【一】基础概念
【1】爬虫
(1)定义
- 爬虫,又称为网络爬虫或网络蜘蛛
- 是一种按照一定规则 自动抓取 ** 万维网信息的程序或者脚本**
(2)流程
- 发送请求
get还是post- 请求头内容等
- 获取响应
text还是content还是json等
- 解析响应
BeautifulSoup、lxml、re等
- 存储数据
mysql、csv、json等
(3)常见反爬措施
- 频率限制、封
IP或者封账号 - 请求头携带加密信息
Referer(来源页面地址)和User-Agent(浏览器标识)
- 设置验证码
JS加密- 使用
javascript对核心代码加密 - 函数和变量名的改变:
ers()变为function()等
- 使用
- 绑定手机设备
(2)分类
- 分类一
- 通用爬虫和定向爬虫
- 区别:是否针对特定网站
- 分类二
- 基于规则的爬虫和基于机器学习的爬虫
- 区别:依赖于指定的规则,还是机器学习学习算法自动优化
- 分类三
- 单机爬虫和分布式爬虫
- 区别:是否在多个服务器上同时运行
(3)注意事项
- 爬虫需要合法、合法、合法
- 爬虫的访问速度要限制
- 特殊环境的爬虫需要稳定性,保证异常不会终止程序
- 数据量不同,存储方式不同
【2】HTTP协议
(1)四大特性
- 基于请求-响应
- 客户端发送请求
- 等待服务端响应
- 基于
TCP/IP层之上- HTTP协议是应用层协议
- 依赖于底层的传输协议
- 无状态
- 不会保存客户端状态信息
- 每次访问都当成新用户
- 常见解决方案:Cookie、Session、Token等
- 无连接
- 每次请求都需要建立一个连接
- 在请求处理后关闭连接
- HTTP1.1引入持久连接
- 后续允许一个TCP连接发送多个请求和响应
(2)HTTP状态码
- 1 xx:信息状态码
- 表示服务器已经接收到请求并正在处理,但需要进一步的操作才能完成请求
- 例如:100 Continue状态码表示客户端应继续发送请求
- 2 xx:成功状态码
- 表示请求已被服务器接收、理解和处理
- 例如:200 OK状态码表示请求已经成功,服务器正常处理并返回了请求的资源
- 3 xx:重定向状态码
- 表示表示客户端需要进一步的操作才能完成请求,通常意味着需要重定向到另一个位置
- 例如:301 Moved Permanently状态码表示请求的资源已被永久的移动到新的URL
- 4 xx:客户端错误状态码
- 表示客户端发送的请求错误或无法完成
- 404 Not Found状态码表示服务器无法找到请求的资源
- 5 xx:服务器错误状态码
- 表示服务器在处理请求时发生了错误
- 503 Service Unavailable状态码表示服务器暂时无法处理请求,可能由于过载或维护
(3)HTTP请求
- 请求首行
- 请求的方法(get\post)、请求的URL和HTTP协议的版本
- 请求头
- 关于请求的各种附加信息,由字段名和字段值组成
- 字段名和字段值之间用冒号加空格分割
- 而每个字段结束后都有一个
CRLF(回车换行)
- 如:User-Agent(用户代理)、Accept-Language(接收的语言)等
- 关于请求的各种附加信息,由字段名和字段值组成
- 空行
- 用于分割请求头和请求体
- 必须有
- 请求体
- 请求体可选,通常用于POST请求或PUT请求,包含发送给服务器的数据
- 请求体的格式
urlencode形式的键值对Json格式formdata格式
(4)HTTP响应
- 响应首行
- 通常包含HTTP协议版本、状态码以及描述信息
- 响应头
- 包含响应的元数据,如服务器类型、日期、内容类型等
- 响应头由字段名和字段值组成。两者之间用冒号加空格分隔
- 空行
- 用于分割响应头和响应体
- 必须有
- 响应体
- 包含实际返回给用户的数据
- 可能是HTML文章、图片、Json数据等
(5)get请求和post请求对比
- get请求
- get请求通常没有请求体,数据通过URL传递
- 由于数据会附加在URL后面,因此大小受限于浏览器和服务器对URL长度的限制
- 触发的方式:网页中单击连接(a标签)、地址栏输入地址并回车、form表单默认触发get请求等
- post请求
