
前言
☀️ 在低照度场景下进行目标检测任务,常存在图像RGB特征信息少、提取特征困难、目标识别和定位精度低等问题,给检测带来一定的难度。
🌻使用图像增强模块对原始图像进行画质提升,恢复各类图像信息,再使用目标检测网络对增强图像进行特定目标检测,有效提高检测的精确度。
⭐本专栏会介绍传统方法、Retinex、EnlightenGAN、SCI、Zero-DCE、IceNet、RRDNet、URetinex-Net等低照度图像增强算法。
👑完整代码已打包上传至资源→低照度图像增强代码汇总资源
目录

🚀一、SCI介绍
相关资料:
☀️1.1 SCI简介
针对现有的低照度图像增强技术普遍存在的难以处理视觉质量和计算效率,而且在未知的复杂场景中普遍无效的问题,大连理工大学2022年4月发表在CVPR Oral上的一篇文章《 Toward Fast, Flexible, and Robust Low-Light Image Enhancement》(实现快速、灵活和稳健的低光照图像增强)。 提出了自校准照明 (Self-Calibrated Illumination, SCI) 学习框架,具有快速、灵活、鲁棒性好的特点。

主要方法:
(1)开发了一个具有权重共享的自校准照明学习模块,以协商每个阶段的结果之间的收敛,提高曝光稳定性,并大幅度减少计算负担。这是第一个利用学习过程来加速微光图像增强算法的工作。
(2)定义了无监督训练损失,以提高模型适应一般场景的能力。
实现效果: 在弱光人脸检测和夜间语义分割方面的应用充分揭示了 SCI 潜在的实用价值。
☀️1.2 SCI网络结构
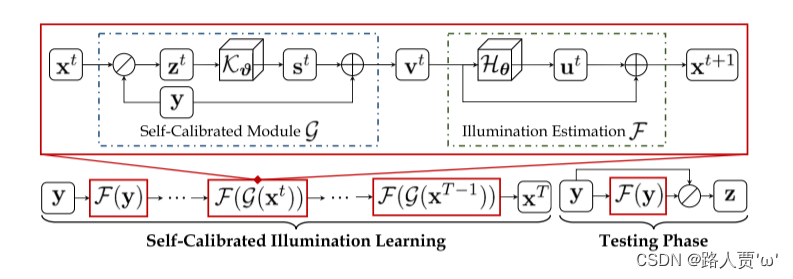
SCI由光照估计和自校准模块组成。其中,自校准模块将添加到原始的微光输入中,作为下一阶段照明估计的输入。
(注意:这两个模块分别是整个训练过程中的共享参数。在测试阶段,我们只使用单个照明估计模块。)
(1)权重共享的照明学习
启示:低照度的图像与想要得到的清晰图像之间是有关联的,其中最重要的成分就是照明,这个也是在弱光图像增强中需要主要进行优化的部分。
作者并没有直接去学习图片和明亮之间的映射,作者提出了一个新的学习照明方法。
公式:
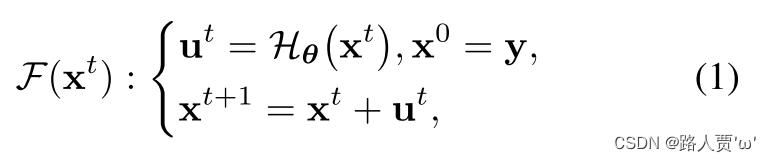
(2)自校准模块
目的:定义一个模块,确保在训练过程中的不同阶段的输出均能够收敛到相同的状态。
公式:
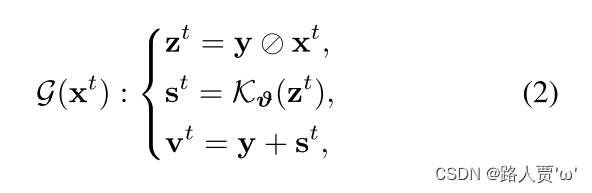
光照优化过程的基本单元被重新公式化为:

☀️1.3 SCI损失函数
无监督损失训练
目的:考虑到已有配对数据的不准确性,本文采用无监督学习来扩大网络的能力。
总损失公式:
Lf :表示保真度;Ls :表示平滑损失
1.保真度损失
保真度损失是为了保证估计照度和每个阶段输入之间的像素级一致性,公式如下:
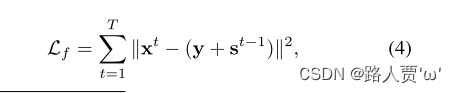
2.平滑损失
本文采用了一个具有空间变化 l1 范数的平滑项 ,表示为:
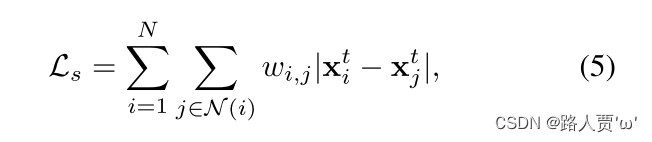
🚀二、SCI核心代码讲解
🎄2.1 model.py
完整代码:
import torch
import torch.nn as nn
from loss import LossFunction
class EnhanceNetwork(nn.Module):
def __init__(self, layers, channels):
super(EnhanceNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.ReLU()
)
self.conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.conv)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
illu = fea + input
illu = torch.clamp(illu, 0.0001, 1)
return illu
class CalibrateNetwork(nn.Module):
def __init__(self, layers, channels):
super(CalibrateNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.layers = layers
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.convs = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.convs)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
delta = input - fea
return delta
class Network(nn.Module):
def __init__(self, stage=3):
super(Network, self).__init__()
self.stage = stage
self.enhance = EnhanceNetwork(layers=1, channels=3)
self.calibrate = CalibrateNetwork(layers=3, channels=16)
self._criterion = LossFunction()
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
ilist, rlist, inlist, attlist = [], [], [], []
input_op = input
for i in range(self.stage):
inlist.append(input_op)
i = self.enhance(input_op)
r = input / i
r = torch.clamp(r, 0, 1)
att = self.calibrate(r)
input_op = input + att
ilist.append(i)
rlist.append(r)
attlist.append(torch.abs(att))
return ilist, rlist, inlist, attlist
def _loss(self, input):
i_list, en_list, in_list, _ = self(input)
loss = 0
for i in range(self.stage):
loss += self._criterion(in_list[i], i_list[i])
return loss
class Finetunemodel(nn.Module):
def __init__(self, weights):
super(Finetunemodel, self).__init__()
self.enhance = EnhanceNetwork(layers=1, channels=3)
self._criterion = LossFunction()
