
完整数据集下载:下载链接
1 前言
在当今数字化时代,图像处理和分析已经成为了科学研究和技术应用领域的关键部分。在生物医学领域,图像分析对于诊断、治疗和疾病研究具有重要意义。本项目将带您深入了解 U-net 细胞分割技术,这是一种在生物医学图像领域广泛应用的语义分割方法,旨在精确地提取图像中细胞部分的像素点。通过学习如何应用 U-net,您将能够更有效地处理生物医学图像,并从中获取有价值的信息。
2 实验概述
实验目的: 在本项目中,我们旨在精确提取图片中的细胞部分像素点,以实现细胞分割。
实验数据集:实验数据集。
实验语言: 本项目主要使用了 Python 编程语言。
实验所需的库: 在实验中,我们使用了多个库,包括 PIL、numpy、torch 以及 opencv。如果你在安装后遇到问题,可以参考这篇博文:解决 opencv 安装问题。
实验数据集示例:
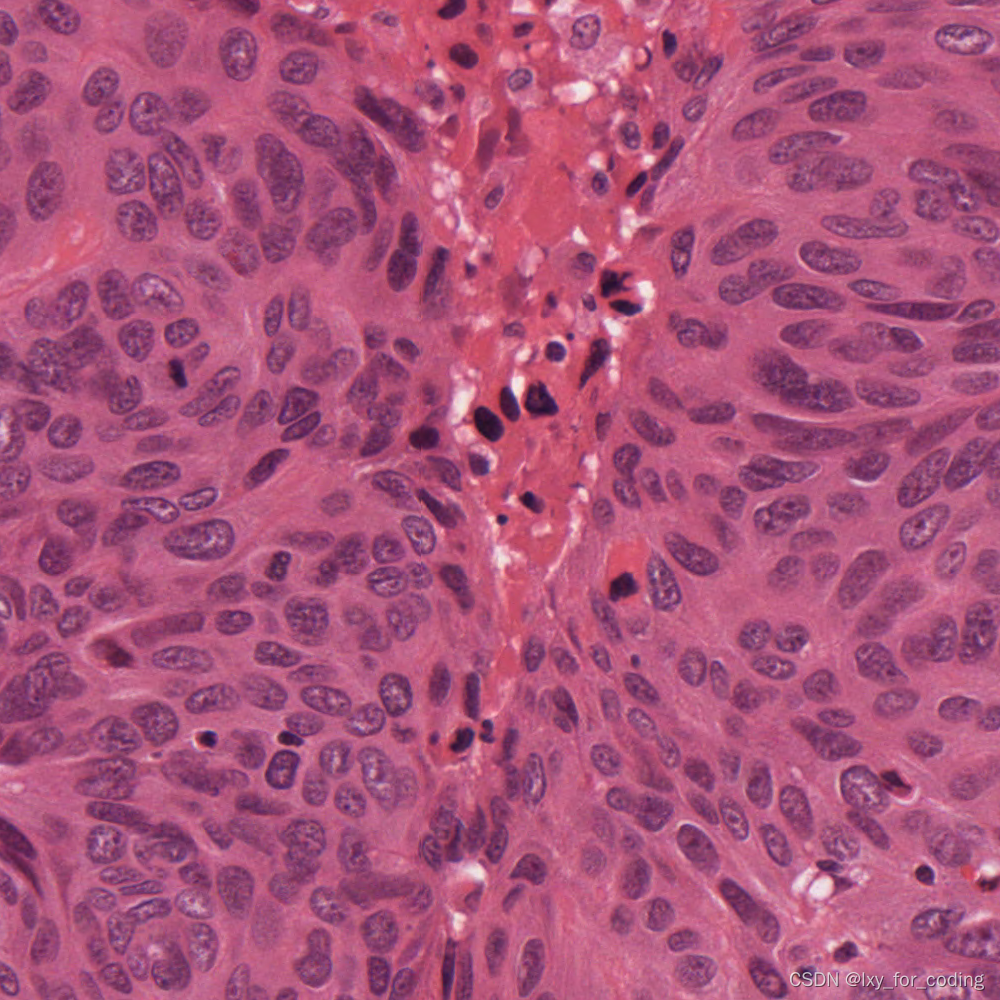
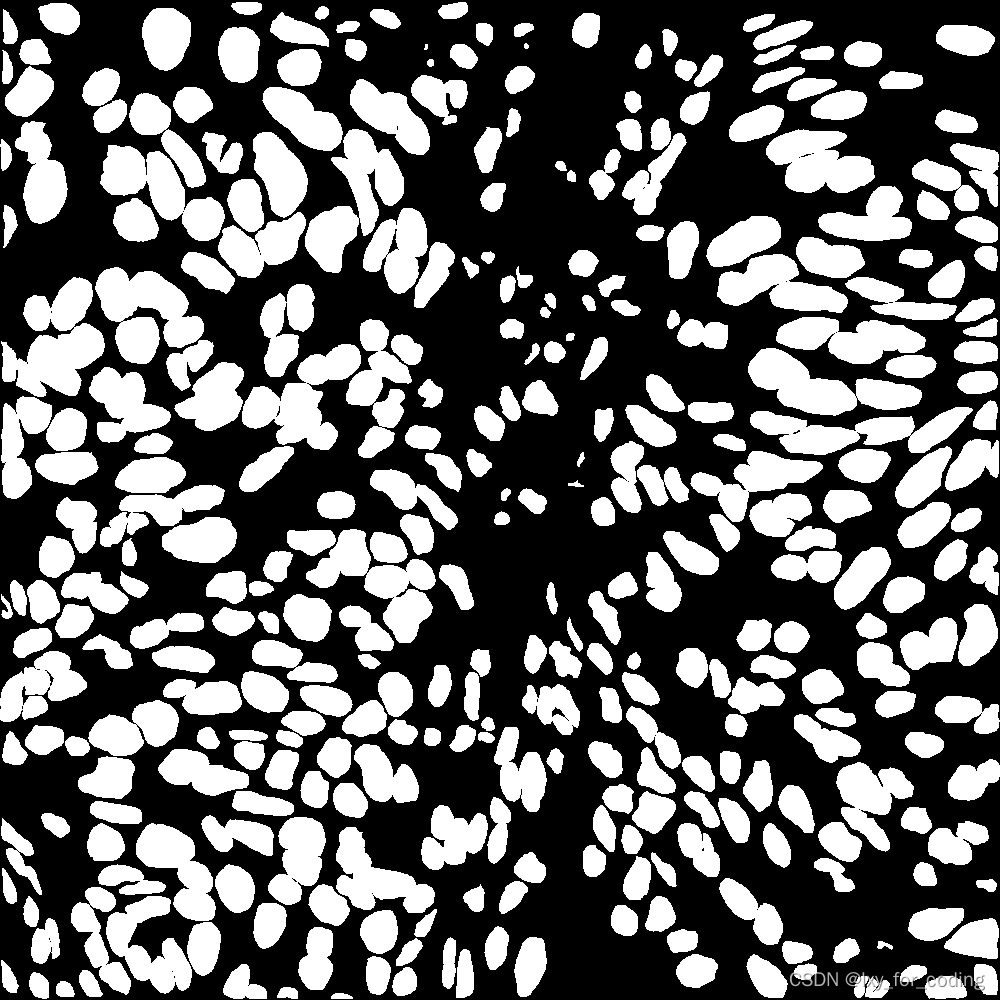
3 U-net 概述
在生物医学图像分析中,语义分割扮演着重要角色,应用广泛,涵盖了 x 射线、MRI 扫描、数字病理、显微镜、内窥镜等领域。更多关于 U-net 的详细讲解,请查看 U-net详细讲解。
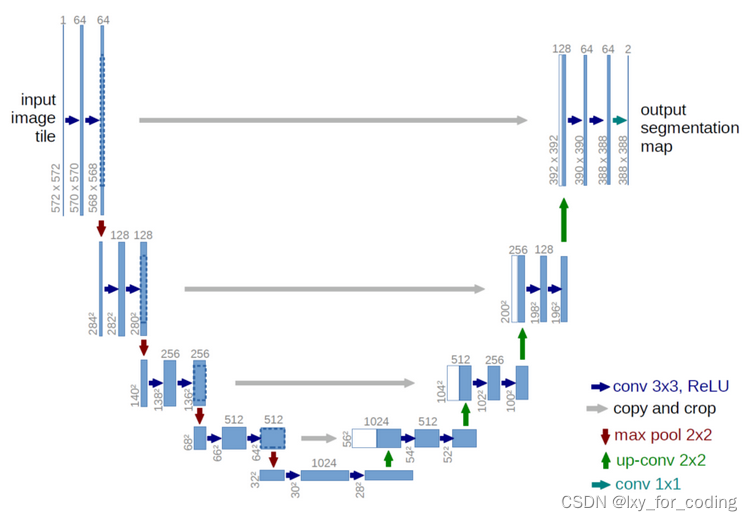
4 实验过程及代码
step1:导入相关的包
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, models, transforms
from torch.utils.data import Dataset, DataLoader
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
from torchsummary import summary
from PIL import Image
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
step2:加载数据
# 图片大小设置
img_size = (512, 512)
# 数据预处理的转换
transform = transforms.Compose([
transforms.ToTensor()
])
# 自定义数据集类
class MyData(Dataset):
def __init__(self, path, img_size, transform):
self.path = path
self.files = os.listdir(self.path+"/images")
self.img_size = img_size
self.transform = transform
def __getitem__(self, index):
fn = self.files[index]
img = Image.open(self.path + "/images/" + fn).resize(self.img_size)
mask = Image.open(self.path + "/masks/" + fn).resize(self.img_size)
if self.transform:
img = self.transform(img)
mask = self.transform(mask)
return img, mask
def __len__(self):
return len(self.files)
# 训练数据集
train_path = "train"
train_data = MyData(train_path, img_size, transform)
train_data_size = len(train_data)
train_dataloader = DataLoader(train_data, batch_size=8, shuffle=True)
# 测试数据集
test_path = "test"