- post请求将数据放在请求体中
- 理论上可以发送大量信息,具体大小取决于服务器配置
- 触发的方式:form表单改为POST提交数据、上传文件、发送
API请求等
【二】requests模块
【1】引言
-
requests模块基于内置模块urllib使用Python语言编写
- 采用Apache2 Licensed开源协议的HTTP库
-
安装
pip install requests
【2】发送请求
(1)请求参数
- url:发送请求地址,字符串
- headers:请求头,字典
- Host:指定目标服务器域名或IP
- User-Agent:表示发送请求用户代理(通常是浏览器)
- 可使用
fake_useragent模块的UserAgent对象随机random生成
- 可使用
- Accept:指定客户端能够接收的内容类型
- Accept-Language:指定客户端期望接收的语言
- Accept-Encoding:指定客户端支持的编码内容
- Content-Type:指定请求体的媒体类型
- Content-Length:指定请求体的长度(单位字节)
- Cookie:向服务器传递保存在浏览器中的Cookie信息
- 字符串格式
- Referer:指定源地址,可以用于图片防盗链等
- Location:在重定向响应中,提供重定向的目标URL
- Cache-Control:指定请求或响应的缓存策略
- params:携带参数,字典
- cookies:放在外面就要求是字典格式了,还可以是
requets.get().cookies对象
(2)get请求-百度示例
-
分析百度的URL地址栏发现,wd后面携带是搜索内容
-
https://www.baidu.com/s?wd=%E5%91%A8%E6%98%9F%E9%A9%B0
-
可以使用urlib模块的parse进行转换
-
encoded_text = urllib.parse.quote(chinese_text.encode('gbk')) decoded_text = urllib.parse.unquote(encoded_text).decode('gbk')
-
# 百度发送携带数据的get请求
import requests
from fake_useragent import UserAgent
# 使用随机生成发送请求用户代理
user_agent = UserAgent().random
headers = {
'User-Agent': user_agent,
}
# 指定访问地址
url = "https://www.baidu.com/?="
# 携带参数
params = {
"wd": "周星驰",
}
# 发送请求
res = requests.get(url, headers=headers, params=params)
print(res.text)
(3)get请求-京东示例
- 在登录成功的情况下
- 我们随便找个地址访问【爱国者爱国者GT8智能手表 黑色】爱国者(aigo)智能手表GT8男款健康监测血压心率多功能通话圆盘运动手表 黑色【行情 报价 价格 评测】-京东 (jd.com)
- 现在我们退出登录以后再次直接访问这个链接,会发现到了登录界面
- 即京东的详情界面是需要携带参数才可以访问的
- 登录以后查看详情界面抓包工具中的请求头
- 可以发现携带了cookie
- 现在尝试携带cookie爬虫访问
- 有时会访问失败(前方拥挤请刷新重试)
import requests
from fake_useragent import UserAgent
# 使用随机生成发送请求用户代理
user_agent = UserAgent().random
headers = {
'User-Agent': user_agent,
# 方式一
# cookie直接复制放在headers中
"Cookie": "",
}
# 指定访问地址
url = "https://item.jd.com/100058029494.html"
# 发送请求, 方式一
res = requests.get(url, headers=headers)
print(res.text)
