目录
前言
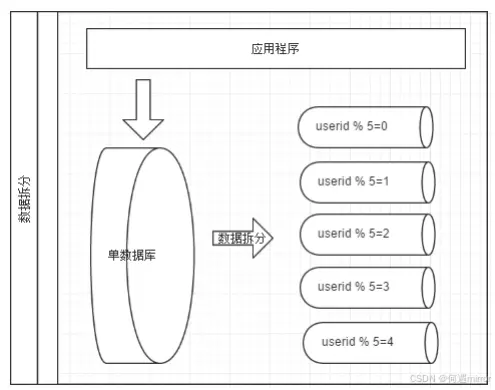
分库分表是数据库优化中的一项重要技术,它通过将数据分散到多个数据库或表中,以提高系统的处理能力和响应速度。本篇将详细解析三种常见的分库分表策略:基于范围(Range)、基于哈希(Hash)以及基于映射表(Mapping Table),并提供Java代码示例。
1. 基于范围的分库分表(Range)
原理: 基于范围的分库分表策略是根据数据的一个特定属性(如时间戳、用户ID等)将其分配到不同的数据库或表中。例如,你可以根据用户的注册时间,将用户数据分配到不同的月份或年度数据库中。
代码示例: 下面代码展示如何根据用户ID的范围来确定数据应存储在哪一个分库中:
public class RangeShardingStrategy {
// 分库数量
private static final int SHARD_COUNT = 2;
/**
* 根据用户ID的范围确定分库编号。
* @param userId 用户ID
* @return 分库编号
*/
public int getShardId(long userId) {
// 假设每个分库处理50%的用户ID
int shardId = (int)(userId % SHARD_COUNT);
return shardId;
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
RangeShardingStrategy strategy = new RangeShardingStrategy();
long userId = 12345L;
int shardId = strategy.getShardId(userId);
System.out.println("User ID " + userId + " will be stored in Shard " + shardId);
}
}2. 基于哈希的分库分表(Hash)
原理: 基于哈希的分库分表策略使用哈希函数将数据映射到特定的数据库或表中。这种策略的目的是确保数据在多个数据库或表之间均匀分布,从而达到负载均衡的效果。
代码示例: 下面代码示例展示如何使用MD5哈希函数将用户ID映射到分库中:
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class HashShardingStrategy {
private static final int SHARD_COUNT = 2;
/**
* 使用MD5哈希函数将用户ID映射到分库编号。
* @param userId 用户ID
* @return 分库编号
*/
public int getShardId(long userId) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] hashBytes = md.digest(Long.toString(userId).getBytes());
int hashInt = ((hashBytes[3] & 0xFF) << 24) | ((hashBytes[2] & 0xFF) << 16) | ((hashBytes[1] & 0xFF) << 8) | (hashBytes[0] & 0xFF);
return Math.abs(hashInt % SHARD_COUNT);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("Error creating MD5 digest", e);
}
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
HashShardingStrategy strategy = new HashShardingStrategy();
long userId = 12345L;
int shardId = strategy.getShardId(userId);
System.out.println("User ID " + userId + " will be stored in Shard " + shardId);
}
}3. 基于映射表的分库分表(Mapping Table)
原理: 基于映射表的分库分表策略使用一个额外的表来记录数据与分库之间的映射关系。这种方法适用于数据分片规则复杂或需要动态调整分片规则的场景。
代码示例: 由于映射表通常存储在数据库中,下面示例将展示如何使用JDBC连接数据库并查询分库编号:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MappingTableShardingStrategy {
private static final String JDBC_URL = "jdbc:mysql://localhost:3306/sharding";
private static final String USER = "root";
private static final String PASSWORD = "password";
/**
* 从映射表中查找用户ID对应的分库编号。
* @param userId 用户ID
* @return 分库编号
*/
public int getShardIdFromMapping(long userId) {
int shardId = -1;
try (Connection conn = DriverManager.getConnection(JDBC_URL, USER, PASSWORD)) {
PreparedStatement stmt = conn.prepareStatement("SELECT shard_id FROM mapping_table WHERE user_id = ?");
stmt.setLong(1, userId);
ResultSet rs = stmt.executeQuery();
if (rs.next()) {
shardId = rs.getInt("shard_id");
}
} catch (Exception e) {
e.printStackTrace();
}
return shardId;
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
MappingTableShardingStrategy strategy = new MappingTableShardingStrategy();
long userId = 12345L;
int shardId = strategy.getShardIdFromMapping(userId);
System.out.println("User ID " + userId + " will be stored in Shard " + shardId);
}
}