test_data = MyData(test_path, img_size, transform)
test_data_size = len(test_data)
test_dataloader = DataLoader(test_data, batch_size=1, shuffle=True)
# 获取数据示例并可视化
img, mask = train_data.__getitem__(0)
img, mask = img.mul(255).byte(), mask.mul(255).byte()
img, mask = img.numpy().transpose((1, 2, 0)), mask.numpy().transpose((1, 2, 0))
# 可视化示例
fig, ax = plt.subplots(1, 3, figsize=(30, 10))
ax[0].imshow(img)
ax[0].set_title('Img')
ax[1].imshow(mask.squeeze())
ax[1].set_title('Mask')
ax[2].imshow(img)
ax[2].contour(mask.squeeze(), colors='k', levels=[0.5])
ax[2].set_title('Mixed')

step3 U-net模型构建
# 连续两次卷积的模块
class Double_Conv2d(nn.Module):
def __init__(self, in_channel, out_channel):
super(Double_Conv2d, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True))
self.conv2 = nn.Sequential(
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True))
def forward(self, inputs):
outputs = self.conv1(inputs)
outputs = self.conv2(outputs)
return outputs
# 上采样块
class Up_Block(nn.Module):
def __init__(self, in_channel, out_channel):
super(Up_Block, self).__init__()
self.conv = Double_Conv2d(in_channel, out_channel) # 卷积
self.up = nn.ConvTranspose2d(in_channel, out_channel, kernel_size=2, stride=2) # 反卷积上采样
def forward(self, inputs1, inputs2):
outputs2 = self.up(inputs2) # 上采样
padding = (outputs2.size()[-1] - inputs1.size()[-1]) // 2 # shape(batch, channel, width, height)
outputs1 = F.pad(inputs1, 2 * [padding, padding])
outputs = torch.cat([outputs1, outputs2], 1) # 合并
return self.conv(outputs) # 卷积
# Unet网络
class Unet(nn.Module):
def __init__(self, in_channel=3):
super(Unet, self).__init__()
self.in_channel = in_channel
# 特征缩放
filters = [16, 32, 64, 128, 256] # 特征数列表
# 下采样
self.conv1 = Double_Conv2d(self.in_channel, filters[0]) # 卷积