import requests
from fake_useragent import UserAgent
# 使用随机生成发送请求用户代理
user_agent = UserAgent().random
headers = {
'User-Agent': user_agent,
}
# 指定访问地址
url = "https://item.jd.com/100070683706.html"
# 方式二
# cookie是一个字典
# 将浏览器的cookie进行字符串处理
def cookie_operate(cookies_str):
return {key: value for key, value in [cookies.split("=", 1) for cookies in cookies_str.split(";")]}
cookies = ""
cookies = cookie_operate(cookies)
# 发送请求, 方式二
res = requests.get(url, headers=headers, cookies=cookies)
print(res.text)
(4)post请求的两个参数(传递请求体)
-
data参数
-
data用于发送非json格式的请求体,比如表单数据
-
他通常是一个字典、元组列表、字节字符串或文件对象
-
默认情况下,requests库会将data编码为
application/x-www-form-urlencoded格式。 -
发送其他数据类型(XML或文本)类型,可自定义
-
# 发送XML数据 xml_data = b'<xml>...</xml>' response = requests.post(url, data=xml_data, headers={'Content-Type': 'application/xml'}) # 发送自定义格式的文本 text_data = 'Some custom text' response = requests.post(url, data=text_data, headers={'Content-Type': 'text/plain'})
-
-
Json参数
-
json参数用于发送JSON格式的请求体。
-
requests库会自动将Python对象转换为JSON字符串,并设置Content-Type头部为application/json
-
import requests url = 'http://example.com/api' payload = {'key1': 'value1', 'key2': 'value2'} response = requests.post(url, json=payload)
-
-
注意
- 两个参数不可同时使用
- 发送json数据,优先使用json参数,可以自动处理头部编码和头部设置
- 需要发送非json数据,并想自定义Content-Type,那就用data
(5)post请求-华华手机示例
-
http://www.aa7a.cn/user.php -
目标网址没有后端验证码的验证
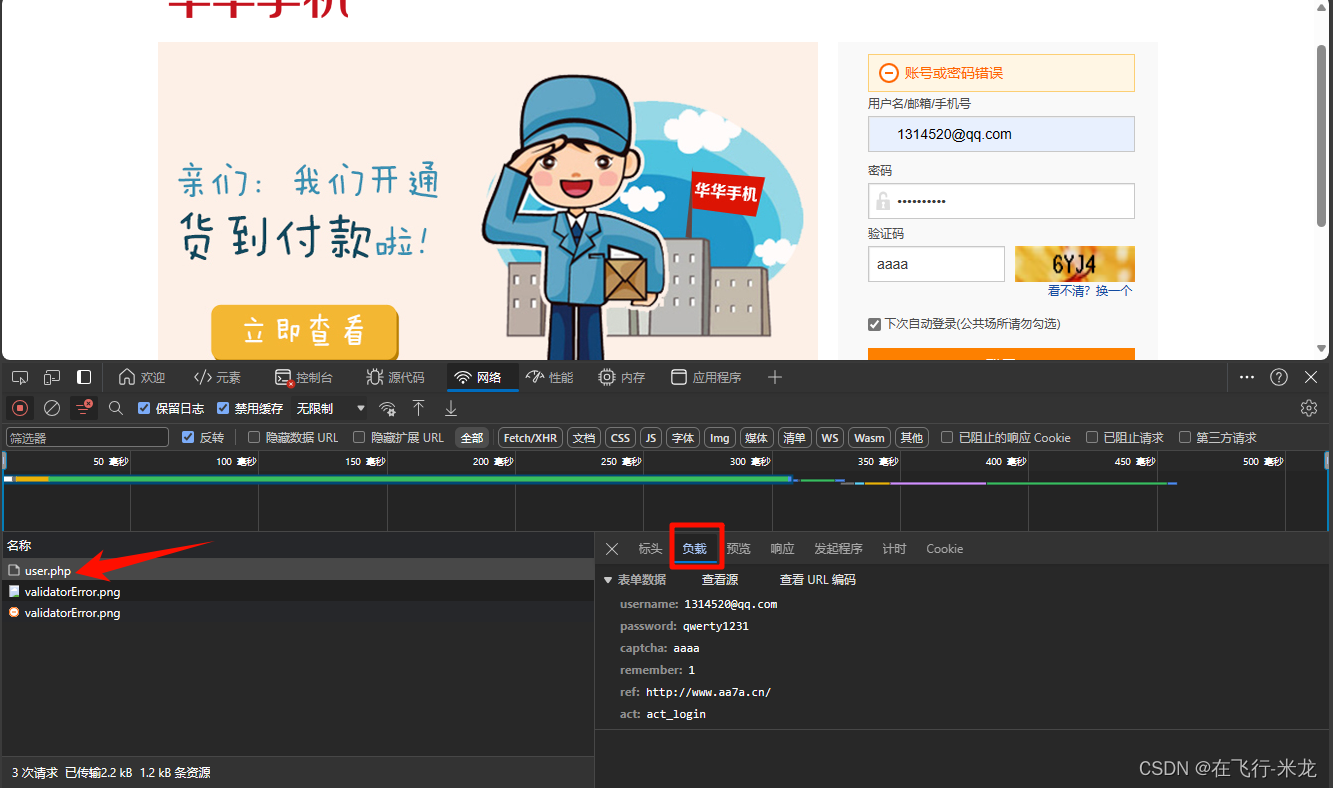
import requests
from fake_useragent import UserAgent
# 使用随机生成发送请求用户代理
user_agent = UserAgent().random
headers = {
'User-Agent': user_agent,
}
# 指定访问地址
url = "http://www.aa7a.cn/user.php"
# post请求携带数据
data = {
"username": "[email protected]",
"password": "qwerty123",
"captcha": "aaaa",
"remember": "1",
"ref": "http://www.aa7a.cn/",
"act": "act_login"
}
res = requests.post(url, headers=headers, data=data)
print(res.text)
