我自己的原文哦~ https://blog.51cto.com/whaosoft/12538137
#SIF3D
通过两种创新的注意力机制——三元意图感知注意力(TIA)和场景语义一致性感知注意力(SCA)——来识别场景中的显著点云,并辅助运动轨迹和姿态的预测。
设想一下,你在家中准备起身,前往橱柜取东西。一个集成 SIF3D 技术的智能家居系统,已经预测出你的行动路线(路线通畅,避开桌椅障碍物)。当你接近橱柜时,系统已经理解了你的意图,柜门在你达到之前就已自动打开,无需手动操作。

视频中,左边为 3D 场景和预测结果(红色人体表示真实序列,蓝色人体表示预测结果)中间为运动序列最有可能和场景发生交互的点云,右边为每一个人体 pose 最有可能和场景发生交互的点云(红交互可能性大,蓝色交互可能性小)
SIF3D(Sense-Informed Forcasting of 3D human motion),即场景感知运动预测技术,由小红书创作发布团队提出,目前已被计算机视觉顶会 CVPR2024 收录。SIF3D 的先进之处在于其多模态感知能力。它结合人过去的动作序列、真实 3D 场景信息以及人的视线三个方面,预测未来的人体运动。
这项技术特别擅长于理解和预测在复杂环境中的动作,如避开障碍物,这对于自动驾驶、机器人导航、游戏开发和虚拟现实等领域至关重要。比如使得汽车能够更准确地提前预测马路上的行人、车辆未来可能的运动趋势,或是应用于医疗康复诊疗,提前对病人可能发生的不安全运动行为进行预警等。
SIF3D 的工作原理是:通过两种创新的注意力机制——三元意图感知注意力(TIA)和场景语义一致性感知注意力(SCA)——来识别场景中的显著点云,并辅助运动轨迹和姿态的预测。 TIA 专注于预测人的意图和全局动作轨迹,而 SCA 则专注于局部场景细节,确保每一帧的姿态预测都与环境保持连贯性。
实验结果表明,SIF3D 在多个大规模场景感知运动预测的数据集上的卓越性能(SOTA),预测时长突破目前算法边界,达到 5 秒时长。它能够有效地识别场景中那些可能与人的运动相关联、相耦合的部分(显著性区域),并通过场景中显著性区域的特征辅助运动预测。这一开创性的方法,不仅推动了人体运动预测技术的发展,也为未来在更多场景下应用场景感知人体运动提供了新的方向和可能性。
01 背景
人体动作预测(Human Motion Forecasting),即根据观测到的人体运动序列预测其将来的动作,这是机器智能(MI)、自动驾驶汽车(AD)和人机协作(HRI)等领域的关键技术。在现实生活中,人类的动作是与周围环境紧密相连的,比如我们会因为障碍物而改变行走路径。然而在现有的运动预测研究中,场景信息却常常被忽略,大大制约了技术在真实 3D 场景下的应用。
在机器人技术中,场景信息通常被表达为 3D 点云。现有的场景感知运动预测的方法,通常会将整个 3D 点云进行编码,而后通过全局嵌入或索引、插值等手段将其作为条件引入至运动预测任务当中。尽管该方法可行,但我们注意到:并非点云中的所有信息都与运动预测任务同等相关,相反,往往只有小部分的场景点云会对我们当前序列的运动预测起到作用,我们称其为显著点云(salient point clouds)。
此外,人眼的凝视点(与场景的交汇点)也是一种能够体现人的运动意图的表现。我们期望通过联合分析 3D 场景和人眼凝视点,可以捕捉人类向特定位置的运动行为,从而更准确地预测其运动序列。

3D 场景(左),传统运动预测(中)与本文提出的场景感知预测(右)的对比
为了解决上述挑战,我们提出了一种全新的多模态场景感知的运动预测方法 SIF3D(Multimodal Sense-Informed Forecasting of 3D Human Motions)。SIF3D 主要包含以下两个核心组件:
- 三元意图感知注意力机制(ternary intention-aware attention,TIA):通过观测序列、场景点云、人眼凝视的三元多模态联合分析,预测人的意图并区分全局显著点云(global salient points),用于辅助人体运动轨迹预测
- 场景语义一致性感知注意力机制(semantic cohenrence-aware attention,SCA):逐帧分析运动序列与场景语义的连贯性与一致性,区别得到逐帧的局部显著点云(local salient points),用于辅助人体姿态预测
通过在新引入的大型数据集上的广泛实验,SIF3D 在真实场景下的 3D 人体运动预测方面取得了最优越的性能,证明了其捕获显著点云的准确性,以及通过显著点云辅助运动预测的有效性。此外,这些发现同样为将来基于真实场景的高保真运动预测、人机交互等领域的应用提供了新的视角和可能性。
02 方法

SIF3D 算法流程图
如图所示,SIF3D 主要涉及以下三个核心步骤:
- Encoding: 通过点云网络(PointNet)和 Transformer 分别提取 3D 场景的空间信息与运动序列的时间、空间信息,并将其编码为高维隐藏特征;
- Crossmodal Attention: 通过提出的三元意图感知注意力机制(TIA)与场景语义一致性感知注意力机制(SCA)提取 3D 场景中的全局与局部显著点云,并通过跨模态注意力机制分别辅助运动轨迹与姿态的预测;
- Decoding: 融合 TIA 与 SCA 预测的轨迹与姿态,并使用真伪判别器进一步监督预测序列的保真度。
2.1 多模态编码(Multimodal Encoding)
由于 SIF3D 使用到了三种模态的信息(运动序列、3D 场景点云、人眼凝视点),在对它们进行联合分析之前,我们首先需要将运动序列与 3D 场景点云编码并映射至同一空间,而人眼凝视点则作为索引,用于获取凝视点的 3D 场景特征。具体操作如下:

2.2 三元意图感知注意力机制(TIA)
三元意图感知注意力机制(ternary intention-aware attention,TIA)通过分析观测序列与场景之间的关系,同时基于“人们大多数时候总是会走向看着的地方“这一先验来分析这三种模态间的关联,并通过以下步骤辅助路径规划:
a. 运动特征编码与聚合: 短期内,人的意图在运动序列中具有唯一性且不会随着运动的持续进行而发生变化,因此我们首先对运动特征进行进一步编码,并将整个序列的运动特征聚合为一个向量:

b. 全局显著性点云识别: 将聚合得到的运动特征与场景特征进行跨模态注意力分析,寻找出场景中那些响应当前观测序列的点云,作为全局显著点云,我们仅会利用全局显著点云用于提取跨模态意图特征,并用于辅助轨迹预测:


d. 全局特征特征融合: 通过三元多模态感知,我们试图从多个维度来分析人的运动意图,最后我们通过标准的多层感知机(MLP)来融合这些全局特征,作为 TIA 的输出:

2.3 场景语义一致性感知注意力机制(SCA)
不同于 TIA 关注全局特征与人的运动意图,场景语义一致性感知注意力机制(SCA)则更加关注每一帧的局部显著性场景细节,用来更好地指导每一帧局部姿态的预测:
a. 局部点云显著度: 我们首先对运动特征进一步编码,得到每一帧的姿态特征,并将它们分别与场景特征进行跨模态注意力分析,来找到场景中响应每一帧运动姿态的局部显著性点云。

b. 空间显著度偏置: 由于 SCA 会更关注场景中的一些可能影响人体姿态的细粒度信息,且正对着人的朝向且距离更近的场景点往往更可能会影响人体姿态,我们基于每个场景点相对于每一帧中人体的距离与方向额外对于局部点云显著性引入了一项空间显著度偏置 :

c. 局部特征特征融合: 结合了局部点云显著度与空间显著度偏置,我们同样只利用局部显著性点云来辅助姿态预测:

而后利用多层感知机(MLP)来融合局部特征,作为 SCA 的输出:

2.4 运动序列解码与生成
预测未来的运动序列需要同时考虑轨迹和姿势。TIA 通过识别全局显著点云分析了人的意图,而 SCA 则识别局部点云以维持每一帧人体与环境的连贯性与一致性,因此我们利用 TIA 的特征预测轨迹,而用 SCA 的特征预测人体姿态:

由于分别预测得到的轨迹与姿态可能存在不一致,因此我们利用一个基于图网络(GCN)的解码器来融合它们并得到最终结果:


03 实验
3.1 实验设置
本文基于 GIMO 与 GTA-1M 两个近期发布的包含 3D 场景点云的人体运动数据集,将 SIF3D 与包含经典方法、最新最优方法在内的 4 个方法进行了对比:基于图网络的 LTD、SPGSN,基于 Transformer 的 AuxFormer,以及考虑了场景信息的 BiFu。
本文从轨迹与姿态两个维度对 SIF3D 与对比方法进行了评估,轨迹评估计算了预测轨迹与真实轨迹之间的偏差,姿态评估了则计算了每个关节点的位置与真实位置的平均偏差。
对于所有的指标我们都从所有的预测帧与最终的预测帧两个方面来评估,包括:
- Traj-path: 衡量了整个预测序列中平均的轨迹偏差;
- Traj-dest: 衡量了最终预测帧的轨迹偏差;
- MPJPE-path: 衡量了整个预测序列中的平均姿态关节点偏差;
- MPJPE-dest: 衡量了最终预测帧的平均姿态关节点偏差。
3.2 实验结果
我们首先统计了引入不同多模态信息时(3D 场景点云 Scene,人眼凝视点 Gaze),各个方法的预测性能(表 1),而后详细展开统计了不同场景以及不同时间点下各个方法的预测性能(表 2)

表 1:考虑了不同模态时(3D 场景点云 Scene,人眼凝视点 Gaze)各个方法的预测结果

表 2:不同场景以及不同时间点下各个方法的详细预测性能
3.3 可视化对比结果
可视化结果提供了一种更为直观的方法将 SIF3D 与传统方法进行了对比。

通过识别场景中的全局与局部显著点云,我们可以更高效地利用场景信息辅助运动预测,得到更为精准与真实的预测序列。我们可以清楚地看到,SIF3D 不但能更好地识别场景元素,还能感知人的意图,其预测结果不但更接近真实序列,也具有更高的保真度。

3.4 消融实验
消融实验(Ablation Study)旨在评价 SIF3D 中不同组件的重要度以及对最终预测性能的影响,即通过移除或修改某些部分来评估模型性能的变化。主要包括:
a. 移除主要组件: 包括 TIA,SCA,运动解码器,真伪判别器与场景编码器 PointNet++。它们是构成 SIF3D 最主要的五个部件,通过比较移除这些组件前后的预测误差,可以评估它们在提高预测准确性方面的重要性,如下表所示。可以看出本文提出的组件均不同程度地有主提高最终的预测效果,尤其是意图注意力模组和场景编码模块。

b. 调整场景点云大小:
原始的 LiDAR 传感器采样得到的场景点云可能包含 50 万以上的顶点数量,为了更高效地利用点云数据,我们对其进行了下采样。然而过度下采样可能影响点云对于场景的表征能力,因此我们需要权衡下采样的点云大小,如下表所示。本文实验采用了 4096 作为场景点云的大小。可以看到,在点云数量为4096时,算法在内存开销、推理速度、最终性能等方面取得了最佳平衡。

c. TIA 中的运动特征聚合方法:
在 TIA 中,我们将编码得到的运动特征聚合为一个向量用于计算与场景点云间的全局显著性,这里我们研究了不同聚合方式对于性能的影响,包括:
Last,采用最后一帧的运动特征;Mean,采用所有帧运动特征的均值;Max,采用帧间最大池化;Conv,利用三层卷积网络进行下采样;Transformer,引入单层 Transformer 解码器用于聚合。结果如下表所示。可以看出,使用运动特征的最后一个时间维度的特征作为计算场景相关性的key-query取得了最佳的性能,这也意味着:
(1)最后一帧的运动特征可能包含了之前所有时间的上下文信息;
(2)最后时刻的运动信息对于人类未来轨迹起到的作用最大。

04 结语
在本研究中,我们提出了一个开创性的多模态感知信息框架 SIF3D,用于在真实世界的 3D 场景中进行人体运动预测。通过结合外部客观的 3D 场景点云和主观的人眼凝视点,SIF3D 能够通过 TIA 与 SCA 注意力机制感知场景和理解人类意图的。在 GIMO 与 GTA-1M 两个数据集中,SIF3D 均取得了目前最佳的预测性能。与此同时,我们的发现强调了 3D 场景与人眼凝视点在场景感知的运动预测中的重要性。此外,我们认为,在现实世界的 3D 场景中深入研究高保真度的不同人体运动生成任务,有望成为未来探索的一条引人注目的途径。
项目地址: https://sites.google.com/view/cvpr2024sif3d
#SAMPro3D
论文提出了一种创新的3D室内场景分割方法,这在增强现实、机器人技术等领域是一个关键的任务。该任务的核心是从多种3D场景表现形式(如网格或点云)中预测3D物体掩膜。 三维场景零样本分割新突破
SAMPro3D: Locating SAM Prompts in 3D for Zero-Shot Scene Segmentation

