2o
echo "Configuring and building Thirdparty/g2o ..."
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j
cd ../../../
if [ ! -d Vocabulary ]; then
echo "Download and Uncompress vocabulary ..."
mkdir Vocabulary
cd Vocabulary
wget https://github.com/ivipsourcecode/dxslam/releases/download/1.0.0/DXSLAM.tar.xz
tar -xf *.tar.xz
cd ..
else
echo "dir exist"
fi
cd hf-net
if [ ! -e model.tar.xz ]; then
wget https://github.com/ivipsourcecode/dxslam/releases/download/1.0.0/model.tar.xz
tar -xf *.tar.xz
cd ..
else
echo "dir exist"
cd ..
fi
echo "Configuring and building DXSLAM ..."
mkdir -p build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
make -j
如果编译通过了,那么接下来就要下载TUM Dataset
Computer Vision Group - Dataset Download
我下载的是fr1/xyz 大概0.47gb左右,里面结构如下:

接着就要安装tensorflow了,这也是个坑,千万不要用conda装!
//创建conda环境
conda create -n tf python=3.6
//激活环境
conda activate tf
//安装tensorflow
pip3 install tensorflow=1.13.1
//安装opencv,它默认装4.3xx版本 用到的api没改动,所以无所谓
pip3 install opencv-python
//一般默认会装上numpy 不过还是装一下 万一呢
pip3 install numpy
我的目录如下:
(tf) liqunzhao@DESKTOP-DT3VKG6:~/dxslam$ tree -L 2
.
├── CMakeLists.txt
├── CameraTrajectory.txt
├── Dependencies.md
├── Examples
│ └── RGB-D
├── KeyFrameTrajectory.txt
├── LICENSE.txt
├── License-gpl.txt
├── README.md
├── Thirdparty
│ ├── DBoW2
│ ├── cnpy
│ ├── fbow
│ └── g2o
├── Vocabulary
│ ├── DXSLAM.fbow
│ └── DXSLAM.tar.xz
├── associate.py
├── associations.txt
├── build
│ ├── CMakeCache.txt
│ ├── CMakeFiles
│ ├── Makefile
│ ├── cmake_install.cmake
│ └── compile_commands.json
├── build.sh
├── cmake_modules
│ └── FindEigen3.cmake
├── hf-net
│ ├── features
│ ├── getFeature.py
│ ├── model
│ └── model.tar.xz
├── include
│ ├── Converter.h
│ ├── Frame.h
│ ├── FrameDrawer.h
│ ├── Initializer.h
│ ├── KeyFrame.h
│ ├── KeyFrameDatabase.h
│ ├── LocalMapping.h
│ ├── LoopClosing.h
│ ├── Map.h
│ ├── MapDrawer.h
│ ├── MapPoint.h
│ ├── Matcher.h
│ ├── Optimizer.h
│ ├── PnPsolver.h
│ ├── Sim3Solver.h
│ ├── System.h
│ ├── Tracking.h
│ ├── Viewer.h
│ └── Vocabulary.h
├── lib
│ └── libDXSLAM.so
├── readnpytool.py
├── rgbd_dataset_freiburg1_xyz
│ ├── accelerometer.txt
│ ├── depth
│ ├── depth.txt
│ ├── groundtruth.txt
│ ├── rgb
│ └── rgb.txt
└── src
├── Converter.cc
├── Frame.cc
├── FrameDrawer.cc
├── Initializer.cc
├── KeyFrame.cc
├── KeyFrameDatabase.cc
├── LocalMapping.cc
├── LoopClosing.cc
├── Map.cc
├── MapDrawer.cc
├── MapPoint.cc
├── Matcher.cc
├── Optimizer.cc
├── PnPsolver.cc
├── Sim3Solver.cc
├── System.cc
├── Tracking.cc
└── Viewer.cc
20 directories, 62 files现在一切就绪,环境已经搭完了
还需要下载两个文件 associate.py和TUM1.yaml 我放在这里给大家
#!/usr/bin/python
# Software License Agreement (BSD License)
#
# Copyright (c) 2013, Juergen Sturm, TUM
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
#
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above
# copyright notice, this list of conditions and the following
# disclaimer in the documentation and/or other materials provided
# with the distribution.
# * Neither the name of TUM nor the names of its
# contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
# COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
# POSSIBILITY OF SUCH DAMAGE.
#
# Requirements:
# sudo apt-get install python-argparse
"""
The Kinect provides the color and depth images in an un-synchronized way. This means that the set of time stamps from the color images do not intersect with those of the depth images. Therefore, we need some way of associating color images to depth images.
For this purpose, you can use the ''associate.py'' script. It reads the time stamps from the rgb.txt file and the depth.txt file, and joins them by finding the best matches.