# {"error":0,"ref":"http://www.aa7a.cn/"}
print(res.status_code)
# 200
(6)get请求案例-雪球网
-
这个网址是雪球网中的一个地址
-
这是雪球网的官网
-
存在这么一个现象
- 当你直接访问这个网址时,你是拿不到数据的
- 但是当你加载雪球网的首页以后,再次刷新上面的地址你就可以拿到数据了
-
通过抓包对比
- 发现在进入官网以后再次进行那个信息页时
- cookie增加了很多很多
-
那么就尝试先get请求拿到访问官网的cookie
- 然后再携带cookie访问详情页面试试
import requests
from fake_useragent import UserAgent
# 请求头 指定用户代理是浏览器
headers = {
"User-Agent": UserAgent().random,
}
# 主页路由
home_url = "https://xueqiu.com/"
# 详情地址
info_url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
# 获取首页cookie
home_cookie = requests.get(url=home_url, headers=headers).cookies
# 由于返回的是requests.cookies.RequestsCookieJar对象
# requests中的cookie参数可以接收字典也可以接收这个对象
# 所以可以对类型不处理
# home_cookie = dict(home_cookie)
# 向详情页发送请求拿数据
res = requests.get(headers=headers, url=info_url, cookies=home_cookie)
print(res.text)
(7)session案例-雪球网
- 在上面的案例中,还需要手动获取cookie
- 然后再传递cookie,甚是麻烦
- 其中
request.Session()对象就可以自动完整这个操作
import requests
from fake_useragent import UserAgent
# 指定用户代理是浏览器
headers = {
"User-Agent": UserAgent().random,
}
# 主页路由
home_url = "https://xueqiu.com/"
# 详情地址
info_url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006,SH000688,SH000016,SH000300,BJ899050,HKHSI,HKHSCEI,HKHSTECH,.DJI,.IXIC,.INX'
# 创建session对象
session = requests.Session()
# 先向主页发起请求,带上cookie
session.get(headers=headers, url=home_url)
# 向详情页发起请求,获取数据
res = session.get(headers=headers, url=info_url)
print(res.text)
【3】获取响应
(1)响应参数
-
response.text
- 返回Unicode字符串,表示响应体
- 这是响应体内容的文本形式
-
response.content
- 以字节形式返回响应体
- 适用于处理图片、视频等非文本类型的响应
- 默认是16进制
-
response.json()
- 当服务器响应的内容是json格式时,
- 可以使用这个方法将其转换为Python对象
- 如果返回的不是Json格式数据时,
- 使用此方法会报错
- 当服务器响应的内容是json格式时,
-
response.iter_content()
- 一个生成器,用于迭代响应的内容。
- 这在处理大文件或流数据时特别有用
- 参数:
chunk_size=1024- 指定每次获取的字节数
-
response.encoding
- 获取或设置响应体的编码方式
- 基本全是UTF8了
- 可以在网页源码的head中的meta里面查看当前网页编码格式
-
response.status_code
- 响应状态码
