之前对于整个项目的优化不够清晰,在参考了一些笔记以及官方文档之后,重新尝试一次并记录分享。
模型参数设置
对于这部分,基于这篇笔记,以及我之前得到的结果来说,降低随机性和增大tokens和输出时间确实有助于模型的要素提取。故设置跟这位大佬一样。Datawhale AI夏令营-大模型技术实践:基于基于星火大模型的群聊对话分角色要素提取个人心得 - 知乎 (zhihu.com)
数据清洗
对于这部分跟之前的想法一样,一部分为是进行手工清洗,例如去除图片、超链接等,另外一部分使用大模型进行清洗。其实大模型在进行清洗的时候就已经清洗得非常不错了,只保留了关键性的信息。重点是对数据集进行构造,确定数据集的instruction、输入和输出。个人认为这部分还是属于特别重要的,一方面清洗过后的数据还是存在上下文过长的问题,对于模型来说记忆比较困难,另外一方面在我是如何赢得GPT-4提示工程大赛冠军的 (qq.com)这篇文章中也对数据的输入、输出格式有强调。所以对于这部分我只使用了官方文档里面的数据清洗和数据集构造的方法。没有再额外进行手工清洗。

以上是部分训练集,可以看出微调的训练集作出了新的规范,分为三个大类,instruction、input、output,这样做将复杂任务分解为简单任务,有利于后续任务的进行。

再来分析一下大模型数据清洗的prompt,根据这篇文章提出的我是如何赢得GPT-4提示工程大赛冠军的 (qq.com)prompt的CO-STAR架构,基本非常符合要求。
C:context,对话分析
O:object,分析数据,区分客户
S:style,数据分析大师
T:tone,没有要求
A:audience,只输出。。。不要无关内容
R:responce,md格式
开始微调
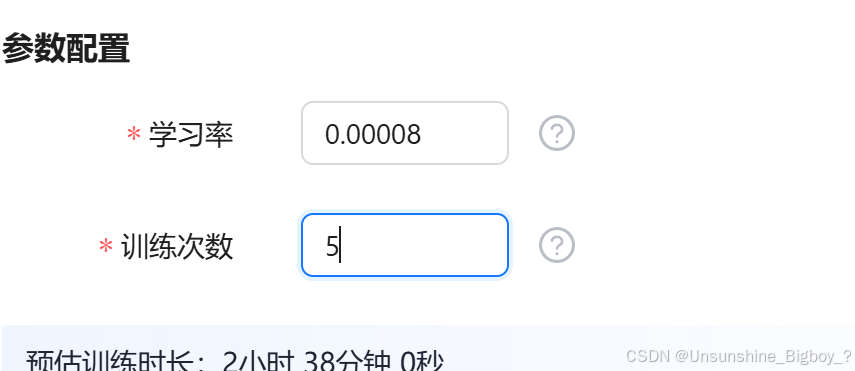
在生成了训练数据和测试数据之后,准备开始模型微调。在微调的参数设置方面,将训练次数设置为5观察是否会有更好的效果。
最终结果
最终结果有点可惜,不如第一次,说明多次训练的效果未必更好。