"""
"""
运动相机提供的RGB图和深度图是不同步的,这就意味着大量RGB图的时间戳和深度图的时间戳不匹配
我们需要把RGB图和深度图通过某种方式联系在一起。associate.py脚本读取RGB和DEPTH的时间戳,并将二者最佳的时候匹配在一起
"""
import argparse
import sys
import os
import numpy
def read_file_list(filename):
"""
Reads a trajectory from a text file.
File format:
The file format is "stamp d1 d2 d3 ...", where stamp denotes the time stamp (to be matched)
and "d1 d2 d3.." is arbitary data (e.g., a 3D position and 3D orientation) associated to this timestamp.
Input:
filename -- File name
Output:
dict -- dictionary of (stamp,data) tuples
"""
file = open(filename)
data = file.read()
lines = data.replace(","," ").replace("\t"," ").split("\n")
list = [[v.strip() for v in line.split(" ") if v.strip()!=""] for line in lines if len(line)>0 and line[0]!="#"]
list = [(float(l[0]),l[1:]) for l in list if len(l)>1]
return dict(list)
def associate(first_list, second_list,offset,max_difference):
"""
Associate two dictionaries of (stamp,data). As the time stamps never match exactly, we aim
to find the closest match for every input tuple.
Input:
first_list -- first dictionary of (stamp,data) tuples
second_list -- second dictionary of (stamp,data) tuples
offset -- time offset between both dictionaries (e.g., to model the delay between the sensors)
max_difference -- search radius for candidate generation
Output:
matches -- list of matched tuples ((stamp1,data1),(stamp2,data2))
"""
first_keys = list(first_list)
second_keys = list(second_list)
potential_matches = [(abs(a - (b + offset)), a, b)
for a in first_keys
for b in second_keys
if abs(a - (b + offset)) < max_difference]
potential_matches.sort()
matches = []
for diff, a, b in potential_matches:
if a in first_keys and b in second_keys:
first_keys.remove(a)
second_keys.remove(b)
matches.append((a, b))
matches.sort()
return matches
if __name__ == '__main__':
# parse command line
parser = argparse.ArgumentParser(description='''
This script takes two data files with timestamps and associates them
''')
parser.add_argument('first_file', help='first text file (format: timestamp data)')
parser.add_argument('second_file', help='second text file (format: timestamp data)')
parser.add_argument('--first_only', help='only output associated lines from first file', action='store_true')
parser.add_argument('--offset', help='time offset added to the timestamps of the second file (default: 0.0)',default=0.0)
parser.add_argument('--max_difference', help='maximally allowed time difference for matching entries (default: 0.02)',default=0.02)
args = parser.parse_args()
first_list = read_file_list(args.first_file)
second_list = read_file_list(args.second_file)
matches = associate(first_list, second_list,float(args.offset),float(args.max_difference))
if args.first_only:
for a,b in matches:
print("%f %s"%(a," ".join(first_list[a])))
else:
for a,b in matches:
print("%f %s %f %s"%(a," ".join(first_list[a]),b-float(args.offset)," ".join(second_list[b])))
%YAML:1.0
#--------------------------------------------------------------------------------------------
# Camera Parameters. Adjust them!
#--------------------------------------------------------------------------------------------
# Camera calibration and distortion parameters (OpenCV)
Camera.fx: 517.306408
Camera.fy: 516.469215
Camera.cx: 318.643040
Camera.cy: 255.313989
Camera.k1: 0.262383
Camera.k2: -0.953104
Camera.p1: -0.005358
Camera.p2: 0.002628
Camera.k3: 1.163314
# Camera frames per second
Camera.fps: 30.0
# Color order of the images (0: BGR, 1: RGB. It is ignored if images are grayscale)
Camera.RGB: 1
#--------------------------------------------------------------------------------------------
# ORB Parameters
#--------------------------------------------------------------------------------------------
