📖标题:Model-in-the-Loop (MILO): Accelerating Multimodal AI Data Annotation with LLMs
🌐来源:arXiv, 2409.10702
摘要
🔸对人工智能训练数据日益增长的需求已经将数据标注转变为一个全球性的行业,但依赖人工标注的传统方法往往耗时、劳动密集,而且质量不一致。我们提出了模型in-the-Loop(MILO)框架,该框架将AI/ML模型集成到注释过程中。
🔸我们的研究引入了一种协作范式,该范式利用了专业人类注释者和大型语言模型(LLM)的优势。通过使用LLM作为预注释和实时助手,并对注释者的响应进行判断,MILO实现了人类注释者和LLM之间的有效交互模式。
🔸三项关于多模态数据注释的实证研究证明了MILO在减少处理时间、提高数据质量和增强注释者体验方面的有效性。我们还引入了质量量规,用于对开放式注释进行灵活评估和细粒度反馈。MILO框架对加速AI/ML开发、减少对人类神经的依赖以及促进人类和机器价值观之间的更好一致性具有重要意义。
🛎️文章简介
🔸研究问题:在大规模生产任务中,如何通过将AI/ML模型(包括LLM)集成到人类标注过程中,以提高标注效率和质量?
🔸主要贡献:论文提出了MILO框架,通过人机协作提高标注效率和质量,还通过这些标注增强LLM的开发,从而创建一个更高效的标注生命周期。
📝重点思路
🔺相关工作
🔸用模型扩展数据集:模型辅助具有成本效益,是劳动密集型注释的替代方案。
🔸模型优于众包注释器:ChatGPT的每个注释成本明显低于众包工作者。
🔸模型增强人类注释者:模型可以充当过滤器来选择信息最丰富的数据进行人工审查或验证,也称为联合注释策略。
🔸模型辅助人类注释者:模型可以利用预测的置信度分数来预选或建议可能的标签,帮助注释者缩小决策空间并减少处理时间。