self.maxpool1 = nn.MaxPool2d(kernel_size=2) # 最大池化
self.conv2 = Double_Conv2d(filters[0], filters[1])
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = Double_Conv2d(filters[1], filters[2])
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.conv4 = Double_Conv2d(filters[2], filters[3])
self.maxpool4 = nn.MaxPool2d(kernel_size=2)
# center
self.center = Double_Conv2d(filters[3], filters[4])
# 上采样
self.Up_Block4 = Up_Block(filters[4], filters[3])
self.Up_Block3 = Up_Block(filters[3], filters[2])
self.Up_Block2 = Up_Block(filters[2], filters[1])
self.Up_Block1 = Up_Block(filters[1], filters[0])
# final conv
self.final = nn.Conv2d(filters[0], 1, kernel_size=1)
self.out = nn.Sigmoid()
def forward(self, inputs):
conv1 = self.conv1(inputs)
maxpool1 = self.maxpool1(conv1)
conv2 = self.conv2(maxpool1)
maxpool2 = self.maxpool2(conv2)
conv3 = self.conv3(maxpool2)
maxpool3 = self.maxpool3(conv3)
conv4 = self.conv4(maxpool3)
maxpool4 = self.maxpool4(conv4)
center = self.center(maxpool4)
up4 = self.Up_Block4(conv4, center)
up3 = self.Up_Block3(conv3, up4)
up2 = self.Up_Block2(conv2, up3)
up1 = self.Up_Block1(conv1, up2)
final = self.final(up1)
return self.out(final)
#创建模型实例,并查看3*512*512的输入图像在每层的参数和输出shape
model = Unet()#创建Unet模型实例
if use_gpu:model = model.cuda()#如果有GPU可用,则将模型转移到GPU上
print(summary(model,(3,512,512)))#输出模型参数
step4:模型训练
def train_model(model, dataloader, data_size, use_gpu, criterion, optimizer, scheduler, num_epochs):
best_model_wts = model.state_dict()#定义存储最佳模型的字典
best_loss = np.inf#定义最佳模型的损失
losslist = []
for epoch in range(num_epochs):
print('-' * 10, 'Epoch {}/{}'.format(epoch+1, num_epochs),'-' * 10)
model.train(True) # 设置模型为训练模式
running_loss = 0.0#定义当前轮迭代损失
for inputs, labels in dataloader:
if use_gpu:inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())#将输入输入转移到对应设备上
else:inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()# 初始化梯度
outputs = model(inputs)# Forward得到输出
loss = criterion(outputs.squeeze(1), labels.squeeze(1))#计算损失
loss.backward()#损失梯度反传
optimizer.step()#参数更新
running_loss += loss.item() * inputs.size(0)#训练损失求和
epoch_loss = running_loss / data_size
print('Loss: {:.4f}'.format(epoch_loss))#输出当前轮迭代损失平均值
scheduler.step()#学习率衰减
losslist.append(epoch_loss)
#保存最佳模型
if epoch_loss < best_loss:
print('Best Loss improved from {} to {}'.format(best_loss, epoch_loss))
best_loss = epoch_loss
best_model_wts = model.state_dict()
print('Best Loss: {:4f}'.format(best_loss))#输出最佳模型的损失
model.load_state_dict(best_model_wts)#加载最佳模型
return model, losslist
criterion = nn.BCEWithLogitsLoss()#定义损失函数
optimizer_ft = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)#参数优化器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#每7个epoch学习率下降0.1
num_epochs = 50#机器较差 仅训练10个epoch
#训练模型
model, losslist = train_model(
model=model,
dataloader=train_dataloader,
data_size=train_data_size,
use_gpu=use_gpu,
criterion=criterion,
optimizer=optimizer_ft,
scheduler=exp_lr_scheduler,
num_epochs=num_epochs)
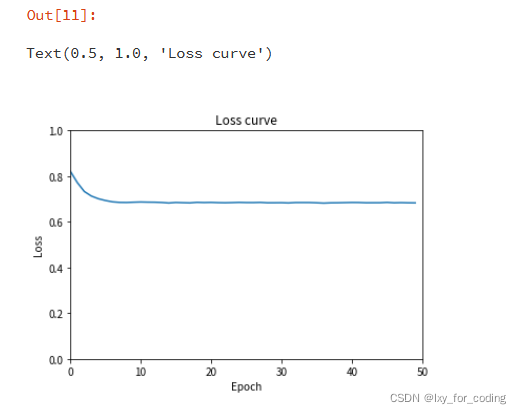
#可视化训练过程中损失变化
plt.xlim(0, len(losslist))
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.ylim(0, 1)
plt.plot(losslist)
plt.title('Loss curve')
step5:模型预测及评估
计算混淆矩阵和精度Acc的函数
# 获得混淆矩阵
def BinaryConfusionMatrix(prediction, groundtruth):
TP = np.float64(np.sum((prediction == 1) & (groundtruth == 1)))
FP = np.float64(np.sum((prediction == 1) & (groundtruth == 0)))
FN = np.float64(np.sum((prediction == 0) & (groundtruth == 1)))
TN = np.float64(np.sum((prediction == 0) & (groundtruth == 0)))
return TN, FP, FN,TP