base_weights = torch.load(weights)
pretrained_dict = base_weights
model_dict = self.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.load_state_dict(model_dict)
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
i = self.enhance(input)
r = input / i
r = torch.clamp(r, 0, 1)
return i, r
def _loss(self, input):
i, r = self(input)
loss = self._criterion(input, i)
return loss
主要由EnhanceNetwork 、CalibrateNetwork、Network、Finetunemodel 四个类组成。
① class EnhanceNetwork
class EnhanceNetwork(nn.Module):
def __init__(self, layers, channels):
# 调用父类的构造函数,完成初始化
super(EnhanceNetwork, self).__init__()
# 卷积核大小为3*3、膨胀设为1、通过计算,得到合适的填充大小。
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
# 输入卷积层
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.ReLU()
)
# 中间卷积层
self.conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
# 模块列表
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.conv)
# 输出卷积层
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
# 将输入数据通过输入卷积层 self.in_conv,得到中间特征 fea。
fea = self.in_conv(input)
# 通过多个中间卷积层 self.blocks 进行迭代,
for conv in self.blocks:
# 每次迭代中将当前特征 fea 与中间卷积层的输出相加。
fea = fea + conv(fea)
fea = self.out_conv(fea)
# 将输出特征与输入数据相加,得到增强后的图像。
illu = fea + input
# 通过 torch.clamp 函数将图像的像素值限制在 0.0001 到 1 之间,以确保输出在有效范围内。
illu = torch.clamp(illu, 0.0001, 1)
return illu这段代码主要作用是对输入图像进行增强。
通过多次堆叠卷积块,来学习图像的特征。增强后的图像通过与输入相加并进行截断,以确保像素值在合理范围内。
首先,通过__init__初始化超参数和网络层,参数设置看注释。
然后,将输入图像通过3*3的卷积层,得到特征 fea,对特征 fea 多次应用相同的卷积块进行叠加,通过输出卷积层获得最终的特征 fea。
接着,将生成的特征与输入图像相加,得到增强后的图像,通过 clamp 函数将图像像素值限制在 0.0001 和 1 之间。
最后,返回增强后的图像 illu。
② class CalibrateNetwork
class CalibrateNetwork(nn.Module):
def __init__(self, layers, channels):
super(CalibrateNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.layers = layers
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.convs = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.convs)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
# 将输入数据通过输入卷积层,得到中间特征 fea。
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
# 计算输入与输出的差异,得到增益调整的值。
delta = input - fea
return delta这段代码主要作用是定义了一个校准网络。
初始化和上一段差不多,就不再逐行注释。区别是在前向传播时,输入经过一系列卷积操作后,对于最终的特征 fea再与原始输入相减,得到最终的增益调整结果delta。
③ class Network
class Network(nn.Module):
def __init__(self, stage=3):
super(Network, self).__init__()
# 将传入的 stage 参数保存到类的实例变量中
self.stage = stage
# 增强和校准
self.enhance = EnhanceNetwork(layers=1, channels=3)
self.calibrate = CalibrateNetwork(layers=3, channels=16)
# 创建了一个损失函数实例,用于计算损失
self._criterion = LossFunction()
# 权重使用正态分布初始化
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
# 初始化空列表 ilist, rlist, inlist, attlist 用于存储不同阶段的结果
ilist, rlist, inlist, attlist = [], [], [], []
# 将输入数据保存到 input_op 变量中。
input_op = input
for i in range(self.stage):
# 将当前输入添加到输入列表中
inlist.append(input_op)
# 使用图像增强网络 self.enhance 处理当前输入,得到增强后的图像
i = self.enhance(input_op)
# 计算增强前后的比例
r = input / i
# 将比例值限制在 [0, 1] 范围内
r = torch.clamp(r, 0, 1)
# 使用校准网络 self.calibrate 对比例进行校准,得到校准值
att = self.calibrate(r)
# 将原始输入与校准值相加,得到下一阶段的输入
input_op = input + att
# 分别将当前阶段的增强图像、比例、输入和校准值的绝对值添加到对应的列表中
ilist.append(i)
rlist.append(r)
attlist.append(torch.abs(att))