🔸模型作为人工标注的判断者:模型经过专门训练,可以评估和批评人类或其他模型生成的响应,或者根据预定义的标准或错误代码对多个响应进行排名。
🔸LLM开发的数据注释:人工智能反馈强化学习 (RLAIF)和宪法人工智能等技术,采用模型产生偏好作为奖励信号。
🔺论文方案
🔸MILO框架设计:该框架模型无关,可以集成现有的模型,并根据模型在标注生命周期中的不同角色(助手、标注者或评判者)进行设计。
🔸双向协作:MILO框架不仅利用LLM来改进标注过程,还利用这些标注来增强LLM的开发,从而形成一个双向协作的标注框架。
🔸实验评估:一系列在内部标注平台上进行的实验,评估MILO框架的有效性,包括模型作为UI助手提供建议和上下文,以及模型在实时标注过程中的辅助作用。
🔸用户反馈收集:通过收集标注者的反馈,评估LLM助手在减轻标注疲劳、提供结构化答案等方面的效果。
🔎分析总结
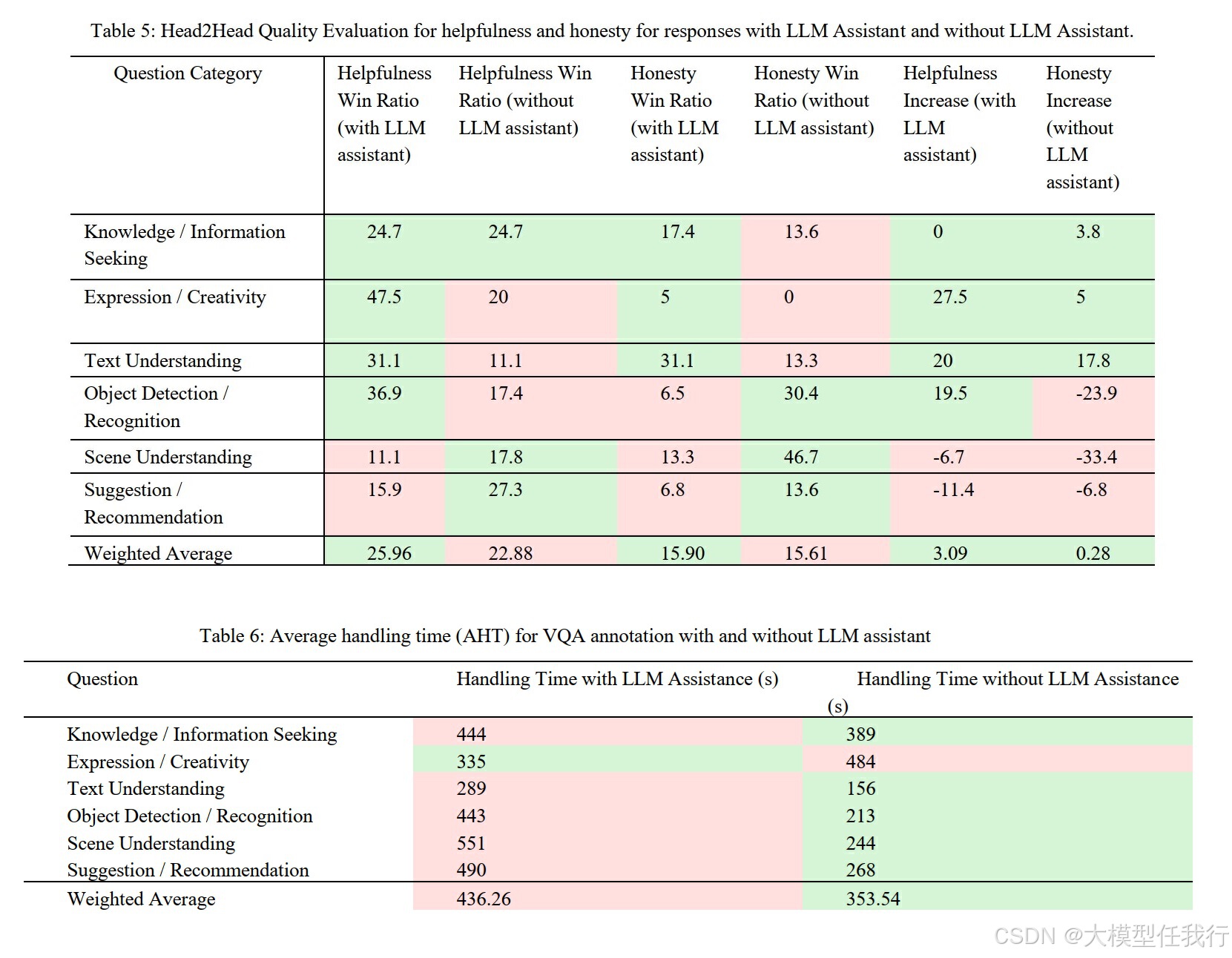
🔸提升标注效率:预标注的LLM助手可以支持标注者的决策,并将标注时间减少了12%。
🔸减轻标注疲劳:LLM助手在实时标注过程中显著减轻了标注者的创作疲劳,提供了结构化的文本生成任务支持。
🔸模型评判的有效性:LLM评判者与专家研究者的意见一致率达到79.55%,表明其作为有效评判者的潜力,可以扩展QA覆盖范围并优化宝贵的审计资源。
🔸减少人类标注偏差:通过更好的标注者教育和清晰的标注指南,可以减轻模型幻觉对标注过程的影响。
🔸增强人机协作:MILO框架促进了人与AI之间的共创,标注者可以主动参与生成过程,并通过编辑和细化生成的输出,实现更高质量的标注。
💡个人观点
论文的核心是通过双向协作的方式,将LLM集成到人类标注过程中,以提高标注效率和质量,并增强LLM的开发。
附录