Albert和Bert代码简单介绍
这篇文章将借助Albert的代码将Albert和Bert简单介绍一下。
一 区别(Albert变化)
- 词嵌入向量参数的因式分解
O(V * H) to O(V * E + E * H) V:字典个数。 E:输入层。 H:隐藏层。
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。
- 跨层参数共享
可以选择共享selfattention,feedforward,或者两个都共享,他们默认都是全部共享。
- NSP–> NOP
bert 的两个句子是从同一语料库随机抽取,Albert认为这种方式对机器识别太过简单,所以采用首先获得的两个句子都是有关联的,然后50%的几率使他们从texta,textb-->textb,texta
- 其他变化
1)去掉了dropout
最大的模型,训练了1百万步后,还是没有过拟合训练数据。说明模型的容量还可以更大,就移除了dropout
2)使用LAMB做为优化器(优化器只是可以加快训练速度)
3)采用n-gram
Bert采用的随机mask某个单字,而Albert采用n-gram是mask片段(最大三个单词),但是我获得的中文训练模型并不是采用这中方法。采用的全词Mask(好像是和哈工大的WWM是一样的)
二 代码简读
pytorch代码来源
https://github.com/huggingface/transformers
上面网站团队这几天已经把许多模型形成了接口,需要的可以自己看看
分词部分
(这部分Bert和Albert相同)
对于中文,只是简单的将单个字分开,想详细了解的可以看看下面的网站,讲的还是挺好的。
–> https://blog.csdn.net/u010099080/article/details/102587954
主模型部分
以下的代码都不是完整的,我去掉了一下不是很重要的,例如归一化和正则的都去掉了,还有一些实际使用中并没使用的功能,例如,代码中还有不经过feedforward的实现。
Embedding层介绍
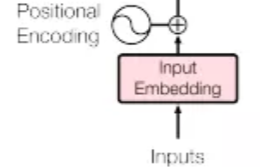
对应的transformer下图所示的位置
这地方,我们看到,一共两个输入,input Embedding和PositionEncoding,但是实际上来说一共有三层,还有一个token_type_embedding ,这三个是干嘛的呢,分别解释。
input embedding:就是我们的文本输入(Albert和Bert会有不同,见上面的不同1),将每个单词对应一个随机初始化的字典。这个维度是(批量大小,句子长度,单词向量长度)。
Position Encoding: 这个是为了下面做attention的时候,对于近处和远处的单词有个区分,注意这里论文中说的是用一个三角函数计算出来的,但是实际代码中还是随机初始化的。维度同input
token_type_embedding:Bert的一种预训练方式就是将输入两个句子,而这个就是做这个分别的,如果是两个句子就是(0,0…0, 1, 1…1),0表示第一个句子,1表示第二个句子。维度也是同input。
最后输入就是三个embedding相加。
class AlbertEmbeddings(nn.Module):
def __init__(self, config):
super(AlbertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=0)
self.word_embeddings_2 = nn.Linear(config.embedding_size, config.hidden_size, bias=False)
# 在此处Bert只有一个word_embeddings ,正是Albert的因式分解的变化,下面是Bert的
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
def forward(self, input_ids, token_type_ids=None, position_ids=None):
seq_length = input_ids.size(1)
# 位置嵌入的信息是随机初始化的
if position_ids is None:
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)#
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
# 完成从随机的字典中取E的向量,再转化成H,我这E=128,H=312
words_embeddings = self.word_embeddings(input_ids)
words_embeddings = self.word_embeddings_2(words_embeddings)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + position_embeddings + token_type_embeddings
return embeddings
Selfattention
接下来就是Bert的比较重要的模块
大家可能已经看了许多Bert的详解了,我这里用维度变化来解释一下。
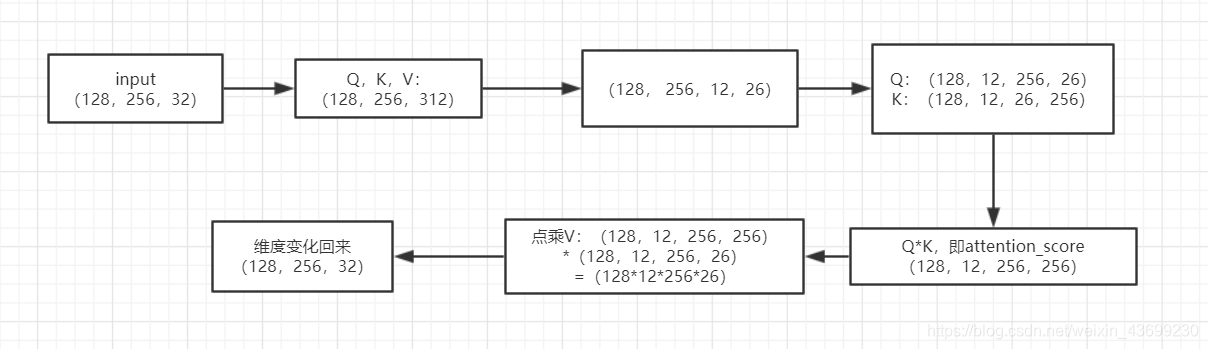
1.首先看这张图,input的输入是(batch_size , seq, hidden)我假设embedding层的输入三个分别是(128,256,312)
2. 将input与Wq, Wk, Wv 点积,代码中可以看到,W的维度是(hidden,config.hidden_size / config.num_attention_heads * self.attention_head_size)其实还是(hidden,hidden)即(312,312),生成的Q,K,V也即图示。
3. 为什么要生成Q,K,V呢,就是为了attention,为什么要attention(还没写,占个坑)。如何进行attention,将每一个单词的Q与所有单词的K进行点积,但是我们说Bert是多头注意力,如何实现呢,在其他的讲解Bert的文章中,他们都说是将Q,K,V分解,然后计算然后累加,我一开始预想的是先分解,再累加,但是实际上维度变化可以一起完成。我假设头的个数是12,将Q,K,V在hidden维度上进行分解,这里我理解是将每一个单词在不同维度的信息能够进行“相互交流“。最后结果为(128,256,12, 26)
4. 紧接着为了让每个单词可以在字向量维度进行"交流",将K的维度变化.