# ORB Extractor: Number of features per image
ORBextractor.nFeatures: 1000
# ORB Extractor: Scale factor between levels in the scale pyramid
ORBextractor.scaleFactor: 1.2
# ORB Extractor: Number of levels in the scale pyramid
ORBextractor.nLevels: 8
# ORB Extractor: Fast threshold
# Image is divided in a grid. At each cell FAST are extracted imposing a minimum response.
# Firstly we impose iniThFAST. If no corners are detected we impose a lower value minThFAST
# You can lower these values if your images have low contrast
ORBextractor.iniThFAST: 20
ORBextractor.minThFAST: 7
#--------------------------------------------------------------------------------------------
# Viewer Parameters
#--------------------------------------------------------------------------------------------
Viewer.KeyFrameSize: 0.05
Viewer.KeyFrameLineWidth: 1
Viewer.GraphLineWidth: 0.9
Viewer.PointSize:2
Viewer.CameraSize: 0.08
Viewer.CameraLineWidth: 3
Viewer.ViewpointX: 0
Viewer.ViewpointY: -0.7
Viewer.ViewpointZ: -1.8
Viewer.ViewpointF: 500
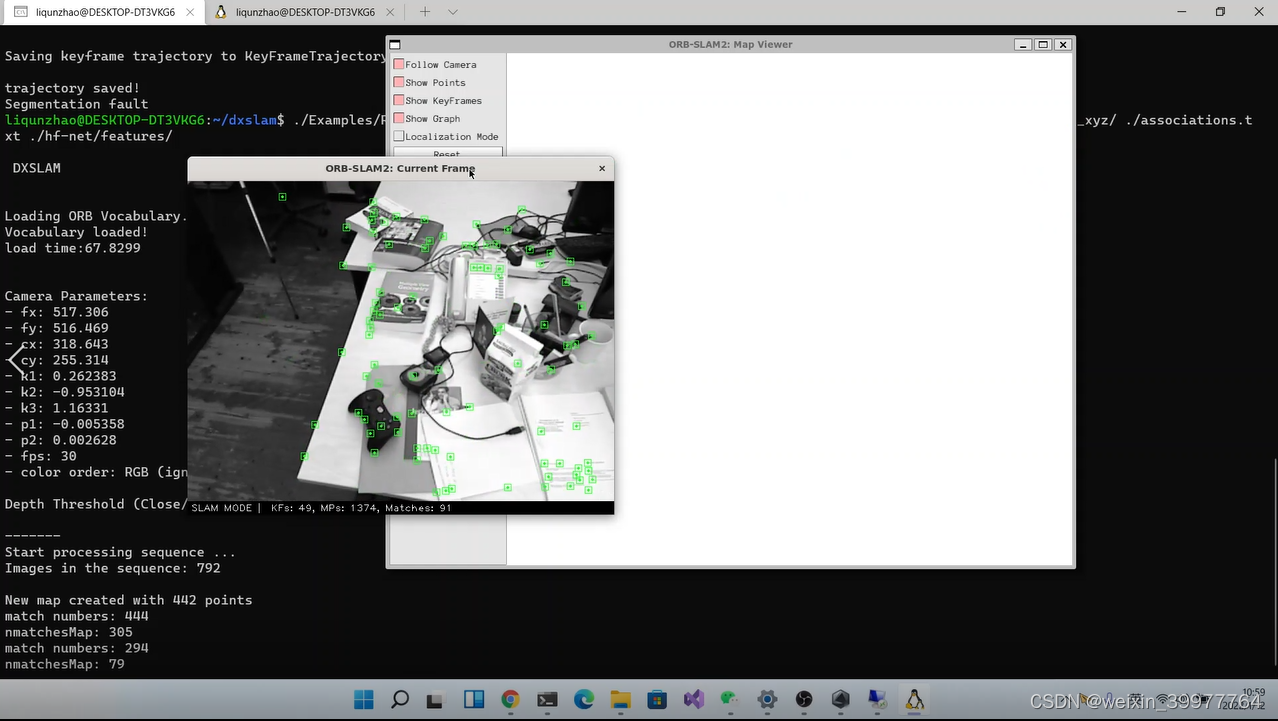
OK 现在开始运行
由于是OFFLINE的,所以它的关联RGB&DEPTH和提取特征点还有运行slam是分离开的
python associate.py PATH_TO_SEQUENCE/rgb.txt PATH_TO_SEQUENCE/depth.txt > associations.txt
//按我的目录就是这样
python associate.py ./rgbd_dataset_freiburg1_xyz/rgb.txt ./rgbd_dataset_freiburg1_xyz/depth.txt > associations.txtcd hf-net
python3 getFeature.py image/path/to/rgb output/feature/path
//按我的目录是这样子
cd hf-net
python3 getFeature.py ../rgbd_dataset_freiburg1_xyz ./features其中 features目录下保存的是通过网络输出后的特征点信息,存在矩阵里
./Examples/RGB-D/rgbd_tum Vocabulary/DXSLAM.fbow Examples/RGB-D/TUMX.yaml PATH_TO_SEQUENCE_FOLDER ASSOCIATIONS_FILE OUTPUT/FEATURE/PATH
//按我的目录就是这样
./Examples/RGB-D/rgbd_tum Vocabulary/DXSLAM.fbow ./Examples/RGB-D/TUM1.yaml ./rgbd_dataset_freiburg1_xyz associations.txt ./hf-net/features最后的结果: