问题描述
基于Seq2seq模型来实现文本生成的模型,输入可以为一段已知的金庸小说段落,来生成新的段落并做分析。
实验原理
Seq2Seq
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。如下图所,输入的中文长度为4,输出的英文长度为2。
在网络结构中,输入一个中文序列,然后输出它对应的中文翻译,输出的部分的结果预测后面,根据上面的例子,也就是先输出“machine”,将"machine"作为下一次的输入,接着输出"learning",这样就能输出任意长的序列。
机器翻译、人机对话、聊天机器人等等,这些都是应用在当今社会都或多或少的运用到了我们这里所说的Seq2Seq。
Seq2Seq结构
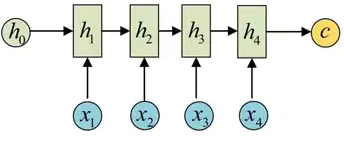
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
首先将源语句输入至encoder编码为一个向量,我们称为上下文向量,它可以视为整个输入句子的抽象表示。然后,该向量由第二个LSTM解码,该LSTM通过一次生成一个单词来学习输出目标语句。下面给出文本翻译的例子。
源语句被输入至embedding层(黄色),然后被输入编码器(绿色),我们还分别将序列的开始()和序列的结束()标记附加到句子的开始和结尾,sos为start of sentence,eos为end of sentence。在每一个时间步,我们输入给encoder当前的单词以及上一个时间步的隐藏状态h_t-1,encoder吐出新的h_t,这个tensor可以视为目前为止的句子的抽象表示。这个RNN可以表示为一个方程: ht=EncoderRNN(emb(xt),ht-1) 这里的RNN可以是LSTM或GRU或任何RNN的变体。在最后一个时间步,我们将h_T赋给z,作为decoder的输入。
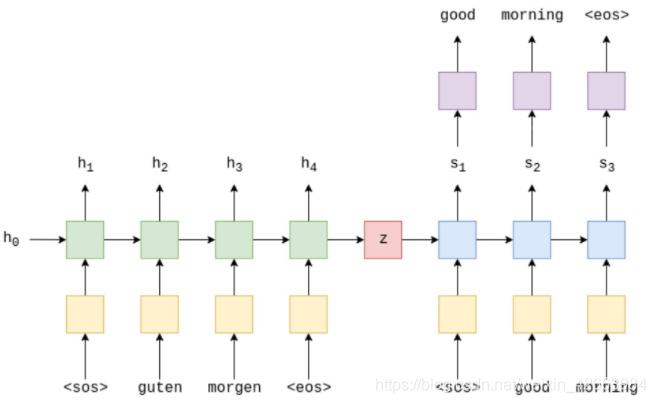
在每个时间步,解码器RNN(蓝色)的输入是当前单词的嵌入,以及上一个时间步的隐藏状态,其中初始解码器隐藏状态就是上下文向量,即初始解码器隐藏状态是最终编码器隐藏状态。因此,方程为 s_t=DecoderRNN(emb(y_t,x_t-1) ,然后在每一个时间步,我们将s_t输入给线形层(紫色),得到y_t_hat,即 y_t_hat=f(s_t) ,而后用y_hat与y进行交叉熵计算,得到损失,并优化参数。
Encoder(编码器)
在前向计算中,我们传入源语句,并使用嵌入层将其转换为密集向量,然后应用dropout。 然后将这些嵌入传递到RNN。 当我们将整个序列传递给RNN时,它将为我们自动对整个序列进行隐藏状态的递归计算。请注意,我们没有将初始的隐藏状态或单元状态传递给RNN。
Decoder(解码器)
解码器执行解码的单个步骤,即,每个时间步输出单个token。 第一层将从上一时间步中接收到一个隐藏的单元格状态,并将其与当前嵌入的token一起通过LSTM馈送,以产生一个新的隐藏的单元格状态。 后续层将使用下一层的隐藏状态,以及其图层中先前的隐藏状态和单元格状态。
Decoder的参数与encoder类似,但要注意它们的hid_dim要相同,否则矩阵无法运算。
模型应用领域
首先作为为机器翻译问题为出发点提出来的seq2seq模型,机器翻译的准确率因为该模型的提出而有了较大的提升。
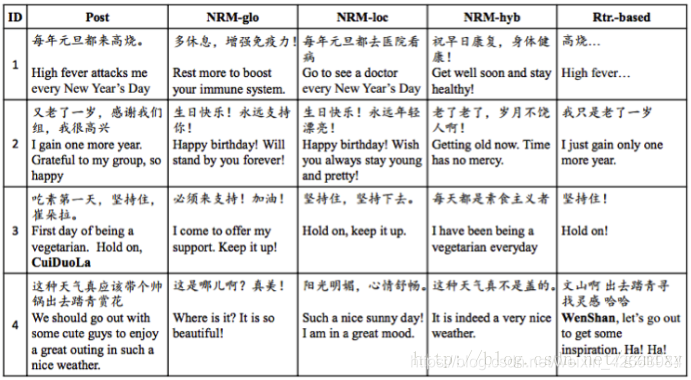
作为seq2seq模型研发团队,Google Brain团队在2014年的文章的应用案例中对LSTm的隐藏结点做了主成分分析,如下图所示,从图中可以看出,模型中的语境向量很明显包涵了输入序列的语言意义,后沟将不同次序所产的的不同意思的语句划分开,这对于提升机器翻译的准确率很有帮助。其次seq2seq模型因为突破了传统的固定大小输入问题框架,因而除了翻译场景,还被用于智能对话与问答的实现以及微博的自动回复,2015年华为团队,通过seq2seq为基础设计的模型实现了计算机对微博的自动回复,并通过模型间的对比得到了一系列有意思的结果。如下图,post为微博主发的文,其余四列为不同模型对该条微博做出的回复。
实验流程
首先进行判断文章是否是乱码
# ==============判断char是否是乱码===================
def is_uchar(uchar):
"""判断一个unicode是否是汉字"""
if uchar >= u'\u4e00' and uchar<=u'\u9fa5':
return True
"""判断一个unicode是否是数字"""
if uchar >= u'\u0030' and uchar<=u'\u0039':
return True
"""判断一个unicode是否是英文字母"""
if (uchar >= u'\u0041' and uchar<=u'\u005a') or (uchar >= u'\u0061' and uchar<=u'\u007a'):
return True
if uchar in (',','。',':','?','“','”','!',';','、','《','》','——'):
return True
return False
接着进行模型搭建
# ====================================搭建模型===================================
class RNNModel():
"""docstring for RNNModel"""
def __init__(self, BATCH_SIZE, HIDDEN_SIZE, HIDDEN_LAYERS, VOCAB_SIZE, learning_rate):
super(RNNModel, self).__init__()
self.BATCH_SIZE = BATCH_SIZE
self.HIDDEN_SIZE = HIDDEN_SIZE
self.HIDDEN_LAYERS = HIDDEN_LAYERS
self.VOCAB_SIZE = VOCAB_SIZE
# ======定义占位符======
with tf.name_scope('input'):
self.inputs = tf.placeholder(tf.int32, [BATCH_SIZE, None])
self.targets = tf.placeholder(tf.int32, [BATCH_SIZE, None])
self.keepprb = tf.placeholder(tf.float32)
# ======定义词嵌入层======
with tf.name_scope('embedding'):
embedding = tf.get_variable('embedding', [VOCAB_SIZE, HIDDEN_SIZE])
emb_input = tf.nn.embedding_lookup(embedding, self.inputs)
emb_input = tf.nn.dropout(emb_input, self.keepprb)
# ======搭建lstm结构=====
with tf.name_scope('rnn'):
lstm = tf.contrib.rnn.LSTMCell(HIDDEN_SIZE, state_is_tuple=True)
lstm = tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=self.keepprb)
cell = tf.contrib.rnn.MultiRNNCell([lstm] * HIDDEN_LAYERS)
self.initial_state = cell.zero_state(BATCH_SIZE, tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(cell, emb_input, initial_state=self.initial_state)
# =====重新reshape输出=====
with tf.name_scope('output_layer'):
outputs = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE])
w = tf.get_variable('outputs_weight', [HIDDEN_SIZE, VOCAB_SIZE])
b = tf.get_variable('outputs_bias', [VOCAB_SIZE])
logits = tf.matmul(outputs, w) + b
# ======计算损失=======
with tf.name_scope('loss'):
self.loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [tf.reshape(self.targets, [-1])],
[tf.ones([BATCH_SIZE * TIME_STEPS],
dtype=tf.float32)])
self.cost = tf.reduce_sum(self.loss) / BATCH_SIZE
# =============优化算法==============
with tf.name_scope('opt'):
# =============学习率衰减==============
global_step = tf.Variable(0)
learning_rate = tf.train.exponential_decay(learning_rate, global_step, BATCH_NUMS, 0.99, staircase=True)
# =======通过clip_by_global_norm()控制梯度大小======
trainable_variables = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, trainable_variables), MAX_GRAD_NORM)
self.opt = tf.train.AdamOptimizer(learning_rate).apply_gradients(zip(grads, trainable_variables))
# ==============预测输出=============
with tf.name_scope('predict'):
self.predict = tf.argmax(logits, 1)
载入训练集,本实验采用白马啸西风为例
# ========读取原始数据========
with open('./data/白马啸西风.txt', 'r', encoding='utf-8') as f:
data = f.readlines()
print(data[0])
import re
# 生成一个正则,负责找'()'包含的内容
pattern = re.compile(r'\(.*\)')
# 将其替换为空
data = [pattern.sub('', lines) for lines in data]
# 将.....替换为句号
data = [line.replace('……', '。') for line in data if len(line) > 1]
print(data)
# 将每行的list合成一个长字符串
data = ''.join(data)
data = [char for char in data if is_uchar(char)]
data = ''.join(data)
print(data[:100])
# =====生成字典=====
vocab = set(data)
id2char = list(vocab)
char2id = {c: i for i, c in enumerate(vocab)}
print('字典长度:', len(vocab))
import jieba
word_data = list(jieba.cut(data))
接着生成字典
# =====生成字典=====
word_vocab = set(word_data)
id2word = list(word_vocab)
word2id = {c: i for i, c in enumerate(vocab)}
print(word_data[:100])
print(id2word[:100])
print(len(vocab))
import numpy as np
# =====转换数据为数字格式======
numdata = [char2id[char] for char in data]
numdata = np.array(numdata)
print('数字数据信息:\n', numdata[:100])
print('\n文本数据信息:\n', ''.join([id2char[i] for i in numdata[:100]]))
print(len(data))
# 打印输出数据
data_batch = data_generator(numdata, 2, 5)
x, y = next(data_batch)
print('input data:', x[0], '\noutput data:', y[0])
训练参数定义如下
# =======预定义模型参数========
VOCAB_SIZE = len(vocab)
EPOCHS = 1000
BATCH_SIZE = 8
TIME_STEPS = 100
BATCH_NUMS = len(numdata) // (BATCH_SIZE * TIME_STEPS)
HIDDEN_SIZE = 512
HIDDEN_LAYERS = 6
MAX_GRAD_NORM = 1
learning_rate = 0.05
# ===========模型训练===========
model = RNNModel(BATCH_SIZE, HIDDEN_SIZE, HIDDEN_LAYERS, VOCAB_SIZE, learning_rate)
print(model)
# 保存模型
saver = tf.train.Saver()
with tf.Session() as sess:
writer = tf.summary.FileWriter('logs/tensorboard', tf.get_default_graph())
sess.run(tf.global_variables_initializer())
for k in range(EPOCHS):
state = sess.run(model.initial_state)
train_data = data_generator(numdata, BATCH_SIZE, TIME_STEPS)
total_loss = 0.
for i in range(BATCH_NUMS):
xs, ys = next(train_data)
feed = {model.inputs: xs, model.targets: ys, model.keepprb: 0.8, model.initial_state: state}
costs, state, _ = sess.run([model.cost, model.final_state, model.opt], feed_dict=feed)
total_loss += costs
if (i + 1) % 50 == 0:
print('epochs:', k + 1, 'iter:', i + 1, 'cost:', total_loss / i + 1)
saver.save(sess, './checkpoints/lstm.ckpt')
writer.close()
最后进行模型测试
# ============模型测试============
tf.reset_default_graph()
evalmodel = RNNModel(1, HIDDEN_SIZE, HIDDEN_LAYERS, VOCAB_SIZE, learning_rate)
# 加载模型
T=[]
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, './checkpoints/lstm.ckpt')
new_state = sess.run(evalmodel.initial_state)
with open('./data/白马啸西风_target.txt', 'r', encoding='utf-8') as f:
for n in f:
n = n.replace('\n', "")
t = char2id[n]
T.append(t)
print(T)
x= np.array([T])
samples = []
for i in range(100):
feed = {evalmodel.inputs: x, evalmodel.keepprb: 1., evalmodel.initial_state: new_state}
c, new_state = sess.run([evalmodel.predict, evalmodel.final_state], feed_dict=feed)
for j in range(len(T)):
x[0][j] = c[0]
# x[0][0] = c[0]
samples.append(c[0])
print(x)
print(len(c))
print(samples)
print('test:', ''.join([id2char[index] for index in samples]))
实验结果
input data: [1413 1026 974 788 217]
output data: [1026 974 788 217 1088]
输入的数据是白马啸西风中的段落:
他跨下的枣红马奔驰了数十里地,早已筋疲力尽,在主人没命价的鞭打催踢之下,逼得气也喘不过来了,这时嘴边已全是白沫,猛地里前腿一软,跪倒在地。
输出的结果是:
丁计是的在哭衣,误了珠普普戈豪你人截下的汉啸啸,江的一。迸厚人的侠到她这。蒙珍冻扑,妈堆碍抽病洞项隐胜咳瘦蛋将作侠戈匀娜戈遭遭戈古藤灌灌灌兵识思,是兵珍汉戈你是恼
总结
通过循环输入文本学习小说的语法及写作风格,并生成了一些文本,虽然时间和算力限制,没有对模型进行很好的改进和调节,但是对LSTM以及Seq2Seq模型的训练和测试过程有了一定的体会,也对文本生成的人物有了一定的了解。在实验中,我也体会到复杂的模型并不一定带来更好的效果,通过一些采样方法或数据处理手段往往可以很直观的提升文本生成的效果。
最后的实验结果还是有点不尽人意,还需要继续调整。
文本生成学习(一)教你用seq2seq训练一个chatbotFork
自然语言处理之seq2seq模型
NLP之Seq2Seq
利用LSTM生成莫言小说