-
response.headers
- 获取响应头信息,是一个字典对象
-
response.cookies
- 获取服务器返回的cookie信息,是一个
CookieJar对象
- 获取服务器返回的cookie信息,是一个
-
response.cookies.get_dict()
- 返回的是cookie字典
-
response.cookies.items()
- 返回的是元组列表,元组是cookie的键和值
-
response.url
- 最终请求的URL。
- 这个在发生重定向的时候特别有用,因为他表示实际访问的URL,而不是原始请求的URL
-
response.request.url
- 原始请求的URL。
- 即使发生了重定向,获取的任然是原始请求的URL
-
response.history
- 一个包含所有重定向响应的列表。
- 如果没有发生重定向,那么就是一个空列表
(2)和重定向有关的三个方法
- 示例
- 先向主网页home.html发送一个请求
- 然后向网页A.html发送一个请求
- 得到了一个重定向地址B.html
- 发生重定向后又得到了一个C.html地址
- 最后拿到的是C.html的响应内容
- 这个过程结束后
response.url是http://example.com/C.htmlresponse.request.url是http://example.com/A.htmlresponse.history包含两个重定向的详细信息。
【4】SSL认证
(1)HTTP和HTTPS的区别
- 安全性:
- HTTP是一种明文的超文本传输协议,不提供任何形式加密
- HTTPS是HTTP的安全版本,它使用SSL/TLS协议对传输数据进行加密,保证传输过程中的安全性
- 端口号
- HTTP通常使用80端口
- HTTPS通常使用443端口
- 资源消耗
- HTTPS对传输数据进行加密,所以相对HTTP来说
- HTTPS会消耗更多的CPU和内存资源
- 所以一些网站考虑性能和成本的情况下会使用HTTP
- 浏览器显示
- HTTPS网站的地址栏会显示为绿色,并会显示一个锁形图标,表示该网站的数据传输安全
- HTTP网站没有这些显示
(2)SSl
- SSL认证是一种数字证书认证方式
- 主要用于为客户和服务器提供身份验证
- 并确保在数据传输过程中的安全性
- 原理
- 主要是基于公钥加密技术,通过客户端和服务器之间互相交换公钥,使用公钥进行数据加密,只用持有私钥的一方才能解密数据并读取其中内容
- 什么情况会出现SSL证书错误提示
- 网站没有设置好HTTPS证书
- 或者HTTPS证书不被CA机构认可
- 示例
verify参数被默认为True,表示会验证 SSL 证书verify参数设置为False时,会忽略证书验证,但会引发警告- 如果有自定义证书,可以添加证书路径到
verify参数中 - 注意:禁用 SSL 证书验证存在安全风险,因为它允许您的请求受到中间人攻击。
# 验证证书报错
import requests
url = 'https://ssr2.scrape.center/'
response = requests.get(url)
print(response.status_code)
# requests.exceptions.SSLError:
# HTTPSConnectionPool(host='ssr2.scrape.center', port=443):
# Max retries exceeded with url: /
# (Caused by SSLError(SSLCertVerificationError(1,
# '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed:
# self signed certificate (_ssl.c:997)')))
# 不验证证书,发出警告,请求通过
import requests
url = 'https://ssr2.scrape.center/'
response = requests.get(url=url, verify=False)
print(response.status_code)
