损失函数的作用:衡量模型预测的好坏。
简单来说就是,损失函数就是用来表现预测与真实数据的差距程度。
令 真实值 为Y,预测值为 f(x),损失函数为L( Y , f(x)),关系如下:

损失函数(loss funtion)是用来估量模型的预测值和真实值的不一样程度,它是一个非负实值函数。损失函数越小,模型的鲁棒性就越好。
例子:
X:门店数 Y:销量
我们会发现销量随着门店数上升而上升。于是我们就想要知道大概门店和销量的关系是怎么样的呢?
我们根据图上的点描述出一条直线:
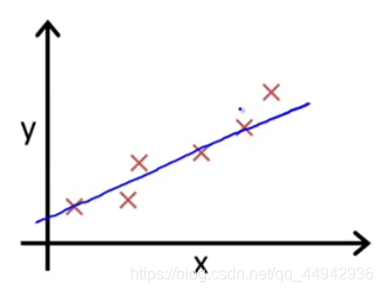
似乎这个直线差不多能说明门店数X和Y得关系了:我们假设直线的方程为Y=a0+a1X(a为常数系数)。假设a0=10 a1=3 那么Y=10+3X(公式1)
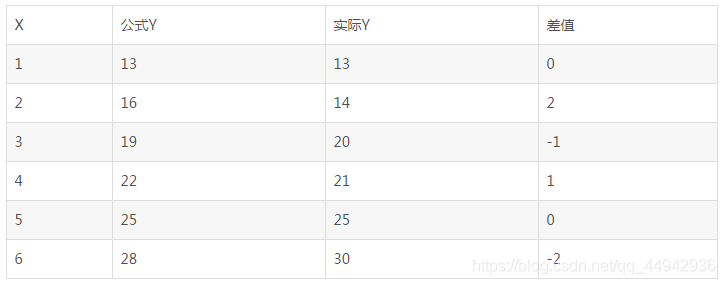
我们希望我们预测的公式与实际值差值越小越好,所以就定义了一种衡量模型好坏的方式,即损失函数(用来表现预测与实际数据的差距程度)。于是乎我们就会想到这个方程的损失函数可以用绝对损失函数表示:
公式Y-实际Y的绝对值,数学表达式:
上面的案例它的绝对损失函数求和计算求得为:6
为后续数学计算方便,我们通常使用平方损失函数代替绝对损失函数:
公式Y-实际Y的平方,数学表达式:L(Y,f(X))=
上面的案例它的平方损失函数求和计算求得为:10
以上为公式1模型的损失值。
假设我们再模拟一条新的直线:a0=8,a1=4
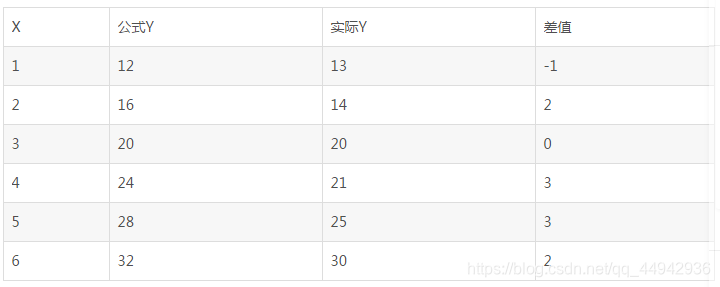
公式对比,学习损失函数的意义
公式2 Y=8+4X
绝对损失函数求和:11 平方损失函数求和:27
公式1 Y=10+3X
绝对损失函数求和:6 平方损失函数求和:10
从损失函数求和中,就能评估出公式1能够更好得预测门店销售。
统计学习中常用的损失函数有以下几种:
1】0-1损失函数(gold standard标准式)
0-1损失函数是指,预测值与损失值不相等为1,否则为0.
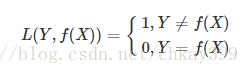
该函数不考虑预测值和真实值的误差程度,也就是说只要预测错误,预测错误差一点和差很多是一样的,感知机就是用的这种损失函数,但是由于相等这个条件太过严格,我们可以放宽条件:
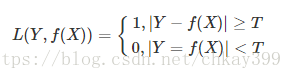
这种损失函数用在实际场景中比较少,更多的是用俩衡量其他损失函数的效果。
2】绝对损失函数
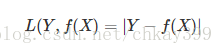
3】平方损失函数(squared loss)
实际结果和观测结果之间差距的平方和,一般用在线性回归中,可以理解为最小二乘法:
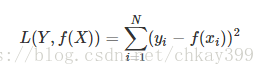
4】对数损失函数(logarithmic loss)
主要在逻辑回归中使用,样本预测值和实际值的误差符合高斯分布,使用极大似然估计的方法,取对数得到损失函数:
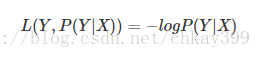
损失函数L(Y,P(Y|X))L(Y,P(Y|X))是指样本X在分类Y的情况下,使概率P(Y|X)达到最大值。
经典的对数损失函数包括entropy和softmax,一般在做分类问题的时候使用(而回归时多用绝对值损失(拉普拉斯分布时,μ值为中位数)和平方损失(高斯分布时,μ值为均值))。
5】指数损失函数(Exp-Loss)
在boosting算法中比较常见,比如Adaboosting中,标准形式是:
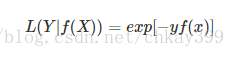
6】铰链损失函数(Hinge Loss)
铰链损失函数主要用在SVM中,Hinge Loss的标准形式为:
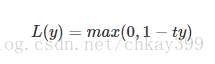
y是预测值,在-1到+1之间,t为目标值(-1或+1)。其含义为,y的值在-1和+1之间就可以了,并不鼓励|y|>1|y|>1,即并不鼓励分类器过度自信,让某个正确分类的样本的距离分割线超过1并不会有任何奖励,从而使分类器可以更专注于整体的分类误差。
损失函数越小,模型就越好。
总结:
损失函数可以很好的反应模型与实际数据差距的工具,理解损失函数能够更好得对后续优化工具(梯度下降等)进行分析与理解,很多时候遇见复杂的问题,最难的一关是如何写出损失函数。
参考:
(19条消息) 损失函数的意义及作用(含有帮助理解的例子)_万分之一的的博客-CSDN博客_损失函数的意义和作用
(19条消息) 机器学习总结(三)——损失函数_chkay399的博客-CSDN博客_损失函数