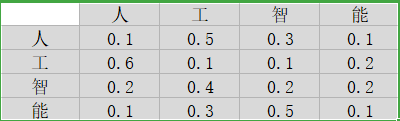
5. 之后Q*K=(128, 12,256,256) ,在代码我们看到在除以√K以后进行了attention_scores + attention_mask,这是在干嘛呢,在我们输入的句子的时候,句子的长度是不一样的,通常是采用最长的句子长度作为seq_length,其他没有这么长的进行padding,但是在后面需要进行softmax,获得自注意力矩阵:
就是每一行表示每个字对其他字的关注程度,每一行的和都是1.(这是我随便写的)
但是softmax函数是这样的,上面的e0会等于1,也就是那些padding的会对上面的分数产生影响,为了避免这个,需要加一个很的的负数,使得ei 接近0.
6.处理完之后,将结果与V进行点积,再进行维度变化,就恢复了维度.

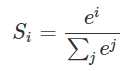
class BertSelfAttention(nn.Module):
def __init__(self, config):
super(BertSelfAttention, self).__init__()
#多头的个数是自己定义的,我这是12,
self.num_attention_heads = config.num_attention_heads#头数是12
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)#312/12
self.all_head_size = self.num_attention_heads * self.attention_head_size#多头总个数
#q,v,k初始化都是[H,H]即[312,312]
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
#分解并进行转置来实现q,k,v可以相乘,[batch_size, seq_length, H]-->
#[batch,seq_length,num_heads,hidding/num_heads]-->[batch,num_heads, seq,hidden/num_heads]
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask, head_mask=None):
#只取了q的代码来说明,完成q*w
mixed_query_layer = self.query(hidden_state)
#用上面的函数对q,k,v分解成多头
query_layer = self.transpose_for_scores(mixed_query_layer)
#Q K 求点积
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
#除以K的,开平方根归一为标准正态分布
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
#下面的attention_mask 是为了填充句子长度不一,他的维度是[batch_size, 1, 1, seq_length]
#后面有这个实现的函数
attention_scores = attention_scores + attention_mask
attention_probs = nn.Softmax(dim=-1)(attention_scores)
#乘以V[batch_size, length, H]
context_layer = torch.matmul(attention_probs, value_layer)
#这地方把q*k的结果也获得了,但实际并没有使用
outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
return outputs
第一次的add
class BertSelfOutput(nn.Module):
def __init__(self, config):
super(BertSelfOutput, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)#【H,H】
self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps)
#残差连接并且归一化
def forward(self, hidden_states, input_tensor):
#进行一个线性变化
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
#这个preln不知道是在干啥,这个在Bert里并没有,且Albert的下游任务中并没有使用这个,我猜测是某个预训练的方式,如果是ln_type是这个的后面没有进行feedforward,
if self.ln_type == 'preln':
# preln
hidden_states = hidden_states + input_tensor
else:
# postln,直接将embedding的输出和self层的输出相加
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
attention
将self和add封装一下,这里有Bert中没有对多头进行随机减少,但是下游任务没有使用
class BertAttention(nn.Module):
def __init__(self, config):
super(BertAttention, self).__init__()
self.self = BertSelfAttention(config)#获得selfAttention
self.output = BertSelfOutput(config)#add
self.pruned_heads = set()#<class 'set'>: set()
self.ln_type = config.ln_type
#这个类其他的就是封装一下self和add层,这下面的函数也是Bert没有的,用来随机化减少头的个数
def prune_heads(self, heads):
if len(heads) == 0:
return
mask = torch.ones(self.self.num_attention_heads, self.self.attention_head_size)
heads = set(heads) - self.pruned_heads # Convert to set and emove already pruned heads
for head in heads:
# Compute how many pruned heads are before the head and move the index accordingly
head = head - sum(1 if h < head else 0 for h in self.pruned_heads)
mask[head] = 0
mask = mask.view(-1).contiguous().eq(1)
index = torch.arange(len(mask))[mask].long()
# 只保留上面随机产生的index中有的头
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# 保存
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(self, input_tensor, attention_mask=None, head_mask=None):
if self.ln_type == 'preln':
hidden_state = self.output.LayerNorm(input_tensor)#对输入先归一再输入
self_outputs = self.self(hidden_state, attention_mask, head_mask)
else:
self_outputs = self.self(input_tensor, attention_mask, head_mask)#进行self-attention
attention_output = self.output(self_outputs[0], input_tensor)#进行残差连接
outputs = (attention_output,) + self_outputs[1:] # 加入selfattention结果,如果需要可以取出来
return outputs
feed层
就是一个简单的线性变化
class BertIntermediate(nn.Module):
def __init__(self, config):
super(BertIntermediate, self).__init__()
#y = wx+b
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
self.intermediate_act_fn = config.hidden_act#激活函数gelu或swish
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)#torch.Size([8, 480, 1248])
hidden_states = self.intermediate_act_fn(hidden_states)#torch.Size([8, 480, 1248])
return hidden_states
封装self 和 feed层
,就是神经网络的一层,这里面实现的权重共享,这里是Albert与Bert不同的地方,Bert是没有这个权重共享的.