# InsecureRequestWarning: Unverified HTTPS request is
# being made to host 'ssr2.scrape.center'.
# Adding certificate verification is strongly advised.
# See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#tls-warnings
# warnings.warn(
# 自定义证书路径
import requests
url = 'https://ssr2.scrape.center/'
cert_file = "/path/to/my_certificate.pem" //有才行
response = requests.get(url, verify=cert_file)
print(response.status_code)
【5】代理
(1)使用代理的方法
- 代理格式
proxies={"协议":"协议://IP:端口号"}
- 方法一:requests.get()设置代理
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
response = requests.get('http://example.org', proxies=proxies)
- 方法二:session设置代理
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "https://10.10.1.10:1080",
}
with requests.Session() as session:
session.proxies = proxies
response = session.get('http://example.org')
- 两个方法的区别
- 作用域:
- requests.get的代理设置作用于单个请求
- session设置的代理适用于所有session发送的请求
- 效率:
- 如果发送多个请求到相同的代理,session更高效
- 灵活性:
- requests.get提供了更直接的请求方式,适用于简单的单次请求场景
- session提供了更多的功能和灵活性,如保持挎请求的cookie和会话信息
- 作用域:
(2)使用代理IP示例
- http://httpbin.org/get
- 这个网址中的origin参数就是当前访问的IP
- 查看本机IP
- 由于返回的信息是Json格式数据
- 所以可以直接json()方法转换为字典后
- 按照字典的方法取值
import requests
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().random,
}
url = 'http://httpbin.org/get'
response = requests.get(url=url, headers=headers)
print(response.json().get("origin"))
- 使用免费代理测试
import requests
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().random,
}
proxies = {
"http": "47.243.114.192:8180",
}
url = 'http://httpbin.org/get'
response = requests.get(url=url, headers=headers, proxies=proxies)
print(response.json().get("origin"))
# 47.243.114.192
【6】超时设置
(1)时间设置
- timeout参数用于设置发出请求后等待服务器响应的最长时间
- 这个参数可以是数值型或元组型
- 数值型:表示最大的请求等待时间,单位秒
- 元组型:元组含有两个参数,分别是连接超时时间和读取超时时间,单位秒
- 即传入一个参数,那么连接超时时间和读取超时时间相同,传入元组(两个参数),那么就是分别设置这两个时间
- 连接超时时间
- 主要用来控制客户端尝试连接远程服务器时所需要的时间
- 连接超时时间的配置通常较短,因为TCP三次握手建立连接的过程通常很快
- 读取超时时间
- 指从服务器开始传输数据到客户端读取完数据的最大等待时间。
- 微服务中,对于短平快的同步接口调用,并发较大,应设置一个较短的读取超过时间,以防止被下有服务拖慢。
- 过长可能会让下游服务的抖动影响到自己
- 过短则可能影响成功率
- 数值型示例:设置等待时间
import requests
import time
from fake_useragent import UserAgent
url = 'http://www.google.com'
headers = {
"User-Agent": UserAgent().random,
}
print(f"开始时间:{time.strftime('%H:%M:%S', time.localtime())}")
try:
response = requests.get(url=url, headers=headers, timeout=5)
print(response.status_code)
print(f"成功访问时间:{time.strftime('%H:%M:%S', time.localtime())}")
except requests.exceptions.RequestException as e:
print(e)
print(f"访问失败时间:{time.strftime('%H:%M:%S', time.localtime())}")
# 开始时间:20:31:24
# HTTPConnectionPool(host='www.google.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x000002BCE696E410>, 'Connection to www.google.com timed out. (connect timeout=5)'))
# 访问失败时间:20:31:29
- 元组型示例:
# 例子相同
# 但是可以设置timeout=(5, 1)或timeout=(1, 5)
# 查看效果
(2)重试次数
-
方法一:
- 在try-execpt方法外面套一层while或者for循环
-
方法二:
-
requests.Session()内有指定的参数mount
-