return ilist, rlist, inlist, attlist
def _loss(self, input):
i_list, en_list, in_list, _ = self(input)
loss = 0
for i in range(self.stage):
loss += self._criterion(in_list[i], i_list[i])
return loss这段代码主要作用是组合了刚刚我们提到的图像增强网络 (EnhanceNetwork) 和校准网络 (CalibrateNetwork),并多次执行这两个操作。
首先,初始化网络结构,并创建EnhanceNetwork、CalibrateNetwork以及loss损失函数的实例。
接着,定义权重初始化的方法。
然后,通过多次迭代,每次迭代中进行以下步骤:
- 将当前输入保存到列表中。
- 使用图像增强网络
EnhanceNetwork处理当前输入,得到增强后的图像。 - 计算增强前后的比例,并将比例值限制在 [0, 1] 范围内。
- 使用校准网络
CalibrateNetwork对比例进行校准,得到校准值。 - 将原始输入与校准值相加,得到下一阶段的输入。
- 将当前阶段的增强图像、比例、输入和校准值的绝对值保存到对应的列表中。
- 返回四个列表,分别包含不同阶段的增强图像、比例、输入和校准值。
最后,计算损失。
④ class Finetunemodel
class Finetunemodel(nn.Module):
def __init__(self, weights):
super(Finetunemodel, self).__init__()
self.enhance = EnhanceNetwork(layers=1, channels=3)
self._criterion = LossFunction()
# 加载预训练权重
base_weights = torch.load(weights)
pretrained_dict = base_weights
model_dict = self.state_dict()
# 仅保留预训练权重中在当前模型中存在的键值对
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 将筛选后的预训练权重更新到当前模型的字典中。
model_dict.update(pretrained_dict)
# 加载更新后的权重到模型
self.load_state_dict(model_dict)
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
i = self.enhance(input)
r = input / i
r = torch.clamp(r, 0, 1)
return i, r
def _loss(self, input):
i, r = self(input)
loss = self._criterion(input, i)
return loss这段代码主要作用是进行模型的微调。
这块没啥好讲的~
🎄2.2 loss.py
完整代码:
import torch
import torch.nn as nn
class LossFunction(nn.Module):
def __init__(self):
super(LossFunction, self).__init__()
self.l2_loss = nn.MSELoss()
self.smooth_loss = SmoothLoss()
def forward(self, input, illu):
Fidelity_Loss = self.l2_loss(illu, input)
Smooth_Loss = self.smooth_loss(input, illu)
return 1.5*Fidelity_Loss + Smooth_Loss
class SmoothLoss(nn.Module):
def __init__(self):
super(SmoothLoss, self).__init__()
self.sigma = 10
def rgb2yCbCr(self, input_im):
im_flat = input_im.contiguous().view(-1, 3).float()
mat = torch.Tensor([[0.257, -0.148, 0.439], [0.564, -0.291, -0.368], [0.098, 0.439, -0.071]]).cuda()
bias = torch.Tensor([16.0 / 255.0, 128.0 / 255.0, 128.0 / 255.0]).cuda()
temp = im_flat.mm(mat) + bias
out = temp.view(input_im.shape[0], 3, input_im.shape[2], input_im.shape[3])
return out
# output: output input:input
def forward(self, input, output):
self.output = output
self.input = self.rgb2yCbCr(input)
sigma_color = -1.0 / (2 * self.sigma * self.sigma)
w1 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :] - self.input[:, :, :-1, :], 2), dim=1,
keepdim=True) * sigma_color)
w2 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :] - self.input[:, :, 1:, :], 2), dim=1,
keepdim=True) * sigma_color)
w3 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, 1:] - self.input[:, :, :, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w4 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, :-1] - self.input[:, :, :, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w5 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :-1] - self.input[:, :, 1:, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w6 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, 1:] - self.input[:, :, :-1, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w7 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :-1] - self.input[:, :, :-1, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w8 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, 1:] - self.input[:, :, 1:, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w9 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :] - self.input[:, :, :-2, :], 2), dim=1,