class BertLayer(nn.Module):
def __init__(self, config):
super(BertLayer, self).__init__()
self.ln_type = config.ln_type#'postln'
#处理共享机制,最小的Albert使用了4层网络
if config.share_type == 'ffn':
#这里就是如果共享feed层就只创造一个feed层
self.attention = ([BertAttention(config) for _ in range(config.num_hidden_layers)])
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
elif config.share_type == 'attention':
self.attention = BertAttention(config)
self.intermediate = nn.ModuleList([BertIntermediate(config) for _ in range(config.num_hidden_layers)])
self.output = nn.ModuleList([BertOutput(config) for _ in range(config.num_hidden_layers)])
else:
self.attention = BertAttention(config)#获得attention的输出
self.intermediate = BertIntermediate(config)
self.output = BertOutput(config)
#分享函数
def forward(self, hidden_states, attention_mask, layer_num, head_mask=None):
if isinstance(self.attention, nn.ModuleList):
# 处理attention
attention_outputs = self.attention[layer_num](hidden_states, attention_mask, head_mask)
else:
attention_outputs = self.attention(hidden_states, attention_mask, head_mask)#经过这
#因为所有的输出都加了一个attention list,到这里处理完self 和 残差连接
attention_output = attention_outputs[0]
#如果是这个就不用feed层
if self.ln_type == 'preln':
if isinstance(self.intermediate, nn.ModuleList):
# share attention 自注意力机制
attention_output_pre = self.output[layer_num].LayerNorm(attention_output)
else:
attention_output_pre = self.output.LayerNorm(attention_output)
else:
attention_output_pre = attention_output
#处理feed forward, 输出层
if isinstance(self.intermediate, nn.ModuleList):
# share attention
intermediate_output = self.intermediate[layer_num](attention_output_pre)
layer_output = self.output[layer_num](intermediate_output, attention_output)
else:
intermediate_output = self.intermediate(attention_output_pre)
layer_output = self.output(intermediate_output, attention_output)
outputs = (layer_output,) + attention_outputs[1:]
return outputs
取出cls
就是把输出的cls向量取出来做分类任务,解释是,经过attention机制,cls也获得了句子中所有字的信息
class BertPooler(nn.Module):
def __init__(self, config):
super(BertPooler, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)#312,312
self.activation = nn.Tanh()#激活函数
def forward(self, hidden_states):
#就是简单的把cls取出来
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
预训练的训练方式
这下面的模型都只是预先处理,后面LM要进行soft,而NOP也要进行个预测,比较简单,就不贴出来了。
class AlbertLMPredictionHead(nn.Module):
def __init__(self, config):
super(AlbertLMPredictionHead, self).__init__()
self.transform = BertPredictionHeadTransform(config)
#上面是创建一个线性映射层, 把transformer block输出的[batch_size, seq_len, H]映射为[batch_size, seq_len, vocab_size], 也就是把最后一个维度映射成字典中字的数量, 获取MaskedLM的预测结果
self.project_layer = nn.Linear(config.hidden_size, config.embedding_size, bias=False)
self.decoder = nn.Linear(config.embedding_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.project_layer(hidden_states)
hidden_states = self.decoder(hidden_states) + self.bias
return hidden_states
class AlbertPreTrainingHeads(nn.Module):
def __init__(self, config):
super(AlbertPreTrainingHeads, self).__init__()
#调用上面类进行LM训练
self.predictions = AlbertLMPredictionHead(config)
#映射成2,进行NOP的训练
self.seq_relationship = nn.Linear(config.hidden_size, 2)
#
def forward(self, sequence_output, pooled_output):
prediction_scores = self.predictions(sequence_output)
seq_relationship_score = self.seq_relationship(pooled_output)
return prediction_scores, seq_relationship_score