session.mount('http://', HTTPAdapter(max_retries=3)) session.mount('https://', HTTPAdapter(max_retries=3))
-
import requests
import time
from fake_useragent import UserAgent
from requests.adapters import HTTPAdapter
url = 'http://www.google.com'
headers = {
"User-Agent": UserAgent().random,
}
session = requests.Session()
# 访问Http网址的超时次数
session.mount("http://", HTTPAdapter(max_retries=3))
# 访问Https网址的超时次数
session.mount("https://", HTTPAdapter(max_retries=3))
print(f"开始时间:{time.strftime('%H:%M:%S', time.localtime())}")
try:
response = requests.get(url=url, headers=headers, timeout=(5, 1))
print(response.status_code)
print(f"成功访问时间:{time.strftime('%H:%M:%S', time.localtime())}")
except requests.exceptions.RequestException as e:
print(e)
print(f"访问失败时间:{time.strftime('%H:%M:%S', time.localtime())}")
# 开始时间:20:59:57
# HTTPConnectionPool(host='www.google.com', port=80): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x000002109AD2EB90>, 'Connection to www.google.com timed out. (connect timeout=5)'))
# 访问失败时间:21:00:02
【7】上传文件
(1)网址说明
-
- 这是一个简单的HTTP请求和响应服务
- 主要用于测试HTTP请求和响应的各种信息
- 比如cookie、ip、headers和登录验证等
- 它支持GET、POST等多种HTTP方法,对web开发和测试很有帮助
-
在httpbin.org上
- 可以测试不同的HTTP动词(如GET、POST、DELETE等),进行身份验证,生成具有给定状态代码的响应,检查请求和响应数据,以不同的数据格式返回响应(如json、html、xml等),创建、读取和删除Cookies,返回不同的图像格式(如jpeg、png等),以及返回不同的重定向响应等。
(2)示例
-
files参数是一个字典
-
键为表单中的字段名()
-
值为打开的文件对象信息元组
-
("1.png", open('1.png', 'rb'), "image/png") -
不同的网站,格式可能有所不同
-
import requests
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().random
}
files = {'files': ("1.png", open('1.png', 'rb'), "image/png")}
response = requests.post('http://httpbin.org/post', files=files, headers=headers)
print(response.status_code)
【8】认证设置
- 官网地址身份验证 — 请求 2.31.0 文档 (python-requests.org)
- 当你需要向受保护的资源发送请求时,例如需要身份验证的 API,你通常需要提供认证信息。
requests提供了几种方式来设置认证。
(1)基本认证
- 基本认证是一种简单的认证方式,通过用户名和密码来验证用户。
- 在
requests中,你可以使用auth参数来设置基本认证HTTPBasicAuth对象或(username, password)元组被传递给auth参数。- 当请求被发送时,
requests会自动在请求头中包含基本认证信息。
import requests
from requests.auth import HTTPBasicAuth
url = 'https://httpbin.org/basic-auth/user/pass'
basic = HTTPBasicAuth('user', 'pass')
# 使用HTTPBasicAuth对象
response = requests.get(url=url, auth=basic)
# 直接使用元组
response = requests.get(url=url, auth=('user', 'pass'))
(2)自定义认证头
- 有时,API 可能使用自定义的认证机制,而不是基本认证。
- 在这种情况下,可以通过手动设置请求头来提供认证信息:
- 创建一个包含认证信息的字典
headers,并将其传递给headers参数 - 这允许发送任何自定义的认证头。
- 创建一个包含认证信息的字典
import requests
url = 'https://api.example.com/resource'
token = 'my_custom_token'
headers = {
'Authorization': f'Bearer {token}' # 假设API使用Bearer token认证
}
response = requests.get(url, headers=headers)
(3)代理认证
- 如果需要通过代理服务器发送请求,并且代理服务器需要认证,
- 可以使用
proxies参数和proxy_auth参数
import requests
from requests.auth import HTTPProxyAuth
proxy_username = 'proxy_user'
proxy_password = 'proxy_pass'
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
proxy_auth = HTTPProxyAuth(proxy_username, proxy_password)
response = requests.get(url, proxies=proxies, proxies_auth=proxy_auth)