这篇论文提出了一种创新的3D室内场景分割方法,这在增强现实、机器人技术等领域是一个关键的任务。该任务的核心是从多种3D场景表现形式(如网格或点云)中预测3D物体掩膜。历史上,传统方法在分割训练过程中未遇到的新物体类别时常常遇到困难,这限制了它们在陌生环境中的有效性。
最近的进展,如Segment Anything Model(SAM),在2D图像分割方面显示出潜力,能够在无需额外训练的情况下分割陌生的图像。本文探讨了将SAM原理应用于3D场景分割的可能性,具体研究了是否可以直接将SAM应用于2D帧,以分割3D场景,而无需额外训练。这一探索基于SAM的一个独特特点:它的提示功能,即它接受各种输入类型来指定图像中的分割目标。
作者指出了一个关键挑战:确保同一3D物体在不同帧中的2D分割的一致性。他们观察到,像SAM3D这样的现有方法,它将自动化SAM应用于单个帧,但在不同帧中存在不一致性,导致3D分割效果不佳。另一种方法,SAM-PT,在视频跟踪中效果显著,但在3D场景中失败,因为物体并非始终出现在所有帧中。
为了应对这些挑战,论文提出了一个名为SAMPro3D的新框架,该框架在输入场景中定位3D点作为SAM提示。这些3D提示被投影到2D帧上,确保了跨帧一致的像素提示和相应的掩膜。这种方法确保了同一3D物体在不同视角下的分割掩膜的一致性。
SAMPro3D首先初始化3D提示,使用SAM在各个帧中生成相应的2D掩膜。然后,它根据所有帧中相应掩膜的质量过滤3D提示,优先选择在所有视图中都能产生高质量结果的提示。为了解决部分物体分割的问题,该框架合并了重叠的3D提示,整合信息以实现更全面的分割。SAMPro3D累积跨帧的预测结果,以得出最终的3D分割。值得注意的是,该方法不需要额外的领域特定训练或3D预训练网络,这保持了SAM的零样本能力,是之前方法所不具备的显著优势。
该论文通过广泛的实验验证了SAMPro3D的有效性,展示了它在实现高质量和多样化分割方面的能力,通常甚至超过了人类级别的标注和现有方法。此外,它还展示了在2D分割模型(如HQ-SAM和Mobile-SAM)中的改进可以有效地转化为改进的3D结果。这篇论文为3D室内场景分割引入了一种开创性的方法,巧妙地利用了2D图像分割模型的能力,并将其创新地应用于3D领域。结果是一种强大的、零样本的分割方法,显著推进了3D视觉理解领域的最新发展。
方法

本文提出的方法名为SAMPro3D,旨在直接应用Segment Anything Model (SAM) 对室内场景的3D点云及其关联的2D帧进行零样本3D场景分割。
3D Prompt Proposal

2D-Guided Prompt Filter

Prompt Consolidation
有时,由单个3D提示对齐的2D掩膜可能只分割了对象的一部分,因为2D帧的覆盖范围有限。为解决这个问题,我们设计了一个提示合并策略。该策略涉及检查不同3D提示生成的掩膜,并识别它们之间的一定重叠。在这种情况下,我们认为这些提示可能正在分割同一个对象,并将它们合并为单个伪提示。这个过程促进了提示间信息的整合,导致更全面的对象分割。
3D Scene Segmentation
在前面的步骤之后,我们获得了最终的3D提示集合及其在帧间的2D分割掩膜。此外,我们还确保了每个3D对象由单个提示分割,允许提示ID自然地作为对象ID。

实验

从这个表格中提供的实验数据中,我们可以得出一些结论关于3D室内场景分割性能。这些数据基于ScanNet200数据集的标注,评价指标是mIoU(mean Intersection over Union),一个常用的衡量图像分割效果的指标。

这些实验结果表明,本文提出的方法在3D室内场景分割任务上具有强大的性能,尤其是在采用2D引导的提示过滤和提示合并策略,以及进一步增强SAM模型时。此外,这些结果还揭示了不同提示数量和投票机制对性能的影响,以及优化3D提示的潜力。
讨论

这篇论文在3D室内场景分割领域提出了一种创新的方法,展示了显著的性能提升,尤其是在处理具有挑战性的零样本场景时。其主要优势在于有效地利用了Segment Anything Model(SAM),通过一系列精心设计的步骤,如3D提示提议、2D引导的提示过滤和提示合并策略,来改善3D场景的分割效果。这种方法充分利用了SAM在2D图像分割领域的强大能力,并巧妙地将其扩展到3D场景,显示了跨领域应用的巨大潜力。
特别是,该方法通过3D提示的初始化和精确过滤,确保了3D分割的精度和一致性。此外,通过集成HQ-SAM和Mobile-SAM,该方法进一步提升了其性能,显示了在不断发展的深度学习领域中,通过集成新技术以适应更复杂应用场景的重要性。
然而,该方法也存在一些潜在的限制。首先,尽管实验结果表明该方法在多个指标上表现出色,但它依赖于SAM模型,这可能限制了其在没有大规模预训练数据时的适用性。此外,3D提示的初始化和过滤策略虽然有效,但可能需要显著的计算资源,尤其是在处理大规模或复杂的3D场景时。此外,该方法的泛化能力尚需在更多不同类型的3D场景中进行测试和验证。
综上所述,尽管这篇论文在3D室内场景分割方面取得了显著进展,但其依赖于特定的深度学习模型和可能需要较高计算资源的处理流程,这些因素可能会影响其在实际应用中的广泛可行性。
结论

总的来说,这篇论文提出了一种创新且有效的方法,用于提升3D室内场景分割的准确度和效率。其通过集成先进的2D图像分割模型并将其扩展到3D领域,展示了显著的性能提升。尽管存在一些潜在的限制,如对预训练数据的依赖和高计算资源需求,但这项工作无疑为3D视觉理解领域带来了新的见解和方法。
#MonoLSS
MonoLSS: Learnable Sample Selection For Monocular 3D Detection
排名第一,用于视觉3D检测训练中的样本选择(百度最新)
论文链接:https://arxiv.org/pdf/2312.14474.pdf
在自动驾驶领域,单目3D检测是一个关键任务,它在单个RGB图像中估计物体的3D属性(深度、尺寸和方向)。先前的工作以一种启发式的方式使用特征来学习3D属性,而没有考虑不适当的特征可能产生不良影响。在本文中,引入了样本选择,只有适合的样本才应该用于回归3D属性。为了自适应地选择样本,提出了一个可学习的样本选择(LSS)模块,该模块基于Gumbel-Softmax和相对距离样本划分。LSS模块在warmup策略下工作,提高了训练稳定性。此外,由于专用于3D属性样本选择的LSS模块依赖于目标级特征,进一步开发了一种名为MixUp3D的数据增强方法,用于丰富符合成像原理的3D属性样本而不引入歧义。作为两种正交的方法,LSS模块和MixUp3D可以独立或结合使用。充分的实验证明它们的联合使用可以产生协同效应,产生超越各自应用之和的改进。借助LSS模块和MixUp3D,无需额外数据,方法MonoLSS在KITTI 3D目标检测基准的所有三个类别(汽车、骑行者和行人)中均排名第一,并在Waymo数据集和KITTI-nuScenes跨数据集评估中取得了有竞争力的结果。
MonoLSS主要贡献:
论文强调,并非所有特征对学习3D属性都同样有效,并首先将其重新表述为样本选择问题。相应地,开发了一种新的可学习样本选择(LSS)模块,该模块可以自适应地选择样本。
为了丰富3D属性样本,设计了MixUp3D数据增强,它模拟了空间重叠,并显著提高了3D检测性能。
在不引入任何额外信息的情况下,MonoLSS在KITTI基准的所有三个类别中排名第一,在汽车类别的中等和中等水平上,超过了当前的最佳方法11.73%和12.19%。它还实现了Waymo数据集和KITTI nuScenes跨数据集评估的SOTA结果。
MonoLSS主要思路
MonoLSS框架如下图所示。首先,使用与ROI Align相结合的2D检测器来生成目标特征。然后,六个Head分别预测3D特性(深度、尺寸、方向和3D中心投影偏移)、深度不确定性和对数概率。最后,可学习样本选择(LSS)模块自适应地选择样本并进行损失计算。

Learnable Sample Selection
假设U~Uniform(0,1),则可以使用逆变换采样通过计算G=−log(−log(U))来生成Gumbel分布G。通过用Gumbel分布独立地扰动对数概率,并使用argmax函数找到最大元素,Gumbel Max技巧实现了无需随机选择的概率采样。基于这项工作,Gumbel Softmax使用Softmax函数作为argmax的连续可微近似,并在重新参数化的帮助下实现了整体可微性。
GumbelTop-k通过在没有替换的情况下绘制大小为k的有序采样,将采样点的数量从Top-1扩展到Top-k,其中k是一个超参数。然而,相同的k并不适用于所有目标,例如,被遮挡的目标应该比正常目标具有更少的正样本。为此,我们设计了一个基于超参数相对距离的模块来自适应地划分样本。总之,作者提出了一个可学习样本选择(LSS)模块来解决三维属性学习中的样本选择问题,该模块由Gumbel Softmax和相对距离样本除法器组成。LSS模块的示意图如图2的右侧所示。
Mixup3D数据增强
由于严格的成像约束,数据增强方法在单目3D检测中受到限制。除了光度失真和水平翻转之外,大多数数据增强方法由于破坏了成像原理而引入了模糊特征。此外,由于LSS模块专注于目标级特性,因此不修改目标本身特性的方法对LSS模块来说并不足够有效。
由于MixUp的优势,可以增强目标的像素级特征。作者提出了MixUp3D,它为2D MixUp添加了物理约束,使新生成的图像基本上是空间重叠的合理成像。具体而言,MixUp3D仅违反物理世界中对象的碰撞约束,同时确保生成的图像符合成像原理,从而避免任何歧义!

实验结果
KITTI测试集上汽车类的单目3D检测性能。与KITTI排行榜相同,方法排名在中等难度以下。我们以粗体突出显示最佳结果,以下划线突出显示第二个结果。对于额外的数据:1)LIDAR表示在训练过程中使用额外的LIDAR云点的方法。2) 深度是指利用在另一深度估计数据集下预先训练的深度图或模型。3) CAD表示使用由CAD模型提供的密集形状注释。4) 无表示不使用额外数据。


Wamyo上数据集测试结果:

KITTI-val模型在深度为MAE的KITTI-val和nuScenes前脸val汽车上的跨数据集评估:


#Zip-NeRF
2020 年,加州大学伯克利分校、谷歌的研究者开源了一项 2D 图像转 3D 模型的重要研究 ——NeRF。它可以利用几张静态图像生成多视角的逼真 3D 图像,生成效果非常惊艳:NeRF原班人马
打造

三年之后,这支团队做出了更惊艳的效果:在一项名为「Zip-NeRF」的研究中,他们完整还原了一个家庭的所有场景,就像无人机航拍的效果一样。

作者介绍说,Zip-NeRF 模型结合了 scale-aware 的抗混叠 NeRF 和快速基于网格的 NeRF 训练,以解决神经辐射场训练中的混叠问题。与以前的技术相比,Zip-NeRF 的错误率降低 8%-76%,训练速度提高 22 倍。
这项技术有望在 VR 领域得到应用,比如参观线上博物馆、线上看房。
- 论文地址:https://arxiv.org/pdf/2304.06706.pdf
- 项目地址:https://jonbarron.info/zipnerf/
论文概览
在神经辐射场(NeRF)中,一个神经网络被训练来模拟一个三维场景的体积表示,这样通过光线跟踪就可以呈现该场景的新视图。NeRF 已被证明是一种有效的任务工具,如视图合成,生成媒体,机器人,和计算摄影。
Mip-NeRF 360 和 instant-NGP(iNGP)都是基于 NeRF 的形式:通过投射 3D 射线和沿光线距离 t 的位置来渲染像素,这些特征被输入给神经网络,输出渲染后呈现颜色。反复投射与训练图像中的像素对应的光线,并最小化(通过梯度下降)每个像素的渲染颜色和观察颜色之间的误差来完成训练。
Mip-NeRF 360 和 instant-NGP 在沿射线的坐标参数化方式上有显著差异。在 mip-NeRF 360 中,一条射线被细分为一组区间 [t_i,t_i+1],每一个代表一个锥形锥,其形状近似于多元高斯值,该高斯值的期望位置编码被用于一个大型 MLP [3] 的输入。相比之下,instant-NGP 是将位置的特征值插值到一个不同大小的三维网格层次中,之后使用一个小的 MLP 生成特征向量。作者们提出的模型结合了 mip-NeRF360 的整体框架和 instant-NGP 的特征化方法,但盲目地直接结合这两种方法,会引入了两种混叠形式:
1、instant-NGP 的特征网格方法与 mip-nerf360 的尺度感知集成位置编码技术互相不兼容,因此 instant-NGP 产生的特征相对于空间坐标进行别名,从而产生别名的渲染图。在后面的介绍中,研究者通过引入一种用于计算预过滤的 instant-NGP 特性的类似多采样的解决方案来解决这个问题。
2、使用 instant-NGP 后显著加速了训练,但这暴露了 mip-nerf360 在线蒸馏方法的一个问题,该方法导致高度可见的 “z - 混叠”(沿着射线混叠),其中场景内容随着摄像机的移动而不稳定地消失。在后面的介绍中,研究人员用一个新的损失函数来解决这个问题,它在在线蒸馏过程中沿着每条射线进行预过滤。
方法概览
1.Spatial Anti-Aliasing:
Mip-NeRF 使用的特征近似于子体素内坐标的位置编码的积分,在 NeRF 中是沿圆锥形的圆锥体。这导致了当每个正弦曲线的周期大于高斯曲线的标准差时,傅里叶特征的振幅很小 —— 这些特征只在大于子体素大小的波长上表示子体积的空间位置。因为这个特性同时编码位置和尺度,所以使用它的 MLP 能够学习出呈现抗锯齿的图像的 3D 场景的多尺度表示。像 iNGP 这样的基于网格的表示不去查询子体素,而是在单个点上使用三线性插值来构造用于 MLP 的特性,这将导致训练后的模型不能推理不同尺度或混叠。
研究人员为了解决这个问题将每个圆锥变成一组各向同性高斯,使用多采样和特征加权:各向异性子体素首先转换为一组点近似其形状,然后每个点被认为是一个各向同性高斯尺度。这个各向同性的假设,可以利用网格中的值是零均值这一事实来近似特征网格在子体素上的真实积分。通过平均这些降加权特征,从 iNGP 网格中获得了具有尺度感知的预过滤特征。有关可视化信息见下图。

抗锯齿的问题在一些图形文献中有深入的探讨。Mip-map(Mip-nerf 的同名名称)预先计算了一个能够快速反锯齿的结构,但尚不清楚如何将这种方法应用于 iNGP 底层的散列数据结构。超采样技术采用了一种直接增加采样数量的方法来抗锯齿,产生了大量的不必要采样,这种方法与 mip-map 效果类似,但花费更高。Multi-sampling 技术构建一小组样本,然后将这些多样本的信息汇集到聚合表示中,该聚合表示提供给复杂的渲染过程 —— 一种类似于作者方法的策略。另一种相关的方法是椭圆加权平均,它近似于一个沿椭圆长轴排列的各向同性样本的椭圆核。
给定沿射线的间隔 [t_i,t_(i+1)),研究者想构建一组近似圆锥形的多样本形状。正如在样本预算有限的图形应用多采样的程序中一样,他们为他们的用例手工设计了一个多采样模式,沿着一个螺旋分配了 n 个点,它使 m 个点绕着射线的轴循环,并沿着 t 呈线性间隔:

这些三维坐标被旋转成世界坐标,通过乘以一个标准正交基,这个标准正交基的第三个向量是射线的方向,其前两个向量是垂直于视图方向的任意帧,然后由射线的原点移动。当 n≥3 和 n 和 m 是共素数时,保证每一组多样本的样本均值和协方差与每个样本的均值和协方差完全匹配,类似于 mip-NeRF 中的高斯采样。

研究者使用这 n 个多样本 {x_j} 作为各向同性高斯分布的均值,每个样本的标准差为 σ_j。他们将 σ_j 设置为 rt,通过一个超参数(在实验中为 0.35)。因为 iNGP 网格需要输入坐标位于一个有界域内,研究人员应用了 mip-NeRF 360 的收缩函数。因为这些高斯分布是各向同性的,所以可以使用 mip-NeRF 360 使用的卡尔曼滤波方法的简化和优化版本来执行这种收缩,详情请后面补充内容。
为了对每个单独的多样本进行反别名插值,研究者以一种新的方式重新加权每个尺度上的特征,其与每个网格单元内各样本的各向同性高斯拟合程度成反比例:如果高斯值远远大于被插值的单元,插值的特征可能是不可靠的就应该降低加权。Mip-NeRF 的 IPE 特性也有类似的解释。
在 iNGP 中,对坐标 x 处的每个 {V_l} 进行插值是通过用网格的线性大小 n 缩放,并对 V_l 进行三线性插值,得到一个 c 长度向量。相反,研究者插值一组具有均值和标准差为 σ_j 的多采样各向同性高斯分布。通过对高斯 CDFs 的推理,可以计算出在 V 中 [−1/2n,1/2n]^3 内的每个高斯 PDF 的分数,它被插值为一个与尺度相关的下降权重因子 ω_j,l, 研究者在 {V} 上施加权重衰减使得鼓励 V 中的值是符合正态分布和零均值。这个零均值假设让他们将每个多样本的高斯分布的期望网格特征近似为 ω_j・f_j,l+(1−ω_j)・0=ω_j・f_j,l。这样,可以通过取每个多样本插值特征的加权平均值来近似与圆锥锥对应的期望特征:

2. Z-Aliasing and Proposal Supervision:

虽然之前提到的精细的多采样和减加权方法是减少空间混叠的有效方法,但大家必须考虑在光线沿线还有一个额外的混叠来源 --z - 混叠。它是由于在 mip-NeRF360 的使用下 MLP 学习产生上限场景几何:在训练和渲染期间,沿着射线反复评估这个 MLP 生成直方图的下一轮采样,只有最后一组样本是由 NeRF 的 MLP 网络呈现。Mip-NeRF 360 表明,与之前学习一个的 mi-nerf 或多个的 nerf 的策略相比,该方法显著提高了速度和渲染质量,这些策略都使用图像重建损失进行监督。研究者发现 mip-NeRF 360 中的 MLP 方案倾向于学习从输入坐标到输出体积密度的非光滑映射。这将导致一个射线跳跃场景内容的伪影,如上图所示。虽然这个假象在 mip-NeRF 360 中很微小,但如果作者在他们提出的网络中使用 iNGP 后端而不是 MLP(可以增加新模型的快速优化能力),就变得常见和视觉突出,尤其是当相机沿其 z 轴转换时。

下图里,研究人员可视化了一个训练实例的 proposal 监督,其中一个狭窄的 NeRF 直方图(蓝色)沿着一个相对于一个粗糙的 proposal 直方图(橙色)的射线翻译。(a) mip-NeRF360 使用的损失是分段常数的,但 (b) 新模型的损失是平滑的,因为研究人员将 NeRF 直方图模糊为分段线性样条(绿色)。新模型中的预过滤损失可以学习反锯齿的 proposal 分布。Anti-Aliased Interlevel Loss:

研究者继承的 mip-NeRF 360 中的提案监督方法需要一个损失函数,该函数以由 NeRF(s,w)产生的阶跃函数和由 proposal 模型(^s,^w)产生的类似阶跃函数作为输入。这两个阶跃函数都是直方图,其中 s 和ˆs 是端点位置的向量,而 w 和ˆw 是和等于≤1 的权重向量,其中 w_i 表示可见场景内容是阶跃函数的间隔 i。每个 s_i 都是真度量距离 ti 的标准化函数,根据一些标准化函数 g (・),研究者稍后将讨论。请注意,s 和ˆs 是不相同的 —— 每个直方图的端点都是不同的。

Normalizing Metric Distance:

许多 NeRF 方法都需要一个函数来将度量距离 t∈[0,∞) 转换为标准化距离 s∈[0,1] 的方法。左图:功率变换 P(x,λ)允许通过修改 λ 在公共曲线之间进行插值,如线性、对数和逆,同时在原点附近保持线性形状。右图:构建一条从线性过渡到逆 / 反转查询的曲线,并支持靠近摄像机的场景内容。
实验效果
研究者们的模型是在 JAX 中实现的,并基于 mip-NeRF 360 的 baseline,重新设计实现了 iNGP 的体素网格和哈希表结构,取代 mip-NeRF 360 使用的大 MLP 网络,除了在其中引入的抗混叠调整,以及一些附加修改外整体模型架构与 mip-NeRF 360 相同。
在 360 Datase 的多尺度版本上的性能,训练和评估多尺度图像。红色、橙色和黄色的高光表示每个指标的第一、第二和第三个最佳表现技术。所提出的模型显著优于两个基线 —— 特别是基于 iNGP 的基线,特别是在粗糙尺度上,新模型误差减少了 54%-76%。A-M 行是模型的消融实验,详情请论文最后面参阅扩展文本。

虽然 360dataset 中包含很多具有挑战性的场景内容,它不能衡量以渲染质量作为规模的函数,因为这个数据集是由相机环绕在一个中心对象以大致恒定的距离拍摄得到的,学习模型不需要处理训练在不同的图像分辨率或不同的距离中心对象。因此研究者使用一个更具挑战性的评估过程,类似于使用 mip-NeRF 的多尺度的 blender 数据集:研究人员把每个图像变成一组四个图像被用 [1,2,4,8] 尺度分别降采样的图像额外的训练 / 测试视图的相机已经从场景的中心放大出来了。在训练过程中,研究者将数据项乘以每条射线的尺度因子,在测试时他们分别评估每个尺度。这大大增加了模型跨尺度泛化的重建难度,并导致混叠伪影效果显著出现,特别是在粗尺度上。
在表 1 中,研究者根据 iNGP、mipNeRF 360、mip-NeRF 360 + iNGP 基线和许多消融方法来评估了新提出的模型。尽管 mip-NeRF 360 表现合理(因为它可以训练多尺度),新模型在最精细的尺度上降低了 8.5%,在最粗糙的尺度上降低了 17%,同时快了 22 倍。mip-NeRF 360 + iNGP 基线因为其没有抗锯齿或推理规模的机制,表现很差:新模型的均方根误差在最精细的尺度下低 18%,在最粗糙的尺度上低 54%,最粗尺度下的 DSSIM 和 LPIPS 都低了 76%。这种改进可以从下图中看出。研究者的 mip-NeRF 360 + iNGP 基线通常优于 iNGP(除了最粗的尺度),正如他们在第二张表中所预期的那样。

总结
研究者提出了 Zip-NeRF 模型,该模型整合了在尺度感知抗锯齿 NeRF 和基于快速网格的 NeRF 训练这两种方式的优点。通过利用关于多采样和预过滤的方法,该模型能够实现比之前技术低 8%-76% 的错误率,同时也比 mip-NeRF360(目前相关问题的最先进技术)快 22 倍。研究者希望这里提出的工具和分析关于混叠(网的空间混叠从空间坐标颜色和密度的映射,以及 z - 混叠的损失函数在在线蒸馏沿每个射线)可以进一步提高 nerf 逆渲染技术的质量,速度和成品效率。
#D3GA~
创建逼真的动态虚拟角色,要么在训练期间需要准确的 3D 配准,要么在测试期间需要密集的输入图像,有时则两者都需要,也许 D3GA 是你需要的。AI研究也能借鉴印象派?这些栩栩如生的人竟然是3D模型
在 19 世纪,印象主义的艺术运动在绘画、雕塑、版画等艺术领域盛行,其特点是以「短小的、断断续续的笔触,几乎不传达形式」为特征,就是后来的印象派。简单来说印象派笔触未经修饰而显见,不追求形式的精准,模糊的也合理,其将光与色的科学观念引入到绘画之中,革新了传统固有色观念。
在 D3GA 中,作者的目标反其道而行之,是希望创建像照片般逼真的表现。在 D3GA 中,作者对高斯泼溅(Gaussian Splatting)进行创造性的运用,作为现代版的「段笔触」,来创造实时稳定的虚拟角色的结构和外观。

印象派画家莫奈代表作《日出・印象》。

对于虚拟形象的构建工作来说,创造驱动型(即可以生成动画新内容)的逼真人类形象目前需要密集的多视角数据,因为单目方法缺乏准确性。此外,现有的技术依赖于复杂的预处理,包括精确的 3D 配准。然而,获取这些配准需要迭代,很难集成到端到端的流程中去。而其它不需要准确配准的方法基于神经辐射场(NeRFs),通常对于实时渲染来说太慢,或者在服装动画方面存在困难。
Kerbl 等人在经典 Surface Splatting 渲染方法基础上引入了 3D Gaussian Splatting(3DGS)。与基于神经辐射场的最先进方法相比,这种方法在更快的帧率下呈现更高质量的图像,并且不需要任何高度准确的 3D 初始化。
但是,3DGS 是为静态场景设计的。并且已经有人提出基于时间条件的 Gaussian Splatting 可用来渲染动态场景,这些模型只能回放先前观察到的内容,所以不适用于表达新的或其未曾见过的运动。
在驱动型的神经辐射场的基础上,作者对 3D 的人类的外观及变形进行建模,将其放置在一个规范化的空间中,但使用 3D 高斯而不是辐射场。除性能更好以外,Gaussian Splatting 还不需要使用相机射线采样启发式方法。
剩下的问题是定义触发这些 cage 变形的信号。目前在驱动型的虚拟角色中的最新技术需要密集的输入信号,如 RGB-D 图像甚至是多摄像头,但这些方法可能不适用于传输带宽比较低的情况。在本研究中,作者采用基于人体姿势的更紧凑输入,包括以四元数形式的骨骼关节角度和 3D 面部关键点。
通过在九个高质量的多视图序列上训练个体特定的模型,涵盖各种身体形状、动作和服装(不仅限于贴身服装),以后我们就可以通过任何主体的新姿势对人物形象进行驱动了。