# 准确率的计算方法
def get_accuracy(prediction, groundtruth):
TN, FP, FN,TP = BinaryConfusionMatrix(prediction, groundtruth)
accuracy = float(TP+TN)/(float(TP + FP + FN + TN) + 1e-6)
return accuracy
#加载测试数据
acc = []#用于存储每一张test图片的精度
model = model.to('cpu')
model.eval()#不使用BN和Dropout,防止预测图片失真
#Forward不存储梯度
with torch.no_grad():
for img, mask in test_dataloader:
pre = model(img)#Forward输出预测结果
pre = pre.mul(255).byte().squeeze().numpy()#转为uint8的array,方便计算精度
mask = mask.mul(255).byte().squeeze().numpy()
_, pre = cv2.threshold(pre,0,1,cv2.THRESH_BINARY | cv2.THRESH_OTSU)#THRESH_OTSU大津法二值化图像,方便计算精度
_, mask = cv2.threshold(mask,0,1,cv2.THRESH_BINARY | cv2.THRESH_OTSU)
acc.append(get_accuracy(pre, mask))#计算并存储精度
print('Acc:', [x for x in acc])#输出每张图的精度及平均精度
print('Mean_Acc:{}'.format(np.mean(acc)))
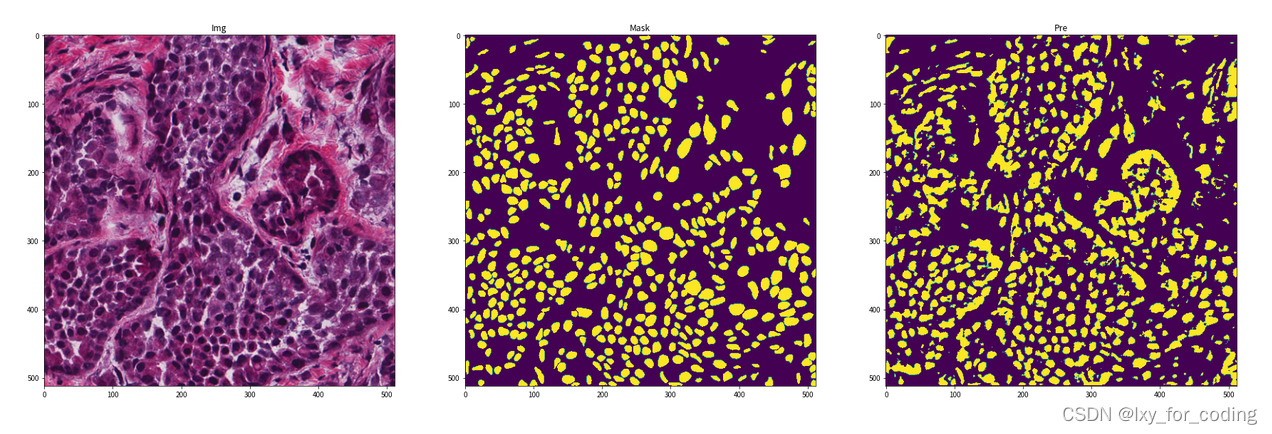
step6:可视化展示
img = img.mul(255).byte().squeeze().numpy().transpose((1, 2, 0))
print("img.shape={}, mask.shape={}, pre.shape={}".format(img.shape, mask.shape, pre.shape))
fig, ax = plt.subplots(1, 3, figsize=(30, 10))
ax[0].imshow(img)
ax[0].set_title('Img')
ax[1].imshow(mask)
ax[1].set_title('Mask')
ax[2].imshow(pre)
ax[2].set_title('Pre')
5 结语
在我们探索这个 U-net 细胞分割项目的过程中,我们深入了解了在生物医学图像分析领域中的重要应用。通过这个项目,我们更加理解了 U-net 这一强大的语义分割方法,它能够精确地提取细胞图像中的像素点,为生物医学领域的研究和诊断提供了重要支持。
在本文中,我们首先介绍了实验的目的以及所用的数据集、必要的 Python 库和技术。接下来,我们详细解释了 U-net 的工作原理,并探讨了它在生物医学图像分割中的广泛应用。通过深入挖掘相关资源,我们更深入地了解了 U-net 在生物医学领域的多种应用场景和挑战。
此外,我们还通过示例代码演示了如何加载和预处理数据集,构建 U-net 模型,并对其进行训练和预测。通过详细的代码注释,我们希望能让你更容易理解每个步骤的目的和功能。最后,我们展示了一些图像示例,向你展示了 U-net 分割模型的效果。
综上所述,这个 U-net 细胞分割项目为生物医学图像分析领域的研究和实际应用提供了强大工具。通过深入研究这个项目,我们更好地理解了 U-net 的原理和应用,也为未来的研究和创新铺平了道路。无论是自动化医学影像分析,还是更准确的疾病诊断,U-net 都将在生物医学领域持续发挥着重要作用。在这个不断进步的领域中,我们期待着更多人能够借助 U-net 和类似的技术,为医学科学的进步贡献自己的一份力量。