keepdim=True) * sigma_color)
w10 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :] - self.input[:, :, 2:, :], 2), dim=1,
keepdim=True) * sigma_color)
w11 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, 2:] - self.input[:, :, :, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w12 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, :-2] - self.input[:, :, :, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w13 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :-1] - self.input[:, :, 2:, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w14 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, 1:] - self.input[:, :, :-2, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w15 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :-1] - self.input[:, :, :-2, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w16 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, 1:] - self.input[:, :, 2:, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w17 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :-2] - self.input[:, :, 1:, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w18 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, 2:] - self.input[:, :, :-1, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w19 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :-2] - self.input[:, :, :-1, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w20 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, 2:] - self.input[:, :, 1:, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w21 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :-2] - self.input[:, :, 2:, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w22 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, 2:] - self.input[:, :, :-2, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w23 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :-2] - self.input[:, :, :-2, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w24 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, 2:] - self.input[:, :, 2:, :-2], 2), dim=1,
keepdim=True) * sigma_color)
p = 1.0
pixel_grad1 = w1 * torch.norm((self.output[:, :, 1:, :] - self.output[:, :, :-1, :]), p, dim=1, keepdim=True)
pixel_grad2 = w2 * torch.norm((self.output[:, :, :-1, :] - self.output[:, :, 1:, :]), p, dim=1, keepdim=True)
pixel_grad3 = w3 * torch.norm((self.output[:, :, :, 1:] - self.output[:, :, :, :-1]), p, dim=1, keepdim=True)
pixel_grad4 = w4 * torch.norm((self.output[:, :, :, :-1] - self.output[:, :, :, 1:]), p, dim=1, keepdim=True)
pixel_grad5 = w5 * torch.norm((self.output[:, :, :-1, :-1] - self.output[:, :, 1:, 1:]), p, dim=1, keepdim=True)
pixel_grad6 = w6 * torch.norm((self.output[:, :, 1:, 1:] - self.output[:, :, :-1, :-1]), p, dim=1, keepdim=True)