方法概览
- 论文链接:https://arxiv.org/pdf/2311.08581.pdf
- 项目链接:https://zielon.github.io/d3ga/
目前用于动态体积化虚拟角色的方法要么将点从变形空间映射到规范空间,要么仅依赖正向映射。基于反向映射的方法往往在规范空间中会累积误差,因为它们需要一个容易出错的反向传递,并且在建模视角相关效果时存在问题。
因此,作者决定采用仅正向映射的方法。D3GA 是基于 3DGS 的基础上通过神经表示和 cage 进行扩展,分别对虚拟角色的每个动态部分的颜色和几何形状进行建模。

D3GA 使用 3D 姿势 ϕ、面部嵌入 κ、视点 dk 和规范 cage v(以及自动解码的颜色特征 hi)来生成最终的渲染 C¯ 和辅助分割渲染 P¯。左侧的输入通过每个虚拟角色部分的三个网络(ΨMLP、ΠMLP、ΓMLP)进行处理,以生成 cage 位移∆v、高斯变形 bi、qi、si 以及颜色 / 透明度 ci、oi。
在 cage 变形将规范高斯变形后,通过方程式 9,它们被光栅化成最终的图像。

实验结果
D3GA 在 SSIM、PSNR 和感知度量 LPIPS 等指标上进行评估。表 1 显示,D3GA 在只使用 LBS 的方法中(即不需要为每个帧扫描 3D 数据)其在 PSNR 和 SSIM 上的表现是最佳的,并在这些指标中胜过所有 FFD 方法,仅次于 BD FFD,尽管其训练信号较差且没有测试图像(DVA 是使用所有 200 台摄像机进行测试的)。

定性比较显示,与其它最先进方法相比,D3GA 能更好地建模服装,特别是像裙子或运动裤这样的宽松服装 (图 4)。FFD 代表自由形变网格,其包含比 LBS 网格更丰富的训练信号 (图 9)。


与其基于体积方法相比,作者的方法可以将虚拟角色的服装分离出来,并且服装也是可驱动的。图 5 显示了每个单独的服装层,可以仅通过骨骼关节角度控制,而不需要特定的服装配准模块。

#4DGen
4DGen定义了” Grounded 4D Generation“的任务形式,通过视频序列和可选3D模型的引入提升了4D生成的可控性。通过高效的4D Gaussian Splatting的表达,2D和3D伪标签的监督和时空的连续性约束,使得4DGen可以实现高分辨率、长时序的高质量的4D内容生成。
本文分享4D生成方向新工作,由北京交通大学和得克萨斯大学奥斯汀分校共同完成的4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency,文章使用Gaussian Splatting实现了高质量的4D生成。基于动态 3D 高斯的可控 4D 生成
- 文章主页:https://vita-group.github.io/4DGen/
- 论文地址:https://arxiv.org/abs/2312.17225
- 开源代码:https://github.com/VITA-Group/4DGen
视频
发不了...
研究背景
尽管3D和视频生成取得了飞速的发展,由于缺少高质量的4D数据集,4D生成始终面临着巨大的挑战。过去几篇工作尝试了Text-To-4D的任务,但依然存在两个主要问题:
- 由于输入依赖于单视角的图片或者简单的文本描述,并不能保证得到精准的4D结果,需要花费大量的时间进行反复调整。
- 尽管采用了Hexplane作为4D的表征,基于NeRF的方法在高分辨率和长视频上的渲染所需要的计算时间和显存占用是难以接受的。即使采用了一个超分辨的后处理网络,依然会有模糊和闪烁的结果。
为了解决上述问题,4DGen定义了“Grounded 4D Generation“新型任务形式,并且设计了新的算法框架实现高质量的4D内容生成。
任务定义
过往的4D生成工作是“one click“的方式,并不能对生成的结果进行有效的控制。4DGen提出了“Grounded 4D Generation“的形式,通过利用视频序列和可选的3D模型作为4D生成的控制信息,可以实现更为精准的4D内容生成。用户可通过输入视频序列或3D模型来约束4D结果的运动和外观;当用户仅提供单张图片作为输入时,可借助预训练好的视频生成模型来得到视频序列;当用户未提供3D模型时,可通过单张图片重建3D模型来作为起始点。

方法介绍
4DGen框架的输入起始点为用户给定或者模型生成的视频序列,对于任意的单张图片,借助多视角生成模型(multi-view diffusion model),可以得到不同视角的图片。4DGen通过对第一帧多视图进行三维重建,得到初始的静态3D Gaussians作为4D生成的起始点。
由于4D数据的匮乏,需要尽可能的从先验模型中蒸馏信息。4DGen将每一帧生成的多视图作为2D伪标签,并且采用多视图生成的点云作为3D点的伪标签来监督训练过程。
因为多视图生成具有ill-posed的特点,得到的伪标签在不同视角之间,不同时序之间存在不连续性,需要引入时间和空间上的一致性损失函数进行约束。相较于拟合多视图DDIM采样得到的图片,score distillation sampling(SDS)是根据先验的扩散模型对场景表达进行似然估计。4DGen依据正面视角计算任意视角图片在Zero123模型上的SDS损失,用于提升空间上的连续性。
为了缓解闪烁问题,4DGen引入了无监督的时间平滑约束。通过计算平面的平滑损失和Gaussians不同时刻的平滑损失,有效提升了时间上的一致性。

实施细节
4DGen的 4D表达采用了4D Gaussian Spaltting的方式,通过一个多分辨率Hexplane对每个Gaussian进行编码。将6个时空平面的特征进行相加,并经过一个额外的MLP解码得到对应Gaussian在不同时刻的位置偏移量。训练上采用三阶段方式,第一阶段对场景进行静态建模,第二阶段利用2D和3D的伪标签进行动态场景的初步建模,第三建模利用平滑损失增强模型的细节和连续性。
所有实验可以在一张RTX3090上完成,对于2.5万个Gaussians只需45分钟的训练,对于9万个Gaussians训练2小时可以得到更加好的细节效果。
实验结果
4DGen可以实现不同视角、不同时间的高质量图片渲染。相较于对比方法在细节表达、噪声去除、颜色还原、时空连续性等方面有显著提升。更多视觉效果可以参考项目主页。

量化对比上,4DGen采用了不同时序图片和参考图片的CLIP距离来衡量生成质量,采用CLIP-T衡量不同时间下的图像连续性。4DGen在多项指标上明显优于过往方法。

总结
4DGen定义了” Grounded 4D Generation“的任务形式,通过视频序列和可选3D模型的引入提升了4D生成的可控性。通过高效的4D Gaussian Splatting的表达,2D和3D伪标签的监督和时空的连续性约束,使得4DGen可以实现高分辨率、长时序的高质量的4D内容生成。
#O²-Recon
在计算机视觉中,物体级别的三维表面重建技术面临诸多挑战。与场景级别的重建技术不同,物体级别的三维重建需要为场景中的每个物体给出独立的三维表示,以支持细粒度的场景建模和理解。这对 AR/VR/MR 以及机器人相关的应用具有重要意义。清华大学提出三维重建的新方法:O²-Recon,用2D扩散模型补全残缺的3D物体
许多现有方法利用三维生成模型的隐空间来完成物体级别的三维重建,这些方法用隐空间的编码向量来表示物体形状,并将重建任务建模成对物体位姿和形状编码的联合估计。得益于生成模型隐空间的优秀性质,这些方法可以重建出完整的物体形状,但仅限于特定类别物体的三维重建,如桌子或椅子。即使在这些类别中,这类方法优化得到的形状编码也往往难以准确匹配实际物体的三维形状。另外一些方法则从数据库中检索合适的 CAD 模型,并辅以物体位姿估计来完成三维重建,这类方法也面临着类似的问题,其可扩展性比较有限,重建准确性低,很难贴合物体真实的三维表面结构。
随着 NeRF 和 NeuS 等技术的发展,imap 和 vMap 等技术能够利用可微渲染来优化物体的几何结构,这些方法能够重建出更加贴合真实物体表面的网格模型,也能够重建多个类别的物体,打破单一物体类别的限制。然而,由于场景内部拍摄角度的约束,很多物体都是被遮挡的,比如靠近墙壁的物体,或者彼此遮挡的物体。在物体被遮挡的情况下,这些方法重建出的物体往往是不完整的,如下图所示。这些不完整的三维模型无法支持大角度的旋转和大范围平移,就很难被各种下游任务利用。

遮挡下的重建结果
清华大学刘永进教授团队提出物体三维重建的新方法 O²-Recon,利用已有的 2D 扩散模型补全物体图像中被遮挡的区域,继而用神经隐式表面场从补全后的图像中重建完整的三维物体。该论文利用重投影机制保持填充区域的三维一致性,并且在隐式重建过程中加入 CLIP 损失函数监督不可见角度的语义信息,最终重建出完整且合理的三维物体模型,支持大角度的旋转和平移,可以用于各种下游任务。目前,该论文已被人工智能顶会之一 AAAI 2024 接收。
论文链接:https://arxiv.org/abs/2308.09591
O²-Recon 简介

方法介绍
受到 2D 扩散模型在图像补全任务中出色表现的启发,研究者设计了 O²-Recon 方法,旨在利用预训练的扩散模型来补全图像中物体被遮挡的区域。虽然现有的扩散模型在图像补全中表现出强劲的性能,但如果没有准确的遮罩(Mask)来指出物体应当被补全的区域,扩散模型就很有可能生成错误的图像内容,比如超出正确区域的结构或者错误的形状。在 O²-Recon 方法中,研究者引入了少量的人工操作来构建准确的 Mask,从而保证 2D 补全和 3D 重建的质量。
给定一段带有物体 Mask 的 RGB-D 视频序列,需要用户选择 1-3 帧图像,并推测这 1-3 帧图像中物体被遮挡的区域,绘制被遮挡区域的 Mask。结合扩散模型补全出的深度信息,研究者将这些视角下的 Mask 投影到所有其他视角,得到其他视角下的遮挡区域 Mask。通过加入少量的人机交互,研究者保证了 Mask 的质量,同时由于这些 Mask 是重投影得到的,它们在不同视角下具有的几何一致性,从而能够引导 2D 扩散模型为遮挡区域填充出合理且一致的图像内容。
在三维重建阶段,研究者利用类似于 NeuS 的神经隐式表面场来完成表面重建,并利用体渲染构建损失函数进行优化。考虑到补全的图像仍然可能存在不一致性,这种隐式表示能在多视角优化的过程中逐渐学习出合理的三维结构。另一方面,研究者从两个角度来提升完全不可见区域的重建效果:首先,研究者利用 CLIP 特征监督新视角下渲染结果与和物体类别文本的一致性;其次,研究者设计了一个级联网络结构来编码隐式表面场,其中包括一个浅层的 MLP+低频位置编码来确保表面的整体平滑性,以及一个更深的 MLP 分支+高频 PE 位置编码来预测 SDF 的残差。这种结构既保证可见区域表面的灵活性,又确保了物体不可见区域的平滑性。
实验效果
物体的三维重建效果

主要实验结果展示
与其他物体级别的三维重建方法相比,O²-Recon 能重建出更准确,更完整的三维结构,如上图所示。其中 FroDO 是基于隐空间形状编码的方法,Scan2CAD 是基于数据库检索的方法,vMap 是利用 NeRF 做表面重建的方法,MonoSDF 是场景级别的三维重建方法。

动图对比

动图对比

动图对比
重建后物体的位置编辑
由于 O²-Recon 重建出的物体较为完整,我们可以对这些物体做大幅度的旋转或平移,在编辑位置之后,从新的角度观察这些物体,其表面质量仍然不错,如下图所示。
在编辑之前,这些物体在原场景中的位置下:

多物体动图对比
在编辑之后,这些物体在新的位置下:

多物体动图对比
总结
本文提出了 O²-Recon 方法,来利用预训练的 2D 扩散模型重建场景中被遮挡物体的完整 3D 几何形状。研究者利用扩散模型对多视角 2D 图像中的遮挡部分进行补全,并从补全后的图像利用神经隐式表面重建 3D 物体。为了防止 Mask 的不一致性,研究者采用了一种人机协同策略,通过少量人机交互生成高质量的多角度 Mask,有效地引导 2D 图像补全过程。在神经隐式表面的优化过程中,研究者设计了一个级联的网络架构来保证 SDF 的平滑性,并利用预训练的 CLIP 模型通过语义一致性损失监督新视角。研究者在 ScanNet 数据集上的实验证明,O²-Recon 能够为任意类别的被遮挡物体重建出精确完整的 3D 表面。这些重建出的完整 3D 物体支持进一步的编辑操作,如大范围旋转和平移。
#3D Gaussian Splatting
这是3D Gaussian Splatting综述, 先回顾3D Gaussian的原理和应用,借着全面比较了3D GS在静态场景、动态场景和驾驶场景中的性能,最后为未来指明了研究方向!
三维 Gaussian splatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3D GS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3D GS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3D GS领域的最新发展和关键贡献。首先详细探索了3D GS出现的基本原理和公式,为理解其意义奠定了基础。进而深度讨论3D GS的实用性。通过促进实时性能,3D GS开辟了大量应用,从虚拟现实到交互式媒体等等。此外,还对领先的3D GS模型进行了比较分析,并在各种基准任务中进行了评估,以突出其性能和实用性。该综述的结论是确定了当前的挑战,并提出了该领域未来研究的潜在途径。通过这项调查,我们旨在为新来者和经验丰富的研究人员提供宝贵的资源,促进在适用和明确的辐射场表示方面的进一步探索和进步。

为了帮助读者跟上3D GS的快速发展,我们提供了首个关于3D GS的调查综述,我们系统而及时地收集了有关该主题的最重要的最新文献。鉴于3D GS是最近的一项创新(图1),我们的重点是自其推出以来出现的各种发展和贡献。3D GS的相关工作主要来源于arxiv。文章的主要目标是对3D GS的初步发展、理论基础和新兴应用进行全面和最新的分析,突出其在该领域的革命性潜力。承认3D GS的新生但快速发展的性质,本次调查还旨在确定和讨论该领域的当前挑战和未来前景。我们提供了对3D GS可能促进的正在进行的研究方向和潜在进展的见解。希望给大家的不仅仅是提供一个学术综述,而是促进这一领域的进一步研究和创新。本文的文章结构如图2所示:

本节首先提供辐射场的简要公式,辐射场是场景渲染中的一个关键概念。它概述了两种主要类型的辐射场表示:隐式如NeRF,它使用神经网络进行直接但计算要求高的渲染;和显式的比如网格,它采用离散结构来更快地访问,但代价是更高的内存使用率。下文进一步建立了与相关领域的联系,如场景重建和渲染。
问题定义

两全其美的3D Gaussian Splatting:3D GS表示从隐式辐射场到显式辐射场的转变。它通过利用3D高斯作为灵活高效的表示,利用了这两种方法的优势。这些高斯系数经过优化,可以准确地表示场景,结合了基于神经网络的优化和显式结构化数据存储的优点。这种混合方法旨在通过更快的训练和实时性能实现高质量渲染,特别是对于复杂的场景和高分辨率输出。3D高斯表示公式化为:

上下文和术语
许多技术和研究学科与3D GS有着密切的关系,下文将对其进行简要描述。
场景重建与渲染:粗略地说,场景重建涉及从图像或其他数据的集合创建场景的3D模型。渲染是一个更具体的术语,专注于将计算机可读信息(例如,场景中的3D对象)转换为基于像素的图像。早期的技术基于光场生成逼真的图像。structure-from-motion(SfM)和多视图立体(MVS)算法通过从图像序列估计3D结构进一步推进了这一领域。这些历史方法为更复杂的场景重建和渲染技术奠定了基础。
神经渲染与辐射场:神经渲染将深度学习与传统图形技术相结合,以创建照片级真实感图像。早期的尝试使用卷积神经网络(CNNs)来估计混合权重或纹理空间解决方案。辐射场表示一个函数,该函数描述了通过空间中每个点在每个方向上传播的光量。NeRFs使用神经网络对辐射场进行建模,从而实现详细逼真的场景渲染。
体积表示和Ray-Marching:体积表示不仅将目标和场景建模为曲面,还将其建模为填充了材质或空白空间的体积。这种方法可以更准确地渲染雾、烟或半透明材料等现象。Ray-Marching是一种与体积表示一起使用的技术,通过增量跟踪穿过体积的光的路径来渲染图像。NeRF分享了体积射线行进的相同精神,并引入了重要性采样和位置编码来提高合成图像的质量。在提供高质量结果的同时,体积射线行进在计算上是昂贵的,这促使人们寻找更有效的方法,如3D GS。
基于点的渲染:基于点的渲染是一种使用点而不是传统多边形来可视化3D场景的技术。这种方法对于渲染复杂、非结构化或稀疏的几何数据特别有效。点可以用额外的属性来增强,如可学习的神经描述符,并有效地渲染,但这种方法可能会遇到诸如渲染中的漏洞或混叠效应等问题。3D GS通过使用各向异性高斯来扩展这一概念,以实现场景的更连续和更有凝聚力的表示。
显式辐射场的3D高斯
3D GS在不依赖神经组件的情况下,在实时、高分辨率图像渲染方面取得了突破。
学习得到的3D高斯用于新视角合成
考虑一个由(数百万)优化的3D高斯表示的场景。目标是根据指定的相机姿势生成图像。回想一下,NeRF是通过计算要求很高的体积射线行进来完成这项任务的,对每个像素的3D空间点进行采样。这种模式难以实现高分辨率图像合成,无法实现实时渲染速度。与此形成鲜明对比的是,3D GS首先将这些3D高斯投影到基于像素的图像平面上,这一过程被称为“splatting”(图3a)。然后,3D GS对这些高斯进行排序,并计算每个像素的值。如图所示,NeRF和3D GS的渲染可以被视为彼此的逆过程。在接下来的内容中,我们从3D高斯的定义开始,这是3D GS中场景表示的最小元素。接下来描述如何将这些3D高斯用于可微分渲染。最后介绍了3D GS中使用的加速技术,这是快速渲染的关键。
三维高斯的性质:三维高斯的特征是其中心(位置)μ、不透明度α、三维协方差矩阵∑和颜色c。对于与视图相关的外观,c由球面谐波表示。所有属性都是可学习的,并通过反向传播进行优化。
Frustum Culling:给定指定的相机位姿,此步骤将确定哪些3D高斯位于相机的平截头体之外。通过这样做,给定视图之外的3D高斯将不会参与后续计算,从而节省计算资源。
Splatting:**在该步骤中,3D高斯(椭球)被投影到2D图像空间(椭球)中用于渲染。给定观看变换W和3D协方差矩阵∑,投影的2D协方差矩阵∑′使用以下公式计算:

Tiles (Patches):为了避免为每个像素推导高斯系数的成本计算,3D GS将精度从像素级转移到patch级细节。具体来说,3D GS最初将图像划分为多个不重叠的块,在原始论文中称为“tiles”。图3b提供了tiles的图示。每个瓦片包括16×16个像素。3D GS进一步确定哪些tiles与这些投影的高斯图相交。假设投影的高斯可能覆盖多个tiles,逻辑方法包括复制高斯,为每个副本分配相关tiles的标识符(即tile ID)。
并行渲染:在复制之后,3D GS将各个tile ID与从每个高斯的视图变换获得的深度值相组合。这生成字节的未排序列表,其中高位表示tile ID,低位表示深度。通过这样做,排序后的列表可以直接用于渲染(即alpha合成)。图3c和图3d提供了这些概念的视觉演示。值得强调的是,渲染每个tile和像素都是独立发生的,这使得这个过程非常适合并行计算。另一个好处是,每个tile的像素都可以访问公共共享内存,并保持统一的读取序列,从而能够以更高的效率并行执行alpha合成。在原始论文的官方实现中,该框架将tile和像素的处理分别视为类似于CUDA编程架构中的块和线程。

简而言之,3D GS在前向处理阶段引入了几种近似,以提高计算效率,同时保持高标准的图像合成质量。
3D Gaussian Splatting的优化
3D GS的核心是一个优化过程,旨在构建大量的3D高斯集合,准确捕捉场景的本质,从而促进自由视点渲染。一方面,3D高斯的特性应该通过可微分渲染来优化,以适应给定场景的纹理。另一方面,能够很好地表示给定场景的3D高斯数是预先未知的。一个很有前途的途径是让神经网络自动学习3D高斯密度。我们将介绍如何优化每个高斯的性质以及如何控制高斯的密度。这两个过程在优化工作流程中是交错的。由于在优化过程中有许多手动设置的超参数,为了清晰起见,我们省略了大多数超参数的符号。
参数优化
损失函数:一旦图像的合成完成,就将损失计算为渲染图像和GT的差:

密度控制
初始化:3D GS从SfM或随机初始化的稀疏点的初始集合开始。然后,采用点加密和修剪来控制三维高斯的密度。
点密集化:在点密集化阶段,3D GS自适应地增加高斯密度,以更好地捕捉场景的细节。这一过程特别关注几何特征缺失的区域或高斯分布过于分散的区域。密集化在一定次数的迭代之后执行,目标是表现出大的视图空间位置梯度(即,高于特定阈值)的高斯。它涉及在重建不足的区域克隆小高斯,或在重建过度的区域分裂大高斯。对于克隆,将创建高斯的副本,并将其移向位置梯度。对于分裂,用两个较小的高斯代替一个较大的高斯,将它们的规模缩小一个特定的因子。该步骤寻求高斯在3D空间中的最佳分布和表示,从而提高重建的整体质量。
点修剪:点修剪阶段涉及去除多余或影响较小的高斯,在某种程度上可以被视为一个正则化过程。这一步骤是通过消除几乎透明的高斯(α低于指定阈值)和在世界空间或视图空间中过大的高斯来执行的。此外,为了防止输入相机附近高斯密度的不合理增加,在一定次数的迭代后,将高斯的阿尔法值设置为接近零。这允许控制必要的高斯密度的增加,同时能够淘汰多余的高斯。该过程不仅有助于节省计算资源,还确保模型中的高斯对场景的表示保持精确和有效。
应用领域和任务
3D GS的变革潜力远远超出了其理论和计算的进步。本节深入探讨3D GS正在产生重大影响的各种开创性应用领域,如机器人、场景重建和表示、人工智能生成的内容、自动驾驶,甚至其他科学学科。3D GS的应用展示了其多功能性和革命性的潜力。在这里,我们概述了一些最著名的应用领域,深入了解3D GS如何在每个领域形成新的前沿。
SLAM
SLAM是机器人和自主系统的核心计算问题。它涉及机器人或设备在未知环境中理解其位置的挑战,同时建图环境布局。SLAM在各种应用中至关重要,包括自动驾驶汽车、增强现实和机器人导航。SLAM的核心是创建未知环境的地图,并实时确定设备在该地图上的位置。因此,SLAM对计算密集型场景表示技术提出了巨大的挑战,同时也是3D GS的良好试验台。
3D GS作为一种创新的场景表示方法进入SLAM领域。传统的SLAM系统通常使用点/曲面云或体素网格来表示环境。相比之下,3D GS利用各向异性高斯来更好地表示环境。这种表示提供了几个好处:1)效率:自适应地控制3D高斯的密度,以便紧凑地表示空间数据,减少计算负载。2) 准确性:各向异性高斯可以进行更详细、更准确的环境建模,尤其适用于复杂或动态变化的场景。3) 适应性:3D GS可以适应各种规模和复杂的环境,使其适用于不同的SLAM应用。一些创新研究在SLAM中使用了3D高斯飞溅,展示了这种范式的潜力和多功能性。
动态场景建模
动态场景建模是指捕捉和表示随时间变化的场景的三维结构和外观的过程。这涉及到创建一个数字模型,该模型准确地反映场景中对象的几何体、运动和视觉方面。动态场景建模在各种应用中至关重要,包括虚拟和增强现实、3D动画和计算机视觉。4D高斯散射(4D GS)将3D GS的概念扩展到动态场景。它结合了时间维度,允许对随时间变化的场景进行表示和渲染。这种范式在实时渲染动态场景的同时保持高质量的视觉输出方面提供了显著的改进。
AIGC
AIGC是指由人工智能系统自主创建或显著改变的数字内容,特别是在计算机视觉、自然语言处理和机器学习领域。AIGC的特点是能够模拟、扩展或增强人工生成的内容,实现从逼真图像合成到动态叙事创作的应用。AIGC的意义在于其在各个领域的变革潜力,包括娱乐、教育和技术发展。它是不断发展的数字内容创作格局中的一个关键元素,为传统方法提供了可扩展、可定制且通常更高效的替代方案。
3D GS的这种明确特性有助于实现实时渲染功能以及前所未有的控制和编辑水平,使其与AIGC应用程序高度相关。3D GS的显式场景表示和可微分渲染算法完全符合AIGC生成高保真、实时和可编辑内容的要求,这对虚拟现实、交互式媒体等领域的应用至关重要。
自动驾驶
自动驾驶旨在让车辆在没有人为干预的情况下导航和操作。这些车辆配备了一套传感器,包括相机、LiDAR以及雷达,并结合了先进的算法、机器学习模型和强大的计算能力。中心目标是感知环境,做出明智的决策,安全高效地执行机动。自动驾驶对交通运输具有变革潜力,提供了关键好处,如通过减少人为失误提高道路安全性,增强无法驾驶者的机动性,以及优化交通流量,从而减少拥堵和环境影响。
自动驾驶汽车需要感知和解读周围环境,才能安全行驶。这包括实时重构驾驶场景,准确识别静态和动态物体,并了解它们的空间关系和运动。在动态驾驶场景中,由于其他车辆、行人或动物等移动物体,环境不断变化。实时准确地重建这些场景对于安全导航至关重要,但由于所涉及元素的复杂性和可变性,这是一项挑战。在自动驾驶中,3D GS可以用于通过将数据点(例如从LiDAR等传感器获得的数据点)混合成内聚和连续的表示来重建场景。这对于处理不同密度的数据点和确保场景中静态背景和动态目标的平滑准确重建特别有用。到目前为止,很少有作品使用3D高斯对动态驾驶/街道场景进行建模,并且与现有方法相比,在场景重建方面表现出优异的性能。
性能对比
本节通过展示我们之前讨论的几种3D GS算法的性能来提供更多的经验证据。3D GS在许多任务中的不同应用,加上每个任务的定制算法设计,使得在单个任务或数据集中对所有3D GS算法进行统一比较变得不切实际。因此,我们在3D GS领域中选择了三个具有代表性的任务进行深入的性能评估。性能主要来源于原始论文,除非另有说明。
定位性能

静态场景渲染性能

动态场景渲染性能

驾驶场景渲染性能

数字人体性能

未来研究方向
尽管近几个月来3D GS的后续工作取得了显著进展,但我们认为仍存在一些有待克服的挑战。
- 数据高效的3D GS解决方案:从有限的数据点生成新颖的视图和重建场景是非常令人感兴趣的,特别是因为它们有可能以最小的输入增强真实感和用户体验。最近的进展已经探索了使用深度信息、密集概率分布和像素到高斯映射来促进这种能力。然而,仍然迫切需要在这一领域进行进一步探索。此外,3D GS的一个显著问题是在观测数据不足的地区出现伪影。这一挑战是辐射场渲染中的一个普遍限制,因为稀疏数据往往会导致重建不准确。因此,在这些稀疏区域中开发新的数据插值或积分方法代表了未来研究的一条很有前途的途径。
- 内存高效的3D GS解决方案:虽然3D GS展示了非凡的能力,但其可扩展性带来了重大挑战,尤其是当与基于NeRF的方法并置时。后者得益于仅存储学习的MLP的参数的简单性。在大规模场景管理的背景下,这种可扩展性问题变得越来越严重,其中计算和内存需求显著增加。因此,迫切需要在训练阶段和模型存储期间优化内存利用率。探索更高效的数据结构和研究先进的压缩技术是解决这些限制的有希望的途径。
- 高级渲染算法:目前3D GS的渲染管道是向前的,可以进一步优化。例如,简单的可见性算法可能导致高斯深度/混合顺序的剧烈切换。这突出了未来研究的一个重要机会:实现更先进的渲染算法。这些改进的方法应旨在更准确地模拟给定场景中光和材料特性的复杂相互作用。一种有前景的方法可能涉及将传统计算机图形学中的既定原理同化和适应到3D GS的特定环境中。在这方面值得注意的是,正在进行的将增强渲染技术或混合模型集成到3D GS当前计算框架中的努力。此外,逆渲染及其应用的探索为研究提供了肥沃的土壤。
- 优化和正则化:各向异性高斯虽然有利于表示复杂的几何形状,但会产生视觉伪像。例如,那些大的3D高斯,尤其是在具有依赖于视图的外观的区域,可能会导致弹出的伪影,视觉元素突然出现或消失,破坏沉浸感。在3D GS的正则化和优化方面有相当大的探索潜力。引入抗锯齿可以缓解高斯深度和混合顺序的突然变化。优化算法的增强可能会更好地控制空间中的高斯系数。此外,将正则化纳入优化过程可以加速收敛、平滑视觉噪声或提高图像质量。此外,如此大量的超参数影响了3D GS的泛化,这急需解决方案。
- 网格重建中的3D高斯:3D GS在网格重建中的潜力及其在体积和表面表示谱中的位置尚待充分探索。迫切需要研究高斯基元如何适用于网格重建任务。这一探索可以弥合体积绘制和传统基于表面的方法之间的差距,为新的绘制技术和应用提供见解。
- 赋予3D GS更多可能性:尽管3D GS具有巨大的潜力,但3D GS的全部应用范围在很大程度上仍未开发。一个很有前途的探索途径是用额外的属性来增强3D高斯,例如为特定应用量身定制的语言和物理属性。此外,最近的研究已经开始揭示3D GS在几个领域的能力,例如,相机姿态估计、手-物体相互作用的捕捉和不确定性的量化。这些初步发现为跨学科学者进一步探索3D GS提供了重要机会。
结论
据我们所知,这篇综述首次全面概述了3D GS,这是一项革命性的显式辐射场和计算机图形学技术。它描绘了传统NeRF方法的范式转变,突出了3D GS在实时渲染和增强可控性方面的优势。我们的详细分析证明了3D GS在实际应用中的优势,特别是那些需要实时性能的应用。我们提供了对未来研究方向和该领域尚未解决的挑战的见解。总的来说,3D GS是一项变革性技术,有望对3D重建和表示的未来发展产生重大影响。这项调查旨在作为一项基础资源,推动这一快速发展领域的进一步勘探和进展。
#ORB-SLAM3~地图初始化
基础矩阵/单应矩阵/三角化的实际应用
目的
通收获如下内容:
- 对极几何、对极约束以及基础矩阵(Fundamental)/本质矩阵(Essential)的数学原理,并且明白为何视觉SLAM中需要对极几何
- 单应矩阵(Homography)的基础概念,以及单应矩阵与基础矩阵的区别
- 如何通过匹配点对求解基础矩阵和单应矩阵
- 如何通过基础矩阵和单应矩阵求解相机的位姿
- 三角化的基础概念和应用
- ORBSLAM中的地图初始化详细流程
- 一个精简的剥离了复杂的ORB_SLAM3框架的地图初始化代码,并进行详细的中文注释。同时,提供可直接运行的demo。
本文代码:https://github.com/zeal-up/ORB_SLAM_Tracking
Part1 视觉SLAM中的地图初始化
在视觉SLAM中,地图初始化是一个非常重要的步骤,它决定了后续的跟踪、建图等模块的效果。简单来说,初始化的目的是利用前几帧图像,计算出相机位姿,并且构建出第一批3D地图点
第一批3D地图点为跟踪、建图等模块提供了一个初始的地图,这样后续的模块就可以利用这些地图点进行跟踪、建图等工作。
由于ORB_SLAM系列工作将传感器模式扩展到了:单目、双目、RGBD、IMU+单目、IMU+双目、IMU+RGBD等多种模式,所以地图初始化的方式也有所不同。
双目由于已知两个相机的内外参,可以直接三角化出3D点。三角化是单目的一个步骤,所以双目初始化比较简单。RGBD可以直接通过深度值还原3D坐标,更加简单。 配置了IMU之后实际也可以直接两个相机之间的姿态,也可以直接三角化出3D点(虽然IMU初始化需要考虑IMU参数的初始化,但是这部分内容不在本文的讨论范围内)。
因此,本文将重点放在单目初始化上。单目初始化由于涉及到对极几何和三角化和矩阵求解等知识,对于初学者会比较复杂。
Part2 ORB_SLAM地图初始化流程

01-init_pipeline
本文将对这流程中的每一个步骤进行详细的讲解,并且给出代码实现。
Part3 ORB特征提取及匹配
特征点提取是一个比较独立的内容,对于ORB特征提取可以参考这篇文章:https://zeal-up.github.io/2023/05/18/orbslam/orbslam3-ORBextractor/

Part4 对极几何及对极约束
4.1从实际问题出发
为什么视觉SLAM需要对极几何?

02-feature_point_matching
那么,我们现在的问题是,如何从这些点对的匹配关系,得到相机之间的相对位姿?
PS:通常,我们会将第一帧图像当作参考帧,也就是世界坐标系。第二帧相机的位姿也就是相对于第一帧相机的位姿。
4.2 对极几何
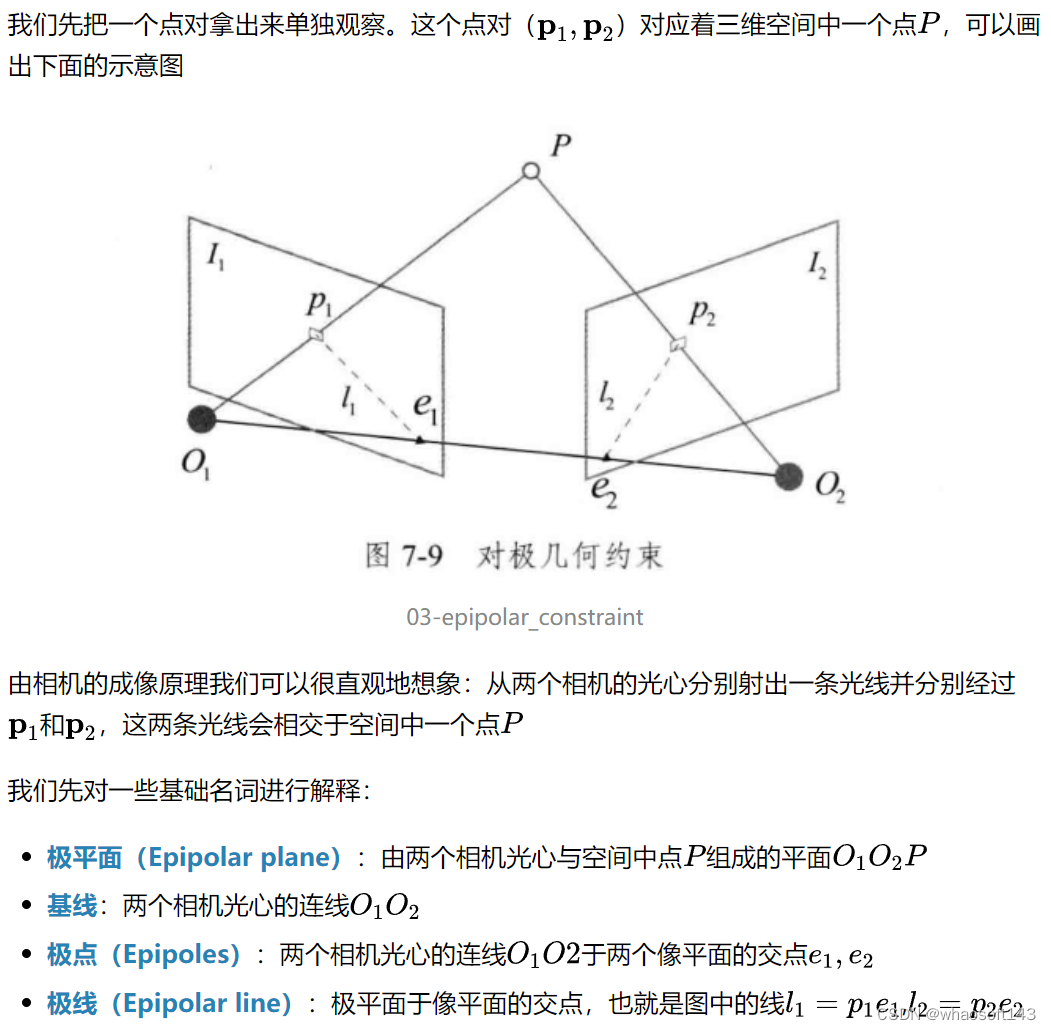
所谓的对极几何,就是指物体与两个相机之间空间几何关系。我们可以利用这个几何关系来求解相机之间的相对位姿。
4.3 对极约束


4.4 基础矩阵(Fundamental Matrix)F与本质矩阵(Essential Matrix)E
公式(7)和公式(9)都可以叫做对极约束。公式(7)忽略了相机内参的影响,因为一般在SLAM中相机内参是已知的,而归一化平面坐标可以方便地由相机内参和像素坐标得到,因此公式(7)是公式(9)的简化形式。
为了简便,我们可以记公式(9)中间部分为两个矩阵

要注意的是,由于上式中等式右边是0,因此左右两边同时乘以一个系数等式依旧成立,这一点我们在后面会再次提到
4.5 对极约束的几何意义
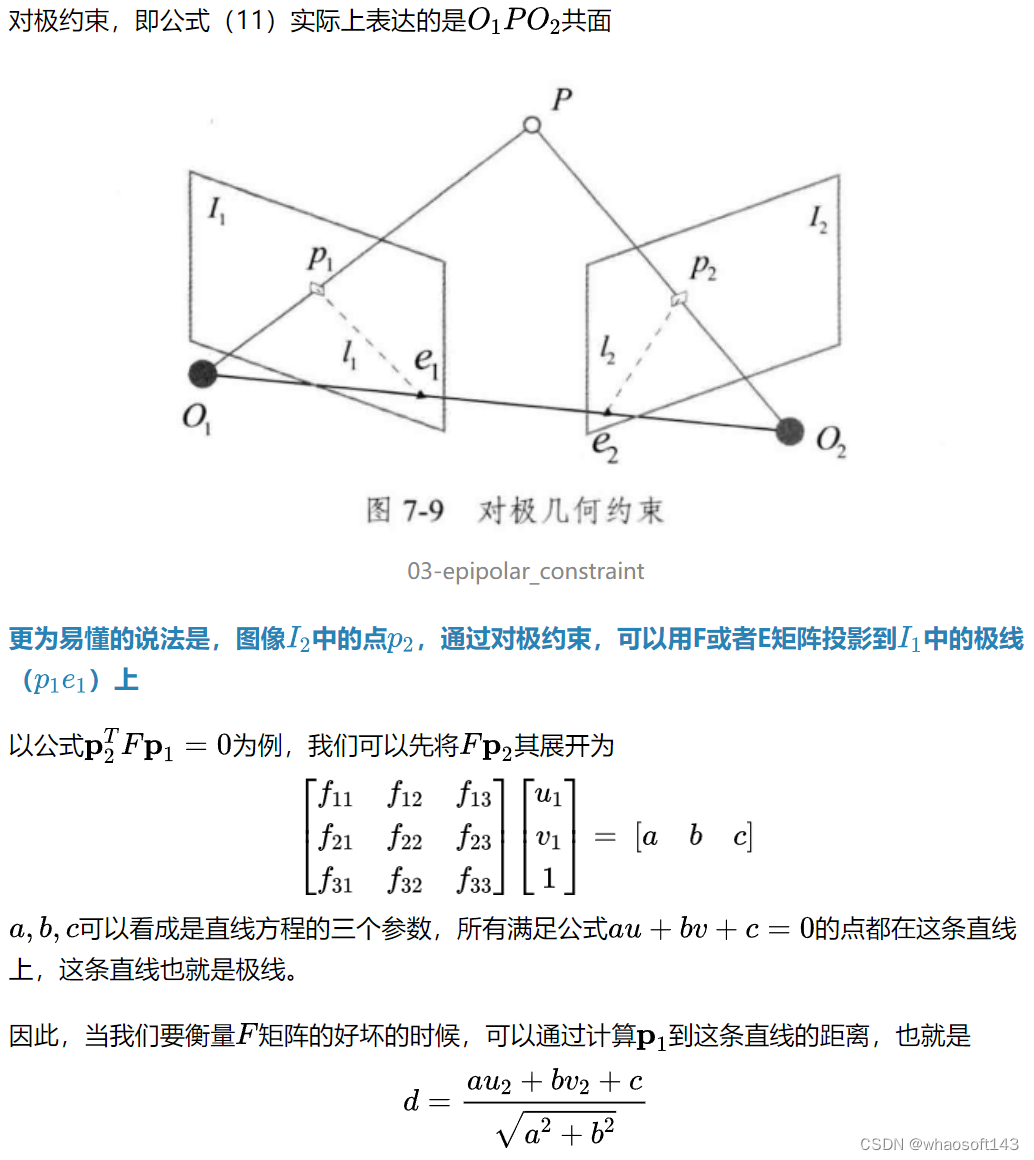
4.6 本质矩阵与基础矩阵的求解
4.6.1 基础矩阵的求解推导
本质矩阵是一个3x3矩阵,但其是由旋转与平移组成(6自由度),并且,要注意到公式(11)可以对任意尺度成立,也就是说本质矩阵可以放缩任意一个尺度,因此,本质矩阵有5个自由度。 因此,从理论上最少可以由5对点对求解(注意这里与PnP算法的不同,PnP算法等号两边没有0,一个点对可以建立两个等式,因此一个点对可以约束2个自由度。而这里一个点对只能建立一条等式,也就是约束一个自由度,因此需要5个点对)
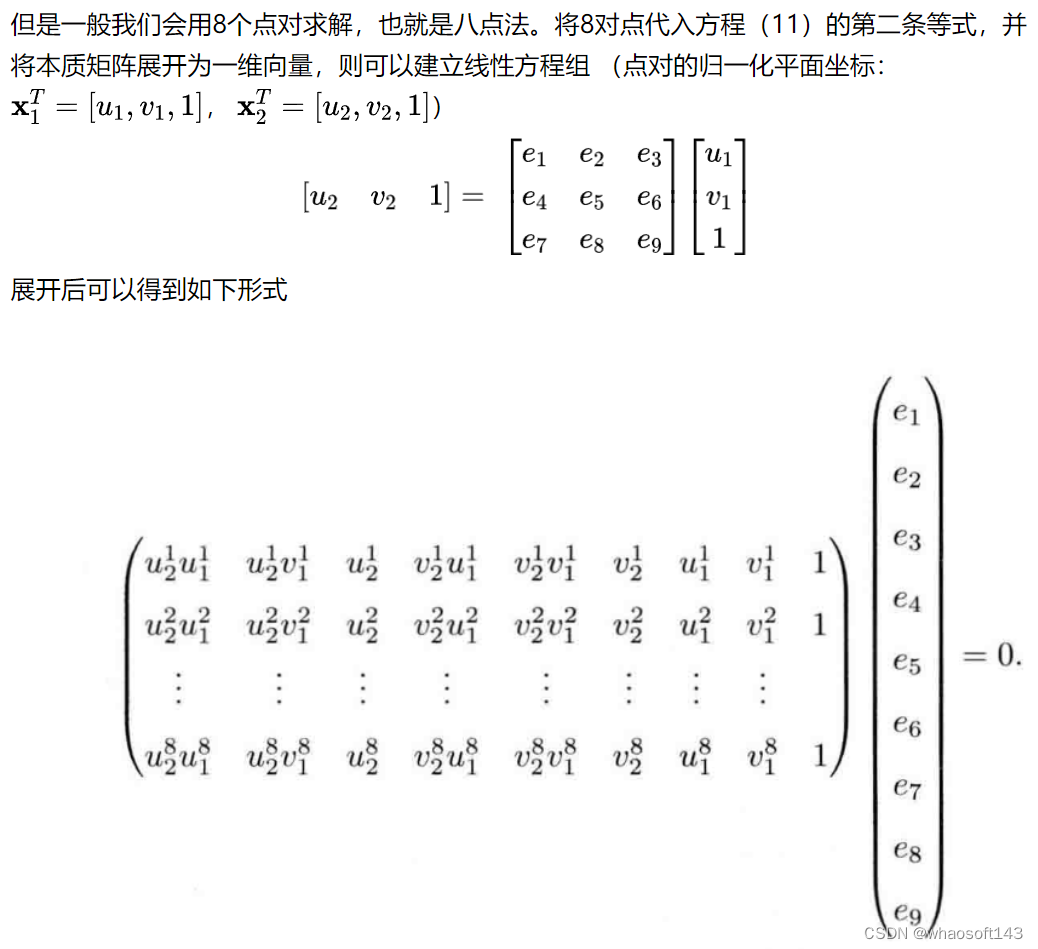
04-solve_essential_matrix
以上方程求解后就可以得到本质矩阵(对任意尺度成立)
4.6.2 使用OpenCV求解
OpenCV有Api可以直接通过匹配点对计算基础矩阵
Mat cv::findFundamentalMat(
InputArray points1,
InputArray points2,
int method,
double ransacReprojThreshold,
double confidence,
int maxIters,
OutputArray mask = noArray()
)具体说明可以参考Api说明:findFundamentalMat()
Part5 单目尺度不确定性

5.1 如何理解单目尺度不确定性
让我们再次回到对极几何的图
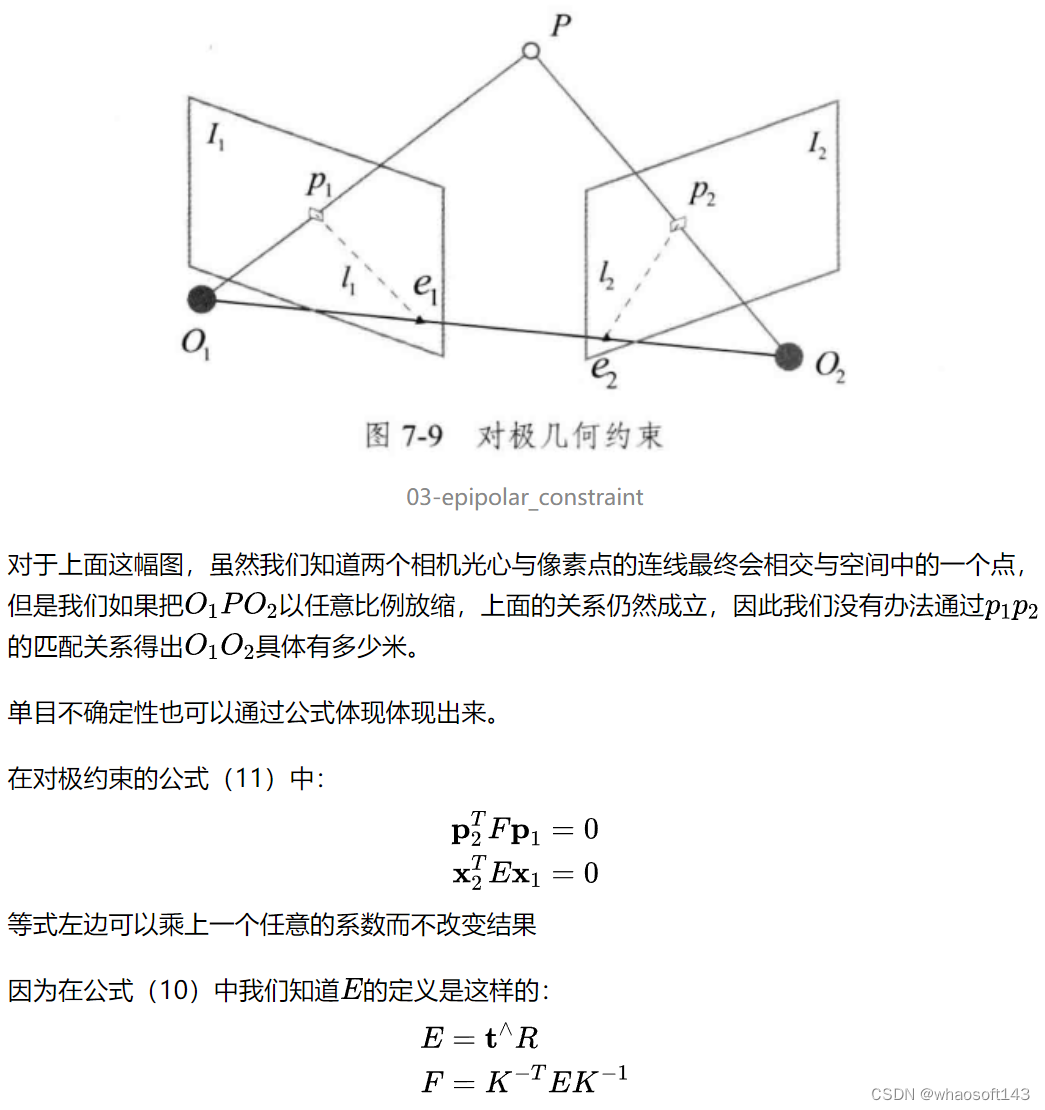

Part6 单应矩阵(Homography Matrix)
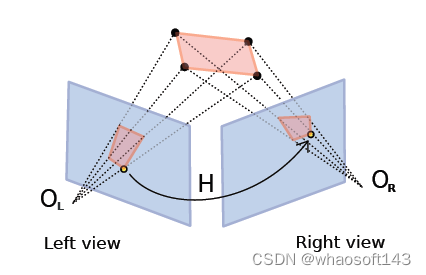
我们前面讨论基础矩阵的概念以及如何从一些匹配点对关系中求解基础矩阵。我们没有对关键点是否在一个平面上进行任何假设。但是,如果我们假设关键点在一个平面上,那么我们就可以使用单应矩阵(Homography Matrix)来求解相机之间的位姿。

05-homography_example
当匹配点对的关键点都是在3D空间中一个平面上时,这些点对关系可以通过单应矩阵来描述(相差一个常量系数)
06_homographyMatrix

6.1 单应矩阵与相机内外参的关系

6.2 单应矩阵的求解
6.2.1 单应矩阵的求解推导

6.2.2 使用OpenCV求解
OpenCV提供接口可以直接求解单应矩阵
Mat cv::findHomography(
InputArray srcPoints,
InputArray dstPoints,
int method = 0,
double ransacReprojThreshold = 3,
OutputArray mask = noArray(),
const int maxIters = 2000,
const double confidence = 0.995
)详细的使用可以参考Api说明:cv::findHomography()
如果对内部实现有兴趣,可以参考这篇文章博客:对OpenCV::findHomography的源码解读
Part7 从H、E矩阵恢复R、t
7.1 基础要点
F矩阵与E矩阵只相差相机内参,通常我们会将F矩阵转换为E矩阵,然后再恢复R、t。
从H、E矩阵求解R、t涉及到比较复杂的数学推导,对于CV从业人员我认为这部分可以忽略具体推导过程,但是要抓住几个要点:

7.2 从E矩阵恢复R、t
求解推导过程忽略,我们只需要知道根据E可以分解出两对R,t如下

08-four_situation_of_E
7.3 使用OpenCV从E中求解R,t
OpenCV提供了一个api可以直接从E矩阵中分解出R、t
void cv::decomposeEssentialMat(
InputArray E,
OutputArray R1,
OutputArray R2,
OutputArray t
)详细使用参考API说明:cv::decomposeEssentialMat
7.4 从H矩阵恢复R、t
从H矩阵恢复R、t有多种方法,论文中的方法叫Faugeras SVD-based decomposition,最终可以求解出8种解。另外一种有名的数值解法(通过奇异值分解)叫Zhang SVD-based decomposition
OpenCV的接口使用的是分析解法:https://inria.hal.science/inria-00174036v3/documentOpenCV的接口最终返回4种解
OpenCV的接口使用说明:cv::decomposeHomographyMat
Part8 如何选择正确的R、t
无论从E矩阵还是H矩阵中恢复出R、t,都会得到多种解。我们需要从这些解中选择出正确的解。 最简单的做法是利用分解出的R、t对匹配点进行三角化,并检查该3D点在两个相机下的深度值,3D点必须在两个相机下都是正的才是正确的解。
对于单应矩阵的分解结果,OpenCV提供了一个函数可以帮助我们选择正确的解:cv::filterHomographyDecompByVisibleRefpoints
在ORB_SLAM中,对于每一种解,都会对所有匹配点进行三角化,对三角化出来的点,会进行很多步骤的检查,最后选择拥有最多内点的解作为正确的解。
Part9 三角化
9.1 三角化的基础概念和推导
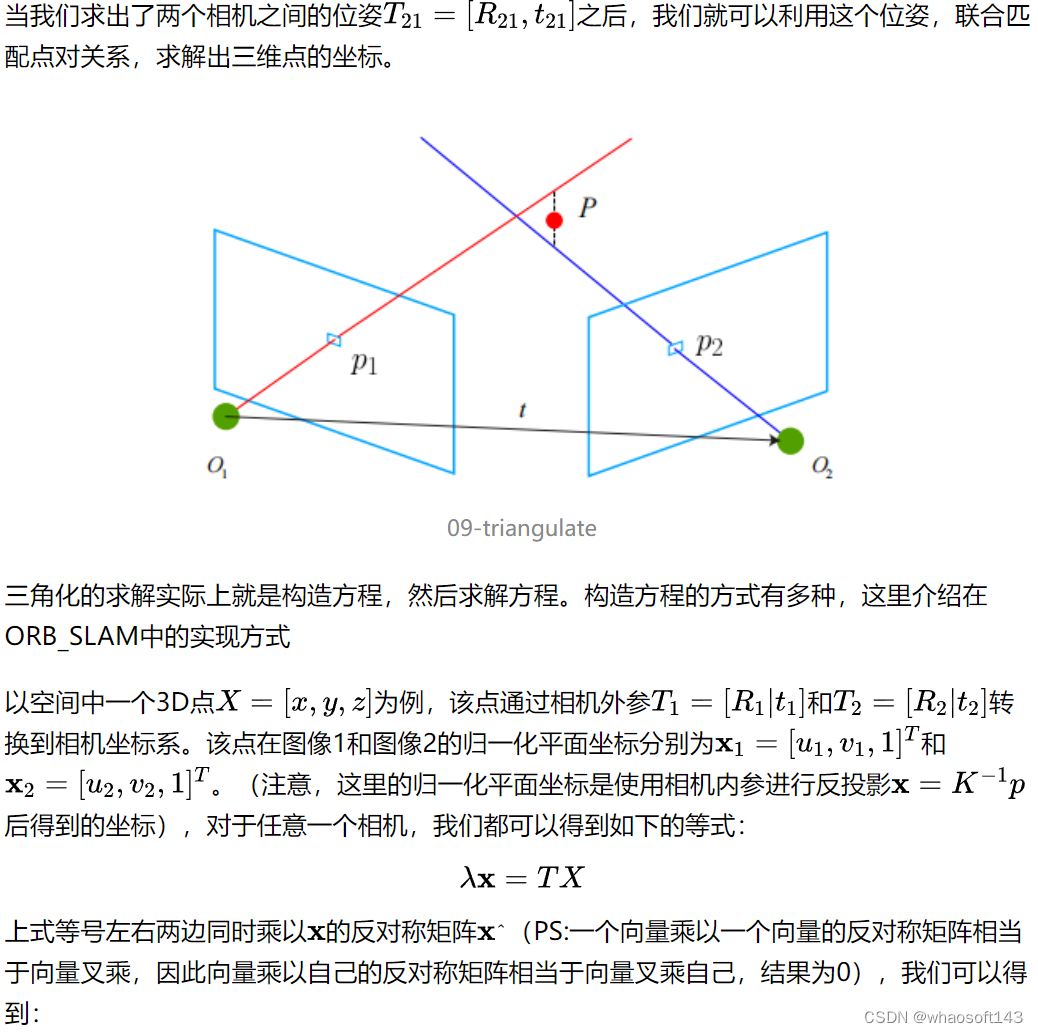

9.2 三角化的求解实现
可以用SVD求解上述方程,求解出的3D坐标有4个元素,需要将第四个元素归一化为1。这里把ORB_SLAM的这部分代码也贴出来
/**
* @brief 三角化获得三维点
* @param x_c1 点在关键帧1下的归一化坐标
* @param x_c2 点在关键帧2下的归一化坐标
* @param Tc1w 关键帧1投影矩阵 [K*R | K*t]
* @param Tc2w 关键帧2投影矩阵 [K*R | K*t]
* @param x3D 三维点坐标,作为结果输出
*/
bool GeometricTools::Triangulate(
Eigen::Vector3f &x_c1, Eigen::Vector3f &x_c2, Eigen::Matrix<float,3,4> &Tc1w, Eigen::Matrix<float,3,4> &Tc2w,
Eigen::Vector3f &x3D)
{
Eigen::Matrix4f A;
// x = a*P*X, 左右两面乘x的反对称矩阵 a*[x]^ * P * X = 0 ,[x]^*P构成了A矩阵,中间涉及一个尺度a,因为都是归一化平面,但右面是0所以直接可以约掉不影响最后的尺度
// 0 -1 v P(0) -P.row(1) + v*P.row(2)
// 1 0 -u * P(1) = P.row(0) - u*P.row(2)
// -v u 0 P(2) u*P.row(1) - v*P.row(0)
// 发现上述矩阵线性相关(第一行乘以-u加上第二行乘以-v等于第三行),所以取前两维,两个点构成了4行的矩阵(X分别投影到相机1和相机2),就是如下的操作,求出的是4维的结果[X,Y,Z,A],所以需要除以最后一维使之为1,就成了[X,Y,Z,1]这种齐次形式
A.block<1,4>(0,0) = x_c1(0) * Tc1w.block<1,4>(2,0) - Tc1w.block<1,4>(0,0);
A.block<1,4>(1,0) = x_c1(1) * Tc1w.block<1,4>(2,0) - Tc1w.block<1,4>(1,0);
A.block<1,4>(2,0) = x_c2(0) * Tc2w.block<1,4>(2,0) - Tc2w.block<1,4>(0,0);
A.block<1,4>(3,0) = x_c2(1) * Tc2w.block<1,4>(2,0) - Tc2w.block<1,4>(1,0);
// 解方程 AX=0
Eigen::JacobiSVD<Eigen::Matrix4f> svd(A, Eigen::ComputeFullV);
Eigen::Vector4f x3Dh = svd.matrixV().col(3);
if(x3Dh(3)==0)
return false;
// Euclidean coordinates
x3D = x3Dh.head(3)/x3Dh(3);
return true;
}9.3 使用OpenCV进行三角化
OpenCV也提供接口进行三角化,且可以批量操作:cv::triangulatePoints
Part10 ORB_SLAM中的初始化
ORB_SLAM中对于初始化部分的操作虽然基础原理离不开上面的内容,但是具体实现上有很多细节,不仅仅反应作者的深厚算法功底,也反映了作者的工程能力。我们这里介绍ORB_SLAM中初始化部分的一些特殊操作
10.1 自动选择Homography或者Fundamental模型进行初始化

10.2 从H、F矩阵恢复R、t
选择了H或者F模型之后,会对H/F进行分解得到R、t。对于每一种[R,t]组合,会对所有匹配点对进行三角化,然后对三角化出来的3D点进行检查,去除以下情况的点:
- 深度为负(需满足在两个相机下都是正的)
- 重投影误差大于某个阈值(默认为2个像素)
同时,对每个点会统计其到两个相机光心的夹角,最后对所有夹角进行从小到大排序,选择第50个夹角,如果这个夹角小于1度,会认为初始化失败。
10.3 只在特征金字塔的最底层进行特征点匹配
在ORB_SLAM中,初始化阶段特征点匹配是在特征金字塔的最底层进行的。这一点也可以理解。图像金字塔主要是用来解决移动造成的尺度变化,而在初始化阶段,两帧图像不会有大的尺度变化,因此只需要在最底层进行匹配即可。
Part11附录A:在复现过程中的一些问题
PS:本文提供详细注释的精简代码,并附有demo:https://github.com/zeal-up/ORB_SLAM_Tracking
A-1 H矩阵的分数一直比F模型的分数低
在实验的过程中发现,H矩阵的分数一直比F模型的分数低,初始化时一直是选择的F模型进行初始化。后来发现ORBSLAM3中有一个bug,在使用H模型重建时并没有对3D点赋值,所以H模型其实可能一直没有被用上。https://github.com/UZ-SLAMLab/ORB_SLAM3/pull/806
A-2 与OpenCV求解H/F矩阵的对比
笔者在使用ORB_SLAM提供的代码进行初始化的时候很容易失败,而且每次运行的结果可能都不太相同。后来尝试使用OpenCV的接口求解H/F矩阵,发现每次运行的结果都比较一致,而且很少失败。OpenCV在求解H/F矩阵时也是用的RANSAC方法,区别比较大的应该是分数的计算。ORB_SLAM中计算分数的时候是计算双边投影误差,而OpenCV中计算分数的时候是计算内点个数。这两种方法的区别可能导致了ORB_SLAM中的实现对随机数非常敏感,每次运行的结果都不一样。
同时,使用ORB_SLAM的实现找出来的H/F矩阵,很容易在后续的三角化阶段被拒绝。而使用OpenCV接口求解的H/F矩阵,很少被拒绝。
另外,使用OpenCV的接口计算H、F矩阵,速度要比ORB_SLAM中的实现快很多,一个原因可能还是双边投影误差的计算需要两次投影。
Part12 附录B:Demo结果
PS:本文提供详细注释的精简代码,并附有demo:https://github.com/zeal-up/ORB_SLAM_Tracking
B.1 特征提取结果
同时可视化特征点的角度方向

run_01-features
B.2 特征点匹配

run_02-matches
B.3 成功三角化的特征点
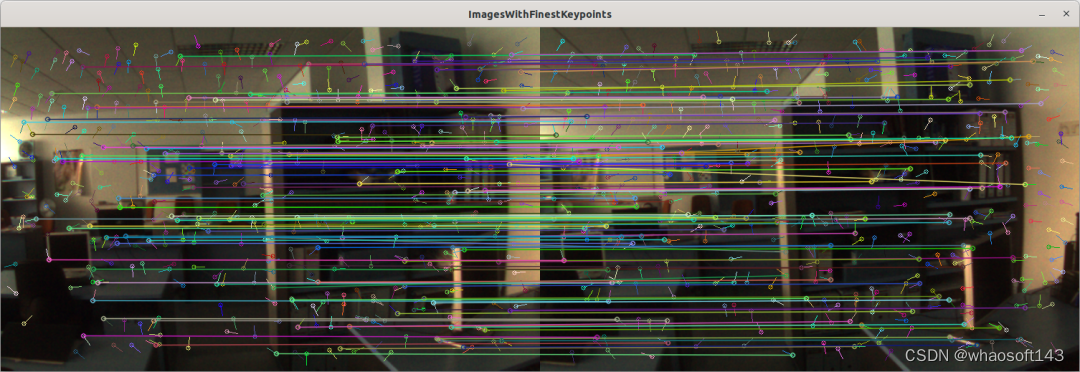
run_03-matchesWithFinestFeatures
B.4 三角化的点
