说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。
1.项目背景
随着深度学习技术的快速发展,卷积神经网络(Convolutional Neural Network, CNN)在图像识别、物体检测等多个领域取得了显著的成功。然而,随着数据规模的不断扩大以及模型复杂度的提高,如何高效地训练这些模型成为了研究者面临的一个重要挑战。传统的方法通常依赖于梯度下降及其变种来寻找最优解,但是这些方法往往容易陷入局部最优,并且对于超参数的选择非常敏感。
粒子群优化算法(Particle Swarm Optimization, PSO)是一种基于群体智能的全局优化算法,它通过模拟鸟类觅食的行为来搜索最优解。PSO算法具有简单易实现、需要调整的参数少等优点,因此在许多优化问题中得到了广泛的应用。但是,标准的PSO算法在处理高维、大规模的问题时仍然存在收敛速度慢、易于早熟等问题。
为了解决上述问题,本项目提出了一种基于随机分布式延迟的粒子群优化算法(Randomly Distributed Delay Particle Swarm Optimization, RODDPSO),用于优化CNN模型的训练过程。RODDPSO通过引入随机延迟机制,使得粒子更新的速度更加灵活,有助于跳出局部最优解,同时采用分布式计算的方式加快了搜索速度,提高了优化效率。此外,该算法还能够更好地适应不同规模的数据集和复杂的模型结构。
本项目通过Python实现随机分布式延迟PSO优化算法(RODDPSO)优化CNN分类模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因变量 |
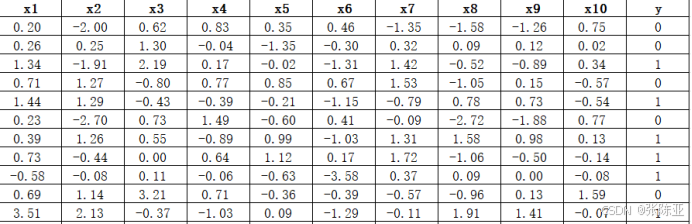
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
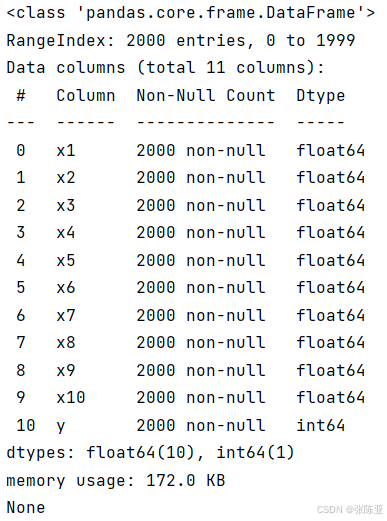
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
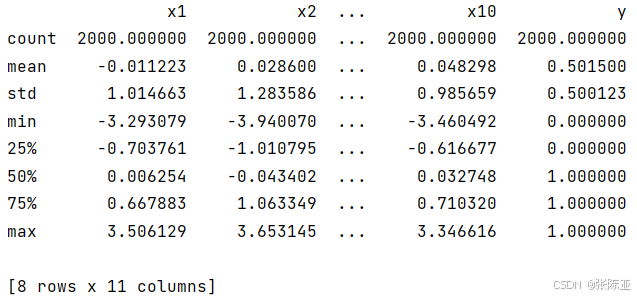
关键代码如下:

4.探索性数据分析
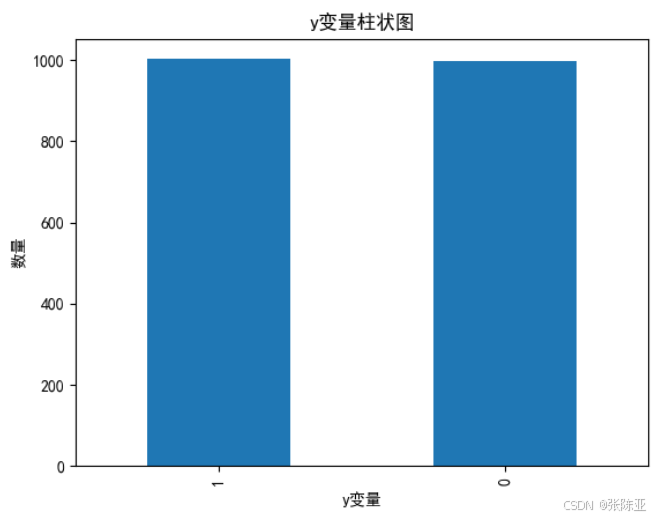
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
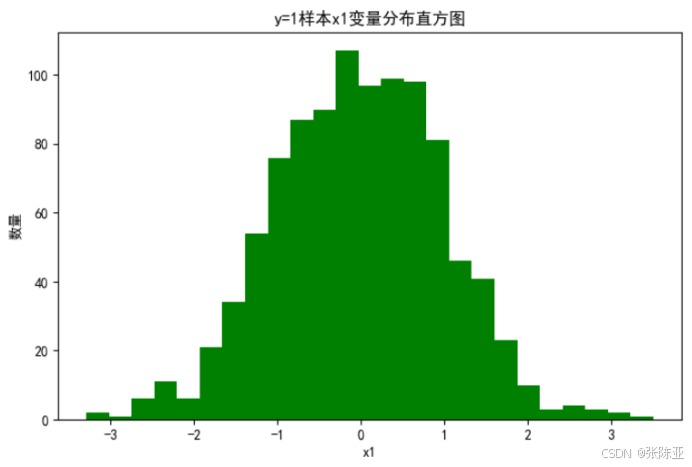
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
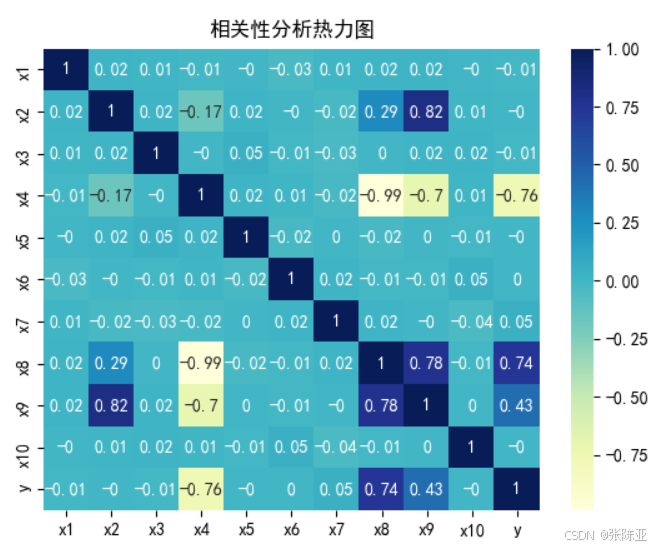
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

5.3 特征样本增维
特征增维后的形状如下:

6.构建随机分布式延迟PSO优化算法优化CNN分类模型
主要通过随机分布式延迟PSO优化算法优化CNN分类模型算法,用于目标分类。
6.1 寻找最优参数值
最优参数值:

6.2 最优参数构建模型
| 模型名称 | 模型参数 |
| CNN分类模型 | units=best_units |
| epochs=best_epochs |
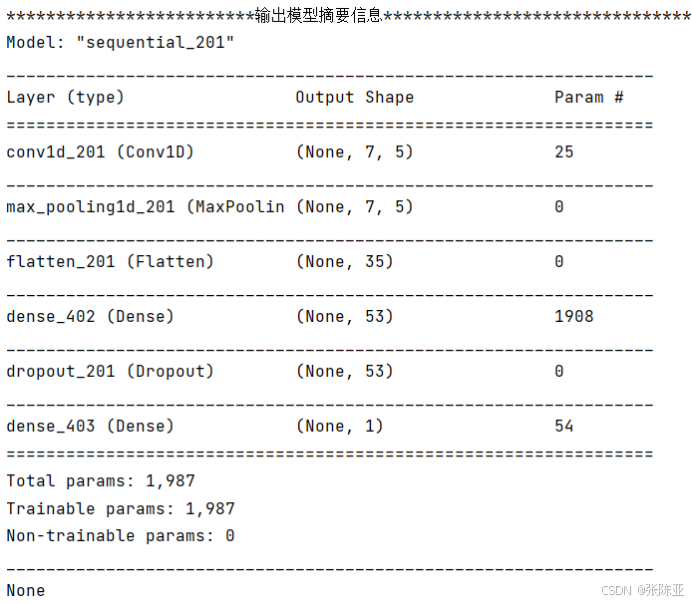
6.3 模型摘要信息
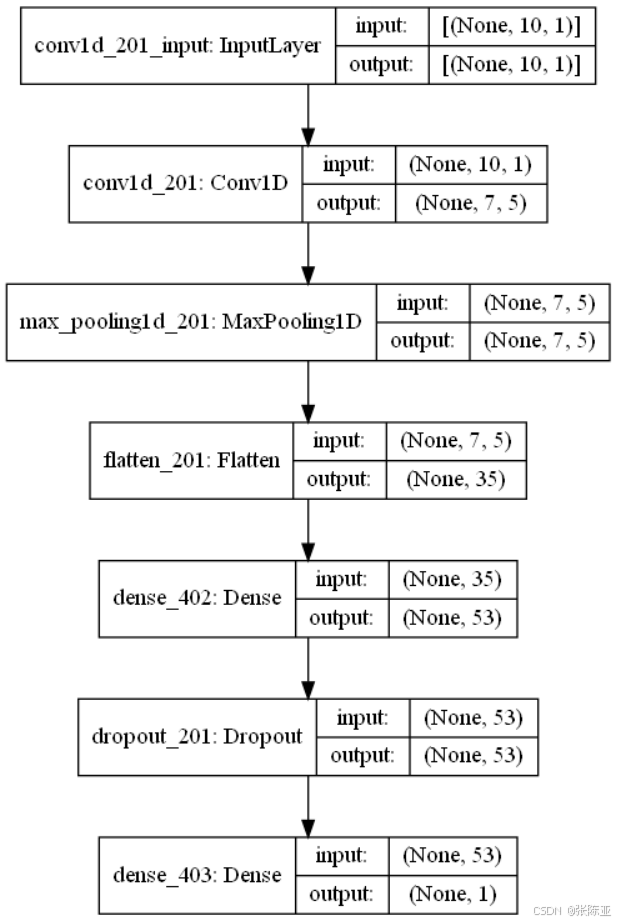
6.4 模型网络结构
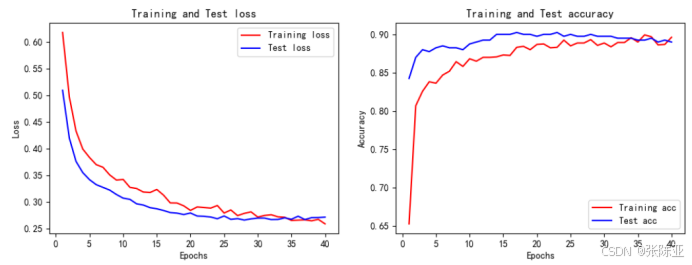
6.5 模型训练集测试集准确率和损失曲线图
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| CNN分类模型 | 准确率 | 0.8900 |
| 查准率 | 0.9096 | |
| 查全率 | 0.8636 | |
| F1分值 | 0.886 | |
从上表可以看出,F1分值为0.886,说明随机分布式延迟PSO粒子群优化算法优化的CNN模型效果良好。
关键代码如下:

7.2 分类报告
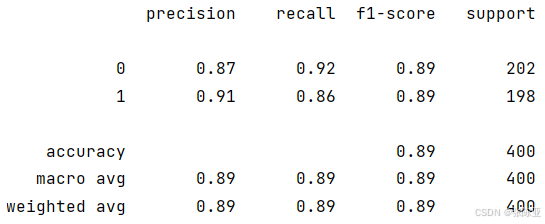
从上图可以看出,分类为0的F1分值为0.89;分类为1的F1分值为0.89。
7.3 混淆矩阵
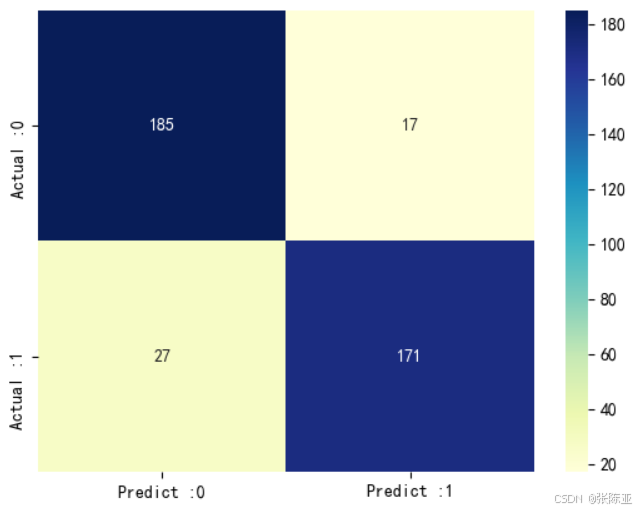
从上图可以看出,实际为0预测不为0的 有17个样本,实际为1预测不为1的 有27个样本,模型效果良好。
8.结论与展望
综上所述,本文采用了通过随机分布式延迟PSO优化算法优化CNN分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。