pixel_grad7 = w7 * torch.norm((self.output[:, :, 1:, :-1] - self.output[:, :, :-1, 1:]), p, dim=1, keepdim=True)
pixel_grad8 = w8 * torch.norm((self.output[:, :, :-1, 1:] - self.output[:, :, 1:, :-1]), p, dim=1, keepdim=True)
pixel_grad9 = w9 * torch.norm((self.output[:, :, 2:, :] - self.output[:, :, :-2, :]), p, dim=1, keepdim=True)
pixel_grad10 = w10 * torch.norm((self.output[:, :, :-2, :] - self.output[:, :, 2:, :]), p, dim=1, keepdim=True)
pixel_grad11 = w11 * torch.norm((self.output[:, :, :, 2:] - self.output[:, :, :, :-2]), p, dim=1, keepdim=True)
pixel_grad12 = w12 * torch.norm((self.output[:, :, :, :-2] - self.output[:, :, :, 2:]), p, dim=1, keepdim=True)
pixel_grad13 = w13 * torch.norm((self.output[:, :, :-2, :-1] - self.output[:, :, 2:, 1:]), p, dim=1, keepdim=True)
pixel_grad14 = w14 * torch.norm((self.output[:, :, 2:, 1:] - self.output[:, :, :-2, :-1]), p, dim=1, keepdim=True)
pixel_grad15 = w15 * torch.norm((self.output[:, :, 2:, :-1] - self.output[:, :, :-2, 1:]), p, dim=1, keepdim=True)
pixel_grad16 = w16 * torch.norm((self.output[:, :, :-2, 1:] - self.output[:, :, 2:, :-1]), p, dim=1, keepdim=True)
pixel_grad17 = w17 * torch.norm((self.output[:, :, :-1, :-2] - self.output[:, :, 1:, 2:]), p, dim=1, keepdim=True)
pixel_grad18 = w18 * torch.norm((self.output[:, :, 1:, 2:] - self.output[:, :, :-1, :-2]), p, dim=1, keepdim=True)
pixel_grad19 = w19 * torch.norm((self.output[:, :, 1:, :-2] - self.output[:, :, :-1, 2:]), p, dim=1, keepdim=True)
pixel_grad20 = w20 * torch.norm((self.output[:, :, :-1, 2:] - self.output[:, :, 1:, :-2]), p, dim=1, keepdim=True)
pixel_grad21 = w21 * torch.norm((self.output[:, :, :-2, :-2] - self.output[:, :, 2:, 2:]), p, dim=1, keepdim=True)
pixel_grad22 = w22 * torch.norm((self.output[:, :, 2:, 2:] - self.output[:, :, :-2, :-2]), p, dim=1, keepdim=True)
pixel_grad23 = w23 * torch.norm((self.output[:, :, 2:, :-2] - self.output[:, :, :-2, 2:]), p, dim=1, keepdim=True)
pixel_grad24 = w24 * torch.norm((self.output[:, :, :-2, 2:] - self.output[:, :, 2:, :-2]), p, dim=1, keepdim=True)
ReguTerm1 = torch.mean(pixel_grad1) \
+ torch.mean(pixel_grad2) \
+ torch.mean(pixel_grad3) \
+ torch.mean(pixel_grad4) \
+ torch.mean(pixel_grad5) \
+ torch.mean(pixel_grad6) \
+ torch.mean(pixel_grad7) \
+ torch.mean(pixel_grad8) \
+ torch.mean(pixel_grad9) \
+ torch.mean(pixel_grad10) \
+ torch.mean(pixel_grad11) \
+ torch.mean(pixel_grad12) \
+ torch.mean(pixel_grad13) \
+ torch.mean(pixel_grad14) \
+ torch.mean(pixel_grad15) \
+ torch.mean(pixel_grad16) \
+ torch.mean(pixel_grad17) \
+ torch.mean(pixel_grad18) \
+ torch.mean(pixel_grad19) \
+ torch.mean(pixel_grad20) \
+ torch.mean(pixel_grad21) \
+ torch.mean(pixel_grad22) \
+ torch.mean(pixel_grad23) \
+ torch.mean(pixel_grad24)
total_term = ReguTerm1
return total_term
SCI使用的是无监督损失训练,由fifidelity loss和smoothing loss的线性组合构成。
代码太复杂了,我就说一下大概的吧~
① Fidelity Loss
- 采用均方误差损失函数
nn.MSELoss计算输入图像input与增强后的图像illu之间的均方误差。 - 正则化项基于像素梯度和其指数权重的计算。
② Smooth Loss
- 采用
SmoothLoss类的实例self.smooth_loss计算输入图像input与增强后的图像illu之间的光滑损失。 - 通过 YCbCr 色彩空间的梯度计算来衡量图像的光滑性。
🚀三、SCI实现效果


可以看到增强效果是非常不错的。
但是很容易出现曝光,如下图:


