Word2Vec如何优化从中间层到输出层的计算?
重要性:★★
用负采样优化中间层到输出层的计算
以词汇量为 100 万个、中间层的神经元个数为 100 个的 wod2vec(CBOW 模型)为例,word2vec 进行的处理如下图所示.
词汇量为100万个时的word2vec:上下文是you和goodbye,目标词是say :
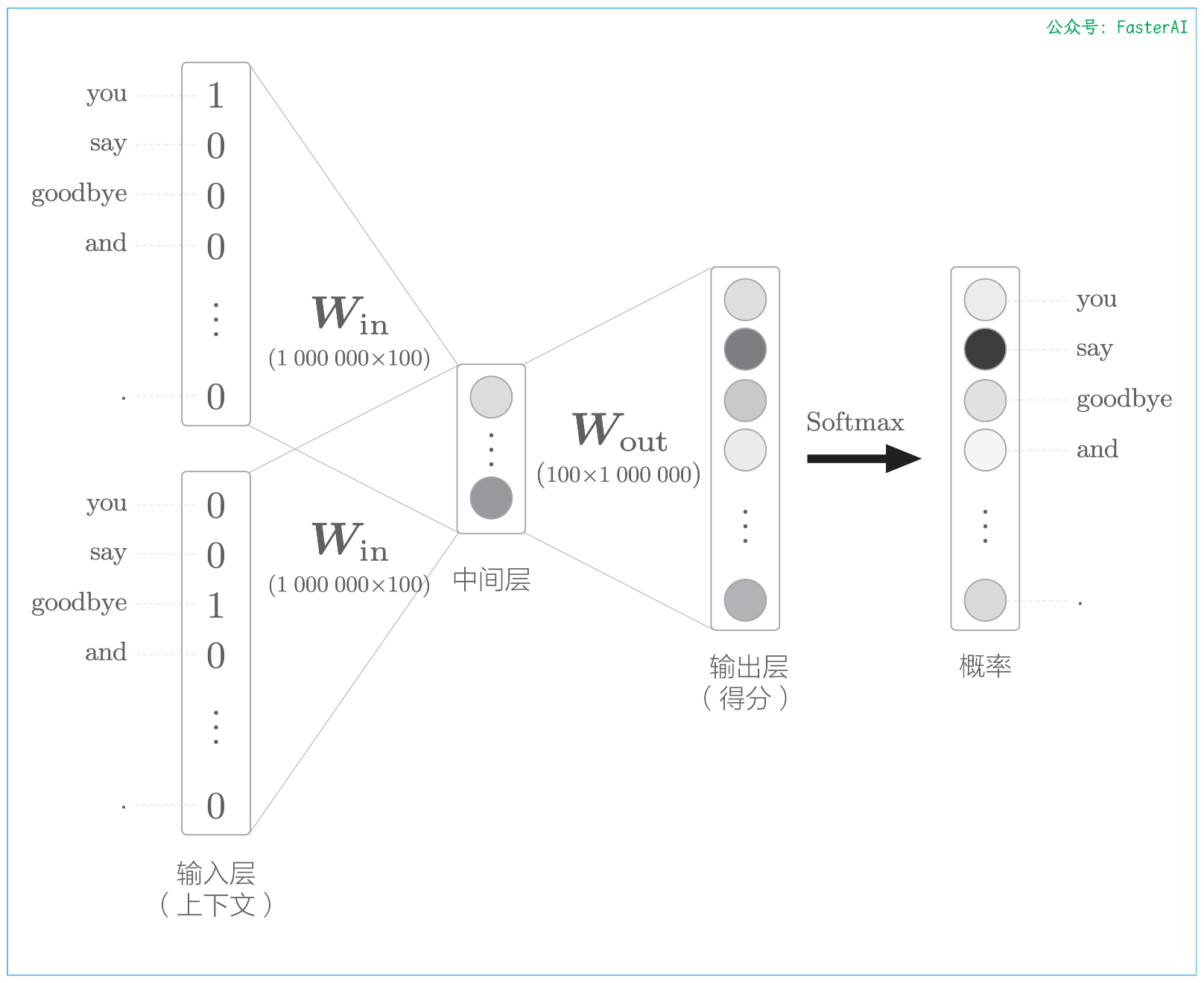
词汇量是 100 万个的情况下,模型输出时需要预测所有词(100万个)的概率。此时,在以下两个地方需要很多计算时间:
- 问题1:中间层的神经元和权重矩阵( W o u t W_{out} Wout)的乘积,这个问题在于巨大的矩阵乘积计算
- 问题2:Softmax 层的计算,随着词汇量的增加,Softmax 的计算量也会增加。
因为假定词汇量是 100 万个,Softmax的分母需要进行 100 万次的 exp 计算。这个计算也与词汇量成正比,因此,需要一个可以替代 Softmax 的“轻量”的计算。我们将采用名为负采样(negative sampling) 的方法作为解决方案,使用 Negative Sampling 替代 Softmax,无论词汇量有多大,都可以使计算量保持较低或恒定。
负采样方法的关键思想
负采样方法的关键思想在于二分类(binary classification),更准确地说,是用二分类拟合多分类(multiclass classification),这是理解负采样的重点。现在,我们来考虑如何将多分类问题转化为二分类问题。
比如,让神经网络来回答“当上下文是 you 和 goodbye 时,目标词是 say 吗?”这个问题,这时输出层只需要一个神经元即可。可以认为输出层的神经元输出的是 say 的得分。此时 CBOW 模型进行什么样的处理呢?如下图所示,仅计算目标词的得分的神经网络。
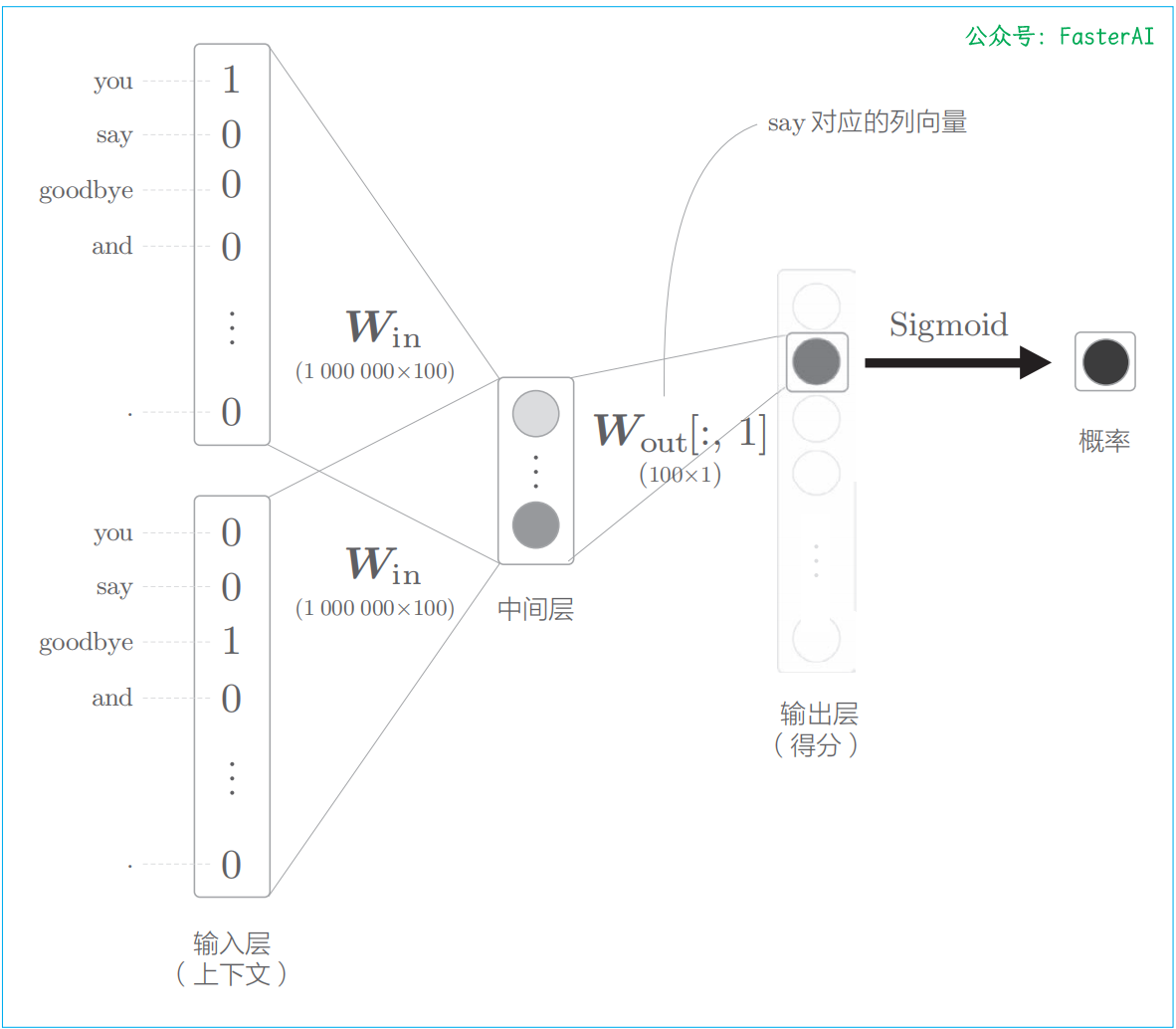
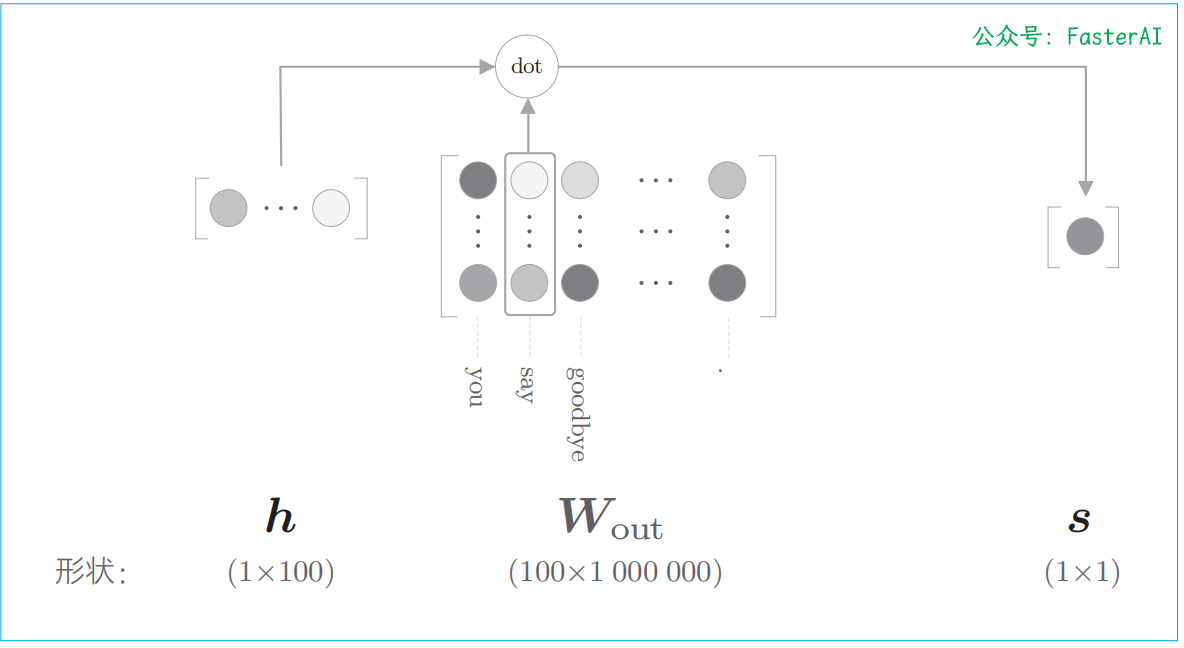
输出层的神经元仅有一个。因此,要计算中间层和输出侧的权重矩阵的乘积,只需要提取 say 对应的列(单词向量),并用它与中间层的神经元计算内积即可。这个计算的详细过程如下图所示:
进行二分类的CBOW模型的全貌图:
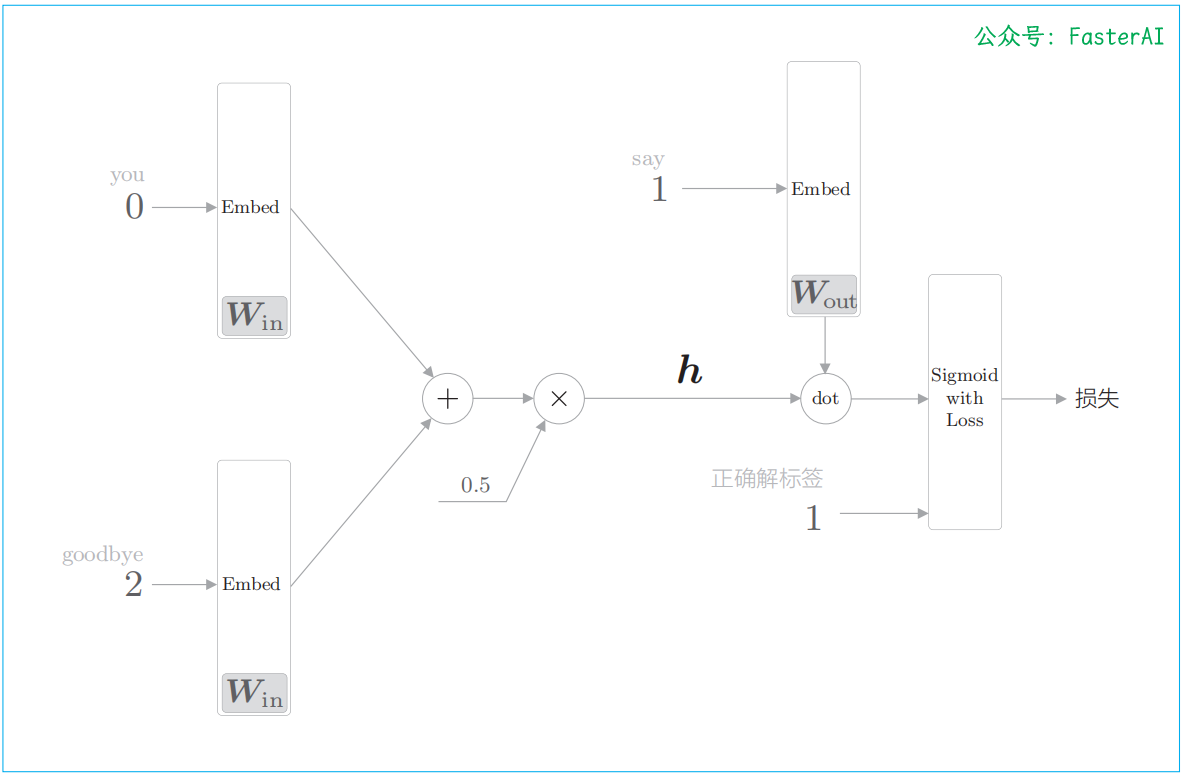
至此,我们成功地把要解决的问题从多分类问题转化成了二分类问题。但是,这样问题就被解决了吗?很遗憾,事实并非如此。因为我们目前仅学习了正例(正确答案),还不确定负例(错误答案)会有怎样的结果。
为了把多分类问题处理为二分类问题,对于“正确答案”(正例)和“错误答案”(负例),都需要能够正确地进行分类(二分类)。
那么,我们需要以所有的负例为对象进行学习吗?答案显然是“No”。如果以所有的负例为对象,词汇量将暴增至无法处理。为此,作为一种近似方法,我们将选择若干个(5 个或者 10 个)负例(如何选择将在下文介绍)。也就是说,只使用少数负例。这就是负采样方法的含义。
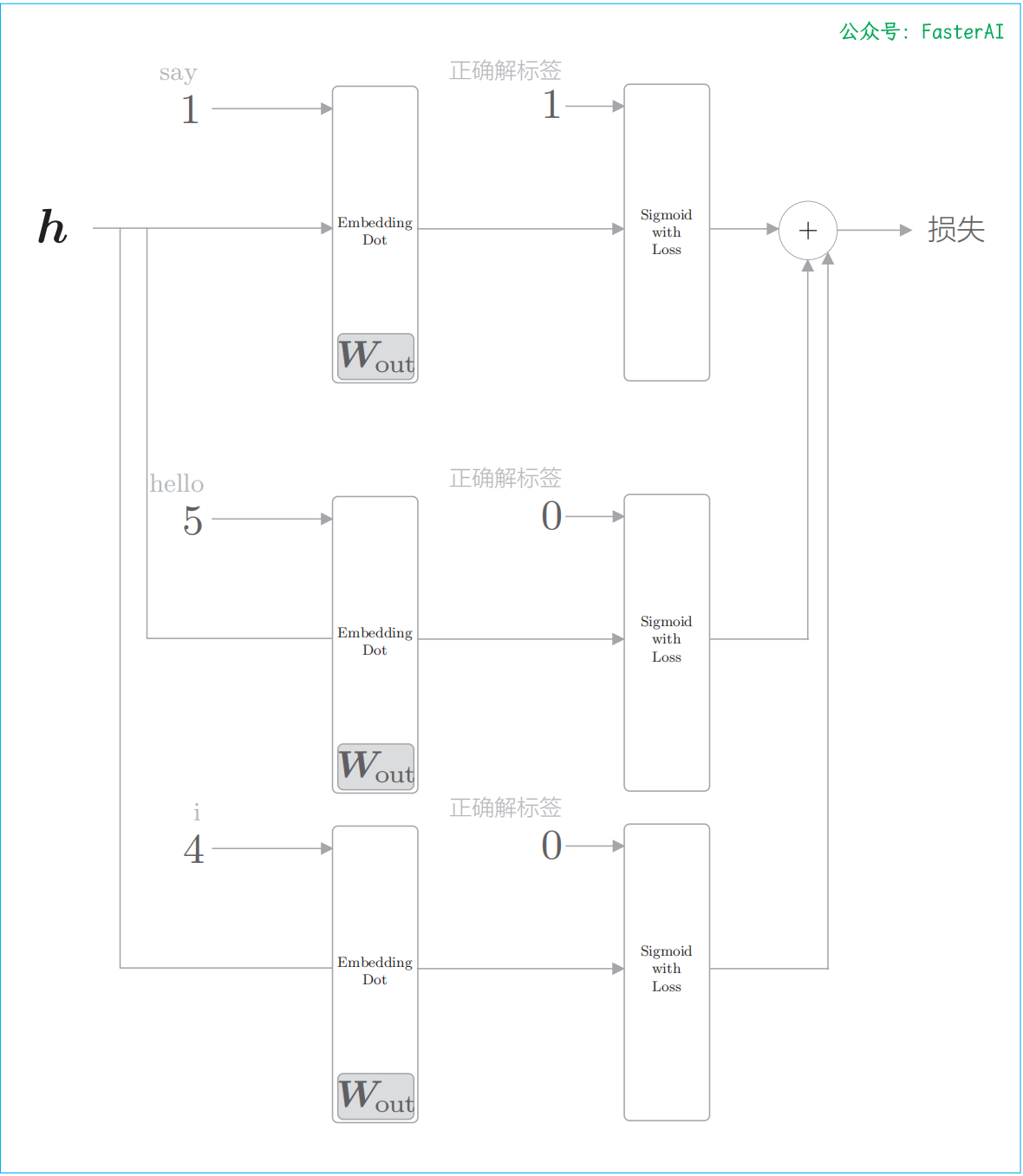
总而言之,负采样方法既可以求将正例作为目标词时的损失,同时也可以采样(选出)若干个负例,对这些负例求损失。然后,将这些数据(正例和采样出来的负例)的损失加起来,将其结果作为最终的损失。
负采样的例子
负采样的例子(只关注中间层之后的处理,画出基于层的计算图):
负采样的采样方法
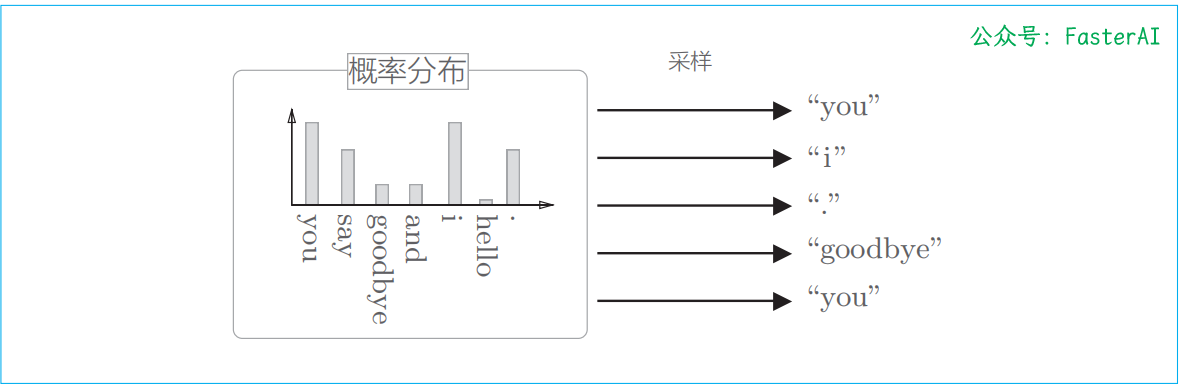
负采样的采样方法:基于语料库的统计数据进行采样的方法比随机抽样要好。基于语料库中单词使用频率的采样方法会先计算语料库中各个单词的出现次数,并将其表示为“概率分布”,然后使用这个概率分布对单词进行采样。
根据概率分布多次进行采样的例子:
为了防止低频单词被忽略。word2vec 中提出的负采样对刚才的概率分布增加了一个步骤:对原来的概率分布取 0.75 次方。通过这种方式,取 0.75 次方作为一种补救措施,使得低频单词稍微更容易被抽到。此外,0.75 这个值并没有什么理论依据,也可以设置成0.75 以外的值。
利用“部分”数据而不是“全部”数据,这是一个重要思想。正如人不能全知全能一样,以当前的计算机性能,要处理所有的数据也是不现实的。相反,仅处理对我们有用的那一小部分数据会有更好的效果。负采样技术就是基于这种思想设计的,通过仅关注部分单词实现了计算的高速化。